Baru-baru ini saya berbicara tentang cara menggunakan resep standar untuk meningkatkan kinerja kueri SQL "baca" dari database PostgreSQL. Hari ini kita akan berbicara tentang bagaimana Anda dapat membuat rekaman dalam database lebih efisien tanpa menggunakan "tikungan" dalam konfigurasi - hanya dengan mengatur aliran data dengan benar.# 1. Partisi
Artikel tentang bagaimana dan mengapa perlu mengatur penerapan partisi “secara teori” telah dilakukan, di sini kita akan fokus pada praktik menggunakan beberapa pendekatan dalam kerangka layanan pemantauan kami untuk ratusan server PostgreSQL ."Kasus masa lalu ..."
Pada awalnya, seperti MVP lainnya, proyek kami dimulai di bawah beban yang cukup kecil - pemantauan dilakukan hanya untuk sepuluh server paling kritis, semua tabel relatif kompak ... Tetapi waktu berlalu, semakin banyak host yang dipantau, dan sekali lagi mencoba melakukan sesuatu dengan salah satu tabel dengan ukuran 1,5TB , kami menyadari bahwa meskipun mungkin untuk terus seperti ini, itu sangat merepotkan.Waktu hampir epik, varian 9.g PostgreSQL yang berbeda relevan, sehingga semua partisi harus dilakukan "secara manual" - melalui pewarisan tabel dan pemicu perutean dinamis EXECUTE.Solusi yang dihasilkan ternyata cukup universal untuk dapat menerjemahkannya ke semua tabel:PG10:
Tetapi partisi melalui pewarisan secara historis tidak cocok untuk bekerja dengan aliran tulis aktif atau sejumlah besar bagian anak. Misalnya, Anda mungkin ingat bahwa algoritme untuk memilih bagian yang diinginkan memiliki kompleksitas kuadrat , yang berfungsi dengan 100 bagian, Anda memahami caranya ...Di PG10, situasi ini sangat dioptimalkan dengan menerapkan dukungan untuk partisi asli . Oleh karena itu, kami segera mencoba menerapkannya segera setelah migrasi penyimpanan, tetapi ...Ternyata setelah menggali manual, tabel yang dipartisi secara asli di versi ini:- tidak mendukung deskripsi indeks
- tidak mendukung pemicu di atasnya
- tidak bisa menjadi dirinya sendiri "keturunan"
- tidak mendukung
