Hai, nama saya Alexander Vasin, saya pengembang backend di Edadil. Gagasan materi ini dimulai dengan fakta bahwa saya ingin mengurai tugas pengantar ( Ya.Disk ) ke dalam Sekolah Pengembangan Backend Yandex. Saya mulai menggambarkan semua seluk-beluk pilihan teknologi tertentu, metodologi pengujian ... Ternyata tidak ada analisis sama sekali, tetapi panduan yang sangat rinci tentang cara menulis backend dengan Python. Dari ide aslinya, hanya persyaratan layanan yang tersisa, misalnya, yang nyaman untuk membongkar alat dan teknologi. Akibatnya, saya terbangun dengan seratus ribu karakter. Sangat banyak yang diperlukan untuk mempertimbangkan semuanya dengan sangat terperinci. Jadi, program untuk 100 kilobyte berikutnya: bagaimana membangun backend layanan, dari pilihan alat hingga penyebaran. TL; DR: Ini adalah perwakilan GitHub dengan aplikasi, dan yang menyukai longread (nyata) - tolong, di bawah kucing.Kami akan mengembangkan dan menguji layanan REST API dengan Python, mengemasnya dalam wadah Docker yang ringan dan menggunakannya menggunakan Ansible.
TL; DR: Ini adalah perwakilan GitHub dengan aplikasi, dan yang menyukai longread (nyata) - tolong, di bawah kucing.Kami akan mengembangkan dan menguji layanan REST API dengan Python, mengemasnya dalam wadah Docker yang ringan dan menggunakannya menggunakan Ansible.Anda dapat mengimplementasikan layanan REST API dengan berbagai cara menggunakan alat yang berbeda. Solusi yang dijelaskan bukan satu-satunya yang tepat, saya memilih implementasi dan alat berdasarkan pengalaman dan preferensi pribadi saya.
Apa yang kita lakukan?
Bayangkan bahwa toko suvenir online berencana untuk meluncurkan tindakan di berbagai wilayah. Agar strategi penjualan efektif, analisis pasar diperlukan. Toko memiliki pemasok yang secara teratur mengirim (misalnya, melalui pos) data bongkar dengan informasi tentang penduduk.Mari kita kembangkan layanan API Python REST yang akan menganalisis data yang disediakan dan mengidentifikasi permintaan hadiah dari penduduk dari berbagai kelompok umur di berbagai kota berdasarkan bulan.Kami menerapkan penangan berikut dalam layanan:POST /imports
Menambahkan unggahan baru dengan data;
GET /imports/$import_id/citizens
Mengembalikan penghuni tempat pembuangan yang ditentukan;
PATCH /imports/$import_id/citizens/$citizen_id
Mengubah informasi tentang penduduk (dan kerabatnya) dalam bongkar yang ditentukan;
GET /imports/$import_id/citizens/birthdays
, ( ), ;
GET /imports/$import_id/towns/stat/percentile/age
50-, 75- 99- ( ) .
?
Jadi, kami menulis layanan dalam Python menggunakan kerangka kerja yang umum, perpustakaan dan DBMS.Dalam 4 kuliah kursus video, berbagai DBMS dan fiturnya dijelaskan. Untuk implementasi saya, saya memilih PostgreSQL DBMS , yang telah memantapkan dirinya sebagai solusi yang dapat diandalkan dengan dokumentasi yang sangat baik di Rusia , komunitas Rusia yang kuat (Anda selalu dapat menemukan jawaban untuk pertanyaan dalam bahasa Rusia), dan bahkan kursus gratis . Model relasional cukup fleksibel dan dipahami dengan baik oleh banyak pengembang. Meskipun hal yang sama dapat dilakukan pada DBMS NoSQL apa pun, pada artikel ini kami akan mempertimbangkan PostgreSQL.Tujuan utama dari layanan ini - pengiriman data melalui jaringan antara database dan klien - tidak menyiratkan beban yang besar pada prosesor, tetapi membutuhkan kemampuan untuk memproses beberapa permintaan sekaligus. Dalam 10 kuliah dianggap pendekatan tidak sinkron. Ini memungkinkan Anda untuk secara efisien melayani banyak klien dalam proses OS yang sama (tidak seperti, misalnya, model pre-fork yang digunakan dalam Flask / Django, yang menciptakan beberapa proses untuk memproses permintaan dari pengguna, masing-masing dari mereka mengkonsumsi memori, tetapi sebagian besar waktu menganggur) ) Oleh karena itu, sebagai perpustakaan untuk menulis layanan, saya memilih aiohttp asinkron . Kuliah ke
- 5 dari kursus video mengatakan bahwa SQLAlchemy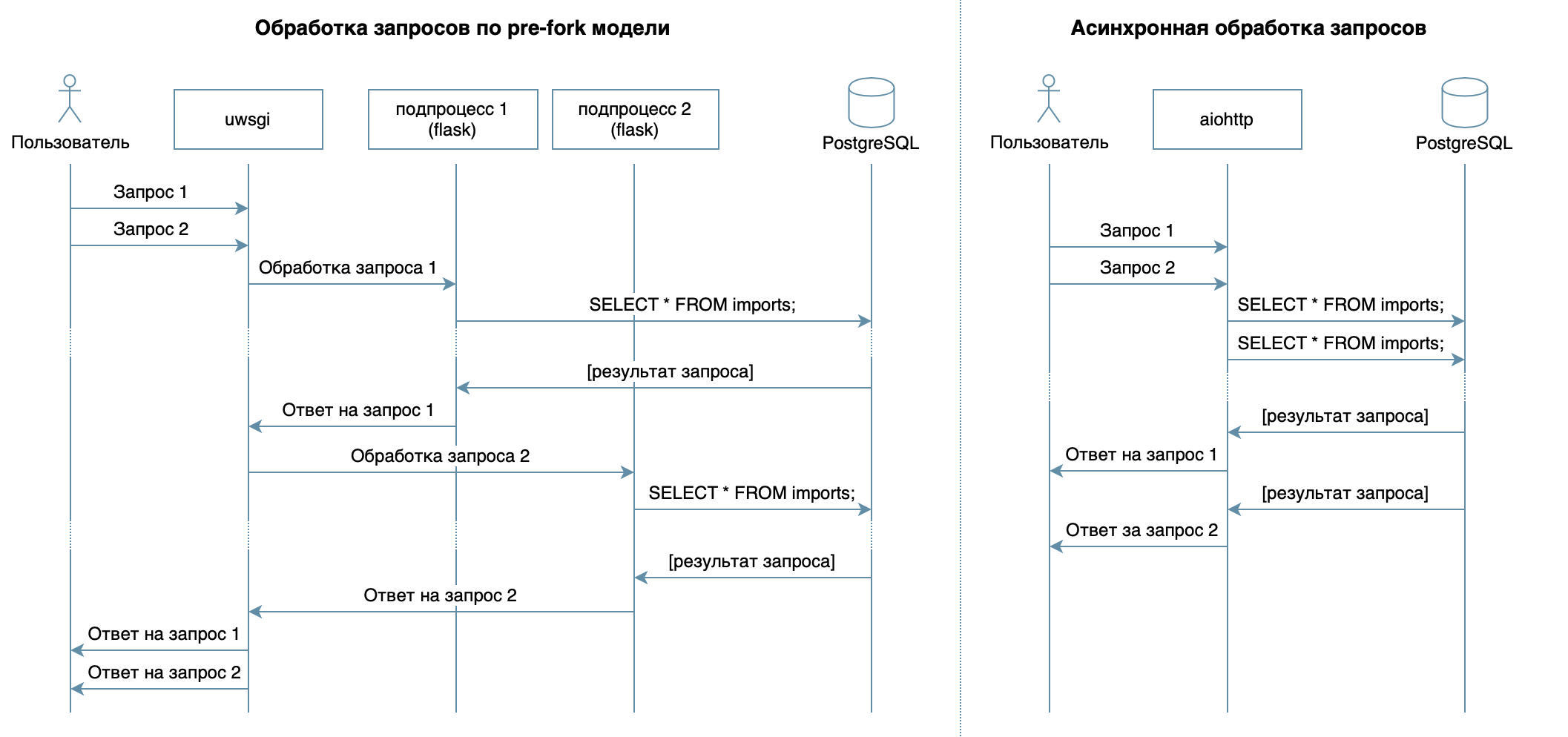 memungkinkan Anda untuk menguraikan kueri kompleks menjadi beberapa bagian, menggunakannya kembali, menghasilkan kueri dengan seperangkat bidang dinamis (misalnya, prosesor PATCH memungkinkan pembaruan sebagian penduduk dengan bidang arbitrer) dan fokus langsung pada logika bisnis. Pengemudi asyncpg dapat menangani permintaan ini dan mentransfer data dengan tercepat , dan asyncpgsa akan membantu mereka berteman .Alat favorit saya untuk mengelola keadaan basis data dan bekerja dengan migrasi adalah Alembic . Ngomong-ngomong, saya baru-baru ini membicarakannya di Moscow Python .Logika validasi dijelaskan secara ringkas oleh skema Marshmallow (termasuk cek untuk ikatan keluarga). Menggunakan modul aiohttp-specSaya menautkan aiohttp-handler dan skema untuk validasi data, dan bonusnya adalah menghasilkan dokumentasi dalam format Swagger dan menampilkannya dalam antarmuka grafis .Untuk tes menulis, saya memilih
memungkinkan Anda untuk menguraikan kueri kompleks menjadi beberapa bagian, menggunakannya kembali, menghasilkan kueri dengan seperangkat bidang dinamis (misalnya, prosesor PATCH memungkinkan pembaruan sebagian penduduk dengan bidang arbitrer) dan fokus langsung pada logika bisnis. Pengemudi asyncpg dapat menangani permintaan ini dan mentransfer data dengan tercepat , dan asyncpgsa akan membantu mereka berteman .Alat favorit saya untuk mengelola keadaan basis data dan bekerja dengan migrasi adalah Alembic . Ngomong-ngomong, saya baru-baru ini membicarakannya di Moscow Python .Logika validasi dijelaskan secara ringkas oleh skema Marshmallow (termasuk cek untuk ikatan keluarga). Menggunakan modul aiohttp-specSaya menautkan aiohttp-handler dan skema untuk validasi data, dan bonusnya adalah menghasilkan dokumentasi dalam format Swagger dan menampilkannya dalam antarmuka grafis .Untuk tes menulis, saya memilih pytest, lebih banyak tentangnya dalam 3 kuliah .Untuk debug dan profil proyek ini, saya menggunakan debugger PyCharm ( kuliah 9 ).Dalam 7 kuliah menjelaskan bagaimana komputer Docker (atau bahkan pada OS yang berbeda) dapat berjalan dikemas tanpa harus menyesuaikan lingkungan aplikasi untuk memulai dan mudah untuk menginstal / memperbarui / menghapus aplikasi di server.Untuk penyebaran, saya memilih Ansible. Ini memungkinkan Anda untuk mendeskripsikan keadaan server dan layanannya secara deklaratif, bekerja melalui ssh dan tidak memerlukan perangkat lunak khusus.Pengembangan
Saya memutuskan untuk memberi nama paket Python analyzerdan menggunakan struktur berikut: Dalam file
Dalam file analyzer/__init__.pysaya memposting informasi umum tentang paket: deskripsi ( docstring ), versi, lisensi, kontak pengembang.Itu dapat dilihat dengan bantuan bawaan$ python
>>> import analyzer
>>> help(analyzer)
Help on package analyzer:
NAME
analyzer
DESCRIPTION
REST API, .
PACKAGE CONTENTS
api (package)
db (package)
utils (package)
DATA
__all__ = ('__author__', '__email__', '__license__', '__maintainer__',...
__email__ = 'alvassin@yandex.ru'
__license__ = 'MIT'
__maintainer__ = 'Alexander Vasin'
VERSION
0.0.1
AUTHOR
Alexander Vasin
FILE
/Users/alvassin/Work/backendschool2019/analyzer/__init__.py
Paket ini memiliki dua titik input - layanan REST API ( analyzer/api/__main__.py) dan utilitas manajemen status basis data ( analyzer/db/__main__.py). File dipanggil __main__.pykarena suatu alasan - pertama, nama seperti itu menarik perhatian, memperjelas bahwa file tersebut adalah titik masuk.Kedua, berkat pendekatan ini ke titik masuk python -m:
$ python -m analyzer.api --help
$ python -m analyzer.db --help
Mengapa Anda harus mulai dengan setup.py?
