Saya akan segera menjelaskan judul artikel tersebut. Awalnya, ini direncanakan untuk memberikan saran yang baik dan dapat diandalkan tentang mempercepat penggunaan refleksi menggunakan contoh sederhana namun realistis, tetapi selama benchmarking ternyata refleksi tidak bekerja selambat yang saya pikir, LINQ bekerja lebih lambat daripada yang diimpikan dalam mimpi buruk. Tetapi pada akhirnya ternyata saya juga membuat kesalahan dalam pengukuran ... Detail kisah hidup ini di bawah potongan dan di komentar. Karena contohnya cukup sehari-hari dan pada prinsipnya diterapkan, seperti yang biasanya dilakukan di perusahaan, ternyata cukup menarik, seperti yang terlihat bagi saya, sebuah demonstrasi kehidupan: tidak ada efek nyata pada kecepatan subjek utama artikel karena logika eksternal: Moq, Autofac, EF Core, dll. "Tegap".Saya memulai pekerjaan saya di bawah kesan artikel ini: Mengapa Refleksi lambatSeperti yang Anda lihat, penulis menyarankan untuk menggunakan delegasi yang dikompilasi alih-alih secara langsung menggunakan metode tipe refleksi sebagai cara yang bagus untuk mempercepat aplikasi. Tentu saja ada emisi IL, tetapi saya ingin menghindarinya, karena ini adalah cara yang paling padat karya untuk menyelesaikan tugas, yang penuh dengan kesalahan.Mempertimbangkan bahwa saya selalu berpegang pada pendapat yang sama tentang kecepatan refleksi, saya tidak bermaksud untuk memberikan keraguan khusus pada kesimpulan penulis.Saya sering menemukan penggunaan refleksi yang naif dalam suatu perusahaan. Jenis diambil. Informasi properti diambil. Metode SetValue dipanggil, dan semua orang senang. Nilai terbang ke bidang target, semua orang senang. Orang-orang yang sangat pandai - sinior dan pemimpin tim - menulis ekstensi mereka pada objek, berdasarkan pada implementasi yang naif dari pemetaan "universal" dari satu jenis ke jenis lainnya. Inti dari ini biasanya: kita mengambil semua bidang, kita mengambil semua properti, beralih di atasnya: jika nama-nama anggota bertepatan, kita mengeksekusi SetValue. Kami secara berkala menangkap pengecualian pada kesalahan ketika salah satu tipe tidak menemukan properti, tetapi ada juga jalan keluar yang mencapai kinerja. Coba tangkap.Saya melihat orang-orang menciptakan parser dan pemetaan tanpa dipersenjatai sepenuhnya dengan informasi tentang bagaimana sepeda diciptakan sebelum mereka bekerja. Saya melihat orang menyembunyikan implementasi naif mereka di belakang strategi, di belakang antarmuka, di belakang suntikan, seolah-olah ini akan menjadi alasan bacchanalia berikutnya. Dari implementasi seperti itu aku menoleh. Bahkan, saya tidak mengukur kebocoran kinerja nyata, dan jika mungkin, saya hanya mengubah implementasinya menjadi lebih "optimal", jika tangan saya mencapai. Karena pengukuran pertama, yang dibahas di bawah ini, saya benar-benar malu.Saya pikir banyak dari Anda, ketika membaca Richter atau ideolog lain, telah datang dengan pernyataan yang cukup adil bahwa refleksi dalam kode adalah fenomena yang memiliki efek yang sangat