Sangat sering, selama 15 tahun pengalaman saya sebagai pengembang perangkat lunak dan pemimpin tim, saya menemukan hal yang sama. Pemrograman berubah menjadi agama - jarang ada orang yang mencoba memperkenalkan teknologi berdasarkan pilihan yang masuk akal, dengan masuk akal, dengan mempertimbangkan batasan akun, portabilitas, menilai tingkat keterikatan dengan vendor, harga sebenarnya, prospek teknologi dan kebebasan lisensi. Pengembang pergi ke konferensi atau membaca posting - mulai hype, dan direktur dan manajer TI mereka diberi makan tidak hanya dengan kisah masa depan yang lincah cerah di berbagai acara, berbagai visioner, penjualan dan konsultan. Dan ternyata teknologinya ada di proyek, tidak memperhitungkan kenyamanan pengembangan dan implementasi, persyaratan non-fungsional dari proyek, tetapi karena hype dan google menggunakan sendiri,amazon merekomendasikan (meskipun lowongan mereka mengatakan bahwa mereka sendiri tidak sering menggunakannya) atau keputusan tertinggi telah dibuat oleh manajemen perusahaan untuk menerapkan "ini."
Apa yang mempengaruhi pemilihan basis data?
Dari sudut pandang saya, ketika memilih database, saya harus menyelesaikan setidaknya trade-off berikut:- pemrosesan transaksi real-time atau pemrosesan analitik online
- terukur secara vertikal atau horizontal
- dalam kasus basis terdistribusi - konsistensi / ketersediaan / ketahanan pemisahan data (teorema CAP)
- skema data tertentu dan batasan dalam database atau penyimpanan yang tidak memerlukan skema data
- model data - nilai kunci, hierarkis, grafik, dokumen, atau relasional
- pemrosesan logika sedekat mungkin dengan data atau semua pemrosesan dalam aplikasi
- bekerja terutama di RAM atau dengan subsistem disk
- solusi universal atau khusus
- kami menggunakan keahlian yang ada pada database yang tidak terlalu cocok untuk persyaratan proyek atau kami mengembangkan yang baru dalam pelatihan yang sesuai tetapi tidak dikenal, "darah dan keringat" (hal yang sama tidak hanya berlaku untuk pengembangan, tetapi juga untuk operasi)
- built-in atau dalam proses / jaringan lain
- hipster atau mundur
Seringkali kita mendapatkan "hadiah" untuk solusi yang diterapkan:- Bahasa permintaan "Alien"
- satu-satunya API asli untuk bekerja dengan database, yang akan mempersulit transisi ke database lain (waktu, upaya tim dan anggaran proyek dihabiskan)
