Halo semuanya. Menjelang dimulainya kursus Jaringan Saraf Python, kami telah menyiapkan untuk Anda terjemahan dari materi lain yang menarik.
Kami senang memperkenalkan PyCaret , perpustakaan pembelajaran mesin Python open source untuk mempelajari dan menggunakan model dengan dan tanpa guru dalam lingkungan kode-rendah. PyCaret memungkinkan Anda beralih dari persiapan data ke penerapan model dalam beberapa detik di lingkungan notebook yang Anda pilih.Dibandingkan dengan perpustakaan pembelajaran mesin terbuka lainnya, PyCaret adalah alternatif kode rendah yang dapat menggantikan ratusan baris kode hanya dengan beberapa kata. Kecepatan percobaan yang lebih efisien akan meningkat secara eksponensial. PyCaret pada dasarnya adalah sebuah shell Python pada beberapa pustaka pembelajaran mesin seperti scikit-learn , XGBoost , Microsoft LightGBM , spaCydan banyak lagi.PyCaret sederhana dan mudah digunakan. Semua operasi yang dilakukan oleh PyCaret disimpan secara berurutan dalam pipa yang sepenuhnya siap untuk ditempatkan. Baik itu menambahkan nilai yang hilang, mengonversi data kategorikal, fitur teknik, atau mengoptimalkan hiperparameter, PyCaret dapat mengotomatisasi semua ini. Untuk mempelajari lebih lanjut tentang PyCaret, lihat video singkat ini .Memulai dengan PyCaret
Rilis stabil pertama dari PyCaret versi 1.0.0 dapat diinstal menggunakan pip. Gunakan antarmuka baris perintah atau lingkungan notebook dan jalankan perintah di bawah ini untuk menginstal PyCaret.pip install pycaret
Jika Anda menggunakan Azure Notebooks atau Google Colab , jalankan perintah berikut:!pip install pycaret