Ke depan, kami akan memikirkan cara mendistribusikan aplikasi: itu dapat dikemas ke dalam arsip zip (serta roda / telur), paket rpm, file pkg untuk macOS dan diinstal pada komputer jarak jauh, di mesin virtual, MacBook atau Docker- wadah.Tujuan utama dari file setup.pyini adalah untuk menggambarkan paket dengan aplikasi untuk . File harus berisi informasi umum tentang paket (nama, versi, penulis, dll.), Tetapi juga di dalamnya Anda dapat menentukan modul yang diperlukan untuk pekerjaan, dependensi “ekstra” (misalnya, untuk pengujian), titik masuk (misalnya, perintah yang dapat dieksekusi ) dan persyaratan untuk juru bahasa. Plugin Setuptools memungkinkan Anda untuk mengumpulkan artefak dari paket yang dijelaskan. Ada plugin bawaan: zip, egg, rpm, macOS pkg. Plugin yang tersisa didistribusikan melalui PyPI: wheel ,distutils/setuptoolsxar , pex .Pada intinya, menggambarkan satu file, kita mendapatkan peluang besar. Itulah sebabnya pengembangan proyek baru harus dimulai setup.py.Dalam fungsinya, setup()modul dependen ditunjukkan oleh daftar:setup(..., install_requires=["aiohttp", "SQLAlchemy"])
Tapi saya menggambarkan dependensi dalam file terpisah requirements.txtdan requirements.dev.txtyang isinya digunakan setup.py. Tampaknya lebih fleksibel bagi saya, ditambah ada rahasia: nanti akan memungkinkan Anda untuk membangun gambar Docker lebih cepat. Dependensi akan ditetapkan sebagai langkah terpisah sebelum menginstal aplikasi itu sendiri, dan ketika membangun kembali wadah Docker, itu ada dalam cache.Untuk setup.pydapat membaca dependensi dari file requirements.txtdan requirements.dev.txt, fungsinya ditulis:def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
Perlu dicatat bahwa setuptoolsketika default distribusi sumber perakitan hanya mencakup file perakitan .py, .c, .cppdan .h. Untuk file dependensi requirements.txtdan requirements.dev.txttekan tas, mereka harus ditentukan dengan jelas dalam file MANIFEST.in.setup.py seluruhnyaimport os
from importlib.machinery import SourceFileLoader
from pkg_resources import parse_requirements
from setuptools import find_packages, setup
module_name = 'analyzer'
module = SourceFileLoader(
module_name, os.path.join(module_name, '__init__.py')
).load_module()
def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
setup(
name=module_name,
version=module.__version__,
author=module.__author__,
author_email=module.__email__,
license=module.__license__,
description=module.__doc__,
long_description=open('README.rst').read(),
url='https://github.com/alvassin/backendschool2019',
platforms='all',
classifiers=[
'Intended Audience :: Developers',
'Natural Language :: Russian',
'Operating System :: MacOS',
'Operating System :: POSIX',
'Programming Language :: Python',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.8',
'Programming Language :: Python :: Implementation :: CPython'
],
python_requires='>=3.8',
packages=find_packages(exclude=['tests']),
install_requires=load_requirements('requirements.txt'),
extras_require={'dev': load_requirements('requirements.dev.txt')},
entry_points={
'console_scripts': [
'{0}-api = {0}.api.__main__:main'.format(module_name),
'{0}-db = {0}.db.__main__:main'.format(module_name)
]
},
include_package_data=True
)
Anda dapat menginstal proyek dalam mode pengembangan menggunakan perintah berikut (dalam mode yang dapat diedit, Python tidak akan menginstal seluruh paket dalam folder site-packages, tetapi hanya membuat tautan, sehingga setiap perubahan yang dibuat pada file paket akan segera terlihat):
pip install -e '.[dev]'
pip install -e .
Bagaimana cara menentukan versi ketergantungan?
Sangat bagus ketika pengembang secara aktif mengerjakan paket mereka - bug sedang diperbaiki secara aktif di dalamnya, fungsionalitas baru muncul dan umpan balik dapat diperoleh lebih cepat. Tetapi kadang-kadang perubahan dalam pustaka tergantung tidak kompatibel ke belakang dan dapat menyebabkan kesalahan dalam aplikasi Anda jika Anda tidak memikirkannya sebelumnya.Untuk setiap paket dependen, Anda dapat menentukan versi tertentu, misalnya aiohttp==3.6.2. Kemudian aplikasi akan dijamin akan dibangun secara khusus dengan versi pustaka dependen yang dengannya ia diuji. Tetapi pendekatan ini memiliki kelemahan - jika pengembang memperbaiki bug kritis dalam paket dependen yang tidak mempengaruhi kompatibilitas ke belakang, perbaikan ini tidak akan masuk ke dalam aplikasi.Ada pendekatan untuk versi Semantic Versioning, yang menyarankan pengiriman versi dalam format MAJOR.MINOR.PATCH:MAJOR - meningkat ketika perubahan yang tidak kompatibel mundur ditambahkan;MINOR - Meningkat ketika menambahkan fungsionalitas baru dengan dukungan untuk kompatibilitas mundur;PATCH - meningkat ketika menambahkan perbaikan bug dengan dukungan kompatibilitas mundur.
Jika paket tergantung berikut pendekatan ini (yang penulis biasanya dilaporkan dalam file README dan CHANGELOG), itu sudah cukup untuk memperbaiki nilai MAJOR, MINORdan untuk membatasi nilai minimum untuk PATCH-versi: >= MAJOR.MINOR.PATCH, == MAJOR.MINOR.*.Persyaratan seperti itu dapat diimplementasikan menggunakan operator ~ = . Misalnya, ini aiohttp~=3.6.2akan memungkinkan PIP untuk menginstal untuk aiohttpversi 3.6.3, tetapi tidak 3.7.Jika Anda menentukan interval versi dependensi, ini akan memberikan satu keuntungan lagi - tidak akan ada konflik versi antara pustaka dependen.Jika Anda mengembangkan pustaka yang memerlukan paket dependensi berbeda, maka izinkan untuk itu bukan satu versi spesifik, tetapi sebuah interval. Maka akan jauh lebih mudah bagi pengguna perpustakaan Anda untuk menggunakannya (tiba-tiba aplikasi mereka membutuhkan paket ketergantungan yang sama, tetapi dari versi yang berbeda).Semantic Versioning hanyalah perjanjian antara penulis dan konsumen paket. Itu tidak menjamin bahwa penulis menulis kode tanpa bug dan tidak dapat membuat kesalahan dalam versi baru paket mereka.Basis data
Kami merancang skema
Deskripsi POST / import handler memberikan contoh pembongkaran dengan informasi tentang penduduk:Unggah Contoh{
"citizens": [
{
"citizen_id": 1,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "26.12.1986",
"gender": "male",
"relatives": [2]
},
{
"citizen_id": 2,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "01.04.1997",
"gender": "male",
"relatives": [1]
},
{
"citizen_id": 3,
"town": "",
"street": " ",
"building": "2",
"apartment": 11,
"name": " ",
"birth_date": "23.11.1986",
"gender": "female",
"relatives": []
},
...
]
}
Pikiran pertama adalah untuk menyimpan semua informasi tentang penduduk dalam satu tabel citizens, di mana hubungan tersebut akan diwakili oleh bidang relativesdalam bentuk daftar bilangan bulat .Tetapi metode ini memiliki beberapa kelemahanGET /imports/$import_id/citizens/birthdays , , citizens . relatives UNNEST.
, 10- :
SELECT
relations.citizen_id,
relations.relative_id,
date_part('month', relatives.birth_date) as relative_birth_month
FROM (
SELECT
citizens.import_id,
citizens.citizen_id,
UNNEST(citizens.relatives) as relative_id
FROM citizens
WHERE import_id = 1
) as relations
INNER JOIN citizens as relatives ON
relations.import_id = relatives.import_id AND
relations.relative_id = relatives.citizen_id
relatives PostgreSQL, : relatives , . ( ) .
Selanjutnya, saya memutuskan untuk membawa semua data yang diperlukan untuk pekerjaan ke bentuk normal ketiga , dan struktur berikut diperoleh:
- Tabel impor terdiri dari kolom yang bertambah secara otomatis
import_id. Diperlukan untuk membuat pemeriksaan kunci asing di tabel citizens.
- Tabel warga menyimpan data skalar tentang penduduk (semua bidang kecuali informasi tentang hubungan keluarga).
Sepasang ( import_id, citizen_id) digunakan sebagai kunci utama , menjamin keunikan penghuni citizen_iddalam kerangka kerja import_id.
Kunci asing citizens.import_id -> imports.import_idmemastikan bahwa bidang citizens.import_idhanya berisi pembongkaran yang ada.
- relations .
( ): citizens relations .
(import_id, citizen_id, relative_id) , import_id citizen_id c relative_id.
: (relations.import_id, relations.citizen_id) -> (citizens.import_id, citizens.citizen_id) (relations.import_id, relations.relative_id) -> (citizens.import_id, citizens.citizen_id), , citizen_id relative_id .
Struktur ini memastikan integritas data menggunakan PostgreSQL , memungkinkan Anda untuk secara efisien mendapatkan penghuni dengan kerabat dari database, tetapi tunduk pada kondisi balapan saat memperbarui informasi tentang penghuni dengan pertanyaan kompetitif (kami akan melihat lebih dekat pada implementasi penangan PATCH).Jelaskan skema dalam SQLAlchemy
Dalam Bab 5, saya berbicara tentang cara membuat kueri menggunakan SQLAlchemy, Anda perlu menjelaskan skema basis data menggunakan objek khusus: tabel diuraikan menggunakan sqlalchemy.Tabledan terikat ke registri sqlalchemy.MetaDatayang menyimpan semua meta-informasi tentang database. By the way, registri MetaDatatidak hanya dapat menyimpan meta-informasi yang dijelaskan dalam Python, tetapi juga mewakili keadaan sebenarnya dari database dalam bentuk objek SQLAlchemy.Fitur ini juga memungkinkan Alembic untuk membandingkan kondisi dan membuat kode migrasi secara otomatis.Omong-omong, setiap database memiliki skema penamaan kendala standar sendiri. Agar Anda tidak membuang waktu menyebutkan batasan baru atau mencari / mengingat kendala apa yang akan Anda hapus, SQLAlchemy menyarankan menggunakan pola penamaan konvensi penamaan . Mereka dapat didefinisikan dalam registri MetaData.Buat registri MetaData dan berikan pola penamaan padanya
from sqlalchemy import MetaData
convention = {
'all_column_names': lambda constraint, table: '_'.join([
column.name for column in constraint.columns.values()
]),
'ix': 'ix__%(table_name)s__%(all_column_names)s',
'uq': 'uq__%(table_name)s__%(all_column_names)s',
'ck': 'ck__%(table_name)s__%(constraint_name)s',
'fk': 'fk__%(table_name)s__%(all_column_names)s__%(referred_table_name)s',
'pk': 'pk__%(table_name)s'
}
metadata = MetaData(naming_convention=convention)
Jika Anda menentukan pola penamaan, Alembic akan menggunakannya selama generasi migrasi otomatis dan akan memberi nama semua kendala sesuai dengan mereka. Di masa depan, registri yang dibuat MetaDataakan diminta untuk menggambarkan tabel:Kami menggambarkan skema database dengan objek SQLAlchemy
from enum import Enum, unique
from sqlalchemy import (
Column, Date, Enum as PgEnum, ForeignKey, ForeignKeyConstraint, Integer,
String, Table
)
@unique
class Gender(Enum):
female = 'female'
male = 'male'
imports_table = Table(
'imports',
metadata,
Column('import_id', Integer, primary_key=True)
)
citizens_table = Table(
'citizens',
metadata,
Column('import_id', Integer, ForeignKey('imports.import_id'),
primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('town', String, nullable=False, index=True),
Column('street', String, nullable=False),
Column('building', String, nullable=False),
Column('apartment', Integer, nullable=False),
Column('name', String, nullable=False),
Column('birth_date', Date, nullable=False),
Column('gender', PgEnum(Gender, name='gender'), nullable=False),
)
relations_table = Table(
'relations',
metadata,
Column('import_id', Integer, primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('relative_id', Integer, primary_key=True),
ForeignKeyConstraint(
('import_id', 'citizen_id'),
('citizens.import_id', 'citizens.citizen_id')
),
ForeignKeyConstraint(
('import_id', 'relative_id'),
('citizens.import_id', 'citizens.citizen_id')
),
)
Sesuaikan Alembic
Ketika skema database dijelaskan, perlu untuk menghasilkan migrasi, tetapi untuk ini Anda harus terlebih dahulu mengkonfigurasi Alembic, yang juga dibahas dalam Bab 5 .Untuk menggunakan perintah alembic, Anda harus melakukan langkah-langkah berikut:- Instal Paket:
pip install alembic - Initialize Alembic:
cd analyzer && alembic init db/alembic.