- tidak tersedianya driver untuk platform / bahasa / sistem operasi lain
- kurangnya kode sumber, deskripsi format data pada disk (atau larangan lisensi reverse engineering, terutama Oracle dengan buggy Coherence)
- pertumbuhan biaya lisensi dari tahun ke tahun
- memiliki ekosistem dan kesulitan menemukan spesialis
- , ,
Sistem penskalaan horizontal cukup rumit dan membutuhkan keahlian tim. Pengembang berpengalaman cukup mahal di pasar, aplikasi terdistribusi lebih sulit untuk dikembangkan, di-debug dan diuji. Oleh karena itu, jika memungkinkan untuk mengubah server ke server yang lebih kuat dan jumlah data yang diizinkan sistem, mereka sering melakukannya. Sekarang server dapat memiliki RAM terabyte dan ratusan inti prosesor. Jadi, tidak pernah sebelumnya, menjadi penting untuk menggunakan semua sumber daya server seefisien mungkin. Biaya lisensi basis data juga penting, dan jika mereka dijual oleh inti prosesor, anggaran operasi, bahkan dengan penskalaan vertikal, dapat menelan biaya sebanyak program ruang superpower. Oleh karena itu, penting untuk mengingat hal ini agar tidak dapat meningkatkan skala kinerja database karena lisensi.Jelas bahwa dengan bantuan pemasaran mereka akan mencoba meyakinkan Anda bahwa hanya solusi dari perusahaan tertentu yang akan menyelesaikan semua masalah Anda (tetapi mereka diam tentang berapa banyak yang baru akan muncul). Tidak ada satu pun basis data yang ideal yang cocok untuk semua orang dan cocok untuk semuanya.Jadi di masa mendatang, kami masih akan mendukung beberapa basis data yang berbeda untuk memproses data yang sama untuk berbagai jenis kueri dalam sistem yang berbeda. Tidak ada solusi untuk Fabric Data tanpa caching data, Data Lake belum dapat dibandingkan dengan database dengan arsitektur paralel-massa dalam hal kinerja dan optimalisasi kueri. Data transaksional akan tetap disimpan di PostgreSQL, Oracle, MS Sql Server, pertanyaan analitik dalam Citus, Greenplum, Snowflake, Redshift, Vertica, Impala, Teradata, dan rawa data mentah dalam HDFS / S3 / ADLS (Azure) akan dikelola oleh Dremio , Redshift Spectrum, Apache Spark, Presto.Tetapi solusi yang tercantum di atas tidak cocok untuk menganalisis data deret waktu dengan waktu respons rendah. Menurut popularitasnya dalam bekerja dengan data deret waktu, sekarang menjadi favorit InfluxDB. Dalam ceruk basis data dalam-memori, kdb + dan memSQL menjaga tempatnya.QuestDB