Ketika Anda menginstal PyCaret, semua dependensi akan diinstal secara otomatis. Anda dapat melihat daftar dependensi di sini .Itu tidak bisa lebih mudah
Panduan
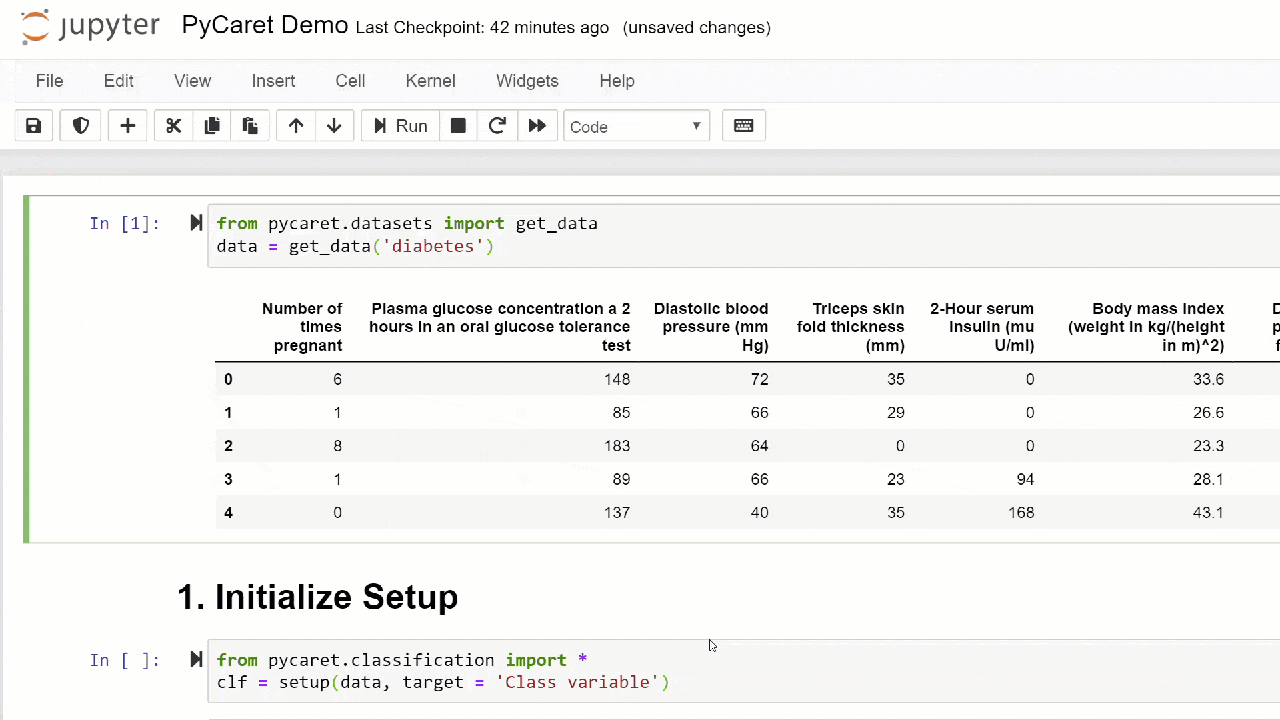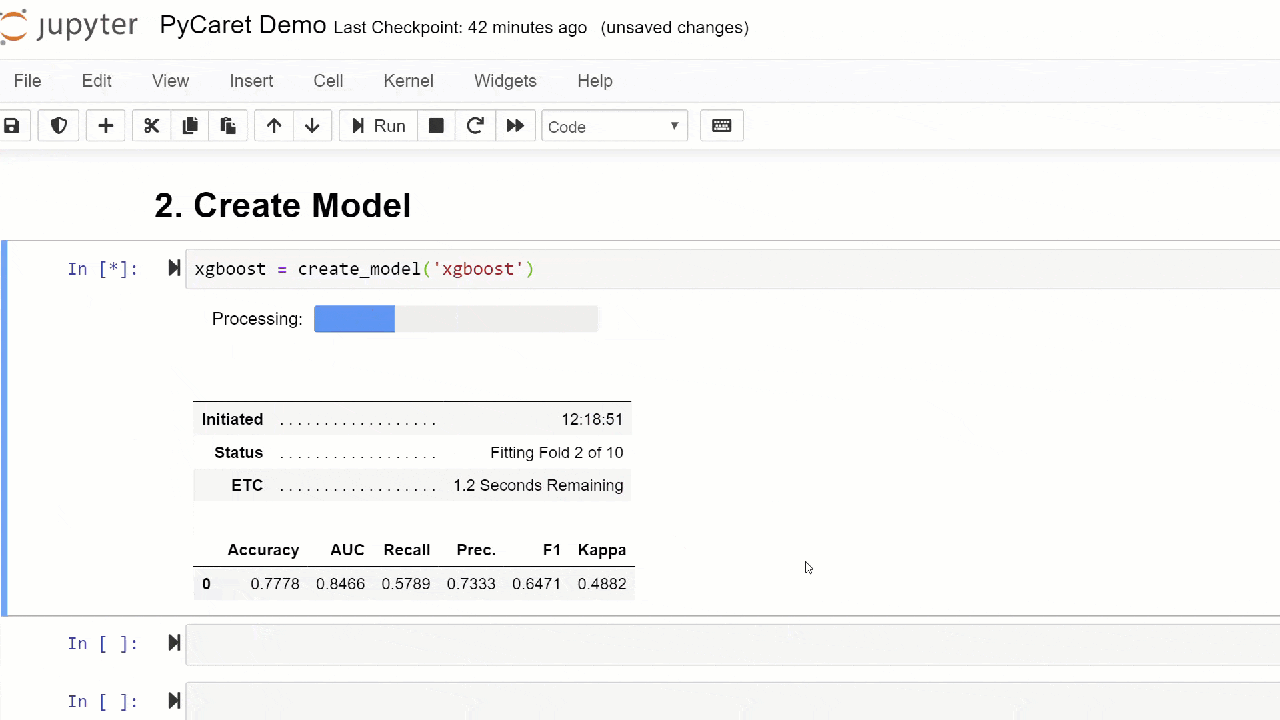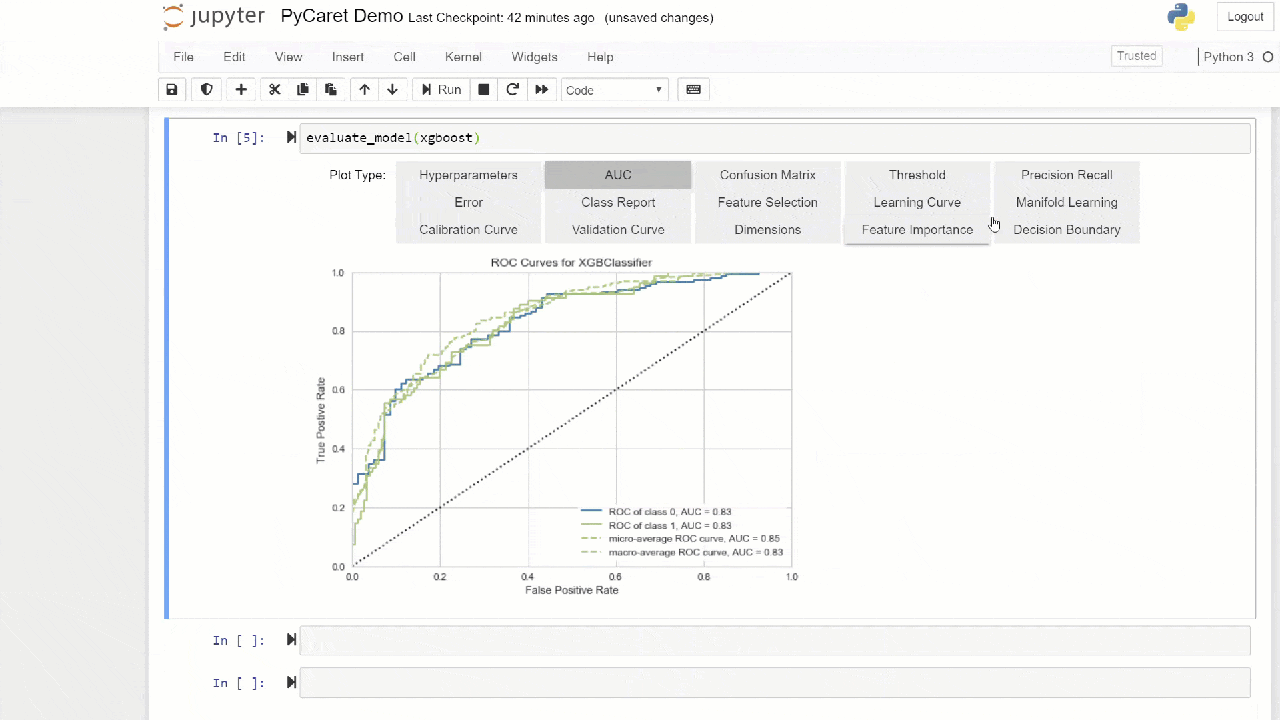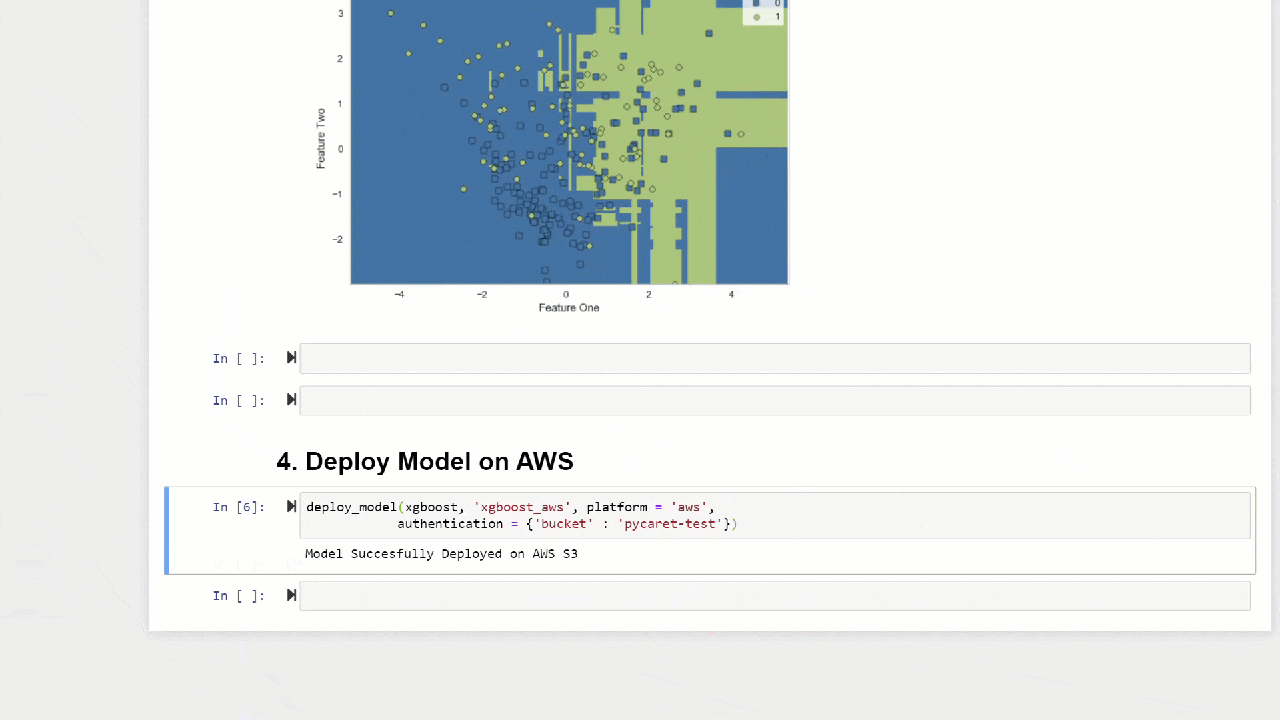
1. Akuisisi DataDalam langkah-langkah ini, kami akan menggunakan dataset diabetes, tujuan kami adalah untuk memprediksi hasil pasien (dalam biner 0 atau 1) berdasarkan beberapa faktor seperti tekanan, tingkat insulin darah, usia, dll. . Dataset ini tersedia di repositori PyCaret GitHub . Cara termudah untuk mengimpor dataset secara langsung dari repositori adalah dengan menggunakan fungsi get_datadari modul pycaret.datasets.from pycaret.datasets import get_data
diabetes = get_data('diabetes')
 PyCaret dapat bekerja secara langsung dengan bingkai data panda2. Menyiapkan lingkunganSetiap percobaan dengan pembelajaran mesin di PyCaret dimulai dengan mengatur lingkungan dengan mengimpor modul yang diperlukan dan menginisialisasi
PyCaret dapat bekerja secara langsung dengan bingkai data panda2. Menyiapkan lingkunganSetiap percobaan dengan pembelajaran mesin di PyCaret dimulai dengan mengatur lingkungan dengan mengimpor modul yang diperlukan dan menginisialisasi setup(). Modul yang akan digunakan dalam contoh ini adalah pycaret.classification .Setelah mengimpor modul, modul setup()diinisialisasi dengan mendefinisikan kerangka data ( 'diabetes' ) dan variabel target ( 'variabel Kelas' ).from pycaret.classification import *
exp1 = setup(diabetes, target = 'Class variable')
 Semua preprocessing berlangsung di