negatif pada kinerja aplikasi.Panggilan refleksi memaksa CLR untuk pergi berkeliling majelis untuk mencari yang tepat, menarik metadata-nya, menguraikannya, dll. Selain itu, refleksi selama urutan traversal mengarah ke alokasi sejumlah besar memori. Kami menghabiskan memori, CLR mengungkap HZ dan membeku berpacu. Seharusnya terasa lambat, percayalah. Sejumlah besar memori server produksi modern atau mesin cloud tidak menghemat dari penundaan pemrosesan yang tinggi. Bahkan, semakin banyak memori, semakin tinggi kemungkinan Anda AKAN PEMBERITAHUAN tentang cara kerja HZ. Refleksi, secara teori, kain merah ekstra untuknya.Namun demikian, kita semua menggunakan wadah IoC dan pembuat tanggal, yang prinsipnya juga didasarkan pada refleksi, namun, pertanyaan tentang kinerja mereka biasanya tidak muncul. Tidak, bukan karena pengenalan dependensi dan abstrak dari model konteks terbatas eksternal adalah hal yang sangat penting sehingga kita harus mengorbankan kinerja dalam hal apa pun. Semuanya lebih sederhana - itu benar-benar tidak mempengaruhi kinerja.Faktanya adalah bahwa kerangka kerja paling umum yang didasarkan pada teknologi refleksi menggunakan semua jenis trik untuk bekerja dengannya secara lebih optimal. Ini biasanya sebuah cache. Biasanya ini adalah Ekspresi dan delegasi yang dikompilasi dari pohon ekspresi. Auto-mapper yang sama memegang kamus kompetitif, mencocokkan jenis dengan fungsi yang dapat mereka konversi satu sama lain tanpa memanggil refleksi.Bagaimana ini dicapai? Sebenarnya, ini tidak berbeda dengan logika yang digunakan platform itu sendiri untuk menghasilkan kode JIT. Ketika Anda pertama kali memanggil suatu metode, itu mengkompilasi (dan, ya, proses ini tidak cepat), dengan panggilan berikutnya, kontrol ditransfer ke metode yang sudah dikompilasi, dan tidak akan ada penurunan kinerja khusus.Dalam kasus kami, Anda juga dapat menggunakan kompilasi JIT dan kemudian menggunakan perilaku yang dikompilasi dengan kinerja yang sama dengan rekan-rekan AOT-nya. Dalam hal ini, ekspresi akan membantu kami.Secara singkat, kita dapat merumuskan prinsip tersebut sebagai berikut: Hasilakhir dari refleksi harus di-cache dalam bentuk delegasi yang berisi fungsi yang dikompilasi. Masuk akal juga untuk men-cache semua objek yang diperlukan dengan informasi tentang tipe di bidang tipe Anda yang disimpan di luar objek - pekerja.Ada logika dalam hal ini. Akal sehat memberi tahu kita bahwa jika sesuatu dapat dikompilasi dan di-cache, maka ini harus dilakukan.Ke depan, harus dikatakan bahwa cache dalam bekerja dengan refleksi memiliki kelebihan, bahkan jika Anda tidak menggunakan metode yang diusulkan untuk mengkompilasi ekspresi. Sebenarnya, di sini saya hanya mengulangi tesis dari penulis artikel yang saya rujuk di atas.Sekarang tentang kodenya. Mari kita lihat contoh yang didasarkan pada rasa sakit saya baru-baru ini yang harus saya hadapi dalam produksi serius sebuah organisasi kredit yang serius. Semua entitas fiktif sehingga tidak ada yang akan menebak.Ada entitas