Mengakses GPU dari Jawa menunjukkan kekuatan yang luar biasa. Ini menjelaskan cara kerja GPU dan cara mengakses dari Java.Pemrograman GPU adalah dunia yang sangat tinggi bagi programmer Java. Ini dapat dimengerti karena tugas-tugas Java yang normal tidak cocok untuk GPU. Namun, GPU memiliki kinerja teraflops, jadi mari kita jelajahi kemampuan mereka.Untuk membuat topik ini dapat diakses, saya akan meluangkan waktu menjelaskan arsitektur GPU bersama dengan sedikit sejarah yang akan memfasilitasi perendaman dalam pemrograman besi.Setelah saya ditunjukkan perbedaan antara komputasi GPU dan CPU, saya akan menunjukkan cara menggunakan GPU di dunia Java. Akhirnya, saya akan menjelaskan kerangka kerja utama dan perpustakaan yang tersedia untuk menulis kode Java dan menjalankannya pada GPU, dan saya akan memberikan beberapa contoh kode.Sedikit latar belakang
GPU pertama kali dipopulerkan oleh NVIDIA pada tahun 1999. Ini adalah prosesor khusus yang dirancang untuk memproses data grafik sebelum dipindahkan ke layar. Dalam banyak kasus, ini memungkinkan beberapa perhitungan untuk membongkar CPU, sehingga membebaskan sumber daya CPU yang mempercepat perhitungan yang tidak dimuat ini. Hasilnya adalah input besar dapat diproses dan disajikan pada resolusi output yang lebih tinggi, menjadikan presentasi visual lebih menarik dan laju bingkai lebih halus.Inti dari pemrosesan 2D / 3D terutama dalam manipulasi matriks, ini dapat dikontrol menggunakan pendekatan terdistribusi. Apa yang akan menjadi pendekatan yang efektif untuk pemrosesan gambar? Untuk menjawab ini, mari kita bandingkan arsitektur CPU standar (ditunjukkan pada Gambar 1.) dan GPU.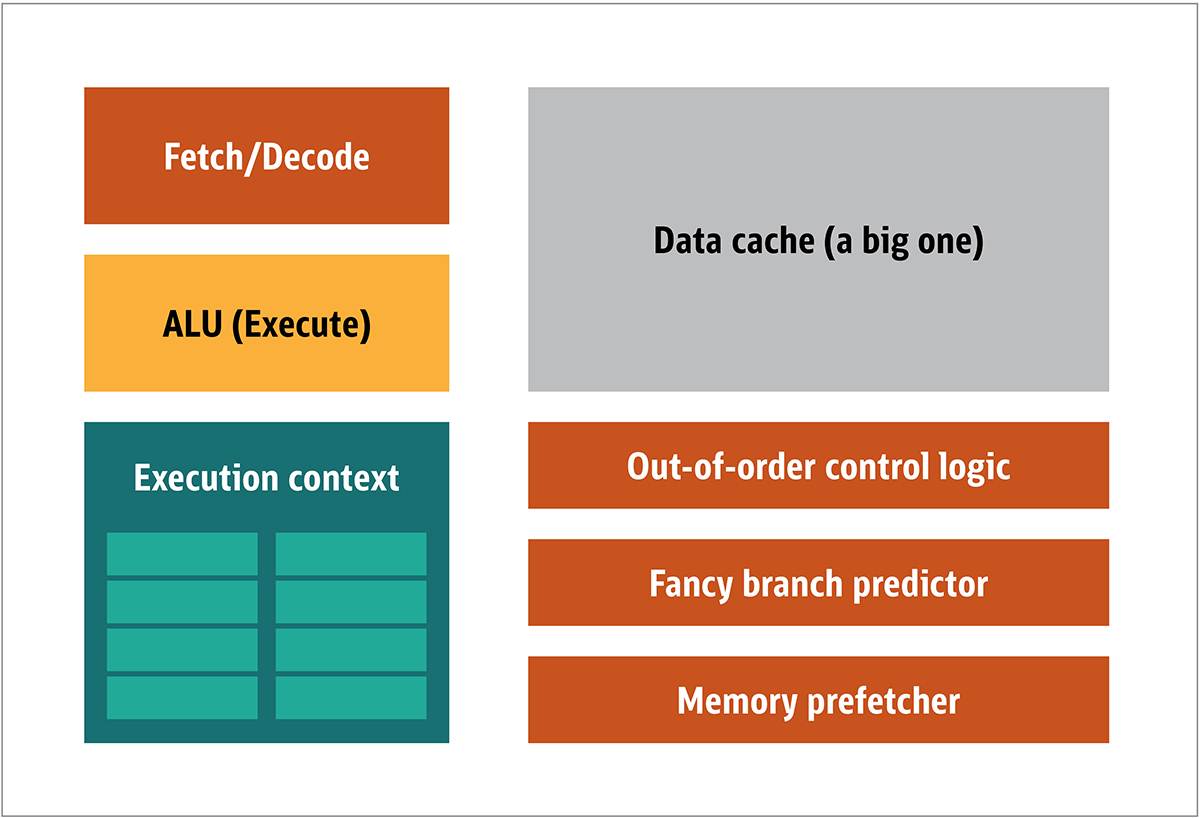 Ara. 1. Blok Arsitektur CPUDalam CPU, elemen pemrosesan aktual - register, unit logika aritmatika (ALU), dan konteks eksekusi - hanyalah sebagian kecil dari keseluruhan sistem. Untuk mempercepat pembayaran tidak beraturan yang datang dalam urutan yang tidak dapat diprediksi, ada cache yang besar, cepat, dan mahal; berbagai jenis kolektor; dan prediktor cabang.Anda tidak memerlukan semua ini pada GPU, karena data diterima dengan cara yang dapat diprediksi, dan GPU melakukan serangkaian operasi yang sangat terbatas pada data. Dengan demikian, dimungkinkan untuk membuatnya sangat kecil dan prosesor yang murah dengan arsitektur blok yang mirip dengan ini ditunjukkan pada Gambar. 2.
