 Internet penuh dengan artikel tentang model bahasa berbasis N-gram. Pada saat yang sama, ada beberapa perpustakaan yang siap bekerja.Ada KenLM , SriLM dan IRSTLM . Mereka populer dan digunakan dalam banyak proyek besar. Tetapi ada beberapa masalah:
Internet penuh dengan artikel tentang model bahasa berbasis N-gram. Pada saat yang sama, ada beberapa perpustakaan yang siap bekerja.Ada KenLM , SriLM dan IRSTLM . Mereka populer dan digunakan dalam banyak proyek besar. Tetapi ada beberapa masalah:- Perpustakaan sudah tua, tidak berkembang.
- Dukungan yang buruk untuk bahasa Rusia.
- Hanya bekerja dengan teks bersih, disiapkan khusus
- Dukungan buruk untuk UTF-8. Sebagai contoh, SriLM dengan bendera tolower merusak encoding.
KenLM
sedikit menonjol dari daftar . Ini didukung secara teratur dan tidak memiliki masalah dengan UTF-8, tetapi juga menuntut kualitas teks.Suatu ketika saya membutuhkan perpustakaan untuk membangun model bahasa. Setelah banyak percobaan dan kesalahan, saya sampai pada kesimpulan bahwa mempersiapkan dataset untuk mengajar model bahasa terlalu rumit dan proses yang panjang. Terutama jika itu bahasa Rusia ! Tapi entah bagaimana saya ingin mengotomatiskan segalanya.Dalam penelitiannya, ia mulai dari perpustakaan SriLM . Saya akan segera mencatat bahwa ini bukan peminjaman kode atau garpu SriLM . Semua kode ditulis sepenuhnya dari awal.Contoh teks kecil:
! .
Kurangnya ruang antara kalimat adalah kesalahan ketik yang cukup umum. Kesalahan seperti itu sulit ditemukan dalam sejumlah besar data, sementara itu memecahkan tokenizer.Setelah diproses, N-gram berikut akan muncul dalam model bahasa:
-0.3009452 !
Tentu saja, ada banyak masalah lain, kesalahan ketik, karakter khusus, singkatan, berbagai rumus matematika ... Semua ini harus ditangani dengan benar.APA PUN LM ( ALM )
Perpustakaan hanya mendukung Linux , MacOS X, dan FreeBSD sistem operasi . Saya tidak memiliki Windows dan tidak ada dukungan yang direncanakan.Deskripsi singkat tentang fungsionalitas
- Dukungan untuk UTF-8 tanpa ketergantungan pihak ketiga.
- Dukungan untuk format data: Arpa, Vocab, Urutan Peta, N-gram, Binary alm dictionary.
- : Kneser-Nay, Modified Kneser-Nay, Witten-Bell, Additive, Good-Turing, Absolute discounting.
- , , , .
- , N-, N- , N-.
- — N-, .
- : , -.
- N- — N-, backoff .
- N- backoff-.
- , : , , , , Python3.
- « », .
- 〈unk〉 .
- N- Python3.
- , .
- . : , , .
- Tidak seperti model bahasa lainnya, ALM dijamin untuk mengumpulkan semua N-gram dari teks, berapa pun panjangnya (kecuali untuk Modifikasi Kneser-Nay). Ada juga kemungkinan pendaftaran wajib semua N-gram langka, bahkan jika mereka bertemu hanya 1 kali.
Dari format model bahasa standar, hanya format ARPA yang didukung . Jujur, saya tidak melihat alasan untuk mendukung seluruh kebun binatang dalam semua jenis format.Format ARPA peka huruf besar-kecil dan ini juga merupakan masalah yang pasti.Terkadang hanya berguna untuk mengetahui keberadaan data tertentu dalam N-gram. Misalnya, Anda perlu memahami keberadaan angka dalam N-gram, dan artinya tidak begitu penting.Contoh:
, 2
Akibatnya, N-gram masuk ke model bahasa:
-0.09521468 2
Nomor spesifik, dalam hal ini, tidak masalah. Dijual di toko bisa 1 dan 3 dan sebanyak hari yang Anda suka.Untuk mengatasi masalah ini, ALM menggunakan tokenization kelas.Token yang didukung
Standar:〈s〉 - Token dari awal kalimat〈/s〉 - Token dari akhir kalimat〈unk Tok - Token dari kata yang tidak diketahuiNon-standar:〈url〉 - Token dari alamat url〈num〉 - Token angka (Arab atau Romawi)〈date〈 - Tanggal token (18 Juli 2004 | 18/07/2004)〈time〉 - Token Waktu (15:44:56)〈abbr〉 - Token Singkatan (1st | 2nd | 20th)〉 anum〉 - Pseudo -Token numbers (T34 | 895-M-86 | 39km)〈math〉 - Token operasi matematika (+ | - | = | / | * | ^)〈range〉 - Token dari rentang angka (1-2 | 100-200 | 300- 400)〈aprox〉- Sebuah token angka perkiraan (~ 93 | ~ 95.86 | 10 ~ 20)〉score〉 - Token akun numerik (4: 3 | 01:04)〈dimen〉 - Keseluruhan token (200x300 | 1920x1080)〈fract〉 - A fraksi token (5/20 | 192/864)〈punct〉 - Token karakter tanda baca (. | ... |, |! |? |: |;)〈Specl〉 - Token karakter khusus (~ | @ | # | No. |% | & | $ | § | ±)<isolat> - simbol Isolasi tanda ( "| '|" | "|‘|’|` | (|) | [|] | {|})Tentu saja, dukungan untuk masing-masing token dapat dinonaktifkan jika N-gram tersebutdiperlukan. Jika Anda perlu memproses tag lain (misalnya, Anda perlu menemukan nama negara dalam teks), ALM mendukung koneksi skrip eksternal di Python3.Contoh skrip deteksi token:
def init():
"""
:
"""
def run(token, word):
"""
:
@token
@word
"""
if token and (token == "<usa>"):
if word and (word.lower() == ""): return "ok"
elif token and (token == "<russia>"):
if word and (word.lower() == ""): return "ok"
return "no"
Skrip semacam itu menambahkan dua tag lagi ke daftar tag standar: 〈usa〉 dan 〈russia〉 .Selain skrip untuk mendeteksi token, ada dukungan untuk skrip untuk preprocessing kata yang diproses. Script ini dapat mengubah kata sebelum menambahkan kata ke model bahasa.Contoh skrip pengolah kata:
def init():
"""
:
"""
def run(word, context):
"""
:
@word
@context
"""
return word
Pendekatan semacam itu dapat berguna jika perlu untuk menyusun model bahasa yang terdiri dari lemma atau batang .Format Model Bahasa Teks Didukung oleh ALM
ARPA:
\data\
ngram 1=52
ngram 2=68
ngram 3=15
\1-grams:
-1.807052 1- -0.30103
-1.807052 2 -0.30103
-1.807052 3~4 -0.30103
-2.332414 -0.394770
-3.185530 -0.311249
-3.055896 -0.441649
-1.150508 </s>
-99 <s> -0.3309932
-2.112406 <unk>
-1.807052 T358 -0.30103
-1.807052 VII -0.30103
-1.503878 -0.39794
-1.807052 -0.30103
-1.62953 -0.30103
...
\2-grams:
-0.29431 1-
-0.29431 2
-0.29431 3~4
-0.8407791 <s>
-1.328447 -0.477121
...
\3-grams:
-0.09521468
-0.166590
...
\end\
ARPA adalah format teks standar untuk model bahasa bahasa alami yang digunakan oleh Sphinx / CMU dan Kaldi .NGRAM:
\data\
ad=1
cw=23832
unq=9390
ngram 1=9905
ngram 2=21907
ngram 3=306
\1-grams:
<s> 2022 | 1
<num> 117 | 1
<unk> 19 | 1
<abbr> 16 | 1
<range> 7 | 1
</s> 2022 | 1
244 | 1
244 | 1
11 | 1
762 | 1
112 | 1
224 | 1
1 | 1
86 | 1
978 | 1
396 | 1
108 | 1
77 | 1
32 | 1
...
\2-grams:
<s> <num> 7 | 1
<s> <unk> 1 | 1
<s> 84 | 1
<s> 83 | 1
<s> 57 | 1
82 | 1
11 | 1
24 | 1
18 | 1
31 | 1
45 | 1
97 | 1
71 | 1
...
