Dalam prosesor Intel x86 modern, pipa dapat dibagi menjadi 2 bagian: Front End dan Back End.Front End bertanggung jawab untuk memuat kode dari memori dan mendekodekannya dalam operasi mikro.Back End bertanggung jawab untuk melakukan operasi mikro dari Front End. Karena operasi mikro ini dapat dilakukan oleh kernel yang rusak, Back End juga memastikan bahwa hasil dari operasi mikro ini benar-benar sesuai dengan urutan kode tersebut.Dalam kebanyakan kasus, penggunaan Front End'a yang tidak efisien tidak memiliki efek nyata pada kinerja. Bandwidth puncak pada sebagian besar prosesor Intel adalah 4 operasi mikro per siklus, oleh karena itu, misalnya, untuk kode yang terikat Memori / L3, CPU tidak akan dapat sepenuhnya menggunakannya.Danau Es Pro relatif baru, Ice Lake 4 5 . , , .
Namun, dalam beberapa kasus, perbedaan kinerja bisa sangat signifikan. Di bawah potongan adalah analisis dampak dari cache operasi mikro pada kinerja.Isi artikel
- Lingkungan Hidup
- Tinjauan Umum tentang prosesor Front End'a Intel
- Analisis Bandwidth Puncak µop cache -> IDQ
- Contoh
Lingkungan Hidup
Untuk semua pengukuran dalam artikel ini akan digunakan i7-8550U Kaby Lake, HT diaktifkan / Ubuntu 18.04/Linux Kernel 5.3.0-45-generic. Dalam hal ini, lingkungan seperti itu dapat menjadi signifikan, karena setiap model CPU memiliki acara kinerjanya sendiri. Khususnya, untuk arsitektur mikro yang lebih tua dari Sandy Bridge, beberapa peristiwa yang digunakan di masa depan sama sekali tidak masuk akal.Tinjauan Umum tentang prosesor Front End'a Intel
Organisasi jalur perakitan tingkat tinggi adalah informasi yang tersedia untuk umum dan diterbitkan dalam dokumentasi resmi Intel tentang pengoptimalan perangkat lunak . Penjelasan lebih rinci tentang beberapa fitur yang dihilangkan dari dokumentasi resmi dapat ditemukan di sumber-sumber terkemuka lainnya, seperti Agner Fog atau Travis Downs . Jadi, misalnya, skema jalur pipa perakitan untuk Skylake dalam dokumentasi Intel terlihat seperti ini: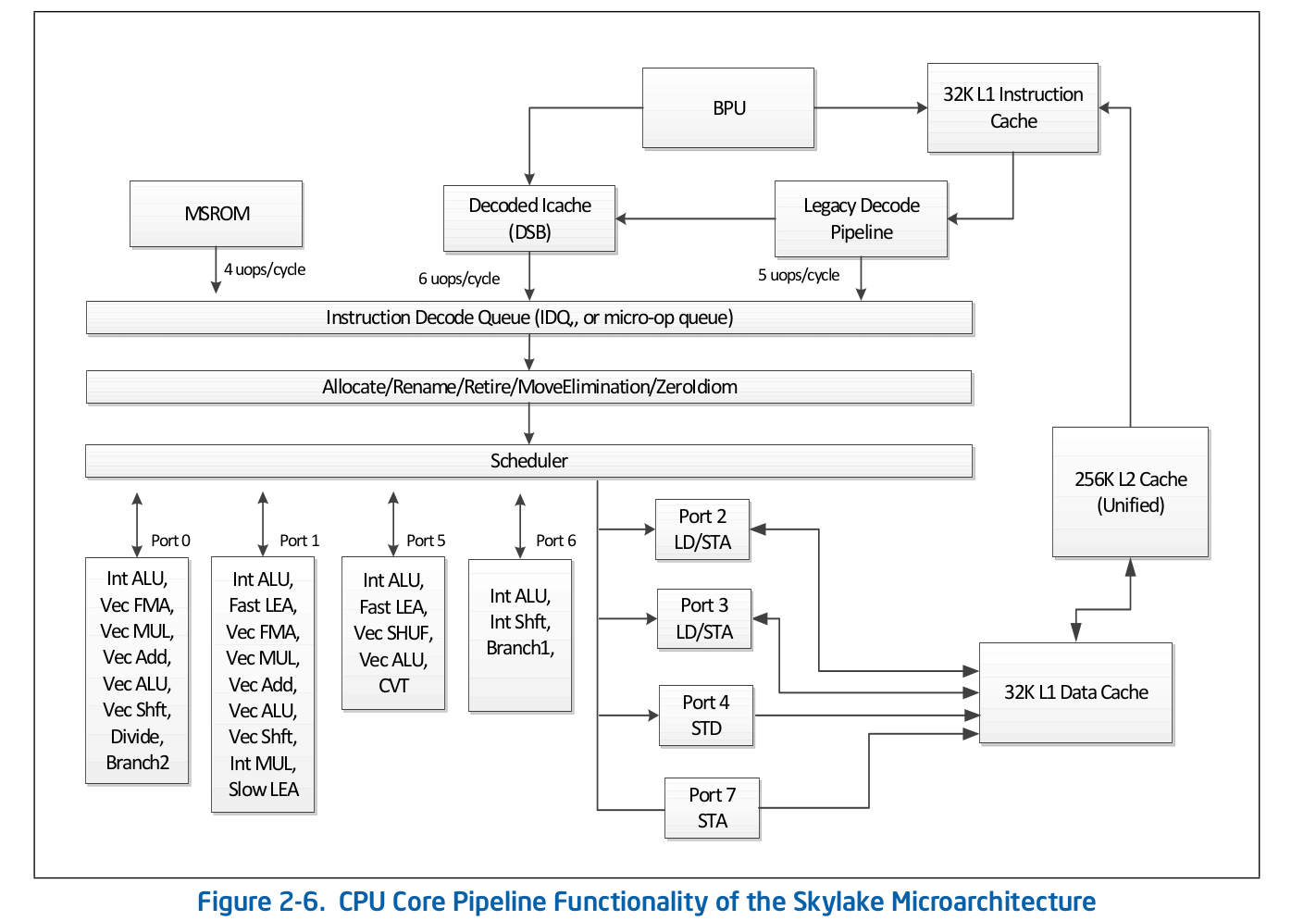 Mari kita lihat lebih dekat di bagian atas skema ini - Front End.
Mari kita lihat lebih dekat di bagian atas skema ini - Front End. Pipeline Decode Pipeline bertanggung jawab untuk mendekode kode dalam operasi mikro. Ini terdiri dari komponen-komponen berikut:
Pipeline Decode Pipeline bertanggung jawab untuk mendekode kode dalam operasi mikro. Ini terdiri dari komponen-komponen berikut:- Unit Ambil Instruksi - IFU
- Cache Petunjuk Level Pertama - L1i
- Instruksi Log Terjemahan Alamat Cache - ITLB
- Pengajar Instruktur
- Petunjuk pra-dekoder