Ara. 1. Blok Arsitektur CPUDalam CPU, elemen pemrosesan aktual - register, unit logika aritmatika (ALU), dan konteks eksekusi - hanyalah sebagian kecil dari keseluruhan sistem. Untuk mempercepat pembayaran tidak beraturan yang datang dalam urutan yang tidak dapat diprediksi, ada cache yang besar, cepat, dan mahal; berbagai jenis kolektor; dan prediktor cabang.Anda tidak memerlukan semua ini pada GPU, karena data diterima dengan cara yang dapat diprediksi, dan GPU melakukan serangkaian operasi yang sangat terbatas pada data. Dengan demikian, dimungkinkan untuk membuatnya sangat kecil dan prosesor yang murah dengan arsitektur blok yang mirip dengan ini ditunjukkan pada Gambar. 2.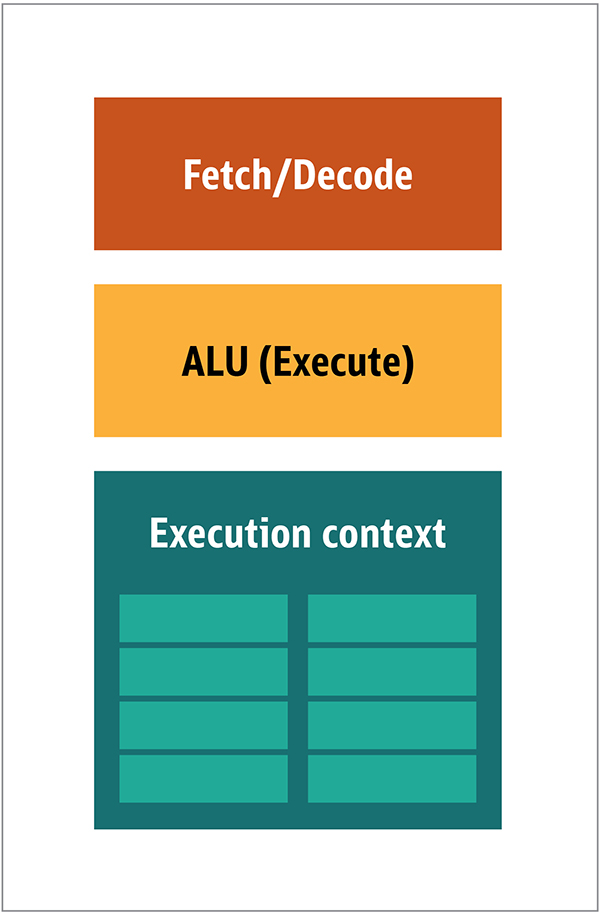 Gambar. 2. Blok arsitektur untuk inti GPU sederhanaKarena prosesor tersebut lebih murah dan data yang diproses di dalamnya dalam potongan paralel, mudah untuk membuat banyak dari mereka bekerja secara paralel. Ini dirancang dengan mengacu pada beberapa instruksi, banyak data atau MIMD (diucapkan "mim-dee").Pendekatan kedua didasarkan pada fakta bahwa seringkali sebuah instruksi tunggal diterapkan pada beberapa bagian data. Ini dikenal sebagai instruksi tunggal, banyak data atau SIMD (diucapkan “sim-dee”). Dalam desain ini, satu GPU berisi beberapa ALU dan konteks eksekusi, area kecil yang ditransfer ke data konteks bersama, seperti yang ditunjukkan pada Gambar 3.
