Intro
Jika Anda belum ketiduran beberapa tahun terakhir, maka Anda, tentu saja, telah mendengar dari transformer - arsitektur dari kanonik Perhatian adalah semua yang Anda butuhkan . Mengapa transformer sangat bagus? Sebagai contoh, mereka menghindari pengulangan, yang memungkinkan mereka untuk secara efisien membuat presentasi data ke mana banyak informasi kontekstual dapat didorong, yang secara positif mempengaruhi kemampuan untuk menghasilkan teks dan kemampuan yang tak tertandingi untuk mentransfer pembelajaran.
Transformers meluncurkan longsoran kerja pemodelan bahasa - tugas di mana model memilih kata berikutnya, dengan mempertimbangkan probabilitas kata-kata sebelumnya, yaitu, belajar di p(x)mana xtoken saat ini. Seperti yang Anda duga, tugas ini tidak memerlukan markup sama sekali, dan oleh karena itu Anda dapat menggunakan larik teks yang tidak ditandai yang sangat besar di dalamnya. Model bahasa yang sudah terlatih dapat menghasilkan teks, sehingga kadang-kadang penulis menolak untuk mengeluarkan model yang terlatih .
Tetapi bagaimana jika kita ingin menambahkan beberapa "pena" ke generasi teks? Misalnya, lakukan pembangkitan bersyarat dengan menetapkan tema atau mengendalikan atribut lainnya. Bentuk seperti itu sudah membutuhkan probabilitas bersyarat p(x|a), di mana aatribut yang diinginkan. Menarik? Mari kita potong!
Para penulis artikel menawarkan pendekatan yang sederhana (dan karena itu Plug and Play) dan elegan untuk generasi bersyarat, menggunakan model bahasa pra-terlatih yang berat (selanjutnya LM) dan beberapa pengklasifikasi sederhana, dengan demikian mengambil sampel dari distribusi tampilan p(x|a) ∝ p(a|x)p(x). Perlu dicatat bahwa LM asli tidak dimodifikasi dengan cara apa pun. Para penulis mengusulkan dua bentuk pengklasifikasi, yang disebut model atribut dalam artikel: BoW untuk kontrol topik dan classifier linier untuk kontrol nada suara. Para penulis membuat analisis yang cukup rinci tentang kontribusi utama mereka, membandingkan ide dan pendekatan metode mereka dengan artikel lain. Salah satu poin terpenting adalah kemudahan pendekatan, dan di sini, mungkin, lihat saja pelat ini:
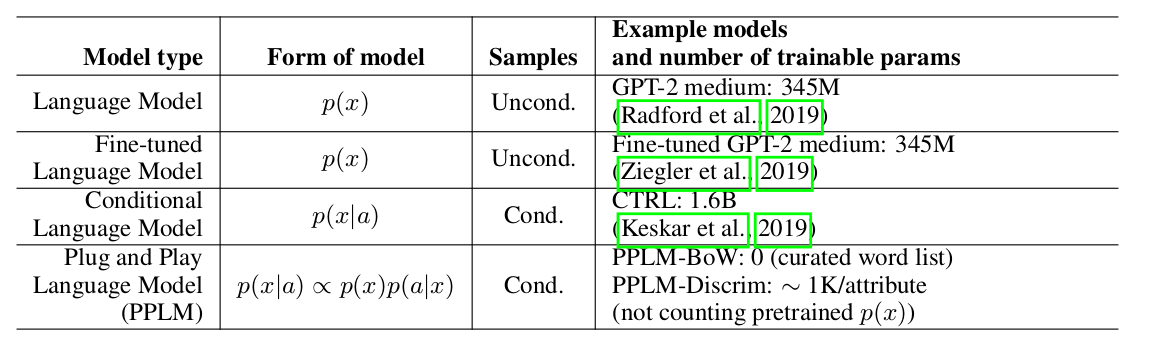
Dapat dilihat bahwa PPLM mengungguli semua pesaing dalam jumlah parameter.
Decoding tertimbang 2.0
Uber weighted decoding: , . , , . , . , , , .
Uber : , LM, . , , , ( , ) . ( perturb_past — , .
? log-likelihood: p(x) a attribute model p(a|x). , backward pass .
log-likelihood? , :
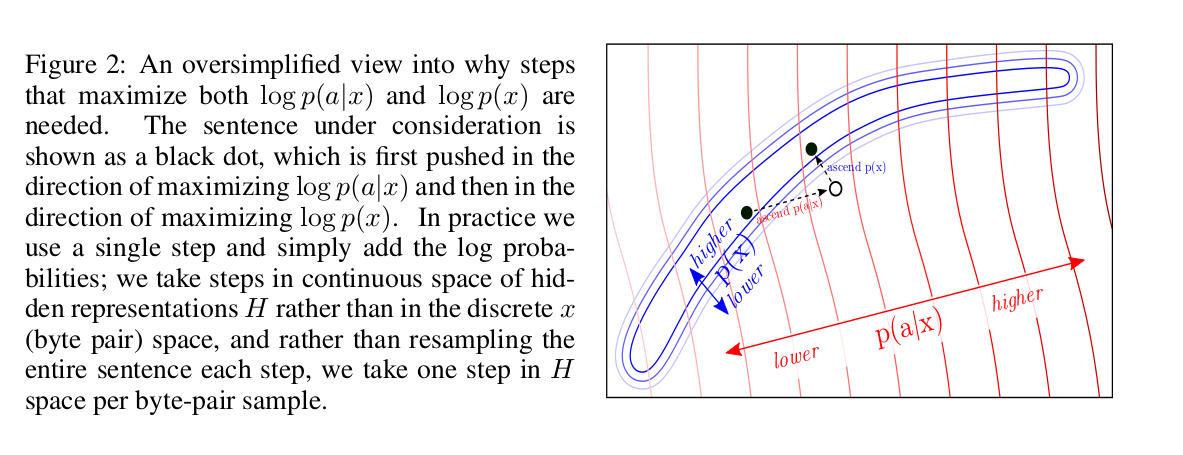
, , LM. , fluency LM.
