 (gambar diambil dari sini )
(gambar diambil dari sini )
Hari ini kami ingin memberi tahu Anda tentang tugas post-processing hasil pengakuan bidang teks berdasarkan pengetahuan apriori bidang tersebut. Sebelumnya, kami telah menulis tentang metode koreksi lapangan berdasarkan trigram , yang memungkinkan Anda untuk memperbaiki beberapa kesalahan pengenalan kata-kata yang ditulis dalam bahasa alami. Namun, bagian penting dari dokumen penting, termasuk dokumen identifikasi, adalah bidang yang berbeda sifatnya - tanggal, angka, kode VIN mobil, nomor TIN dan SNILS, zona yang dapat dibaca mesindengan checksum mereka dan banyak lagi. Meskipun mereka tidak dapat dikaitkan dengan bidang bahasa alami, namun demikian, bidang tersebut sering memiliki beberapa, kadang-kadang tersirat, model bahasa, yang berarti bahwa beberapa algoritma koreksi juga dapat diterapkan pada bidang tersebut. Dalam posting ini, kita akan membahas dua mekanisme untuk hasil pengenalan pasca pemrosesan yang dapat digunakan untuk sejumlah besar dokumen dan tipe bidang.Model bahasa bidang dapat secara kondisional dibagi menjadi tiga komponen:- Sintaks : aturan yang mengatur struktur representasi bidang teks. Contoh: bidang "tanggal kedaluwarsa dokumen" di zona yang dapat dibaca mesin direpresentasikan sebagai tujuh digit "DDDDDDD".
- : , . : “ ” - – , 3- 4- – , 5- 6- – , 7- – .
- : , . : “ ” , , “ ”.
Memiliki informasi tentang struktur semantik dan sintaksis dokumen dan bidang yang dikenali, Anda dapat membangun algoritma khusus untuk pasca-memproses hasil pengakuan. Namun, dengan mempertimbangkan kebutuhan untuk mendukung dan mengembangkan sistem pengenalan dan kompleksitas pengembangannya, menarik untuk mempertimbangkan metode dan alat "universal" yang akan memungkinkan, dengan upaya minimal (dari pengembang), untuk membangun algoritma pasca-pemrosesan yang cukup baik yang akan bekerja dengan kelas yang luas dokumen dan bidang. Metodologi untuk mengatur dan mendukung algoritma seperti itu akan disatukan, dan hanya model bahasa yang akan menjadi komponen variabel dari struktur algoritma.Perlu dicatat bahwa pasca-pemrosesan hasil pengenalan bidang teks tidak selalu berguna, dan kadang-kadang bahkan berbahaya: jika Anda memiliki modul pengenalan garis yang cukup baik dan Anda bekerja dalam sistem kritis dengan dokumen identifikasi, maka beberapa jenis pasca-pemrosesan lebih baik untuk meminimalkan dan menghasilkan hasil "apa adanya", atau memantau dengan jelas setiap perubahan dan melaporkannya kepada klien. Namun, dalam banyak kasus, ketika diketahui bahwa dokumen tersebut valid, dan bahwa model bahasa bidang ini dapat diandalkan, penggunaan algoritma pasca-pemrosesan dapat secara signifikan meningkatkan kualitas pengakuan akhir.Jadi, artikel ini akan membahas dua metode pasca-pemrosesan yang mengklaim bersifat universal. Yang pertama didasarkan pada konverter terbatas hingga, memerlukan deskripsi model bahasa dalam bentuk mesin negara terbatas, tidak sangat mudah digunakan, tetapi lebih universal. Yang kedua lebih mudah digunakan, lebih efisien, hanya membutuhkan menulis fungsi untuk memeriksa validitas nilai bidang, tetapi juga memiliki sejumlah kelemahan.Metode Pemancar Akhir Berbobot
Model cantik dan cukup umum yang memungkinkan Anda membangun algoritma universal untuk hasil pengenalan pasca pemrosesan dijelaskan dalam karya ini . Model ini bergantung pada struktur data Transduser Berbobot Hingga Negara (WFST).WFST adalah generalisasi dari mesin negara hingga tertimbang - jika mesin negara hingga terbobot mengkode beberapa bahasa yang berbobot  (mis., Seperangkat garis tertimbang di atas alfabet tertentu