Semua preprocessing berlangsung di setup(). Menggunakan lebih dari 20 fungsi untuk menyiapkan data sebelum pembelajaran mesin, PyCaret membuat pipa transformasi berdasarkan parameter yang ditentukan dalam fungsi setup(). Secara otomatis membangun semua dependensi dalam pipa, sehingga Anda tidak perlu secara manual mengontrol eksekusi berurutan pada tes atau set data baru (tidak terlihat).Pipa PyCaret dapat dengan mudah ditransfer dari satu lingkungan ke lingkungan lain atau digunakan untuk produksi. Di bawah ini Anda dapat membiasakan diri dengan fitur preprocessing yang telah tersedia di PyCaret sejak rilis pertama.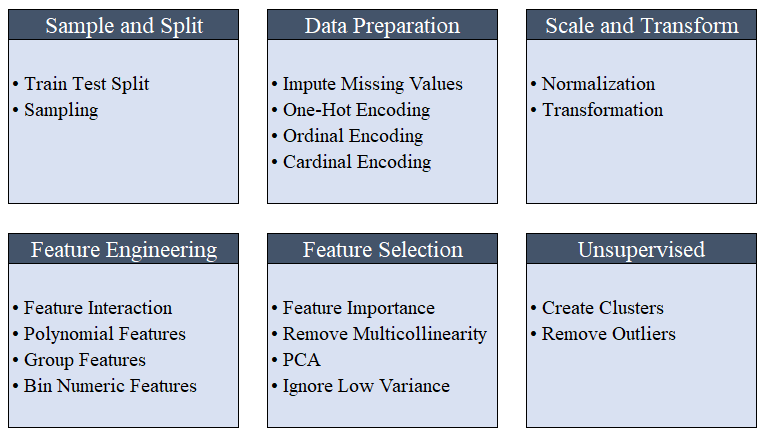 Langkah-langkah preprocessing data wajib untuk pembelajaran mesin, seperti menambahkan nilai yang hilang, variabel kualitas pengkodean, label pengkodean (ya atau tidak ke 1 atau 0) dan train-test-split, dilakukan secara otomatis selama inisialisasi
Langkah-langkah preprocessing data wajib untuk pembelajaran mesin, seperti menambahkan nilai yang hilang, variabel kualitas pengkodean, label pengkodean (ya atau tidak ke 1 atau 0) dan train-test-split, dilakukan secara otomatis selama inisialisasi setup(). Anda dapat mempelajari lebih lanjut tentang fitur preprocessing di PyCaret di sini .3. Perbandingan modelIni adalah langkah pertama yang direkomendasikan untuk dilakukan ketika bekerja dengan pelatihan guru ( klasifikasi atau regresi ). Fungsi ini melatih semua model di perpustakaan model dan membandingkan perkiraan indikator satu sama lain menggunakan validasi silang untuk blok-K (secara default 10 blok). Indikator yang diperkirakan digunakan sebagai berikut:- Untuk klasifikasi: Akurasi, AUC, Ingat, Presisi, F1, Kappa
- Untuk regresi: MAE, MSE, RMSE, R2, RMSLE, MAPE
