 Efek dari tabel dan indeks kembung (bloat) sudah dikenal luas dan tidak hanya ada di Postgres. Ada cara untuk menghadapinya "out of the box" seperti VACUUM FULL atau CLUSTER, tetapi mereka memblokir tabel selama operasi dan karenanya tidak selalu dapat digunakan.Artikel ini akan memiliki sedikit teori tentang bagaimana mengasapi terjadi, bagaimana menghadapinya, tentang kendala yang ditangguhkan, dan tentang masalah yang mereka bawa ke penggunaan ekstensi pg_repack.Artikel ini didasarkan pada presentasi saya di PgConf.Russia 2020.
Efek dari tabel dan indeks kembung (bloat) sudah dikenal luas dan tidak hanya ada di Postgres. Ada cara untuk menghadapinya "out of the box" seperti VACUUM FULL atau CLUSTER, tetapi mereka memblokir tabel selama operasi dan karenanya tidak selalu dapat digunakan.Artikel ini akan memiliki sedikit teori tentang bagaimana mengasapi terjadi, bagaimana menghadapinya, tentang kendala yang ditangguhkan, dan tentang masalah yang mereka bawa ke penggunaan ekstensi pg_repack.Artikel ini didasarkan pada presentasi saya di PgConf.Russia 2020.Mengapa kembung terjadi
Postgres didasarkan pada model multi-versi ( MVCC ). Esensinya adalah bahwa setiap baris dalam tabel dapat memiliki beberapa versi, sementara transaksi tidak lebih dari satu versi ini, tetapi tidak harus sama. Ini memungkinkan beberapa transaksi untuk bekerja secara bersamaan dan hampir tidak memiliki pengaruh satu sama lain.Jelas, semua versi ini perlu disimpan. Postgres bekerja dengan halaman memori per halaman dan halaman adalah jumlah minimum data yang dapat dibaca dari disk atau tertulis. Mari kita lihat contoh kecil untuk memahami bagaimana ini terjadi.Misalkan kita memiliki tabel di mana kita telah menambahkan beberapa catatan. Di halaman pertama file tempat tabel disimpan, data baru telah muncul. Ini adalah versi live string yang tersedia untuk transaksi lain setelah komit (untuk kesederhanaan, kami akan menganggap bahwa tingkat isolasi yang dilakukan Read Read).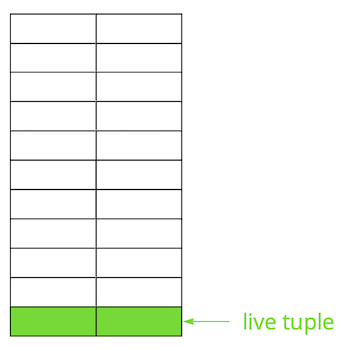 Kemudian kami memperbarui salah satu entri dan dengan demikian menandai versi lama sebagai tidak relevan.
Kemudian kami memperbarui salah satu entri dan dengan demikian menandai versi lama sebagai tidak relevan.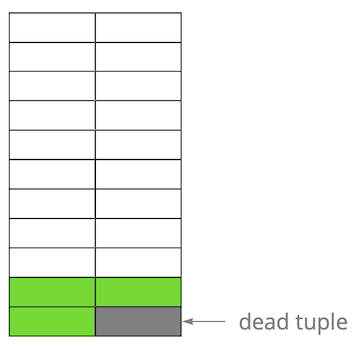 Langkah demi langkah, memperbarui dan menghapus versi baris, kami mendapat halaman di mana sekitar setengah dari data adalah "sampah". Data ini tidak terlihat oleh transaksi apa pun.
Langkah demi langkah, memperbarui dan menghapus versi baris, kami mendapat halaman di mana sekitar setengah dari data adalah "sampah". Data ini tidak terlihat oleh transaksi apa pun.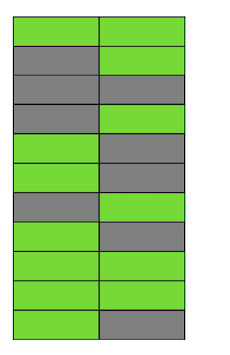 Postgres memiliki mekanisme VACUUM, yang membersihkan versi yang tidak relevan dan membebaskan ruang untuk data baru. Tetapi jika tidak cukup dikonfigurasi secara agresif atau sibuk bekerja di tabel lain, maka "data sampah" tetap ada, dan kita harus menggunakan halaman tambahan untuk data baru.Jadi dalam contoh kita, pada suatu titik waktu, tabel akan terdiri dari empat halaman, tetapi hanya akan ada setengah data langsung di dalamnya. Akibatnya, saat mengakses tabel, kita akan membaca lebih banyak data daripada yang diperlukan.