Apa yang bisa menentang semua solusi QuestDB open source ini dengan lisensi Apache?- Upaya untuk memanfaatkan perangkat keras secara maksimal untuk melakukan kueri analitik - vektorisasi fungsi agregasi, bekerja dengan data melalui file yang dipetakan memori
- SQL sebagai bahasa kueri DML dan operasi DDL untuk mengelola struktur basis data
- dukungan untuk tabel bergabung khusus untuk time series DB
- dukungan untuk fungsi jendela dan agregasi dalam SQL
- kemampuan untuk menanamkan basis data dalam aplikasi pada JVM
- JVM, ServiceLoader
- Influx DB line protocol (ILP) UDP Telegraf. «What makes QuestDB faster than InfluxDB»
- PostgreSql 11 PostgreSQL: JDBC, ODBC psql
- web - REST endpoint , SQL json
- ,
- zero-GC API, .
- ( )
- 64 Windows, Linux, OSX, ARM Linux FreeBSD
- , open source,
Ketika database ini dapat berguna bagi Anda - jika Anda sedang mengembangkan sistem keuangan pada JVM dengan latensi rendah dan Anda memerlukan solusi untuk analisis data dalam RAM. Sebagai pengganti kdb + karena biaya lisensi. Jika Anda mengumpulkan metrik sesuai dengan protokol Influx / Telegraf, tetapi kinerja dan kegunaan bekerja dengan InfluxDB tidak memuaskan. Jika proyek Anda berjalan di JVM dan Anda memerlukan database bawaan untuk menyimpan metrik atau data aplikasi yang hanya ditambahkan dan tidak diperbarui.Rilis baru 4.2.0 dengan dukungan untuk instruksi SIMD menyebabkan gelombang komentar pada Reddit . Bagi penggemar untuk berpartisipasi dalam kompetisi pengetahuan tentang perangkat keras modern dan pemrogramannya yang efektif, saya sarankan berbicara dengan penulis database (bluestreak01) di komentar!Operasi SIMD
Tim proyek melakukan tes pada data sintetik dan membandingkan QuestDB 4.2.0 dengan kdb 4.0 untuk mengumpulkan satu miliar nilai, memanfaatkan instruksi SIMD dari prosesor.Pada platform Intel 8850H: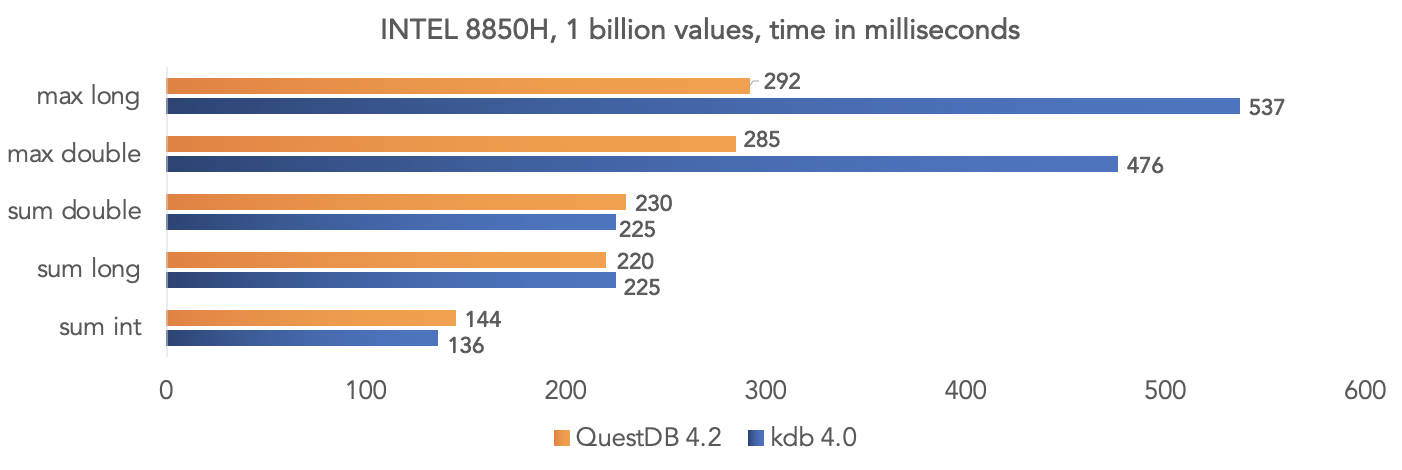 Pada platform AMD Ryzen 3900X:
Pada platform AMD Ryzen 3900X: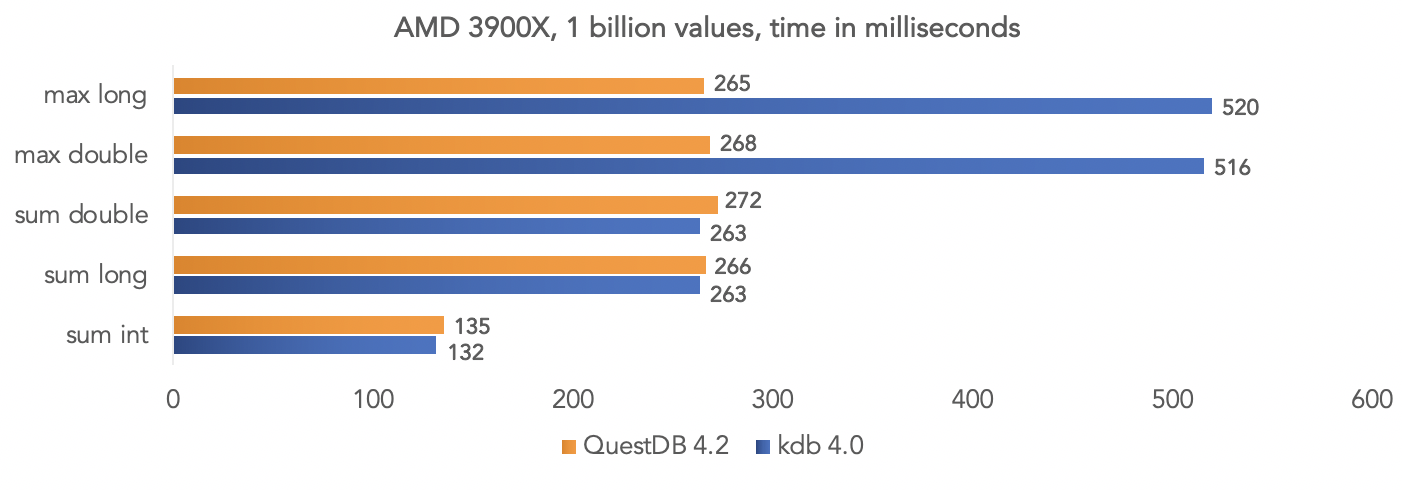 Jelas bahwa semua ini adalah tes dalam "ruang hampa", tetapi Anda dapat membandingkan data Anda jika proyek Anda menggunakan kdb dan membagikan hasilnya dengan komunitas.
