Apa yang harus saya lakukan jika saya ingin menuliskan banyak "fakta" dalam database dengan volume yang jauh lebih besar daripada yang bisa ditahan? Pertama, tentu saja, kami membawa data ke bentuk normal yang lebih ekonomis dan mendapatkan "kamus", yang akan kami tulis satu kali . Tetapi bagaimana cara melakukannya paling efektif?Ini persis pertanyaan yang kami hadapi ketika mengembangkan pemantauan dan analisis log server PostgreSQL , ketika metode lain untuk mengoptimalkan catatan dalam database habis.Segera buat reservasi bahwa kolektor kami menjalankan Node.js , jadi kami tidak berinteraksi dengan register dan cache prosesor. Dan opsi untuk menggunakan "seratus" atau layanan / basis data caching eksternal memberi terlalu banyak penundaan untuk aliran masuk beberapa ratus Mbps .Oleh karena itu, kami mencoba untuk men - cache semuanya dalam RAM , khususnya dalam memori proses JavaScript. Tentang cara mengatur ini lebih efisien, dan kami akan melangkah lebih jauh.Caching Ketersediaan
Tugas utama kami adalah memastikan bahwa satu-satunya instance dari objek apa pun masuk ke database. Ini adalah teks asli berulang dari query SQL, template rencana untuk implementasi mereka , node dari rencana ini - singkatnya, beberapa blok teks .Secara historis, sebagai pengidentifikasi kami menggunakan UUIDnilai-, yang diperoleh sebagai hasil perhitungan langsung hash MD5 dari teks objek. Setelah itu, kami memeriksa ketersediaan hash semacam itu di "kamus" lokal di memori proses , dan jika tidak ada di sana, hanya kemudian kami menulis dalam database di tabel "kamus".Artinya, kita tidak perlu menyimpan nilai teks asli itu sendiri (dan kadang-kadang dibutuhkan puluhan kilobyte) - cukup fakta bahwa keberadaan hash yang sesuai dalam kamus sudah cukup .Kamus Kunci
Kamus semacam itu dapat disimpan Array, dan digunakan Array.includes()untuk memeriksa ketersediaan, tetapi ini cukup berlebihan - pencarian menurun (setidaknya dalam versi V8 sebelumnya) secara linear dari ukuran array, O (N). Dan dalam implementasi modern, terlepas dari semua optimasi, ia kehilangan kecepatan 2-3%.Oleh karena itu, di era pra-ES6, penyimpanan adalah solusi tradisional Object, dengan nilai yang disimpan sebagai kunci. Tetapi semua orang menetapkan nilai kunci apa yang dia inginkan - misalnya Boolean,:var dict = {};
function has(key) {
return dict[key] !== undefined;
}
function add(key) {
dict[key] = true;
}