- Antrian instruksi yang telah diterjemahkan
- Pengurai instruksi pra-dekode operasi mikro
Pertimbangkan masing-masing bagian dari Legacy Decode Pipeline secara individual.Unit Ambil Instruksi.Dia bertanggung jawab untuk memuat kode, pra-pengkodean (menentukan panjang instruksi dan properti seperti "apakah instruksi adalah cabang") dan mengirimkan instruksi yang telah didekodekan ke antrian.Cache Petunjuk Level Pertama - L1iUntuk mengunduh kode, IFU menggunakan L1i, cache instruksi tingkat pertama, dan L2 / LLC, cache level kedua dan cache offcore tingkat atas, yang umum digunakan untuk kode dan data. Pengunduhan dilakukan dalam ukuran 16 byte, juga disesuaikan dengan 16 byte. Ketika potongan kode 16 byte berikutnya dimuat secara berurutan, panggilan dilakukan ke L1i dan, jika baris yang sesuai tidak ditemukan, maka pencarian dilakukan di L2 dan, jika terjadi kegagalan, pada LLC dan memori. Sebelum Skylake LLC, cache bersifat inklusif - setiap baris di L1 (i / d) dan L2 harus dimuat dalam LLC. Dengan demikian, LLC “tahu” tentang semua garis di semua inti dan, dalam kasus LLC meleset, diketahui apakah cache di inti lainnya berisi garis yang diperlukan dalam keadaan Dimodifikasi, yang berarti bahwa garis ini dapat dimuat dari inti lain. Skylake LLC menjadi cache korban-L2 yang non-inklusif, tetapi ukuran L2 meningkat 4 kali lipat. Saya tidak tahuapakah L2 inklusif sehubungan dengan L1i. L2tidak inklusif sehubungan dengan L1d.Penerjemahan alamat logis dari instruksi - ITLBSebelum mengunduh data dari cache, Anda harus mencari baris yang sesuai. Untuk ncache asosiatif-jalan , setiap baris dapat berada di ntempat yang berbeda dalam cache itu sendiri. Untuk menentukan posisi yang mungkin dalam cache, indeks digunakan (biasanya beberapa bit lebih rendah dari alamat). Untuk menentukan apakah baris cocok dengan alamat yang kami butuhkan, tag digunakan (sisa alamat). Alamat mana yang akan digunakan: fisik atau logis - tergantung pada implementasi cache. Menggunakan alamat fisik membutuhkan terjemahan alamat. Untuk terjemahan alamat, buffer TLB digunakan, yang menyimpan hasil penelusuran halaman, dengan demikian mengurangi penundaan dalam menerima alamat fisik dari alamat logis pada panggilan berikutnya. Untuk instruksi, ada buffer TLB Instruksi sendiri, yang terletak secara terpisah dari TLB Data. Inti CPU juga memiliki TLB tingkat kedua yang umum digunakan untuk kode dan data - STLB. Apakah STLB inklusif tidak saya ketahui (dikabarkan bukan cache korban inklusif relatif terhadap D / I TLB). Menggunakan Petunjuk Prefetch Perangkat Lunakprefetcht1Anda dapat menarik baris dengan kode di