Latar Belakang
Baru-baru ini, dalam kerangka kegiatan pendidikan, saya perlu menggunakan algoritma genetika lama yang baik untuk menemukan fungsi minimum dan maksimum dari dua variabel. Namun, yang mengejutkan saya, tidak ada implementasi serupa pada python di Internet, dan bagian ini tidak dibahas dalam artikel tentang algoritma genetika di Wikipedia. Jadi saya memutuskan untuk menulis paket kecil saya dengan Python dengan visualisasi algoritma, yang menurutnya akan lebih mudah untuk mengkonfigurasi algoritma ini dan mencari seluk-beluk dari model yang dipilih.Dalam artikel singkat ini, saya ingin membagikan proses, pengamatan, dan hasil.
Jadi saya memutuskan untuk menulis paket kecil saya dengan Python dengan visualisasi algoritma, yang menurutnya akan lebih mudah untuk mengkonfigurasi algoritma ini dan mencari seluk-beluk dari model yang dipilih.Dalam artikel singkat ini, saya ingin membagikan proses, pengamatan, dan hasil.Prinsip algoritma
Saya tidak akan berbicara tentang prinsip global karya algoritma genetika, tetapi jika Anda belum pernah mendengar tentang ini, maka Anda dapat membiasakan diri dengan itu di Wikipedia .Saat ini, paket hanya mengimplementasikan satu GA, yang diparameterisasi oleh data input melalui guiche sederhana. Saya akan memberi tahu Anda secara singkat tentang fungsi genetik yang dipilih dan solusi algoritmik dasar.Individu monokromosom membawa dalam setiap informasi gennya tentang koordinat x atau y yang sesuai. Suatu populasi ditentukan oleh banyak individu, tetapi populasinya dibagi menjadi 4 individu. Solusi ini, tentu saja, adalah karena upaya untuk menghindari konvergensi ke optimal lokal, karena tugasnya adalah menemukan ekstrem global. Pembagian seperti itu, seperti yang telah ditunjukkan oleh praktik, dalam