Terjemahan artikel ini disiapkan khusus untuk siswa dari kursus "Database" .
Apa yang mungkin belum Anda ketahui tentang generasi nomor acak sysbenchSysbench adalah alat pengujian kinerja yang populer. Awalnya ditulis oleh Peter Zaitsev pada awal 2000-an dan menjadi standar de facto untuk pengujian dan benchmarking. Saat ini didukung oleh Alexei Kopytov dan diposting di Github di .Namun, saya perhatikan bahwa, meskipun distribusinya luas, ada saat-saat yang asing bagi banyak orang di sysbench. Sebagai contoh, kemampuan untuk dengan mudah memodifikasi tes MySQL menggunakan Lua atau untuk mengkonfigurasi parameter dari generator angka acak bawaan.Tentang apa artikel ini?
Saya menulis artikel ini untuk menunjukkan betapa mudahnya menyesuaikan sysbench dengan kebutuhan Anda. Ada banyak cara untuk memperluas fungsionalitas sysbench, dan salah satunya adalah mengkonfigurasi generasi pengidentifikasi acak (ID).Secara default, sysbench hadir dengan lima opsi berbeda untuk menghasilkan angka acak. Tetapi sangat sering (pada kenyataannya, hampir tidak pernah), tidak satupun dari mereka secara eksplisit ditunjukkan, dan bahkan lebih jarang Anda dapat melihat parameter generasi (untuk opsi di mana mereka tersedia).Jika Anda memiliki pertanyaan: “Dan mengapa saya harus tertarik dengan ini? Bagaimanapun, nilai defaultnya cukup cocok, ”maka postingan ini dirancang untuk membantu Anda memahami mengapa hal ini tidak selalu terjadi.Ayo mulai
Apa cara untuk menghasilkan angka acak di sysbench? Berikut ini sedang diterapkan (Anda dapat dengan mudah melihatnya melalui opsi --help):- Spesial (distribusi khusus)
- Gaussian (Distribusi Gaussian)
- Pareto (Distribusi Pareto)
- Zipfian (Distribusi Zipf)
- Seragam (distribusi seragam)
Secara default, Special digunakan dengan parameter berikut:rand-spec-iter = 12 - Jumlah iterasi untuk distribusi khususrand-spec-pct = 1 - persentase dari seluruh rentang di mana nilai "khusus" jatuh dengan distribusi khususrand-spec-res = 75 - persentase nilai "khusus" untuk digunakan dalam distribusi khusus
Karena saya menyukai tes dan skrip yang sederhana dan mudah direproduksi, semua data selanjutnya akan dikumpulkan menggunakan perintah sysbench berikut:- sysbench ./src/lua/oltp_read.lua -mysql_storage_engine = innodb –db-driver = mysql –tabel = 10 –table_size = 100 persiapkan
- sysbench ./src/lua/oltp_read_write.lua –db-driver=mysql –tables=10 –table_size=100 –skip_trx=off –report-interval=1 –mysql-ignore-errors=all –mysql_storage_engine=innodb –auto_inc=on –histogram –stats_format=csv –db-ps-mode=disable –threads=10 –time=60 –rand-type=XXX run
Jangan ragu untuk bereksperimen sendiri. Deskripsi skrip dan data dapat ditemukan di sini .Mengapa sysbench menggunakan generator angka acak? Salah satu tujuannya adalah untuk menghasilkan ID yang akan digunakan dalam kueri. Jadi, dalam contoh kita, angka antara 1 dan 100 akan dihasilkan, dengan mempertimbangkan pembuatan 10 tabel dengan masing-masing 100 baris.Bagaimana jika Anda menjalankan sysbench seperti yang dijelaskan di atas dan hanya mengubah tipe-brand?Saya menjalankan skrip ini dan menggunakan log umum untuk mengumpulkan dan menganalisis frekuensi nilai ID yang dihasilkan. Inilah hasilnya: SeragamKhusus Zipfian Pareto Gaussian
Dapat dilihat bahwa parameter ini penting, bukan? Bagaimanapun, sysbench melakukan persis seperti yang kita harapkan darinya.



 Mari kita melihat lebih dekat pada masing-masing distribusi.
