Selama 10 tahun keberadaan ivi, kami telah menyusun basis data 90.000 video dengan berbagai panjang, ukuran, dan kualitas. Ratusan yang baru muncul setiap minggu. Kami memiliki gigabyte metadata, yang berguna untuk rekomendasi, menyederhanakan navigasi layanan dan mengatur iklan. Tapi kami mulai mengekstrak informasi langsung dari video hanya dua tahun yang lalu.Dalam artikel ini saya akan memberi tahu Anda bagaimana kita mengurai film menjadi elemen struktural dan mengapa kita membutuhkannya. Pada akhirnya, ada tautan ke repositori Github dengan kode algoritme dan contoh.
Terdiri dari apa sebuah video?
Klip video memiliki struktur hierarkis. Ini tentang video digital, jadi pada level terendah adalah piksel , titik-titik berwarna yang membentuk gambar diam.Gambar diam disebut bingkai - mereka saling menggantikan dan menciptakan efek gerakan. Pada instalasi, frame dipotong menjadi kelompok-kelompok, yang, sebagaimana diarahkan oleh sutradara, dipertukarkan dan dilem kembali. Urutan frame dari satu rakitan yang direkatkan ke yang lain dalam bahasa Inggris disebut istilah shot. Sayangnya, terminologi Rusia tidak berhasil, karena di dalamnya kelompok seperti itu juga disebut bingkai. Agar tidak bingung, mari gunakan istilah bahasa Inggris. Cukup masukkan versi bahasa Rusia: "shot" .Bidikan dikelompokkan berdasarkan makna, mereka disebut adegan.Adegan ini ditandai oleh kesatuan tempat, waktu dan karakter.Kita dapat dengan mudah mendapatkan frame individual dan bahkan pixel dari frame-frame ini, karena algoritma pengkodean video digital diatur sedemikian rupa. Informasi ini diperlukan untuk reproduksi.Perbatasan pemotretan dan pemandangan jauh lebih sulit diperoleh. Sumber dari program instalasi mungkin membantu, tetapi mereka tidak tersedia untuk kami.Untungnya, algoritma dapat melakukan ini, meskipun tidak sepenuhnya akurat. Saya akan memberi tahu Anda tentang algoritma untuk membagi ke dalam adegan.
Pada instalasi, frame dipotong menjadi kelompok-kelompok, yang, sebagaimana diarahkan oleh sutradara, dipertukarkan dan dilem kembali. Urutan frame dari satu rakitan yang direkatkan ke yang lain dalam bahasa Inggris disebut istilah shot. Sayangnya, terminologi Rusia tidak berhasil, karena di dalamnya kelompok seperti itu juga disebut bingkai. Agar tidak bingung, mari gunakan istilah bahasa Inggris. Cukup masukkan versi bahasa Rusia: "shot" .Bidikan dikelompokkan berdasarkan makna, mereka disebut adegan.Adegan ini ditandai oleh kesatuan tempat, waktu dan karakter.Kita dapat dengan mudah mendapatkan frame individual dan bahkan pixel dari frame-frame ini, karena algoritma pengkodean video digital diatur sedemikian rupa. Informasi ini diperlukan untuk reproduksi.Perbatasan pemotretan dan pemandangan jauh lebih sulit diperoleh. Sumber dari program instalasi mungkin membantu, tetapi mereka tidak tersedia untuk kami.Untungnya, algoritma dapat melakukan ini, meskipun tidak sepenuhnya akurat. Saya akan memberi tahu Anda tentang algoritma untuk membagi ke dalam adegan.Mengapa kita memerlukan ini?
Kami memecahkan masalah pencarian di dalam video dan ingin menguji secara otomatis setiap adegan dari setiap film di ivi. Membagi menjadi adegan adalah bagian penting dari pipa ini.Untuk mengetahui di mana adegan dimulai dan berakhir, Anda perlu membuat trailer sintetis. Kami sudah memiliki algoritma yang menghasilkannya, tetapi sejauh ini, deteksi adegan tidak digunakan di sana.Sistem pemberi rekomendasi juga berguna untuk membagi menjadi beberapa adegan. Dari mereka, diperoleh tanda-tanda yang menggambarkan film mana yang disukai pengguna dalam struktur.Apa pendekatan untuk memecahkan masalah?