banyak kasus tidak memungkinkan satu genotipe mendominasi seluruh populasi, tetapi, sebaliknya, memberikan dinamika "evolusi" yang lebih besar. Untuk setiap bagian populasi tersebut, algoritma berikut diterapkan:- Seleksi berlangsung mirip dengan metode peringkat. 3 individu dipilih dengan indikator fungsi kebugaran terbaik (mis., Individu diurutkan dalam urutan naik / turun dari fungsi yang ditetapkan oleh pengguna, yang bertindak sebagai fungsi adaptasi).
- Selanjutnya, fungsi persimpangan diterapkan sedemikian rupa sehingga generasi baru (atau lebih tepatnya segmen baru dari populasi 4 individu) menerima 2 pasang gen yang tidak diredam dari individu tersebut dengan indikasi fungsi kebugaran terbaik dan sepasang gen yang bermutasi dari dua individu lain. Lebih lanjut tentang kompilasi fungsi mutasi akan ditulis di bagian selanjutnya.
Prinsip operasi seleksi, persilangan dan mutasi jelas terlihat seperti ini (pada generasi N, kromosom individu sudah diurutkan dalam urutan yang benar, dan kotak hitam kecil berarti mutasi):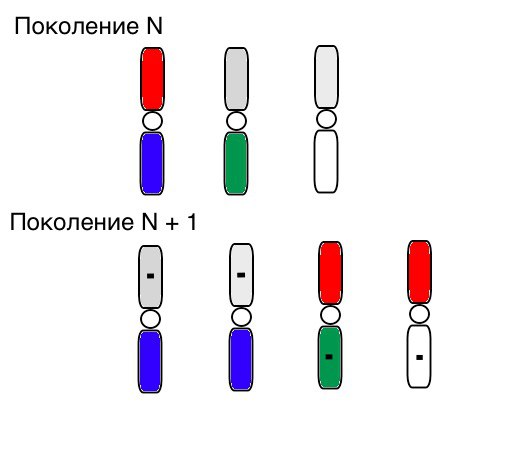
Tes dan pengamatan primer
Jadi, kami menguji algoritma ini pada dua contoh sederhana:Uji 1
 Tes 2
Tes 2

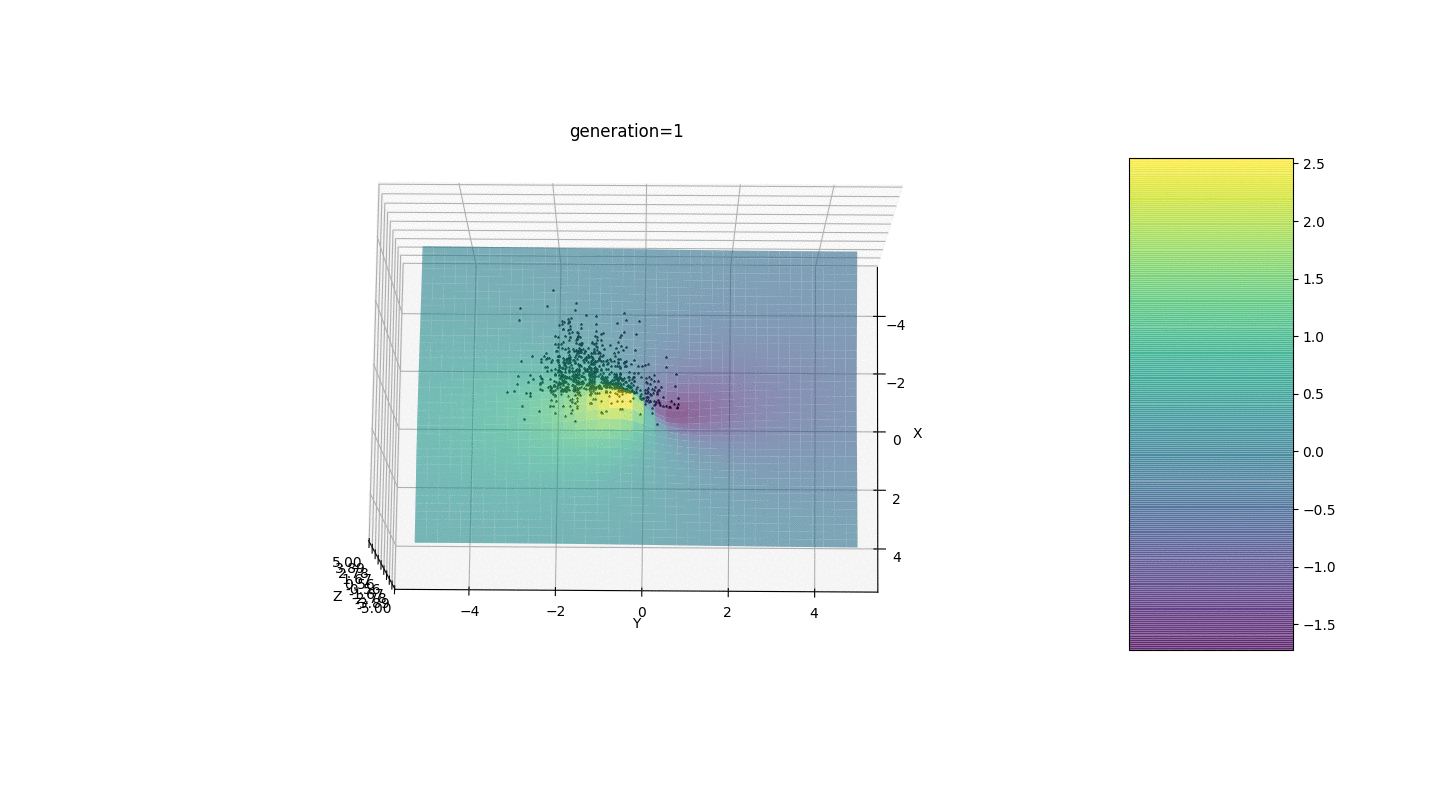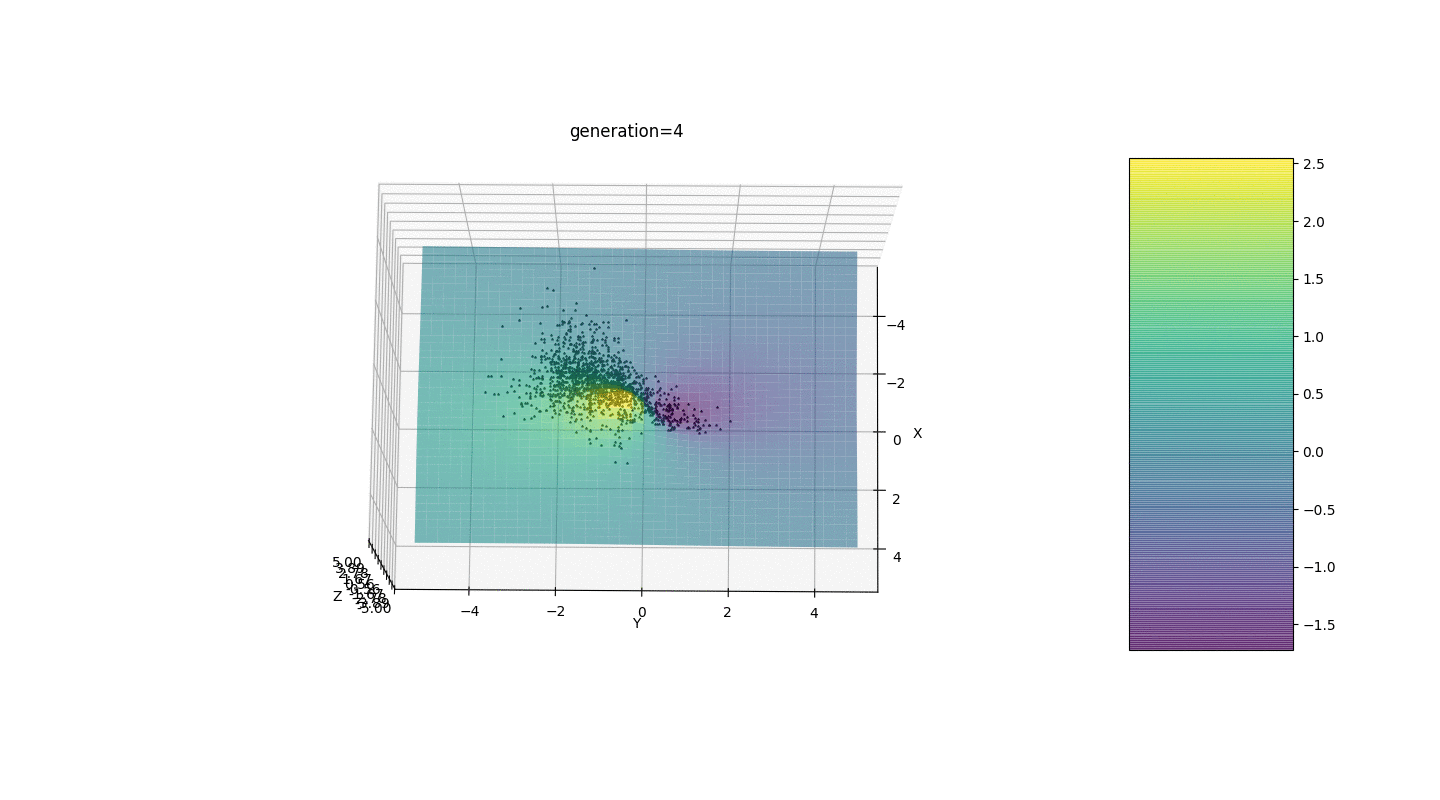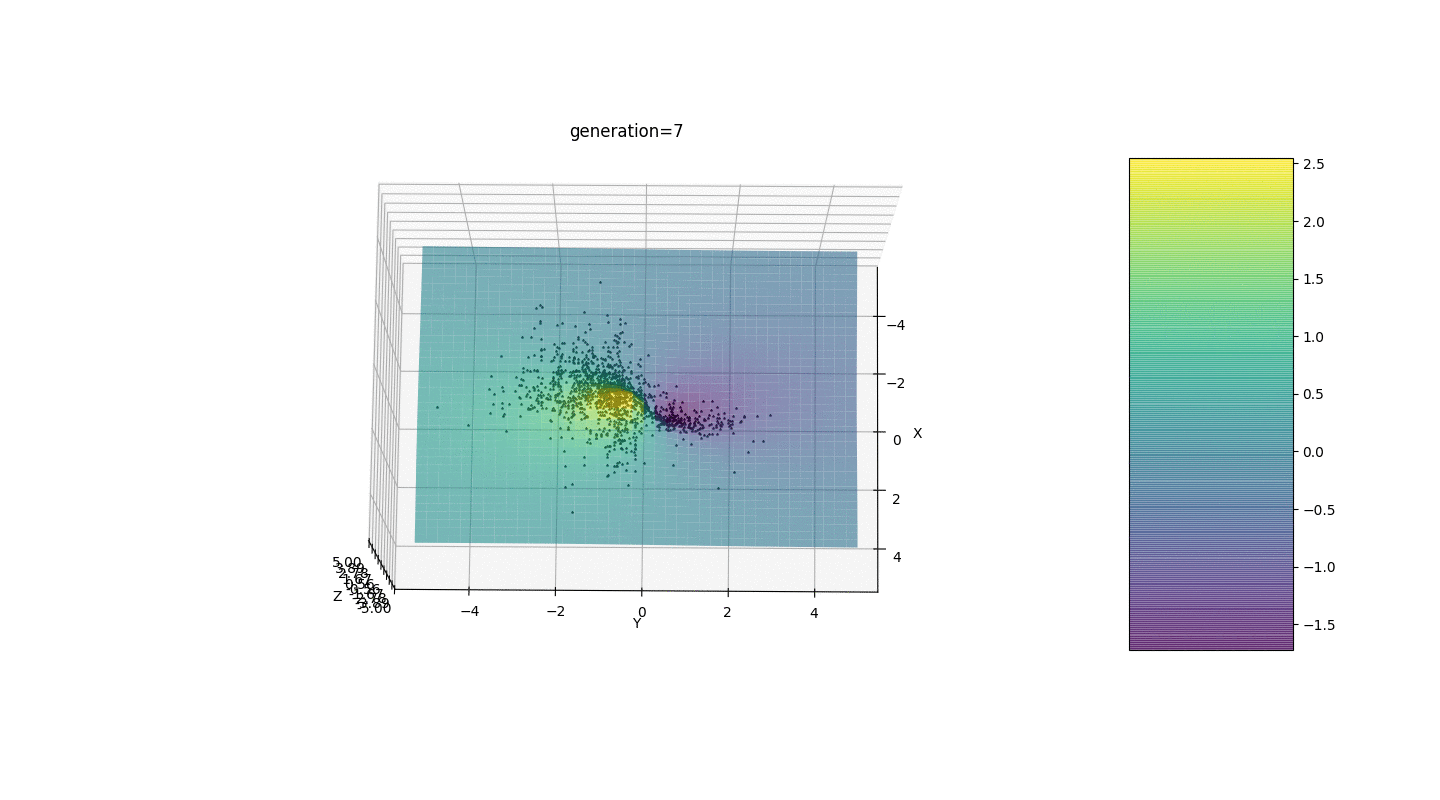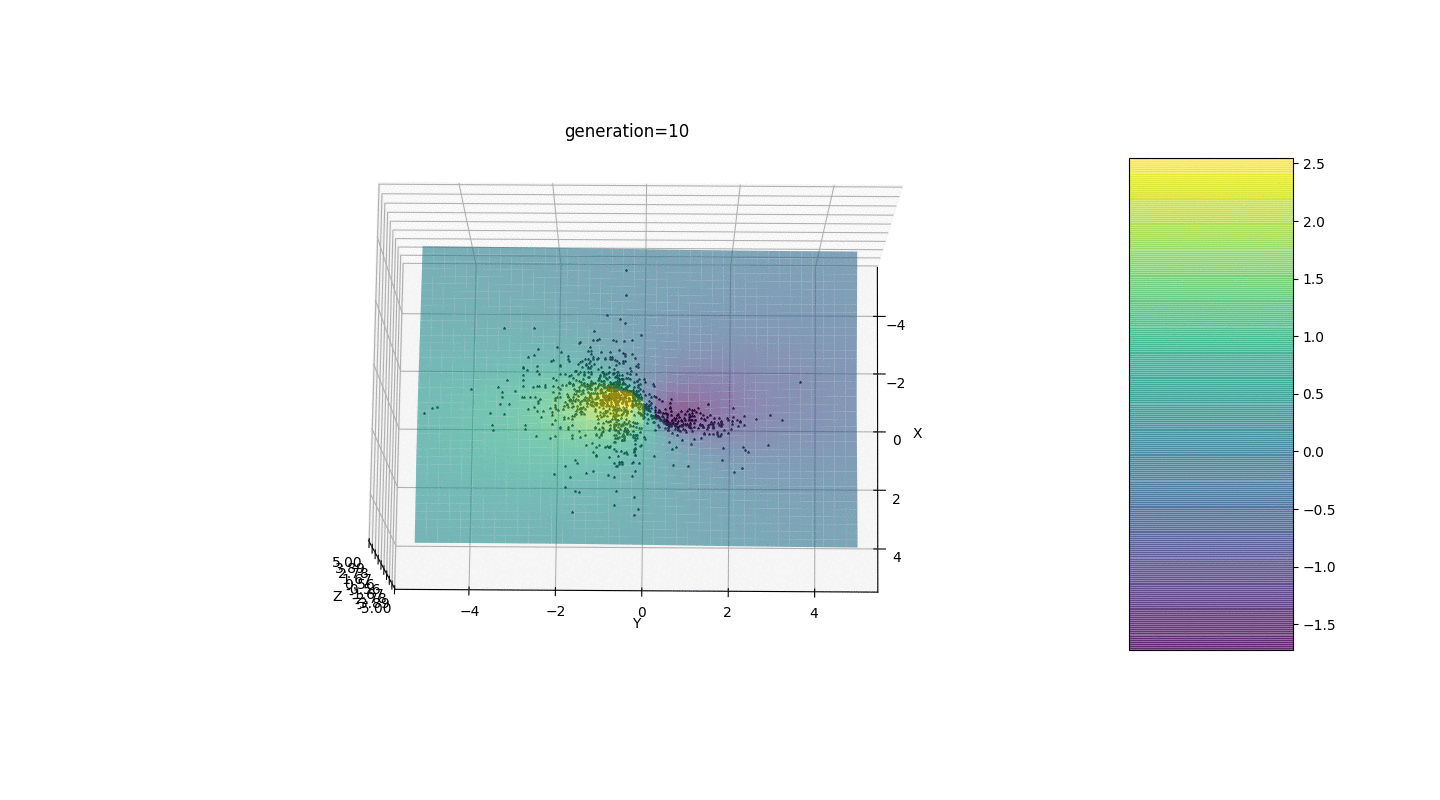
 Setelah menguji dan mempelajari operasi algoritma dengan metode tatapan dan poking acak, beberapa hipotesis-pola terungkap:
Setelah menguji dan mempelajari operasi algoritma dengan metode tatapan dan poking acak, beberapa hipotesis-pola terungkap:- Kesalahan algoritma berbanding lurus dengan jumlah individu, tetapi rata-rata kesalahan dihitung pada seperseratus, meskipun dengan parameter yang tidak berhasil kesalahan dapat mencapai sepersepuluh