INSERT ... ON CONFLICT - tidak dapat menelurkan bagian secara otomatis
Dengan susah payah menyapu dahi kami, kami menyadari bahwa kami tidak dapat melakukannya tanpa memodifikasi aplikasi, dan menunda penelitian lebih lanjut selama enam bulan.PG10: Peluang Kedua
Jadi, kami mulai memecahkan masalah pada gilirannya:- Karena pemicu
ON CONFLICTternyata diperlukan di beberapa tempat, kami membuat tabel proxy perantara untuk mengatasinya . - Kami menyingkirkan "perutean" di pemicu - yaitu, dari
EXECUTE. - Mereka mengeluarkan tabel templat terpisah dengan semua indeks sehingga mereka bahkan tidak ada di tabel proxy.
Akhirnya, setelah semua ini, tabel utama sudah dipartisi secara native. Membuat bagian baru tetap pada hati nurani aplikasi.Kamus "Menggergaji"
Seperti dalam sistem analitik apa pun, kami juga memiliki "fakta" dan "potongan" (kamus). Dalam kasus kami, dalam kapasitas ini, misalnya, badan "templat" dari jenis kueri lambat yang sama atau teks kueri itu sendiri."Fakta" kami dipartisi berdasarkan hari untuk waktu yang lama, jadi kami dengan tenang menghapus bagian yang sudah usang, dan itu tidak mengganggu kami (log!). Tetapi dengan kamus masalahnyaternyata ... Bukan untuk mengatakan bahwa ada banyak dari mereka, tetapi sekitar 100TB "fakta" ternyata menjadi kamus untuk 2.5TB . Anda tidak dapat dengan mudah menghapus apa pun dari tabel seperti itu, Anda tidak akan memerasnya dalam waktu yang memadai, dan menulis kepadanya secara bertahap menjadi lebih lambat.Sepertinya kamus ... di dalamnya setiap entri harus disajikan tepat sekali ... dan itu benar, tapi! .. Tidak ada yang mengganggu kita untuk memiliki kamus terpisah untuk setiap hari ! Ya, ini membawa redundansi tertentu, tetapi memungkinkan Anda untuk:- tulis / baca lebih cepat karena ukuran bagian yang lebih kecil
- gunakan lebih sedikit memori dengan bekerja dengan indeks yang lebih ringkas
- menyimpan lebih sedikit data karena kemampuan untuk menghapus dengan cepat usang