Perintah ini akan membuat file konfigurasi analyzer/alembic.inidan folder analyzer/db/alembicdengan konten berikut:
env.py- Dipanggil setiap kali Anda memulai Alembic. Terhubung ke registri Alembic sqlalchemy.MetaDatadengan deskripsi kondisi database yang diinginkan dan berisi instruksi untuk memulai migrasi.
script.py.mako - templat berdasarkan migrasi yang dihasilkan.versions - folder tempat Alembic akan mencari (dan menghasilkan) migrasi.
- Tentukan alamat database dalam file alembic.ini:
; analyzer/alembic.ini
[alembic]
sqlalchemy.url = postgresql://user:hackme@localhost/analyzer
- Tentukan deskripsi kondisi database (registri
sqlalchemy.MetaData) yang diinginkan sehingga Alembic dapat menghasilkan migrasi secara otomatis:
from analyzer.db import schema
target_metadata = schema.metadata
Alembic sudah dikonfigurasi dan sudah bisa digunakan, tetapi dalam kasus kami konfigurasi ini memiliki beberapa kelemahan:- Utilitas
alembicmencari alembic.inidi direktori kerja saat ini. Anda alembic.inidapat menentukan jalur ke argumen baris perintah, tetapi ini tidak nyaman: Saya ingin dapat memanggil perintah dari folder apa pun tanpa parameter tambahan. - Untuk mengonfigurasi Alembic agar berfungsi dengan database tertentu, Anda perlu mengubah file
alembic.ini. Akan jauh lebih mudah untuk menentukan pengaturan basis data untuk variabel lingkungan dan / atau argumen baris perintah, misalnya --pg-url. - Nama utilitas
alembictidak berkorelasi sangat baik dengan nama layanan kami (dan pengguna mungkin sebenarnya tidak memiliki Python sama sekali dan tidak tahu apa-apa tentang Alembic). Akan jauh lebih nyaman bagi pengguna akhir jika semua perintah layanan yang dapat dieksekusi memiliki awalan umum, misalnya analyzer-*.
Masalah-masalah ini diselesaikan dengan pembungkus kecil. analyzer/db/__main__.py:- Alembic menggunakan modul standar untuk memproses argumen baris perintah
argparse. Ini memungkinkan Anda untuk menambahkan argumen opsional --pg-urldengan nilai default dari variabel lingkungan ANALYZER_PG_URL.
Kodeimport os
from alembic.config import CommandLine, Config
from analyzer.utils.pg import DEFAULT_PG_URL
def main():
alembic = CommandLine()
alembic.parser.add_argument(
'--pg-url', default=os.getenv('ANALYZER_PG_URL', DEFAULT_PG_URL),
help='Database URL [env var: ANALYZER_PG_URL]'
)
options = alembic.parser.parse_args()
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
config.set_main_option('sqlalchemy.url', options.pg_url)
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
- Jalur ke file
alembic.inidapat dihitung relatif terhadap lokasi file yang dapat dieksekusi, dan bukan direktori kerja pengguna saat ini.
Kodeimport os
from alembic.config import CommandLine, Config
from pathlib import Path
PROJECT_PATH = Path(__file__).parent.parent.resolve()
def main():
alembic = CommandLine()
options = alembic.parser.parse_args()
if not os.path.isabs(options.config):
options.config = os.path.join(PROJECT_PATH, options.config)
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
alembic_location = config.get_main_option('script_location')
if not os.path.isabs(alembic_location):
config.set_main_option('script_location',
os.path.join(PROJECT_PATH, alembic_location))
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
Ketika utilitas untuk mengelola keadaan basis data siap, ia dapat didaftarkan setup.pysebagai perintah yang dapat dieksekusi dengan nama yang dapat dimengerti oleh pengguna akhir, misalnya analyzer-db:Daftarkan perintah yang dapat dieksekusi di setup.pyfrom setuptools import setup
setup(..., entry_points={
'console_scripts': [
'analyzer-db = analyzer.db.__main__:main'
]
})
Setelah menginstal ulang modul, file akan dibuat env/bin/analyzer-dbdan perintah analyzer-dbakan tersedia:$ pip install -e '.[dev]'
Kami menghasilkan migrasi
Untuk menghasilkan migrasi, diperlukan dua status: diinginkan (yang kami jelaskan dengan objek SQLAlchemy) dan nyata (database, dalam kasus kami, kosong).Saya memutuskan bahwa cara termudah untuk meningkatkan Postgres dengan Docker adalah menambahkan perintah make postgresyang menjalankan sebuah wadah dengan PostgreSQL di port 5432 di latar belakang:Naikkan PostgreSQL dan hasilkan migrasi$ make postgres
...
$ analyzer-db revision --message="Initial" --autogenerate
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'imports'
INFO [alembic.autogenerate.compare] Detected added table 'citizens'
INFO [alembic.autogenerate.compare] Detected added index 'ix__citizens__town' on '['town']'
INFO [alembic.autogenerate.compare] Detected added table 'relations'
Generating /Users/alvassin/Work/backendschool2019/analyzer/db/alembic/versions/d5f704ed4610_initial.py ... done
Alembic umumnya melakukan pekerjaan yang baik dari pekerjaan rutin menghasilkan migrasi, tapi saya ingin menarik perhatian sebagai berikut:- Tipe data pengguna yang ditentukan dalam tabel yang dibuat dibuat secara otomatis (dalam kasus kami -
gender), tetapi kode untuk menghapusnya downgradetidak dihasilkan. Jika Anda menerapkan, memutar kembali, dan kemudian menerapkan migrasi lagi, ini akan menyebabkan kesalahan karena tipe data yang ditentukan sudah ada.
Hapus tipe data gender dalam metode downgradefrom alembic import op
from sqlalchemy import Column, Enum
GenderType = Enum('female', 'male', name='gender')
def upgrade():
...
op.create_table('citizens', ...,
Column('gender', GenderType, nullable=False))
...
def downgrade():
op.drop_table('citizens')
GenderType.drop(op.get_bind())
- Dalam metode ini,
downgradebeberapa tindakan terkadang dapat dihapus (jika kami menghapus seluruh tabel, Anda tidak dapat menghapus indeksnya secara terpisah):
contohnyadef downgrade():
op.drop_table('relations')
op.drop_index(op.f('ix__citizens__town'), table_name='citizens')
op.drop_table('citizens')
op.drop_table('imports')
Saat migrasi diperbaiki dan siap, kami menerapkannya:$ analyzer-db upgrade head
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> d5f704ed4610, Initial
aplikasi
Sebelum Anda mulai membuat penangan, Anda harus mengonfigurasi aplikasi aiohttp.Jika Anda melihat aiohttp quickstart, Anda dapat menulis sesuatu seperti iniimport logging
from aiohttp import web
def main():
logging.basicConfig(level=logging.DEBUG)
app = web.Application()
app.router.add_route(...)
web.run_app(app)
Kode ini menimbulkan sejumlah pertanyaan dan memiliki sejumlah kelemahan:- Bagaimana cara mengkonfigurasi aplikasi? Minimal, Anda harus menentukan host dan port untuk menghubungkan klien, serta informasi untuk menghubungkan ke database.
Saya benar-benar ingin menyelesaikan masalah ini dengan bantuan modul ConfigArgParse: ia memperluas yang standar argparsedan memungkinkan menggunakan argumen baris perintah, variabel lingkungan (sangat diperlukan untuk mengkonfigurasi wadah Docker) dan bahkan file konfigurasi (serta menggabungkan metode ini) untuk konfigurasi. Dengan menggunakannya ConfigArgParse, Anda juga dapat memvalidasi nilai parameter konfigurasi aplikasi.
Contoh pemrosesan parameter menggunakan ConfigArgParsefrom aiohttp import web
from configargparse import ArgumentParser, ArgumentDefaultsHelpFormatter
from analyzer.utils.argparse import positive_int
parser = ArgumentParser(
auto_env_var_prefix='ANALYZER_',
formatter_class=ArgumentDefaultsHelpFormatter
)
parser.add_argument('--api-address', default='0.0.0.0',
help='IPv4/IPv6 address API server would listen on')
parser.add_argument('--api-port', type=positive_int, default=8081,
help='TCP port API server would listen on')
def main():
args = parser.parse_args()
app = web.Application()
web.run_app(app, host=args.api_address, port=args.api_port)
if __name__ == '__main__':
main()
, ConfigArgParse, argparse, ( -h --help). :
$ python __main__.py --help
usage: __main__.py [-h] [--api-address API_ADDRESS] [--api-port API_PORT]
If an arg is specified in more than one place, then commandline values override environment variables which override defaults.
optional arguments:
-h, --help show this help message and exit
--api-address API_ADDRESS
IPv4/IPv6 address API server would listen on [env var: ANALYZER_API_ADDRESS] (default: 0.0.0.0)
--api-port API_PORT TCP port API server would listen on [env var: ANALYZER_API_PORT] (default: 8081)
- — , «» . , .
os.environ.clear(), Python (, asyncio?), , ConfigArgParser.
import os
from typing import Callable
from configargparse import ArgumentParser
from yarl import URL
from analyzer.api.app import create_app
from analyzer.utils.pg import DEFAULT_PG_URL
ENV_VAR_PREFIX = 'ANALYZER_'
parser = ArgumentParser(auto_env_var_prefix=ENV_VAR_PREFIX)
parser.add_argument('--pg-url', type=URL, default=URL(DEFAULT_PG_URL),
help='URL to use to connect to the database')
def clear_environ(rule: Callable):
"""
,
rule
"""
for name in filter(rule, tuple(os.environ)):
os.environ.pop(name)
def main():
args = parser.parse_args()
clear_environ(lambda i: i.startswith(ENV_VAR_PREFIX))
app = create_app(args)
...
if __name__ == '__main__':
main()
- stderr/ .
9 , logging.basicConfig() stderr.
, . aiomisc.
aiomiscimport logging
from aiomisc.log import basic_config
basic_config(logging.DEBUG, buffered=True)
- , ? ,
fork , (, Windows ).
import os
from sys import argv
import forklib
from aiohttp.web import Application, run_app
from aiomisc import bind_socket
from setproctitle import setproctitle
def main():
sock = bind_socket(address='0.0.0.0', port=8081, proto_name='http')
setproctitle(f'[Master] {os.path.basename(argv[0])}')
def worker():
setproctitle(f'[Worker] {os.path.basename(argv[0])}')
app = Application()
run_app(app, sock=sock)
forklib.fork(os.cpu_count(), worker, auto_restart=True)
if __name__ == '__main__':
main()
- - ? , ( — ) ,
nobody. — .
import os
import pwd
from aiohttp.web import run_app
from aiomisc import bind_socket
from analyzer.api.app import create_app
def main():
sock = bind_socket(address='0.0.0.0', port=8085, proto_name='http')
user = pwd.getpwnam('nobody')
os.setgid(user.pw_gid)
os.setuid(user.pw_uid)
app = create_app(...)
run_app(app, sock=sock)
if __name__ == '__main__':
main()
create_app, .