\3-grams:
<s> <num> </s> 3 | 1
<s> 6 | 1
<s> 4 | 1
<s> 2 | 1
<s> 3 | 1
2 | 1
</s> 2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
</s> 2 | 1
</s> 3 | 1
2 | 1
...
\end\
Ngrams - format teks non-standar dari model bahasa, adalah modifikasi dari format ARPA .Deskripsi:- ad - Jumlah dokumen dalam enklosur
- cw - Jumlah kata dalam semua dokumen dalam korpus
- unq - Jumlah kata unik yang dikumpulkan
KOSA KATA:
\data\
ad=1
cw=23832
unq=9390
\words:
33 244 | 1 | 0.010238 | 0.000000 | -3.581616
34 11 | 1 | 0.000462 | 0.000000 | -6.680889
35 762 | 1 | 0.031974 | 0.000000 | -2.442838
40 12 | 1 | 0.000504 | 0.000000 | -6.593878
330344 47 | 1 | 0.001972 | 0.000000 | -5.228637
335190 17 | 1 | 0.000713 | 0.000000 | -6.245571
335192 1 | 1 | 0.000042 | 0.000000 | -9.078785
335202 22 | 1 | 0.000923 | 0.000000 | -5.987742
335206 7 | 1 | 0.000294 | 0.000000 | -7.132874
335207 29 | 1 | 0.001217 | 0.000000 | -5.711489
2282019644 1 | 1 | 0.000042 | 0.000000 | -9.078785
2282345502 10 | 1 | 0.000420 | 0.000000 | -6.776199
2282416889 2 | 1 | 0.000084 | 0.000000 | -8.385637
3009239976 1 | 1 | 0.000042 | 0.000000 | -9.078785
3009763109 1 | 1 | 0.000042 | 0.000000 | -9.078785
3013240091 1 | 1 | 0.000042 | 0.000000 | -9.078785
3014009989 1 | 1 | 0.000042 | 0.000000 | -9.078785
3015727462 2 | 1 | 0.000084 | 0.000000 | -8.385637
3025113549 1 | 1 | 0.000042 | 0.000000 | -9.078785
3049820849 1 | 1 | 0.000042 | 0.000000 | -9.078785
3061388599 1 | 1 | 0.000042 | 0.000000 | -9.078785
3063804798 1 | 1 | 0.000042 | 0.000000 | -9.078785
3071212736 1 | 1 | 0.000042 | 0.000000 | -9.078785
3074971025 1 | 1 | 0.000042 | 0.000000 | -9.078785
3075044360 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123271427 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123322362 1 | 1 | 0.000042 | 0.000000 | -9.078785
3126399411 1 | 1 | 0.000042 | 0.000000 | -9.078785
…
Vocab adalah format kamus teks yang tidak standar dalam model bahasa.Deskripsi:- oc - kemunculan kasus
- dc - kemunculan dalam dokumen
- tf - (term frequency — ) — . , , : [tf = oc / cw]
- idf - (inverse document frequency — ) — , , : [idf = log(ad / dc)]
- tf-idf - : [tf-idf = tf * idf]
- wltf - , : [wltf = 1 + log(tf * dc)]
MAP:
1:{2022,1,0}|42:{57,1,0}|279603:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|320749:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|351283:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|379815:{3,1,0}
1:{2022,1,0}|42:{57,1,0}|26122748:{3,1,0}
1:{2022,1,0}|44:{6,1,0}
1:{2022,1,0}|48:{1,1,0}
1:{2022,1,0}|51:{11,1,0}|335967:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|371327:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|40260976:{7,1,0}
1:{2022,1,0}|65:{68,1,0}|34:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|3277:{3,1,0}
1:{2022,1,0}|65:{68,1,0}|278003:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|320749:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|11353430797:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|34270133320:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|51652356484:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|66967237546:{2,1,0}
1:{2022,1,0}|2842:{11,1,0}|42:{7,1,0}
…
Peta - isi file, memiliki makna teknis murni. Digunakan bersama dengan file vocab , Anda dapat menggabungkan beberapa model bahasa, memodifikasi, menyimpan, mendistribusikan, dan mengekspor ke format apa pun ( arpa , ngrams , binary alm ).Format File Teks Helper Didukung oleh ALM
Seringkali, ketika menyusun model bahasa, kesalahan ketik muncul dalam teks, yang menggantikan huruf (dengan huruf alfabet lain yang serupa secara visual).ALM memecahkan masalah ini dengan file dengan huruf yang mirip.p
c
o
t
k
e
a
h
x
b
m
Jika, ketika mengajar model bahasa, mentransfer file dengan daftar domain dan singkatan tingkat pertama, maka ALM dapat membantu dengan deteksi yang lebih akurat untuk tag kelas 〈url〉 dan 〈abbr〉 .File Daftar Singkatan:
…
File Daftar Zona Domain:
ru
su
cc
net
com
org
info
…
Untuk mendeteksi token 〈url〉 yang lebih akurat , Anda harus menambahkan zona domain tingkat pertama Anda (semua zona domain dari contoh sudah diinstal sebelumnya) .Wadah biner dari model bahasa ALM
Untuk membangun wadah biner untuk model bahasa, Anda perlu membuat file JSON dengan deskripsi parameter Anda.Opsi JSON:
{
"aes": 128,
"name": "Name dictionary",
"author": "Name author",
"lictype": "License type",
"lictext": "License text",
"contacts": "Contacts data",
"password": "Password if needed",
"copyright": "Copyright author"
}
Deskripsi:- aes - ukuran enkripsi AES (128, 192, 256) bit
- nama - nama Kamus
- penulis - penulis kamus
- lictype - Jenis lisensi
- lictext - Teks lisensi
- kontak - Penulis detail kontak
- kata sandi - Kata sandi enkripsi (jika diperlukan), enkripsi dilakukan hanya ketika mengatur kata sandi
- hak cipta - Hak cipta dari pemilik kamus
Semua parameter bersifat opsional kecuali nama wadah.Contoh Perpustakaan ALM
Operasi Tokenizer
Tokenizer menerima teks pada input, dan menghasilkan JSON pada output.$ echo 'Hello World?' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
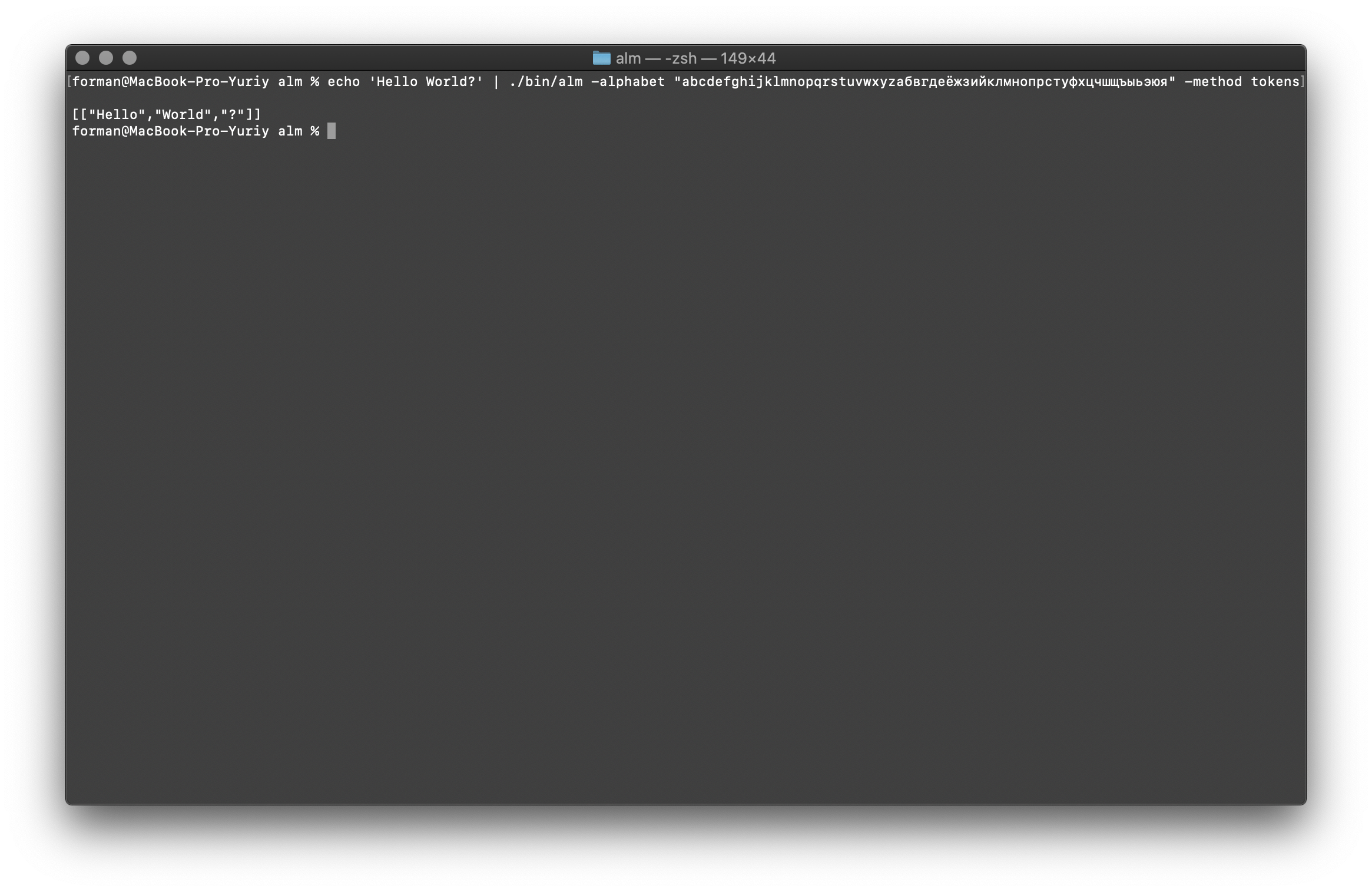 Uji:
Uji:Hello World?