- - . , , , ( )
- 5-15 , «»
dan mungkin ada kasus-kasus ketika alun-alun ini mencakup ekstrem lokal, yang tidak cocok untuk kita
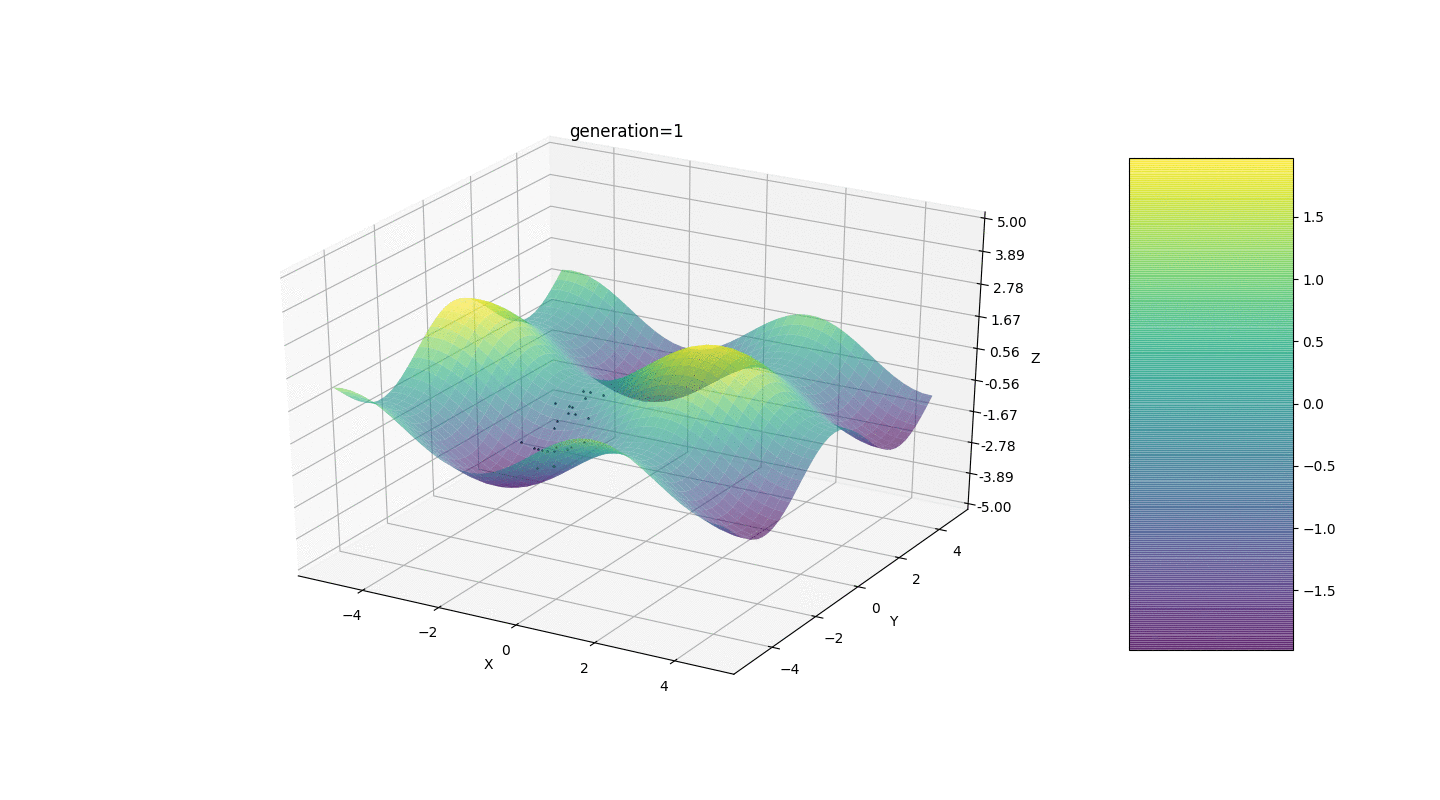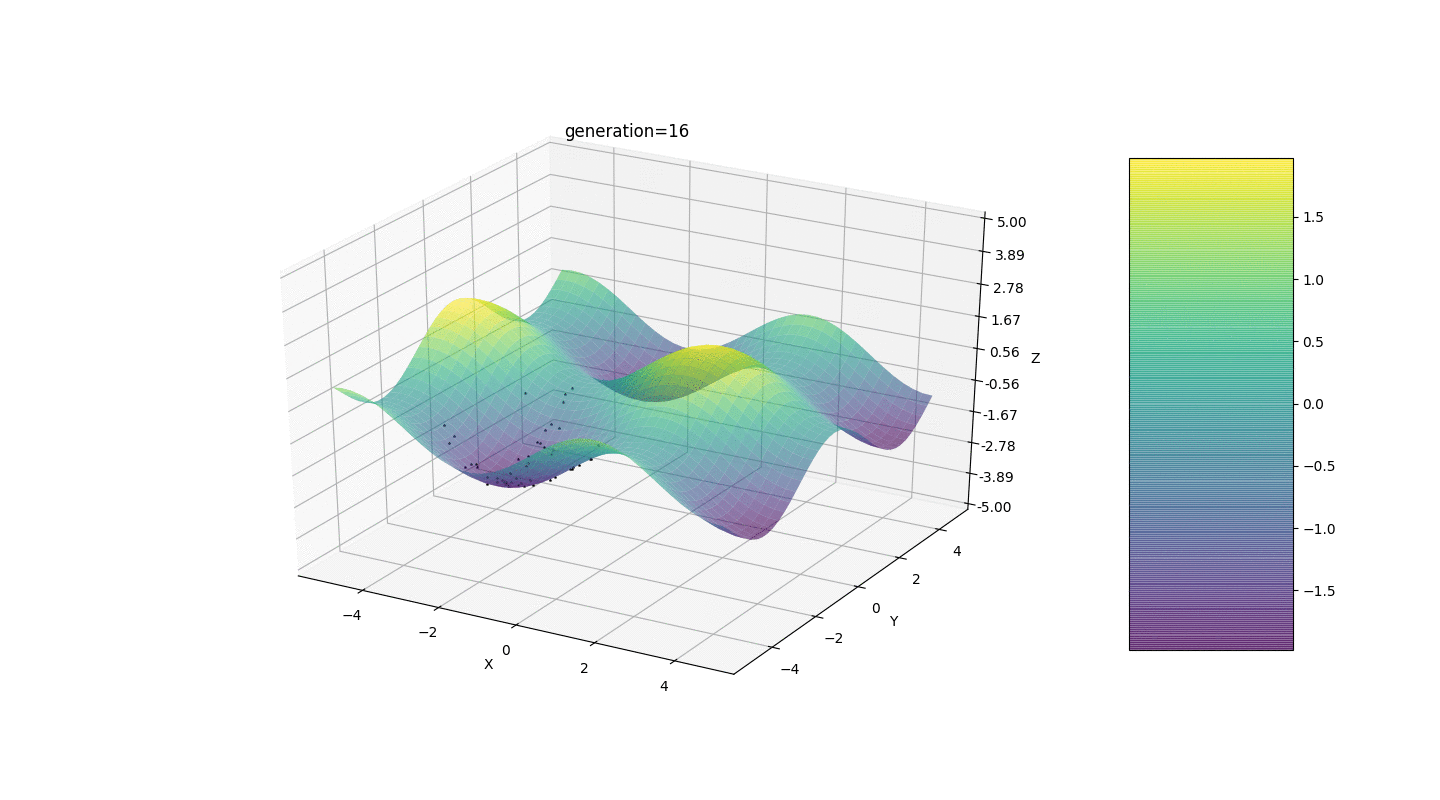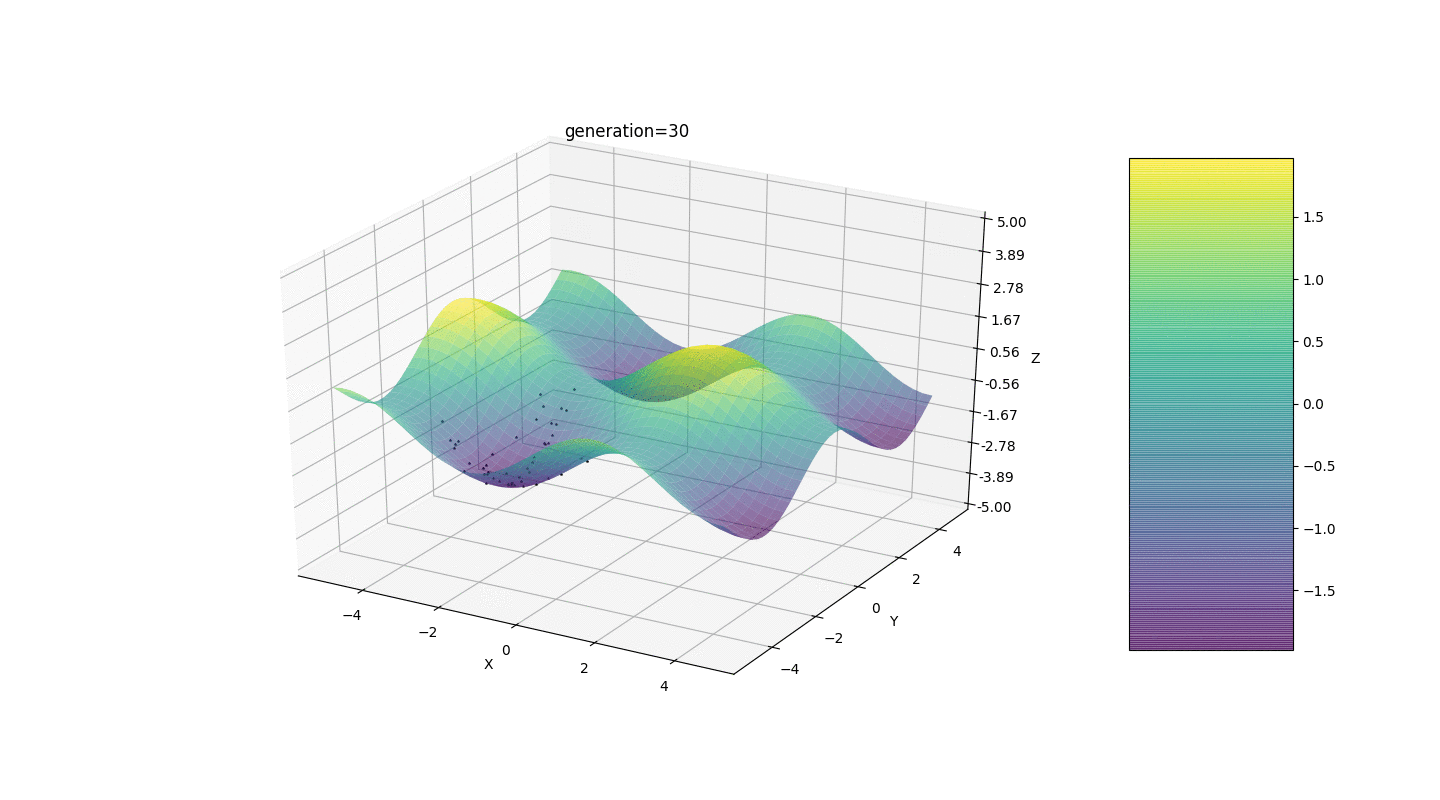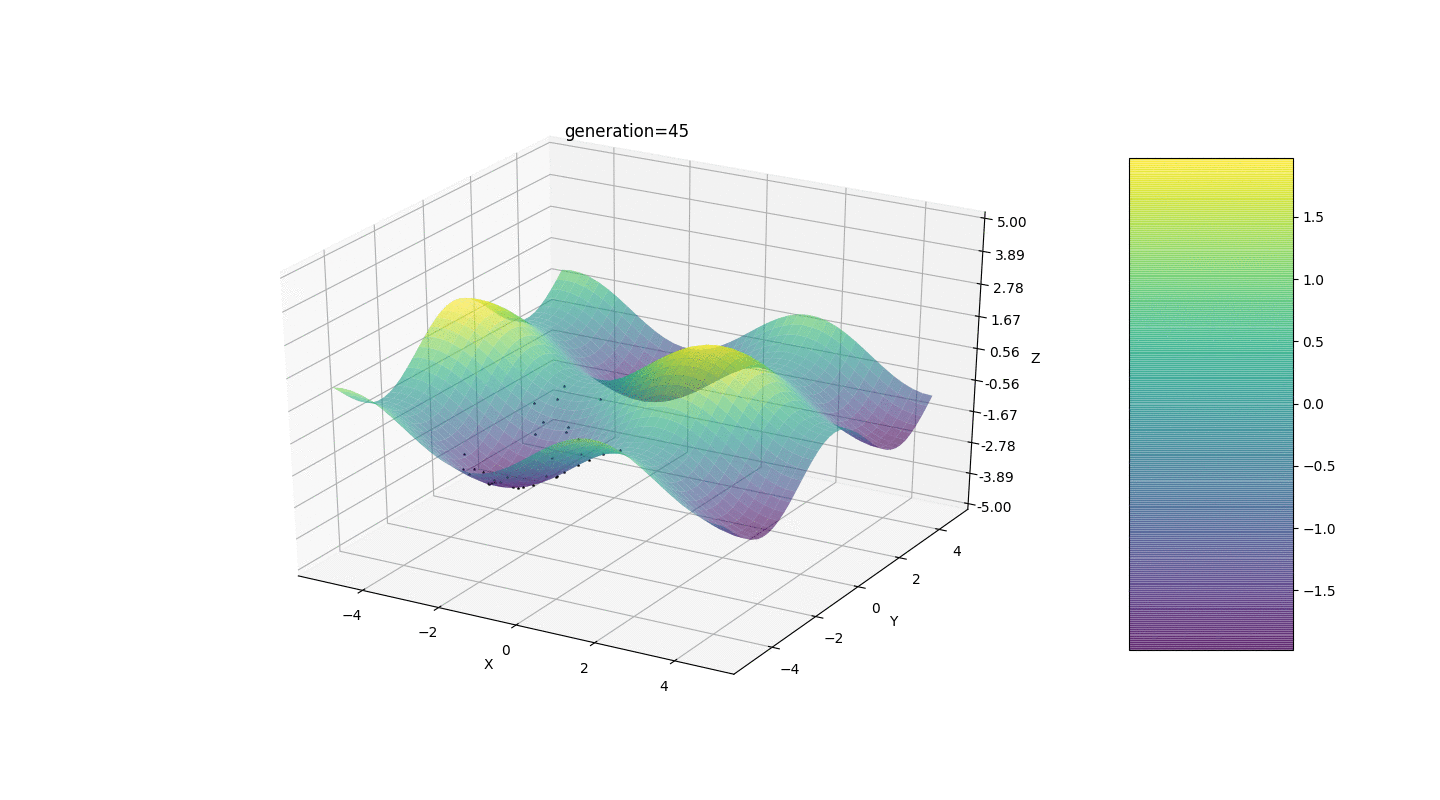
Pertimbangkan permukaan dengan banyak bentuk ekstra:Ekstrem fungsi g akan berada pada titik.Tes 3 Contoh ini menegaskan dan mengilustrasikan semua pengamatan di atas.
Contoh ini menegaskan dan mengilustrasikan semua pengamatan di atas.Peningkatan Algoritma Genetika
Jadi, saat ini, fungsi mutasi tersusun sangat primitif: ia menambahkan nilai acak dari setengah intervalke gen bermutasi. Invarian mutasi seperti itu terkadang mengganggu operasi algoritma yang benar, tetapi ada cara yang efektif untuk memperbaiki cacat ini.Kami memperkenalkan parameter