(mis., Seperangkat garis tertimbang di atas alfabet tertentu  ), lalu WFST menyandikan peta tertimbang dari bahasa di
), lalu WFST menyandikan peta tertimbang dari bahasa di  atas alfabet
atas alfabet  ke dalam bahasa di
ke dalam bahasa di  atas alfabet
atas alfabet  . Mesin negara hingga tertimbang, mengambil string di
. Mesin negara hingga tertimbang, mengambil string di  atas alfabet , memberikan bobot tertentu
atas alfabet , memberikan bobot tertentu  , sedangkan WFST, mengambil string
, sedangkan WFST, mengambil string di atas alfabet , kaitkan dengan seperangkat (mungkin tak terbatas) pasangan
di atas alfabet , kaitkan dengan seperangkat (mungkin tak terbatas) pasangan  , di mana
, di mana  garis di atas alfabet ke mana garis dikonversi , dan
garis di atas alfabet ke mana garis dikonversi , dan  merupakan bobot dari konversi tersebut. Setiap transisi dari konverter ditandai oleh dua status (di antaranya transisi dibuat), karakter input (dari alfabet ), karakter output (dari alfabet ) dan bobot transisi. Karakter kosong (string kosong) dianggap sebagai elemen dari kedua huruf. Bobot string
merupakan bobot dari konversi tersebut. Setiap transisi dari konverter ditandai oleh dua status (di antaranya transisi dibuat), karakter input (dari alfabet ), karakter output (dari alfabet ) dan bobot transisi. Karakter kosong (string kosong) dianggap sebagai elemen dari kedua huruf. Bobot string  ke konversi string
ke konversi string  adalah jumlah produk dari bobot transisi sepanjang semua jalur di mana rangkaian karakter input membentuk string , dan gabungan karakter output membentuk string., dan yang mentransfer konverter dari keadaan awal ke salah satu yang terminal.Operasi komposisi ditentukan pada WFST, yang menjadi dasar metode pasca-pemrosesan. Biarkan dua transformator diberikan
adalah jumlah produk dari bobot transisi sepanjang semua jalur di mana rangkaian karakter input membentuk string , dan gabungan karakter output membentuk string., dan yang mentransfer konverter dari keadaan awal ke salah satu yang terminal.Operasi komposisi ditentukan pada WFST, yang menjadi dasar metode pasca-pemrosesan. Biarkan dua transformator diberikan  dan
dan  , dan mengkonversi baris atas
, dan mengkonversi baris atas  ke baris atas
ke baris atas  dengan berat
dengan berat  , dan mengkonversi lebih ke baris
, dan mengkonversi lebih ke baris  atas
atas  dengan berat
dengan berat  . Kemudian konverter
. Kemudian konverter  , yang disebut komposisi konverter, mengubah string menjadi string dengan bobot
, yang disebut komposisi konverter, mengubah string menjadi string dengan bobot . Komposisi transduser adalah operasi yang mahal secara komputasional, tetapi dapat dihitung dengan malas - keadaan dan transisi dari transduser yang dihasilkan dapat dibangun pada saat mereka perlu diakses.Algoritma untuk pasca-pemrosesan hasil pengakuan berdasarkan WFST didasarkan pada tiga sumber utama informasi -
. Komposisi transduser adalah operasi yang mahal secara komputasional, tetapi dapat dihitung dengan malas - keadaan dan transisi dari transduser yang dihasilkan dapat dibangun pada saat mereka perlu diakses.Algoritma untuk pasca-pemrosesan hasil pengakuan berdasarkan WFST didasarkan pada tiga sumber utama informasi -  model hipotesis , model kesalahan,
model hipotesis , model kesalahan,  dan model bahasa
dan model bahasa  . Ketiga model disajikan dalam bentuk transduser akhir berbobot:
. Ketiga model disajikan dalam bentuk transduser akhir berbobot:- ( WFST – , ), , . ,
 , ():
, ():  ,
,  –
–  - ,
- ,  – () .