, :

forward pass LM, p(a|x) — attribute model. backward pass, , attribute model, , . , .
, : “” k k forward backward pass’, n. LM forward pass. , : ( num of iterations=3 gen length=5, ).
, ( colab , ) , , , “the kitten” “military” :
- The kitten is a creature with no real personality, it is just a pet. You can use it as a combat item.
- The kitten that is now being called the "suspected killer" of a woman in a San Diego apartment complex was shot by another person who then shot him, according to authorities.
combat, shot, killer — , military. LM :
- The kitten that escaped a cage has been rescued from a cat sanctuary in Texas.
- The cat, named "Lucky," was found wandering in the back yard of the Humane Society at the time of the incident on Friday.
attribute models
, BoW discriminator. :
p_t+1 — LM, w_i — i- .
Discriminator model , BoW, , , , . , .
, LM, LM weighted decoding CTRL (conditional LM). fluency , , perplexity . PPLM :
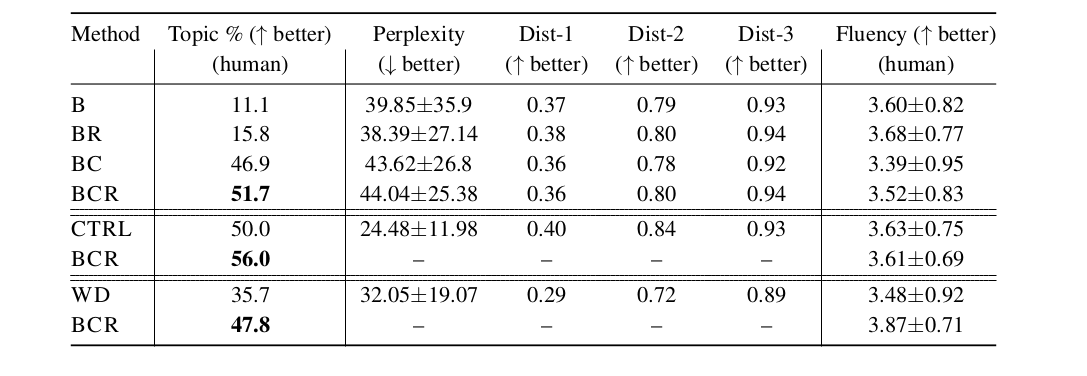
:
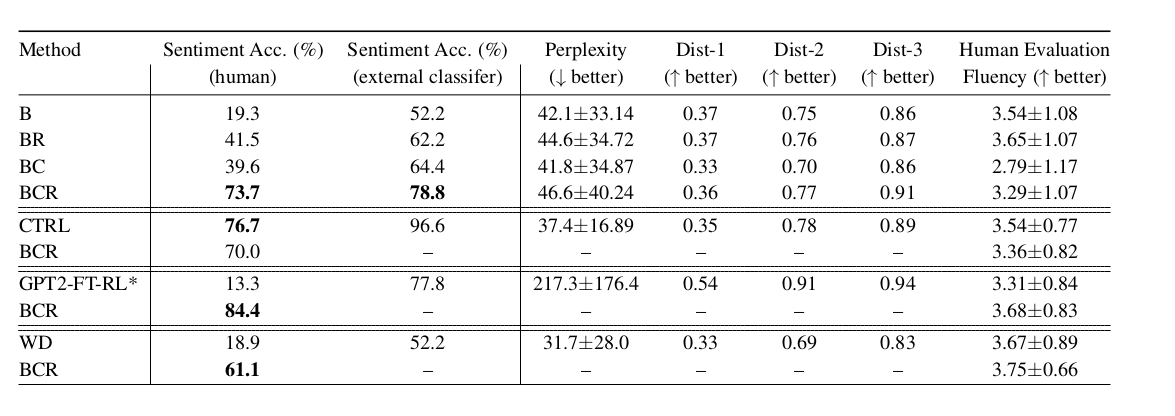
- B — baseline, GPT-2 LM;
- BR — , B,
r , log-likelihood ; - BC — , ;
- BCR — , BC,
r , log-likelihood ; - CTRL — Keskar et al, 2019;
- GPT2-FT-RL — GPT2, fine-tuned RL ;
- WD — weighted decoding,
p(a|x);
— , LM, . , , - :)