Hasil:[
["Hello","World","?"]
]
Mari kita coba sesuatu yang lebih sulit ...$ echo ' ??? ....' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
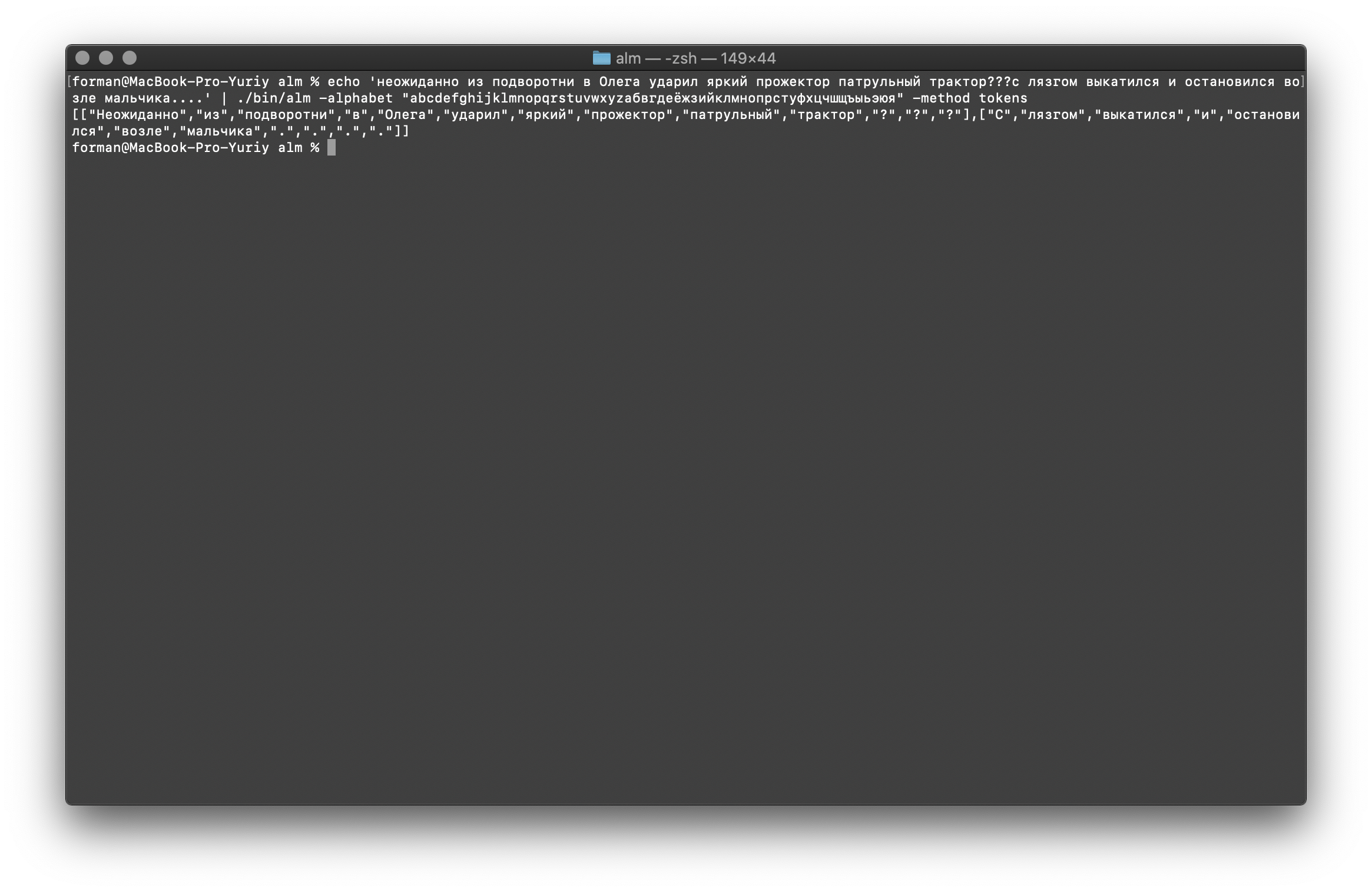 Uji:
Uji: ??? ....
Hasil:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"?",
"?",
"?"
],[
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"."
]
]
Seperti yang Anda lihat, tokenizer bekerja dengan benar dan memperbaiki kesalahan dasar.Ubah sedikit teks dan lihat hasilnya.$ echo ' ... .' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
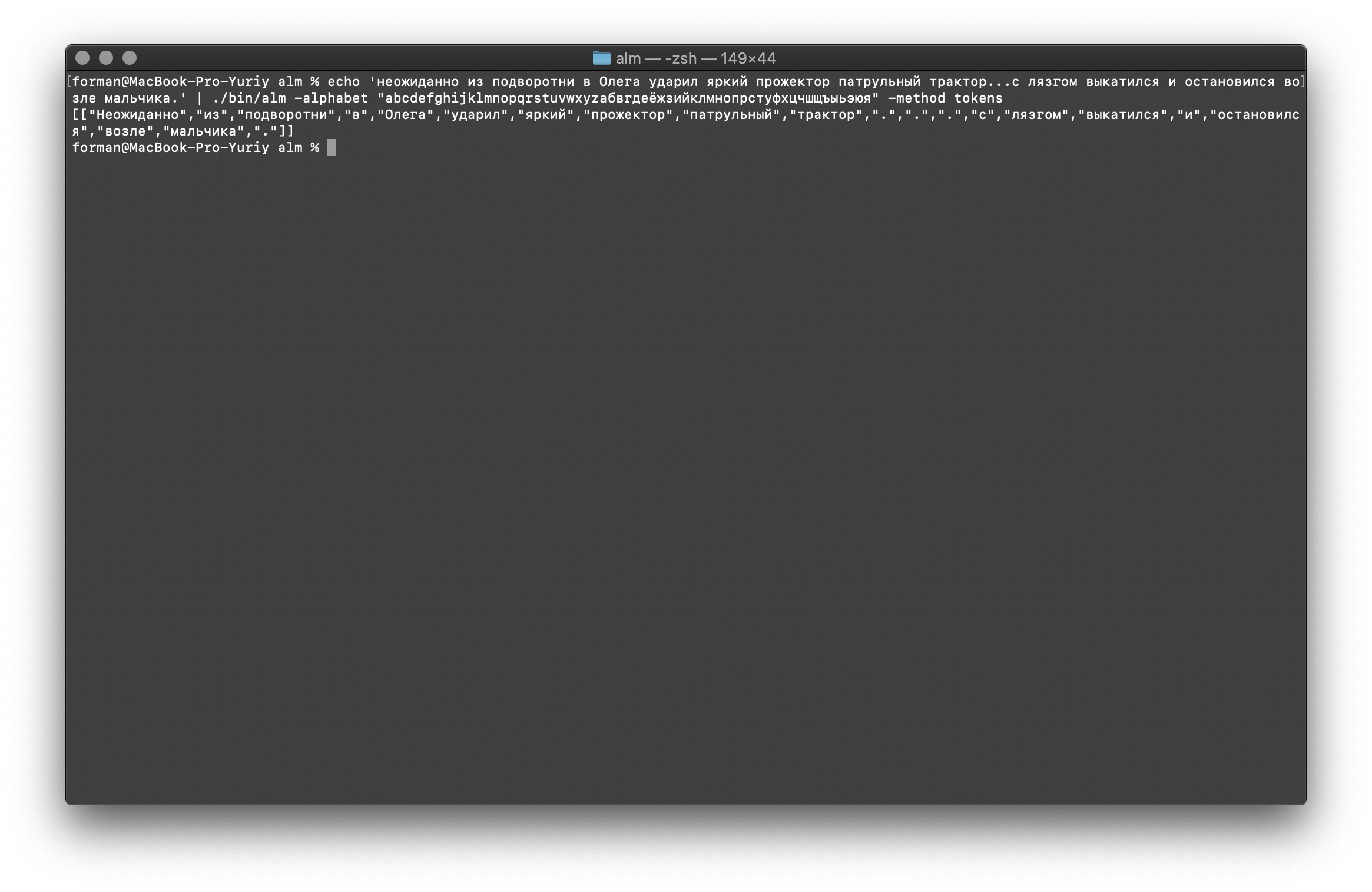 Uji:
Uji: ... .