Mari kita melihat lebih dekat pada masing-masing distribusi.Khusus
Special digunakan secara default, jadi jika Anda TIDAK menentukan rand-type, maka sysbench akan menggunakan special. Special menggunakan sejumlah nilai ID yang sangat terbatas. Dalam contoh kita, kita dapat melihat bahwa nilai-nilai 50-51 terutama digunakan, nilai-nilai yang tersisa antara 44-56 sangat jarang, sementara yang lain praktis tidak digunakan. Harap perhatikan bahwa nilai yang dipilih berada di tengah kisaran 1-100 yang tersedia.Dalam hal ini, puncaknya adalah sekitar dua ID yang mewakili 2% dari sampel. Jika saya menambah jumlah rekaman menjadi satu juta, puncaknya akan tetap, tetapi akan menjadi 7493, yang merupakan 0,74% dari sampel. Karena ini akan lebih ketat, jumlah halaman cenderung lebih dari satu.Seragam (distribusi seragam)
Seperti namanya, jika kita menggunakan Uniform, maka semua nilai akan digunakan untuk ID, dan distribusinya akan ... uniform.Zipfian (Distribusi Zipf)
Distribusi Zipf, kadang-kadang disebut distribusi zeta, adalah distribusi diskrit yang biasa digunakan dalam linguistik, asuransi, dan pemodelan kejadian langka. Dalam hal ini, sysbench akan menggunakan angka mulai dari yang terkecil (1) dan sangat cepat mengurangi frekuensi penggunaan, pindah ke angka yang lebih besar.Pareto (Pareto)
Pareto menerapkan aturan "80-20" . Dalam hal ini, ID yang dihasilkan akan dioleskan lebih sedikit dan akan lebih terkonsentrasi di segmen kecil. Dalam contoh kami, 52% dari semua ID memiliki nilai 1, dan 73% dari nilai berada di 10 angka pertama.Gaussian (Distribusi Gaussian)
Distribusi Gaussian (distribusi normal) sudah dikenal dan dikenal luas . Ini digunakan terutama dalam statistik dan perkiraan di sekitar faktor utama. Dalam hal ini, ID yang digunakan didistribusikan di sepanjang kurva berbentuk lonceng, dimulai dengan nilai rata-rata, dan perlahan-lahan menurun ke tepi.Apa gunanya ini?
Setiap opsi di atas memiliki penggunaannya sendiri dan dapat dikelompokkan berdasarkan tujuannya. Pareto dan Fokus khusus pada hot spot. Dalam hal ini, aplikasi menggunakan halaman / data yang sama berulang kali. Ini mungkin yang kita butuhkan, tetapi kita harus memahami apa yang kita lakukan dan tidak membuat kesalahan di sini.Misalnya, jika kami menguji kinerja kompresi halaman InnoDB saat membaca, kita harus menghindari menggunakan nilai default Special atau Pareto. Jika kami memiliki kumpulan data 1 TB dan kolam buffer 30 GB, dan kami meminta halaman yang sama berkali-kali, maka halaman ini akan sudah dibaca dari disk dan akan tersedia dalam memori yang tidak terkompresi.Singkatnya, tes semacam itu adalah buang-buang waktu dan usaha.Hal yang sama jika kita perlu memeriksa kinerja rekaman. Menulis halaman yang sama berulang kali bukanlah pilihan terbaik.Bagaimana dengan pengujian kinerja?Sekali lagi, kami ingin menguji kinerja, tetapi untuk kasus apa? Penting untuk dipahami bahwa metode menghasilkan angka acak sangat memengaruhi hasil tes. Dan "default yang cukup baik" Anda dapat menyebabkan kesimpulan yang salah.Grafik berikut menunjukkan latensi yang berbeda tergantung pada jenis rand (jenis tes, waktu, parameter tambahan, dan jumlah utas sama di mana-mana).Dari tipe ke tipe, keterlambatannya sangat berbeda: Di sini saya membaca dan menulis, dan data diambil dari Skema Kinerja (
Di sini saya membaca dan menulis, dan data diambil dari Skema Kinerja (sys.schema_table_statistics) Seperti yang diharapkan, Pareto dan Special memakan waktu lebih lama daripada yang lain, menyebabkan sistem (MySQL-InnoDB) secara artifisial menderita dari persaingan dalam satu "hot spot".Mengubah rand-type tidak hanya mempengaruhi penundaan, tetapi juga jumlah baris yang diproses, seperti yang ditunjukkan oleh skema kinerja.