– () .  - , :
- , :  - ,
- ,  - – ,
- – ,  -
-  -
-  . - , . , .
. - , . , .
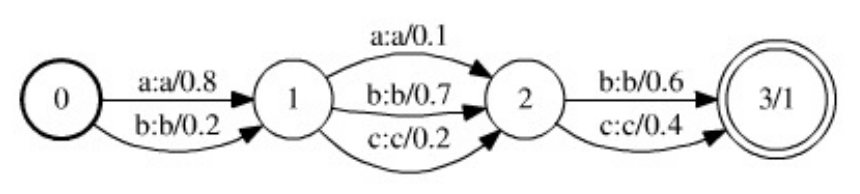
. 1. , WFST ( ). .
- , , . WFST ( ). . , .
- . .. , ( ).
Setelah mendefinisikan model hipotesis, kesalahan, dan model bahasa, tugas hasil pengakuan pasca-pemrosesan sekarang dapat diajukan sebagai berikut: pertimbangkan komposisi ketiga model  (dalam hal komposisi WFST). Konverter
(dalam hal komposisi WFST). Konverter  mengkodekan semua kemungkinan konversi string dari model hipotesis ke string dari model bahasa , menerapkan transformasi yang dikodekan dalam model kesalahan ke string . Selain itu, bobot transformasi semacam itu termasuk bobot hipotesis asli, bobot transformasi, dan bobot string yang dihasilkan (dalam kasus model bahasa berbobot). Dengan demikian, dalam model seperti itu, pasca-pemrosesan optimal dari hasil pengenalan akan sesuai dengan jalur optimal (dalam hal berat) di konvertermenerjemahkannya dari awal ke salah satu status terminal. Baris input di sepanjang jalur ini akan sesuai dengan hipotesis awal yang dipilih, dan jalur output ke hasil pengakuan yang dikoreksi. Jalur optimal dapat dicari menggunakan algoritma untuk menemukan jalur terpendek dalam grafik berarah.Keuntungan dari pendekatan ini adalah sifat umum dan fleksibilitasnya. Model kesalahan, misalnya, dapat dengan mudah diperluas sedemikian rupa dengan mempertimbangkan penghapusan dan penambahan karakter (untuk ini, hanya layak menambahkan transisi dengan output kosong atau simbol input, masing-masing, ke model kesalahan). Namun, model ini memiliki kelemahan yang signifikan. Pertama, model bahasa di sini harus disajikan sebagai transformator terbatas berbobot hingga. Untuk bahasa yang rumit, otomat semacam itu bisa menjadi agak rumit, dan jika terjadi perubahan atau penyempurnaan model bahasa, maka perlu untuk membangunnya kembali. Juga harus dicatat bahwa komposisi dari tiga transduser sebagai akibatnya, memiliki transduser yang bahkan lebih besar,dan komposisi ini dihitung setiap kali Anda mulai memproses satu hasil pengakuan. Karena besarnya komposisi, pencarian untuk jalur yang optimal dalam praktek harus dilakukan dengan metode heuristik, seperti A * -search.Dengan menggunakan model verifikasi tata bahasa, dimungkinkan untuk membangun model yang lebih sederhana dari tugas hasil pengakuan pasca-pemrosesan, yang tidak akan bersifat umum seperti model yang didasarkan pada WFST, tetapi mudah diperluas dan mudah diimplementasikan.Tata bahasa pemeriksa adalah pasangan
mengkodekan semua kemungkinan konversi string dari model hipotesis ke string dari model bahasa , menerapkan transformasi yang dikodekan dalam model kesalahan ke string . Selain itu, bobot transformasi semacam itu termasuk bobot hipotesis asli, bobot transformasi, dan bobot string yang dihasilkan (dalam kasus model bahasa berbobot). Dengan demikian, dalam model seperti itu, pasca-pemrosesan optimal dari hasil pengenalan akan sesuai dengan jalur optimal (dalam hal berat) di konvertermenerjemahkannya dari awal ke salah satu status terminal. Baris input di sepanjang jalur ini akan sesuai dengan hipotesis awal yang dipilih, dan jalur output ke hasil pengakuan yang dikoreksi. Jalur optimal dapat dicari menggunakan algoritma untuk menemukan jalur terpendek dalam grafik berarah.Keuntungan dari pendekatan ini adalah sifat umum dan fleksibilitasnya. Model