baru, yang kami sebut "rentang mutasi" dan yang akan menunjukkan setengah interval gen mana yang bermutasi. Mari kita buat koefisien mutasi ini berbanding terbalik dengan jumlah generasi. Itu semakin tinggi jumlah generasi, semakin lemah gen bermutasi. Solusi ini memungkinkan Anda untuk menyesuaikan area awal dan meningkatkan akurasi perhitungan jika perlu.Tes 1
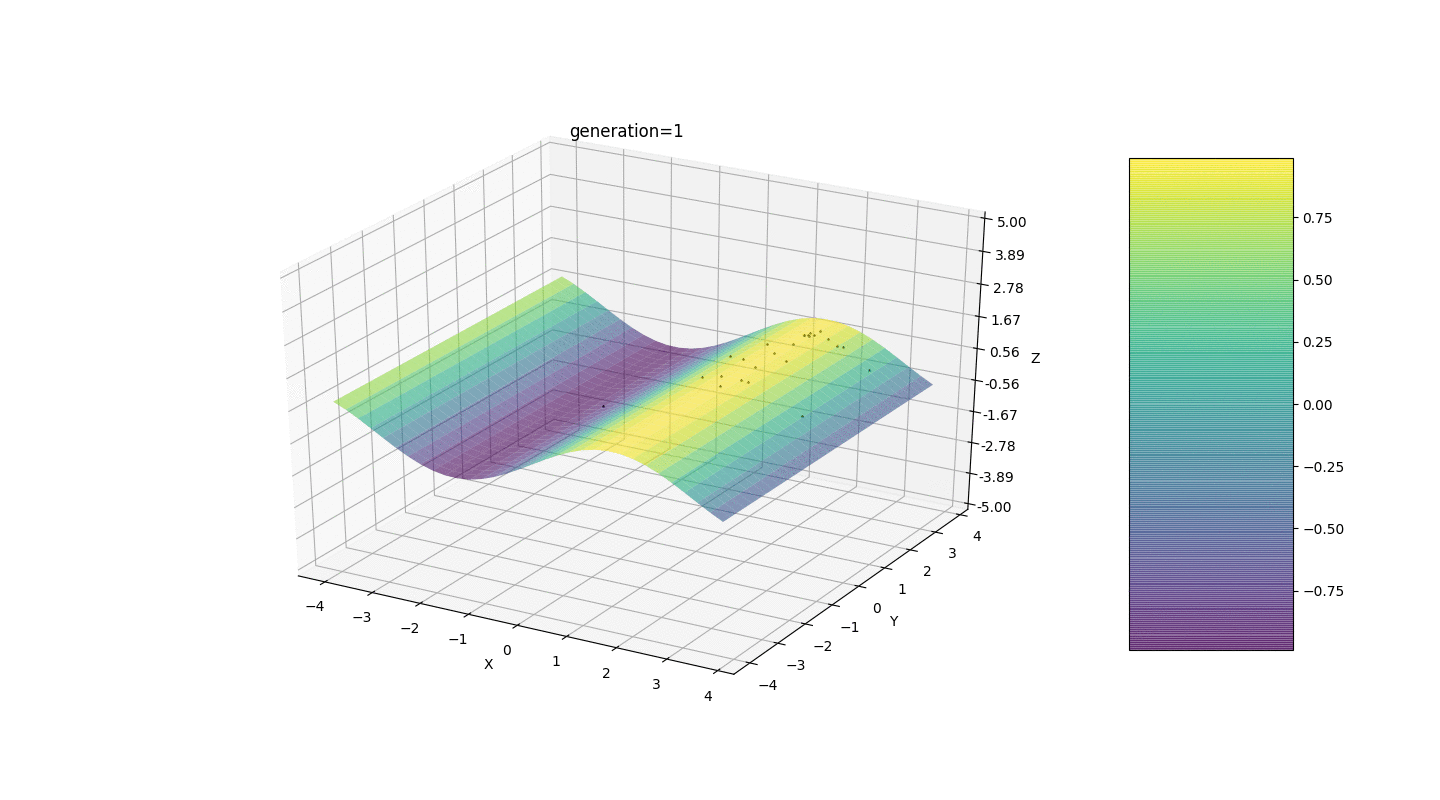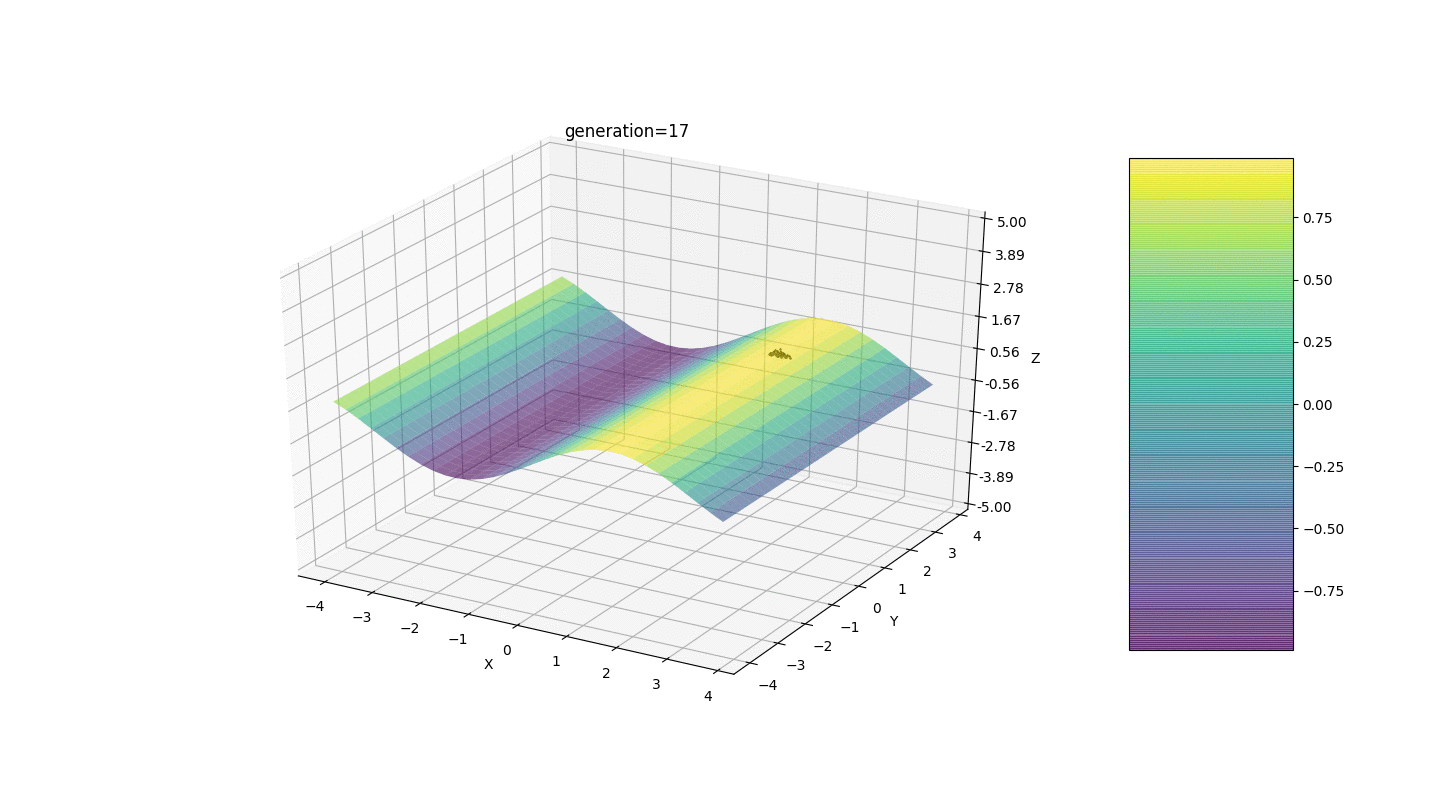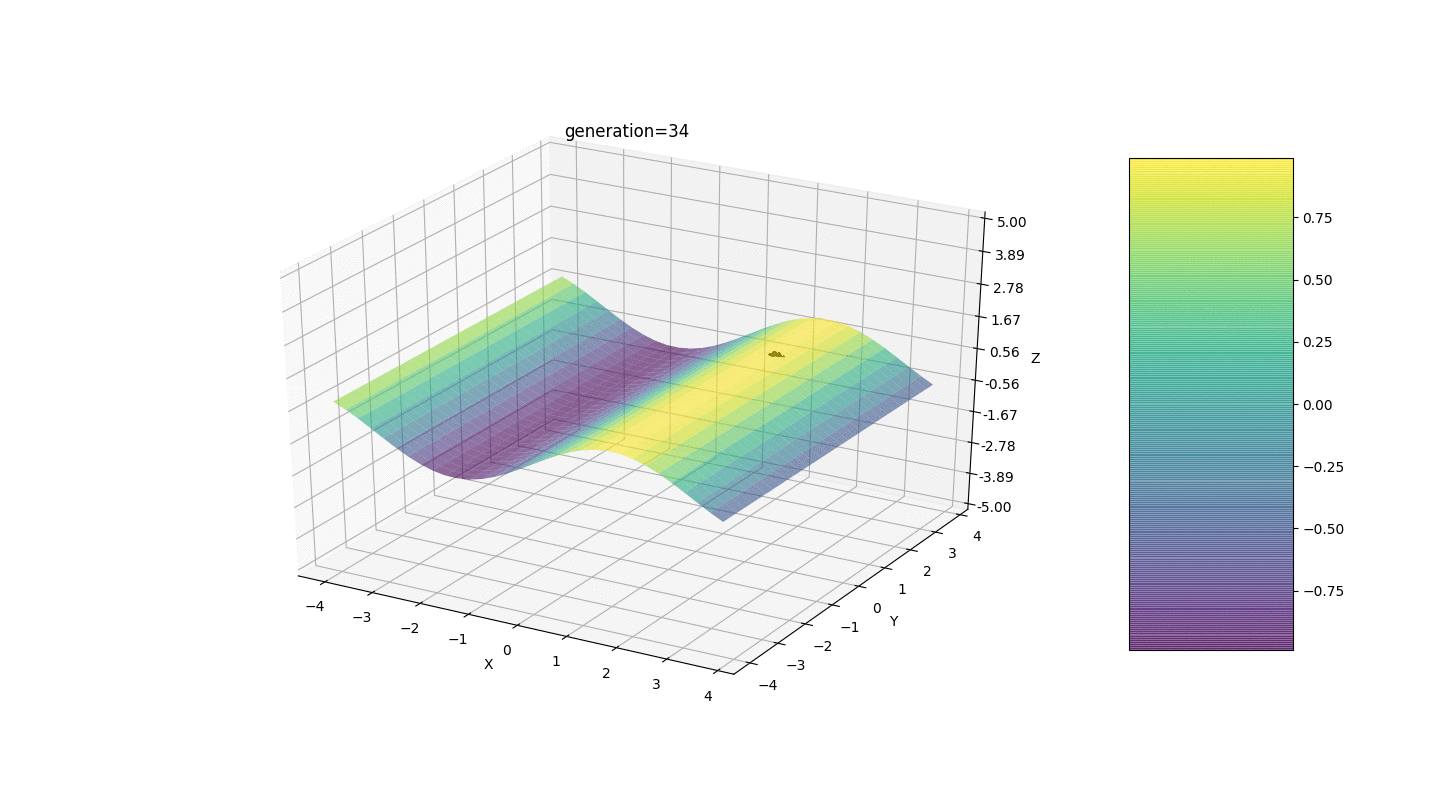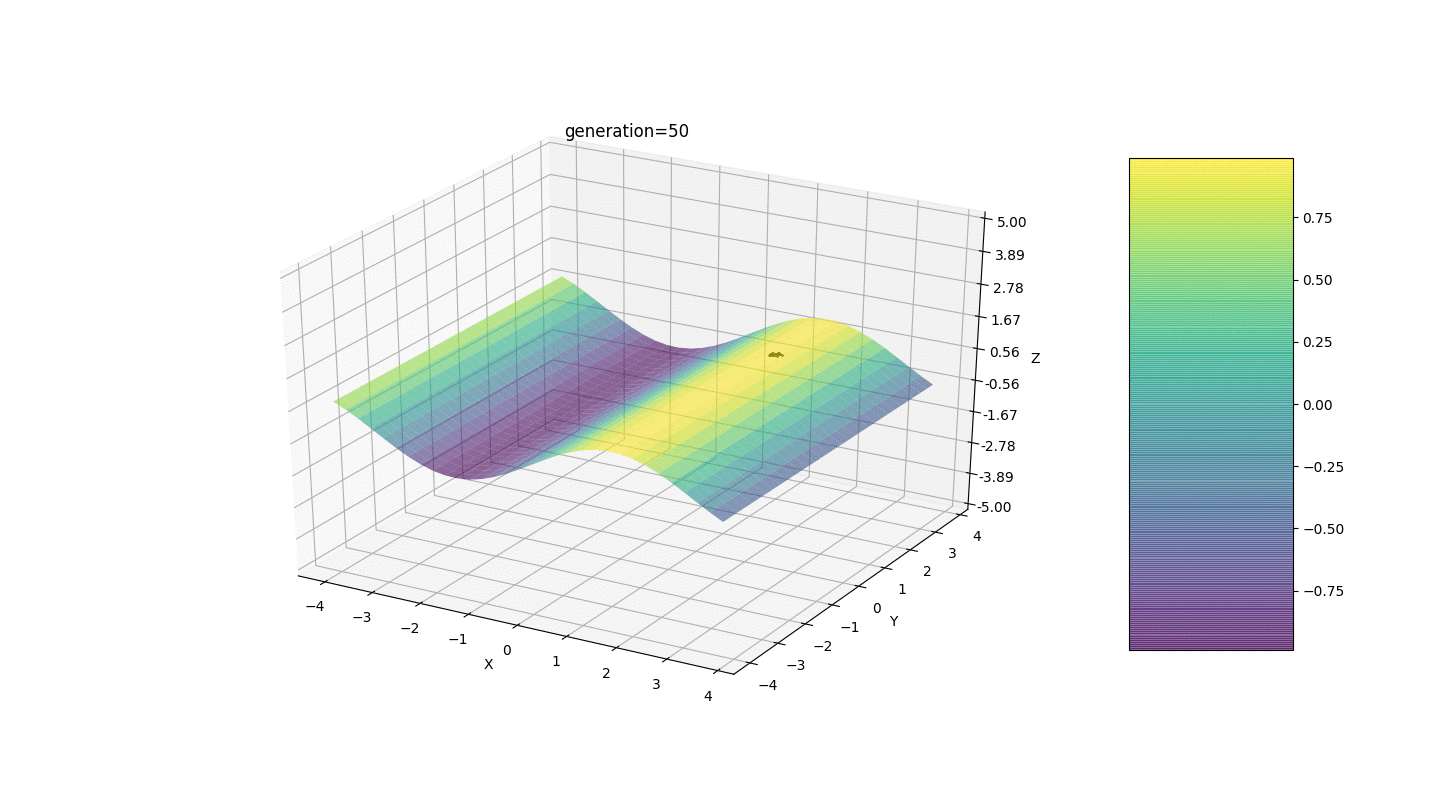
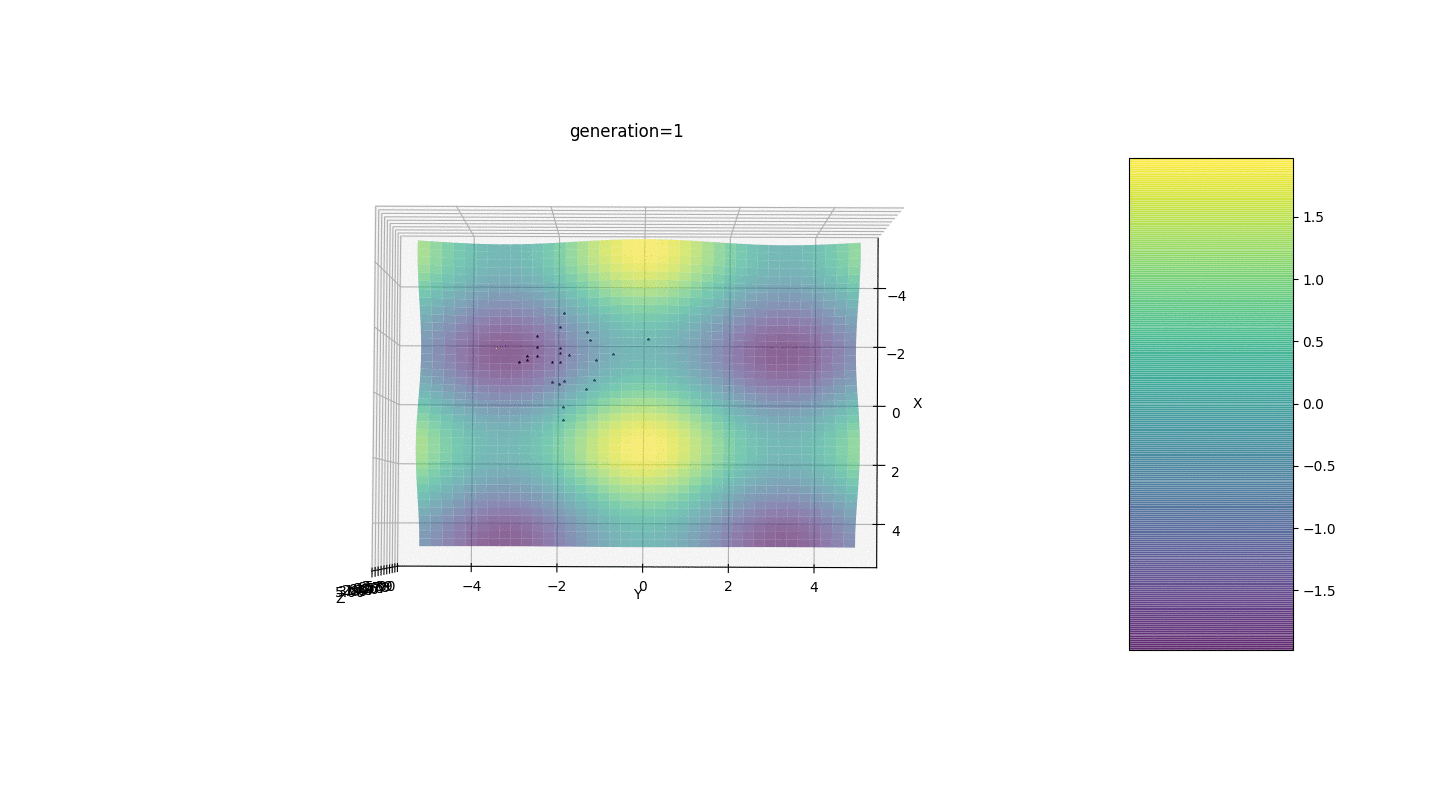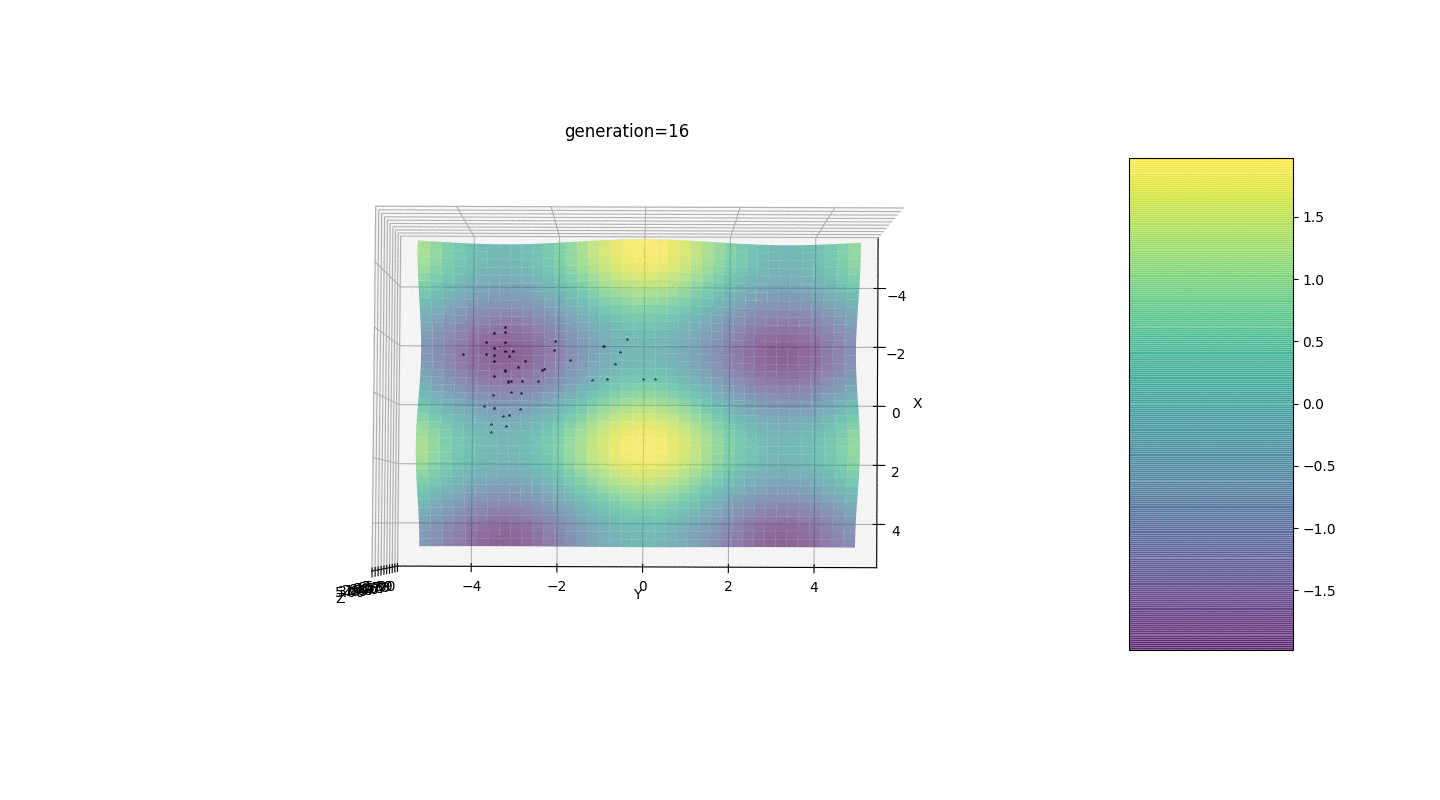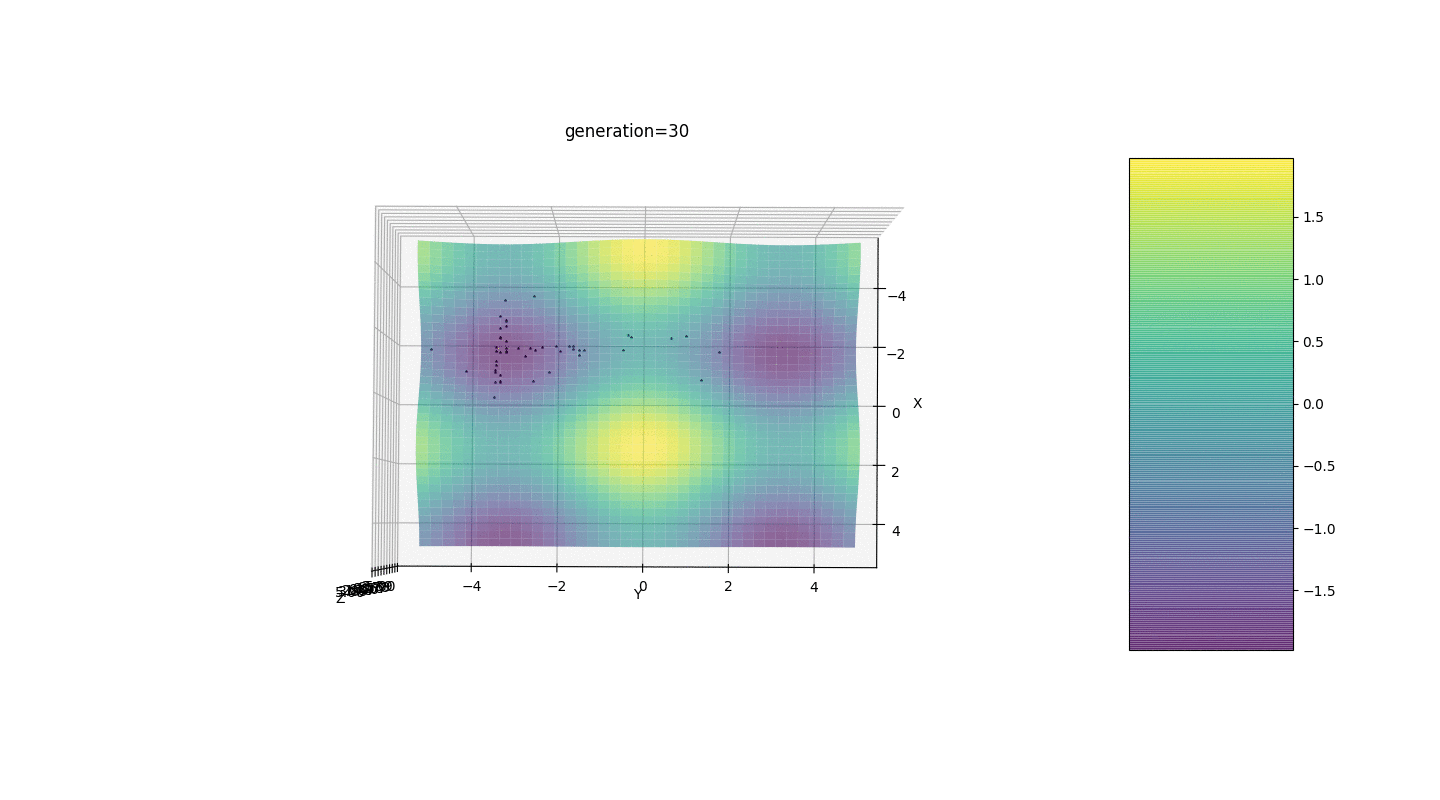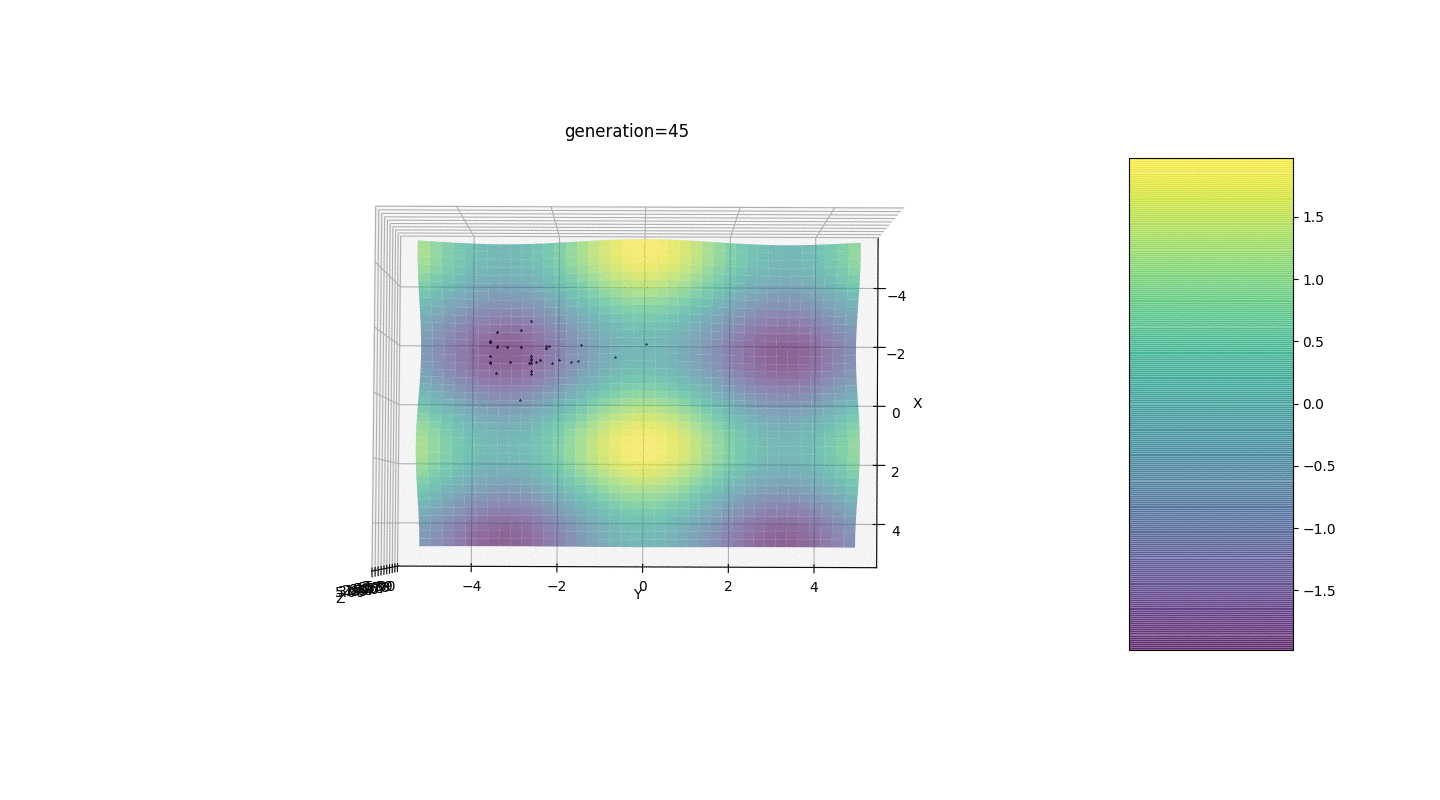
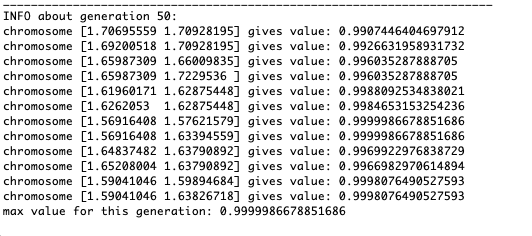 Seperti yang ditunjukkan oleh contoh, sekarang, dengan setiap generasi, populasi semakin banyak berkumpul ke titik ekstrem dan menghitung nilai yang paling akurat karena fluktuasi yang lemah.Tapi bagaimana dengan masalah ekstrim lokal? Pertimbangkan contoh yang sudah dikenal.Tes 2