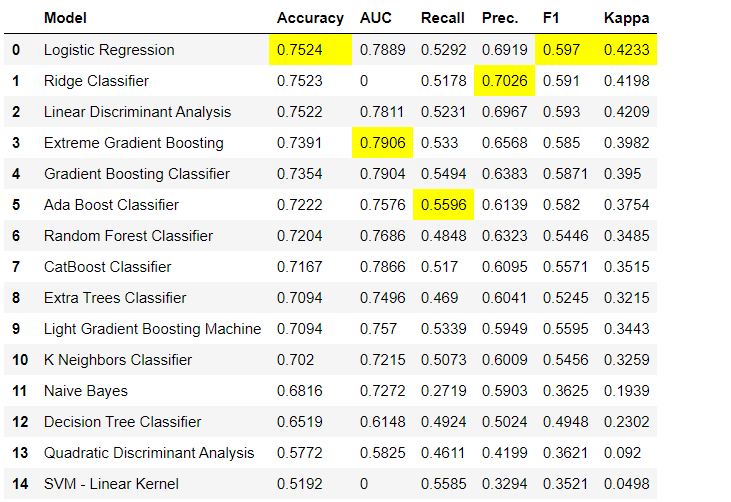 Secara default, metrik dievaluasi menggunakan validasi silang lebih dari 10 blok. Jumlah blok dapat diubah dengan mengubah nilai parameter
Secara default, metrik dievaluasi menggunakan validasi silang lebih dari 10 blok. Jumlah blok dapat diubah dengan mengubah nilai parameter fold.Tabel default diurutkan berdasarkan “Akurasi” dari nilai tertinggi ke terendah. Urutan penyortiran juga dapat diubah menggunakan opsi sort.4. Membuat modelMembuat model dalam modul PyCaret sangat sederhana sehingga Anda hanya perlu menuliskannya create_model. Fungsi ini mengambil satu parameter pada input, mis. nama model diberikan sebagai string. Fungsi ini mengembalikan tabel dengan skor yang divalidasi silang dan objek model yang terlatih.adaboost = create_model('ada')
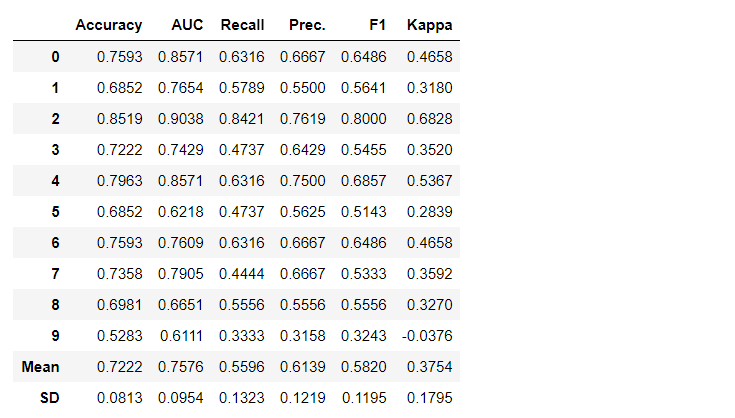 Variabel "adaboost" menyimpan objek model yang dilatih, yang mengembalikan fungsi
Variabel "adaboost" menyimpan objek model yang dilatih, yang mengembalikan fungsi create_modelyang, di bawah tenda, adalah evaluator scikit-belajar. Akses ke atribut sumber dari objek yang dilatih dapat diperoleh dengan menggunakan fungsi period ( . )setelah variabel. Anda dapat menemukan contoh penggunaan di bawah ini. PyCaret memiliki lebih dari 60 algoritma open source yang siap digunakan. Daftar lengkap evaluator / model yang tersedia di PyCaret dapat ditemukan di sini .5. Pengaturan modelFungsi ini