kesalahan, misalnya, dapat dengan mudah diperluas sedemikian rupa dengan mempertimbangkan penghapusan dan penambahan karakter (untuk ini, hanya layak menambahkan transisi dengan output kosong atau simbol input, masing-masing, ke model kesalahan). Namun, model ini memiliki kelemahan yang signifikan. Pertama, model bahasa di sini harus disajikan sebagai transformator terbatas berbobot hingga. Untuk bahasa yang rumit, otomat semacam itu bisa menjadi agak rumit, dan jika terjadi perubahan atau penyempurnaan model bahasa, maka perlu untuk membangunnya kembali. Juga harus dicatat bahwa komposisi dari tiga transduser sebagai akibatnya, memiliki transduser yang bahkan lebih besar,dan komposisi ini dihitung setiap kali Anda mulai memproses satu hasil pengakuan. Karena besarnya komposisi, pencarian untuk jalur yang optimal dalam praktek harus dilakukan dengan metode heuristik, seperti A * -search.Dengan menggunakan model verifikasi tata bahasa, dimungkinkan untuk membangun model yang lebih sederhana dari tugas hasil pengakuan pasca-pemrosesan, yang tidak akan bersifat umum seperti model yang didasarkan pada WFST, tetapi mudah diperluas dan mudah diimplementasikan.Tata bahasa pemeriksa adalah pasangan  , di mana alfabetnya, dan
, di mana alfabetnya, dan  merupakan predikat kelayakan string di atas alfabet , mis.
merupakan predikat kelayakan string di atas alfabet , mis.  . Tata bahasa pemeriksa mengkode bahasa tertentu di atas alfabet sebagai berikut: sebuah baris
. Tata bahasa pemeriksa mengkode bahasa tertentu di atas alfabet sebagai berikut: sebuah baris  milik bahasa jika predikat mengambil nilai sebenarnya pada baris ini. Perlu dicatat bahwa memeriksa tata bahasa adalah cara yang lebih umum untuk mewakili model bahasa daripada mesin negara. Memang, bahasa apa pun direpresentasikan sebagai mesin negara yang terbatas, dapat direpresentasikan dalam bentuk tata bahasa pemeriksa (dengan predikat
milik bahasa jika predikat mengambil nilai sebenarnya pada baris ini. Perlu dicatat bahwa memeriksa tata bahasa adalah cara yang lebih umum untuk mewakili model bahasa daripada mesin negara. Memang, bahasa apa pun direpresentasikan sebagai mesin negara yang terbatas, dapat direpresentasikan dalam bentuk tata bahasa pemeriksa (dengan predikat  , di mana
, di mana  seperangkat garis diterima oleh otomat . Namun, tidak semua bahasa yang dapat direpresentasikan sebagai tata bahasa pemeriksa diwakili sebagai otomat terbatas dalam kasus umum (misalnya, bahasa kata yang panjangnya tidak terbatas) alfabet
seperangkat garis diterima oleh otomat . Namun, tidak semua bahasa yang dapat direpresentasikan sebagai tata bahasa pemeriksa diwakili sebagai otomat terbatas dalam kasus umum (misalnya, bahasa kata yang panjangnya tidak terbatas) alfabet  , di mana jumlah karakter
, di mana jumlah karakter  lebih besar dari jumlah karakter
lebih besar dari jumlah karakter  .)Biarkan hasil pengenalan (model hipotesis) diberikan sebagai urutan sel(sama seperti pada bagian sebelumnya). Untuk kenyamanan, kami berasumsi bahwa setiap sel berisi alternatif K dan semua estimasi alternatif mengambil nilai positif. Evaluasi (berat) string akan dianggap sebagai produk dari peringkat masing-masing karakter string ini. Jika model bahasa diberikan dalam bentuk tata bahasa pemeriksaan , maka masalah pasca-pemrosesan dapat dirumuskan sebagai masalah optimisasi diskrit (maksimalisasi) pada set kontrol