Postgres memiliki mekanisme VACUUM, yang membersihkan versi yang tidak relevan dan membebaskan ruang untuk data baru. Tetapi jika tidak cukup dikonfigurasi secara agresif atau sibuk bekerja di tabel lain, maka "data sampah" tetap ada, dan kita harus menggunakan halaman tambahan untuk data baru.Jadi dalam contoh kita, pada suatu titik waktu, tabel akan terdiri dari empat halaman, tetapi hanya akan ada setengah data langsung di dalamnya. Akibatnya, saat mengakses tabel, kita akan membaca lebih banyak data daripada yang diperlukan.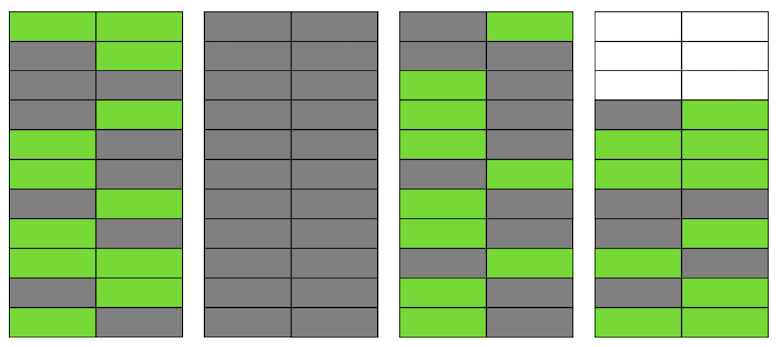 Bahkan jika VACUUM sekarang menghapus semua versi string yang tidak relevan, situasinya tidak akan membaik secara dramatis. Kami akan memiliki ruang kosong di halaman atau bahkan seluruh halaman untuk baris baru, tetapi kami akan terus membaca lebih banyak data daripada yang diperlukan.Omong-omong, jika halaman yang benar-benar kosong (yang kedua dalam contoh kita) berada di akhir file, maka VACUUM dapat memangkasnya. Tapi sekarang dia ada di tengah, jadi tidak ada yang bisa dilakukan dengannya.
Bahkan jika VACUUM sekarang menghapus semua versi string yang tidak relevan, situasinya tidak akan membaik secara dramatis. Kami akan memiliki ruang kosong di halaman atau bahkan seluruh halaman untuk baris baru, tetapi kami akan terus membaca lebih banyak data daripada yang diperlukan.Omong-omong, jika halaman yang benar-benar kosong (yang kedua dalam contoh kita) berada di akhir file, maka VACUUM dapat memangkasnya. Tapi sekarang dia ada di tengah, jadi tidak ada yang bisa dilakukan dengannya.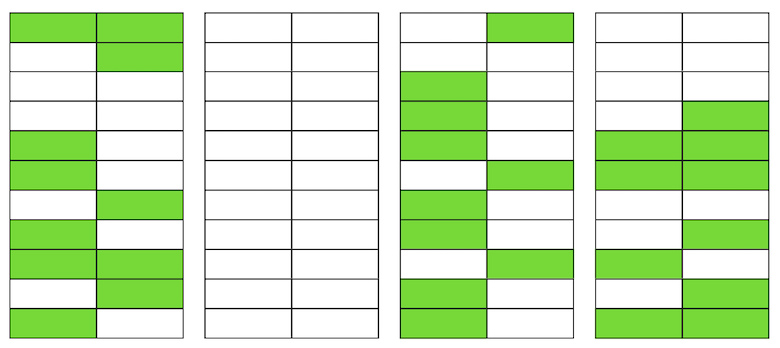 Ketika jumlah halaman kosong atau sangat datar tersebut menjadi besar, yang disebut mengasapi, itu mulai mempengaruhi kinerja.Segala sesuatu yang dijelaskan di atas adalah mekanisme terjadinya mengasapi dalam tabel. Dalam indeks, ini terjadi dengan cara yang hampir sama.
Ketika jumlah halaman kosong atau sangat datar tersebut menjadi besar, yang disebut mengasapi, itu mulai mempengaruhi kinerja.Segala sesuatu yang dijelaskan di atas adalah mekanisme terjadinya mengasapi dalam tabel. Dalam indeks, ini terjadi dengan cara yang hampir sama.Apakah saya mengalami gembung?