PyCaret memiliki lebih dari 60 algoritma open source yang siap digunakan. Daftar lengkap evaluator / model yang tersedia di PyCaret dapat ditemukan di sini .5. Pengaturan modelFungsi ini tune_modeldigunakan untuk secara otomatis mengkonfigurasi hyperparameters model pembelajaran mesin. Penggunaan PyCaretrandom grid searchdi ruang pencarian tertentu. Fungsi mengembalikan tabel dengan estimasi yang divalidasi silang dan objek model yang terlatih.tuned_adaboost = tune_model('ada')
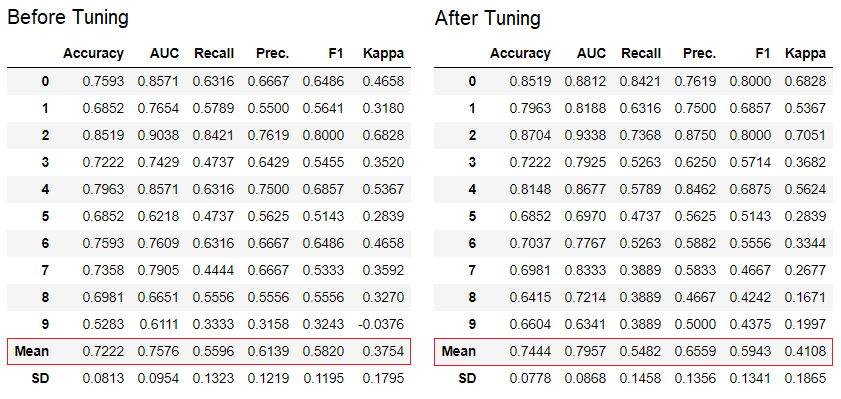 Fungsi
Fungsi tune_modeldalam modul pembelajaran non-guru seperti pycaret.nlp , pycaret.clustering, dan pycaret.anomaly dapat digunakan bersama dengan modul pembelajaran guru. Misalnya, modul NLP di PyCaret dapat digunakan untuk menyesuaikan parameter number of topicsdengan mengevaluasi fungsi tujuan atau fungsi kerugian dari model dengan guru, seperti "Akurasi" atau "R2".6. Ensemble model. Fungsi ini ensemble_modeldigunakan untuk membuat ansambel model yang terlatih. Pada input, dibutuhkan satu parameter - objek model yang terlatih. Fungsi mengembalikan tabel dengan estimasi yang divalidasi silang dan objek model yang terlatih.
dt = create_model('dt')
dt_bagged = ensemble_model(dt)
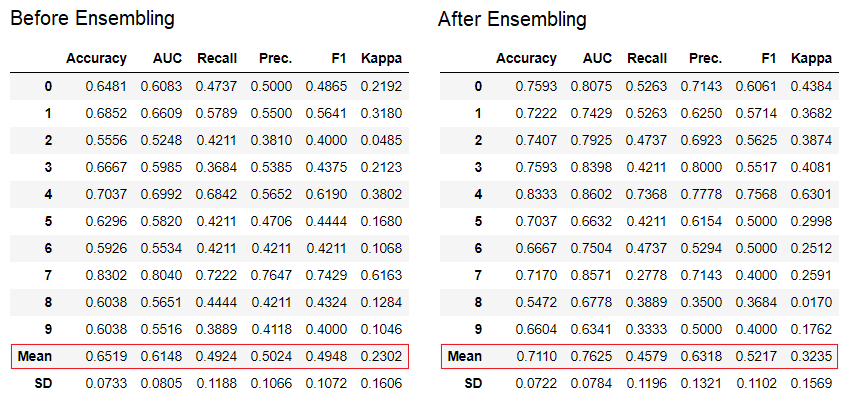 Metode "mengantongi" digunakan saat membuat ensemble secara default, itu dapat diubah menjadi "meningkatkan" menggunakan parameter
Metode "mengantongi" digunakan saat membuat ensemble secara default, itu dapat diubah menjadi "meningkatkan" menggunakan parameter methoddalam fungsi ensemble_model.PyCaret juga menyediakan fungsi blend_modelsdan stack_models untuk menggabungkan beberapa model terlatih.7. Visualisasi model.Anda dapat mengevaluasi kinerja dan mendiagnosis model pembelajaran mesin yang terlatih menggunakan fungsi ini plot_model. Dibutuhkan objek model yang terlatih dan jenis grafik dalam bentuk string.