.)Biarkan hasil pengenalan (model hipotesis) diberikan sebagai urutan sel(sama seperti pada bagian sebelumnya). Untuk kenyamanan, kami berasumsi bahwa setiap sel berisi alternatif K dan semua estimasi alternatif mengambil nilai positif. Evaluasi (berat) string akan dianggap sebagai produk dari peringkat masing-masing karakter string ini. Jika model bahasa diberikan dalam bentuk tata bahasa pemeriksaan , maka masalah pasca-pemrosesan dapat dirumuskan sebagai masalah optimisasi diskrit (maksimalisasi) pada set kontrol  (himpunan semua garis panjang di atas alfabet ) dengan predikat kelayakan dan fungsional
(himpunan semua garis panjang di atas alfabet ) dengan predikat kelayakan dan fungsional  , di mana
, di mana  estimasi simbol
estimasi simbol  dalam sel engan .Masalah optimisasi diskrit apa pun (mis., Dengan satu set kontrol yang terbatas) dapat diselesaikan menggunakan enumerasi kontrol yang lengkap. Algoritma yang dijelaskan secara efisien beralih pada kontrol (baris) dalam mengurangi urutan nilai fungsional sampai predikat validitas menerima nilai sebenarnya. Kami menetapkan sebagai
dalam sel engan .Masalah optimisasi diskrit apa pun (mis., Dengan satu set kontrol yang terbatas) dapat diselesaikan menggunakan enumerasi kontrol yang lengkap. Algoritma yang dijelaskan secara efisien beralih pada kontrol (baris) dalam mengurangi urutan nilai fungsional sampai predikat validitas menerima nilai sebenarnya. Kami menetapkan sebagai  jumlah maksimum iterasi dari algoritma, yaitu jumlah maksimum baris dengan estimasi maksimum predikat akan dihitung.Pertama, kita semacam alternatif dalam urutan perkiraan, dan kami lebih lanjut berasumsi bahwa untuk setiap sel yang ketidaksetaraan
jumlah maksimum iterasi dari algoritma, yaitu jumlah maksimum baris dengan estimasi maksimum predikat akan dihitung.Pertama, kita semacam alternatif dalam urutan perkiraan, dan kami lebih lanjut berasumsi bahwa untuk setiap sel yang ketidaksetaraan  untuk benar
untuk benar  . Posisi akan menjadi urutan indeks yang
. Posisi akan menjadi urutan indeks yang  sesuai dengan baris
sesuai dengan baris . Evaluasi posisi, mis. nilai fungsional dalam posisi itu, mempertimbangkan penilaian alternatif produk yang sesuai dengan indeks termasuk dalam posisi:
. Evaluasi posisi, mis. nilai fungsional dalam posisi itu, mempertimbangkan penilaian alternatif produk yang sesuai dengan indeks termasuk dalam posisi:  . Untuk menyimpan posisi, Anda memerlukan struktur data PositionBase , yang memungkinkan Anda untuk menambahkan posisi baru (dengan mendapatkan alamatnya), mendapatkan posisi di alamat dan memeriksa apakah posisi yang ditentukan ditambahkan ke database.Dalam proses daftar posisi, kami akan memilih posisi yang tidak ditinjau dengan peringkat maksimum, dan kemudian menambahkan ke antrian untuk mempertimbangkan PositionQueue semua posisi yang dapat diperoleh dari posisi saat ini dengan menambahkan satu ke salah satu indeks yang termasuk dalam posisi. Antrean untuk pertimbangan PositionQueue akan berisi tiga kali lipat