Gambar. 2. Blok arsitektur untuk inti GPU sederhanaKarena prosesor tersebut lebih murah dan data yang diproses di dalamnya dalam potongan paralel, mudah untuk membuat banyak dari mereka bekerja secara paralel. Ini dirancang dengan mengacu pada beberapa instruksi, banyak data atau MIMD (diucapkan "mim-dee").Pendekatan kedua didasarkan pada fakta bahwa seringkali sebuah instruksi tunggal diterapkan pada beberapa bagian data. Ini dikenal sebagai instruksi tunggal, banyak data atau SIMD (diucapkan “sim-dee”). Dalam desain ini, satu GPU berisi beberapa ALU dan konteks eksekusi, area kecil yang ditransfer ke data konteks bersama, seperti yang ditunjukkan pada Gambar 3.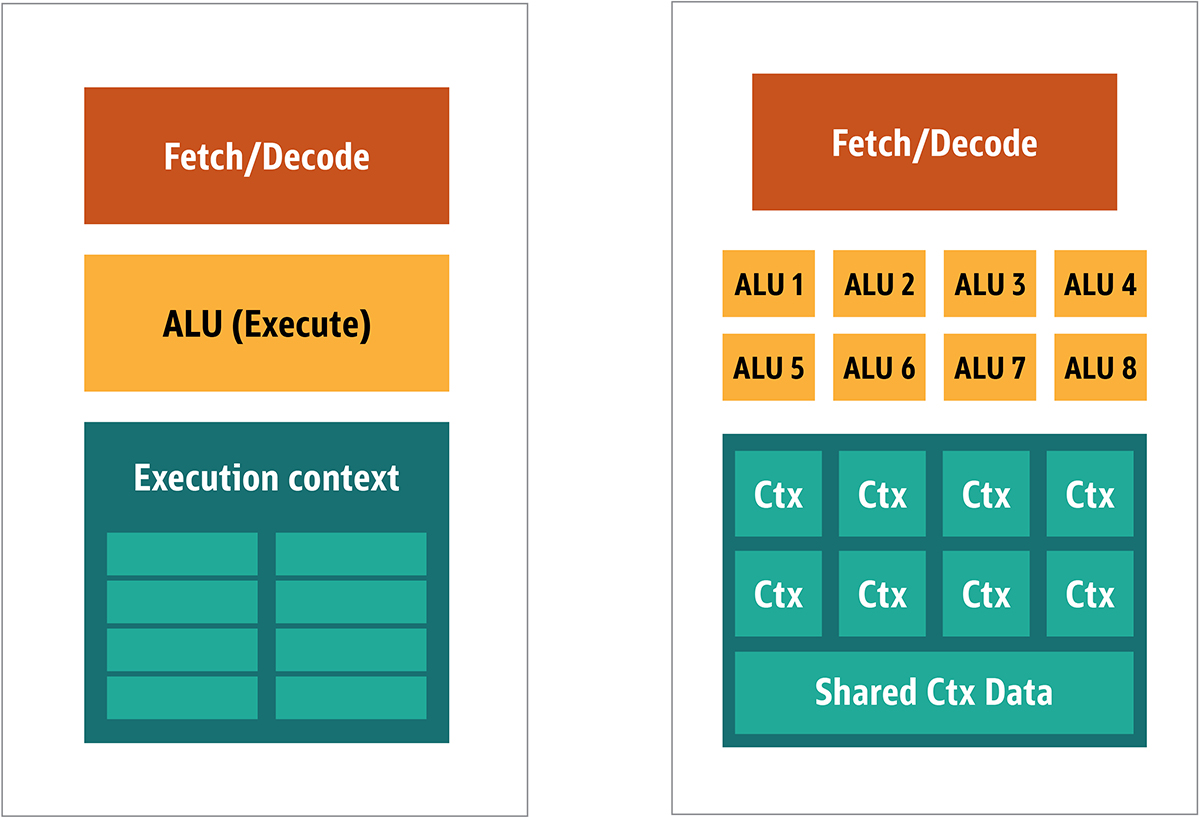 Gambar. 3. Perbandingan arsitektur gaya-MIMD dari blok GPU (dari kiri), dengan desain SIMD (dari kanan)Memadukan pemrosesan SIMD dan MIMD memberikan bandwidth maksimum yang akan saya bypass. Dalam desain ini, Anda memiliki beberapa prosesor SIMD yang berjalan secara paralel, seperti pada Gambar 4.
