Mode operasi jarak jauh dengan latar belakang isolasi diri universal dapat mengakibatkan konsekuensi yang sangat buruk. Dan kelelahan emosional - masih ada di mana pun ia pergi: setelah semua, itu tidak jauh dari atap. Dalam hal ini, seperti banyak orang, ia mencoba untuk "menenangkan" dirinya sendiri dengan mengalokasikan waktu untuk kelas-kelas lain - dan mulai menerjemahkan artikel-artikel paling menarik dari bahasa Inggris ke dalam bahasa Rusia: "Kamu memberi pembelajaran mesin kepada massa!".) Kita harus membayar upeti: itu sangat mengganggu. Jika Anda memiliki saran untuk konten semantik dan terjemahan teks ini untuk pembaca berbahasa Rusia, bergabunglah dengan diskusi. Jadi, inilah terjemahan halaman peramalan Time series dari bagian manual tensorflow: tautan . Penambahan saya bersama dengan ilustrasi untuk terjemahan ditujukan untuk membantu memahami ide-ide dasar dalam salah satu bidang ML dan ekonometrik yang paling menarik secara umum - perkiraan waktu.Pengantar kecil sebelum terjemahan.Manual ini adalah deskripsi prediksi suhu udara berdasarkan deret waktu satu dimensi ( deret waktu univariat) dan deret waktu multivariat ( deret waktu multivariat) . Untuk setiap bagian, masukkan dataharus disiapkan sesuai. Dengan mempertimbangkan set data meteorologi yang dipertimbangkan dalam panduan ini, pemisahannya adalah sebagai berikut:
Jadi, inilah terjemahan halaman peramalan Time series dari bagian manual tensorflow: tautan . Penambahan saya bersama dengan ilustrasi untuk terjemahan ditujukan untuk membantu memahami ide-ide dasar dalam salah satu bidang ML dan ekonometrik yang paling menarik secara umum - perkiraan waktu.Pengantar kecil sebelum terjemahan.Manual ini adalah deskripsi prediksi suhu udara berdasarkan deret waktu satu dimensi ( deret waktu univariat) dan deret waktu multivariat ( deret waktu multivariat) . Untuk setiap bagian, masukkan dataharus disiapkan sesuai. Dengan mempertimbangkan set data meteorologi yang dipertimbangkan dalam panduan ini, pemisahannya adalah sebagai berikut: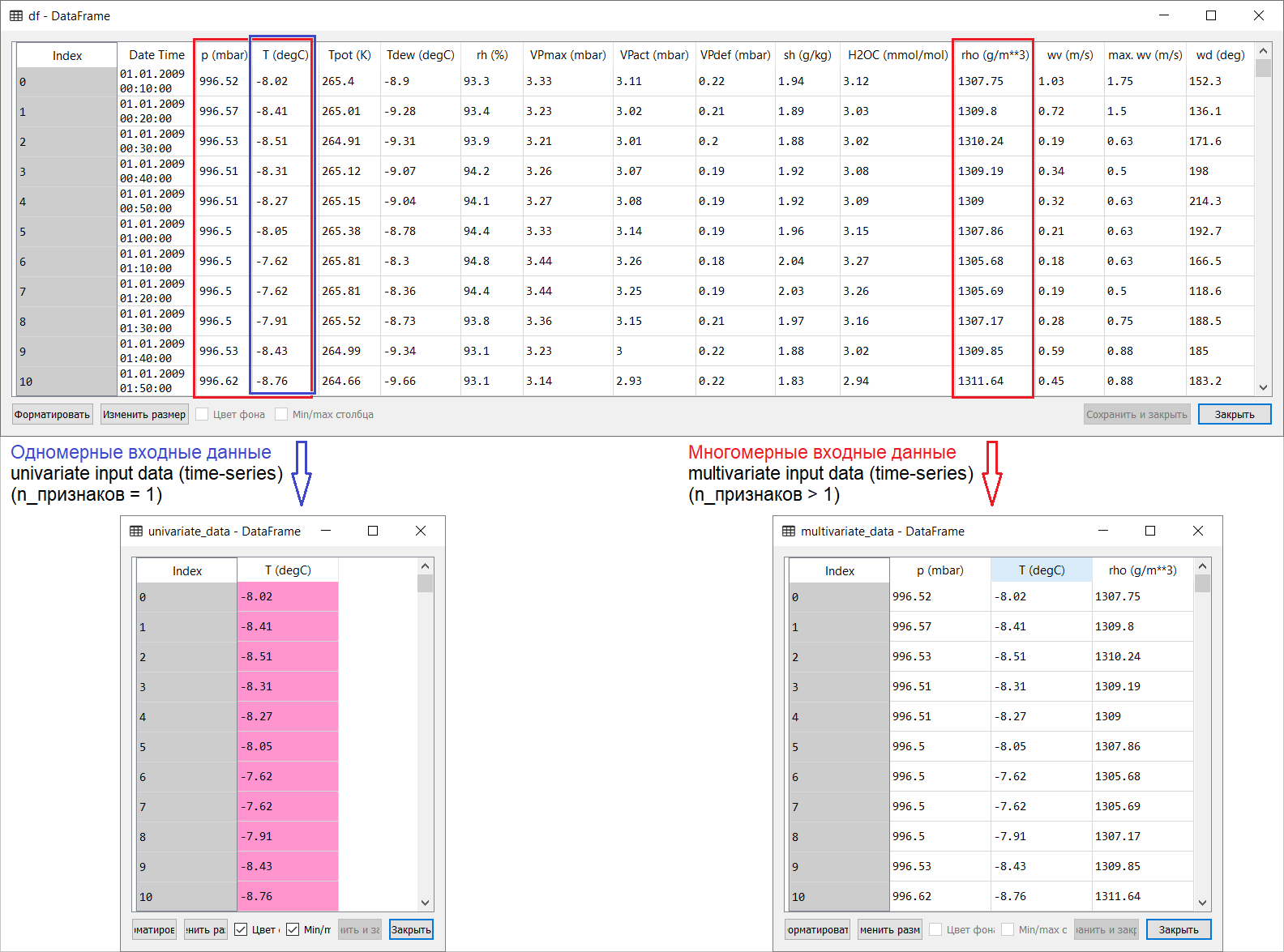 Untuk pertanyaan tentang apa yang harus diambil untuk X dan untuk apa Y , yaitu, bagaimana mempersiapkan data untuk kelas pelatihan yang diawasi, maka akan menjadi jelas dari ilustrasi berikut. Saya hanya mencatat bahwa pembentukan vektor target (Y) untuk bekerja dengan seri waktu satu-dimensi dan multi-dimensi adalah sama: vektor target dikompilasi berdasarkan tanda T (degC)(temperatur udara). Perbedaan di antara mereka adalah "terkubur" dalam pembentukan serangkaian fitur yang dimasukkan ke input model: dalam kasus seri waktu satu dimensi untuk memprediksi suhu di masa depan, vektor input (X) terdiri dari satu fitur: pada kenyataannya, suhu udara; dan untuk multidimensi - lebih dari satu: selain suhu udara, p (mbar) (tekanan atmosfer) dan rho (g / m ** 3) (kelembaban) digunakan dalam contoh panduan ini .Pada awalnya, jauh-dangkal, sebuah contoh dengan peramalan suhu terlihat tidak meyakinkan dari sudut pandang menggunakan input multidimensi: untuk peramalan suhu, tanda yang paling relevan adalah suhu. Namun, ini sama sekali tidak terjadi: untuk mengembangkan perkiraan kualitatif suhu udara, banyak faktor harus diperhitungkan, hingga gesekan udara di permukaan bumi, dll. Selain itu, dalam praktiknya, beberapa hal jauh dari jelas, dan vektor target mungkin dalam bentuk gado-gado (atau borsch). Dalam hal ini, analisis data eksplorasi dengan pemilihan fitur yang paling relevan untuk pembentukan input multidimensi selanjutnya adalah satu-satunya keputusan yang tepat.Jadi, terjemahan manual disajikan di bawah ini. Teks tambahan akan dicetak miring .