Ada beberapa cara untuk menentukan apakah Anda kembung. Gagasan pertama adalah menggunakan statistik Postgres internal, yang berisi informasi perkiraan tentang jumlah baris dalam tabel, jumlah baris "langsung", dll. Di Internet, Anda dapat menemukan banyak variasi skrip yang sudah jadi. Kami mengambil sebagai dasar naskah dari PostgreSQL Pakar, yang dapat mengevaluasi tabel mengasapi bersama dengan roti bakar dan indeks btree mengasapi. Dalam pengalaman kami, kesalahannya adalah 10-20%.Cara lain adalah dengan menggunakan ekstensi pgstattuple , yang memungkinkan Anda untuk melihat ke dalam halaman dan mendapatkan nilai mengasapi yang diperkirakan dan akurat. Tetapi dalam kasus kedua, Anda harus memindai seluruh tabel.Nilai mengasapi kecil, hingga 20%, kami anggap dapat diterima. Ini dapat dianggap sebagai analog dari fillfactor untuk tabel dan indeks . Pada 50% ke atas, masalah kinerja dapat dimulai.Cara mengatasi kembung
Ada beberapa cara untuk mengatasi mengasapi kotak di Postgres, tetapi mereka jauh dari selalu cocok untuk semua orang.Atur AUTOVACUUM agar mengasapi tidak terjadi . Dan lebih tepatnya, untuk mempertahankannya pada tingkat yang dapat diterima untuk Anda. Ini tampaknya menjadi saran "kapten", tetapi dalam kenyataannya ini tidak selalu mudah dicapai. Misalnya, Anda secara aktif mengembangkan dengan perubahan reguler pada skema data atau semacam migrasi data yang terjadi. Akibatnya, profil pemuatan Anda dapat sering berubah dan, biasanya, dapat berbeda untuk tabel yang berbeda. Ini berarti bahwa Anda harus terus bekerja sedikit di depan kurva dan menyesuaikan AUTOVACUUM dengan perubahan profil setiap tabel. Tetapi jelas bahwa ini tidak mudah.Alasan umum lainnya bahwa AUTOVACUUM tidak punya waktu untuk memproses tabel adalah adanya transaksi yang panjang yang mencegahnya dari kliring data karena fakta bahwa itu tersedia untuk transaksi ini. Rekomendasi di sini juga jelas - singkirkan transaksi yang menggantung dan meminimalkan waktu transaksi aktif. Tetapi jika beban pada aplikasi Anda adalah hibrida dari OLAP dan OLTP, maka pada saat yang sama Anda dapat memiliki banyak pembaruan dan permintaan singkat, serta operasi yang panjang - misalnya, membuat laporan. Dalam situasi seperti itu, ada baiknya memikirkan untuk menyebarkan beban ke pangkalan yang berbeda, yang akan memungkinkan penyetelan yang lebih baik dari masing-masing.Contoh lain - bahkan jika profilnya seragam, tetapi basis datanya berada di bawah beban yang sangat tinggi, bahkan AUTOVACUUM yang paling agresif pun tidak dapat mengatasinya, dan akan terjadi bloat. Penskalaan (vertikal atau horizontal) adalah satu-satunya solusi.Tapi bagaimana dengan situasi ketika Anda mengkonfigurasi AUTOVACUUM, tetapi mengasapi terus tumbuh. VACUUM FULLCommandmembangun kembali isi tabel dan indeks dan hanya menyisakan data yang relevan di dalamnya. Untuk menghilangkan mengasapi, ia bekerja dengan sempurna, tetapi selama eksekusi, kunci eksklusif di atas meja (AccessExclusiveLock) ditangkap, yang tidak akan mengizinkan kueri ke tabel ini, bahkan memilih. Jika Anda mampu menghentikan layanan Anda atau bagian dari itu untuk sementara waktu (dari puluhan menit hingga beberapa jam, tergantung pada ukuran database dan perangkat keras Anda), maka opsi ini adalah yang terbaik. Sayangnya, kami tidak punya waktu untuk menjalankan VACUUM FULL selama pemeliharaan terjadwal, jadi metode ini tidak cocok untuk kami.Perintah CLUSTERitu juga membangun kembali isi tabel, seperti halnya VACUUM FULL, pada saat yang sama memungkinkan Anda untuk menentukan indeks yang menurutnya data akan dipesan secara fisik pada disk (tetapi di masa depan pesanan tidak dijamin). Dalam situasi tertentu, ini adalah optimasi yang baik untuk sejumlah pertanyaan - dengan membaca beberapa catatan berdasarkan indeks. Kerugian dari perintah ini sama dengan VACUUM FULL - itu mengunci tabel selama operasi.Perintah REINDEX mirip dengan dua sebelumnya, tetapi membangun kembali indeks tertentu atau semua indeks di atas meja. Kunci sedikit lebih lemah: ShareLock di atas meja (mencegah modifikasi, tetapi memungkinkan Anda untuk memilih) dan AccessExclusiveLock pada indeks yang dapat disetel (memblokir permintaan menggunakan