adaboost = create_model('ada')
plot_model(adaboost, plot = 'auc')
plot_model(adaboost, plot = 'boundary')
plot_model(adaboost, plot = 'pr')
plot_model(adaboost, plot = 'vc')
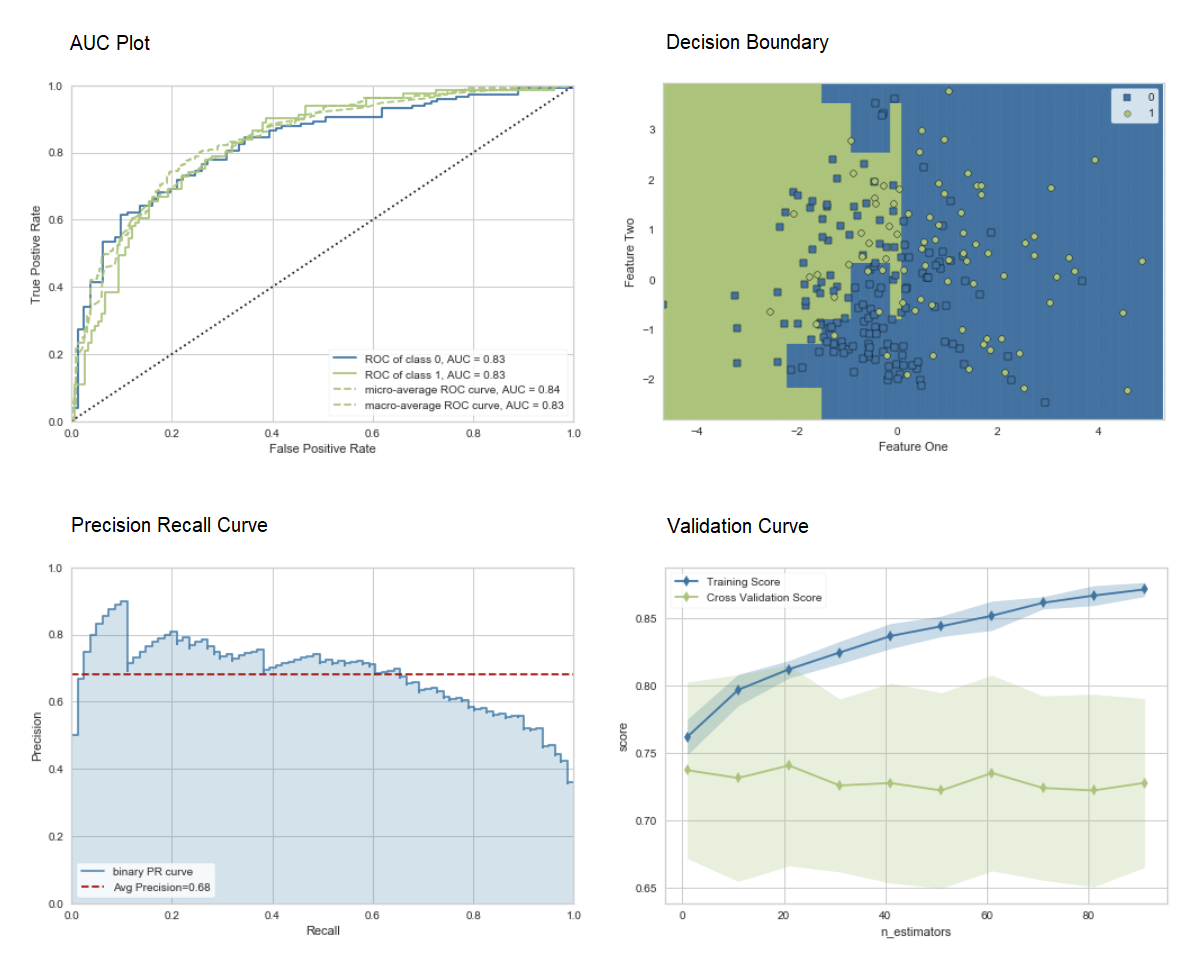 Di sini Anda dapat mempelajari lebih lanjut tentang visualisasi di PyCaret.Anda juga dapat menggunakan fungsi
Di sini Anda dapat mempelajari lebih lanjut tentang visualisasi di PyCaret.Anda juga dapat menggunakan fungsi evaluate_modeluntuk melihat grafik menggunakan antarmuka pengguna notebook. Fungsi
Fungsi plot_modeldalam modul pycaret.nlpdapat digunakan untuk memvisualisasikan tubuh teks dan model tematik semantik. Di sini Anda dapat mempelajari lebih lanjut tentang mereka.8. Interpretasi modelKetika data non-linear, yang sering terjadi dalam kehidupan nyata, kita selalu melihat bahwa model mirip pohon bekerja jauh lebih baik daripada model Gaussian sederhana. Namun, ini karena hilangnya interpretabilitas, karena model pohon tidak menyediakan koefisien sederhana, seperti model linier. PyCaret mengimplementasikan SHAP (SHapley Additive exPlanations ) menggunakan suatu fungsi interpret_model.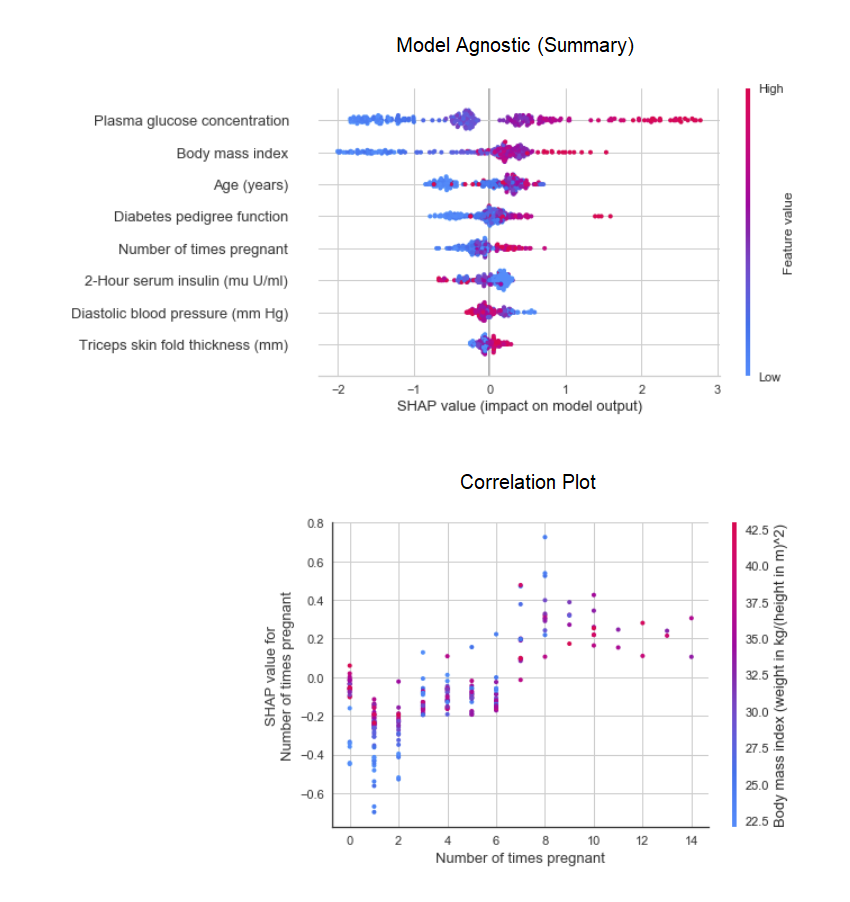 Interpretasi titik data tertentu dalam dataset uji dapat diperkirakan menggunakan grafik "alasan". Dalam contoh di bawah ini, kami menguji contoh pertama dalam dataset uji.
Interpretasi titik data tertentu dalam dataset uji dapat diperkirakan menggunakan grafik "alasan". Dalam contoh di bawah ini, kami menguji contoh pertama dalam dataset uji. 9. Model prediktifHingga saat ini, hasil yang kami peroleh didasarkan pada validasi silang oleh blok-K pada dataset pelatihan (70% secara default). Untuk melihat perkiraan dan kinerja model pada dataset uji / tahan, digunakan fungsi