Untuk pertanyaan tentang apa yang harus diambil untuk X dan untuk apa Y , yaitu, bagaimana mempersiapkan data untuk kelas pelatihan yang diawasi, maka akan menjadi jelas dari ilustrasi berikut. Saya hanya mencatat bahwa pembentukan vektor target (Y) untuk bekerja dengan seri waktu satu-dimensi dan multi-dimensi adalah sama: vektor target dikompilasi berdasarkan tanda T (degC)(temperatur udara). Perbedaan di antara mereka adalah "terkubur" dalam pembentukan serangkaian fitur yang dimasukkan ke input model: dalam kasus seri waktu satu dimensi untuk memprediksi suhu di masa depan, vektor input (X) terdiri dari satu fitur: pada kenyataannya, suhu udara; dan untuk multidimensi - lebih dari satu: selain suhu udara, p (mbar) (tekanan atmosfer) dan rho (g / m ** 3) (kelembaban) digunakan dalam contoh panduan ini .Pada awalnya, jauh-dangkal, sebuah contoh dengan peramalan suhu terlihat tidak meyakinkan dari sudut pandang menggunakan input multidimensi: untuk peramalan suhu, tanda yang paling relevan adalah suhu. Namun, ini sama sekali tidak terjadi: untuk mengembangkan perkiraan kualitatif suhu udara, banyak faktor harus diperhitungkan, hingga gesekan udara di permukaan bumi, dll. Selain itu, dalam praktiknya, beberapa hal jauh dari jelas, dan vektor target mungkin dalam bentuk gado-gado (atau borsch). Dalam hal ini, analisis data eksplorasi dengan pemilihan fitur yang paling relevan untuk pembentukan input multidimensi selanjutnya adalah satu-satunya keputusan yang tepat.Jadi, terjemahan manual disajikan di bawah ini. Teks tambahan akan dicetak miring .Peramalan Seri Waktu
Panduan ini adalah pengantar perkiraan deret waktu menggunakan jaringan saraf berulang (RNS, dari English Recurrent Neural Network, RNN ). Ini terdiri dari dua bagian: yang pertama menggambarkan prediksi suhu udara berdasarkan deret waktu satu dimensi, dan yang kedua - berdasarkan deret waktu multidimensi.import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
mpl.rcParams['figure.figsize'] = (8, 6)
mpl.rcParams['axes.grid'] = False
Seperangkat data meteorologiSemua contoh penggunaan manual urutan waktu dari data cuaca yang direkam di stasiun hidrometeorologi di Institut Biogeokimia dinamai Max Planck .Kumpulan data ini mencakup pengukuran 14 indikator meteorologi yang berbeda (seperti suhu udara, tekanan atmosfer, kelembaban), yang dilakukan setiap 10 menit sejak 2003. Untuk menghemat waktu dan penggunaan memori, manual ini akan menggunakan data yang mencakup periode 2009 hingga 2016. Bagian dataset ini disiapkan oleh François Chollet untuk bukunya, Deep Learning with Python .zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/tensorflow/tf-keras-datasets/jena_climate_2009_2016.csv.zip',
fname='jena_climate_2009_2016.csv.zip',
extract=True)
csv_path, _ = os.path.splitext(zip_path)
df = pd.read_csv(csv_path)
Mari kita lihat apa yang kita miliki.df.head()
 Fakta bahwa periode rekaman pengamatan adalah 10 menit dapat diverifikasi oleh tabel di atas. Dengan demikian, dalam satu jam Anda akan memiliki 6 pengamatan. Pada gilirannya, 144 pengamatan (6x24) diakumulasikan per hari.Katakanlah Anda ingin memprediksi suhu, yang akan dalam 6 jam di masa depan. Anda membuat ramalan ini berdasarkan data yang Anda miliki untuk periode tertentu: misalnya, Anda memutuskan untuk menggunakan 5 hari pengamatan. Oleh karena itu, untuk melatih model, Anda harus membuat interval waktu yang berisi 720 (5x144) pengamatan terakhir (karena konfigurasi yang berbeda dimungkinkan, kumpulan data ini merupakan dasar yang baik untuk eksperimen).Fungsi di bawah ini mengembalikan interval waktu di atas untuk melatih model. Argumen