Sebagai hasil dari keseluruhan tindakan yang rumit , beban CPU menurun ~ 30%, dan oleh disk - hingga ~ 50% :Pada saat yang sama, kami terus menulis hal yang persis sama ke basis data, hanya dengan beban yang lebih sedikit.# 2 Evolusi basis data dan refactoring
Jadi, kami menetapkan fakta bahwa untuk setiap hari kami memiliki bagian kami sendiri dengan data. Sebenarnya, ini CHECK (dt = '2018-10-12'::date)adalah kunci partisi dan kondisi untuk catatan jatuh ke bagian tertentu.Karena semua laporan dalam layanan kami dibuat berdasarkan tanggal tertentu, maka indeks dari "waktu yang tidak dipartisi" adalah semua jenisnya (Server, Tanggal , Templat Paket) , (Server, Tanggal , Paket Node) , ( Tanggal , Kelas Kesalahan, Server) , ...Tapi sekarang setiap bagian memiliki contoh masing-masing indeks tersebut ... Dan dalam setiap bagian tanggalnya konstan ... Ternyata sekarang kita berada di setiap indeks tersebutkami dengan sepele memasukkan konstanta sebagai salah satu bidang, yang menjadikan volume dan waktu pencariannya lebih banyak, tetapi tidak memberikan hasil apa pun. Dirinya meninggalkan menyapu, oops ...Arah pengoptimalan sudah jelas - cukup hapus bidang tanggal dari semua indeks pada tabel yang dipartisi. Dengan volume kami, keuntungannya sekitar 1TB / minggu !Dan sekarang mari kita perhatikan bahwa terabyte ini masih harus ditulis entah bagaimana. Artinya, kita juga harus memuat lebih sedikit disk sekarang ! Dalam gambar ini, efek yang diperoleh dari pembersihan, yang kami curahkan selama seminggu, terlihat jelas: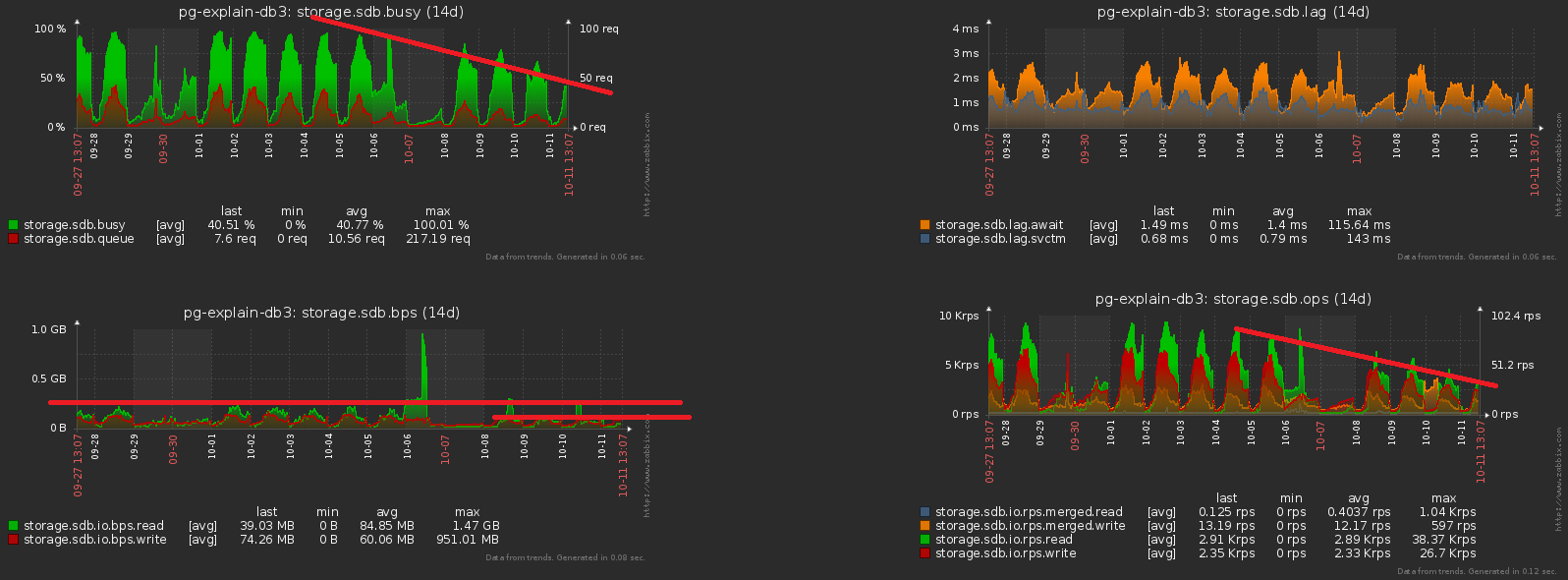
# 3 “Corengkan” beban puncak
Salah satu masalah besar dari sistem yang dimuat adalah sinkronisasi berlebihan dari beberapa operasi yang tidak memerlukannya. Terkadang "karena mereka tidak memperhatikan", kadang-kadang "lebih mudah", tetapi cepat atau lambat Anda harus menyingkirkannya.Kami membawa gambar sebelumnya lebih dekat - dan kami melihat bahwa disk "bergetar" dengan beban dengan amplitudo ganda antara sampel tetangga, yang jelas tidak boleh "secara statistik" dengan begitu banyak operasi: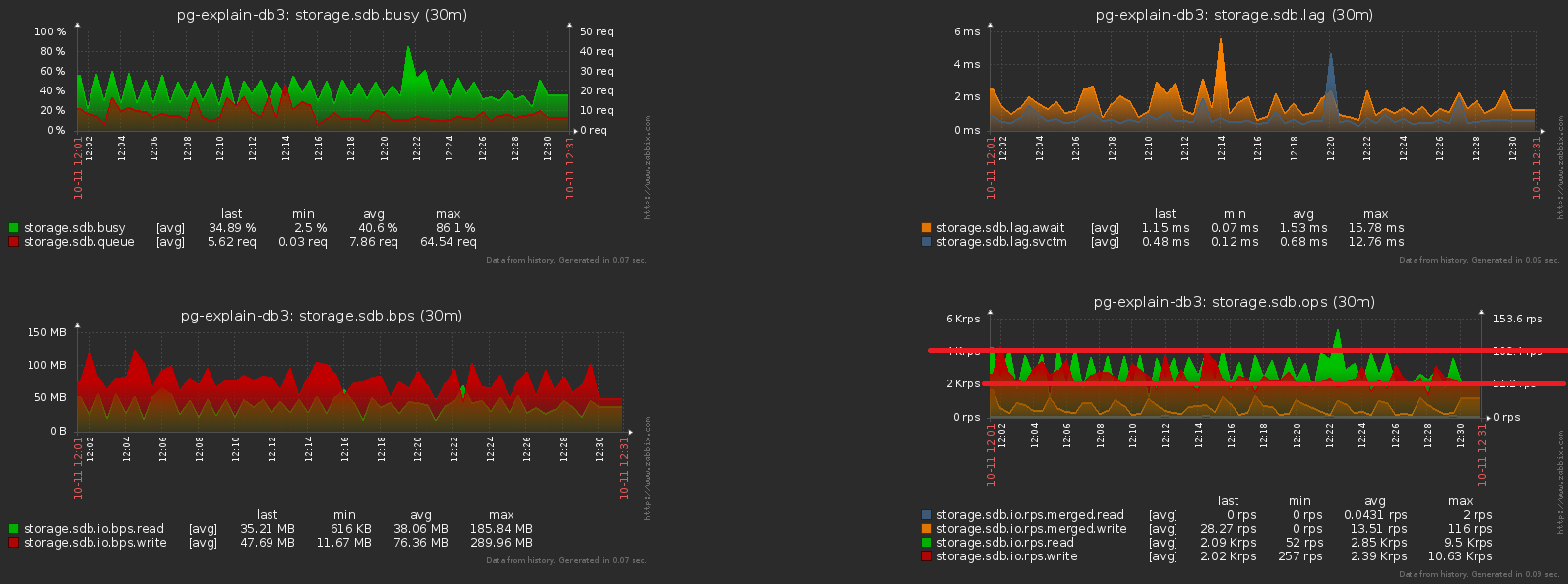 Untuk mencapai ini cukup sederhana. Hampir 1000 server telah diatur untuk pemantauan , masing-masing diproses oleh aliran logis yang terpisah, dan setiap aliran membuang informasi yang terakumulasi untuk dikirim ke database dengan frekuensi tertentu, seperti ini:
Untuk mencapai ini cukup sederhana. Hampir 1000 server telah diatur untuk pemantauan , masing-masing diproses oleh aliran logis yang terpisah, dan setiap aliran membuang informasi yang terakumulasi untuk dikirim ke database dengan frekuensi tertentu, seperti ini:setInterval(sendToDB, interval)
Masalahnya di sini justru terletak pada kenyataan bahwa semua utas dimulai pada waktu yang sama , sehingga waktu pengiriman untuk mereka hampir selalu bertepatan "to the point". Ups No. 2 ...Untungnya, ini diperbaiki dengan cukup mudah dengan menambahkan rentang waktu "acak" :setInterval(sendToDB, interval * (1 + 0.1 * (Math.random() - 0.5)))
# 4 Caching, kebutuhan itu bisa
Masalah highload tradisional ketiga adalah kurangnya cache di mana itu bisa terjadi.Sebagai contoh, kami memungkinkan untuk menganalisis pemecahan node rencana (semua ini Seq Scan on users), tetapi segera berpikir bahwa mereka, pada dasarnya, sama - lupa.Tidak, tentu saja, tidak ada yang ditulis ke database berulang kali, ini memotong pelatuknya INSERT ... ON CONFLICT DO NOTHING. Tetapi data tidak mencapai basis, dan Anda harus melakukan bacaan tambahan untuk memeriksa konflik . Ups No. 3 ...Perbedaan dalam jumlah catatan yang dikirim ke database sebelum / setelah mengaktifkan caching sudah jelas: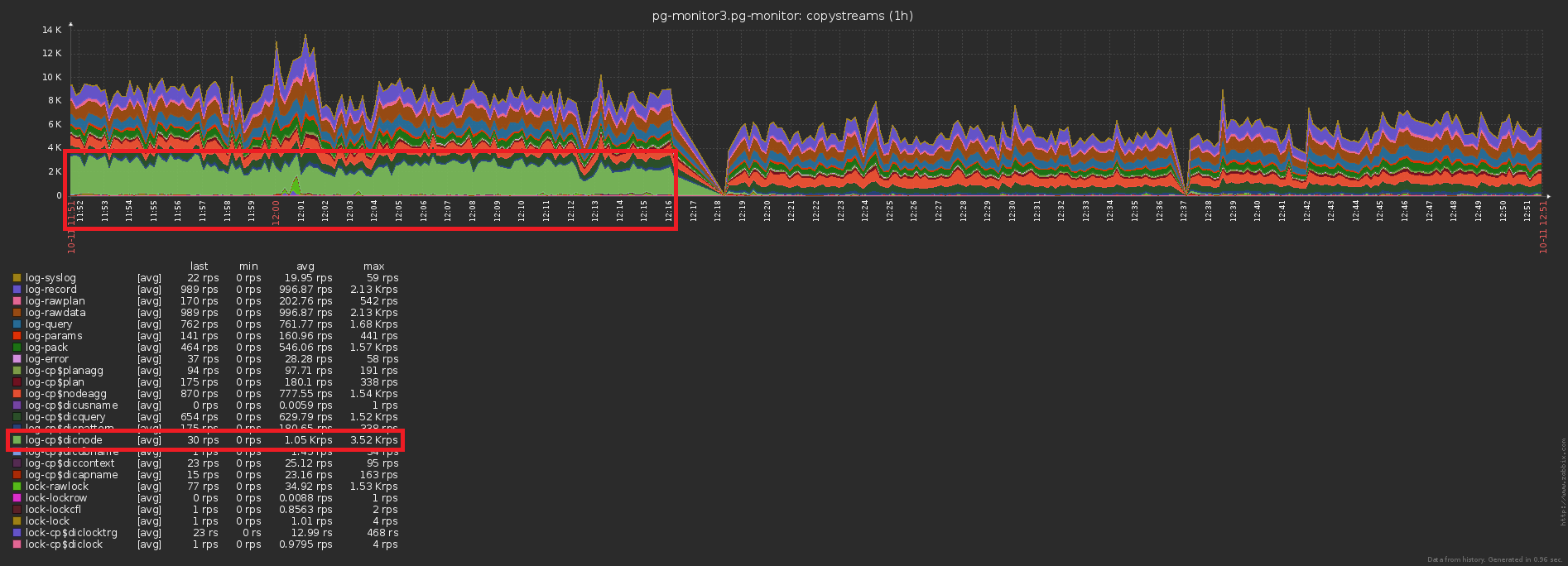 Dan ini adalah penurunan yang bersamaan dalam beban penyimpanan:
Dan ini adalah penurunan yang bersamaan dalam beban penyimpanan:
Total
Terabyte per hari hanya terdengar menakutkan. Jika Anda melakukan semuanya dengan benar, maka ini hanya 2 ^ 40 byte / 86400 detik = ~ 12,5MB / s , yang bahkan dimiliki oleh sekrup IDE desktop. :)Tapi serius, bahkan dengan sepuluh kali lipat "miring" dari beban siang hari, Anda dapat dengan mudah memenuhi kemungkinan SSD modern.