. Untuk menyimpan posisi, Anda memerlukan struktur data PositionBase , yang memungkinkan Anda untuk menambahkan posisi baru (dengan mendapatkan alamatnya), mendapatkan posisi di alamat dan memeriksa apakah posisi yang ditentukan ditambahkan ke database.Dalam proses daftar posisi, kami akan memilih posisi yang tidak ditinjau dengan peringkat maksimum, dan kemudian menambahkan ke antrian untuk mempertimbangkan PositionQueue semua posisi yang dapat diperoleh dari posisi saat ini dengan menambahkan satu ke salah satu indeks yang termasuk dalam posisi. Antrean untuk pertimbangan PositionQueue akan berisi tiga kali lipat  , di mana
, di mana - evaluasi posisi yang tidak
- evaluasi posisi yang tidak  ditinjau , - alamat posisi yang dilihat di PositionBase dari mana posisi ini diperoleh,
ditinjau , - alamat posisi yang dilihat di PositionBase dari mana posisi ini diperoleh,  - indeks elemen posisi dengan alamat yang bertambah satu untuk mendapatkan posisi ini. Memposisikan sebuah antrian PositionQueue akan membutuhkan struktur data yang memungkinkan Anda untuk menambahkan tripel lainnya , serta mengambil tripel dengan peringkat maksimum .Pada iterasi pertama dari algoritma, perlu untuk mempertimbangkan posisi
- indeks elemen posisi dengan alamat yang bertambah satu untuk mendapatkan posisi ini. Memposisikan sebuah antrian PositionQueue akan membutuhkan struktur data yang memungkinkan Anda untuk menambahkan tripel lainnya , serta mengambil tripel dengan peringkat maksimum .Pada iterasi pertama dari algoritma, perlu untuk mempertimbangkan posisi  dengan estimasi maksimum. Jika predikat mengambil nilai sebenarnya pada baris yang sesuai dengan posisi ini, maka algoritme berakhir. Kalau tidak, posisi ditambahkan ke PositionBase , dan diPositionQueue menambahkan semua tiga kali lipat tampilan
dengan estimasi maksimum. Jika predikat mengambil nilai sebenarnya pada baris yang sesuai dengan posisi ini, maka algoritme berakhir. Kalau tidak, posisi ditambahkan ke PositionBase , dan diPositionQueue menambahkan semua tiga kali lipat tampilan  , untuk semua
, untuk semua  , di mana
, di mana  alamat posisi awal di PositionBase . Pada setiap iterasi algoritma berikutnya, triple dengan nilai maksimum estimasi diekstraksi dari PositionQueue , posisi yang dimaksud dikembalikan ke alamat posisi dan indeks asli . Jika posisi telah ditambahkan ke database posisi PositionBase yang dipertimbangkan , maka dilewati dan tiga berikutnya dengan nilai maksimum estimasi diekstraksi dari PositionQueue . Jika tidak, nilai predikat diperiksa pada baris yang sesuai dengan posisi . Jika predikatnyamengambil nilai sebenarnya pada baris ini, lalu algoritma berakhir. Jika predikat tidak menerima nilai sebenarnya pada baris ini, maka baris tersebut ditambahkan ke PositionBase (dengan alamat yang ditetapkan
alamat posisi awal di PositionBase . Pada setiap iterasi algoritma berikutnya, triple dengan nilai maksimum estimasi diekstraksi dari PositionQueue , posisi yang dimaksud dikembalikan ke alamat posisi dan indeks asli . Jika posisi telah ditambahkan ke database posisi PositionBase yang dipertimbangkan , maka dilewati dan tiga berikutnya dengan nilai maksimum estimasi diekstraksi dari PositionQueue . Jika tidak, nilai predikat diperiksa pada baris yang sesuai dengan posisi . Jika predikatnyamengambil nilai sebenarnya pada baris ini, lalu algoritma berakhir. Jika predikat tidak menerima nilai sebenarnya pada baris ini, maka baris tersebut ditambahkan ke PositionBase (dengan alamat yang ditetapkan  ), semua posisi turunan ditambahkan ke antrian PositionQueue , dan iterasi berikutnya dilanjutkan.