Fakta bahwa periode rekaman pengamatan adalah 10 menit dapat diverifikasi oleh tabel di atas. Dengan demikian, dalam satu jam Anda akan memiliki 6 pengamatan. Pada gilirannya, 144 pengamatan (6x24) diakumulasikan per hari.Katakanlah Anda ingin memprediksi suhu, yang akan dalam 6 jam di masa depan. Anda membuat ramalan ini berdasarkan data yang Anda miliki untuk periode tertentu: misalnya, Anda memutuskan untuk menggunakan 5 hari pengamatan. Oleh karena itu, untuk melatih model, Anda harus membuat interval waktu yang berisi 720 (5x144) pengamatan terakhir (karena konfigurasi yang berbeda dimungkinkan, kumpulan data ini merupakan dasar yang baik untuk eksperimen).Fungsi di bawah ini mengembalikan interval waktu di atas untuk melatih model. Argumenhistory_size- ini adalah ukuran interval waktu terakhir, target_size- argumen yang menentukan seberapa jauh ke masa depan yang harus dipelajari model untuk diprediksi. Dengan kata lain, target_sizeadalah vektor target yang perlu diprediksi.def univariate_data(dataset, start_index, end_index, history_size, target_size):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i)
data.append(np.reshape(dataset[indices], (history_size, 1)))
labels.append(dataset[i+target_size])
return np.array(data), np.array(labels)
Di kedua bagian manual, 300.000 baris data pertama akan digunakan untuk melatih model, yang tersisa untuk memvalidasi (memvalidasi) itu. Dalam hal ini, jumlah data pelatihan sekitar 2100 hari.TRAIN_SPLIT = 300000
Untuk memastikan hasil yang dapat direproduksi, fungsi benih diatur.tf.random.set_seed(13)
Bagian 1. Peramalan berdasarkan seri waktu satu dimensi
Pada bagian pertama, Anda akan melatih model hanya menggunakan satu atribut - suhu; model yang terlatih akan digunakan untuk memprediksi suhu di masa depan.Untuk memulai, kami mengekstrak hanya suhu dari kumpulan data.uni_data = df['T (degC)']
uni_data.index = df['Date Time']
uni_data.head()
Date Time
01.01.2009 00:10:00 -8.02
01.01.2009 00:20:00 -8.41
01.01.2009 00:30:00 -8.51
01.01.2009 00:40:00 -8.31
01.01.2009 00:50:00 -8.27
Name: T (degC), dtype: float64
Dan mari kita lihat bagaimana data ini berubah seiring waktu.uni_data.plot(subplots=True)

uni_data = uni_data.values
Sebelum melatih jaringan saraf tiruan (selanjutnya - JST), langkah penting adalah penskalaan data. Salah satu cara umum melakukan penskalaan adalah standardisasi ( standardisasi ), dilakukan dengan mengurangi rata-rata dan membaginya dengan standar deviasi untuk setiap karakteristik. Anda juga bisa menggunakan metode tf.keras.utils.normalizeyang menskala nilai hingga rentang [0,1].Catatan : standardisasi hanya boleh dilakukan menggunakan data pelatihan.uni_train_mean = uni_data[:TRAIN_SPLIT].mean()
uni_train_std = uni_data[:TRAIN_SPLIT].std()
Kami melakukan standarisasi data.uni_data = (uni_data-uni_train_mean)/uni_train_std
Selanjutnya, kami akan menyiapkan data untuk model dengan input satu dimensi. 20 pengamatan terakhir yang direkam dari suhu akan dimasukkan ke pintu masuk ke model, dan model harus dilatih untuk memprediksi suhu pada langkah waktu berikutnya.univariate_past_history = 20
univariate_future_target = 0
x_train_uni, y_train_uni = univariate_data(uni_data, 0, TRAIN_SPLIT,
univariate_past_history,
univariate_future_target)
x_val_uni, y_val_uni = univariate_data(uni_data, TRAIN_SPLIT, None,
univariate_past_history,
univariate_future_target)
Hasil penerapan fungsi univariate_data.print ('Single window of past history')
print (x_train_uni[0])
print ('\n Target temperature to predict')
print (y_train_uni[0])
Single window of past history
[[-1.99766294]
[-2.04281897]
[-2.05439744]
[-2.0312405 ]
[-2.02660912]
[-2.00113649]
[-1.95134907]
[-1.95134907]
[-1.98492663]
[-2.04513467]
[-2.08334362]
[-2.09723778]
[-2.09376424]
[-2.09144854]
[-2.07176515]
[-2.07176515]
[-2.07639653]
[-2.08913285]
[-2.09260639]
[-2.10418486]]
Target temperature to predict
-2.1041848598100876
Penambahan: menyiapkan data untuk model dengan input satu dimensi secara skematis ditunjukkan pada gambar berikut (untuk kenyamanan, dalam angka ini dan selanjutnya, data disajikan dalam bentuk mentah, sebelum standardisasi, dan juga tanpa atribut 'Tanggal waktu' sebagai indeks): Sekarang data dipersiapkan dengan sesuai, pertimbangkan contoh konkret. Informasi yang dikirimkan ke JST disorot dengan warna biru, palang merah menunjukkan nilai masa depan yang harus diprediksi JST.