Hasil:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"",
"",
"",
"",
"",
"",
"",
"."
]
]
Seperti yang Anda lihat, hasilnya telah berubah. Sekarang coba yang lain.$ echo ' 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Uji:
Uji: 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()
Hasil:[
[
"",
"",
"",
"",
"5–7",
".",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
":",
"1",
".",
"",
"",
"(",
"+37–38°",
")",
",",
"",
"5–10",
".",
"–",
"",
"",
"(",
"+12–15°",
")",
"",
"..",
"»",
"|",
"|",
"(",
")"
]
]
Gabungkan semuanya kembali menjadi teks
Pertama, kembalikan tes pertama.$ echo '[["Hello","World","?"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
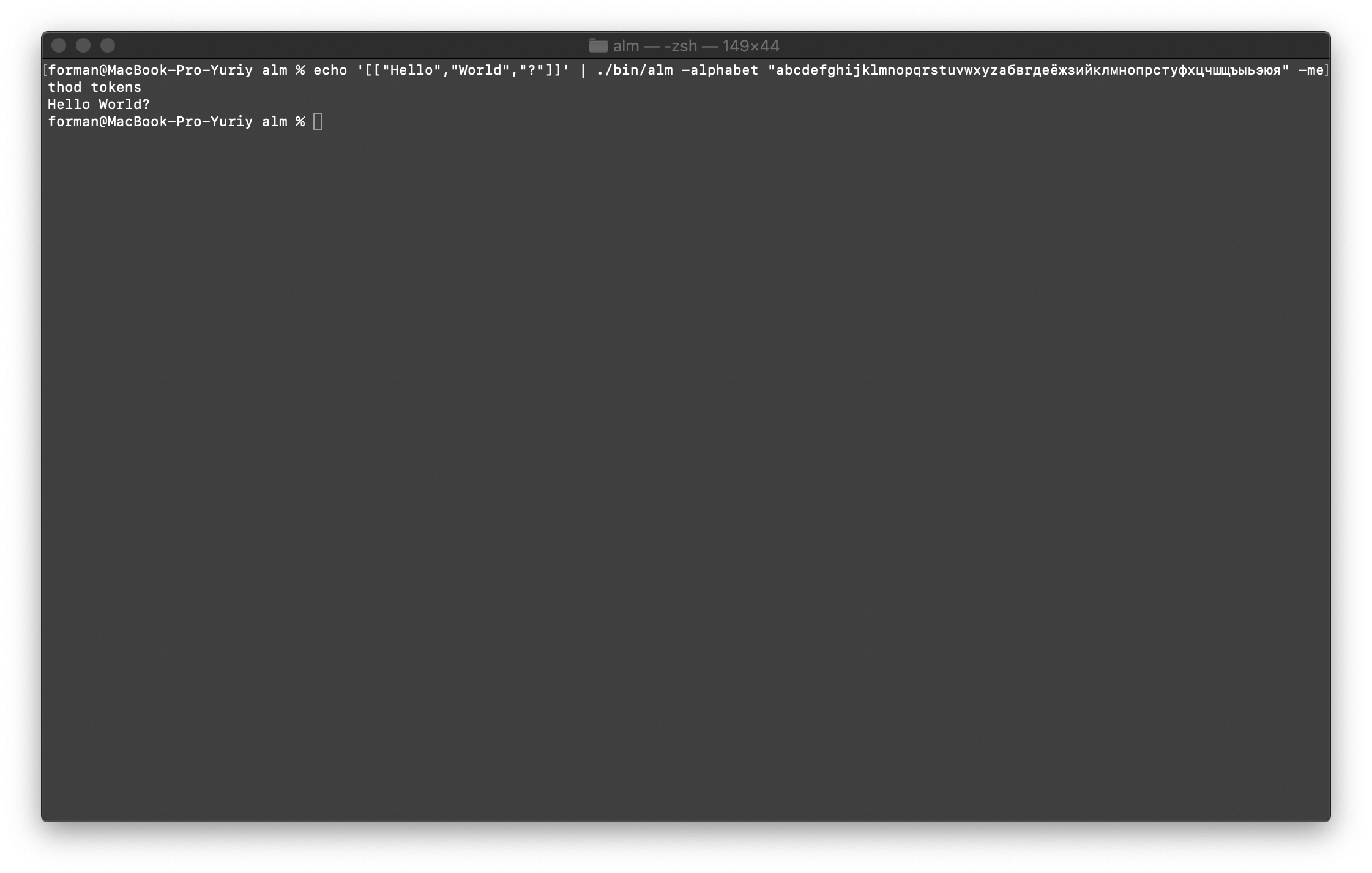 Uji:
Uji:[["Hello","World","?"]]
Hasil:Hello World?