Jelas bahwa semua ini adalah tes dalam "ruang hampa", tetapi Anda dapat membandingkan data Anda jika proyek Anda menggunakan kdb dan membagikan hasilnya dengan komunitas.Menjalankan gambar basis data buruh pelabuhan
Basis data diterbitkan di dockerhub dengan setiap rilis. Rincian lebih lanjut dijelaskan dalam dokumentasi proyek .Dapatkan gambar QuestDB:docker pull questdb/questdb
Kami meluncurkan:docker run --rm -it -p 9000:9000 -p 8812:8812 questdb/questdb
Setelah itu, Anda dapat terhubung menggunakan protokol PostgreSQL ke port 8812, konsol web tersedia di port 9000.Akses Jdbc
Bergantung pada proyek kami, kami menambahkan driver jdbc PostrgreSQL org.postgresql: postgresql: 42.2.12 , untuk tes ini saya menggunakan modul QuestDB untuk testcontainers . Tes tersedia di github bersama dengan skrip build:import org.junit.jupiter.api.Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import static org.assertj.core.api.Assertions.*;
public class QuestDbDriverTest {
@Test
void containerIsUpTestByJdbcInvocation() throws Exception {
try (Connection connection = DriverManager.getConnection("jdbc:tc:questdb:///?user=admin&password=quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
Menjalankan buruh pelabuhan mengarah ke overhead tambahan, dan ini dapat dihindari dengan hanya menerapkan org.questdb: core: jar: 4.2.0 sebagai ketergantungan pada proyek dan menjalankan io.questdb.ServerMain:import io.questdb.ServerMain;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.Statement;
public class QuestDbJdbcTest {
@Test
void embeddedServerStartTest(@TempDir Path tempDir) throws Exception{
ServerMain.main(new String[]{"-d", tempDir.toString()});
try (DriverManager.getConnection("jdbc:postgresql://localhost:8812/", "admin", "quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
Menyematkan aplikasi java
Tapi ini adalah cara tercepat untuk bekerja dengan database menggunakan API java inprocess:import io.questdb.cairo.CairoEngine;
import io.questdb.cairo.DefaultCairoConfiguration;
import io.questdb.griffin.CompiledQuery;
import io.questdb.griffin.SqlCompiler;
import io.questdb.griffin.SqlExecutionContextImpl;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
public class TruncateExecuteTest {