indeks ini). Namun, dalam versi 12 Postgres, parameter CONCURRENTLY, yang memungkinkan Anda membangun kembali indeks tanpa memblokir penambahan, modifikasi, atau penghapusan catatan secara paralel.Dalam versi Postgres sebelumnya, Anda dapat mencapai hasil yang mirip dengan REINDEX CONCURRENTLY dengan CREATE INDEX CONCURRENTLY . Ini memungkinkan Anda untuk membuat indeks tanpa pemblokiran ketat (ShareUpdateExclusiveLock, yang tidak mengganggu kueri paralel), lalu mengganti indeks lama dengan yang baru dan menghapus indeks yang lama. Ini menghilangkan indeks kembung tanpa mengganggu aplikasi Anda. Penting untuk mempertimbangkan bahwa ketika membangun kembali indeks akan ada beban tambahan pada subsistem disk.Jadi, jika ada cara bagi indeks untuk menghilangkan bloat "panas", maka untuk tabel tidak ada. Di sini berbagai ekstensi eksternal ikut berperan : pg_repack(sebelumnya pg_reorg), pgcompact , pgcompacttable , dan lainnya. Dalam kerangka artikel ini, saya tidak akan membandingkannya dan hanya akan berbicara tentang pg_repack, yang, setelah beberapa perbaikan, kami gunakan di rumah.Cara kerja pg_repack
Misalkan kita memiliki tabel yang sangat normal untuk diri kita sendiri - dengan indeks, batasan, dan, sayangnya, dengan mengasapi. Langkah pertama adalah pg_repack membuat tabel log untuk menyimpan data tentang semua perubahan selama operasi. Pemicu akan mereplikasi perubahan ini untuk setiap memasukkan, memperbarui, dan menghapus. Kemudian dibuat tabel yang mirip dengan aslinya dalam struktur, tetapi tanpa indeks dan batasan, agar tidak memperlambat proses memasukkan data.Selanjutnya, pg_repack mentransfer data dari yang lama ke tabel baru, secara otomatis memfilter semua baris yang tidak relevan, dan kemudian membuat indeks untuk tabel baru. Selama pelaksanaan semua operasi ini, perubahan diakumulasikan dalam tabel log.Langkah selanjutnya adalah mentransfer perubahan ke tabel baru. Migrasi dilakukan dalam beberapa iterasi, dan ketika kurang dari 20 entri tetap dalam tabel log, pg_repack menangkap kunci ketat, mentransfer data terbaru dan mengganti tabel lama dengan yang baru di tabel sistem Postgres. Ini adalah satu-satunya titik waktu yang sangat singkat ketika Anda tidak dapat bekerja dengan tabel. Setelah itu, tabel lama dan tabel dengan log dihapus dan ruang dibebaskan di sistem file. Proses selesai.Secara teori, semuanya tampak hebat, apa yang dipraktikkan? Kami menguji pg_repack tanpa memuat dan di bawah beban, kami memeriksa operasinya jika terjadi penghentian prematur (dengan kata lain, Ctrl + C). Semua tes positif.Kami pergi ke prod - dan kemudian semuanya berjalan salah seperti yang kami harapkan.Pancake pertama pada prod
Pada kluster pertama, kami menerima kesalahan tentang melanggar batasan unik:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Pembatasan ini memiliki nama yang dihasilkan secara otomatis index_16508 - itu dibuat oleh pg_repack. Dengan atribut yang termasuk dalam komposisinya, kami menentukan batasan "kami", yang sesuai dengannya. Masalahnya ternyata bukan pembatasan biasa, tetapi kendala yang ditangguhkan , mis. verifikasi dilakukan lebih lambat dari perintah sql, yang mengarah pada konsekuensi yang tidak terduga.Kendala yang ditangguhkan: mengapa mereka dibutuhkan dan bagaimana cara kerjanya
Sedikit teori tentang kendala yang ditangguhkan.Pertimbangkan contoh sederhana: kami memiliki tabel referensi mobil dengan dua atribut - nama dan urutan mobil di direktori.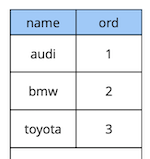
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique
);
Katakanlah kita perlu menukar mobil pertama dan kedua. Solusi "di dahi" adalah memperbarui nilai pertama ke yang kedua, dan yang kedua ke yang pertama:begin;
update cars set ord = 2 where name = 'audi';
update cars set ord = 1 where name = 'bmw';
commit;
Tetapi ketika mengeksekusi kode ini, kami diharapkan mendapatkan pelanggaran batasan, karena urutan nilai dalam tabel adalah unik:[23305] ERROR: duplicate key value violates unique constraint “uk_cars”
Detail: Key (ord)=(2) already exists.