tertentu. Biarkan itu Kontak. Ada surat-surat dengan badan standar, dari mana parser dan hydrator membuat kontak yang sama. Sebuah surat tiba, kami membacanya, membongkar pasangan nilai kunci, membuat kontak, menyimpannya dalam database.Ini dasar. Misalkan kontak memiliki nama, umur, dan nomor kontak dari properti. Data-data ini dikirimkan dalam bentuk surat. Selain itu, bisnis menginginkan dukungan agar dapat dengan cepat menambahkan kunci baru untuk memetakan properti entitas untuk berpasangan di badan surat. Jika seseorang mencetak dalam templat atau jika sebelum rilis akan diperlukan untuk segera memulai pemetaan dari mitra baru, menyesuaikan dengan format baru. Kemudian kita bisa menambahkan korelasi pemetaan baru sebagai perbaikan data murah. Yaitu, contoh hidup.Kami menerapkan, membuat tes. BekerjaSaya tidak akan memberikan kode: ada banyak sumber, dan mereka tersedia di GitHub melalui tautan di akhir artikel. Anda dapat mengunduhnya, menyiksa mereka hingga tidak dapat dikenali dan mengukurnya, karena akan memengaruhi kasus Anda. Saya hanya akan memberikan kode dua metode templat yang membedakan hydrator, yang seharusnya cepat dari hydrator, yang seharusnya lambat.Logikanya adalah sebagai berikut: metode templat menerima pasangan yang dibentuk oleh logika parser dasar. Level LINQ adalah parser dan logika dasar dari hydrator, membuat permintaan ke konteks db dan mencocokkan kunci dengan pasangan dari parser (untuk fungsi-fungsi ini, ada kode tanpa LINQ untuk perbandingan). Selanjutnya, pasangan ditransfer ke metode hidrasi utama dan nilai pasangan diatur ke properti entitas yang sesuai."Cepat" (Awalan cepat dalam tolok ukur): protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var setterMapItem in _proprtySettersMap)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == setterMapItem.Key);
setterMapItem.Value(contact, correlation?.Value);
}
return contact;
}
Seperti yang dapat kita lihat, koleksi statis dengan setter properti digunakan - lambda yang dikompilasi yang memanggil entitas setter. Dihasilkan oleh kode berikut: static FastContactHydrator()
{
var type = typeof(Contact);
foreach (var property in type.GetProperties())
{
_proprtySettersMap[property.Name] = GetSetterAction(property);
}
}
private static Action<Contact, string> GetSetterAction(PropertyInfo property)
{
var setterInfo = property.GetSetMethod();
var paramValueOriginal = Expression.Parameter(property.PropertyType, "value");
var paramEntity = Expression.Parameter(typeof(Contact), "entity");
var setterExp = Expression.Call(paramEntity, setterInfo, paramValueOriginal).Reduce();
var lambda = (Expression<Action<Contact, string>>)Expression.Lambda(setterExp, paramEntity, paramValueOriginal);
return lambda.Compile();
}
Secara umum, jelas. Kami berkeliling properti, membuat delegasi untuk mereka yang memanggil setter, dan menyimpannya. Maka kami akan menelepon jika perlu."Lambat" (Awalan lambat dalam tolok ukur): protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var property in _properties)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == property.Name);