Gambar. 3. Perbandingan arsitektur gaya-MIMD dari blok GPU (dari kiri), dengan desain SIMD (dari kanan)Memadukan pemrosesan SIMD dan MIMD memberikan bandwidth maksimum yang akan saya bypass. Dalam desain ini, Anda memiliki beberapa prosesor SIMD yang berjalan secara paralel, seperti pada Gambar 4. Gbr. 4. Bekerja beberapa prosesor SIMD secara paralel; ada 16 core dengan 128 ALUKarena Anda memiliki banyak prosesor kecil dan sederhana, Anda dapat memprogramnya untuk mendapatkan efek khusus dalam output.
Gbr. 4. Bekerja beberapa prosesor SIMD secara paralel; ada 16 core dengan 128 ALUKarena Anda memiliki banyak prosesor kecil dan sederhana, Anda dapat memprogramnya untuk mendapatkan efek khusus dalam output.Menjalankan program pada GPU
Sebagian besar efek grafis awal dalam game adalah program kecil yang benar-benar dikodekan yang berjalan pada GPU dan diterapkan pada aliran data dari CPU.Ini jelas, bahkan ketika algoritma hard-code tidak mencukupi, terutama dalam desain game, di mana efek visual adalah salah satu arahan magis utama. Sebagai tanggapan, penjual besar membuka akses ke GPU, dan kemudian pengembang pihak ketiga dapat memprogram mereka.Pendekatan tipikal adalah menulis program kecil yang disebut shader dalam bahasa khusus (biasanya subspesies C) dan mengompilasinya menggunakan kompiler khusus untuk arsitektur yang diinginkan. Istilah shader dipilih karena shader sering digunakan untuk mengontrol efek cahaya dan bayangan, tetapi ini tidak berarti bahwa mereka dapat mengontrol efek khusus lainnya.Setiap vendor GPU memiliki bahasa pemrograman dan infrastruktur sendiri untuk membuat shader untuk arsitektur mereka. Pada pendekatan ini, banyak platform telah dibuat.Yang utama adalah:- DirectCompute: Bahasa Microsoft Shader / API pribadi yang merupakan bagian dari Direct3D, dimulai dengan DirectX 10.
- AMD FireStream: Teknologi ATI / Radeon pribadi yang sudah usang oleh AMD.
- OpenACC: Konsorsium Multi-Vendor, Solusi Komputasi Paralel
- ++ AMP: Microsoft C++
- CUDA: Nvidia,
- OpenL: , Apple, Khronos Group
Sebagian besar waktu, bekerja dengan GPU adalah pemrograman tingkat rendah. Untuk membuat ini sedikit lebih dimengerti bagi pengembang, untuk pengkodean, beberapa abstraksi disediakan. Yang paling terkenal adalah DirectX, dari Microsoft, dan OpenGL, dari Khronos Group. Ini adalah API untuk menulis kode tingkat tinggi, yang kemudian dapat disederhanakan untuk GPU, lebih semantik, untuk programmer.Sejauh yang saya tahu, tidak ada infrastruktur Java untuk DirectX, tetapi ada solusi yang baik untuk OpenGL. JSR 231 dimulai pada tahun 2002 dan ditujukan kepada pemrogram GPU, tetapi ditinggalkan pada tahun 2008 dan hanya mendukung OpenGL 2.0.Dukungan OpenGL berlanjut dalam proyek JOCL independen (yang juga mendukung OpenCL) dan tersedia untuk audiens. Dengan demikian, game Minecraft yang terkenal ditulis menggunakan JOCL.GPGPU datang
Sejauh ini, Java dan GPU tidak memiliki kesamaan, meskipun mereka seharusnya. Java sering digunakan dalam perusahaan, dalam ilmu data, dan di sektor keuangan, di mana ada banyak komputasi dan di mana banyak daya komputasi dibutuhkan. Beginilah ide GPU tujuan umum (GPGPU). Gagasan menggunakan GPU di sepanjang jalur ini dimulai ketika produsen adapter video mulai memberikan akses ke buffer bingkai program, yang memungkinkan pengembang membaca konten. Beberapa peretas telah menentukan bahwa mereka dapat menggunakan kekuatan penuh GPU untuk komputasi universal.Resepnya seperti ini:- Menyandikan data sebagai array raster.
- Tulis shader untuk menanganinya.
- Kirim keduanya ke kartu grafis.
- Dapatkan hasil dari frame buffer
- Decode data dari array raster.