Masalahnya dipecahkan dari dua sisi:- Mereka mengambil seluruh video dan mencari batas-batas adegan.
- Pertama, mereka membagi video menjadi bidikan, dan kemudian menggabungkannya menjadi adegan.
Kami pergi dengan cara kedua, karena lebih mudah untuk diformalkan, dan ada artikel ilmiah tentang topik ini. Kami sudah tahu cara membagi video menjadi foto. Tetap mengumpulkan foto-foto ini ke dalam adegan.Hal pertama yang ingin Anda coba adalah pengelompokan. Ambil bidikan, ubah menjadi vektor, lalu bagi vektor menjadi kelompok klasik menggunakan algoritme pengelompokan klasik. Kelemahan utama dari pendekatan ini: tidak memperhitungkan bahwa pemotretan dan adegan saling mengikuti. Tembakan dari adegan lain tidak dapat berdiri di antara dua tembakan dari satu adegan, dan dengan pengelompokan ini dimungkinkan.Pada tahun 2016, Daniel Rothman dan rekan - rekannya dari IBM mengusulkan algoritma yang memperhitungkan struktur waktu dan merumuskan menggabungkan bidikan ke dalam adegan sebagai tugas Pengelompokan Urutan Optimal:
Kelemahan utama dari pendekatan ini: tidak memperhitungkan bahwa pemotretan dan adegan saling mengikuti. Tembakan dari adegan lain tidak dapat berdiri di antara dua tembakan dari satu adegan, dan dengan pengelompokan ini dimungkinkan.Pada tahun 2016, Daniel Rothman dan rekan - rekannya dari IBM mengusulkan algoritma yang memperhitungkan struktur waktu dan merumuskan menggabungkan bidikan ke dalam adegan sebagai tugas Pengelompokan Urutan Optimal:- diberi urutan tembakan
- perlu membaginya menjadi segmen sehingga pemisahan ini optimal.
Apa pemisahan optimal?
Untuk saat ini, kami menganggap itu diberikan, yaitu, jumlah adegan diketahui. Hanya perbatasan mereka yang tidak diketahui.Jelas, semacam metrik diperlukan. Tiga metrik ditemukan, mereka didasarkan pada gagasan jarak berpasangan antara tembakan.Langkah-langkah persiapan adalah sebagai berikut:- Kami mengubah gambar menjadi vektor (histogram atau output dari lapisan kedua dari belakang jaringan saraf)
- Temukan jarak berpasangan antara vektor (Euclidean, cosinus, atau lainnya)
- Kami mendapatkan matriks persegi di mana setiap elemen adalah jarak antar tembakan dan .
 Matriks ini simetris, dan pada diagonal utama ia akan selalu memiliki nol, karena jarak vektor itu sendiri adalah nol.Kotak gelap dilacak di sepanjang diagonal - area di mana bidikan tetangga mirip satu sama lain, dengan demikian jaraknya kurang.Jika kita memilih embeddings bagus yang mencerminkan semantik tembakan dan memilih fungsi jarak yang baik, maka kotak ini adalah adegan. Temukan batas kotak - kita akan menemukan batas layar.Melihat matriks, rekan-rekan Israel merumuskan tiga kriteria untuk partisi yang optimal:
Matriks ini simetris, dan pada diagonal utama ia akan selalu memiliki nol, karena jarak vektor itu sendiri adalah nol.Kotak gelap dilacak di sepanjang diagonal - area di mana bidikan tetangga mirip satu sama lain, dengan demikian jaraknya kurang.Jika kita memilih embeddings bagus yang mencerminkan semantik tembakan dan memilih fungsi jarak yang baik, maka kotak ini adalah adegan. Temukan batas kotak - kita akan menemukan batas layar.Melihat matriks, rekan-rekan Israel merumuskan tiga kriteria untuk partisi yang optimal:
Apakah vektor perbatasan adegan.Manakah dari kriteria untuk partisi optimal untuk memilih?
Fungsi kerugian yang baik untuk tugas Pengurutan Berurutan Optimal memiliki dua properti:- Jika film terdiri dari satu adegan, maka di mana pun kami mencoba membaginya menjadi dua bagian, nilai fungsinya akan selalu sama.
- Jika dibagi menjadi beberapa adegan, nilainya akan lebih kecil dari jika tidak benar.