if (correlation?.Value == null)
continue;
property.SetValue(contact, correlation.Value);
}
return contact;
}
Di sini kita segera berkeliling properti dan memanggil SetValue secara langsung.Untuk kejelasan dan sebagai referensi, saya menerapkan metode naif yang menulis nilai pasangan korelasinya langsung ke bidang entitas. Awalannya adalah Manual.Sekarang kami menggunakan BenchmarkDotNet dan kami mempelajari produktivitas. Dan tiba-tiba ... (spoiler bukan hasil yang tepat, detailnya di bawah)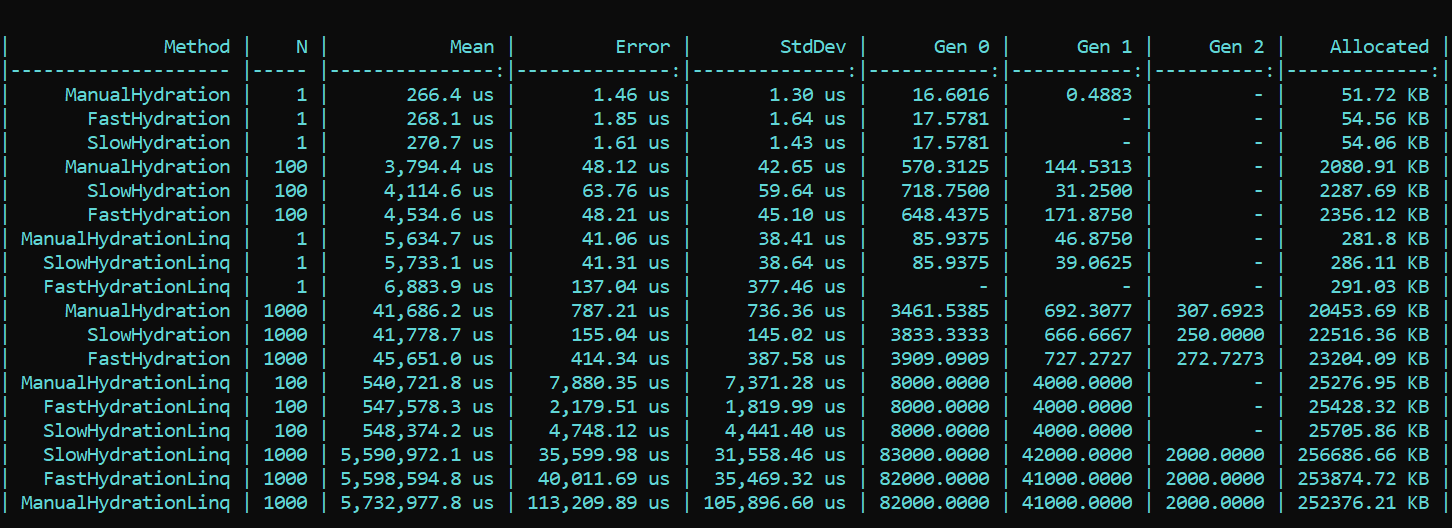 Apa yang kita lihat di sini? Metode yang menggunakan awalan Fast ternyata lebih lambat di hampir semua lintasan daripada metode dengan awalan Lambat. Ini berlaku untuk alokasi, dan untuk kecepatan. Di sisi lain, implementasi pemetaan yang cantik dan elegan menggunakan metode LINQ yang dirancang untuk tujuan ini, sebaliknya, sangat menguras kinerja. Perbedaan pesanan. Tren tidak berubah dengan jumlah lintasan yang berbeda. Perbedaannya hanya dalam skala. Dengan LINQ 4 hingga 200 kali lebih lambat, ada lebih banyak puing pada skala yang sama.DIPERBARUISaya tidak bisa mempercayai mata saya, tetapi yang lebih penting, baik mata saya maupun kode saya tidak dipercaya oleh rekan kami - Dmitry Tikhonov 0x1000000. Setelah memeriksa ulang solusi saya, ia dengan cemerlang menemukan dan menunjukkan kesalahan yang saya lewatkan karena sejumlah perubahan dalam implementasi. Setelah memperbaiki bug yang ditemukan di pengaturan Moq, semua hasil jatuh ke tempatnya. Menurut hasil pengujian ulang, tren utama tidak berubah - LINQ mempengaruhi kinerja masih lebih kuat daripada refleksi. Namun, senang bekerja dengan mengkompilasi Ekspresi tidak sia-sia, dan hasilnya terlihat dalam alokasi dan runtime. Jalankan pertama, ketika bidang statis diinisialisasi, secara alami lebih lambat dalam metode "cepat", tetapi situasi berubah lebih jauh.Ini adalah hasil dari tes ulang:
Apa yang kita lihat di sini? Metode yang menggunakan awalan Fast ternyata lebih lambat di hampir semua lintasan daripada metode dengan awalan Lambat. Ini berlaku untuk alokasi, dan untuk kecepatan. Di sisi lain, implementasi pemetaan yang cantik dan elegan menggunakan metode LINQ yang dirancang untuk tujuan ini, sebaliknya, sangat menguras kinerja. Perbedaan pesanan. Tren tidak berubah dengan jumlah lintasan yang berbeda. Perbedaannya hanya dalam skala. Dengan LINQ 4 hingga 200 kali lebih lambat, ada lebih banyak puing pada skala yang sama.DIPERBARUISaya tidak bisa mempercayai mata saya, tetapi yang lebih penting, baik mata saya maupun kode saya tidak dipercaya oleh rekan kami - Dmitry Tikhonov 0x1000000. Setelah memeriksa ulang solusi saya, ia dengan cemerlang menemukan dan menunjukkan kesalahan yang saya lewatkan karena sejumlah perubahan dalam implementasi. Setelah memperbaiki bug yang ditemukan di pengaturan Moq, semua hasil jatuh ke tempatnya. Menurut hasil pengujian ulang, tren utama tidak berubah - LINQ mempengaruhi kinerja masih