Sekarang data dipersiapkan dengan sesuai, pertimbangkan contoh konkret. Informasi yang dikirimkan ke JST disorot dengan warna biru, palang merah menunjukkan nilai masa depan yang harus diprediksi JST.def create_time_steps(length):
return list(range(-length, 0))
def show_plot(plot_data, delta, title):
labels = ['History', 'True Future', 'Model Prediction']
marker = ['.-', 'rx', 'go']
time_steps = create_time_steps(plot_data[0].shape[0])
if delta:
future = delta
else:
future = 0
plt.title(title)
for i, x in enumerate(plot_data):
if i:
plt.plot(future, plot_data[i], marker[i], markersize=10,
label=labels[i])
else:
plt.plot(time_steps, plot_data[i].flatten(), marker[i], label=labels[i])
plt.legend()
plt.xlim([time_steps[0], (future+5)*2])
plt.xlabel('Time-Step')
return plt
show_plot([x_train_uni[0], y_train_uni[0]], 0, 'Sample Example')
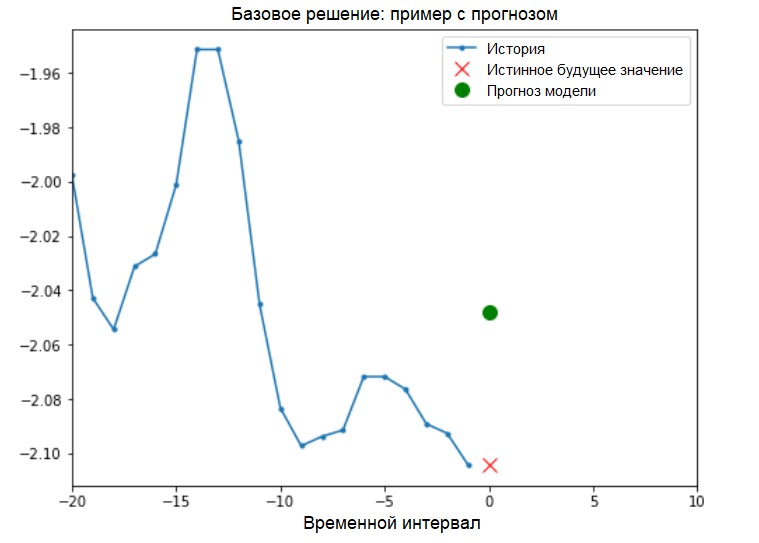
 Solusi dasar (tanpa melibatkan pembelajaran mesin)Sebelum memulai pelatihan model, kami akan menginstal solusi dasar sederhana ( baseline ). Ini terdiri dari yang berikut: untuk vektor input yang diberikan, metode solusi dasar "memindai" seluruh sejarah dan memprediksi nilai berikutnya sebagai rata-rata dari 20 pengamatan terakhir.