L2, namun, catatan TLB yang sesuai akan ditarik hanya di DTLB. Jika STLB tidak inklusif, maka ketika Anda mencari baris ini dengan kode di dalam cache, Anda akan mendapatkan ITLB miss -> STLB miss -> page walk (sebenarnya, itu tidak begitu sederhana, karena kernel dapat memulai berjalan halaman spekulatif sebelum itu terjadi Miss TLB). Dokumentasi Intel juga mencegah penggunaan prefetch SW untuk kode, Intel Software Optimization Manual / 2.5.5.4:Prefetch yang dikendalikan perangkat lunak dimaksudkan untuk mengambil data awal, tetapi tidak untuk kode prefetching.
Namun, Travis D. menyebutkan bahwa prefetch semacam itu bisa sangat efektif (dan kemungkinan besar memang demikian), tetapi sejauh ini tidak jelas bagi saya dan untuk diyakinkan tentang hal ini saya perlu memeriksa masalah ini secara terpisah.Pengajar InstrukturPemuatan data ke dalam cache (L1d / i, L2, dll) terjadi ketika mengakses lokasi memori yang tidak di-cache. Namun, jika ini terjadi hanya dalam kondisi seperti itu, maka sebagai hasilnya kita akan mendapatkan penggunaan bandwidth cache yang tidak efisien. Misalnya, pada operasi Sandy Bridge untuk L1d - 2 baca, 1 tulis 16 byte per siklus; untuk L1i - 1 operasi baca 16 byte, tulis throughput tidak ditentukan dalam dokumentasi, Agner Fog juga tidak ditemukan. Untuk mengatasi masalah ini, ada prefetcher Perangkat Keras yang dapat menentukan pola akses ke memori dan menarik garis yang diperlukan ke dalam cache sebelum kode benar-benar mengatasinya. Dokumentasi Intel menetapkan 4 prefetcher: 2 untuk L1d, 2 untuk L2:- L1 DCU - Awalan garis cache serial. Hanya Baca Maju
- L1 IP — (. 0x5555555545a0, 0x5555555545b0, 0x5555555545c0, ...), , ,
- L2 Spatial — L2 -, 128-. LLC
- L2 Streamer — . L1 DCU «». LLC
Dokumentasi Intel tidak menjelaskan prinsip prefektor L1i. Yang diketahui hanyalah bahwa Unit Prediksi Cabang (BPU) terlibat dalam proses ini, Manual Pengoptimalan Perangkat Lunak Intel / 2.6.2: Agner Fog juga tidak melihat detail apa pun.Pengambilan kode sebelumnya dalam L2 / LLC secara eksplisit ditentukan hanya untuk Streamer. Manual Pengoptimalan / 2.5.5.4 Pembuatan Data:
Agner Fog juga tidak melihat detail apa pun.Pengambilan kode sebelumnya dalam L2 / LLC secara eksplisit ditentukan hanya untuk Streamer. Manual Pengoptimalan / 2.5.5.4 Pembuatan Data:Streamer : Prefetcher ini memonitor permintaan membaca dari cache L1 untuk urutan naik dan turunnya alamat. Permintaan baca yang dimonitor termasuk permintaan L1 DCache yang dimulai oleh operasi memuat dan menyimpan dan oleh prefetcher perangkat keras, dan permintaan L1 ICache untuk pengambilan kode.
