Pelanggan yang terhormat! Anda mungkin sudah tahu bahwa kami telah meluncurkan kursus baru, "Computer Vision," yang akan memulai kelas dalam beberapa hari mendatang. Untuk mengantisipasi dimulainya kelas, kami menyiapkan terjemahan lain yang menarik untuk dibenamkan di dunia CV.
Hobi saya bermain papan permainan, dan karena saya sedikit terbiasa dengan jaringan saraf convolutional, saya memutuskan untuk membuat aplikasi yang dapat mengalahkan seseorang dalam permainan kartu. Saya ingin membangun model dari awal menggunakan dataset saya sendiri dan melihat seberapa baik kerjanya dengan dataset kecil. Saya memutuskan untuk memulai dengan permainan Dobble yang sederhana (juga dikenal sebagai Spot it!).Jika Anda tidak tahu apa itu Dobble, saya akan secara singkat mengingat aturan permainan: Dobble adalah permainan pengenalan pola sederhana di mana para pemain mencoba menemukan gambar yang digambarkan secara bersamaan pada dua kartu. Setiap kartu dalam permainan Dobble asli berisi delapan karakter yang berbeda, dan pada kartu yang berbeda ukurannya berbeda. Dua kartu hanya memiliki satu simbol yang sama. Jika Anda menemukan simbolnya lebih dulu, ambil kartu. Ketika setumpuk 55 kartu berakhir, kartu dengan kartu terbanyak menang. Cobalah sendiri: Simbol apa yang umum untuk kedua kartu ini?
Cobalah sendiri: Simbol apa yang umum untuk kedua kartu ini?Di mana untuk memulai?
Langkah pertama dalam menyelesaikan tugas analisis data adalah mengumpulkan data. Saya mengambil enam foto dari masing-masing kartu di telepon. Total 330 foto ternyata. Empat di antaranya Anda lihat di bawah. Anda mungkin bertanya, apakah ini cukup untuk membuat jaringan saraf convolutional yang bagus? Kami akan kembali ke sini!
Pengolahan citra
OKE, data yang kita miliki, selanjutnya apa? Mungkin bagian terpenting di jalan menuju sukses: pemrosesan gambar. Kita perlu mendapatkan karakter dari setiap gambar. Beberapa kesulitan menunggu kita di sini. Dalam foto di atas, terlihat bahwa beberapa karakter lebih sulit untuk dibedakan daripada yang lain: manusia salju dan hantu (di foto ketiga) dan jarum (di keempat) warna terang, dan noda (di foto kedua) dan tanda seru (di foto keempat) terdiri dari beberapa bagian . Untuk memproses karakter ringan, kami akan menambahkan kontras. Setelah itu kami akan mengubah ukuran dan menyimpan gambar.Tambahkan kontras
Untuk menambahkan kontras, kami menggunakan ruang warna Lab. L adalah cahaya, a adalah komponen berwarna dalam rentang dari hijau ke magenta, dan b adalah komponen berwarna dalam kisaran dari biru ke kuning. Kita dapat dengan mudah mengekstrak komponen ini menggunakan OpenCV :import cv2
import imutils
imgname = 'picture1'
image = cv2.imread(f’{imgname}.jpg’)
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
l, a, b = cv2.split(lab)
 Dari kiri ke kanan: gambar asli, komponen lightness, komponen a, dan komponen bSekarang kita menambahkan kontras pada komponen lightness, sekali lagi gabungkan semua komponen menjadi satu dan ubah menjadi gambar normal:
Dari kiri ke kanan: gambar asli, komponen lightness, komponen a, dan komponen bSekarang kita menambahkan kontras pada komponen lightness, sekali lagi gabungkan semua komponen menjadi satu dan ubah menjadi gambar normal:clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8,8))
cl = clahe.apply(l)
limg = cv2.merge((cl,a,b))
final = cv2.cvtColor(limg, cv2.COLOR_LAB2BGR)
 Dari kiri ke kanan: gambar asli, komponen terang, gambar dengan kontras tinggi dan gambar dikonversi kembali ke RGB
Dari kiri ke kanan: gambar asli, komponen terang, gambar dengan kontras tinggi dan gambar dikonversi kembali ke RGBUbah ukuran
Sekarang ubah ukuran dan simpan gambar:resized = cv2.resize(final, (800, 800))
# save the image
cv2.imwrite(f'{imgname}processed.jpg', blurred)
Selesai!Pengenalan kartu dan karakter
Sekarang setelah gambar diproses, kami dapat mendeteksi kartu dalam gambar. Menggunakan OpenCV kami mencari kontur eksternal. Lalu kami mengonversi gambar menjadi halftones, pilih nilai ambang (dalam kasus kami, 190) untuk membuat gambar hitam-putih dan mencari jalur. Kode:image = cv2.imread(f’{imgname}processed.jpg’)
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 190, 255, cv2.THRESH_BINARY)[1]
# find contours
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
output = image.copy()
# draw contours on image
for c in cnts:
cv2.drawContours(output, [c], -1, (255, 0, 0), 3)
 Gambar yang diproses dikonversi menjadi halftone menggunakan ambang batas dan memilih kontur eksternalJika kita mengurutkan kontur eksternal berdasarkan area, kita akan menemukan kontur dengan area terbesar - ini akan menjadi kartu kita. Untuk mengekstrak karakter kita dapat membuat latar belakang putih.