Solusi dasar (tanpa melibatkan pembelajaran mesin)Sebelum memulai pelatihan model, kami akan menginstal solusi dasar sederhana ( baseline ). Ini terdiri dari yang berikut: untuk vektor input yang diberikan, metode solusi dasar "memindai" seluruh sejarah dan memprediksi nilai berikutnya sebagai rata-rata dari 20 pengamatan terakhir.def baseline(history):
return np.mean(history)
show_plot([x_train_uni[0], y_train_uni[0], baseline(x_train_uni[0])], 0,
'Baseline Prediction Example')
 Mari kita lihat apakah kita bisa melampaui hasil "rata-rata" menggunakan jaringan saraf berulang.Jaringan Syaraf Berulang Jaringansyaraf berulang (RNS) adalah jenis JST yang cocok untuk memecahkan masalah deret waktu. Langkah demi langkah RNS memproses urutan waktu data, memilah-milah elemen-elemennya dan mempertahankan keadaan internal yang diperoleh dengan memproses elemen-elemen sebelumnya. Anda dapat menemukan informasi lebih lanjut tentang RNS dalam panduan berikut . Panduan ini akan menggunakan lapisan khusus RNC yang disebut Long Short-Term Memory ( LSTM ).Lebih lanjut menggunakan
Mari kita lihat apakah kita bisa melampaui hasil "rata-rata" menggunakan jaringan saraf berulang.Jaringan Syaraf Berulang Jaringansyaraf berulang (RNS) adalah jenis JST yang cocok untuk memecahkan masalah deret waktu. Langkah demi langkah RNS memproses urutan waktu data, memilah-milah elemen-elemennya dan mempertahankan keadaan internal yang diperoleh dengan memproses elemen-elemen sebelumnya. Anda dapat menemukan informasi lebih lanjut tentang RNS dalam panduan berikut . Panduan ini akan menggunakan lapisan khusus RNC yang disebut Long Short-Term Memory ( LSTM ).Lebih lanjut menggunakantf.dataAcak, batch, dan cache kumpulan data.Tambahan:
Lebih lanjut tentang metode acak, batch dan cache pada halaman tensorflow :BATCH_SIZE = 256
BUFFER_SIZE = 10000
train_univariate = tf.data.Dataset.from_tensor_slices((x_train_uni, y_train_uni))
train_univariate = train_univariate.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_univariate = tf.data.Dataset.from_tensor_slices((x_val_uni, y_val_uni))
val_univariate = val_univariate.batch(BATCH_SIZE).repeat()
Visualisasi berikut akan membantu Anda memahami seperti apa data setelah pemrosesan batch. Dapat dilihat bahwa LSTM membutuhkan bentuk entri data tertentu, yang disediakan untuk itu.
Dapat dilihat bahwa LSTM membutuhkan bentuk entri data tertentu, yang disediakan untuk itu.simple_lstm_model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(8, input_shape=x_train_uni.shape[-2:]),
tf.keras.layers.Dense(1)
])
simple_lstm_model.compile(optimizer='adam', loss='mae')
Periksa output model.for x, y in val_univariate.take(1):
print(simple_lstm_model.predict(x).shape)
(256, 1)
Tambahan:
Secara umum, RNS bekerja dengan urutan. Ini berarti bahwa data yang dipasok ke input model harus memiliki bentuk berikut:
[, , - ]
Bentuk data pelatihan untuk model dengan input satu dimensi memiliki bentuk berikut:print(x_train_uni.shape)
(299980, 20, 1)Selanjutnya, kita akan mempelajari modelnya. Karena ukuran besar kumpulan data dan untuk menghemat waktu, setiap zaman hanya akan melalui 200 langkah ( steps_per_epoch = 200 ) alih-alih data pelatihan lengkap, seperti yang biasanya dilakukan.EVALUATION_INTERVAL = 200
EPOCHS = 10
simple_lstm_model.fit(train_univariate, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_univariate, validation_steps=50)
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] - 2s 11ms/step - loss: 0.4075 - val_loss: 0.1351
Epoch 2/10
200/200 [==============================] - 1s 4ms/step - loss: 0.1118 - val_loss: 0.0360
Epoch 3/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0490 - val_loss: 0.0289
Epoch 4/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0444 - val_loss: 0.0257
Epoch 5/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0299 - val_loss: 0.0235
Epoch 6/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0317 - val_loss: 0.0224
Epoch 7/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0287 - val_loss: 0.0206
Epoch 8/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0263 - val_loss: 0.0200
Epoch 9/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0254 - val_loss: 0.0182
Epoch 10/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0228 - val_loss: 0.0174
Prediksi menggunakan model LSTM sederhanaSetelah menyelesaikan persiapan model LSTM sederhana, kami akan membuat beberapa prediksi.for x, y in val_univariate.take(3):
plot = show_plot([x[0].numpy(), y[0].numpy(),
simple_lstm_model.predict(x)[0]], 0, 'Simple LSTM model')
plot.show()
 Ini terlihat lebih baik daripada level dasar.Sekarang setelah Anda terbiasa dengan dasar-dasarnya, mari beralih ke bagian kedua, yang menjelaskan bekerja dengan rangkaian waktu multidimensi.