Untuk prefetcher Spasial, ini jelas tidak dijabarkan:Prefetcher Spasial: Prefetcher ini berusaha untuk menyelesaikan setiap baris cache yang diambil ke cache L2 dengan garis pasangan yang melengkapinya ke potongan sejajar 128-byte.
Tetapi ini bisa diverifikasi. Masing-masing prefetcher ini dapat dimatikan menggunakan MSR 0x1A4, seperti yang dijelaskan dalam manual Register Spesifik Model.Tentang MSR 0x1A4MSR L2 Spatial L1i. . , LLC. L2 Streamer 2.5 .
Linux msr , msr . $ sudo wrmsr -p 1 0x1a4 1 L2 Streamer 1.
Instruksi pra-dekoderSetelah kode 16-byte berikutnya dimuat, mereka masuk ke dalam instruksi pra-dekoder. Tugasnya adalah untuk menentukan panjang instruksi, memecahkan kode awalan dan menandai apakah instruksi yang sesuai adalah cabang (kemungkinan besar masih ada banyak properti yang berbeda, tetapi dokumentasi tentang mereka adalah diam). Manual Pengoptimalan Perangkat Lunak Intel / 2.6.2.2:The predecode unit accepts the sixteen bytes from the instruction cache or prefetch buffers and carries out the following tasks:
- Determine the length of the instructions
- Decode all prefixes associated with instructions
- Mark various properties of instructions for the decoders (for example, “is branch.”)
Baris instruksi yang sudah diterjemahkan.Dari IFU, instruksi ditambahkan ke antrian instruksi yang sudah dikodekan. Antrian ini telah muncul sejak Nehalem, sesuai dengan dokumentasi Intel, ukurannya adalah 18 instruksi. Agner Fog juga menyebutkan bahwa antrian ini menampung tidak lebih dari 64 byte.Juga di Core2, antrian ini digunakan sebagai cache loop. Jika semua operasi mikro dari siklus berada dalam antrian, maka dalam beberapa kasus biaya pemuatan dan pra-pengkodean dapat dihindari. Loop Stream Detector (LSD) dapat memberikan instruksi yang sudah ada dalam antrian sampai BPU memberi sinyal bahwa siklus telah berakhir. Agner Fog memiliki sejumlah catatan menarik tentang LSD di Core2:- Terdiri dari 4 baris 16 byte
- Puncak throughput hingga 32 byte kode per siklus
Dimulai dengan Sandy Bridge, cache loop ini telah pindah dari antrian instruksi yang sudah didekodekan kembali ke IDQ.Decoder instruksi pra-dekode dalam operasi mikroDari antrian instruksi pra-dekode, kode dikirim ke decoding dalam operasi mikro. Decoder bertanggung jawab untuk decoding - ada total 4. Sesuai dengan dokumentasi Intel, salah satu decoder dapat mendekode instruksi yang terdiri dari 4 operasi mikro atau kurang. Sisanya menerjemahkan instruksi yang terdiri dari satu operasi mikro (menyatu mikro / makro), Intel Software Optimization Manual / 2.5.2.1:There are four decoding units that decode instruction into micro-ops. The first can decode all IA-32 and Intel 64 instructions up to four micro-ops in size. The remaining three decoding units handle single-micro-op instructions. All four decoding units support the common cases of single micro-op flows including micro-fusion and macro-fusion.