Gambar yang diproses dikonversi menjadi halftone menggunakan ambang batas dan memilih kontur eksternalJika kita mengurutkan kontur eksternal berdasarkan area, kita akan menemukan kontur dengan area terbesar - ini akan menjadi kartu kita. Untuk mengekstrak karakter kita dapat membuat latar belakang putih.# sort by area, grab the biggest one
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[0]
# create mask with the biggest contour
mask = np.zeros(gray.shape,np.uint8)
mask = cv2.drawContours(mask, [cnts], -1, 255, cv2.FILLED)
# card in foreground
fg_masked = cv2.bitwise_and(image, image, mask=mask)
# white background (use inverted mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
# combine back- and foreground
final = cv2.bitwise_or(fg_masked, bk_masked)
 Topeng, latar belakang, gambar latar depan, gambar akhirSekarang saatnya untuk pengenalan karakter! Kita dapat menggunakan gambar yang dihasilkan untuk mendeteksi kontur eksternal lagi, kontur ini akan menjadi simbol. Jika kita membuat kotak di sekitar setiap simbol, kita dapat mengekstrak area ini. Di sini kodenya sedikit lebih lama:
Topeng, latar belakang, gambar latar depan, gambar akhirSekarang saatnya untuk pengenalan karakter! Kita dapat menggunakan gambar yang dihasilkan untuk mendeteksi kontur eksternal lagi, kontur ini akan menjadi simbol. Jika kita membuat kotak di sekitar setiap simbol, kita dapat mengekstrak area ini. Di sini kodenya sedikit lebih lama:
gray = cv2.cvtColor(final, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 195, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.bitwise_not(thresh)
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:10]
i = 0
for c in cnts:
if cv2.contourArea(c) > 1000:
mask = np.zeros(gray.shape, np.uint8)
mask = cv2.drawContours(mask, [c], -1, 255, cv2.FILLED)
fg_masked = cv2.bitwise_and(image, image, mask=mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
finalcont = cv2.bitwise_or(fg_masked, bk_masked)
output = finalcont.copy()
x,y,w,h = cv2.boundingRect(c)
if w < h:
x += int((w-h)/2)
w = h
else:
y += int((h-w)/2)
h = w
roi = finalcont[y:y+h, x:x+w]
roi = cv2.resize(roi, (400,400))
cv2.imwrite(f"{imgname}_icon{i}.jpg", roi)
i += 1
 Gambar hitam dan putih (ambang batas), garis besar yang terdeteksi, simbol hantu dan simbol jantung (karakter diekstraksi dengan topeng)
Gambar hitam dan putih (ambang batas), garis besar yang terdeteksi, simbol hantu dan simbol jantung (karakter diekstraksi dengan topeng)Sortir karakter
Dan sekarang yang paling membosankan! Anda perlu mengurutkan karakter. Anda memerlukan direktori kereta, tes, dan validasi, masing-masing 57 direktori (kami memiliki total 57 karakter yang berbeda). Struktur folder adalah sebagai berikut:symbols
├── test
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
├── train
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
└── validation
├── anchor
├── apple
│ ...