Ini terlihat lebih baik daripada level dasar.Sekarang setelah Anda terbiasa dengan dasar-dasarnya, mari beralih ke bagian kedua, yang menjelaskan bekerja dengan rangkaian waktu multidimensi.Bagian 2: Peramalan Seri Waktu Multidimensi
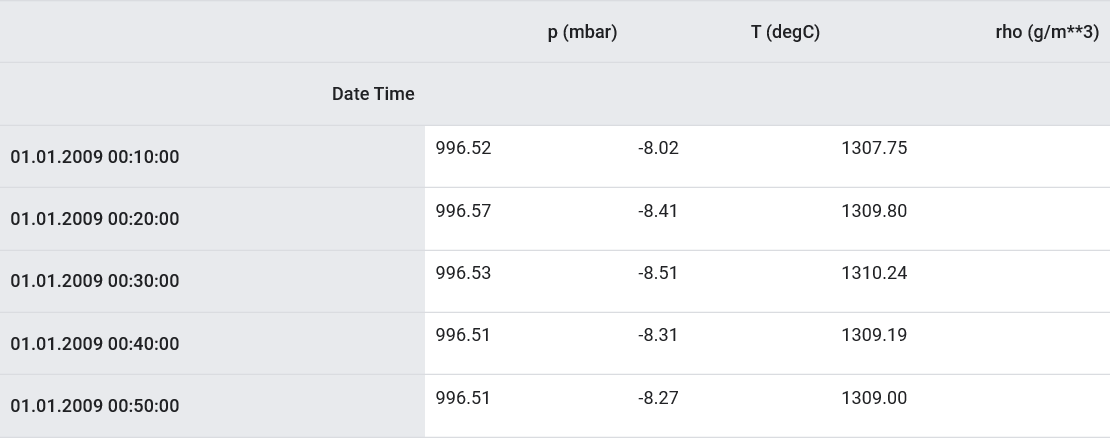
Seperti yang dinyatakan, dataset asli berisi 14 indikator meteorologi yang berbeda. Untuk kesederhanaan dan kenyamanan, pada bagian kedua hanya tiga yang dipertimbangkan - suhu udara, tekanan atmosfer, dan kepadatan udara.Untuk menggunakan lebih banyak fitur, nama mereka harus ditambahkan ke daftar feature_considered .features_considered = ['p (mbar)', 'T (degC)', 'rho (g/m**3)']
features = df[features_considered]
features.index = df['Date Time']
features.head()
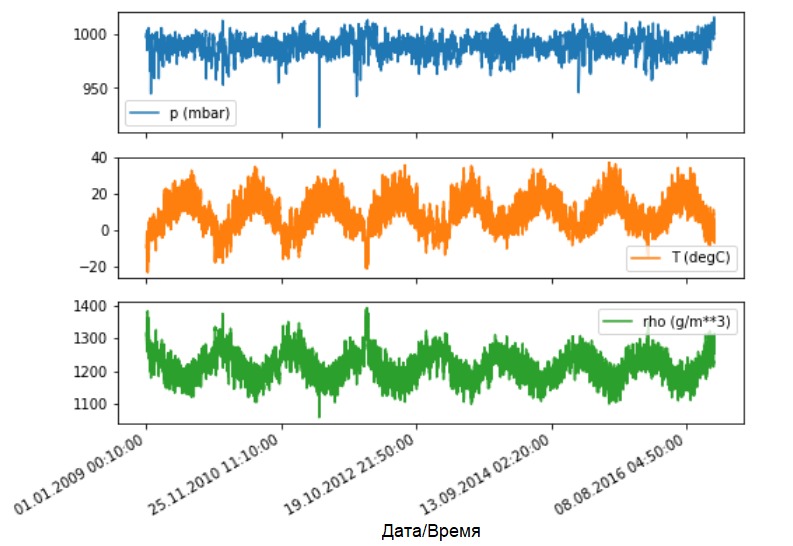
 Mari kita lihat bagaimana indikator ini berubah seiring waktu.
Mari kita lihat bagaimana indikator ini berubah seiring waktu.features.plot(subplots=True)
 Seperti sebelumnya, langkah pertama adalah membakukan data yang ditetapkan dengan perhitungan nilai rata-rata dan standar deviasi dari data pelatihan.
Seperti sebelumnya, langkah pertama adalah membakukan data yang ditetapkan dengan perhitungan nilai rata-rata dan standar deviasi dari data pelatihan.dataset = features.values
data_mean = dataset[:TRAIN_SPLIT].mean(axis=0)
data_std = dataset[:TRAIN_SPLIT].std(axis=0)
dataset = (dataset-data_mean)/data_std
Tambahan:
Selanjutnya dalam manual kita akan berbicara tentang perkiraan titik dan interval.
Intinya adalah sebagai berikut. Jika Anda membutuhkan model untuk memprediksi satu nilai di masa mendatang (misalnya, nilai suhu setelah 12 jam) (model satu langkah / langkah tunggal), maka Anda harus melatih model tersebut sehingga hanya memprediksi satu nilai di masa mendatang. Jika tugasnya adalah memprediksi kisaran nilai di masa mendatang (misalnya, suhu per jam selama 12 jam berikutnya) (model multi-langkah), maka model tersebut juga harus dilatih untuk memprediksi kisaran nilai di masa mendatang. Prediksi titikDalam kasus ini, model dilatih untuk memprediksi satu nilai di masa mendatang berdasarkan beberapa riwayat yang tersedia.Fungsi di bawah ini melakukan tugas yang sama mengatur interval waktu hanya dengan perbedaan bahwa di sini ia memilih pengamatan terbaru berdasarkan ukuran langkah yang diberikan.