Seperti yang ditunjukkan oleh contoh, sekarang, dengan setiap generasi, populasi semakin banyak berkumpul ke titik ekstrem dan menghitung nilai yang paling akurat karena fluktuasi yang lemah.Tapi bagaimana dengan masalah ekstrim lokal? Pertimbangkan contoh yang sudah dikenal.Tes 2

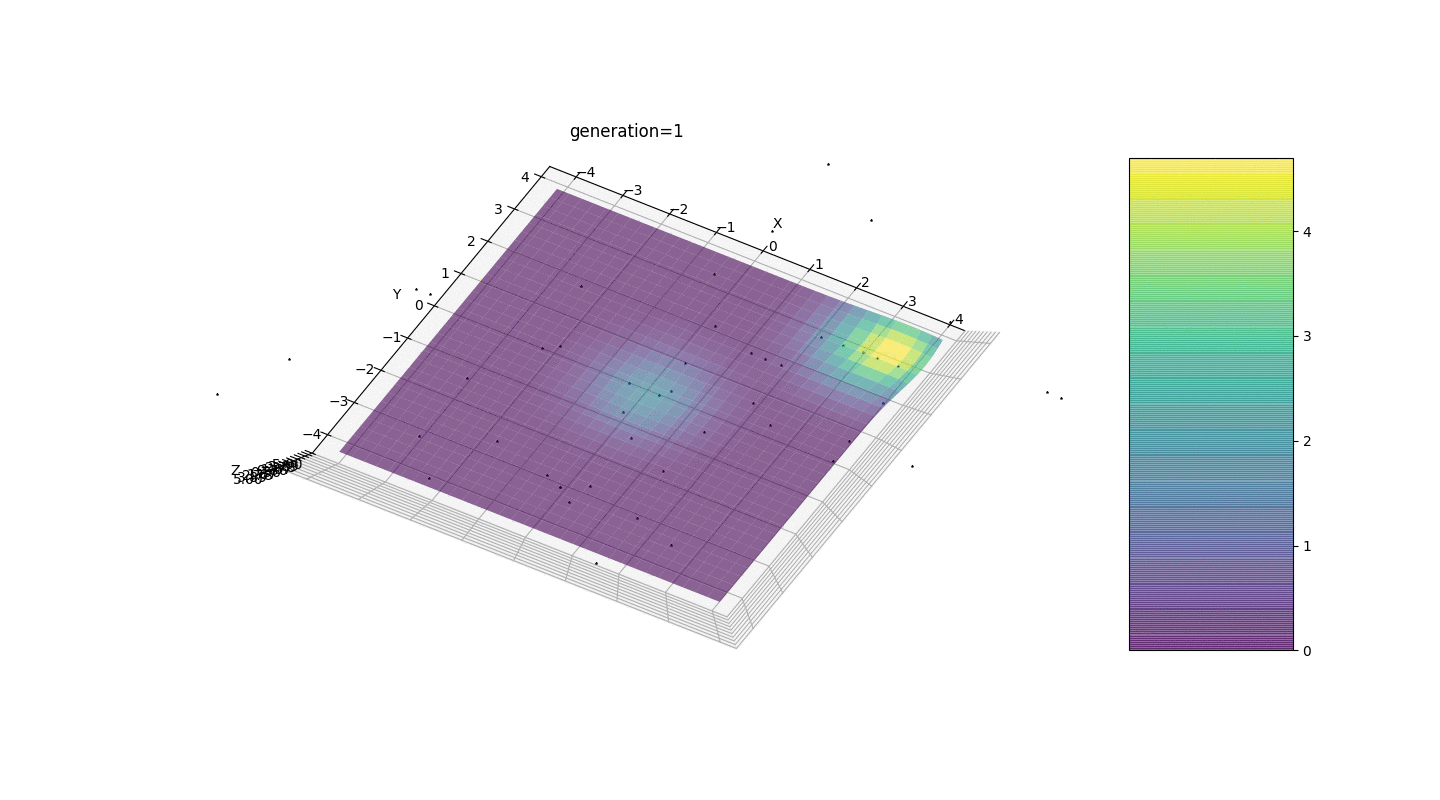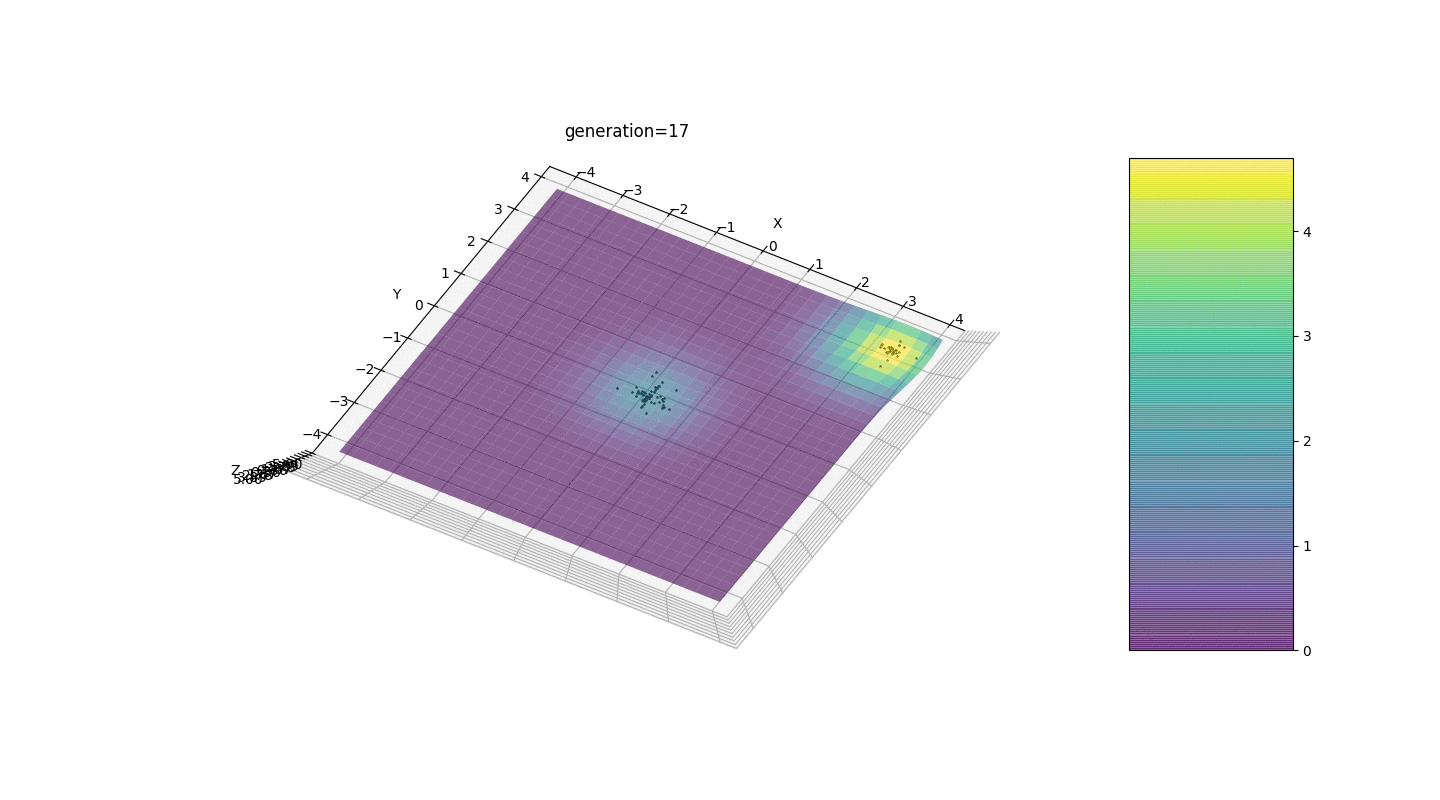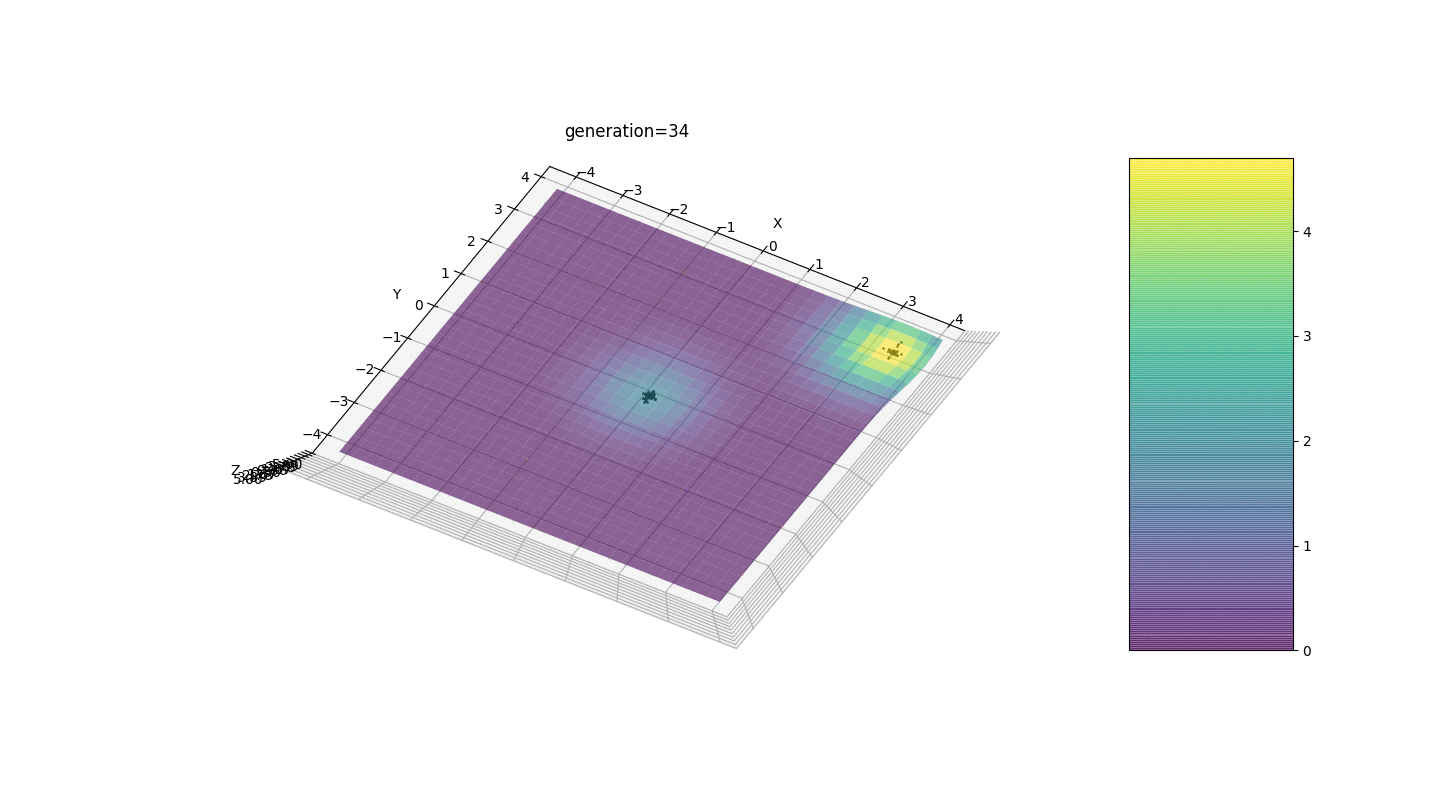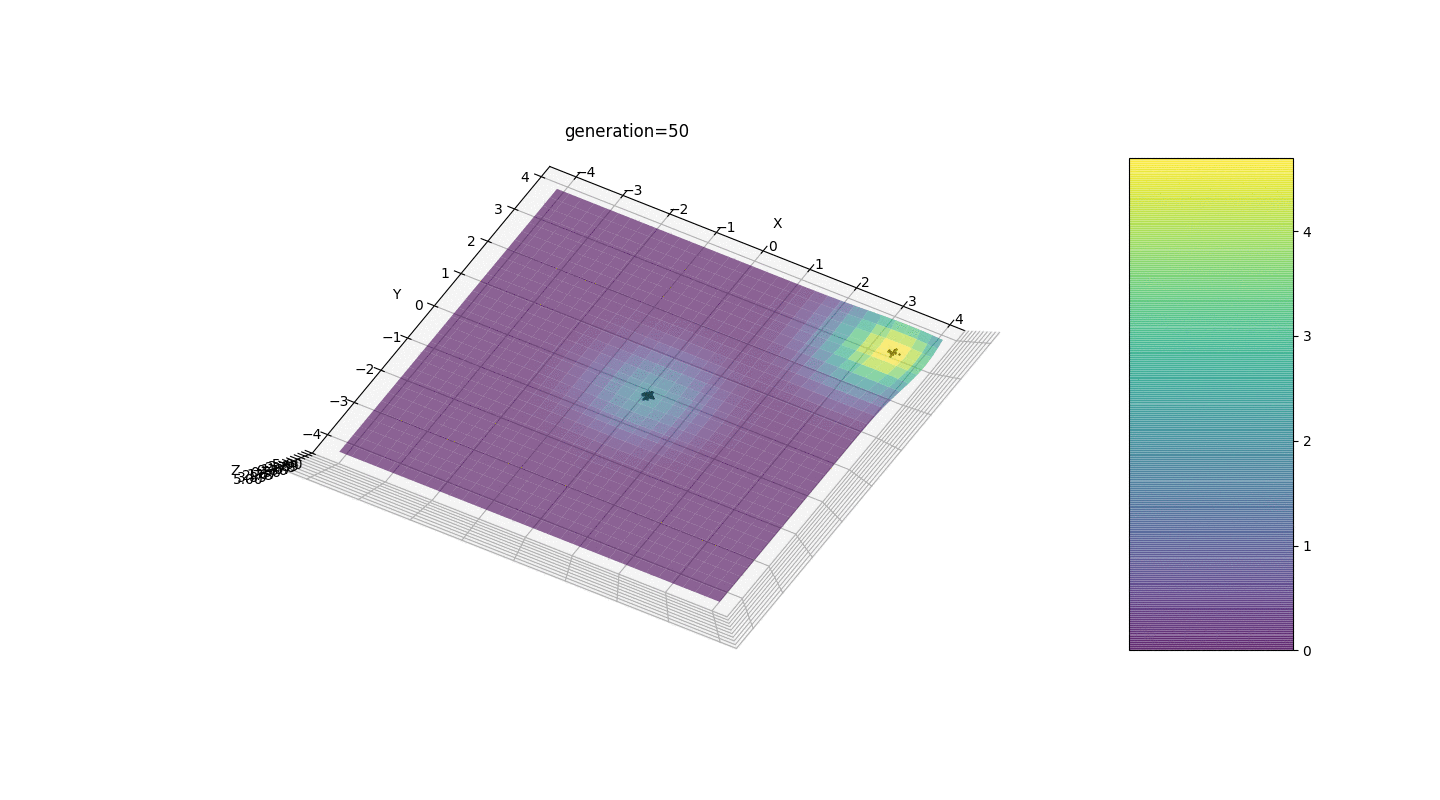
 Kita melihat bahwa sekarang gagasan untuk membagi penduduk menjadi beberapa bagian berfungsi sebagaimana dimaksud. Tanpa segmentasi ini, individu dari generasi awal dapat mengungkapkan genotip dominan palsu di ekstremum lokal, yang akan mengarah pada jawaban yang salah dalam tugas. Yang juga terlihat adalah peningkatan kualitatif dalam keakuratan jawaban karena ketergantungan mutasi pada jumlah generasi.
Kita melihat bahwa sekarang gagasan untuk membagi penduduk menjadi beberapa bagian berfungsi sebagaimana dimaksud. Tanpa segmentasi ini, individu dari generasi awal dapat mengungkapkan genotip dominan palsu di ekstremum lokal, yang akan mengarah pada jawaban yang salah dalam tugas. Yang juga terlihat adalah peningkatan kualitatif dalam keakuratan jawaban karena ketergantungan mutasi pada jumlah generasi.Ringkasan
Saya merangkum hasilnya:- Set parameter yang benar memungkinkan Anda untuk secara akurat menemukan ekstrem global dari fungsi dua variabel
- Partisi populasi dalam banyak kasus menghindari konvergensi ke optimal lokal
- Pengenalan gaya mutasi juga memungkinkan seseorang untuk menghindari konvergensi ke optimal lokal dan kadang-kadang meningkatkan akurasi hasilnya
- ,
- ,
...