Semua respons penangan yang berhasil akan dikembalikan dalam format JSON. Akan lebih mudah bagi klien untuk menerima informasi tentang kesalahan dalam bentuk serial (misalnya, untuk melihat bidang mana yang tidak lulus validasi).Dokumentasi aiohttpmenawarkan metode json_responseyang mengambil objek, membuat serialisasi dalam JSON, dan mengembalikan objek baru aiohttp.web.Responsedengan header Content-Type: application/jsondan data serial di dalamnya.Bagaimana cara membuat cerita bersambung data menggunakan json_responsefrom aiohttp.web import Application, View, run_app
from aiohttp.web_response import json_response
class SomeView(View):
async def get(self):
return json_response({'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
Tetapi ada cara lain: aiohttp memungkinkan Anda untuk mendaftarkan serializer yang sewenang-wenang untuk jenis data respons tertentu dalam registri aiohttp.PAYLOAD_REGISTRY. Misalnya, Anda bisa menentukan serializer aiohttp.JsonPayloaduntuk objek-objek tipe pemetaan .Dalam hal ini, itu akan cukup bagi pawang untuk mengembalikan objek Responsedengan data respons dalam parameter body. aiohttp akan menemukan serializer yang cocok dengan tipe data dan membuat serialisasi respons.Selain fakta bahwa serialisasi objek dideskripsikan di satu tempat, pendekatan ini juga lebih fleksibel - memungkinkan Anda untuk mengimplementasikan solusi yang sangat menarik (kami akan mempertimbangkan salah satu case use di handler GET /imports/$import_id/citizens).Cara membuat cerita bersambung data menggunakan aiohttp.PAYLOAD_REGISTRYfrom types import MappingProxyType
from typing import Mapping
from aiohttp import PAYLOAD_REGISTRY, JsonPayload
from aiohttp.web import run_app, Application, Response, View
PAYLOAD_REGISTRY.register(JsonPayload, (Mapping, MappingProxyType))
class SomeView(View):
async def get(self):
return Response(body={'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
Penting untuk memahami bahwa json_response, seperti aiohttp.JsonPayload, mereka menggunakan metode standar json.dumpsyang tidak dapat membuat serial tipe data yang kompleks, misalnya, datetime.dateatau asyncpg.Record( asyncpgmengembalikan catatan dari database sebagai instance dari kelas ini). Selain itu, beberapa objek kompleks mungkin berisi yang lain: dalam satu catatan dari database mungkin ada bidang tipe datetime.date.Pengembang Python telah mengatasi masalah ini: metode ini json.dumpsmemungkinkan Anda menggunakan argumen defaultuntuk menentukan fungsi yang dipanggil saat perlu membuat serial objek yang tidak dikenal. Fungsi ini diharapkan untuk melemparkan objek asing ke tipe yang dapat membuat serial modul json.Bagaimana cara memperpanjang JsonPayload untuk membuat serial objek yang sewenang-wenangimport json
from datetime import date
from functools import partial, singledispatch
from typing import Any
from aiohttp.payload import JsonPayload as BaseJsonPayload
from aiohttp.typedefs import JSONEncoder
@singledispatch
def convert(value):
raise NotImplementedError(f'Unserializable value: {value!r}')
@convert.register(Record)
def convert_asyncpg_record(value: Record):
"""
,
asyncpg
"""
return dict(value)
@convert.register(date)
def convert_date(value: date):
"""
date —
.
..
"""
return value.strftime('%d.%m.%Y')
dumps = partial(json.dumps, default=convert)
class JsonPayload(BaseJsonPayload):
def __init__(self,
value: Any,
encoding: str = 'utf-8',
content_type: str = 'application/json',
dumps: JSONEncoder = dumps,
*args: Any,
**kwargs: Any) -> None:
super().__init__(value, encoding, content_type, dumps, *args, **kwargs)
Penangan
aiohttp memungkinkan Anda menerapkan penangan dengan fungsi dan kelas asinkron. Kelas lebih dapat diperluas: pertama, kode milik satu penangan dapat ditempatkan di satu tempat, dan kedua, kelas memungkinkan Anda menggunakan warisan untuk menyingkirkan duplikasi kode (misalnya, setiap penangan memerlukan koneksi basis data).Kelas Dasar Handlerfrom aiohttp.web_urldispatcher import View
from asyncpgsa import PG
class BaseView(View):
URL_PATH: str
@property
def pg(self) -> PG:
return self.request.app['pg']
Karena sulit membaca satu file besar, saya memutuskan untuk membagi penangan menjadi file. File kecil mendorong konektivitas yang lemah, dan jika, misalnya, ada impor cincin di dalam handler, itu berarti ada sesuatu yang salah dengan komposisi entitas.POST / impor
Pawang input menerima json dengan data tentang penghuni. Ukuran permintaan maksimum yang diizinkan dalam aiohttp dikendalikan oleh opsi client_max_sizedan 2 MB secara default . Jika batas terlampaui, aiohttp akan mengembalikan respons HTTP dengan status 413: Request Entity Too Large Error.Pada saat yang sama, json yang benar dengan garis dan angka terpanjang akan berbobot ~ 63 megabita, sehingga pembatasan pada ukuran permintaan perlu diperluas.Selanjutnya, Anda perlu memeriksa dan membatalkan registrasi data . Jika salah, Anda harus mengembalikan respons HTTP 400: Bad Request.Saya membutuhkan dua skema Marhsmallow. Yang pertama CitizenSchema, memeriksa data dari masing-masing penduduk, dan juga membatalkan deserialisasi string selamat ulang tahun ke objek datetime.date:- Jenis data, format, dan ketersediaan semua bidang yang diperlukan;
- Kurangnya bidang yang tidak dikenal;
- Tanggal lahir harus ditunjukkan dalam format
DD.MM.YYYYdan tidak boleh penting dari masa depan; - Daftar kerabat masing-masing penduduk harus berisi pengidentifikasi unik dari penduduk yang ada dalam unggahan ini.
Skema kedua ImportSchema,, memeriksa pembongkaran secara keseluruhan:citizen_id setiap penduduk dalam bongkar muat harus unik;- Ikatan keluarga harus dua arah (jika residen # 1 memiliki residen # 2 dalam daftar kerabat, maka residen # 2 juga harus memiliki kerabat # 1).
Jika data benar, mereka harus ditambahkan ke database dengan yang unik baru import_id.Untuk menambahkan data, Anda perlu melakukan beberapa permintaan di tabel yang berbeda. Untuk menghindari sebagian data yang ditambahkan sebagian dalam database jika terjadi kesalahan atau pengecualian (misalnya, ketika memutuskan koneksi klien yang tidak menerima respons penuh, aiohttp akan membuang pengecualian CancelledError ), Anda harus menggunakan transaksi .Penting untuk menambahkan data ke tabel di bagian-bagian , karena dalam satu permintaan ke PostgreSQL tidak boleh ada lebih dari 32.767 argumen. Ada citizens9 bidang dalam tabel . Oleh karena itu, untuk 1 permintaan, hanya 32.767 / 9 = 3.640 baris dapat dimasukkan ke dalam tabel ini, dan dalam satu unggahan bisa ada hingga 10.000 penduduk.DAPATKAN / impor / $ import_id / warga
Pawang mengembalikan semua penghuni untuk diturunkan dengan yang ditentukan import_id. Jika unggahan yang ditentukan tidak ada , Anda harus mengembalikan respons HTTP 404: Not Found. Perilaku ini tampaknya umum untuk penangan yang membutuhkan pembongkaran yang ada, jadi saya menarik kode verifikasi ke kelas yang terpisah.Kelas dasar untuk penangan dengan pembongkaranfrom aiohttp.web_exceptions import HTTPNotFound
from sqlalchemy import select, exists
from analyzer.db.schema import imports_table
class BaseImportView(BaseView):
@property
def import_id(self):
return int(self.request.match_info.get('import_id'))
async def check_import_exists(self):
query = select([
exists().where(imports_table.c.import_id == self.import_id)
])
if not await self.pg.fetchval(query):
raise HTTPNotFound()
Untuk mendapatkan daftar kerabat untuk setiap penduduk, Anda harus melakukan LEFT JOINdari meja citizenske meja relations, mengumpulkan bidang yang relations.relative_iddikelompokkan oleh import_iddan citizen_id.Jika penduduk tidak memiliki kerabat, maka ia LEFT JOINakan mengembalikan relations.relative_idnilai untuknya di lapangan NULLdan, sebagai hasil dari agregasi, daftar kerabat akan terlihat seperti [NULL].Untuk memperbaiki nilai yang salah ini, saya menggunakan fungsi array_remove .Basis data menyimpan tanggal dalam format YYYY-MM-DD, tetapi kami membutuhkan format DD.MM.YYYY.Secara teknis, Anda bisa memformat tanggal baik dengan kueri SQL atau di sisi Python pada saat serialisasi respons dengan json.dumps(asyncpg mengembalikan nilai bidang birth_datesebagai turunan dari kelasdatetime.date)Saya memilih serialisasi di sisi Python, mengingat bahwa itu birth_dateadalah satu-satunya objek datetime.datedalam proyek dengan format tunggal (lihat bagian "Serialisasi Data" ).Terlepas dari kenyataan bahwa prosesor mengeksekusi dua permintaan (memeriksa keberadaan bongkar dan permintaan untuk daftar penduduk), tidak perlu menggunakan transaksi . Secara default, PostgreSQL menggunakan tingkat isolasi, READ COMMITTEDdan bahkan dalam satu transaksi semua perubahan ke yang lain, transaksi yang berhasil diselesaikan akan terlihat (menambahkan baris baru, mengubah yang sudah ada).Unggahan terbesar dalam tampilan teks dapat memakan waktu ~ 63 megabita - ini cukup banyak, terutama mengingat beberapa permintaan untuk menerima data dapat tiba pada saat yang bersamaan. Ada cara yang agak menarik untuk mendapatkan data dari database menggunakan kursor dan mengirimkannya ke klien dalam beberapa bagian .Untuk melakukan ini, kita perlu mengimplementasikan dua objek:SelectQueryTipe objek AsyncIterableyang mengembalikan catatan dari database. Pada panggilan pertama, terhubung ke database, membuka transaksi dan membuat kursor, selama iterasi lebih lanjut, ia mengembalikan catatan dari database. Itu dikembalikan oleh pawang.
Pilih Kode Kuerifrom collections import AsyncIterable
from asyncpgsa.transactionmanager import ConnectionTransactionContextManager
from sqlalchemy.sql import Select
class SelectQuery(AsyncIterable):
"""
, PostgreSQL
, ,
"""
PREFETCH = 500
__slots__ = (
'query', 'transaction_ctx', 'prefetch', 'timeout'
)
def __init__(self, query: Select,
transaction_ctx: ConnectionTransactionContextManager,
prefetch: int = None,
timeout: float = None):
self.query = query
self.transaction_ctx = transaction_ctx
self.prefetch = prefetch or self.PREFETCH
self.timeout = timeout
async def __aiter__(self):
async with self.transaction_ctx as conn:
cursor = conn.cursor(self.query, prefetch=self.prefetch,
timeout=self.timeout)
async for row in cursor:
yield row
- Serializer
AsyncGenJSONListPayloadyang dapat beralih melalui generator asinkron, membuat serialisasi data dari generator asinkron ke JSON dan mengirim data ke klien di beberapa bagian. Terdaftar aiohttp.PAYLOAD_REGISTRYsebagai serializer objek AsyncIterable.
Kode AsyncGenJSONListPayloadimport json
from functools import partial
from aiohttp import Payload
dumps = partial(json.dumps, default=convert, ensure_ascii=False)
class AsyncGenJSONListPayload(Payload):
"""
AsyncIterable,
JSON
"""
def __init__(self, value, encoding: str = 'utf-8',
content_type: str = 'application/json',
root_object: str = 'data',
*args, **kwargs):
self.root_object = root_object
super().__init__(value, content_type=content_type, encoding=encoding,
*args, **kwargs)
async def write(self, writer):
await writer.write(
('{"%s":[' % self.root_object).encode(self._encoding)
)
first = True
async for row in self._value:
if not first:
await writer.write(b',')
else:
first = False
await writer.write(dumps(row).encode(self._encoding))
await writer.write(b']}')
Lebih lanjut, dalam handler akan dimungkinkan untuk membuat objek SelectQuery, meneruskan kueri SQL dan fungsinya untuk membuka transaksi, dan mengembalikannya ke Response body:Kode penangan
from aiohttp.web_response import Response
from aiohttp_apispec import docs, response_schema
from analyzer.api.schema import CitizensResponseSchema
from analyzer.db.schema import citizens_table as citizens_t
from analyzer.utils.pg import SelectQuery
from .query import CITIZENS_QUERY
from .base import BaseImportView
class CitizensView(BaseImportView):
URL_PATH = r'/imports/{import_id:\d+}/citizens'
@docs(summary=' ')
@response_schema(CitizensResponseSchema())
async def get(self):
await self.check_import_exists()
query = CITIZENS_QUERY.where(
citizens_t.c.import_id == self.import_id
)
body = SelectQuery(query, self.pg.transaction())
return Response(body=body)
aiohttpmendeteksi aiohttp.PAYLOAD_REGISTRYserializer terdaftar AsyncGenJSONListPayloaduntuk objek-objek tipe dalam registri AsyncIterable. Kemudian serializer akan beralih di atas objek SelectQuerydan mengirim data ke klien. Pada panggilan pertama, objek SelectQuerymenerima koneksi ke database, membuka transaksi dan membuat kursor, selama iterasi lebih lanjut, ia akan menerima data dari database dengan kursor dan mengembalikannya baris demi baris.Pendekatan ini memungkinkan untuk tidak mengalokasikan memori untuk seluruh jumlah data dengan setiap permintaan, tetapi memiliki kekhasan: aplikasi tidak akan dapat mengembalikan status HTTP yang sesuai ke klien jika kesalahan terjadi (setelah semua, status HTTP, header sudah dikirim ke klien, dan data sedang ditulis).Ketika pengecualian terjadi, tidak ada yang tersisa selain memutuskan koneksi. Pengecualian, tentu saja, dapat diamankan, tetapi klien tidak akan dapat memahami dengan tepat kesalahan apa yang terjadi.Di sisi lain, situasi serupa mungkin muncul bahkan jika prosesor menerima semua data dari database, tetapi jaringan berkedip saat mentransmisikan data ke klien - tidak ada yang aman dari ini.PATCH / impor / $ import_id / warga negara / $ citizen_id
Pawang menerima pengidentifikasi pembongkaran import_id, residen citizen_id, serta json dengan data baru tentang residen. Dalam hal bongkar muat atau penduduk yang tidak ada , respons HTTP harus dikembalikan 404: Not Found.Data yang dikirimkan oleh klien harus diverifikasi dan deserialized . Jika salah, Anda harus mengembalikan respons HTTP 400: Bad Request. Saya menerapkan skema Marshmallow PatchCitizenSchemayang memeriksa:- Jenis dan format data untuk bidang yang ditentukan.