Ini adalah penjelasan yang sangat sederhana. Saya tidak yakin apakah ini akan berhasil dalam produksi, tetapi itu benar-benar berfungsi.Kemudian, banyak penelitian dari Stanford Institute mulai menyederhanakan penggunaan GPU. Pada tahun 2005, mereka membuat BrookGPU, yang merupakan ekosistem kecil yang mencakup bahasa pemrograman, kompiler, dan runtime.BrookGPU mengkompilasi program yang ditulis dalam bahasa pemrograman thread Brook, yang merupakan varian ANSI C. Ini dapat menargetkan OpenGL v1.3 +, DirectX v9 + atau AMD Close to Metal untuk bagian komputasi server, dan dijalankan pada Microsoft Windows dan Linux. Untuk debugging, BrookGPU juga dapat mensimulasikan kartu grafis virtual pada CPU.Namun, ini tidak lepas landas, karena peralatan yang tersedia saat itu. Di dunia GPGPU, Anda perlu menyalin data ke perangkat (dalam konteks ini, perangkat mengacu pada GPU dan perangkat di mana ia berada), tunggu GPU untuk menghitung data, dan kemudian salin kembali data ke program kontrol. Ini menciptakan banyak penundaan. Dan pada pertengahan 2000-an, ketika proyek sedang dalam pengembangan aktif, keterlambatan ini juga mengecualikan penggunaan intensif GPU untuk komputasi dasar.Namun, banyak perusahaan telah melihat masa depan dalam teknologi ini. Beberapa pengembang adapter video mulai memberikan GPGPU dengan teknologi eksklusif mereka, dan aliansi yang dibentuk lainnya menyediakan model pemrograman yang kurang mendasar dan serbaguna yang bekerja pada sejumlah besar perangkat keras.Sekarang saya sudah memberi tahu Anda segalanya, mari kita periksa dua teknologi komputasi GPU paling sukses - OpenCL dan CUDA - lihat juga bagaimana Java bekerja dengannya.OpenCL dan Java
Seperti paket infrastruktur lainnya, OpenCL menyediakan implementasi dasar dalam C. Ini secara teknis tersedia menggunakan Java Native Interface (JNI) atau Java Native Access (JNA), tetapi pendekatan ini akan terlalu sulit bagi kebanyakan pengembang.Untungnya, pekerjaan ini sudah dilakukan oleh beberapa perpustakaan: JOCL, JogAmp, dan JavaCL. Sayangnya, JavaCL telah menjadi proyek mati. Tetapi proyek JOCL masih hidup dan sangat disesuaikan. Saya akan menggunakannya untuk contoh-contoh berikut.Tetapi pertama-tama saya harus menjelaskan apa itu OpenCL. Saya sebutkan sebelumnya bahwa OpenCL menyediakan model yang sangat mendasar yang cocok untuk pemrograman semua jenis perangkat - tidak hanya GPU dan CPU, tetapi bahkan prosesor dan FPGA DSP.Mari kita lihat contoh paling sederhana: melipat vektor mungkin adalah contoh paling terang dan paling sederhana. Anda memiliki dua array angka untuk tambahan dan satu untuk hasilnya. Anda mengambil elemen dari array pertama dan elemen dari array kedua, dan kemudian Anda memasukkan jumlah ke dalam array hasil, seperti yang ditunjukkan pada Gambar. 5.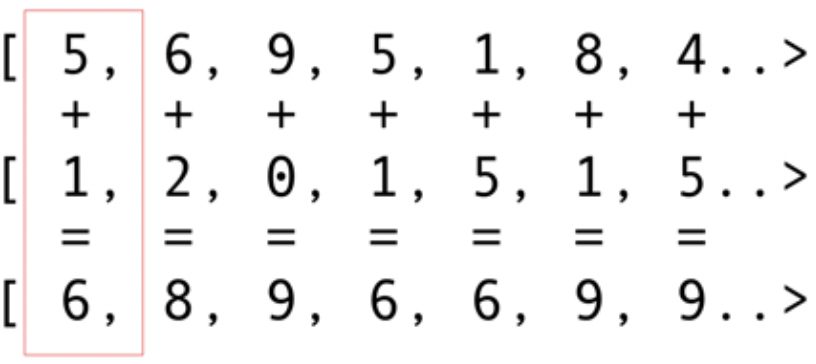 Gambar. 5. Menambahkan elemen dua array dan menyimpan jumlah dalam array yang dihasilkanSeperti yang Anda lihat, operasi ini sangat konsisten dan tetap didistribusikan. Anda dapat mendorong setiap operasi penambahan ke GPU inti yang berbeda. Ini berarti bahwa jika Anda memiliki 2048 core, seperti pada Nvidia 1080, Anda dapat melakukan operasi penambahan 2048 secara bersamaan. Ini berarti bahwa di sini potensi teraflops daya komputer sedang menunggu untuk Anda. Kode untuk larik 10 juta angka ini diambil dari situs web JOCL:
Gambar. 5. Menambahkan elemen dua array dan menyimpan jumlah dalam array yang dihasilkanSeperti yang Anda lihat, operasi ini sangat konsisten dan tetap didistribusikan. Anda dapat mendorong setiap operasi penambahan ke GPU inti yang berbeda. Ini berarti bahwa jika Anda memiliki 2048 core, seperti pada Nvidia 1080, Anda dapat melakukan operasi penambahan 2048 secara bersamaan. Ini berarti bahwa di sini potensi teraflops daya komputer sedang menunggu untuk Anda. Kode untuk larik 10 juta angka ini diambil dari situs web JOCL:public class ArrayGPU {