└── zebra
Diperlukan waktu untuk meletakkan karakter yang diekstraksi (lebih dari 2500 lembar) di direktori yang diperlukan! Saya memiliki kode untuk membuat subfolder, test suite, dan kit validasi di GitHub . Mungkin lain kali lebih baik melakukan pengurutan berdasarkan algoritma pengelompokan ...Pelatihan jaringan saraf convolutional
Setelah bagian yang membosankan, kesenangan datang lagi! Sudah waktunya untuk membuat dan melatih jaringan saraf convolutional. Anda dapat menemukan informasi tentang jaringan saraf convolutional di sini .Arsitektur model
Kami memiliki tugas klasifikasi multi-kelas dengan satu label. Untuk setiap karakter kita membutuhkan satu label. Itu sebabnya kita memerlukan fungsi untuk mengaktifkan lapisan softmax output dengan 57 node dan entropi lintas kategori sebagai fungsi kerugian.Arsitektur model akhir adalah sebagai berikut:
from keras import layers
from keras import models
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(400, 400, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(57, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
Augmentasi Data
Untuk meningkatkan kinerja, saya menggunakan augmentasi data. Augmentasi data adalah proses peningkatan volume dan ragam input data. Ini dapat dilakukan dengan memutar, menggeser, mengubah skala, memotong dan membalik gambar yang ada. Keras dapat dengan mudah menambah data:
train_dir = 'symbols/train'
validation_dir = 'symbols/validation'
test_dir = 'symbols/test'
train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=40, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.1, zoom_range=0.1, horizontal_flip=True, vertical_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(validation_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
Jika Anda tertarik, hantu yang diperbesar terlihat seperti ini: Gambar asli hantu di sebelah kiri, hantu yang diperbesar di semua gambar lainnya
Gambar asli hantu di sebelah kiri, hantu yang diperbesar di semua gambar lainnyaPelatihan model
Mari kita latih modelnya, simpan untuk digunakan untuk prediksi, dan periksa hasilnya.history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)
model.save('models/model.h5')
 Prediksi sempurna!
Prediksi sempurna!hasil
Model dasar yang saya latih tanpa augmentasi data, putus sekolah dan dengan lebih sedikit lapisan. Model ini memberikan hasil sebagai berikut: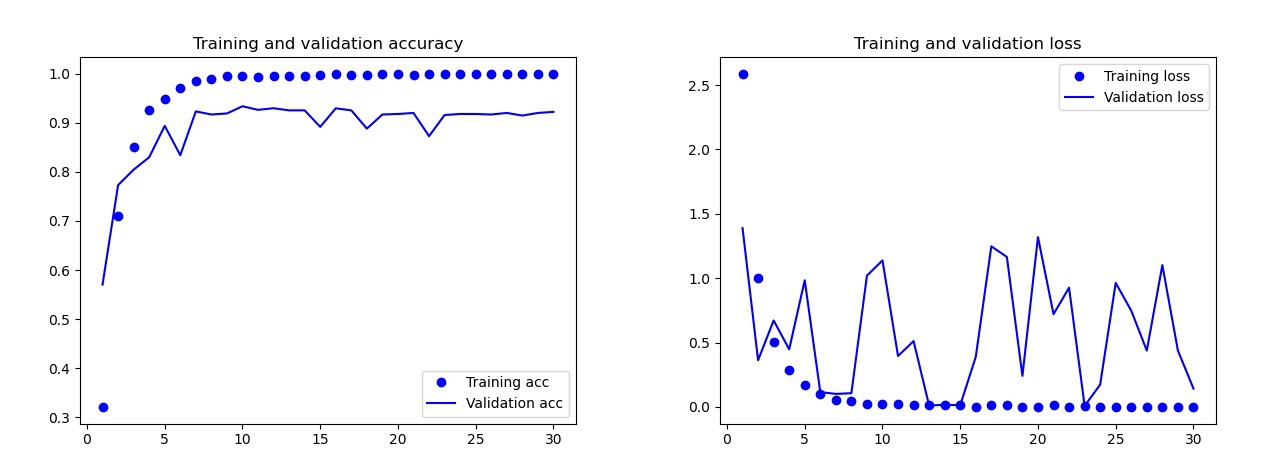 Hasil model dasarDengan mata telanjang, jelas bahwa model ini dilatih ulang. Hasil versi final dari model (kodenya disajikan pada bagian sebelumnya) jauh lebih baik. Pada grafik di bawah ini Anda dapat melihat keakuratan dan kerugian selama pelatihan dan pada set validasi.