Instruksi diterjemahkan dalam sejumlah besar operasi mikro (mis. Rep movsb yang digunakan dalam implementasi memcpy dalam libc pada ukuran tertentu dari memori yang disalin) berasal dari Microcode Sequencer (MS ROM). Bandwidth puncak sequencer adalah 4 operasi mikro per siklus.Seperti yang dapat Anda lihat dalam diagram jalur perakitan, Legacy Decode Pipeline dapat mendekodekan hingga 5 operasi mikro per siklus di Skylake. Pada Broadwell dan yang lebih tua, throughput puncak Pipeline Decode Pipeline adalah 4 operasi mikro per siklus.Cache operasi mikroSetelah instruksi diterjemahkan dalam operasi mikro, dari Legacy Decode Pipeline mereka jatuh ke dalam antrian operasi mikro khusus - Antrian Dekode Instruksi (IDQ), serta apa yang disebut cache operasi mikro (Decoded ICache, cache µop). Cache operasi mikro awalnya diperkenalkan di Sandy Bridge dan digunakan untuk menghindari mengambil dan mendekode instruksi dalam operasi mikro, sehingga meningkatkan throughput untuk mengirimkan operasi mikro di IDQ - hingga 6 per siklus. Setelah masuk ke IDQ, operasi mikro pergi ke Back End untuk eksekusi dengan throughput puncak 4 operasi mikro per siklus.Menurut dokumentasi Intel, cache operasi mikro terdiri dari 32 set, setiap set berisi 8 baris, setiap baris dapat menyimpan cache hingga 6 operasi mikro (penyatuan mikro / makro), memungkinkan total cache hingga 32 * 8 * 6 = 1536 operasi mikro . Caching operasi mikro terjadi dengan granularitas 32 byte, mis. operasi mikro yang mengikuti instruksi dari berbagai wilayah 32-byte tidak dapat dikelompokkan menjadi satu baris. Namun, hingga 3 baris cache yang berbeda dapat sesuai dengan satu wilayah 32-byte. Dengan demikian, hingga 18 operasi mikro dalam cache µop dapat sesuai dengan masing-masing wilayah 32-byte.Manual Pengoptimalan Perangkat Lunak Intel / 2.5.5.2The Decoded ICache consists of 32 sets. Each set contains eight Ways. Each Way can hold up to six micro-ops. The Decoded ICache can ideally hold up to 1536 micro-ops. The following are some of the rules how the Decoded ICache is filled with micro-ops:
- ll micro-ops in a Way represent instructions which are statically contiguous in the code and have their EIPs within the same aligned 32-byte region.
- Up to three Ways may be dedicated to the same 32-byte aligned chunk, allowing a total of 18 micro-ops to be cached per 32-byte region of the original IA program.
- A multi micro-op instruction cannot be split across Ways.
- Up to two branches are allowed per Way.
- An instruction which turns on the MSROM consumes an entire Way.
- A non-conditional branch is the last micro-op in a Way.
- Micro-fused micro-ops (load+op and stores) are kept as one micro-op.
- A pair of macro-fused instructions is kept as one micro-op.
- Instructions with 64-bit immediate require two slots to hold the immediate.
Agner Fog juga menyebutkan bahwa hanya operasi mikro jalur tunggal yang dapat diunduh per siklus (tidak secara eksplisit dinyatakan dalam dokumentasi Intel, meskipun dapat dengan mudah diperiksa secara manual).µop cache --> IDQ
Dalam beberapa kasus, sangat nyaman menggunakan noppanjang 1 byte untuk mempelajari perilaku Front End . Pada saat yang sama, kita dapat yakin bahwa kita sedang menyelidiki Front End, dan bukan Resource Stall di Back End, dengan alasan apa pun. Faktanya adalah bahwa nop, serta instruksi lainnya, mereka diterjemahkan dalam Legacy Decode Pipeline, dicampur dalam µop cache dan dikirim ke IDQ. Selanjutnya nop, serta instruksi lainnya, membutuhkan back end. Perbedaan yang signifikan adalah bahwa dari sumber daya di Back End nophanya menggunakan Penyusun Ulang Pesanan dan tidak memerlukan slot di Stasiun Pemesanan (alias Penjadwal). Dengan demikian, segera setelah memasuki Reorder Buffer, ia nopsiap untuk pensiun, yang akan dilakukan sesuai dengan urutan dalam kode program.Untuk menguji throughput, deklarasikan suatu fungsivoid test_decoded_icache(size_t iteration_count);
dengan implementasi pada nasm:align 32
test_decoded_icache:
;nop', 0 23
dec rdi
ja test_decoded_icache
ret
jaItu tidak dipilih secara kebetulan. jadan decmenggunakan flag yang berbeda - jadibaca dari CFdan ZF, dectidak direkam dalam CF, sehingga Macro Fusion tidak berlaku. Ini dilakukan murni untuk kenyamanan penghitungan operasi mikro dalam satu siklus - setiap instruksi berhubungan dengan satu operasi mikro.Untuk pengukuran, kita membutuhkan acara perf berikut:1. uops_issued.any- Digunakan untuk menghitung operasi mikro yang diambil Renamer dari IDQ.Panduan Pemrograman Sistem Intel mendokumentasikan acara ini sebagai jumlah operasi mikro yang dilakukan Renamer ke dalam Reservation Station:Menghitung jumlah uops yang dikeluarkan Tabel Alokasi Sumber Daya (RAT) ke Stasiun Reservasi (RS).