), semua posisi turunan ditambahkan ke antrian PositionQueue , dan iterasi berikutnya dilanjutkan.FindSuitableString(M, N, K, P, C[1], ..., C[N]):
i : 1 ... N:
C[i]
( )
PositionBase PositionQueue
S_1 = {1, 1, 1, ..., 1}
P(S_1):
: S_1,
( )
S_1 PositionBase R(S_1)
i : 1 ... N:
K > 1, :
<Q * q[i][2] / q[i][1], R(S_1), i> PositionQueue
( )
( )
PositionBase M:
PositionQueue:
PositionQueue <Q, R, I> Q
S_from = PositionBase R
S_curr = {S_from[1], S_from[2], ..., S_from[I] + 1, ..., S_from[N]}
S_curr PositionBase:
:
S_curr PositionBase R(S_curr)
( )
P(S_curr):
: S_curr,
( )
i : 1 ... N:
K > S_curr[i]:
<Q * q[i][S_curr[i] + 1] / q[i][S_curr[i]],
R(S_curr),
i> PositionQueue
( )
( )
( )
( )
M
Perhatikan bahwa selama iterasi predikat akan diperiksa tidak lebih dari sekali, tidak akan ada tambahan lagi pada PositionBase , dan penambahan pada PositionQueue , ekstraksi dari PositionQueue , serta pencarian di PositionBase akan terjadi tidak lebih dari  sekali. Jika implementasi PositionQueue menggunakan "banyak" struktur data, dan untuk organisasi PositionBase menggunakan struktur data "Bor", kompleksitas algoritma adalah
sekali. Jika implementasi PositionQueue menggunakan "banyak" struktur data, dan untuk organisasi PositionBase menggunakan struktur data "Bor", kompleksitas algoritma adalah  , di mana
, di mana  - uji trudoemost berpredikat pada panjang garis .Mungkin kelemahan terpenting dari algoritma berdasarkan memeriksa tata bahasa adalah bahwa ia tidak dapat memproses hipotesis dengan panjang yang berbeda (yang mungkin timbul karena kesalahan segmentasi : kehilangan atau kemunculan karakter tambahan, perekatan dan pemotongan karakter, dll.), Sedangkan perubahan hipotesis seperti "menghapus karakter", "menambahkan karakter", atau bahkan "mengganti karakter dengan pasangan" dapat dikodekan dalam model kesalahan dari algoritma berbasis WFST.Namun, kecepatan dan kemudahan penggunaan (ketika bekerja dengan jenis bidang baru, Anda hanya perlu memberikan akses algoritma ke fungsi validasi nilai) menjadikan metode berdasarkan pemeriksaan tata bahasa alat yang sangat kuat dalam gudang pengembang sistem pengenalan dokumen. Kami menggunakan pendekatan ini untuk sejumlah besar berbagai bidang, seperti berbagai tanggal, nomor kartu bank (predikat - memeriksa kode Bulan ), bidang bidang dokumen yang dapat dibaca mesin dengan checksum, dan banyak lainnya.
- uji trudoemost berpredikat pada panjang garis .Mungkin kelemahan terpenting dari algoritma berdasarkan memeriksa tata bahasa adalah bahwa ia tidak dapat memproses hipotesis dengan panjang yang berbeda (yang mungkin timbul karena kesalahan segmentasi : kehilangan atau kemunculan karakter tambahan, perekatan dan pemotongan karakter, dll.), Sedangkan perubahan hipotesis seperti "menghapus karakter", "menambahkan karakter", atau bahkan "mengganti karakter dengan pasangan" dapat dikodekan dalam model kesalahan dari algoritma berbasis WFST.Namun, kecepatan dan kemudahan penggunaan (ketika bekerja dengan jenis bidang baru, Anda hanya perlu memberikan akses algoritma ke fungsi validasi nilai) menjadikan metode berdasarkan pemeriksaan tata bahasa alat yang sangat kuat dalam gudang pengembang sistem pengenalan dokumen. Kami menggunakan pendekatan ini untuk sejumlah besar berbagai bidang, seperti berbagai tanggal, nomor kartu bank (predikat - memeriksa kode Bulan ), bidang bidang dokumen yang dapat dibaca mesin dengan checksum, dan banyak lainnya.
Publikasi disiapkan berdasarkan artikel : Algoritme universal untuk hasil pengenalan pasca-pemrosesan berdasarkan validasi tata bahasa. K.B. Bulatov, D.P. Nikolaev, V.V. Postnikov. Prosiding ISA RAS, Vol. 65, No. 4, 2015, hlm. 68-73.