Bagaimana cara melakukannya secara berbeda? Opsi satu: tambahkan pengganti nilai tambahan dengan pesanan yang dijamin tidak ada dalam tabel, misalnya, "-1". Dalam pemrograman, ini disebut "bertukar nilai dua variabel melalui yang ketiga." Satu-satunya kelemahan dari metode ini adalah pembaruan tambahan.Opsi dua: mendesain ulang tabel untuk menggunakan tipe data titik-mengambang untuk nilai pesanan, bukan bilangan bulat. Kemudian, ketika memperbarui nilai dari 1, misalnya, ke 2.5, catatan pertama akan secara otomatis "berdiri" antara yang kedua dan ketiga. Solusi ini berfungsi, tetapi ada dua batasan. Pertama, itu tidak akan bekerja untuk Anda jika nilainya digunakan di suatu tempat di antarmuka. Kedua, tergantung pada keakuratan tipe data, Anda akan memiliki jumlah kemungkinan insert yang terbatas sebelum menghitung ulang nilai semua record.Opsi tiga: buat pembatasan ditangguhkan sehingga diperiksa hanya pada saat komit:create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique deferrable initially deferred
);
Karena logika permintaan awal kami memastikan bahwa semua nilai unik pada saat komit, itu akan berhasil.Contoh di atas, tentu saja, sangat sintetis, tetapi ia mengungkapkan idenya. Dalam aplikasi kami, kami menggunakan batasan yang ditangguhkan untuk mengimplementasikan logika yang bertanggung jawab untuk menyelesaikan konflik sambil bekerja secara bersamaan dengan objek widget umum di papan tulis. Menggunakan batasan semacam itu memungkinkan kita membuat kode aplikasi sedikit lebih mudah.Secara umum, tergantung pada jenis kendala di Postgres, ada tiga tingkat rincian untuk memeriksanya: tingkat baris, transaksi, dan ekspresi.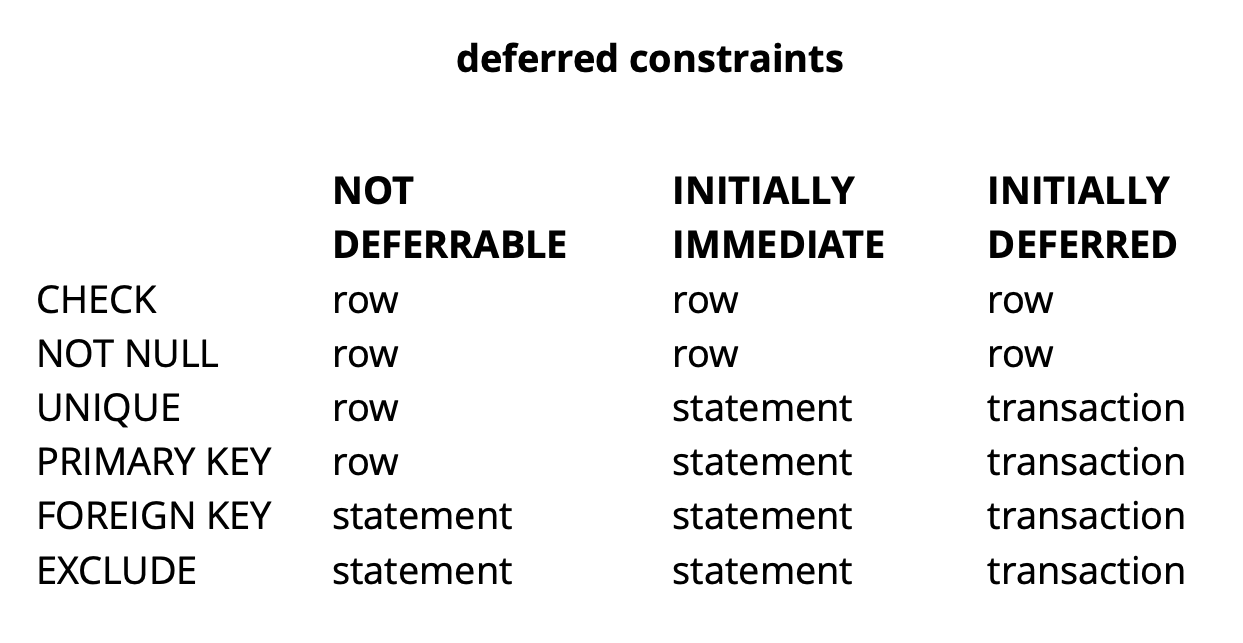 Sumber: pengemisPERIKSA dan BUKAN NULL selalu dicentang di tingkat baris, untuk pembatasan lain, seperti dapat dilihat dari tabel, ada opsi yang berbeda. Baca lebih lanjut di sini .Untuk meringkas secara singkat, pembatasan yang tertunda dalam beberapa situasi memberikan kode lebih mudah dibaca dan lebih sedikit perintah. Namun, Anda harus membayar untuk ini dengan mempersulit proses debug, sejak saat kesalahan terjadi dan saat Anda mengetahuinya dipisahkan dalam waktu. Masalah lain yang mungkin adalah bahwa penjadwal tidak selalu dapat membangun rencana optimal jika kendala tertunda terlibat dalam permintaan.
Sumber: pengemisPERIKSA dan BUKAN NULL selalu dicentang di tingkat baris, untuk pembatasan lain, seperti dapat dilihat dari tabel, ada opsi yang berbeda. Baca lebih lanjut di sini .Untuk meringkas secara singkat, pembatasan yang tertunda dalam beberapa situasi memberikan kode lebih mudah dibaca dan lebih sedikit perintah. Namun, Anda harus membayar untuk ini dengan mempersulit proses debug, sejak saat kesalahan terjadi dan saat Anda mengetahuinya dipisahkan dalam waktu. Masalah lain yang mungkin adalah bahwa penjadwal tidak selalu dapat membangun rencana optimal jika kendala tertunda terlibat dalam permintaan.Perbaikan pg_repack
Kami telah menemukan batasan yang tertunda, tetapi bagaimana kaitannya dengan masalah kami? Ingat kesalahan yang sebelumnya kami terima:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Itu terjadi pada saat menyalin data dari tabel log ke tabel baru. Terlihat aneh karena data dalam tabel log dilakukan bersama dengan data dalam tabel asli. Jika mereka memenuhi batasan dari tabel asli, lalu bagaimana mereka bisa melanggar batasan yang sama di yang baru?Ternyata, akar masalahnya terletak pada langkah sebelumnya dari pg_repack, di mana hanya indeks yang dibuat, tetapi bukan batasan: tabel lama memiliki kendala unik, dan yang baru malah membuat indeks unik. Penting untuk dicatat di sini bahwa jika batasannya normal dan tidak ditangguhkan, maka indeks unik yang dibuat bukan setara dengan pembatasan ini, karena Kendala unik Postgres diimplementasikan dengan membuat indeks unik. Tetapi dalam kasus kendala yang ditangguhkan, perilaku tidak sama, karena indeks tidak dapat ditangguhkan dan selalu diperiksa pada saat perintah sql dieksekusi.Dengan demikian, inti dari masalahnya terletak pada "penundaan" dari cek: pada tabel asli itu terjadi pada saat komit, dan pada yang baru - pada saat pelaksanaan perintah sql. Jadi kita perlu memastikan bahwa pemeriksaan dilakukan dengan cara yang sama dalam kedua kasus: selalu ditunda, atau selalu segera.Jadi ide apa yang kita miliki?