Deskripsi ini tidak sepenuhnya berkorelasi dengan nilai-nilai yang dapat diperoleh dari percobaan. Secara khusus, mereka nopjatuh ke konter ini, meskipun itu hanya fakta bahwa mereka tidak diperlukan sama sekali di Stasiun Reservasi.2. uops_retired.retire_slots- jumlah total pensiunan mikro dengan memperhitungkan mikro / makro-fusi3. uops_retired.stall_cycles- jumlah kutu yang tidak ada satu mikro pensiunan4. resource_stalls.any- jumlah kutu dari konveyor menganggur karena tidak dapat diaksesnya sumber daya apa pun Back EndDalam Intel Software Optimization Manual / B .4.1 ada diagram konten yang mencirikan peristiwa yang dijelaskan di atas: 5.
5. idq.all_dsb_cycles_4_uops- jumlah siklus jam untuk 4 (atau lebih) instruksi yang dikirim dari cache µop.Fakta bahwa metrik ini memperhitungkan pengiriman lebih dari 4 operasi mikro per siklus tidak dijelaskan dalam dokumentasi Intel, tetapi metrik ini sangat setuju dengan eksperimen.6. idq.all_dsb_cycles_any_uops- jumlah tindakan yang sedikitnya satu operasi mikro disampaikan.7. idq.dsb_cycles- Jumlah total langkah-langkah di mana pengiriman berasal dari µop cache8. idq_uops_not_delivered.cycles_le_N_uop_deliv.core- Jumlah langkah-langkah dimana Renamer mengambil satu Natau kurang operasi mikro dan tidak ada downtime di sisi Back End , N- 1, 2, 3.Kami melakukan penelitian iteration_count = 1 << 31. Kami memulai analisis tentang apa yang terjadi di CPU dengan memeriksa jumlah operasi mikro dan, pertama, dengan mengukur bandwidth rata-rata pensiun, yaitu uops_retired.retire_slots/uops_retired.total_cycle: Apa yang segera menarik perhatian Anda adalah surutnya arus pensiun pada ukuran siklus 7 operasi mikro. Untuk memahami apa itu, mari kita perhatikan bagaimana tingkat pengiriman rata-rata cache μop -
Apa yang segera menarik perhatian Anda adalah surutnya arus pensiun pada ukuran siklus 7 operasi mikro. Untuk memahami apa itu, mari kita perhatikan bagaimana tingkat pengiriman rata-rata cache μop - idq.all_dsb_cycles_any_uops / idq.dsb_cycles: dan bagaimana menghubungkan jumlah total siklus jam dan siklus di mana cache μop dikirimkan dalam IDQ:
dan bagaimana menghubungkan jumlah total siklus jam dan siklus di mana cache μop dikirimkan dalam IDQ: Dengan demikian dapat dilihat bahwa siklus 6 operasi mikro yang kita miliki efektif Pemanfaatan bandwidth cache µop - 6 operasi mikro per siklus. Karena kenyataan bahwa Renamer tidak dapat menerima sebanyak µop cache yang dikirimkan, bagian dari siklus cache µop tidak mengirimkan apa pun, yang terlihat jelas dalam grafik sebelumnya.Dengan siklus 7 operasi mikro, kami mendapatkan penurunan tajam dalam throughput cache µop - 3,5 operasi mikro per siklus. Pada saat yang sama, seperti dapat dilihat dari grafik sebelumnya, cache µop terus beroperasi. Dengan demikian, dengan siklus 7 operasi mikro, kami mendapatkan pemanfaatan bandwidth µop cache yang tidak efisien. Faktanya adalah bahwa, seperti disebutkan sebelumnya, cache µop per siklus dapat mengirimkan operasi mikro hanya dari satu baris. Dalam kasus operasi mikro 7 - 6 pertama jatuh dalam satu baris, dan 7 sisanya - di yang lain. Dengan cara ini, kita mendapatkan 7 operasi mikro per 2 siklus, atau 3,5 operasi mikro per siklus.Sekarang mari kita lihat bagaimana Renamer mengambil operasi mikro dari IDQ. Untuk ini kita perlu