Prediksi titikDalam kasus ini, model dilatih untuk memprediksi satu nilai di masa mendatang berdasarkan beberapa riwayat yang tersedia.Fungsi di bawah ini melakukan tugas yang sama mengatur interval waktu hanya dengan perbedaan bahwa di sini ia memilih pengamatan terbaru berdasarkan ukuran langkah yang diberikan.def multivariate_data(dataset, target, start_index, end_index, history_size,
target_size, step, single_step=False):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i, step)
data.append(dataset[indices])
if single_step:
labels.append(target[i+target_size])
else:
labels.append(target[i:i+target_size])
return np.array(data), np.array(labels)
Dalam manual ini, JST beroperasi pada data selama lima (5) hari terakhir, yaitu 720 pengamatan (6x24x5). Misalkan pemilihan data dilakukan tidak setiap 10 menit, tetapi setiap jam: tidak ada perubahan tajam yang diharapkan dalam 60 menit. Oleh karena itu, sejarah lima hari terakhir terdiri dari 120 pengamatan (720/6). Untuk model yang melakukan prediksi titik, tujuannya adalah nilai suhu setelah 12 jam di masa depan. Dalam hal ini, vektor target akan menjadi suhu setelah 72 (12x6) pengamatan ( lihat tambahan berikut. - Approx. Translator ).past_history = 720
future_target = 72
STEP = 6
x_train_single, y_train_single = multivariate_data(dataset, dataset[:, 1], 0,
TRAIN_SPLIT, past_history,
future_target, STEP,
single_step=True)
x_val_single, y_val_single = multivariate_data(dataset, dataset[:, 1],
TRAIN_SPLIT, None, past_history,
future_target, STEP,
single_step=True)
Periksa interval waktu.print ('Single window of past history : {}'.format(x_train_single[0].shape))
Single window of past history : (120, 3)
train_data_single = tf.data.Dataset.from_tensor_slices((x_train_single, y_train_single))
train_data_single = train_data_single.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_data_single = tf.data.Dataset.from_tensor_slices((x_val_single, y_val_single))
val_data_single = val_data_single.batch(BATCH_SIZE).repeat()
single_step_model = tf.keras.models.Sequential()
single_step_model.add(tf.keras.layers.LSTM(32,
input_shape=x_train_single.shape[-2:]))
single_step_model.add(tf.keras.layers.Dense(1))
single_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(), loss='mae')
Kami akan memeriksa sampel kami dan mendapatkan kurva kehilangan pada tahap pelatihan dan verifikasi.for x, y in val_data_single.take(1):
print(single_step_model.predict(x).shape)
(256, 1)
single_step_history = single_step_model.fit(train_data_single, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_data_single,
validation_steps=50)
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] - 4s 18ms/step - loss: 0.3090 - val_loss: 0.2646
Epoch 2/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2624 - val_loss: 0.2435
Epoch 3/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2616 - val_loss: 0.2472
Epoch 4/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2567 - val_loss: 0.2442
Epoch 5/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2263 - val_loss: 0.2346
Epoch 6/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2416 - val_loss: 0.2643
Epoch 7/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2411 - val_loss: 0.2577
Epoch 8/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2410 - val_loss: 0.2388