Ternyata dan tidak memenuhi persyaratan ini, tetapi mengatasi. Untuk menggambarkan hal ini, kami akan melakukan dua percobaan.Dalam percobaan pertama, kami akan membuat matriks sintetis dari jarak berpasangan, mengisinya dengan noise yang seragam. Jika kita mencoba membagi menjadi dua adegan, kita mendapatkan gambar berikut: mengatakan bahwa di tengah video ada perubahan adegan, yang sebenarnya tidak benar. Diabnormal melompat jika partisi ditempatkan di awal atau di akhir video. Hanyaberperilaku seperti yang dipersyaratkan.Dalam percobaan kedua, kita akan membuat matriks yang sama dengan noise yang seragam, tetapi kurangi dua kotak darinya, seolah-olah kita memiliki dua adegan yang sedikit berbeda satu sama lain.
mengatakan bahwa di tengah video ada perubahan adegan, yang sebenarnya tidak benar. Diabnormal melompat jika partisi ditempatkan di awal atau di akhir video. Hanyaberperilaku seperti yang dipersyaratkan.Dalam percobaan kedua, kita akan membuat matriks yang sama dengan noise yang seragam, tetapi kurangi dua kotak darinya, seolah-olah kita memiliki dua adegan yang sedikit berbeda satu sama lain.