private static String programSource =
"__kernel void "+
"sampleKernel(__global const float *a,"+
" __global const float *b,"+
" __global float *c)"+
"{"+
" int gid = get_global_id(0);"+
" c[gid] = a[gid] + b[gid];"+
"}";
public static void main(String args[])
{
int n = 10_000_000;
float srcArrayA[] = new float[n];
float srcArrayB[] = new float[n];
float dstArray[] = new float[n];
for (int i=0; i<n; i++)
{
srcArrayA[i] = i;
srcArrayB[i] = i;
}
Pointer srcA = Pointer.to(srcArrayA);
Pointer srcB = Pointer.to(srcArrayB);
Pointer dst = Pointer.to(dstArray);
final int platformIndex = 0;
final long deviceType = CL.CL_DEVICE_TYPE_ALL;
final int deviceIndex = 0;
CL.setExceptionsEnabled(true);
int numPlatformsArray[] = new int[1];
CL.clGetPlatformIDs(0, null, numPlatformsArray);
int numPlatforms = numPlatformsArray[0];
cl_platform_id platforms[] = new cl_platform_id[numPlatforms];
CL.clGetPlatformIDs(platforms.length, platforms, null);
cl_platform_id platform = platforms[platformIndex];
cl_context_properties contextProperties = new cl_context_properties();
contextProperties.addProperty(CL.CL_CONTEXT_PLATFORM, platform);
int numDevicesArray[] = new int[1];
CL.clGetDeviceIDs(platform, deviceType, 0, null, numDevicesArray);
int numDevices = numDevicesArray[0];
cl_device_id devices[] = new cl_device_id[numDevices];
CL.clGetDeviceIDs(platform, deviceType, numDevices, devices, null);
cl_device_id device = devices[deviceIndex];
cl_context context = CL.clCreateContext(
contextProperties, 1, new cl_device_id[]{device},
null, null, null);
cl_command_queue commandQueue =
CL.clCreateCommandQueue(context, device, 0, null);
cl_mem memObjects[] = new cl_mem[3];
memObjects[0] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcA, null);
memObjects[1] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcB, null);
memObjects[2] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_WRITE,
Sizeof.cl_float * n, null, null);
cl_program program = CL.clCreateProgramWithSource(context,
1, new String[]{ programSource }, null, null);
CL.clBuildProgram(program, 0, null, null, null, null);
cl_kernel kernel = CL.clCreateKernel(program, "sampleKernel", null);
CL.clSetKernelArg(kernel, 0,
Sizeof.cl_mem, Pointer.to(memObjects[0]));
CL.clSetKernelArg(kernel, 1,
Sizeof.cl_mem, Pointer.to(memObjects[1]));
CL.clSetKernelArg(kernel, 2,
Sizeof.cl_mem, Pointer.to(memObjects[2]));
long global_work_size[] = new long[]{n};
long local_work_size[] = new long[]{1};
CL.clEnqueueNDRangeKernel(commandQueue, kernel, 1, null,
global_work_size, local_work_size, 0, null, null);
CL.clEnqueueReadBuffer(commandQueue, memObjects[2], CL.CL_TRUE, 0,
n * Sizeof.cl_float, dst, 0, null, null);
CL.clReleaseMemObject(memObjects[0]);
CL.clReleaseMemObject(memObjects[1]);
CL.clReleaseMemObject(memObjects[2]);
CL.clReleaseKernel(kernel);
CL.clReleaseProgram(program);
CL.clReleaseCommandQueue(commandQueue);
CL.clReleaseContext(context);
}
private static String getString(cl_device_id device, int paramName) {
long size[] = new long[1];
CL.clGetDeviceInfo(device, paramName, 0, null, size);
byte buffer[] = new byte[(int)size[0]];
CL.clGetDeviceInfo(device, paramName, buffer.length, Pointer.to(buffer), null);
return new String(buffer, 0, buffer.length-1);
}
}