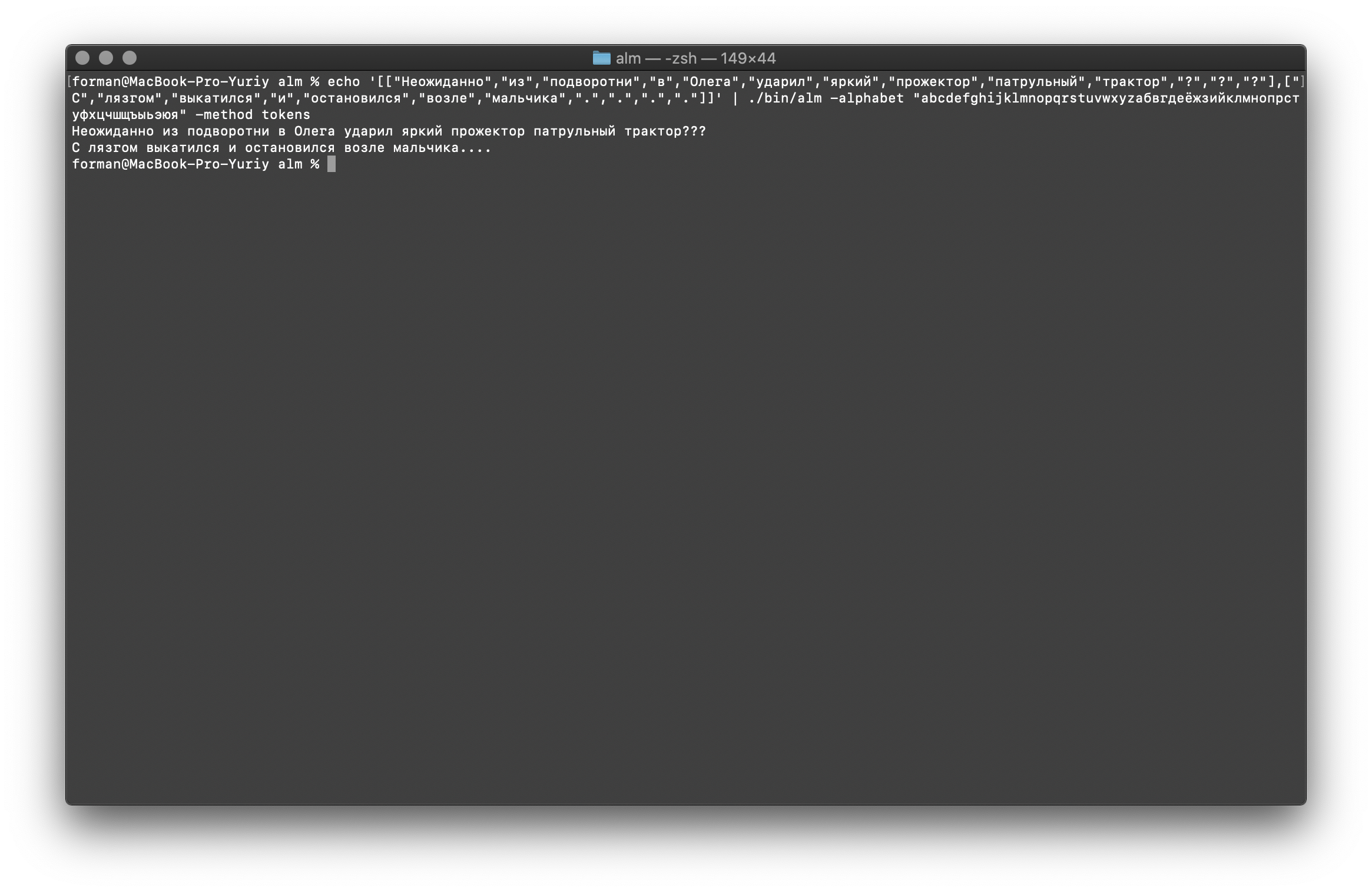
Kami sekarang akan mengembalikan tes yang lebih kompleks.$ echo '[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Uji:
Uji:[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]
Hasil: ???
….
Seperti yang Anda lihat, tokenizer dapat mengembalikan teks yang awalnya rusak.Lanjutkan.$ echo '[["","","","","","","","","","",".",".",".","","","","","","","","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Uji:
Uji:[["","","","","","","","","","",".",".",".","","","","","","","","."]]
Hasil: ... .
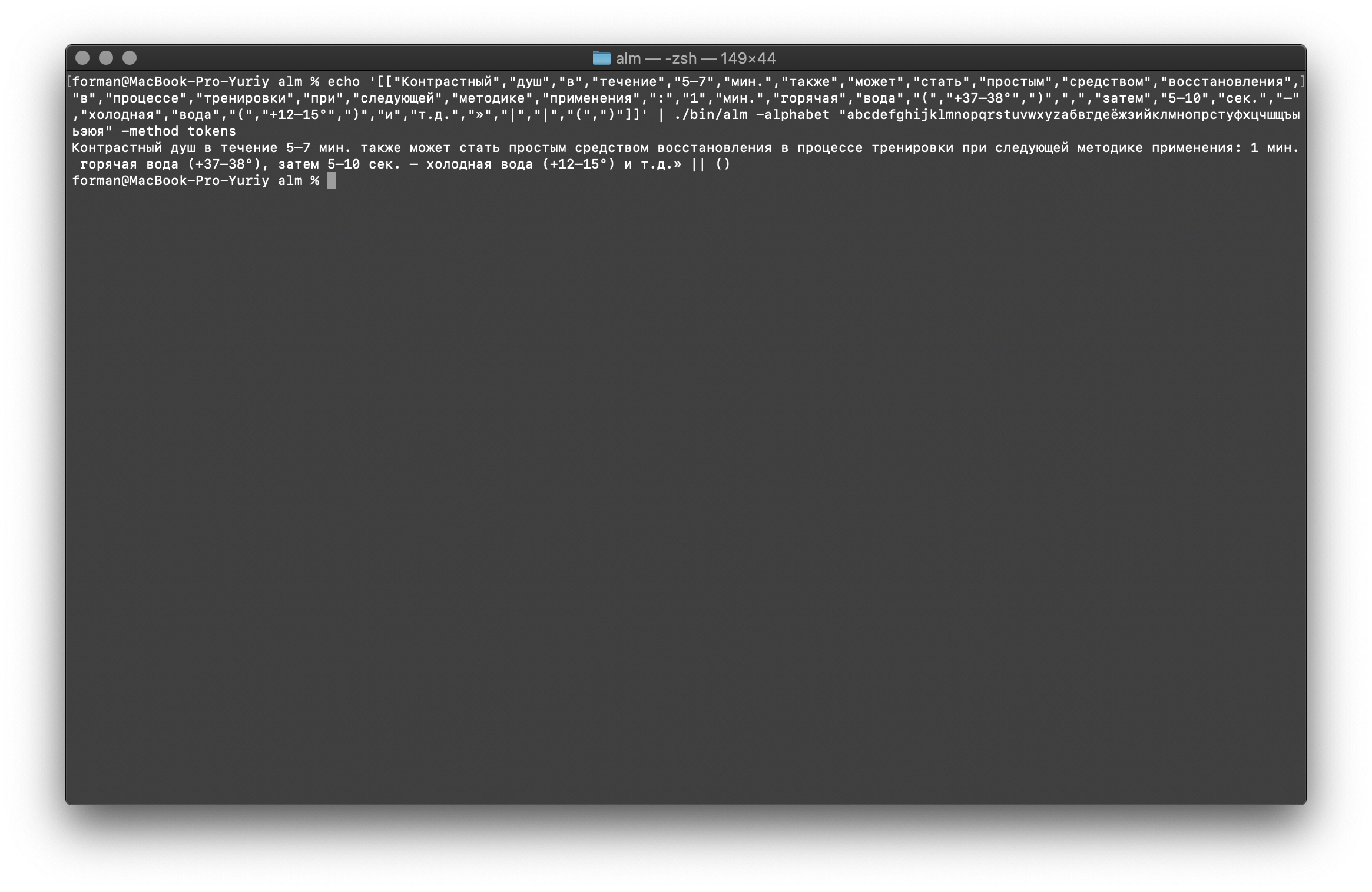
Dan akhirnya, periksa opsi yang paling sulit.$ echo '[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Uji:
Uji:[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]
Hasil: 5–7 . : 1 . (+37–38°), 5–10 . – (+12–15°) ..» || ()
Seperti dapat dilihat dari hasil, tokenizer dapat memperbaiki sebagian besar kesalahan dalam desain teks.Pelatihan model bahasa
$ ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -size 3 -smoothing wittenbell -method train -debug 1 -w-arpa ./lm.arpa -w-map ./lm.map -w-vocab ./lm.vocab -w-ngram ./lm.ngrams -allow-unk -interpolate -corpus ./text.txt -threads 0 -train-segments
Saya akan menjelaskan parameter perakitan secara lebih rinci.- size - Ukuran panjang N-gram (ukuran diatur ke 3 gram )
- smoothing - Smoothing algorithm (algoritma dipilih oleh Witten-Bell )
- metode - Metode kerja (metode pelatihan yang ditentukan )
- debug - Mode debug (indikator status pembelajaran diatur)
- w-arpa — ARPA
- w-map — MAP
- w-vocab — VOCAB
- w-ngram — NGRAM
- allow-unk — 〈unk〉
- interpolate —
- corpus — . ,
- utas - Gunakan multithreading untuk pelatihan (0 - untuk pelatihan, semua inti prosesor yang tersedia akan diberikan,> 0 jumlah inti yang berpartisipasi dalam pelatihan)
- train-segment - Gedung pelatihan akan disegmentasikan secara merata di semua inti
Informasi lebih lanjut dapat diperoleh dengan menggunakan flag [-help] .
Perhitungan kebingungan
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method ppl -debug 2 -r-arpa ./lm.arpa -confidence -threads 0
 Uji:
Uji: ??? ….