Tetapi cukup jelas bahwa kami jelas menyimpan kelebihan di sini - nilai kunci yang tidak diperlukan siapa pun. Tetapi bagaimana jika itu tidak disimpan sama sekali? Jadi objek Set muncul .Tes menunjukkan bahwa pencarian dengan bantuan Set.has()sekitar 20-25% lebih cepat daripada verifikasi kunci c Object. Tapi ini bukan satu-satunya keuntungannya. Karena kita menyimpan lebih sedikit, maka kita perlu lebih sedikit memori - dan ini secara langsung mempengaruhi kinerja ketika menyangkut ratusan ribu kunci semacam itu.Jadi, Objectdi mana terdapat 100 kunci UUID dalam representasi teks, ia menempati 6216 byte dalam memori :
Setdengan konten yang sama - 2632 byte :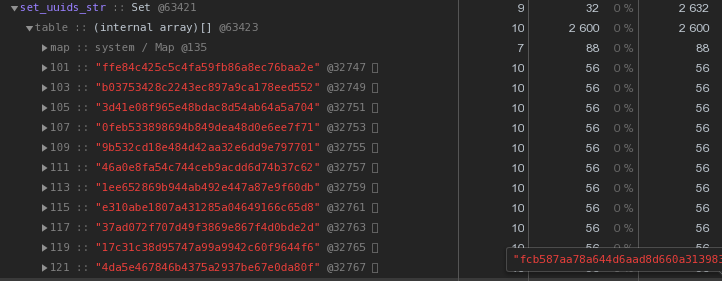 Artinya, ia
Artinya, ia Setbekerja lebih cepat dan pada saat yang sama membutuhkan2,5 kali lebih sedikit memori - pemenangnya jelas.Kami mengoptimalkan penyimpanan kunci UUID
Secara umum, dalam sifat sistem terdistribusi, kunci UUID cukup umum - dalam VLSI kami , paling tidak, digunakan untuk mengidentifikasi dokumen dan peraturan dalam manajemen dokumen elektronik , orang dalam pengiriman pesan , ...Sekarang mari kita perhatikan dengan cermat gambar di atas - setiap UUID- kunci yang disimpan dalam representasi hex "biaya" kami 56 byte memori . Tetapi kami memiliki ratusan ribu dari mereka, jadi masuk akal untuk bertanya: "Apakah mungkin memiliki lebih sedikit?"Pertama, ingat bahwa UUID adalah pengidentifikasi 16-byte. Pada dasarnya sepotong data biner. Dan untuk transmisi melalui email, misalnya, data biner dikodekan dalam base64 - cobalah untuk menerapkannya:let str = Buffer.from(uuidstr, 'hex').toString('base64');
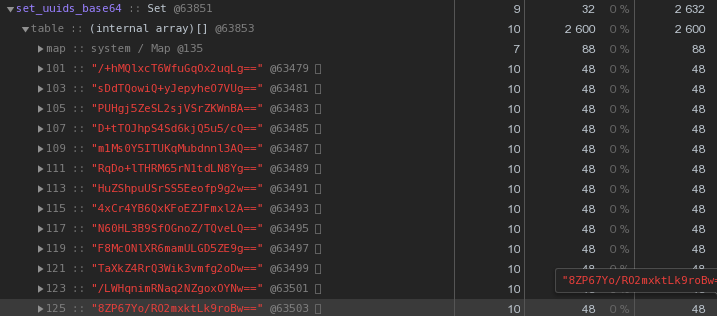 Masing-masing sudah 48 byte lebih baik, tetapi tidak sempurna. Mari kita coba menerjemahkan representasi heksadesimal langsung menjadi string:
Masing-masing sudah 48 byte lebih baik, tetapi tidak sempurna. Mari kita coba menerjemahkan representasi heksadesimal langsung menjadi string:let str = Buffer.from(uuidstr, 'hex').toString('binary');
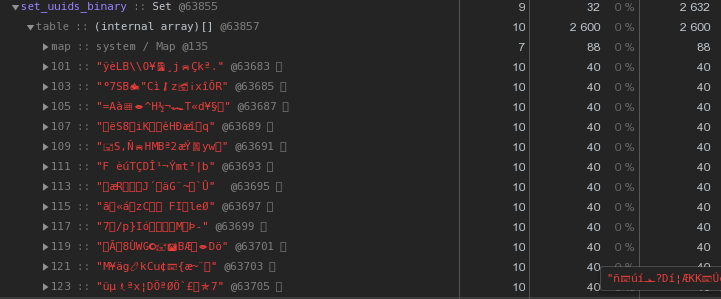 Alih-alih 56 byte per kunci - 40 byte, hemat hampir 30% !
Alih-alih 56 byte per kunci - 40 byte, hemat hampir 30% !Master, pekerja - di mana menyimpan kamus?
Mempertimbangkan bahwa data kosa kata dari pekerja berpotongan cukup kuat, kami membuat penyimpanan kamus dan menulisnya ke database dalam proses master, dan transfer data dari pekerja melalui mekanisme pesan IPC .Namun, sebagian besar dari waktu master dihabiskan untuk channel.onread- yaitu, memproses penerimaan paket dengan informasi "kamus" dari proses anak: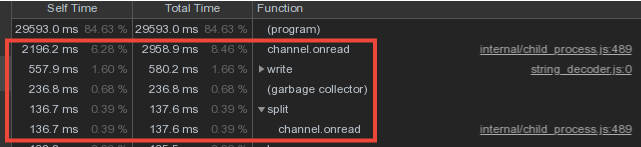
Penghalang Tulis Set Ganda