 Mengingat semua hal di atas, penting untuk memahami apa yang kami coba evaluasi dan uji.Jika tujuan saya adalah untuk menguji kinerja sistem di semua level, saya mungkin lebih suka menggunakan Uniform, yang akan memuat data set / server database / sistem secara merata dan lebih mungkin untuk mendistribusikan read / load / write secara merata.Jika pekerjaan saya adalah bekerja dengan hot spot, maka Pareto dan Special mungkin merupakan pilihan yang tepat.Tetapi jangan gunakan nilai default secara membabi buta. Mungkin cocok untuk Anda, tetapi sering kali dimaksudkan untuk kasus-kasus ekstrem. Dalam pengalaman saya, Anda sering dapat menyesuaikan pengaturan untuk mendapatkan hasil yang Anda butuhkan.Misalnya, Anda ingin menggunakan nilai-nilai di tengah dengan memperluas interval sehingga tidak ada puncak yang tajam (khusus pada pengaturan standar) atau bel (Gaussian).Anda dapat mengonfigurasi Khusus untuk mendapatkan sesuatu seperti ini:
Mengingat semua hal di atas, penting untuk memahami apa yang kami coba evaluasi dan uji.Jika tujuan saya adalah untuk menguji kinerja sistem di semua level, saya mungkin lebih suka menggunakan Uniform, yang akan memuat data set / server database / sistem secara merata dan lebih mungkin untuk mendistribusikan read / load / write secara merata.Jika pekerjaan saya adalah bekerja dengan hot spot, maka Pareto dan Special mungkin merupakan pilihan yang tepat.Tetapi jangan gunakan nilai default secara membabi buta. Mungkin cocok untuk Anda, tetapi sering kali dimaksudkan untuk kasus-kasus ekstrem. Dalam pengalaman saya, Anda sering dapat menyesuaikan pengaturan untuk mendapatkan hasil yang Anda butuhkan.Misalnya, Anda ingin menggunakan nilai-nilai di tengah dengan memperluas interval sehingga tidak ada puncak yang tajam (khusus pada pengaturan standar) atau bel (Gaussian).Anda dapat mengonfigurasi Khusus untuk mendapatkan sesuatu seperti ini: Dalam kasus ini, ID masih dekat, dan ada persaingan. Tetapi pengaruh satu "hot spot" kurang, oleh karena itu kemungkinan konflik sekarang akan dengan beberapa ID, yang, tergantung pada jumlah catatan pada satu halaman, dapat pada beberapa halaman.Contoh lain adalah partisi. Misalnya, bagaimana memeriksa cara kerja sistem Anda dengan partisi, memfokuskan pada data terbaru, mengarsipkan yang lama?Mudah! Ingat grafik distribusi Pareto? Anda dapat mengubahnya sesuai dengan kebutuhan Anda.