Kode ini tidak seperti kode Java, tetapi kode itu. Saya akan menjelaskan kode lebih lanjut; jangan menghabiskan banyak waktu sekarang, karena saya akan membahas secara singkat solusi yang kompleks.Kode akan didokumentasikan, tetapi mari kita lakukan sedikit langkah-langkah. Seperti yang Anda lihat, kode ini sangat mirip dengan kode dalam C. Ini normal karena JOCL hanyalah OpenCL. Pada awalnya, ini adalah beberapa kode di baris, dan kode ini adalah bagian yang paling penting: Dikompilasi menggunakan OpenCL dan kemudian dikirim ke kartu video, di mana kode tersebut dieksekusi. Kode ini disebut Kernel. Jangan bingung istilah ini dengan OC Kernel; Ini adalah kode perangkat. Kode ini ditulis dalam subset C.Setelah kernel datang kode Java untuk menginstal dan mengkonfigurasi perangkat, membagi data, dan membuat buffer memori yang sesuai untuk data yang dihasilkan.Untuk meringkas: di sini adalah "kode host", yang biasanya merupakan bahasa yang mengikat (dalam kasus kami, di Jawa), dan "kode perangkat". Anda selalu menyorot apa yang akan berfungsi pada host dan apa yang harus bekerja pada perangkat, karena host mengontrol perangkat.Kode sebelumnya harus menunjukkan GPU yang setara dengan "Hello World!" Seperti yang Anda lihat, sebagian besar sangat besar.Jangan lupa tentang fitur SIMD. Jika perangkat Anda mendukung ekstensi SIMD, Anda dapat membuat kode aritmatika lebih cepat. Sebagai contoh, mari kita lihat kode perkalian matriks kernel. Kode ini dalam garis Jawa sederhana dalam aplikasi.__kernel void MatrixMul_kernel_basic(int dim,
__global float *A,
__global float *B,
__global float *C){
int iCol = get_global_id(0);
int iRow = get_global_id(1);
float result = 0.0;
for(int i=0; i< dim; ++i)
{
result +=
A[iRow*dim + i]*B[i*dim + iCol];
}
C[iRow*dim + iCol] = result;
}
Secara teknis, kode ini akan bekerja pada potongan data yang diinstal untuk Anda oleh kerangka kerja OpenCL, dengan instruksi yang Anda panggil di bagian persiapan.Jika kartu video Anda mendukung instruksi SIMD dan dapat memproses vektor empat angka floating-point, optimisasi kecil dapat mengubah kode sebelumnya menjadi yang berikut:#define VECTOR_SIZE 4
__kernel void MatrixMul_kernel_basic_vector4(
size_t dim,
const float4 *A,
const float4 *B,
float4 *C)
{
size_t globalIdx = get_global_id(0);
size_t globalIdy = get_global_id(1);
float4 resultVec = (float4){ 0, 0, 0, 0 };
size_t dimVec = dim / 4;
for(size_t i = 0; i < dimVec; ++i) {
float4 Avector = A[dimVec * globalIdy + i];
float4 Bvector[4];
Bvector[0] = B[dimVec * (i * 4 + 0) + globalIdx];
Bvector[1] = B[dimVec * (i * 4 + 1) + globalIdx];
Bvector[2] = B[dimVec * (i * 4 + 2) + globalIdx];
Bvector[3] = B[dimVec * (i * 4 + 3) + globalIdx];
resultVec += Avector[0] * Bvector[0];
resultVec += Avector[1] * Bvector[1];
resultVec += Avector[2] * Bvector[2];
resultVec += Avector[3] * Bvector[3];
}
C[dimVec * globalIdy + globalIdx] = resultVec;
}
Dengan kode ini Anda dapat menggandakan kinerja.Keren. Anda baru saja membuka GPU untuk dunia Java! Tetapi sebagai pengembang Java, apakah Anda benar-benar ingin melakukan semua pekerjaan kotor ini, dengan kode C, dan bekerja dengan detail tingkat rendah seperti itu? Saya tidak mau. Tetapi sekarang setelah Anda memiliki pengetahuan tentang bagaimana GPU digunakan, mari kita lihat solusi lain yang berbeda dari kode JOCL yang baru saja saya sajikan.CUDA dan Java
CUDA adalah solusi Nvidia untuk masalah pemrograman ini. CUDA menyediakan lebih banyak perpustakaan yang siap digunakan untuk operasi GPU standar, seperti matriks, histogram, dan bahkan jaringan saraf yang dalam. Daftar perpustakaan telah muncul dengan banyak solusi yang sudah jadi. Ini semua dari proyek JCuda:- JCublas: segalanya untuk matriks
- JCufft: Fast Fourier Transform
- JCurand: Semuanya untuk Angka Acak
- JCusparse: matriks langka
- JCusolver: faktorisasi angka
- JNvgraph: semuanya untuk grafik
- JCudpp: Perpustakaan CUDA data paralel primitif dan beberapa algoritma penyortiran
- JNpp: Pemrosesan gambar GPU
- JCudnn: perpustakaan jaringan saraf yang mendalam
Saya sedang mempertimbangkan menggunakan JCurand, yang menghasilkan angka acak. Anda dapat menggunakan ini dari kode Java tanpa bahasa Kernel khusus lainnya. Sebagai contoh:...