Sekarang mari kita berpikir sejenak - para pekerja mengirim dan mengirim master data kosa kata yang sama (pada dasarnya ini adalah templat rencana dan badan permintaan yang berulang), dia mem-parsing mereka dengan keringatnya dan ... tidak melakukan apa-apa, karena mereka telah dikirim ke database sebelumnya !Jadi jika kita Set"melindungi" database dari perekaman ulang dari master dengan kamus, mengapa tidak menggunakan pendekatan yang sama untuk "melindungi" master dari transfer dari pekerja? ..Sebenarnya, itu dilakukan, dan mengurangi biaya langsung untuk melayani saluran pertukaran tiga kali :
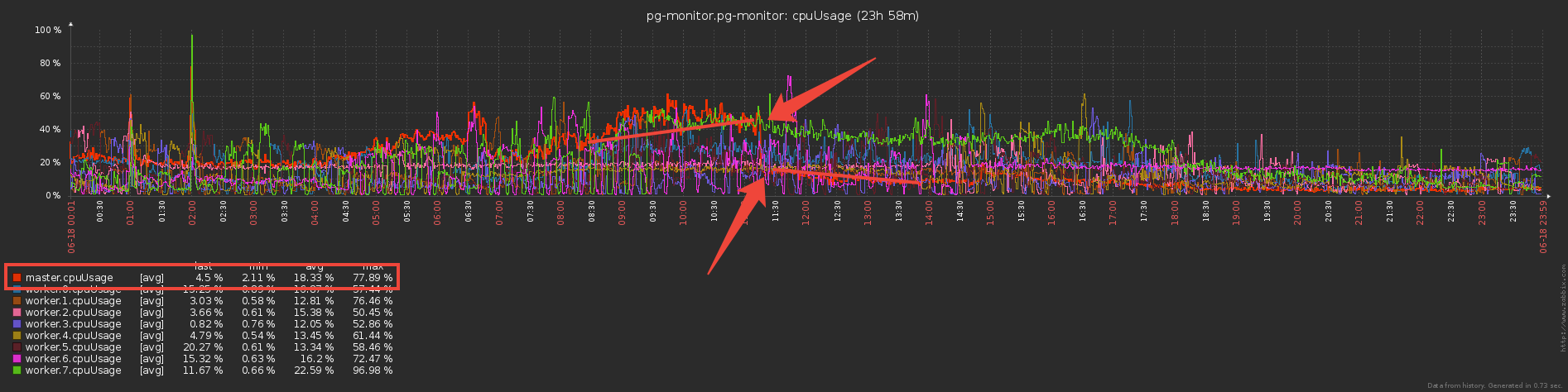 Tapi sekarang para pekerja tampaknya lebih banyak bekerja - menyimpan kamus dan menyaringnya? Atau tidak? ... Sebenarnya, mereka mulai bekerja secara signifikan lebih sedikit, karena transfer volume besar (bahkan melalui IPC!) Tidak murah.
Tapi sekarang para pekerja tampaknya lebih banyak bekerja - menyimpan kamus dan menyaringnya? Atau tidak? ... Sebenarnya, mereka mulai bekerja secara signifikan lebih sedikit, karena transfer volume besar (bahkan melalui IPC!) Tidak murah.Bonus bagus
Ketika penyihir sekarang mulai menerima jumlah informasi yang jauh lebih kecil, ia mulai mengalokasikan lebih sedikit memori untuk wadah ini - yang berarti bahwa waktu yang dihabiskan untuk pekerjaan Pengumpul Sampah menurun secara signifikan, yang secara positif mempengaruhi latensi sistem secara keseluruhan.Skema semacam itu memberikan perlindungan terhadap entri yang berulang di tingkat kolektor, tetapi bagaimana jika kita memiliki beberapa kolektor? Hanya pemicu dengan yang akan membantu di sini INSERT ... ON CONFLICT DO NOTHING.Mempercepat perhitungan hash
Dalam arsitektur kami, seluruh aliran log dari satu server PostgreSQL diproses oleh satu pekerja.Artinya, satu server adalah satu tugas untuk pekerja. Pada saat yang sama, pemuatan pekerja diimbangi dengan tujuan tugas server sehingga konsumsi CPU oleh pekerja dari semua kolektor kurang lebih sama. Ini adalah operator layanan terpisah.“Rata-rata,” setiap pekerja menangani lusinan tugas yang menghasilkan kira-kira beban total yang sama. Namun, ada server yang secara signifikan melampaui sisanya dalam jumlah entri log. Dan bahkan jika pengirim meninggalkan tugas ini satu-satunya pada pekerja, unduhannya jauh lebih tinggi daripada yang lain:Kami menghapus profil CPU pekerja ini: Di baris teratas, perhitungan hash MD5. Dan mereka benar-benar menghitung jumlah yang besar - untuk seluruh aliran objek yang masuk.