Penting untuk dicatat di sini bahwa jika batasannya normal dan tidak ditangguhkan, maka indeks unik yang dibuat bukan setara dengan pembatasan ini, karena Kendala unik Postgres diimplementasikan dengan membuat indeks unik. Tetapi dalam kasus kendala yang ditangguhkan, perilaku tidak sama, karena indeks tidak dapat ditangguhkan dan selalu diperiksa pada saat perintah sql dieksekusi.Dengan demikian, inti dari masalahnya terletak pada "penundaan" dari cek: pada tabel asli itu terjadi pada saat komit, dan pada yang baru - pada saat pelaksanaan perintah sql. Jadi kita perlu memastikan bahwa pemeriksaan dilakukan dengan cara yang sama dalam kedua kasus: selalu ditunda, atau selalu segera.Jadi ide apa yang kita miliki?Buat indeks yang mirip dengan ditangguhkan
Gagasan pertama adalah melakukan kedua pemeriksaan dalam mode langsung. Hal ini dapat menimbulkan beberapa pemicu positif palsu dari pembatasan, tetapi jika ada beberapa di antaranya, maka ini seharusnya tidak mempengaruhi pekerjaan pengguna, karena konflik seperti itu normal bagi mereka. Mereka terjadi, misalnya, ketika dua pengguna mulai secara bersamaan mengedit widget yang sama, dan klien pengguna kedua tidak punya waktu untuk mendapatkan informasi bahwa widget sudah dikunci untuk diedit oleh pengguna pertama. Dalam situasi ini, server menolak pengguna kedua, dan kliennya memutar kembali perubahan dan memblokir widget. Beberapa saat kemudian, ketika pengguna pertama selesai mengedit, yang kedua akan menerima informasi bahwa widget tidak lagi terkunci, dan akan dapat mengulangi tindakannya.Untuk memastikan bahwa pemeriksaan selalu dalam mode darurat, kami membuat indeks baru yang mirip dengan batasan tangguhan asli:CREATE UNIQUE INDEX CONCURRENTLY uk_tablename__immediate ON tablename (id, index);
DROP INDEX CONCURRENTLY uk_tablename__immediate;
Di lingkungan pengujian, kami hanya menerima beberapa kesalahan yang diharapkan. Keberhasilan! Kami kembali meluncurkan pg_repack pada prod dan mendapat 5 kesalahan pada cluster pertama dalam satu jam kerja. Ini adalah hasil yang dapat diterima. Namun, sudah di cluster kedua, jumlah kesalahan meningkat berkali-kali dan kami harus menghentikan pg_repack.Kenapa ini terjadi? Probabilitas kesalahan tergantung pada berapa banyak pengguna yang bekerja secara bersamaan dengan widget yang sama. Rupanya, pada saat itu dengan data yang disimpan di cluster pertama, ada perubahan kompetitif yang jauh lebih sedikit daripada yang lain, yaitu kami hanya "beruntung."Gagasan itu tidak berhasil. Pada saat itu, kami melihat dua opsi solusi lain: menulis ulang kode aplikasi kami untuk mengabaikan batasan yang tertunda, atau "mengajar" pg_repack untuk bekerja dengannya. Kami telah memilih yang kedua.Ganti indeks di tabel baru dengan batasan yang ditangguhkan dari tabel sumber
Tujuan revisi jelas - jika tabel asli memiliki batasan yang ditangguhkan, maka untuk yang baru Anda perlu membuat batasan seperti itu, bukan indeks.Untuk menguji perubahan kami, kami menulis tes sederhana:- tabel dengan pembatasan yang ditangguhkan dan satu catatan;
- masukkan data dalam loop yang bertentangan dengan catatan yang ada;
- melakukan pembaruan - data tidak lagi konflik;
- komit perubahan.
create table test_table
(
id serial,
val int,
constraint uk_test_table__val unique (val) deferrable initially deferred
);
INSERT INTO test_table (val) VALUES (0);
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (0) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
Versi asli pg_repack selalu macet di sisipan pertama, versi revisi berfungsi tanpa kesalahan. Baik.Kami pergi ke prod dan sekali lagi kami mendapatkan kesalahan dalam fase yang sama menyalin data dari tabel log ke yang baru:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Situasi klasik: semuanya berfungsi pada lingkungan pengujian, tetapi tidak pada prod ?!APPLY_COUNT dan sambungan dua bets
Kami mulai menganalisis kode secara harfiah baris demi baris dan menemukan poin penting: data ditransfer dari tabel log ke yang baru dengan batch, konstanta APPLY_COUNT menunjukkan ukuran batch:for (;;)
{
num = apply_log(connection, table, APPLY_COUNT);
if (num > MIN_TUPLES_BEFORE_SWITCH)
continue;
...