Hasil:info: <s> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00209192 [ -2.67945500 ] / 0.99999999
info: p( | ...) = [3gram] 0.91439744 [ -0.03886500 ] / 1.00000035
info: p( | ...) = [3gram] 0.86302624 [ -0.06397600 ] / 0.99999998
info: p( | ...) = [3gram] 0.98003368 [ -0.00875900 ] / 1.00000088
info: p( | ...) = [3gram] 0.85783547 [ -0.06659600 ] / 0.99999955
info: p( | ...) = [3gram] 0.95238819 [ -0.02118600 ] / 0.99999897
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( <punct> | ...) = [3gram] 0.78127873 [ -0.10719400 ] / 1.00000031
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 13 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.18477000 ppl= 1.99027067 ppl1= 2.09848266
info: <s> <punct> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00809597 [ -2.09173100 ] / 0.99999999
info: p( | ...) = [3gram] 0.19675329 [ -0.70607800 ] / 0.99999972
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.98007204 [ -0.00874200 ] / 0.99999931
info: p( | ...) = [3gram] 0.85785325 [ -0.06658700 ] / 1.00000018
info: p( | ...) = [3gram] 0.81482810 [ -0.08893400 ] / 1.00000027
info: p( | ...) = [3gram] 0.93507404 [ -0.02915400 ] / 1.00000058
info: p( <punct> | ...) = [3gram] 0.76391493 [ -0.11695500 ] / 0.99999971
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 11 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.57026500 ppl= 2.40356248 ppl1= 2.60302678
info: 2 sentences, 24 words, 0 OOVs
info: 0 zeroprobs, logprob= -8.75503500 ppl= 2.23975957 ppl1= 2.31629103
info: work time shifting: 0 seconds
Saya pikir tidak ada yang istimewa untuk dikomentari, jadi kami akan melanjutkan lebih jauh.Pemeriksaan Keberadaan Konteks
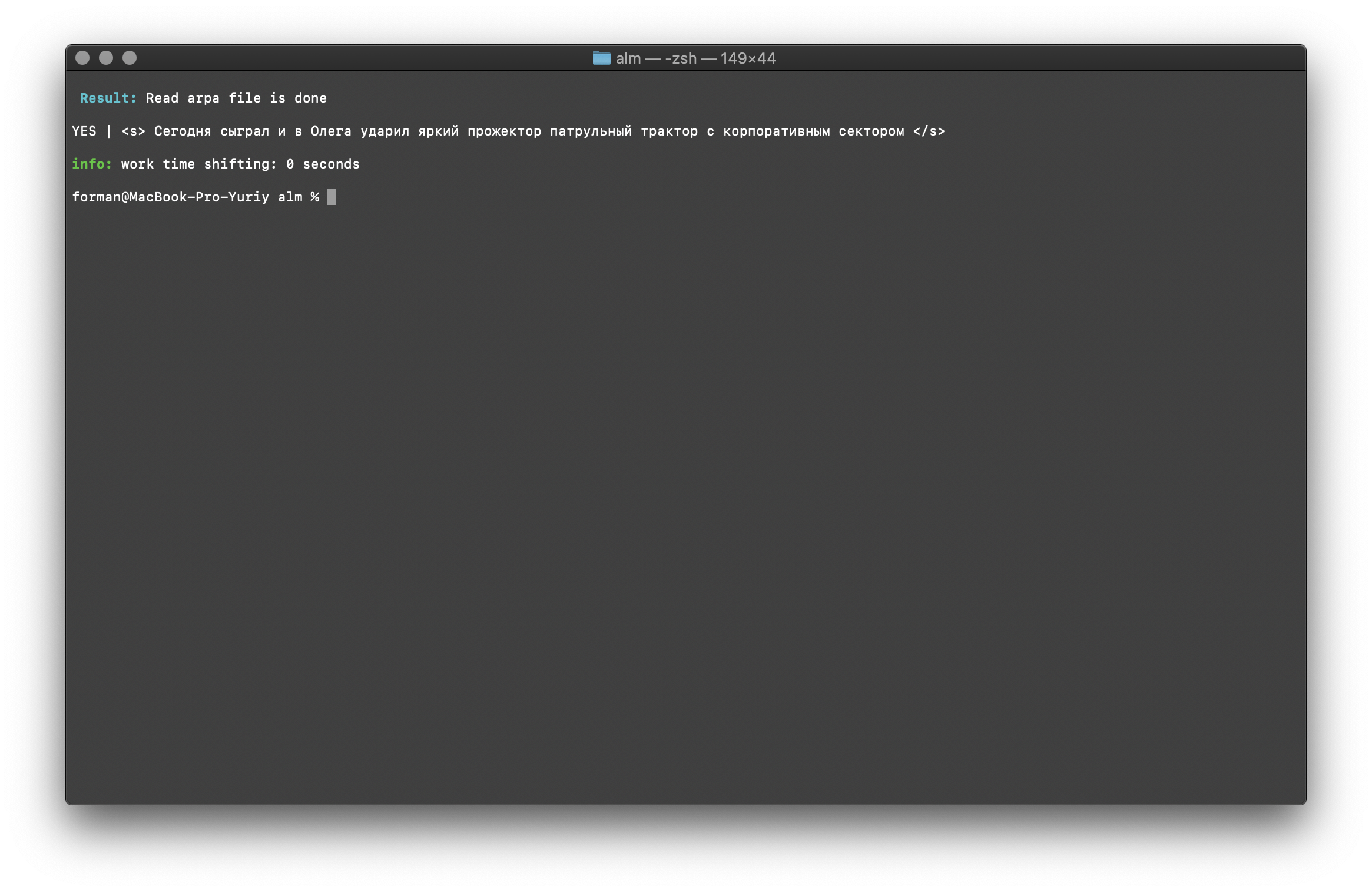
$ echo "<s> </s>" | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method checktext -debug 1 -r-arpa ./lm.arpa -confidence
 Uji:
Uji:<s> </s>
Hasil:YES | <s> </s>
Hasilnya menunjukkan bahwa teks yang diperiksa memiliki konteks yang benar dalam hal model bahasa yang dikumpulkan.Tandai [ -kepercayaan ] - artinya model bahasa akan dimuat saat dibangun, tanpa overtokenization.Koreksi kasus kata
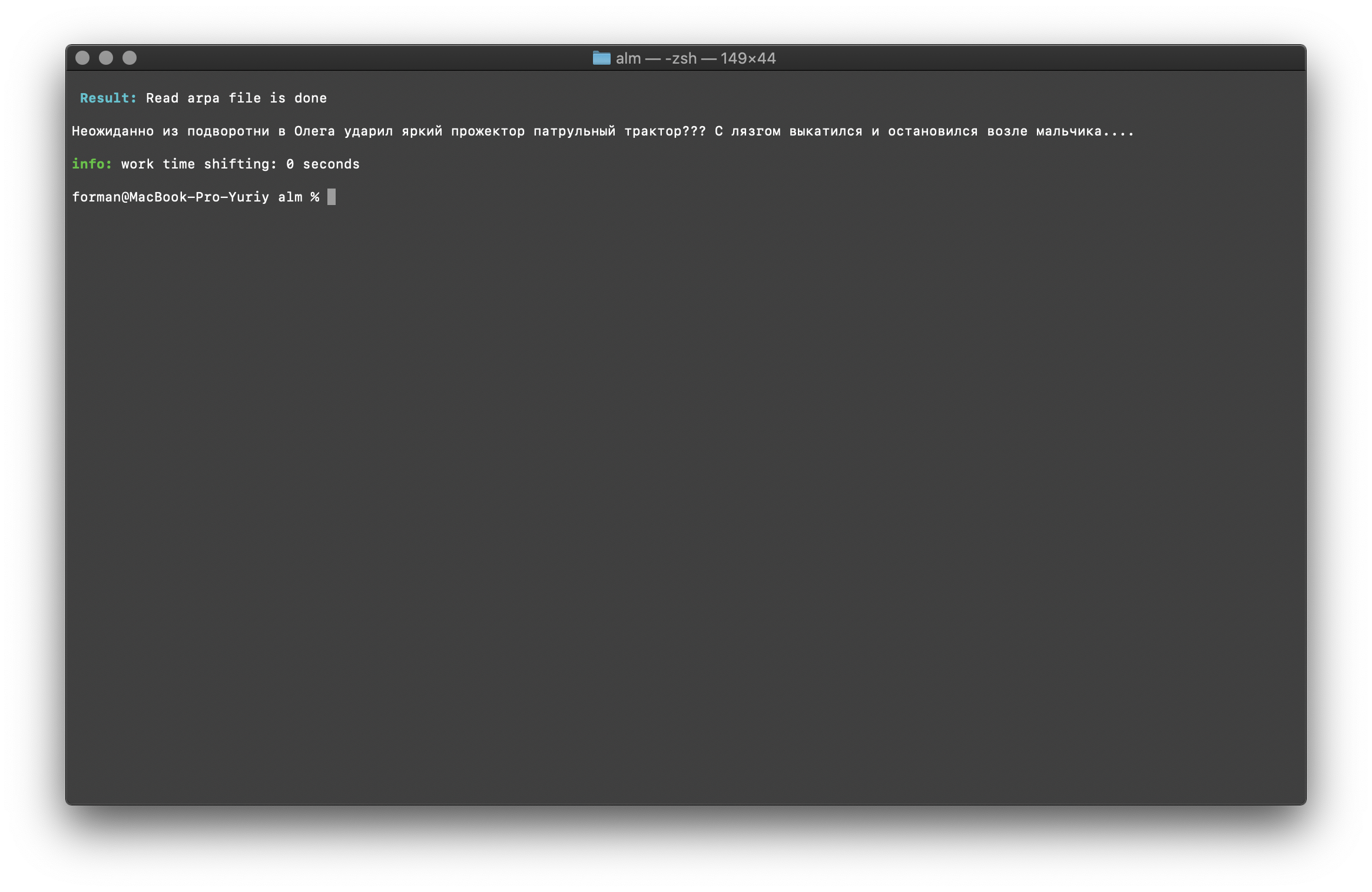
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method fixcase -debug 1 -r-arpa ./lm.arpa -confidence
 Uji:
Uji: ??? ....