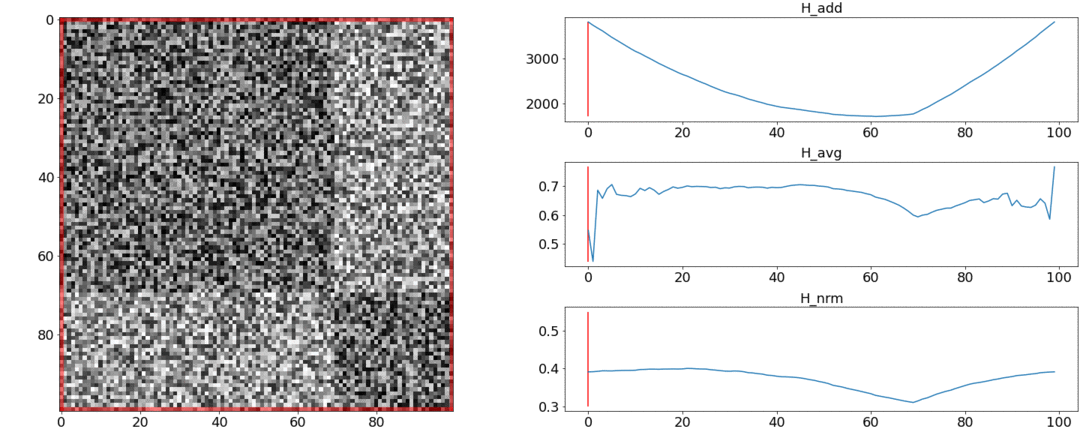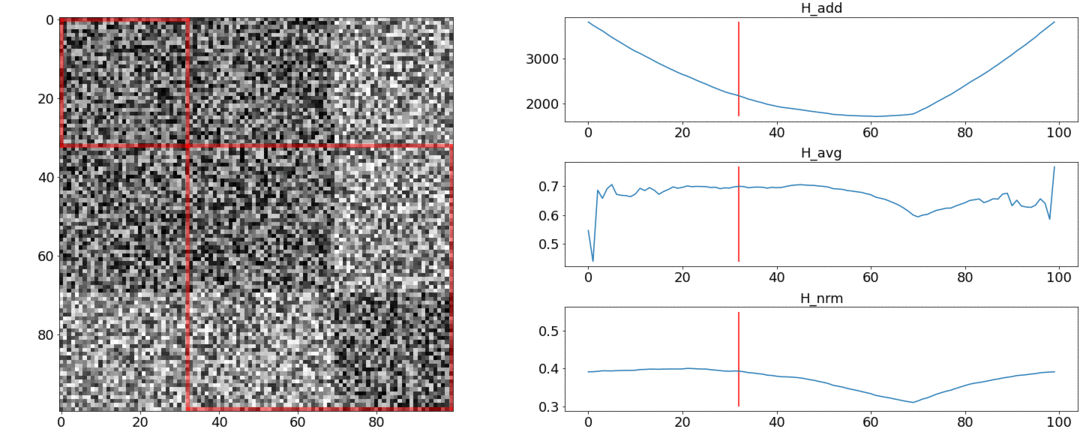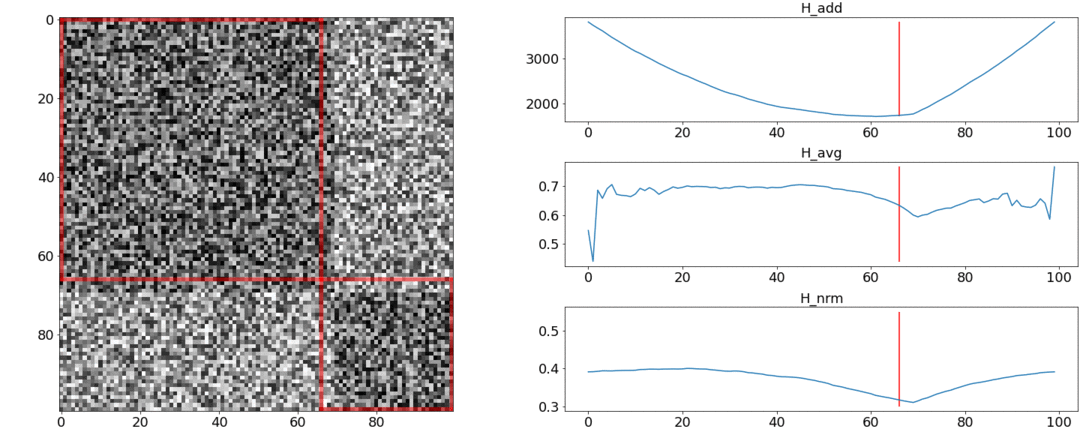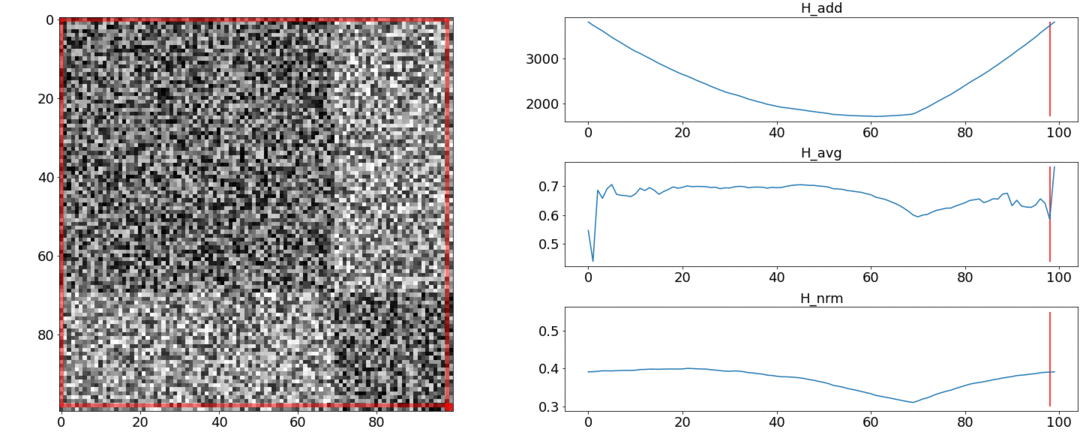 Untuk mendeteksi perekatan ini, fungsi harus mengambil nilai minimum saat. Tapi minimal masih lebih dekat ke tengah segmen, sementara - ke awal. Di minimum yang jelas terlihat di .Tes juga menunjukkan bahwa pemisahan paling akurat dicapai dengan menggunakan. Tampaknya Anda perlu mengambilnya, dan semuanya akan baik-baik saja. Tetapi pertama-tama mari kita lihat kompleksitas algoritma optimasi.Daniel Rothman dan kelompoknya menyarankan mencari partisi optimal menggunakan pemrograman dinamis . Tugas ini dibagi menjadi beberapa subtugas secara rekursif dan diselesaikan secara bergantian. Metode ini memberikan global optimal, tetapi untuk menemukannya, Anda perlu mengulanginya masing-masingsemua kombinasi partisi dari tembakan ke-0 dan ke-N dan pilih yang terbaik. Sini - jumlah adegan, dan - jumlah tembakan.Tidak ada tweak dan optimasi akselerasi akan bekerja tepat waktu . DIAda satu parameter lagi untuk enumerasi - area partisi, dan pada setiap langkah perlu untuk memeriksa semua nilainya. Dengan demikian, waktu bertambah menjadi.Kami berhasil melakukan beberapa peningkatan dan mempercepat pengoptimalan menggunakan teknik Penghafalan - menyimpan hasil rekursi dalam memori agar tidak membaca hal yang sama berulang kali. Tetapi, seperti yang ditunjukkan oleh tes di bawah ini, peningkatan kecepatan yang kuat tidak tercapai.