Di baris teratas, perhitungan hash MD5. Dan mereka benar-benar menghitung jumlah yang besar - untuk seluruh aliran objek yang masuk.xxHash
Bagaimana mengoptimalkan bagian ini, kecuali untuk hash ini, kita tidak bisa?Kami memutuskan untuk mencoba fungsi hash lain - xxHash , yang mengimplementasikan algoritma hash non-cryptographic yang sangat cepat . Dan modul untuk Node.js adalah xxhash-addon , yang menggunakan versi terbaru dari pustaka xxHash 0.7.3 dengan algoritma XXH3 yang baru.Periksa dengan menjalankan setiap opsi pada satu set baris dengan panjang berbeda:const crypto = require('crypto');
const { XXHash3, XXHash64 } = require('xxhash-addon');
const hasher3 = new XXHash3(0xDEADBEAF);
const hasher64 = new XXHash64(0xDEADBEAF);
const buf = Buffer.allocUnsafe(16);
const getBinFromHash = (hash) => buf.fill(hash, 'hex').toString('binary');
const funcs = {
xxhash64 : (str) => hasher64.hash(Buffer.from(str)).toString('binary')
, xxhash3 : (str) => hasher3.hash(Buffer.from(str)).toString('binary')
, md5 : (str) => getBinFromHash(crypto.createHash('md5').update(str).digest('hex'))
};
const check = (hash) => {
let log = [];
let cnt = 10000;
while (cnt--) log.push(crypto.randomBytes(cnt).toString('hex'));
console.time(hash);
log.forEach(funcs[hash]);
console.timeEnd(hash);
};
Object.keys(funcs).forEach(check);
Hasil:xxhash64 : 148.268ms
xxhash3 : 108.337ms
md5 : 317.584ms
Seperti yang diharapkan , xxhash3 jauh lebih cepat daripada MD5 !Masih untuk memeriksa resistensi terhadap tabrakan. Bagian-bagian dari tabel kamus sedang dibuat untuk kita setiap hari, jadi di luar batas hari kita dapat dengan aman membiarkan persimpangan hash.Tapi untuk berjaga-jaga, kami memeriksa dengan margin dalam interval tiga hari - tidak ada satu konflik pun yang cocok untuk kami lebih dari cukup.Penggantian Hash
Tapi kami tidak bisa mengambil dan menukar bidang UUID lama di tabel kamus dengan hash baru, karena basis data dan frontend yang ada menunggu objek untuk terus diidentifikasi oleh UUID.Karena itu, kami akan menambahkan satu cache lagi ke kolektor - untuk MD5 yang sudah dihitung. Sekarang akan menjadi Peta , di mana kuncinya adalah xxhash3, nilainya MD5. Untuk baris yang identik, kami tidak menghitung MD5 "mahal" lagi, tetapi mengambilnya dari cache:const getHashFromBin = (bin) => Buffer.from(bin, 'binary').toString('hex');
const dictmd5 = new Map();
const getmd5 = (data) => {
const hash = xxhash(data);
let md5hash = dictmd5.get(hash);
if (!md5hash) {
md5hash = md5(data);
dictmd5.set(hash, getBinFromHash(md5hash));
return md5hash;
}
return getHashFromBin(md5hash);
};
Kami menghapus profil - sebagian kecil dari waktu untuk menghitung hash telah menurun secara nyata, tepuk tangan! Jadi sekarang kita hitung xxhash3, lalu periksa cache MD5 dan dapatkan MD5 yang diinginkan, lalu periksa cache kamus - jika md5 ini tidak ada, maka kirim ke database untuk menulis.Sesuatu yang terlalu banyak diperiksa ... Mengapa memeriksa cache kamus jika Anda telah memeriksa cache MD5? Ternyata semua cache kamus tidak lagi diperlukan dan cukup hanya memiliki satu cache - untuk MD5, yang dengannya semua operasi dasar akan dilakukan:
Jadi sekarang kita hitung xxhash3, lalu periksa cache MD5 dan dapatkan MD5 yang diinginkan, lalu periksa cache kamus - jika md5 ini tidak ada, maka kirim ke database untuk menulis.Sesuatu yang terlalu banyak diperiksa ... Mengapa memeriksa cache kamus jika Anda telah memeriksa cache MD5? Ternyata semua cache kamus tidak lagi diperlukan dan cukup hanya memiliki satu cache - untuk MD5, yang dengannya semua operasi dasar akan dilakukan: Sebagai hasilnya, kami mengganti cek di beberapa kamus "objek" dengan satu cache MD5, dan operasi penghitungan sumber daya yang intensif dari MD5 adalah Hash dilakukan hanya untuk entri baru, menggunakan xxhash yang jauh lebih efisien untuk aliran masuk.terima kasihKilor untuk bantuan dalam mempersiapkan artikel.
Sebagai hasilnya, kami mengganti cek di beberapa kamus "objek" dengan satu cache MD5, dan operasi penghitungan sumber daya yang intensif dari MD5 adalah Hash dilakukan hanya untuk entri baru, menggunakan xxhash yang jauh lebih efisien untuk aliran masuk.terima kasihKilor untuk bantuan dalam mempersiapkan artikel.