Hasil: ??? ....
Register dalam teks dipulihkan dengan mempertimbangkan konteks model bahasa.Perpustakaan yang dijelaskan di atas untuk bekerja dengan model bahasa statistik peka huruf besar-kecil. Misalnya, N-gram " di Moskow besok akan hujan " tidak sama dengan N-gram " di Moskow akan hujan besok ", ini adalah N-gram yang sama sekali berbeda. Tetapi bagaimana jika case tersebut harus case-sensitive dan, pada saat yang sama, menduplikasi N-gram yang sama tidak rasional? ALM mewakili semua N-gram dalam huruf kecil. Ini menghilangkan kemungkinan duplikasi N-gram. ALM juga mempertahankan peringkat register kata di setiap N-gram. Saat mengekspor ke format teks model bahasa, register dipulihkan tergantung pada peringkat mereka.Memeriksa jumlah N-gram
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -debug 1 -r-arpa ./lm.arpa -confidence
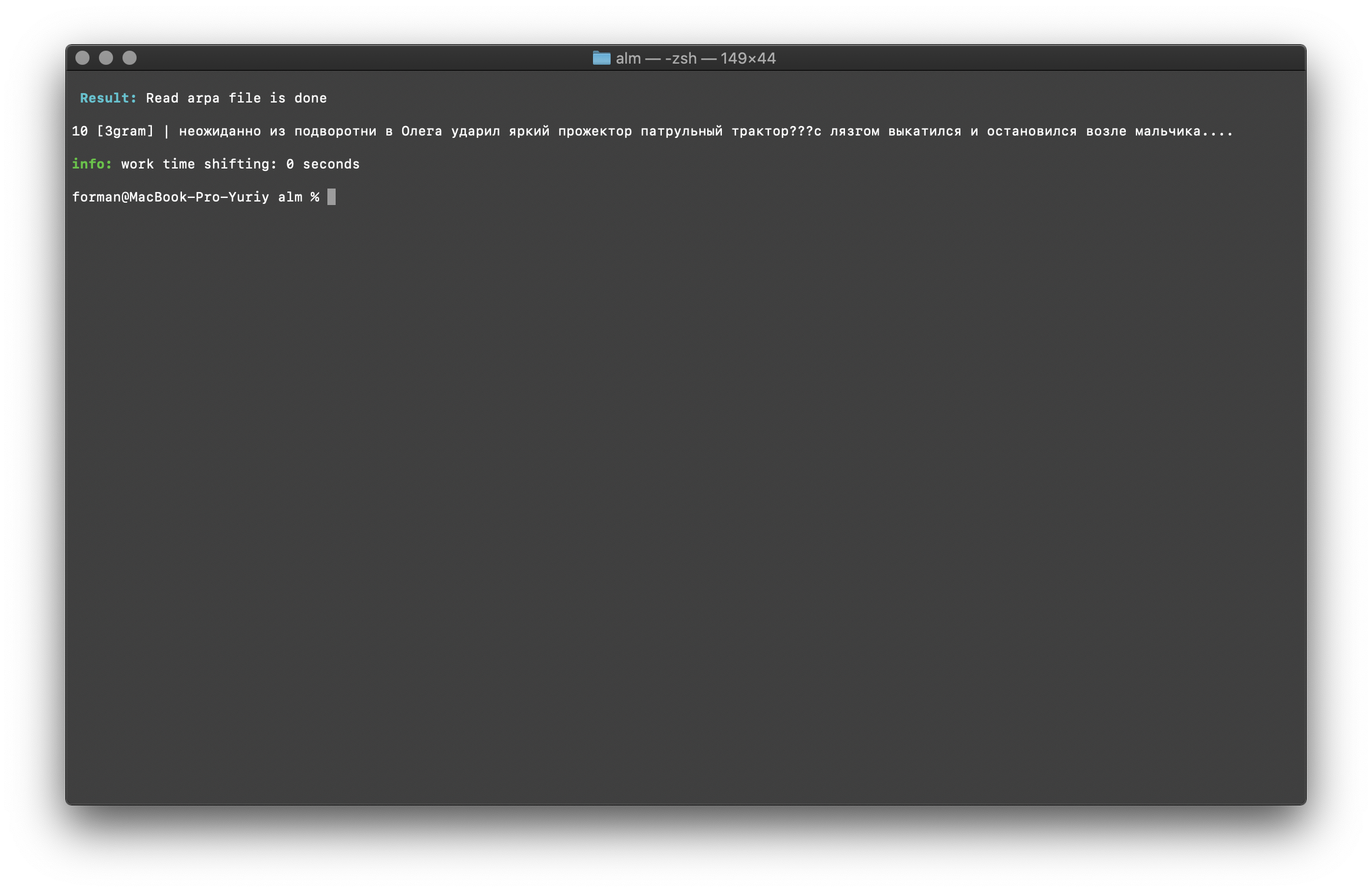 Uji:
Uji: ??? ....
Hasil:10 [3gram] |
N- , .