Hasil model dasarDengan mata telanjang, jelas bahwa model ini dilatih ulang. Hasil versi final dari model (kodenya disajikan pada bagian sebelumnya) jauh lebih baik. Pada grafik di bawah ini Anda dapat melihat keakuratan dan kerugian selama pelatihan dan pada set validasi. Hasil dari model terakhirPada set tes, model ini hanya membuat satu kesalahan, ia mengakui bom sebagai drop. Saya memutuskan untuk tetap menggunakan model ini, akurasi pada set tes adalah 0,995.
Hasil dari model terakhirPada set tes, model ini hanya membuat satu kesalahan, ia mengakui bom sebagai drop. Saya memutuskan untuk tetap menggunakan model ini, akurasi pada set tes adalah 0,995.Pengakuan simbol umum pada dua kartu
Sekarang Anda dapat mulai mencari simbol umum pada dua kartu. Kami menggunakan dua foto, kami akan membuat prediksi untuk setiap gambar secara terpisah dan menggunakan persimpangan set untuk mengetahui simbol mana yang ada di kedua kartu. Kami memiliki 3 opsi kerja:- Terjadi kesalahan selama prediksi: tidak ada karakter yang ditemukan.
- Ada satu simbol di persimpangan (prediksi bisa benar atau salah).
- Ada lebih dari satu karakter di persimpangan. Dalam hal ini, saya memilih simbol dengan probabilitas tertinggi (rata-rata dari kedua prediksi).
Kode untuk memprediksi semua kombinasi pada dua gambar dalam katalog kebohongan dengan GitHub 's main.py.Dan inilah hasilnya:
Kesimpulan
Bukankah itu model yang sempurna? Sayangnya tidak ada. Ketika saya mengambil foto baru kartu-kartu itu dan memberi mereka model untuk prediksi, ada beberapa masalah dengan manusia salju itu. Terkadang dia mengenali mata atau zebra sebagai manusia salju! Akibatnya, terkadang hasilnya aneh: Ya, di mana manusia salju di sini?Apakah model ini lebih baik daripada manusia? Bergantung pada apa yang kita butuhkan: orang-orang mengenali dengan sempurna, tetapi model melakukannya dengan lebih cepat! Saya perhatikan waktu di mana komputer mengatasi: Saya memberi setumpuk 55 kartu dan saya harus mendapatkan simbol umum untuk setiap kombinasi dua kartu. Secara total, ini adalah 1485 kombinasi. Komputer melakukannya dalam waktu kurang dari 140 detik. Dia membuat beberapa kesalahan, tapi dia pasti akan mengalahkan siapa pun ketika datang ke kecepatan!
Ya, di mana manusia salju di sini?Apakah model ini lebih baik daripada manusia? Bergantung pada apa yang kita butuhkan: orang-orang mengenali dengan sempurna, tetapi model melakukannya dengan lebih cepat! Saya perhatikan waktu di mana komputer mengatasi: Saya memberi setumpuk 55 kartu dan saya harus mendapatkan simbol umum untuk setiap kombinasi dua kartu. Secara total, ini adalah 1485 kombinasi. Komputer melakukannya dalam waktu kurang dari 140 detik. Dia membuat beberapa kesalahan, tapi dia pasti akan mengalahkan siapa pun ketika datang ke kecepatan! Saya tidak berpikir bahwa membuat model 100% yang berfungsi itu sulit. Ini dapat dicapai melalui pelatihan transfer. Untuk memahami apa yang dilakukan model, kita dapat memvisualisasikan layer untuk gambar uji. Anda bisa melakukannya lain kali!
Saya tidak berpikir bahwa membuat model 100% yang berfungsi itu sulit. Ini dapat dicapai melalui pelatihan transfer. Untuk memahami apa yang dilakukan model, kita dapat memvisualisasikan layer untuk gambar uji. Anda bisa melakukannya lain kali!
Pelajari lebih lanjut tentang kursus dan lulus ujian masuk