9. Model prediktifHingga saat ini, hasil yang kami peroleh didasarkan pada validasi silang oleh blok-K pada dataset pelatihan (70% secara default). Untuk melihat perkiraan dan kinerja model pada dataset uji / tahan, digunakan fungsi predict_model.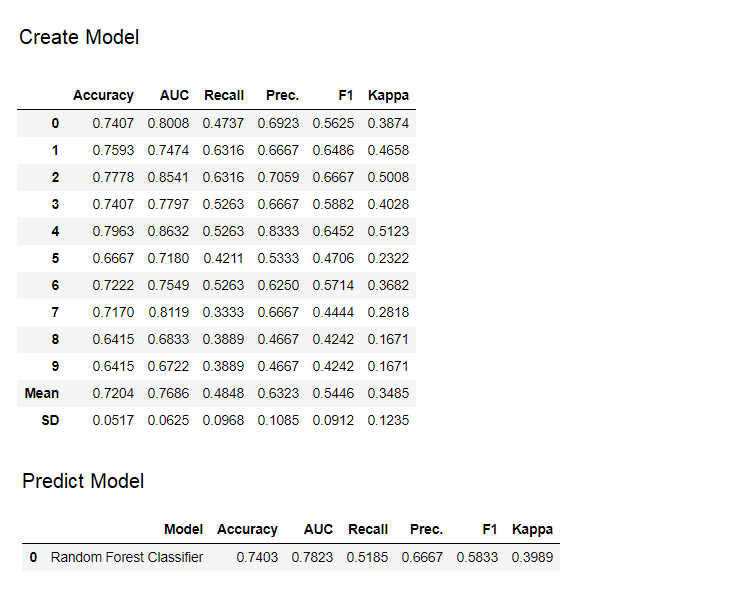 Fungsi ini
Fungsi ini predict_modeldigunakan untuk meramalkan dataset yang tidak terlihat. Sekarang kita akan menggunakan dataset yang sama yang kita gunakan untuk pelatihan, sebagai proksi untuk dataset tidak terlihat yang baru. Dalam praktiknya, fungsinyapredict_modelakan digunakan secara iteratif, setiap kali pada dataset baru yang tidak terlihat.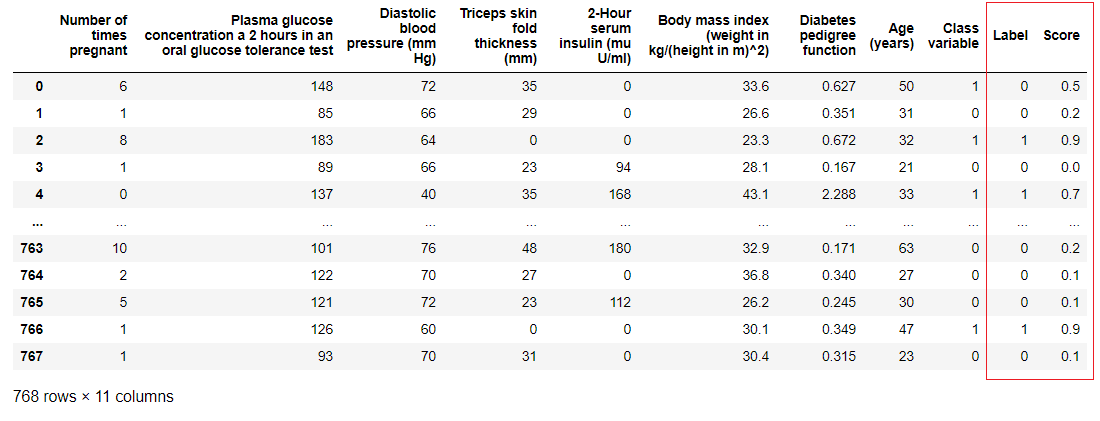 Fungsi
Fungsi predict_modelini juga dapat membuat prediksi untuk rantai berurutan model yang dapat dibuat menggunakan fungsi stack_models dan create_stacknet .Fungsi predict_modelini juga dapat membuat prediksi langsung untuk model yang dihosting di AWS S3 menggunakan fungsi deploy_model .10. Menyebarkan modelSalah satu cara untuk menggunakan model terlatih untuk membuat perkiraan untuk dataset baru adalah dengan menggunakan fungsi tersebutpredict_modeldi notebook / IDE yang sama di mana model itu dilatih. Namun, menghasilkan perkiraan untuk dataset baru (tidak terlihat) adalah proses berulang. Bergantung pada kasus penggunaan, frekuensi ramalan dapat bervariasi dari ramalan real-time ke prediksi kumpulan. Fungsi deploy_modeldi PyCaret memungkinkan Anda untuk menyebarkan seluruh pipa, termasuk model terlatih di cloud dari lingkungan notebook.deploy_model(model = rf, model_name = 'rf_aws', platform = 'aws',
authentication = {'bucket' : 'pycaret-test'})
11. Simpan model / simpan percobaan
Setelah pelatihan, seluruh pipa yang berisi semua transformasi preprocessing dan objek dari model yang terlatih dapat disimpan dalam file acar biner.
adaboost = create_model('ada')