- Tanggal lahir. Itu harus ditentukan dalam format
DD.MM.YYYYdan tidak bisa penting dari masa depan. - Daftar kerabat masing-masing penduduk. Itu harus memiliki pengidentifikasi unik untuk penduduk.
Keberadaan kerabat yang ditunjukkan di lapangan relativestidak dapat diperiksa secara terpisah: jika relationspenduduk yang tidak ada ditambahkan ke tabel, PostgreSQL akan mengembalikan kesalahan ForeignKeyViolationErroryang dapat diproses dan status HTTP dapat dikembalikan 400: Bad Request.Status apa yang harus dikembalikan jika klien mengirim data yang salah untuk penduduk atau pembongkaran yang tidak ada ? Secara semantik lebih tepat untuk memeriksa terlebih dahulu keberadaan bongkar dan penduduk (jika tidak ada, kembali 404: Not Found) dan hanya kemudian apakah klien telah mengirim data yang benar (jika tidak, kembali 400: Bad Request). Dalam praktiknya, seringkali lebih murah untuk memeriksa data terlebih dahulu, dan hanya jika mereka benar, akses database.Kedua opsi dapat diterima, tetapi saya memutuskan untuk memilih opsi kedua yang lebih murah, karena dalam hal apapun hasil operasi adalah kesalahan yang tidak mempengaruhi apa-apa (klien akan memperbaiki data dan kemudian juga mengetahui bahwa penduduk tidak ada).Jika datanya benar, maka perlu memperbarui informasi tentang penduduk di basis data . Di handler, Anda perlu membuat beberapa query ke tabel yang berbeda. Jika terjadi kesalahan atau pengecualian, perubahan pada basis data harus dibatalkan, sehingga kueri harus dilakukan dalam transaksi .Metode ini PATCH memungkinkan Anda untuk mentransfer hanya beberapa bidang untuk penduduk.Pawang harus ditulis sedemikian rupa sehingga tidak macet saat mengakses data yang tidak ditentukan klien, dan juga tidak menjalankan kueri pada tabel di mana data tidak berubah.Jika klien menentukan bidang relatives, perlu untuk mendapatkan daftar kerabat yang ada. Jika sudah berubah, tentukan catatan mana dari tabel yang relativesharus dihapus dan yang mana yang ditambahkan untuk membuat basis data sejalan dengan permintaan klien. Secara default, PostgreSQL menggunakan isolasi transaksi READ COMMITTED. Ini berarti bahwa sebagai bagian dari transaksi saat ini, perubahan akan terlihat oleh catatan yang ada (dan juga yang baru) dari transaksi yang diselesaikan lainnya. Ini dapat menyebabkan kondisi balapan antara permintaan kompetitif .Misalkan ada bongkar muat dengan penghuni#1. #2, #3tanpa kekerabatan. Layanan menerima dua permintaan secara bersamaan untuk mengubah penduduk # 1: {"relatives": [2]}dan {"relatives": [3]}. aiohttp akan membuat dua penangan yang secara bersamaan menerima status residen saat ini dari PostgreSQL.Setiap handler tidak akan mendeteksi hubungan terkait tunggal dan akan memutuskan untuk menambahkan hubungan baru dengan kerabat yang ditentukan. Akibatnya, penduduk # 1 memiliki bidang yang sama dengan kerabat [2,3]. Perilaku ini tidak bisa disebut jelas. Ada dua opsi yang diharapkan untuk memutuskan hasil balapan: untuk menyelesaikan hanya permintaan pertama, dan untuk yang kedua untuk mengembalikan respons HTTP
Perilaku ini tidak bisa disebut jelas. Ada dua opsi yang diharapkan untuk memutuskan hasil balapan: untuk menyelesaikan hanya permintaan pertama, dan untuk yang kedua untuk mengembalikan respons HTTP409: Conflict(sehingga klien mengulangi permintaan), atau untuk mengeksekusi permintaan pada gilirannya (permintaan kedua akan diproses hanya setelah yang pertama selesai).Opsi pertama dapat diterapkan dengan menyalakan mode isolasiSERIALIZABLE. Jika selama pemrosesan permintaan seseorang sudah berhasil mengubah dan mengkomit data, pengecualian akan dilempar, yang dapat diproses dan status HTTP yang sesuai dikembalikan.Kerugian dari solusi ini - sejumlah besar kunci di PostgreSQL, SERIALIZABLEakan mengeluarkan pengecualian, bahkan jika pertanyaan kompetitif mengubah catatan penghuni dari pembongkaran yang berbeda.Anda juga dapat menggunakan mekanisme kunci rekomendasi . Jika Anda mendapatkan kunci seperti itu import_id, permintaan kompetitif untuk pembongkaran yang berbeda akan dapat berjalan secara paralel.Untuk memproses permintaan kompetitif dalam satu unggahan, Anda dapat menerapkan perilaku salah satu opsi: fungsi pg_try_advisory_xact_lockmencoba mendapatkan kunci danmengembalikan hasil boolean segera (jika itu tidak mungkin untuk mendapatkan kunci - pengecualian dapat dilemparkan), tetapi pg_advisory_xact_lockmenunggu sampaisumber daya tersedia untuk diblokir (dalam hal ini, permintaan akan dieksekusi secara berurutan, saya memilih opsi ini).Akibatnya, pawang harus mengembalikan informasi saat ini tentang penduduk yang diperbarui . Dimungkinkan untuk membatasi diri untuk mengembalikan data dari permintaannya kepada klien (karena kami mengembalikan respons kepada klien, itu berarti bahwa tidak ada pengecualian dan semua permintaan berhasil diselesaikan). Atau - gunakan kata kunci RETURNING dalam kueri yang memodifikasi database dan menghasilkan respons dari hasil. Tetapi kedua pendekatan ini tidak akan memungkinkan kami untuk melihat dan menguji kasus ini dengan ras negara.Tidak ada persyaratan beban tinggi untuk layanan ini, jadi saya memutuskan untuk meminta semua data tentang residen lagi dan mengembalikan klien hasil yang jujur dari database.DAPATKAN / impor / $ import_id / warga negara / ulang tahun
Pawang menghitung jumlah hadiah yang akan diberikan oleh masing-masing penduduk bongkar kepada kerabatnya (urutan pertama). Jumlahnya dikelompokkan berdasarkan bulan untuk diunggah dengan yang ditentukan import_id. Dalam hal unggahan yang tidak ada , respons HTTP harus dikembalikan 404: Not Found.Ada dua opsi implementasi:- Dapatkan data untuk penghuni yang memiliki kerabat dari basis data, dan di sisi Python, gabungkan data berdasarkan bulan dan buat daftar untuk bulan-bulan yang tidak ada datanya di dalam basis data.
- Kompilasi permintaan json di database dan tambahkan bertopik untuk bulan-bulan yang hilang.
Saya memilih opsi pertama - secara visual terlihat lebih mudah dimengerti dan didukung. Jumlah ulang tahun di bulan tertentu dapat diperoleh dengan membuat JOINdari tabel dengan ikatan keluarga ( relations.citizen_id- penduduk yang kami anggap sebagai hari ulang tahun kerabat) ke dalam tabel citizens(berisi tanggal lahir dari mana Anda ingin mendapatkan bulan).Nilai bulan tidak boleh mengandung angka nol di depan. Bulan yang diperoleh dari lapangan birth_datemenggunakan fungsi date_partdapat berisi nol di depan. Untuk menghapusnya, saya tampil castuntuk integerdalam query SQL.Terlepas dari kenyataan bahwa pawang harus memenuhi dua permintaan (periksa keberadaan bongkar muat dan dapatkan informasi tentang ulang tahun dan hadiah), transaksi tidak diperlukan .Secara default, PostgreSQL menggunakan mode READ COMMITTED, di mana semua catatan baru (ditambahkan oleh transaksi lain) dan yang sudah ada (dimodifikasi oleh transaksi lain) terlihat dalam transaksi saat ini setelah mereka berhasil diselesaikan.Misalnya, jika unggahan baru ditambahkan pada saat menerima data, itu tidak akan memengaruhi yang sudah ada. Jika pada saat penerimaan data, permintaan untuk mengubah penduduk dieksekusi, apakah data tersebut belum akan terlihat (jika transaksi mengubah data belum selesai), atau transaksi akan selesai sepenuhnya dan semua perubahan akan segera terlihat. Integritas yang diperoleh dari basis data tidak akan dilanggar.DAPATKAN / impor / $ import_id / kota / stat / persentil / usia
Pawang menghitung persentil ke-50, ke-75 dan ke-99 dari usia (tahun penuh) penduduk menurut kota dalam sampel dengan import_id yang ditentukan. Dalam hal unggahan yang tidak ada , respons HTTP harus dikembalikan 404: Not Found.Terlepas dari kenyataan bahwa prosesor mengeksekusi dua permintaan (memeriksa keberadaan bongkar dan mendapatkan daftar penduduk), tidak perlu menggunakan transaksi .Ada dua opsi implementasi:- Dapatkan usia penduduk dari database, dikelompokkan berdasarkan kota, dan kemudian di sisi Python menghitung persentil menggunakan numpy (yang ditentukan sebagai referensi dalam tugas) dan membulatkan hingga dua tempat desimal.
- PostgreSQL: percentile_cont , SQL-, numpy .