}
Masalahnya adalah bahwa data transaksi asli, di mana beberapa operasi berpotensi melanggar pembatasan, dapat ditransfer ke gabungan dua batch selama transfer - setengah dari tim akan berkomitmen dalam pertandingan pertama dan setengah lainnya di yang kedua. Dan inilah betapa beruntungnya: jika tim dalam kelompok pertama tidak melanggar apa pun, maka semuanya baik-baik saja, tetapi jika mereka melanggar - kesalahan terjadi.APPLY_COUNT sama dengan 1000 entri, yang menjelaskan mengapa pengujian kami berhasil - tidak mencakup kasus "persimpangan batch". Kami menggunakan dua perintah - masukkan dan perbarui, jadi 500 transaksi dari dua tim selalu ditempatkan dalam batch dan kami tidak mengalami masalah. Setelah menambahkan pembaruan kedua, hasil edit kami berhenti bekerja:FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (1) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
Jadi, tugas selanjutnya adalah memastikan bahwa data dari tabel sumber yang berubah dalam satu transaksi termasuk dalam tabel baru juga dalam transaksi yang sama.Penolakan Butching
Dan lagi kami punya dua solusi. Pertama: mari kita sepenuhnya meninggalkan batching dan melakukan transfer data dalam satu transaksi. Yang mendukung solusi ini adalah kesederhanaannya - perubahan kode yang diperlukan minimal (omong-omong, dalam versi yang lebih lama maka pg_reorg bekerja seperti itu). Tapi ada masalah - kami membuat transaksi panjang, dan ini, seperti yang dikatakan sebelumnya, merupakan ancaman bagi munculnya bloat baru.Solusi kedua lebih rumit, tetapi mungkin lebih benar: buat kolom di tabel log dengan pengidentifikasi transaksi yang menambahkan data ke tabel. Kemudian, saat menyalin data, kami akan dapat mengelompokkannya berdasarkan atribut ini dan memastikan bahwa perubahan terkait akan ditransfer bersama. Kumpulan akan dibentuk dari beberapa transaksi (atau satu yang besar) dan ukurannya akan bervariasi tergantung pada seberapa banyak data telah berubah dalam transaksi ini. Penting untuk dicatat bahwa karena data transaksi yang berbeda jatuh ke dalam tabel log dalam urutan acak, itu tidak akan mungkin untuk membacanya secara berurutan, seperti sebelumnya. seqscan untuk setiap permintaan yang difilter oleh tx_id terlalu mahal, Anda memerlukan indeks, tetapi itu akan memperlambat metode karena overhead memperbaruinya. Secara umum, seperti biasa, Anda perlu mengorbankan sesuatu.Jadi, kami memutuskan untuk memulai dengan opsi pertama, sebagai opsi yang lebih sederhana. Pertama, perlu dipahami apakah transaksi lama akan menjadi masalah nyata. Karena transfer data utama dari tabel lama ke yang baru juga terjadi dalam satu transaksi panjang, pertanyaannya telah berubah menjadi "berapa banyak kita akan meningkatkan transaksi ini?" Durasi transaksi pertama tergantung terutama pada ukuran tabel. Durasi yang baru tergantung pada berapa banyak perubahan yang terakumulasi dalam tabel selama transfer data, mis. dari intensitas beban. Run