Dalam kasus ini, ID masih dekat, dan ada persaingan. Tetapi pengaruh satu "hot spot" kurang, oleh karena itu kemungkinan konflik sekarang akan dengan beberapa ID, yang, tergantung pada jumlah catatan pada satu halaman, dapat pada beberapa halaman.Contoh lain adalah partisi. Misalnya, bagaimana memeriksa cara kerja sistem Anda dengan partisi, memfokuskan pada data terbaru, mengarsipkan yang lama?Mudah! Ingat grafik distribusi Pareto? Anda dapat mengubahnya sesuai dengan kebutuhan Anda. Dengan menentukan nilai -rand-pareto, Anda bisa mendapatkan apa yang Anda inginkan dengan memaksa sysbench untuk fokus pada nilai ID yang besar.Zipfian juga dapat diatur dan, meskipun Anda tidak bisa mendapatkan inversi, seperti halnya dengan Pareto, Anda dapat dengan mudah beralih dari puncak pada satu nilai ke distribusi yang lebih merata. Contoh yang baik adalah sebagai berikut:
Dengan menentukan nilai -rand-pareto, Anda bisa mendapatkan apa yang Anda inginkan dengan memaksa sysbench untuk fokus pada nilai ID yang besar.Zipfian juga dapat diatur dan, meskipun Anda tidak bisa mendapatkan inversi, seperti halnya dengan Pareto, Anda dapat dengan mudah beralih dari puncak pada satu nilai ke distribusi yang lebih merata. Contoh yang baik adalah sebagai berikut: Hal terakhir yang perlu diingat, dan bagi saya tampaknya ini adalah hal-hal yang jelas, tetapi lebih baik dikatakan daripada tidak mengatakan bahwa ketika mengubah parameter pembangkitan angka acak, kinerja akan berubah.Bandingkan latensi:
Hal terakhir yang perlu diingat, dan bagi saya tampaknya ini adalah hal-hal yang jelas, tetapi lebih baik dikatakan daripada tidak mengatakan bahwa ketika mengubah parameter pembangkitan angka acak, kinerja akan berubah.Bandingkan latensi: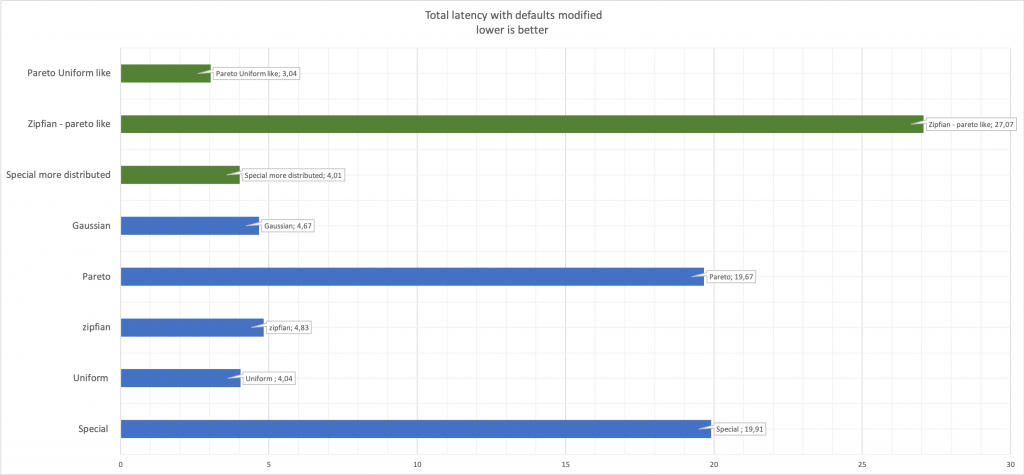 Di sini, hijau menunjukkan nilai yang diubah dibandingkan dengan biru asli.
Di sini, hijau menunjukkan nilai yang diubah dibandingkan dengan biru asli.
temuan
Pada titik ini, Anda harus sudah memahami betapa mudahnya mengatur pembuatan angka acak di sysbench, dan seberapa bermanfaat hal ini bagi Anda. Ingatlah bahwa hal di atas berlaku untuk panggilan apa pun, misalnya, ketika menggunakan sysbench.rand.default:local function get_id()
return sysbench.rand.default(1, sysbench.opt.table_size)
End
Mengingat hal ini, jangan sembarangan menyalin kode dari artikel orang lain, tetapi pikirkan dan selidiki apa yang Anda butuhkan dan bagaimana mencapainya.Sebelum menjalankan tes, periksa opsi pembuatan nomor acak untuk memastikan mereka sesuai dan sesuai dengan kebutuhan Anda. Untuk menyederhanakan hidup saya, saya menggunakan tes sederhana ini . Tes ini menampilkan informasi distribusi ID yang cukup jelas.Saran saya adalah Anda harus memahami kebutuhan Anda dan melakukan pengujian / benchmarking dengan benar.Referensi
Pertama-tama, ini adalah sysbench itu sendiri .Artikel di Zipfian:Pareto:Artikel Percona tentang cara menulis skrip Anda di sysbenchSemua bahan yang digunakan untuk artikel ini ada di GitHub .
→ Pelajari lebih lanjut tentang kursus