Opsi kedua membutuhkan lebih sedikit data untuk ditransfer antara aplikasi dan PostgreSQL, tetapi tidak memiliki perangkap yang sangat jelas: di PostgreSQL, pembulatan adalah matematika, ( SELECT ROUND(2.5)mengembalikan 3), dan dalam Python - akuntansi, ke bilangan bulat terdekat ( round(2.5)mengembalikan 2).Untuk menguji handler, implementasinya harus sama di PostgreSQL dan Python (mengimplementasikan fungsi dengan pembulatan matematis di Python terlihat lebih mudah). Perlu dicatat bahwa ketika menghitung persentil, numpy dan PostgreSQL dapat mengembalikan angka yang sedikit berbeda, tetapi mengingat pembulatannya, perbedaan ini tidak akan terlihat.Pengujian
Apa yang perlu diperiksa dalam aplikasi ini? Pertama, bahwa pawang memenuhi persyaratan dan melakukan pekerjaan yang diperlukan dalam lingkungan sedekat mungkin dengan lingkungan pertempuran. Kedua, migrasi yang mengubah status database berfungsi tanpa kesalahan. Ketiga, ada sejumlah fungsi tambahan yang juga bisa dicakup dengan benar oleh tes.Saya memutuskan untuk menggunakan kerangka pytest karena fleksibilitas dan kemudahan penggunaannya. Ini menawarkan mekanisme yang kuat untuk mempersiapkan lingkungan untuk tes - perlengkapan , yaitu, fungsi dengan dekoratorpytest.mark.fixtureyang namanya dapat ditentukan oleh parameter dalam tes. Jika pytest mendeteksi parameter dengan nama fixture dalam anotasi tes, itu akan menjalankan fixture ini dan meneruskan hasilnya dalam nilai parameter ini. Dan jika fixture adalah generator, maka parameter tes akan mengambil nilai yang dikembalikan yield, dan setelah tes selesai, bagian kedua fixture akan dieksekusi, yang dapat menghapus sumber daya atau menutup koneksi.Untuk sebagian besar tes, kita membutuhkan database PostgreSQL. Untuk mengisolasi tes satu sama lain, Anda dapat membuat database terpisah sebelum setiap tes, dan menghapusnya setelah eksekusi.Buat database fixture untuk setiap tesimport os
import uuid
import pytest
from sqlalchemy import create_engine
from sqlalchemy_utils import create_database, drop_database
from yarl import URL
from analyzer.utils.pg import DEFAULT_PG_URL
PG_URL = os.getenv('CI_ANALYZER_PG_URL', DEFAULT_PG_URL)
@pytest.fixture
def postgres():
tmp_name = '.'.join([uuid.uuid4().hex, 'pytest'])
tmp_url = str(URL(PG_URL).with_path(tmp_name))
create_database(tmp_url)
try:
yield tmp_url
finally:
drop_database(tmp_url)
def test_db(postgres):
"""
, PostgreSQL
"""
engine = create_engine(postgres)
assert engine.execute('SELECT 1').scalar() == 1
engine.dispose()
Modul sqlalchemy_utils melakukan tugasnya dengan baik , dengan mempertimbangkan fitur-fitur dari berbagai basis data dan driver. Sebagai contoh, PostgreSQL tidak mengizinkan eksekusi CREATE DATABASEdalam blok transaksi. Saat membuat database, itu sqlalchemy_utilsmenerjemahkan psycopg2(yang biasanya mengeksekusi semua permintaan dalam transaksi) ke mode autocommit.Fitur penting lainnya: jika setidaknya satu klien terhubung ke PostgreSQL, database tidak dapat dihapus, tetapi sqlalchemy_utilsmemutus semua klien sebelum menghapus database. Basis data akan berhasil dihapus bahkan jika beberapa tes dengan koneksi aktif terhenti.Kami membutuhkan PostgreSQL di negara bagian yang berbeda: untuk menguji migrasi, kami membutuhkan database yang bersih, sementara penangan mengharuskan semua migrasi diterapkan. Anda secara programatik dapat mengubah keadaan database menggunakan perintah Alembic, mereka membutuhkan objek konfigurasi Alembic untuk memanggil mereka.Buat objek konfigurasi fixture Alembicfrom types import SimpleNamespace
import pytest
from analyzer.utils.pg import make_alembic_config
@pytest.fixture()
def alembic_config(postgres):
cmd_options = SimpleNamespace(config='alembic.ini', name='alembic',
pg_url=postgres, raiseerr=False, x=None)
return make_alembic_config(cmd_options)
Harap dicatat bahwa perlengkapan alembic_configmemiliki parameter postgres- pytestmemungkinkan tidak hanya untuk menunjukkan ketergantungan tes pada perlengkapan, tetapi juga ketergantungan antara perlengkapan.Mekanisme ini memungkinkan Anda untuk secara fleksibel memisahkan logika dan menulis kode yang sangat ringkas dan dapat digunakan kembali.Penangan
Penangan penguji membutuhkan database dengan tabel dan tipe data yang dibuat. Untuk menerapkan migrasi, Anda harus secara terprogram memanggil perintah pemutakhiran Alembic. Untuk menyebutnya, Anda memerlukan objek dengan konfigurasi Alembic, yang telah kami tentukan dengan fixture alembic_config. Database dengan migrasi tampak seperti entitas yang sepenuhnya independen, dan dapat direpresentasikan sebagai fixture:from alembic.command import upgrade
@pytest.fixture
async def migrated_postgres(alembic_config, postgres):
upgrade(alembic_config, 'head')
return postgres
Ketika ada banyak migrasi dalam proyek, aplikasi mereka untuk setiap tes mungkin memakan waktu terlalu banyak. Untuk mempercepat proses, Anda bisa membuat database dengan migrasi sekali dan kemudian menggunakannya sebagai templat .Selain database untuk penangan pengujian, Anda akan memerlukan aplikasi yang berjalan, serta klien yang dikonfigurasi untuk bekerja dengan aplikasi ini. Untuk membuat aplikasi ini mudah untuk diuji, saya menempatkan ciptaannya ke dalam fungsi create_appyang mengambil parameter untuk dijalankan: database, port untuk REST API, dan lainnya.Argumen untuk meluncurkan aplikasi juga dapat direpresentasikan sebagai fixture terpisah. Untuk membuatnya, Anda perlu menentukan port gratis untuk menjalankan aplikasi pengujian dan alamat ke basis data sementara yang dimigrasi.Untuk menentukan port bebas, saya menggunakan fixture aiomisc_unused_portdari paket aiomisc.Fixture standar aiohttp_unused_portjuga akan baik-baik saja, tetapi mengembalikan fungsi untuk menentukan port bebas, sementara aiomisc_unused_portsegera mengembalikan nomor port. Untuk aplikasi kami, kami hanya perlu menentukan satu port gratis, jadi saya memutuskan untuk tidak menulis baris kode tambahan dengan panggilan aiohttp_unused_port.@pytest.fixture
def arguments(aiomisc_unused_port, migrated_postgres):
return parser.parse_args(
[
'--log-level=debug',
'--api-address=127.0.0.1',
f'--api-port={aiomisc_unused_port}',
f'--pg-url={migrated_postgres}'
]
)
Semua tes dengan penangan menyiratkan permintaan ke REST API; bekerja secara langsung dengan aplikasi aiohttptidak diperlukan. Oleh karena itu, saya membuat satu perlengkapan yang meluncurkan aplikasi dan menggunakan pabrik aiohttp_clientmembuat dan mengembalikan klien uji standar yang terhubung ke aplikasi aiohttp.test_utils.TestClient.from analyzer.api.app import create_app
@pytest.fixture
async def api_client(aiohttp_client, arguments):
app = create_app(arguments)
client = await aiohttp_client(app, server_kwargs={
'port': arguments.api_port
})
try:
yield client
finally:
await client.close()
Sekarang, jika Anda menentukan fixture dalam parameter pengujian api_client, berikut ini akan terjadi:postgres ( migrated_postgres).alembic_config Alembic, ( migrated_postgres).migrated_postgres ( arguments).aiomisc_unused_port ( arguments).arguments ( api_client).api_client .- .
api_client .postgres .
Perlengkapan memungkinkan Anda untuk menghindari duplikasi kode, tetapi selain mempersiapkan lingkungan dalam pengujian, ada tempat potensial lain di mana akan ada banyak kode yang sama - permintaan aplikasi.Pertama, membuat permintaan, kami berharap mendapatkan status HTTP tertentu. Kedua, jika statusnya sesuai dengan yang diharapkan, maka sebelum bekerja dengan data Anda harus memastikan bahwa mereka memiliki format yang benar. Mudah untuk membuat kesalahan di sini dan menulis penangan yang melakukan perhitungan yang benar dan mengembalikan hasil yang benar, tetapi tidak lulus validasi otomatis karena format respons yang salah (misalnya, lupa untuk membungkus jawaban dalam kamus dengan kunci data). Semua cek ini dapat dilakukan di satu tempat.Dalam modulanalyzer.testing Saya telah menyiapkan untuk setiap penangan fungsi pembantu yang memeriksa status HTTP, serta format respons menggunakan Marshmallow.DAPATKAN / impor / $ import_id / warga
Saya memutuskan untuk memulai dengan penangan yang mengembalikan penghuni, karena sangat berguna untuk memeriksa hasil penangan lain yang mengubah keadaan database.Saya sengaja tidak menggunakan kode yang menambahkan data ke database dari handler POST /imports, meskipun tidak sulit untuk membuatnya menjadi fungsi yang terpisah. Kode penangan memiliki properti untuk diubah, dan jika ada kesalahan dalam kode yang menambah database, ada kemungkinan bahwa tes akan berhenti berfungsi sebagaimana dimaksud dan secara implisit bagi pengembang akan berhenti menunjukkan kesalahan.Untuk tes ini, saya mendefinisikan set data tes berikut:- Bongkar dengan beberapa saudara. Memeriksa bahwa untuk setiap penduduk daftar dengan pengidentifikasi kerabat akan dibentuk dengan benar.
- Bongkar dengan satu penduduk tanpa saudara. Memeriksa bahwa bidang tersebut
relativesadalah daftar kosong (karena LEFT JOINkueri SQL, daftar kerabat mungkin sama [None]). - Bongkar dengan seorang residen yang merupakan kerabat dari dirinya sendiri.
- Bongkar kosong. Periksa bahwa pawang memungkinkan untuk menambahkan pembongkaran kosong dan tidak mengalami kesalahan.
Untuk menjalankan tes yang sama secara terpisah pada setiap unggahan, saya menggunakan mekanisme pytest lain yang sangat kuat - parameterisasi . Mekanisme ini memungkinkan Anda untuk membungkus fungsi tes di dekorator pytest.mark.parametrizedan menjelaskan di dalamnya parameter apa yang harus diambil fungsi tes untuk setiap kasus uji individu.Cara membuat parameter suatu tesimport pytest
from analyzer.utils.testing import generate_citizen
datasets = [
[
generate_citizen(citizen_id=1, relatives=[2, 3]),
generate_citizen(citizen_id=2, relatives=[1]),
generate_citizen(citizen_id=3, relatives=[1])
],
[
generate_citizen(relatives=[])
],
[
generate_citizen(citizen_id=1, name='', gender='male',
birth_date='17.02.2020', relatives=[1])
],
[],
]
@pytest.mark.parametrize('dataset', datasets)
async def test_get_citizens(api_client, dataset):
"""
4 ,
"""
Jadi, tes akan menambahkan unggahan ke basis data, kemudian, menggunakan permintaan ke penangan, ia akan menerima informasi tentang penghuni dan membandingkan unggahan referensi dengan yang diterima. Tapi bagaimana Anda membandingkan penduduk?Setiap penduduk terdiri dari bidang skalar dan bidang relatives- daftar pengidentifikasi kerabat. Daftar dengan Python adalah tipe yang diurutkan, dan ketika membandingkan urutan elemen dari setiap daftar tidak masalah, tetapi ketika membandingkan daftar dengan saudara kandung, urutannya tidak menjadi masalah.Jika Anda membawa relativeske set sebelum perbandingan, maka ketika membandingkannya tidak berhasil menemukan situasi di mana salah satu penghuni di lapangan relativesmemiliki duplikat. Jika Anda mengurutkan daftar dengan pengenal kerabat, ini akan menghindari masalah urutan pengidentifikasi kerabat yang berbeda, tetapi pada saat yang sama mendeteksi duplikat.Ketika membandingkan dua daftar dengan penghuni, satu mungkin menghadapi masalah yang sama: secara teknis, urutan penghuni dalam bongkar tidak penting, tetapi penting untuk mendeteksi jika ada dua penghuni dengan pengidentifikasi yang sama dalam satu bongkar dan tidak di yang lain. Jadi, selain mengatur daftar dengan kerabat, kerabat untuk setiap penduduk perlu mengatur penghuni di setiap pembongkaran.Karena tugas membandingkan penduduk akan muncul lebih dari sekali, saya menerapkan dua fungsi: satu untuk membandingkan dua penduduk, dan yang kedua untuk membandingkan dua daftar dengan penduduk:Bandingkan pendudukfrom typing import Iterable, Mapping
def normalize_citizen(citizen):
"""
"""
return {**citizen, 'relatives': sorted(citizen['relatives'])}
def compare_citizens(left: Mapping, right: Mapping) -> bool:
"""
"""
return normalize_citizen(left) == normalize_citizen(right)
def compare_citizen_groups(left: Iterable, right: Iterable) -> bool:
"""
,
"""
left = [normalize_citizen(citizen) for citizen in left]
left.sort(key=lambda citizen: citizen['citizen_id'])
right = [normalize_citizen(citizen) for citizen in right]
right.sort(key=lambda citizen: citizen['citizen_id'])
return left == right
Untuk memastikan bahwa pawang ini tidak mengembalikan penghuni bongkar muat lainnya, saya memutuskan untuk menambahkan bongkar muat tambahan dengan satu penghuni sebelum setiap tes.POST / impor
Saya mendefinisikan kumpulan data berikut untuk menguji penangan:- Data yang benar, diharapkan berhasil ditambahkan ke database.