Untuk mendeteksi perekatan ini, fungsi harus mengambil nilai minimum saat. Tapi minimal masih lebih dekat ke tengah segmen, sementara - ke awal. Di minimum yang jelas terlihat di .Tes juga menunjukkan bahwa pemisahan paling akurat dicapai dengan menggunakan. Tampaknya Anda perlu mengambilnya, dan semuanya akan baik-baik saja. Tetapi pertama-tama mari kita lihat kompleksitas algoritma optimasi.Daniel Rothman dan kelompoknya menyarankan mencari partisi optimal menggunakan pemrograman dinamis . Tugas ini dibagi menjadi beberapa subtugas secara rekursif dan diselesaikan secara bergantian. Metode ini memberikan global optimal, tetapi untuk menemukannya, Anda perlu mengulanginya masing-masingsemua kombinasi partisi dari tembakan ke-0 dan ke-N dan pilih yang terbaik. Sini - jumlah adegan, dan - jumlah tembakan.Tidak ada tweak dan optimasi akselerasi akan bekerja tepat waktu . DIAda satu parameter lagi untuk enumerasi - area partisi, dan pada setiap langkah perlu untuk memeriksa semua nilainya. Dengan demikian, waktu bertambah menjadi.Kami berhasil melakukan beberapa peningkatan dan mempercepat pengoptimalan menggunakan teknik Penghafalan - menyimpan hasil rekursi dalam memori agar tidak membaca hal yang sama berulang kali. Tetapi, seperti yang ditunjukkan oleh tes di bawah ini, peningkatan kecepatan yang kuat tidak tercapai.Bagaimana cara memperkirakan jumlah adegan?
Sebuah kelompok dari IBM menyarankan bahwa karena banyak baris matriks bergantung secara linear, jumlah cluster persegi sepanjang diagonal akan kira-kira sama dengan pangkat matriks.Untuk memperolehnya dan pada saat yang sama menyaring kebisingan, Anda memerlukan dekomposisi tunggal dari matriks.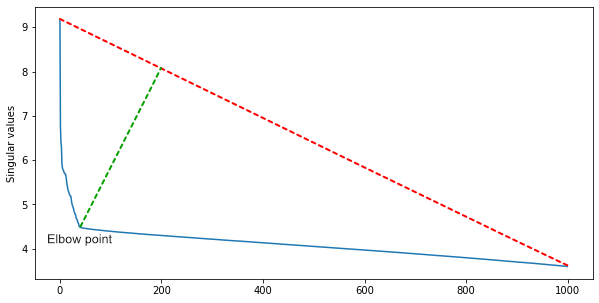 Di antara nilai-nilai singular, diurutkan dalam urutan menurun, kami menemukan titik siku - titik dari mana penurunan nilai melambat tajam. Indeks titik siku adalah perkiraan jumlah adegan dalam sebuah film.Untuk perkiraan pertama, ini sudah cukup, tetapi Anda dapat melengkapi algoritme dengan heuristik untuk berbagai genre bioskop. Dalam film aksi, ada lebih banyak adegan, dan di rumah seni - kurang.
Di antara nilai-nilai singular, diurutkan dalam urutan menurun, kami menemukan titik siku - titik dari mana penurunan nilai melambat tajam. Indeks titik siku adalah perkiraan jumlah adegan dalam sebuah film.Untuk perkiraan pertama, ini sudah cukup, tetapi Anda dapat melengkapi algoritme dengan heuristik untuk berbagai genre bioskop. Dalam film aksi, ada lebih banyak adegan, dan di rumah seni - kurang.Tes
Kami ingin memahami dua hal:- Apakah perbedaan kecepatan begitu dramatis?
- Berapa banyak akurasi yang diderita ketika menggunakan algoritma yang lebih cepat?