Memeriksa jumlah N-gram dilakukan oleh ukuran N-gram dalam model bahasa. Ada juga kesempatan untuk memeriksa bigrams dan trigram .Periksa Bigram
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams bigram -debug 1 -r-arpa ./lm.arpa -confidence
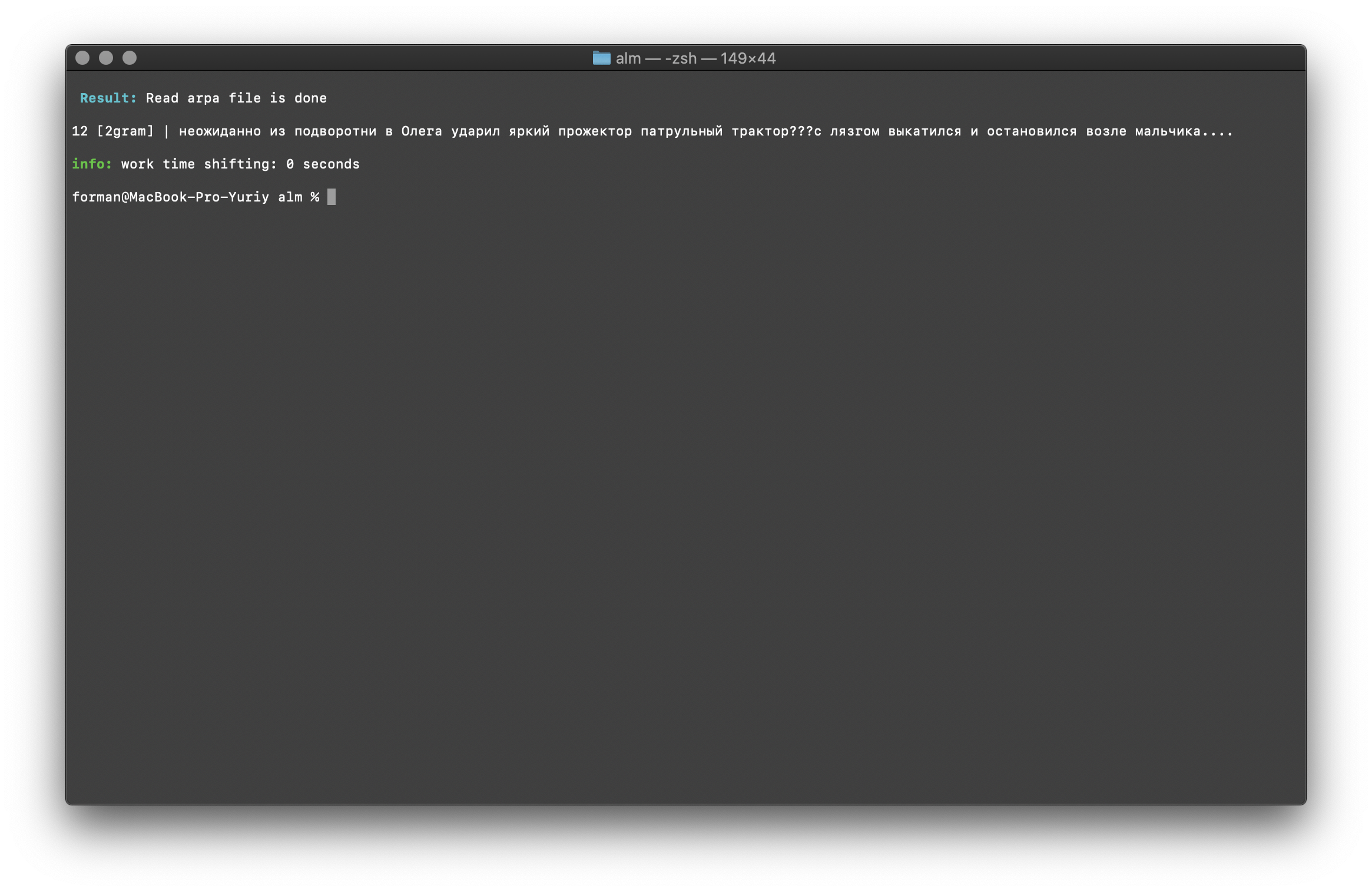 Uji:
Uji: ??? ....
Hasil:12 [2gram] | ??? ….
Pemeriksaan Trigram
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams trigram -debug 1 -r-arpa ./lm.arpa -confidence
Uji: ??? ....
Hasil:10 [3gram] | ??? ….
Cari N-gram dalam bentuk teks
$ echo " " | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method find -debug 1 -r-arpa ./lm.arpa -confidence
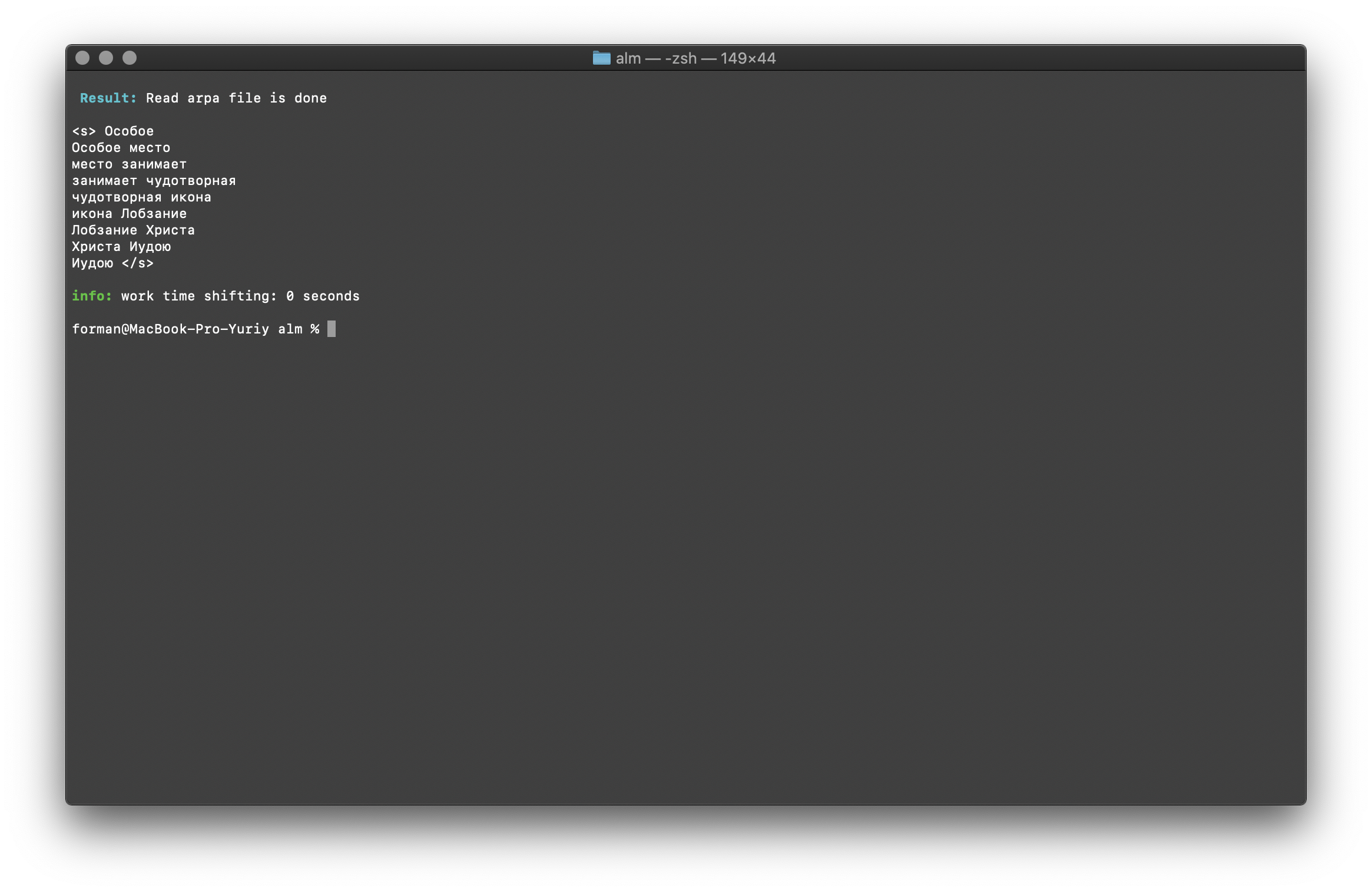 Uji:
Uji:
Hasil:<s>
</s>
Daftar N-gram yang ditemukan dalam teks. Tidak ada yang istimewa untuk dijelaskan di sini.Variabel lingkungan
Semua parameter dapat dilewatkan melalui variabel lingkungan. Variabel dimulai dengan awalan ALM_ dan harus ditulis dalam huruf besar. Kalau tidak, nama variabel sesuai dengan parameter aplikasi.Jika parameter aplikasi dan variabel lingkungan ditentukan, maka parameter aplikasi diberikan prioritas.$ export $ALM_SMOOTHING=wittenbell
$ export $ALM_W-ARPA=./lm.arpa
Dengan demikian, proses perakitan bisa otomatis. Misalnya, melalui skrip BASH.Kesimpulan
Saya mengerti bahwa ada teknologi yang lebih menjanjikan seperti RnnLM atau Bert . Tetapi saya yakin bahwa model statistik N-gram akan relevan untuk waktu yang lama.Pekerjaan ini membutuhkan banyak waktu dan usaha. Dia terlibat di perpustakaan di waktu luangnya dari pekerjaan dasar, di malam hari dan di akhir pekan. Kode tidak mencakup pengujian, kesalahan dan bug dimungkinkan. Saya akan berterima kasih untuk pengujian. Saya juga terbuka untuk saran untuk peningkatan dan fungsionalitas perpustakaan baru. ALM didistribusikan di bawah lisensi MIT , yang memungkinkan Anda untuk menggunakannya hampir tanpa batasan.Berharap mendapat komentar, kritik, saran.Situs proyek Gudang proyek