- ( ).
. , , insert , . - ( , ).
, .
- .
, . :)
, aiohttp PostgreSQL 32 767 ( ).
- Empty unloading
Pawang harus memperhitungkan kasing seperti itu dan tidak jatuh, mencoba melakukan pemasukan kosong ke meja dengan penghuni.
- Data dengan kesalahan, mengharapkan respons HTTP 400: Permintaan Buruk.
- Tanggal lahir salah (future tense).
- citizen_id tidak unik dalam unggahan.
- Hubungan kekerabatan ditunjukkan secara tidak benar (hanya ada dari satu penduduk ke penduduk lainnya, tetapi tidak ada umpan balik).
- Penduduk memiliki kerabat yang tidak ada dalam bongkar muat.
- Ikatan keluarga tidak unik.
Jika prosesor bekerja dengan sukses dan data ditambahkan, Anda perlu membuat penghuni ditambahkan ke database dan membandingkannya dengan pembongkaran standar. Untuk mendapatkan penghuni, saya menggunakan penangan yang sudah diuji GET /imports/$import_id/citizens, dan untuk perbandingan, sebuah fungsi compare_citizen_groups.PATCH / impor / $ import_id / warga negara / $ citizen_id
Validasi data dalam banyak hal mirip dengan yang dijelaskan dalam penangan POST /importsdengan beberapa pengecualian: hanya ada satu penduduk dan klien hanya dapat melewati bidang-bidang yang ia inginkan .Saya memutuskan untuk menggunakan set berikut dengan data yang salah untuk memverifikasi bahwa pawang akan mengembalikan respons HTTP 400: Bad request:- Kolom ditentukan, tetapi memiliki tipe data dan / atau format yang salah
- Tanggal lahir salah (waktu mendatang).
- Kolom
relativesberisi kerabat yang tidak ada di pembongkaran.
Penting juga untuk memverifikasi bahwa pawang memperbarui informasi tentang residen dan kerabatnya dengan benar.Untuk melakukan ini, buat unggahan dengan tiga penduduk, dua di antaranya adalah kerabat, dan kirim permintaan dengan nilai baru untuk semua bidang skalar dan pengenal relatif baru di bidang tersebut relatives.Untuk memastikan bahwa pawang membedakan antara penghuni dengan muatan yang berbeda sebelum ujian (dan, misalnya, tidak mengubah penghuni dengan pengidentifikasi yang sama dari pembongkar yang lain), saya membuat pembongkaran tambahan dengan tiga penghuni yang memiliki pengidentifikasi yang sama.Pawang harus menyimpan nilai-nilai baru dari bidang skalar, menambahkan kerabat yang ditentukan baru dan menghapus hubungan dengan kerabat yang lama, tidak ditentukan. Semua perubahan dalam hubungan keluarga harus bersifat bilateral. Seharusnya tidak ada perubahan dalam pembongkaran lainnya.Karena pawang seperti itu dapat mengalami kondisi balapan (ini dibahas di bagian Pengembangan), saya menambahkan dua tes tambahan . Yang satu mereproduksi masalah dengan kondisi balapan (memperluas kelas penangan dan melepas kunci), yang kedua membuktikan bahwa masalah dengan kondisi balapan tidak direproduksi.DAPATKAN / impor / $ import_id / warga negara / ulang tahun
Untuk menguji penangan ini, saya memilih dataset berikut:- Bongkar di mana seorang penduduk memiliki satu kerabat dalam satu bulan dan dua kerabat di yang lain.
- Bongkar dengan satu penduduk tanpa saudara. Pastikan pawang tidak memperhitungkannya dalam perhitungan.
- Bongkar kosong. Pastikan pawang tidak akan gagal dan akan mengembalikan kamus yang benar dengan 12 bulan sebagai tanggapan.
- Bongkar dengan seorang residen yang merupakan kerabat dari dirinya sendiri. Memeriksa bahwa seorang penduduk akan membeli hadiah untuk bulan kelahirannya.
Pawang harus mengembalikan semua bulan dalam respons, bahkan jika tidak ada ulang tahun pada bulan-bulan ini. Untuk menghindari duplikasi, saya membuat fungsi di mana Anda dapat melewati kamus sehingga melengkapi dengan nilai-nilai untuk bulan yang hilang.Untuk memastikan bahwa pawang membedakan antara penghuni yang berbeda muatan, saya menambahkan pembongkaran tambahan dengan dua saudara. Jika pawang salah menggunakannya dalam perhitungan, hasilnya akan salah dan pawang akan jatuh karena kesalahan.DAPATKAN / impor / $ import_id / kota / stat / persentil / usia
Keunikan dari tes ini adalah bahwa hasil kerjanya tergantung pada waktu saat ini: usia penduduk dihitung berdasarkan tanggal saat ini. Untuk memastikan bahwa hasil tes tidak berubah dari waktu ke waktu, tanggal saat ini, tanggal lahir penduduk dan hasil yang diharapkan harus dicatat. Ini akan membuatnya mudah untuk mereproduksi, bahkan tepi kasus.Apa tanggal perbaikan terbaik? Pawang menggunakan fungsi PostgreSQL untuk menghitung usia penghuni AGE, yang mengambil parameter pertama sebagai tanggal yang diperlukan untuk menghitung usia dan yang kedua sebagai tanggal dasar (ditentukan oleh konstanta TownAgeStatView.CURRENT_DATE).Kami mengganti tanggal dasar dalam handler dengan waktu pengujianfrom unittest.mock import patch
import pytz
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
@patch('analyzer.api.handlers.TownAgeStatView.CURRENT_DATE', new=CURRENT_DATE)
async def test_get_ages(...):
...
Untuk menguji pawang, saya memilih set data berikut (untuk semua penduduk yang saya sebutkan satu kota, karena pawang mengumpulkan hasil berdasarkan kota):- Bongkar dengan beberapa warga yang ulang tahunnya besok (usia - beberapa tahun dan 364 hari). Periksa apakah prosesor hanya menggunakan jumlah tahun penuh dalam perhitungan.
- Bongkar dengan penduduk yang berulang tahun hari ini (umur - tepatnya beberapa tahun). Ini memeriksa kasus regional - usia penduduk yang ulang tahunnya hari ini tidak boleh dihitung sebagai dikurangi dengan 1 tahun.
- Bongkar kosong. Pawang tidak boleh jatuh di atasnya.
numpyPatokan untuk menghitung persentil - dengan interpolasi linier, dan hasil patokan untuk pengujian saya hitung untuk mereka.Anda juga perlu membulatkan nilai persentil pecahan ke dua tempat desimal. Jika Anda menggunakan PostgreSQL untuk pembulatan di handler, dan Python untuk menghitung data referensi, Anda mungkin memperhatikan bahwa pembulatan dalam Python 3 dan PostgreSQL dapat memberikan hasil yang berbeda .contohnya# Python 3
round(2.5)
> 2
-- PostgreSQL
SELECT ROUND(2.5)
> 3
Faktanya adalah bahwa Python menggunakan pembulatan bank ke genap terdekat , dan PostgreSQL menggunakan matematika (setengah-atas). Dalam hal perhitungan dan pembulatan dilakukan dalam PostgreSQL, itu akan benar untuk menggunakan pembulatan matematis dalam tes juga.Pada awalnya saya menggambarkan set data dengan tanggal lahir dalam format teks, tetapi itu tidak nyaman untuk membaca tes dalam format ini: setiap kali saya harus menghitung usia setiap penduduk dalam pikiran saya untuk mengingat apa yang diperiksa oleh set data tertentu. Tentu saja, Anda dapat bertahan dengan komentar dalam kode, tetapi saya memutuskan untuk melangkah lebih jauh dan menulis fungsi age2dateyang memungkinkan Anda untuk menggambarkan tanggal lahir dalam bentuk usia: jumlah tahun dan hari.Misalnya, seperti iniimport pytz
from analyzer.utils.testing import generate_citizen
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
def age2date(years: int, days: int = 0, base_date=CURRENT_DATE) -> str:
birth_date = copy(base_date).replace(year=base_date.year - years)
birth_date -= timedelta(days=days)
return birth_date.strftime(BIRTH_DATE_FORMAT)
generate_citizen(birth_date='17.02.2009')
generate_citizen(birth_date=age2date(years=11))
Untuk memastikan bahwa pawang membedakan antara penghuni yang berbeda muatan, saya menambahkan pembongkaran tambahan dengan satu penduduk dari kota lain: jika pawang salah menggunakannya, sebuah kota tambahan akan muncul dalam hasil dan tes akan pecah.Fakta yang menarik: ketika saya menulis tes ini pada tanggal 29 Februari 2020, saya tiba-tiba berhenti mengeluarkan muatan dengan penduduk karena bug di Faker (2020 adalah tahun kabisat, dan tahun-tahun lain yang Faker pilih tidak selalu kabisat tahun di dalamnya juga bukan 29 Februari). Ingatlah untuk mencatat tanggal dan kasus uji tepi!
Migrasi
Sekilas tentang kode migrasi tampak jelas dan paling tidak rentan kesalahan, mengapa mengujinya? Ini adalah kesalahan yang sangat berbahaya: kesalahan migrasi yang paling berbahaya dapat memanifestasikan diri mereka pada saat yang paling tidak tepat. Bahkan jika mereka tidak merusak data, mereka dapat menyebabkan downtime yang tidak perlu. Migrasi awal yangada di proyek mengubah struktur database, tetapi tidak mengubah data. Kesalahan umum apa yang bisa dilindungi dari migrasi semacam itu?downgrade ( , , ).
, (--): , — .
- C .
- ( ).
Sebagian besar kesalahan ini akan dideteksi oleh tes tangga . Idenya - untuk menggunakan migrasi tunggal, secara konsisten melakukan metode upgrade, downgrade, upgradeuntuk setiap migrasi. Tes semacam itu cukup untuk ditambahkan ke proyek sekali, tidak memerlukan dukungan dan akan melayani dengan setia.Tetapi jika migrasi, selain struktur, akan mengubah data, maka akan perlu untuk menulis setidaknya satu tes terpisah, memeriksa apakah data benar mengubah metode upgradedan kembali ke keadaan awal di downgrade. Untuk jaga-jaga: proyek dengan contoh pengujian migrasi berbeda , yang saya siapkan untuk laporan tentang Alembic di Moscow Python.Majelis
Artefak terakhir yang akan kami gunakan dan yang ingin kami dapatkan sebagai hasil perakitan adalah gambar Docker. Untuk membangun, Anda harus memilih gambar dasar dengan Python. Gambar resmi python:latestberbobot ~ 1 GB dan, jika digunakan sebagai gambar dasar, gambar dengan aplikasi akan sangat besar. Ada gambar berdasarkan OS Alpine , yang ukurannya jauh lebih kecil. Tetapi dengan semakin banyak paket yang diinstal, ukuran gambar akhir akan tumbuh, dan sebagai hasilnya, bahkan gambar yang dikumpulkan berdasarkan Alpine tidak akan begitu kecil. Saya memilih snakepacker / python sebagai gambar dasar - beratnya sedikit lebih banyak daripada gambar Alpine, tetapi didasarkan pada Ubuntu, yang menawarkan banyak pilihan paket dan pustaka.Cara lainkurangi ukuran gambar dengan aplikasi - jangan masukkan dalam gambar akhir kompiler, pustaka dan file dengan header untuk perakitan, yang tidak diperlukan agar aplikasi berfungsi.Untuk melakukan ini, Anda dapat menggunakan perakitan multi-tahap Docker:- Menggunakan gambar "berat"
snakepacker/python:all(~ 1 GB, ~ 500 MB terkompresi), buat lingkungan virtual, instal semua dependensi dan paket aplikasi ke dalamnya. Gambar ini diperlukan khusus untuk perakitan, dapat berisi kompiler, semua perpustakaan yang diperlukan dan file dengan header.
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/*
- Kami menyalin lingkungan virtual yang sudah jadi ke gambar "ringan"
snakepacker/python:3.8(~ 100 MB, terkompresi ~ 50 MB), yang hanya berisi penerjemah dari versi Python yang diperlukan.
Penting: di lingkungan virtual, jalur absolut digunakan, sehingga harus disalin ke alamat yang sama saat dirakit di wadah kolektor.