Tes dibagi menjadi dua kelompok: data sintetis dan nyata. Pada tes sintetik, kualitas dan kecepatan kedua algoritma dibandingkan, dan pada yang nyata, mereka mengukur kualitas algoritma tercepat. Tes kecepatan dilakukan pada MacBook Pro 2017, 2,3 GHz Intel Core i5, 16 GB 2133 MHz LPDDR3.Tes kualitas sintetis
Kami menghasilkan 999 matriks jarak berpasangan dengan ukuran mulai dari 12 hingga 122 bidikan, membaginya secara acak menjadi 2-10 adegan dan menambahkan noise normal dari atas.Untuk setiap matriks, partisi optimal ditemukan dalam hal dan , dan kemudian menghitung metrik Precision, Recall, F1, dan IoU.Kami mempertimbangkan Precision dan Recall untuk interval menggunakan rumus berikut:
Kami menganggap F1 seperti biasa, menggantikan interval Precision and Recall:
Untuk membandingkan segmen yang diprediksi dan yang sebenarnya dalam film, untuk setiap yang diprediksi, kami menemukan segmen yang benar dengan persimpangan terbesar dan mempertimbangkan metrik untuk pasangan ini.Berikut hasilnya: Optimalisasi fungsi dimenangkan dalam semua metrik, seperti dalam pengujian penulis algoritma.
Optimalisasi fungsi dimenangkan dalam semua metrik, seperti dalam pengujian penulis algoritma.Tes kecepatan sintetis
Untuk menguji kecepatan, kami melakukan tes sintetis lainnya. Yang pertama adalah bagaimana waktu menjalankan algoritma tergantung pada jumlah pemotretan.dengan jumlah adegan tetap: Tes mengonfirmasi penilaian teoretis: waktu optimasi tumbuh secara polinomi dengan pertumbuhan dibandingkan dengan waktu linier di .Jika Anda memperbaiki jumlah tembakan dan secara bertahap menambah jumlah adegan , kami mendapatkan gambar yang lebih menarik. Pada awalnya, waktu diharapkan untuk tumbuh, tetapi kemudian mulai menurun. Faktanya adalah bahwa jumlah kemungkinan nilai penyebut (rumus) bahwa kita perlu memeriksa secara proporsional dengan jumlah cara yang dapat kita hancurkan segmen aktif . Dihitung menggunakan kombinasi oleh :
Tes mengonfirmasi penilaian teoretis: waktu optimasi tumbuh secara polinomi dengan pertumbuhan dibandingkan dengan waktu linier di .Jika Anda memperbaiki jumlah tembakan dan secara bertahap menambah jumlah adegan , kami mendapatkan gambar yang lebih menarik. Pada awalnya, waktu diharapkan untuk tumbuh, tetapi kemudian mulai menurun. Faktanya adalah bahwa jumlah kemungkinan nilai penyebut (rumus) bahwa kita perlu memeriksa secara proporsional dengan jumlah cara yang dapat kita hancurkan segmen aktif . Dihitung menggunakan kombinasi oleh :
Dengan pertumbuhan jumlah kombinasi pertama tumbuh, dan kemudian turun saat Anda mendekati . Ini tampaknya keren, tetapi jumlah adegan jarang akan sama dengan jumlah pemotretan, dan akan selalu mengambil nilai sedemikian rupa sehingga ada banyak kombinasi. Dalam "Avengers" yang telah disebutkan 2700 tembakan dan 105 adegan. Jumlah Kombinasi:
Ini tampaknya keren, tetapi jumlah adegan jarang akan sama dengan jumlah pemotretan, dan akan selalu mengambil nilai sedemikian rupa sehingga ada banyak kombinasi. Dalam "Avengers" yang telah disebutkan 2700 tembakan dan 105 adegan. Jumlah Kombinasi:
Untuk memastikan bahwa semuanya dipahami dengan benar dan tidak terjerat dalam notasi artikel asli, kami menulis surat kepada Daniel Rothman. Dia mengkonfirmasi itu sangat lambat untuk mengoptimalkan dan tidak cocok untuk video lebih dari 10 menit, dan dalam praktiknya memberikan hasil yang dapat diterima.Tes data nyata
Jadi, kami telah memilih metrik , yang, meskipun sedikit kurang akurat, bekerja lebih cepat. Sekarang kita membutuhkan metrik, dari mana kita akan membangun pencarian untuk algoritma yang lebih baik.Untuk pengujian kami menandai 20 film dari genre dan tahun yang berbeda. Markup dilakukan dalam lima tahap:- :
- , .