Dengan demikian dapat dilihat bahwa siklus 6 operasi mikro yang kita miliki efektif Pemanfaatan bandwidth cache µop - 6 operasi mikro per siklus. Karena kenyataan bahwa Renamer tidak dapat menerima sebanyak µop cache yang dikirimkan, bagian dari siklus cache µop tidak mengirimkan apa pun, yang terlihat jelas dalam grafik sebelumnya.Dengan siklus 7 operasi mikro, kami mendapatkan penurunan tajam dalam throughput cache µop - 3,5 operasi mikro per siklus. Pada saat yang sama, seperti dapat dilihat dari grafik sebelumnya, cache µop terus beroperasi. Dengan demikian, dengan siklus 7 operasi mikro, kami mendapatkan pemanfaatan bandwidth µop cache yang tidak efisien. Faktanya adalah bahwa, seperti disebutkan sebelumnya, cache µop per siklus dapat mengirimkan operasi mikro hanya dari satu baris. Dalam kasus operasi mikro 7 - 6 pertama jatuh dalam satu baris, dan 7 sisanya - di yang lain. Dengan cara ini, kita mendapatkan 7 operasi mikro per 2 siklus, atau 3,5 operasi mikro per siklus.Sekarang mari kita lihat bagaimana Renamer mengambil operasi mikro dari IDQ. Untuk ini kita perlu idq_uops_not_delivered.coredan idq_uops_not_delivered.cycles_le_N_uop_deliv.core: Anda mungkin memperhatikan bahwa dengan 7 operasi mikro, hanya 3 operasi mikro pada saat yang sama mengambil setengah siklus Renamer. Dari sini kita mendapatkan hasil pensiun rata-rata 3,5 operasi mikro per siklus.Hal menarik lainnya yang terkait dengan contoh ini dapat dilihat jika kita mempertimbangkan throughput pensiun yang efektif . Itu tidak mempertimbangkan
Anda mungkin memperhatikan bahwa dengan 7 operasi mikro, hanya 3 operasi mikro pada saat yang sama mengambil setengah siklus Renamer. Dari sini kita mendapatkan hasil pensiun rata-rata 3,5 operasi mikro per siklus.Hal menarik lainnya yang terkait dengan contoh ini dapat dilihat jika kita mempertimbangkan throughput pensiun yang efektif . Itu tidak mempertimbangkan uops_retired.stall_cycles: Dapat dicatat bahwa dengan 7 operasi mikro, setiap 7 langkah pensiun dari 4 operasi mikro dilakukan, dan setiap langkah ke 8 menganggur tanpa operasi mikro yang pensiun (kandang pensiun). Setelah melakukan serangkaian percobaan, adalah mungkin untuk menemukan bahwa perilaku seperti itu selalu diamati selama 7 operasi mikro, terlepas dari tata letak mereka 1-6, 6-1, 2-5, 5-2, 3-4, 4-3. Saya tidak tahu mengapa ini persis seperti itu, dan tidak, misalnya, pensiun dari 3 operasi mikro dilakukan dalam satu siklus clock, dan 4 di berikutnya. Agner Fog menyebutkan bahwa transisi cabang hanya dapat menggunakan bagian dari slot stasiun pensiun. Mungkin pembatasan ini adalah alasan perilaku pensiun ini.
Dapat dicatat bahwa dengan 7 operasi mikro, setiap 7 langkah pensiun dari 4 operasi mikro dilakukan, dan setiap langkah ke 8 menganggur tanpa operasi mikro yang pensiun (kandang pensiun). Setelah melakukan serangkaian percobaan, adalah mungkin untuk menemukan bahwa perilaku seperti itu selalu diamati selama 7 operasi mikro, terlepas dari tata letak mereka 1-6, 6-1, 2-5, 5-2, 3-4, 4-3. Saya tidak tahu mengapa ini persis seperti itu, dan tidak, misalnya, pensiun dari 3 operasi mikro dilakukan dalam satu siklus clock, dan 4 di berikutnya. Agner Fog menyebutkan bahwa transisi cabang hanya dapat menggunakan bagian dari slot stasiun pensiun. Mungkin pembatasan ini adalah alasan perilaku pensiun ini.Contoh
Untuk memahami apakah ini semua memiliki efek dalam praktik, pertimbangkan contoh berikut yang sedikit lebih praktis daripada dengan nops:Dua array diberikan unsigned. Adalah perlu untuk mengakumulasikan jumlah alat aritmatika untuk setiap indeks dan menulisnya ke array ketiga.Contoh implementasi mungkin terlihat seperti ini:
static unsigned arr1[] = { ... };
static unsigned arr2[] = { ... };
static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
__asm__ __volatile__("" ::: "memory");
}
int main(void){
unsigned out[sizeof arr1 / sizeof(unsigned)];
for(size_t i = 0; i < 4096 * 4096; i++){
arithmetic_mean(arr1, arr2, out, sizeof arr1 / sizeof(unsigned));
}
}
Kompilasi dengan flag gcc-Werror
-Wextra
-Wall
-pedantic
-Wno-stack-protector
-g3
-O3
-Wno-unused-result
-Wno-unused-parameter
Cukup jelas bahwa fungsi arithmetic_meantidak akan ada dalam kode dan akan dimasukkan langsung ke main:(gdb) disas main
Dump of assembler code for function main:
#...