save_model(adaboost, model_name = 'ada_for_deployment')
 Anda juga dapat menyimpan seluruh percobaan, yang berisi semua output antara, sebagai file biner tunggal.save_experiment (experiment_name = 'my_first_experiment')
Anda juga dapat menyimpan seluruh percobaan, yang berisi semua output antara, sebagai file biner tunggal.save_experiment (experiment_name = 'my_first_experiment') Anda dapat memuat model dan percobaan yang disimpan menggunakan fungsi
Anda dapat memuat model dan percobaan yang disimpan menggunakan fungsi load_modeldan load_experimenttersedia dari semua modul PyCaret.12. Panduan SelanjutnyaDalam panduan berikutnya, kami akan menunjukkan cara menggunakan model pembelajaran mesin terlatih di Power BI untuk menghasilkan prediksi batch dalam lingkungan produksi nyata.Anda juga dapat membaca buku catatan untuk pemula dalam modul berikut:Apa itu pipeline pengembangan?
Kami secara aktif bekerja untuk meningkatkan PyCaret. Pipeline pengembangan kami yang akan datang mencakup modul perkiraan waktu seri baru, integrasi TensorFlow, dan peningkatan skalabilitas PyCaret utama. Jika Anda ingin berbagi umpan balik dan membantu kami meningkatkan, Anda dapat mengisi formulir di situs atau memberikan komentar di halaman kami di GitHub atau LinkedIn .Ingin tahu lebih banyak tentang modul tertentu?
Dimulai dengan rilis pertama, PyCaret 1.0.0 memiliki modul-modul berikut yang tersedia untuk digunakan. Ikuti tautan di bawah untuk membiasakan diri Anda dengan dokumentasi dan contoh-contoh pekerjaan. PelatihanKlasifikasiRegresiKlasterAnomali Pencarian AturanTeks Asatif (NLP)Tautan penting
Jika Anda menyukai PyCaret, tempatkan kami ️ di GitHub.Untuk mendengar lebih lanjut tentang PyCaret, Anda dapat mengikuti kami di LinkedIn dan Youtube .
Pelajari lebih lanjut tentang kursus.