- . « ?»
- CV. — , .
- , « ».
Beginilah tampilan juru tulis dan layar inspektur: Dan inilah bagaimana 300 bidikan pertama film "Avengers: Infinity War" dibagi menjadi beberapa adegan. Di sebelah kiri adalah pemandangan yang benar, dan di sebelah kanan adalah yang diprediksi oleh algoritma:
Dan inilah bagaimana 300 bidikan pertama film "Avengers: Infinity War" dibagi menjadi beberapa adegan. Di sebelah kiri adalah pemandangan yang benar, dan di sebelah kanan adalah yang diprediksi oleh algoritma: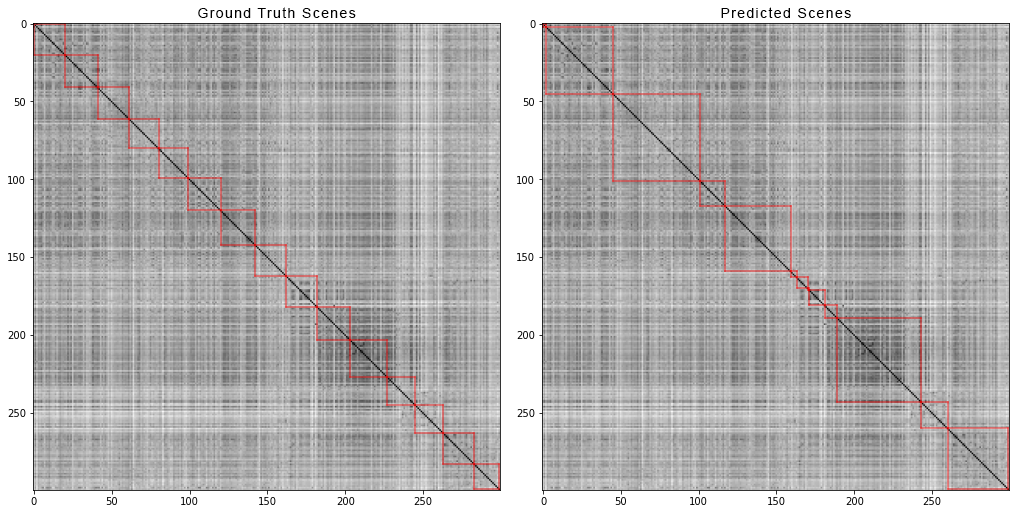 Untuk mendapatkan matriks jarak berpasangan, kami melakukan hal berikut:Untuk setiap video dari set data, kami menghasilkan matriks jarak berpasangan dan, seperti halnya untuk data sintetis, kami menghitung empat metrik. Berikut angka-angka yang keluar:
Untuk mendapatkan matriks jarak berpasangan, kami melakukan hal berikut:Untuk setiap video dari set data, kami menghasilkan matriks jarak berpasangan dan, seperti halnya untuk data sintetis, kami menghitung empat metrik. Berikut angka-angka yang keluar:- Presisi : 0,4861919030708739
- Ingat : 0.8225937459424839
- F1 : 0,513676858711775
- IoU : 0.37560909807842874
Terus?
Kami memiliki garis dasar yang tidak berfungsi dengan baik, tetapi sekarang Anda dapat membangunnya saat kami mencari metode yang lebih akurat.Beberapa rencana selanjutnya:- Coba arsitektur CNN lainnya untuk ekstraksi fitur.
- Coba metrik jarak lain di antara pemotretan.
- Coba metode pengoptimalan lainnya misalnya, algoritma genetika.
- Cobalah untuk mengurangi penguraian keseluruhan film menjadi beberapa bagian terpisah memenuhi dalam waktu yang wajar, dan membandingkan apa yang akan menjadi kerugian dalam kualitas.
Kode dari kedua metode dan percobaan pada data sintetis diterbitkan di Github . Anda dapat menyentuh dan mencoba mempercepat diri sendiri. Suka dan tarik permintaan dipersilakan.Sampai jumpa semuanya, sampai jumpa di artikel selanjutnya!