@Test
void truncate(@TempDir Path tempDir) throws Exception{
SqlExecutionContextImpl executionContext = new SqlExecutionContextImpl();
DefaultCairoConfiguration configuration = new DefaultCairoConfiguration(tempDir.toAbsolutePath().toString());
try (CairoEngine engine = new CairoEngine(configuration)) {
try (SqlCompiler compiler = new SqlCompiler(engine)) {
CompiledQuery createTable = compiler.compile("create table tr_table(id long,name string)", executionContext);
compiler.compile("truncate table tr_table", executionContext);
}
}
}
}
Konsol web
Proyek ini mencakup konsol web untuk menanyakan QuestDB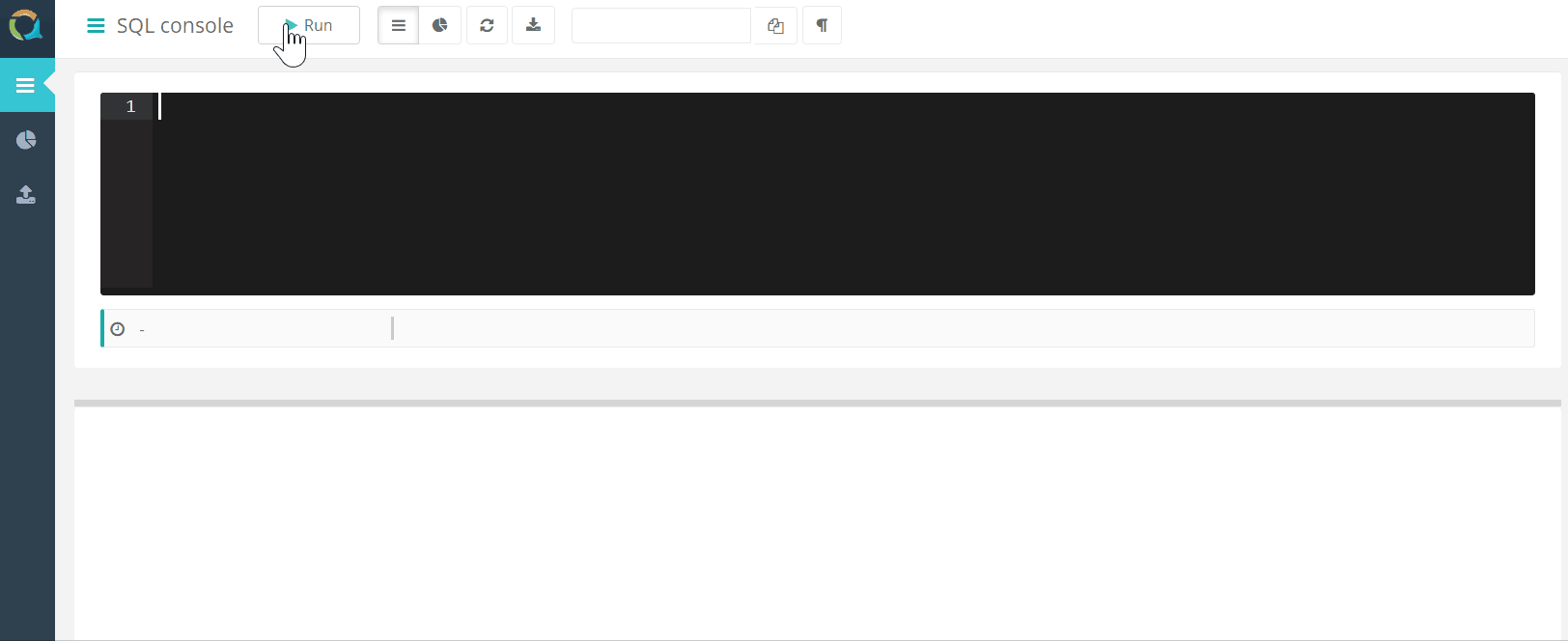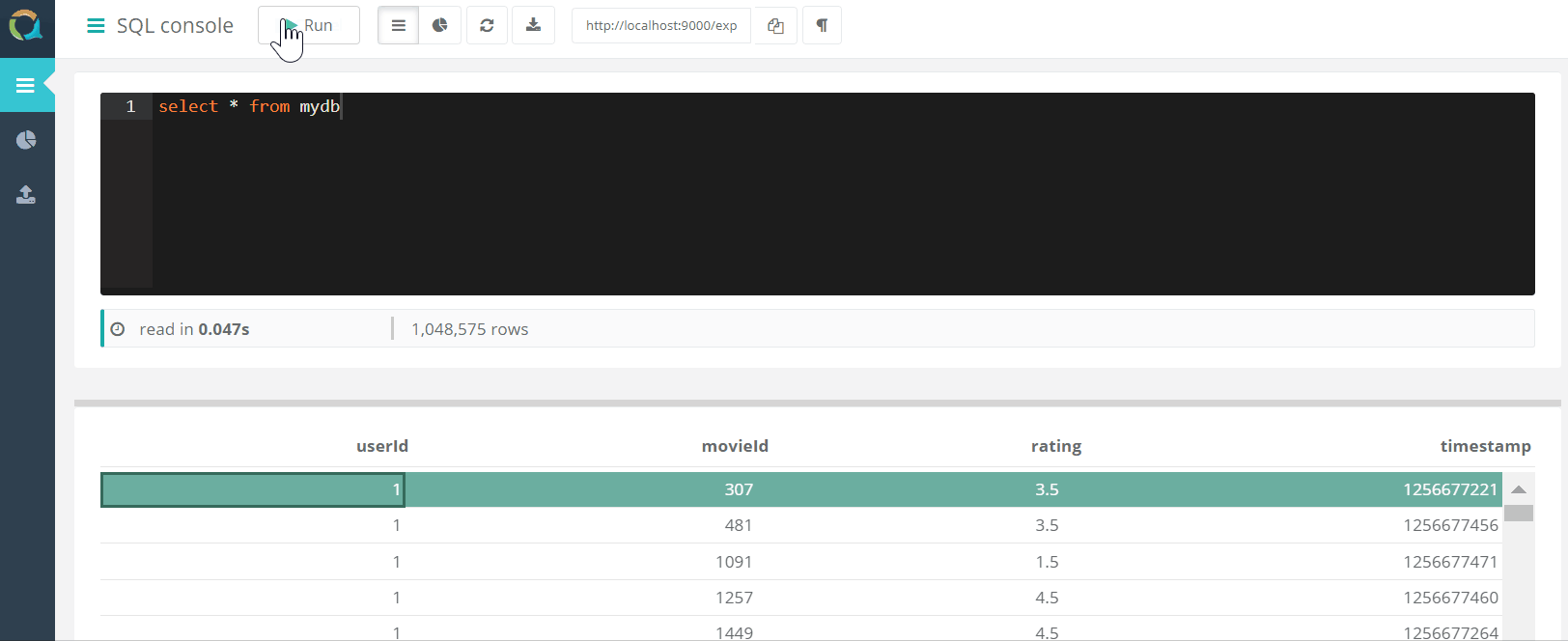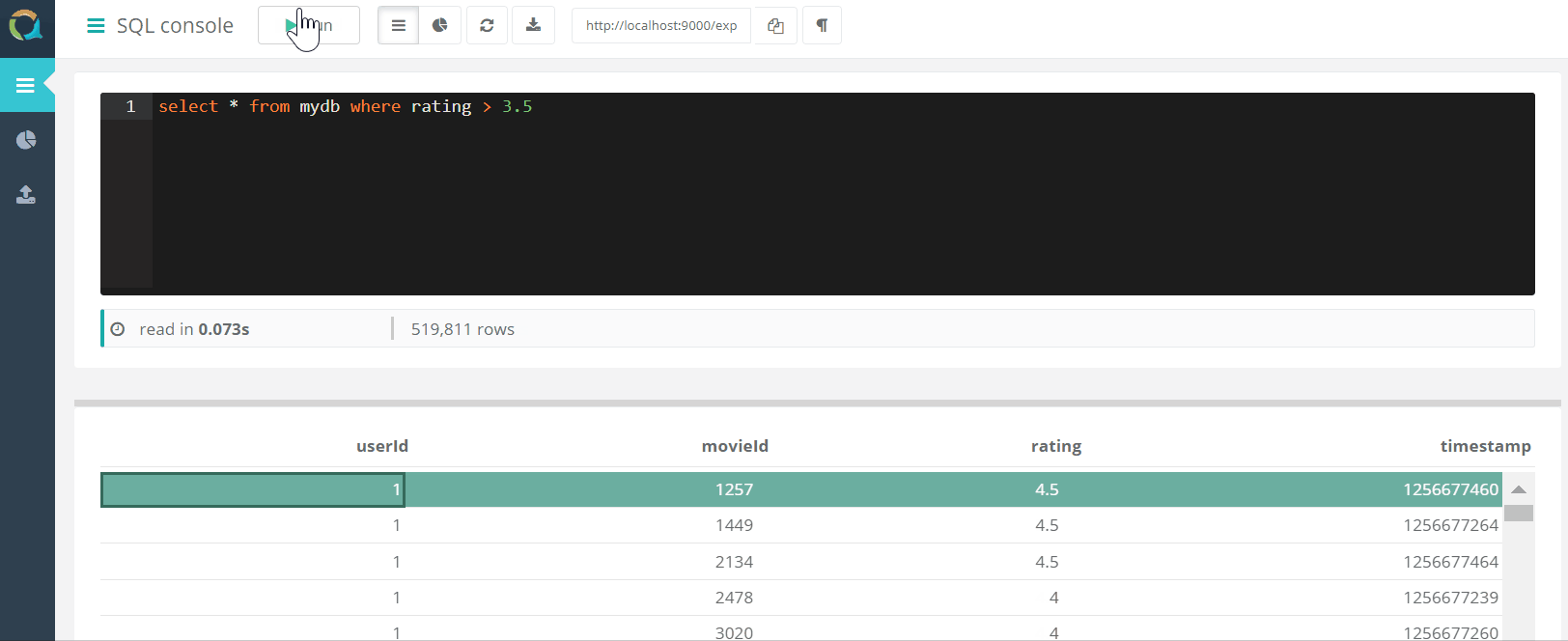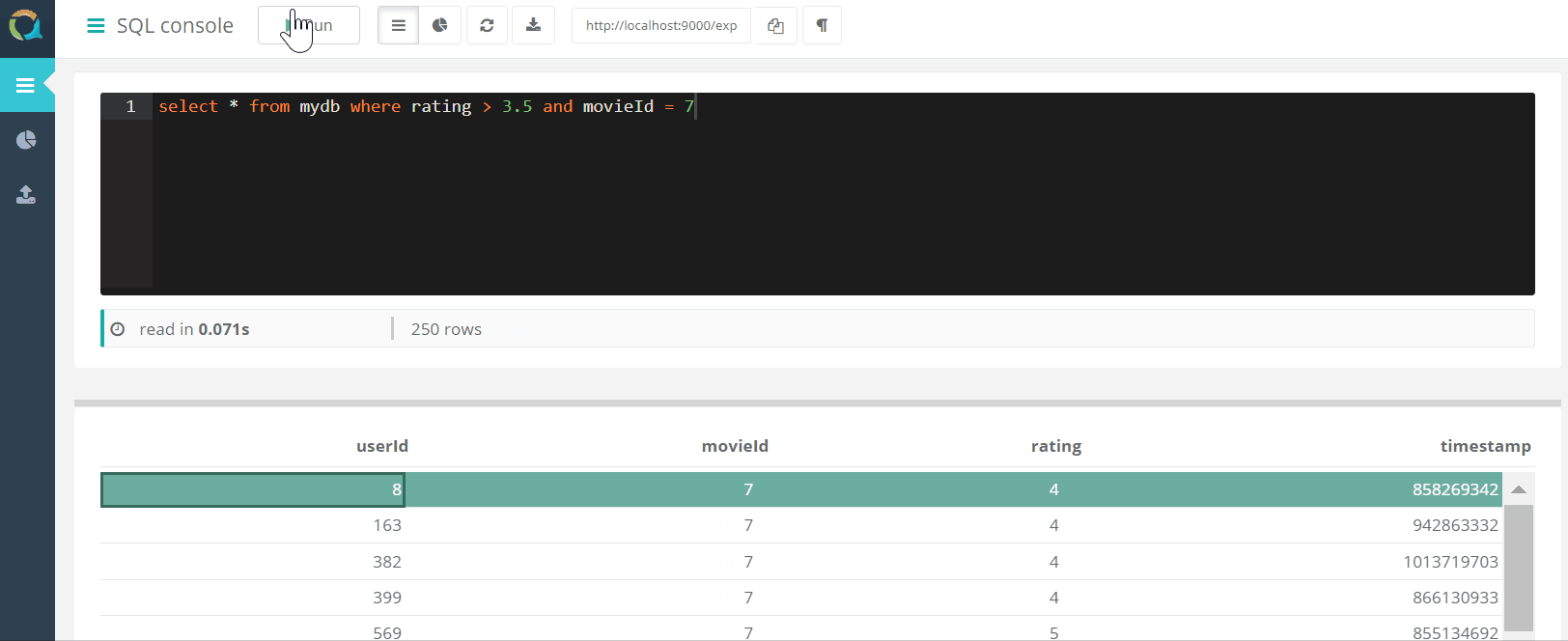 DAN mengunduh data ke basis data dalam format csv melalui peramban.
DAN mengunduh data ke basis data dalam format csv melalui peramban.
Apakah Anda memerlukan database lain?
Proyek ini masih muda dan masih kurang memiliki fitur perusahaan, tetapi sedang berkembang cukup cepat dan beberapa kontributor aktif mengerjakan proyek ini. Saya telah