int n = 100;
curandGenerator generator = new curandGenerator();
float hostData[] = new float[n];
Pointer deviceData = new Pointer();
cudaMalloc(deviceData, n * Sizeof.FLOAT);
curandCreateGenerator(generator, CURAND_RNG_PSEUDO_DEFAULT);
curandSetPseudoRandomGeneratorSeed(generator, 1234);
curandGenerateUniform(generator, deviceData, n);
cudaMemcpy(Pointer.to(hostData), deviceData,
n * Sizeof.FLOAT, cudaMemcpyDeviceToHost);
System.out.println(Arrays.toString(hostData));
curandDestroyGenerator(generator);
cudaFree(deviceData);
...
Ini menggunakan GPU untuk membuat sejumlah besar angka acak berkualitas sangat tinggi, berdasarkan matematika yang sangat kuat.Di JCuda, Anda juga dapat menulis kode CUDA umum dan memanggilnya dari Jawa dengan memanggil beberapa file JAR di classpath Anda. Lihat dokumentasi JCuda untuk contoh yang bagus.Tetap di atas kode level rendah
Semuanya tampak hebat, tetapi ada terlalu banyak kode, terlalu banyak instalasi, terlalu banyak bahasa yang berbeda untuk menjalankan semuanya. Apakah ada cara untuk menggunakan GPU setidaknya sebagian?Bagaimana jika Anda tidak ingin memikirkan semua OpenCL, CUDA, dan hal-hal lain yang tidak perlu ini? Bagaimana jika Anda hanya ingin memprogram di Jawa dan tidak memikirkan segala sesuatu yang tidak jelas? Proyek Aparapi dapat membantu. Aparapi didasarkan pada "API paralel." Saya menganggapnya sebagai bagian dari Hibernate untuk pemrograman GPU yang menggunakan OpenCL di bawah tenda. Mari kita lihat contoh penambahan vektor.public static void main(String[] _args) {
final int size = 512;
final float[] a = new float[size];
final float[] b = new float[size];
for (int i = 0; i < size; i++){
a[i] = (float) (Math.random() * 100);
b[i] = (float) (Math.random() * 100);
}
final float[] sum = new float[size];
Kernel kernel = new Kernel(){
@Override public void run() {
I int gid = getGlobalId();
sum[gid] = a[gid] + b[gid];
}
};
kernel.execute(Range.create(size));
for(int i = 0; i < size; i++) {
System.out.printf("%6.2f + %6.2f = %8.2f\n", a[i], b[i], sum[i])
}
kernel.dispose();
}
Berikut ini adalah kode Java murni (diambil dari dokumentasi Aparapi), juga di sana-sini, Anda dapat melihat istilah Kernel tertentu dan getGlobalId. Anda masih perlu memahami cara memprogram GPU, tetapi Anda dapat menggunakan pendekatan GPGPU dengan cara yang lebih mirip Java. Selain itu, Aparapi menyediakan cara mudah untuk menggunakan konteks OpenGL ke lapisan OpenCL - sehingga memungkinkan data untuk sepenuhnya tetap pada kartu grafis - dan dengan demikian menghindari masalah latensi memori.Jika Anda perlu melakukan banyak perhitungan independen, lihat Aparapi. Ada banyak contoh cara menggunakan komputasi paralel.Selain itu, ada beberapa proyek yang disebut TornadoVM - secara otomatis mentransfer perhitungan yang sesuai dari CPU ke GPU, sehingga memberikan optimasi massal di luar kotak.temuan
Ada banyak aplikasi di mana GPU dapat membawa beberapa keuntungan, tetapi bisa dibilang masih ada beberapa kendala. Namun, Java dan GPU dapat melakukan hal-hal besar bersama. Dalam artikel ini, saya hanya menyentuh topik yang luas ini. Saya bermaksud menunjukkan berbagai opsi level tinggi dan rendah untuk mengakses GPU dari Java. Menjelajahi area ini akan memberikan manfaat kinerja yang luar biasa, terutama untuk tugas-tugas kompleks yang membutuhkan banyak perhitungan yang dapat dilakukan secara paralel.Tautan Sumber