pg_repack terjadi selama beban minimum pada layanan, dan jumlah perubahannya sangat kecil dibandingkan dengan ukuran tabel asli. Kami memutuskan bahwa kami dapat mengabaikan waktu transaksi baru (sebagai perbandingan, ini adalah rata-rata 1 jam dan 2-3 menit).Eksperimennya positif. Berjalan di prod juga. Untuk kejelasan, gambar dengan ukuran salah satu pangkalan setelah dijalankan: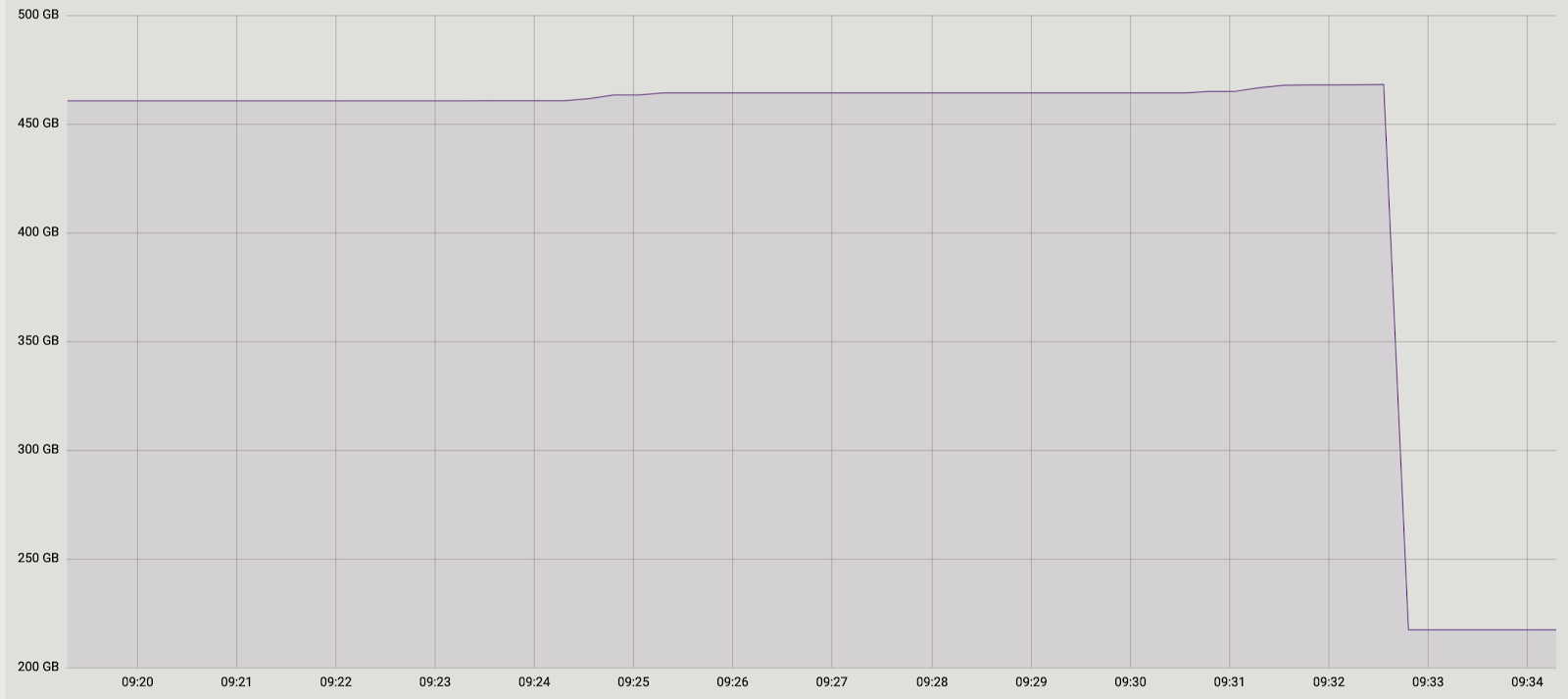 Karena solusi ini sangat cocok untuk kami, kami tidak mencoba menerapkan yang kedua, tetapi kami mempertimbangkan untuk mendiskusikannya dengan pengembang ekstensi. Sayangnya, revisi kami saat ini belum siap untuk dipublikasikan, karena kami telah menyelesaikan masalah hanya dengan pembatasan tertunda yang unik, dan untuk tambalan lengkap, perlu untuk membuat dukungan dari jenis lain. Kami berharap dapat melakukan ini di masa depan.Mungkin Anda memiliki pertanyaan, mengapa kami terlibat dalam cerita ini dengan penyelesaian pg_repack, dan tidak, misalnya, menggunakan analognya? Pada titik tertentu, kami juga memikirkan hal ini, tetapi pengalaman positif menggunakannya sebelumnya, di atas meja tanpa batasan yang tertunda, memotivasi kami untuk mencoba memahami esensi masalah dan memperbaikinya. Selain itu, untuk menggunakan solusi lain, itu juga membutuhkan waktu untuk melakukan tes, jadi kami memutuskan bahwa pertama kami akan mencoba untuk memperbaiki masalah di dalamnya, dan jika kami menyadari bahwa kami tidak dapat melakukannya dalam jumlah waktu yang wajar, maka kami akan mulai mempertimbangkan analog.
Karena solusi ini sangat cocok untuk kami, kami tidak mencoba menerapkan yang kedua, tetapi kami mempertimbangkan untuk mendiskusikannya dengan pengembang ekstensi. Sayangnya, revisi kami saat ini belum siap untuk dipublikasikan, karena kami telah menyelesaikan masalah hanya dengan pembatasan tertunda yang unik, dan untuk tambalan lengkap, perlu untuk membuat dukungan dari jenis lain. Kami berharap dapat melakukan ini di masa depan.Mungkin Anda memiliki pertanyaan, mengapa kami terlibat dalam cerita ini dengan penyelesaian pg_repack, dan tidak, misalnya, menggunakan analognya? Pada titik tertentu, kami juga memikirkan hal ini, tetapi pengalaman positif menggunakannya sebelumnya, di atas meja tanpa batasan yang tertunda, memotivasi kami untuk mencoba memahami esensi masalah dan memperbaikinya. Selain itu, untuk menggunakan solusi lain, itu juga membutuhkan waktu untuk melakukan tes, jadi kami memutuskan bahwa pertama kami akan mencoba untuk memperbaiki masalah di dalamnya, dan jika kami menyadari bahwa kami tidak dapat melakukannya dalam jumlah waktu yang wajar, maka kami akan mulai mempertimbangkan analog.temuan
Apa yang dapat kami rekomendasikan berdasarkan pengalaman kami sendiri:- Pantau bloat Anda. Berdasarkan data pemantauan, Anda dapat memahami seberapa baik autovacuum dikonfigurasi.
- Tetapkan AUTOVACUUM untuk menjaga kembung pada tingkat yang wajar.
- bloat “ ”, . – .
- – , .