mengikuti QuestDB sejak Agustus lalu dan mengembangkan beberapa ekstensi untuk proyek ini ( fungsi jdbc dan osquery ), dan juga mengintegrasikan proyek ini dengan testcontainers. Sekarang saya mencoba untuk menyelesaikan masalah saya saat ini di Dremio dengan mengunggah data tambahan, partisi data dan transaksi panjang ke sumber data dalam produksi menggunakan QuestDB, melengkapi dengan fungsi ekspor data. Saya berencana untuk berbagi pengalaman dalam publikasi berikut. Ini menyuap saya terutama karena saya dapat men-debug fungsi dan database saya pada platform yang saya kenal, menulis tes unit yang berjalan dengan kecepatan cahaya.Anda memutuskan sebagai pengembang berpengalaman. Sekali lagi, QuestDB bukan pengganti untuk database OLTP - PostgreSQL, Oracle, MS Sql Server, DB2, atau bahkan pengganti H2 untuk pengujiandi JVM. Ini adalah basis data sumber terbuka khusus yang kuat dengan dukungan untuk protokol jaringan PostgreSQL, Influx / Telegraf. Jika skenario penggunaan Anda sesuai dengan fitur yang diterapkan di dalamnya dan skenario utama menggunakan basis data kolom, maka pilihannya dibenarkan!