lebih kuat daripada refleksi. Namun, senang bekerja dengan mengkompilasi Ekspresi tidak sia-sia, dan hasilnya terlihat dalam alokasi dan runtime. Jalankan pertama, ketika bidang statis diinisialisasi, secara alami lebih lambat dalam metode "cepat", tetapi situasi berubah lebih jauh.Ini adalah hasil dari tes ulang: Kesimpulan: ketika menggunakan refleksi di suatu perusahaan, beralih ke trik tidak terlalu diperlukan - LINQ akan melahap kinerja lebih kuat. Namun demikian, dalam metode yang sangat banyak yang memerlukan optimasi, seseorang dapat mempertahankan refleksi dalam bentuk inisialisasi dan kompiler delegasi, yang kemudian akan memberikan logika "cepat". Jadi Anda bisa menjaga fleksibilitas refleksi, dan kecepatan aplikasi.Kode dengan tolok ukur tersedia di sini. Setiap orang dapat memeriksa ulang kata-kata saya:HabraReflectionTestsPS: kode menggunakan IoC dalam pengujian, dan desain eksplisit di tolok ukur. Faktanya adalah bahwa dalam implementasi akhir, saya mengelompokkan semua faktor yang dapat mempengaruhi kinerja dan membuat kebisingan.PPS: Terima kasih kepada Dmitry Tikhonov @ 0x1000000untuk mendeteksi kesalahan saya dalam pengaturan Moq, yang memengaruhi pengukuran pertama. Jika ada pembaca yang memiliki karma yang cukup, silakan saja. Pria itu berhenti, pria itu membaca, pria itu memeriksa ulang dan menunjukkan kesalahan. Saya pikir ini layak untuk dihormati dan simpati.PPPS: terima kasih kepada pembaca yang teliti itu yang berhasil mencapai dasar gaya dan desain. Saya menginginkan keseragaman dan kenyamanan. Diplomasi presentasi meninggalkan banyak yang harus diinginkan, tetapi saya memperhitungkan kritik. Saya meminta shell.
Kesimpulan: ketika menggunakan refleksi di suatu perusahaan, beralih ke trik tidak terlalu diperlukan - LINQ akan melahap kinerja lebih kuat. Namun demikian, dalam metode yang sangat banyak yang memerlukan optimasi, seseorang dapat mempertahankan refleksi dalam bentuk inisialisasi dan kompiler delegasi, yang kemudian akan memberikan logika "cepat". Jadi Anda bisa menjaga fleksibilitas refleksi, dan kecepatan aplikasi.Kode dengan tolok ukur tersedia di sini. Setiap orang dapat memeriksa ulang kata-kata saya:HabraReflectionTestsPS: kode menggunakan IoC dalam pengujian, dan desain eksplisit di tolok ukur. Faktanya adalah bahwa dalam implementasi akhir, saya mengelompokkan semua faktor yang dapat mempengaruhi kinerja dan membuat kebisingan.PPS: Terima kasih kepada Dmitry Tikhonov @ 0x1000000untuk mendeteksi kesalahan saya dalam pengaturan Moq, yang memengaruhi pengukuran pertama. Jika ada pembaca yang memiliki karma yang cukup, silakan saja. Pria itu berhenti, pria itu membaca, pria itu memeriksa ulang dan menunjukkan kesalahan. Saya pikir ini layak untuk dihormati dan simpati.PPPS: terima kasih kepada pembaca yang teliti itu yang berhasil mencapai dasar gaya dan desain. Saya menginginkan keseragaman dan kenyamanan. Diplomasi presentasi meninggalkan banyak yang harus diinginkan, tetapi saya memperhitungkan kritik. Saya meminta shell.