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
Untuk mengurangi waktu yang dibutuhkan untuk membangun gambar , modul-modul yang bergantung pada aplikasi dapat diinstal sebelum diinstal di lingkungan virtual. Kemudian Docker akan men-cache mereka dan tidak akan menginstal ulang jika belum berubah.Dockerfile sepenuhnya
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
RUN /usr/share/python3/app/bin/pip install -U pip
COPY requirements.txt /mnt/
RUN /usr/share/python3/app/bin/pip install -Ur /mnt/requirements.txt
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/* \
&& /usr/share/python3/app/bin/pip check
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
Untuk kemudahan perakitan, saya menambahkan perintah make uploadyang mengumpulkan gambar Docker dan mengunggahnya ke hub.docker.com.Ci
Sekarang setelah kode dilindungi dengan tes dan kita dapat membuat gambar Docker, saatnya untuk mengotomatiskan proses ini. Hal pertama yang terlintas dalam pikiran: jalankan tes untuk membuat permintaan kumpulan, dan saat menambahkan perubahan ke cabang master, kumpulkan gambar Docker baru dan unggah ke Docker Hub (atau Paket GitHub , jika Anda tidak akan mendistribusikan gambar secara publik).Saya memecahkan masalah ini dengan Tindakan GitHub . Untuk melakukan ini, perlu membuat file YAML di folder .github/workflowsdan menjelaskan di dalamnya alur kerja (dengan dua tugas: testdan publish), yang saya beri nama CI.Tugas testdijalankan setiap kali alur kerja dimulai CI, menggunakan layananmengambil sebuah wadah dengan PostgreSQL, menunggu sampai tersedia, dan diluncurkan pytestdalam wadah snakepacker/python:all.Tugas publishdilakukan hanya jika perubahan telah ditambahkan ke cabang masterdan jika tugas testberhasil. Itu mengumpulkan distribusi sumber oleh wadah snakepacker/python:all, lalu mengumpulkan dan memuat gambar Docker dengan docker/build-push-action@v1.Deskripsi lengkap alur kerjaname: CI
# Workflow
# - master
on:
push:
branches: [ master ]
pull_request:
branches: [ master ]
jobs:
# workflow
test:
runs-on: ubuntu-latest
services:
postgres:
image: docker://postgres
ports:
- 5432:5432
env:
POSTGRES_USER: user
POSTGRES_PASSWORD: hackme
POSTGRES_DB: analyzer
steps:
- uses: actions/checkout@v2
- name: test
uses: docker://snakepacker/python:all
env:
CI_ANALYZER_PG_URL: postgresql://user:hackme@postgres/analyzer
with:
args: /bin/bash -c "pip install -U '.[dev]' && pylama && wait-for-port postgres:5432 && pytest -vv --cov=analyzer --cov-report=term-missing tests"
# Docker-
publish:
# master
if: github.event_name == 'push' && github.ref == 'refs/heads/master'
# , test
needs: test
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: sdist
uses: docker://snakepacker/python:all
with:
args: make sdist
- name: build-push
uses: docker/build-push-action@v1
with:
username: ${{ secrets.REGISTRY_LOGIN }}
password: ${{ secrets.REGISTRY_TOKEN }}
repository: alvassin/backendschool2019
target: api
tags: 0.0.1, latest
Sekarang, saat menambahkan perubahan ke master di tab Tindakan di GitHub, Anda dapat melihat peluncuran tes, perakitan dan pemuatan gambar Docker: Dan saat membuat permintaan kumpulan di cabang master, hasil tugas juga akan ditampilkan di dalamnya
Dan saat membuat permintaan kumpulan di cabang master, hasil tugas juga akan ditampilkan di dalamnya test:
Menyebarkan
Untuk menyebarkan aplikasi pada server yang disediakan, Anda perlu menginstal Docker, Docker Compose, memulai wadah dengan aplikasi dan PostgreSQL dan menerapkan migrasi.Langkah-langkah ini dapat diotomatisasi menggunakan sistem manajemen konfigurasi Ansible. Itu ditulis dalam Python, tidak memerlukan agen khusus (terhubung langsung melalui ssh), menggunakan template jinja dan memungkinkan secara deskriptif menggambarkan keadaan yang diinginkan dalam file YAML. Pendekatan deklaratif memungkinkan Anda untuk tidak memikirkan kondisi sistem saat ini dan tindakan yang diperlukan untuk membawa sistem ke kondisi yang diinginkan. Semua pekerjaan ini berada di pundak modul Ansible.Ansible memungkinkan Anda untuk mengelompokkan tugas-tugas terkait secara logis ke dalam peran dan kemudian menggunakannya kembali. Kami membutuhkan dua peran:docker(menginstal dan mengkonfigurasi Docker) dan analyzer(menginstal dan mengkonfigurasi aplikasi).Perandocker menambahkan repositori dengan Docker ke sistem, menginstal dan mengkonfigurasi paket docker-cedan docker-compose.Secara opsional, Anda dapat mengatur REST API untuk secara otomatis melanjutkan setelah server reboot. Ubuntu memungkinkan Anda untuk menyelesaikan masalah ini dengan bantuan sistem inisialisasi systemd. Ini mengontrol unit yang mewakili berbagai sumber daya (daemon, soket, titik pemasangan, dan lainnya). Untuk menambahkan unit baru ke systemd, Anda harus menjelaskan konfigurasinya dalam file .service yang terpisah dan letakkan file ini di salah satu folder khusus, misalnya, di /etc/systemd/system. Kemudian unit dapat diluncurkan, serta memungkinkan pengisian otomatis untuknya.Paketdocker-ceselama instalasi, itu akan secara otomatis membuat file dengan konfigurasi unit - Anda hanya perlu memastikan bahwa itu berjalan dan menyala ketika sistem dimulai. Untuk Docker Compose docker-compose@.serviceakan dibuat oleh Ansible. Simbol @dalam nama menunjukkan kepada systemd bahwa unit adalah templat. Ini memungkinkan Anda untuk memulai layanan docker-composedengan parameter - misalnya, dengan nama layanan kami, yang akan diganti alih-alih %idalam file konfigurasi unit:[Unit]
Description=%i service with docker compose
Requires=docker.service
After=docker.service
[Service]
Type=oneshot
RemainAfterExit=true
WorkingDirectory=/etc/docker/compose/%i
ExecStart=/usr/local/bin/docker-compose up -d --remove-orphans
ExecStop=/usr/local/bin/docker-compose down
[Install]
WantedBy=multi-user.target
Peran akananalyzer menghasilkan file dari templat docker-compose.ymldi alamat /etc/docker/compose/analyzer, mendaftarkan aplikasi sebagai layanan yang diluncurkan secara otomatis systemddan menerapkan migrasi. Saat peran sudah siap, Anda perlu menggambarkan buku pedoman.---
- name: Gathering facts
hosts: all
become: yes
gather_facts: yes
- name: Install docker
hosts: docker
become: yes
gather_facts: no
roles:
- docker
- name: Install analyzer
hosts: api
become: yes
gather_facts: no
roles:
- analyzer
Daftar host, serta variabel yang digunakan dalam peran, dapat ditentukan dalam file inventaris hosts.ini.[api]
130.193.51.154
[docker:children]
api
[api:vars]
analyzer_image = alvassin/backendschool2019
analyzer_pg_user = user
analyzer_pg_password = hackme
analyzer_pg_dbname = analyzer
Setelah semua file Ansible siap, jalankan:$ ansible-playbook -i hosts.ini deploy.yml
Tentang pengujian stres, , . , -
. : , — , 10 . , (, , CI-): .
, , , 10 . ? , , . , , .
RPS, : . , ,
import_id,
POST /imports . .
, Python 3,
Locust.
,
locustfile.py locust. - .
Locust . , .
self.round .
locustfile.py
import logging
from http import HTTPStatus
from locust import HttpLocust, constant, task, TaskSet
from locust.exception import RescheduleTask
from analyzer.api.handlers import (
CitizenBirthdaysView, CitizensView, CitizenView, TownAgeStatView
)
from analyzer.utils.testing import generate_citizen, generate_citizens, url_for
class AnalyzerTaskSet(TaskSet):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.round = 0
def make_dataset(self):
citizens = [
generate_citizen(citizen_id=1, relatives=[2]),
generate_citizen(citizen_id=2, relatives=[1]),
*generate_citizens(citizens_num=9998, relations_num=1000,
start_citizen_id=3)
]
return {citizen['citizen_id']: citizen for citizen in citizens}
def request(self, method, path, expected_status, **kwargs):
with self.client.request(
method, path, catch_response=True, **kwargs
) as resp:
if resp.status_code != expected_status:
resp.failure(f'expected status {expected_status}, '
f'got {resp.status_code}')
logging.info(
'round %r: %s %s, http status %d (expected %d), took %rs',
self.round, method, path, resp.status_code, expected_status,
resp.elapsed.total_seconds()
)
return resp
def create_import(self, dataset):
resp = self.request('POST', '/imports', HTTPStatus.CREATED,
json={'citizens': list(dataset.values())})
if resp.status_code != HTTPStatus.CREATED:
raise RescheduleTask
return resp.json()['data']['import_id']
def get_citizens(self, import_id):
url = url_for(CitizensView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens')
def update_citizen(self, import_id):
url = url_for(CitizenView.URL_PATH, import_id=import_id, citizen_id=1)
self.request('PATCH', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/{citizen_id}',
json={'relatives': [i for i in range(3, 10)]})
def get_birthdays(self, import_id):
url = url_for(CitizenBirthdaysView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/birthdays')
def get_town_stats(self, import_id):
url = url_for(TownAgeStatView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/towns/stat/percentile/age')
@task
def workflow(self):
self.round += 1
dataset = self.make_dataset()
import_id = self.create_import(dataset)
self.get_citizens(import_id)
self.update_citizen(import_id)
self.get_birthdays(import_id)
self.get_town_stats(import_id)
class WebsiteUser(HttpLocust):
task_set = AnalyzerTaskSet
wait_time = constant(1)
100 c , , :

, ( — 95 , — ). .

— Ansible ~20.15 ~20.30 Locust.

Apa lagi yang bisa dilakukan?
Profiling aplikasi menunjukkan bahwa sekitar seperempat dari total waktu eksekusi permintaan dihabiskan untuk serialisasi dan deserializing JSON: ada banyak data yang dikirim dan diterima dari layanan. Proses-proses ini dapat dipercepat secara signifikan menggunakan pustaka orjson , tetapi layanan harus dipersiapkan sedikit - orjsonini bukan pengganti drop-in untuk modul standar. jsonBiasanya, produksi memerlukan beberapa salinan layanan untuk memastikan toleransi kesalahan dan mengatasi beban. Untuk mengelola sekelompok layanan, Anda memerlukan alat yang menunjukkan apakah salinan layanan itu "hidup". Masalah ini dapat diselesaikan oleh seorang pawang /healthyang melakukan polling semua sumber daya yang dibutuhkan untuk bekerja, dalam kasus kami, sebuah database. JikaSELECT 1dieksekusi dalam waktu kurang dari satu detik, maka layanannya hidup. Jika tidak, Anda harus memperhatikannya.Ketika aplikasi bekerja sangat intensif dengan jaringan, uvloop dapat dengan keren meningkatkan kinerja.Faktor penting adalah keterbacaan kode. Salah satu kolega saya, Yuri Shikanov, menulis modul abu - abu yang menggabungkan beberapa alat untuk verifikasi otomatis dan desain kode, yang mudah ditambahkan ke pre-commitkait Git, dibuat dengan file konfigurasi tunggal atau variabel lingkungan. Gray memungkinkan Anda untuk mengurutkan impor ( isort ), mengoptimalkan ekspresi python sesuai dengan versi bahasa yang baru ( pyupgrade ), menambahkan koma di akhir pemanggilan fungsi, impor, daftar, dll. (add-trailing-koma ), dan juga mengutip ke satu bentuk ( menyatukan ).* * *
Itu saja untuk saya: kami mengembangkan, ditutupi dengan tes, mengumpulkan dan menggunakan layanan, dan juga melakukan pengujian beban.Ucapan Terima Kasih
Saya ingin mengucapkan terima kasih yang mendalam kepada orang-orang yang meluangkan waktu untuk mengambil bagian dalam menulis artikel ini, untuk meninjau kode, untuk memperkenalkan ide dan komentar saya: kepada Maria Zelenova zelma, Vladimir Solomatin Leenr, Anastasia Semenova morkov, Yuri Shikanov dizballanze, Mikhail Shushpanov mishush, Pavel Mosein pavkazzz dan terutama ke Dmitry Orlov orlovdl.