0x00000000000005dc <+60>: nop DWORD PTR [rax+0x0]
0x00000000000005e0 <+64>: mov edx,DWORD PTR [rdi+rax*4]
0x00000000000005e3 <+67>: add edx,DWORD PTR [r8+rax*4]
0x00000000000005e7 <+71>: shr edx,1
0x00000000000005e9 <+73>: add ecx,edx
0x00000000000005eb <+75>: mov DWORD PTR [rsi+rax*4],ecx
0x00000000000005ee <+78>: add rax,0x1
0x00000000000005f2 <+82>: cmp rax,0x80
0x00000000000005f8 <+88>: jne 0x5e0 <main+64>
0x00000000000005fa <+90>: sub r9,0x1
0x00000000000005fe <+94>: jne 0x5d8 <main+56>
#...
Perhatikan bahwa kompiler menyelaraskan kode loop ke 32 byte ( nop DWORD PTR [rax+0x0]), yang persis apa yang kita butuhkan. Setelah memastikan bahwa tidak ada resource_stalls.anyBack End (semua pengukuran dilakukan dengan mempertimbangkan cache L1d yang dipanaskan), kita dapat mulai mempertimbangkan penghitung yang terkait dengan pengiriman ke IDQ: Performance counter stats for './test_decoded_icache':
2 273 343 251 idq.all_dsb_cycles_4_uops (15,94%)
4 458 322 025 idq.all_dsb_cycles_any_uops (16,26%)
15 473 065 238 idq.dsb_uops (16,59%)
4 358 690 532 idq.dsb_cycles (16,91%)
2 528 373 243 idq_uops_not_delivered.core (16,93%)
73 728 040 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,93%)
107 262 304 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,93%)
108 454 043 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,65%)
2 248 557 762 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,32%)
2 385 493 805 idq_uops_not_delivered.cycles_fe_was_ok (16,00%)
15 147 004 678 uops_retired.retire_slots
4 724 790 623 uops_retired.total_cycles
1,228684264 seconds time elapsed
Perhatikan bahwa badwidth pensiun dalam kasus ini = 15147004678/4724790623 = 3.20585733562, dan juga hanya 3 operasi mikro yang mengambil setengah jam dari Renamer.Sekarang tambahkan promosi loop manual ke implementasi:static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
if(sz & 2){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
__asm__ __volatile__("" ::: "memory");
}
Penghitung perf yang dihasilkan terlihat seperti:Performance counter stats for './test_decoded_icache':
2 152 818 549 idq.all_dsb_cycles_4_uops (14,79%)
3 207 203 856 idq.all_dsb_cycles_any_uops (15,25%)
12 855 932 240 idq.dsb_uops (15,70%)
3 184 814 613 idq.dsb_cycles (16,15%)
24 946 367 idq_uops_not_delivered.core (16,24%)
3 011 119 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,24%)
5 239 222 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,24%)
7 373 563 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,24%)
7 837 764 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,24%)
3 418 529 799 idq_uops_not_delivered.cycles_fe_was_ok (16,24%)
3 444 833 440 uops_retired.total_cycles (18,18%)
13 037 919 196 uops_retired.retire_slots (18,17%)
0,871040207 seconds time elapsed
Dalam hal ini, kami memiliki bandwidth pensiunan = 13037919196/3444833440 = 3.78477491672, serta pemanfaatan bandwidth Renamer yang efisien.Dengan demikian, kami tidak hanya menghilangkan satu operasi percabangan dan satu peningkatan dalam satu lingkaran, tetapi juga meningkatkan bandwidth pensiun menggunakan pemanfaatan yang efisien dari throughput cache operasi mikro, yang memberikan peningkatan total kinerja 28%.Perhatikan bahwa hanya pengurangan dalam satu cabang dan operasi penambahan yang memberikan peningkatan kinerja rata-rata 9%.Komentar kecil
Pada CPU yang digunakan untuk melakukan eksperimen ini, LSD dimatikan. Tampaknya LSD dapat menangani situasi seperti itu. Untuk CPU dengan LSD diaktifkan, kasus-kasus seperti itu perlu diselidiki secara terpisah.