Epoch 9/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2447 - val_loss: 0.2485
Epoch 10/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2388 - val_loss: 0.2422
def plot_train_history(history, title):
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(loss))
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title(title)
plt.legend()
plt.show()
plot_train_history(single_step_history,
'Single Step Training and validation loss')
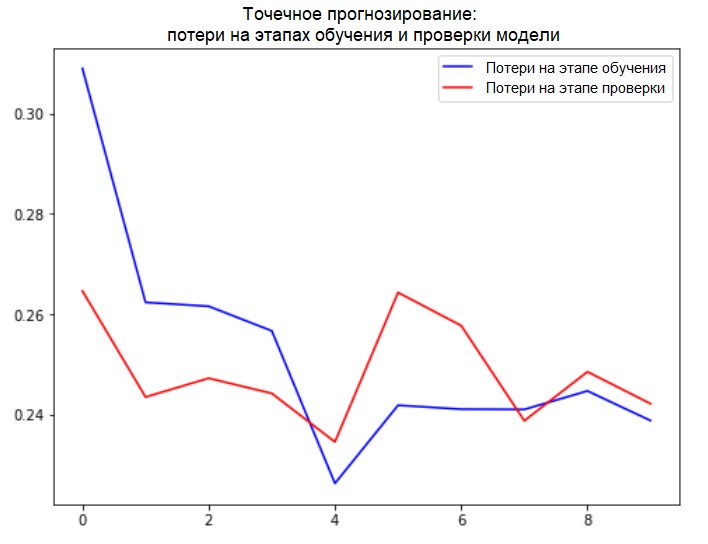 Tambahan:
Tambahan:
Persiapan data untuk model dengan prediksi titik kinerja input multidimensi ditampilkan secara skematis pada gambar berikut. Untuk kenyamanan dan representasi yang lebih visual dari persiapan data, argumennya STEPadalah 1. Perhatikan bahwa dalam fungsi generator yang diberikan, argumen tersebut STEP dimaksudkan hanya untuk pembentukan sejarah , dan bukan untuk vektor target.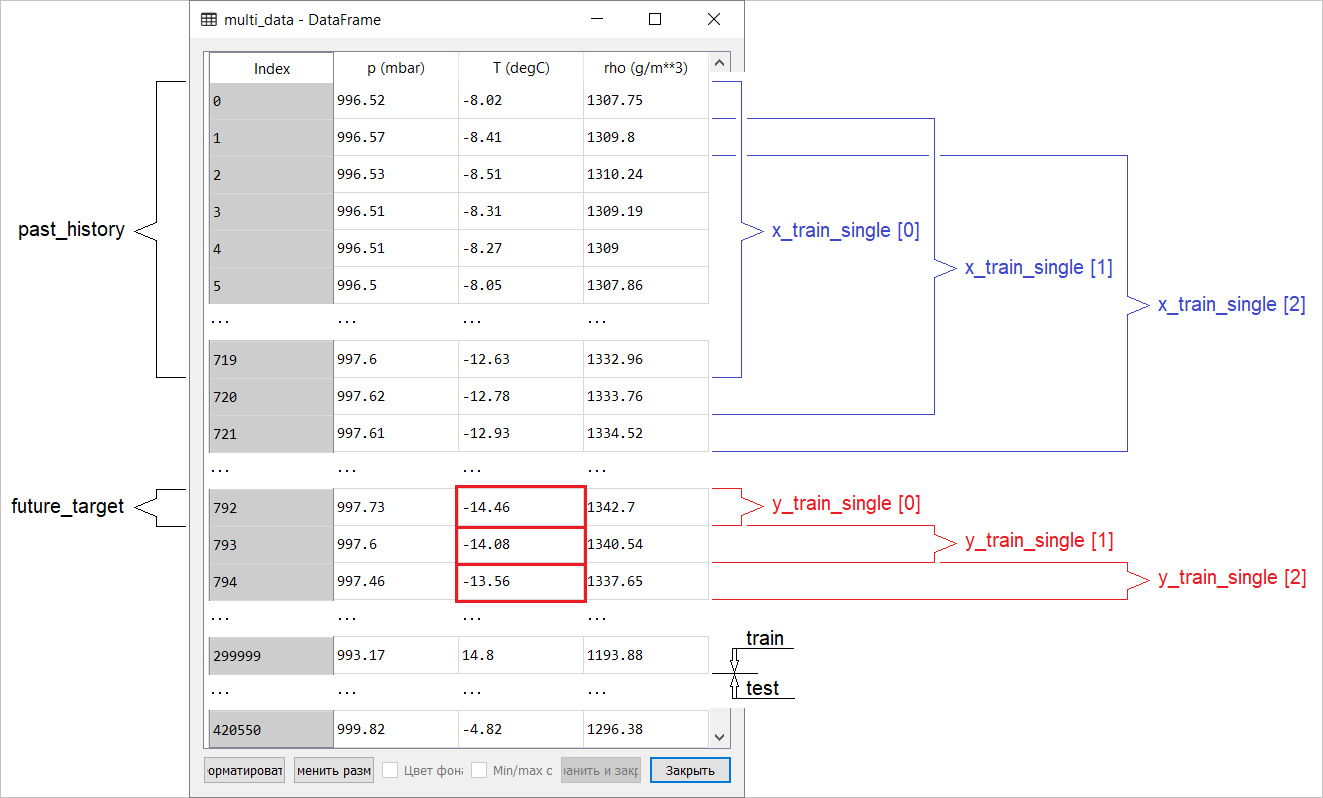 Dalam hal ini, ia
Dalam hal ini, ia x_train_singlememiliki formulir (299280, 720, 3).
Ketika STEP=6, formulir akan mengambil bentuk berikut: (299280, 120, 3)dan kecepatan fungsi akan meningkat secara signifikan. Secara umum, Anda perlu memberikan kredit kepada programmer: generator yang disajikan dalam manual sangat lahap dalam hal konsumsi memori.Melakukan prediksi titikSekarang setelah model dilatih, kami akan melakukan beberapa prediksi pengujian. Sejarah pengamatan 3 tanda selama lima hari terakhir, dipilih setiap jam (interval waktu = 120), dimasukkan ke input model. Karena tujuan kami adalah untuk meramalkan hanya suhu, nilai suhu sebelumnya ( histori ) ditampilkan dengan warna biru pada grafik . Perkiraan dibuat setengah hari ke depan (karenanya kesenjangan antara sejarah dan nilai prediksi).for x, y in val_data_single.take(3):
plot = show_plot([x[0][:, 1].numpy(), y[0].numpy(),
single_step_model.predict(x)[0]], 12,
'Single Step Prediction')
plot.show()
 Perkiraan intervalDalam kasus ini, berdasarkan beberapa riwayat yang tersedia, model dilatih untuk memprediksi interval nilai masa depan. Jadi, berbeda dengan model yang memprediksi hanya satu nilai di masa depan, model ini memprediksi urutan nilai di masa depan.Misalkan, seperti dalam kasus dengan prediksi titik kinerja model, untuk model yang melakukan prediksi interval, data pelatihan adalah pengukuran setiap jam selama lima hari terakhir (720/6). Namun, dalam hal ini, model harus dilatih untuk memprediksi suhu selama 12 jam ke depan. Karena pengamatan dicatat setiap 10 menit, output dari model harus terdiri dari 72 prediksi. Untuk menyelesaikan tugas ini, perlu menyiapkan set data lagi, tetapi dengan interval target yang berbeda.
Perkiraan intervalDalam kasus ini, berdasarkan beberapa riwayat yang tersedia, model dilatih untuk memprediksi interval nilai masa depan. Jadi, berbeda dengan model yang memprediksi hanya satu nilai di masa depan, model ini memprediksi urutan nilai di masa depan.Misalkan, seperti dalam kasus dengan prediksi titik kinerja model, untuk model yang melakukan prediksi interval, data pelatihan adalah pengukuran setiap jam selama lima hari terakhir (720/6). Namun, dalam hal ini, model harus dilatih untuk memprediksi suhu selama 12 jam ke depan. Karena pengamatan dicatat setiap 10 menit, output dari model harus terdiri dari 72 prediksi. Untuk menyelesaikan tugas ini, perlu menyiapkan set data lagi, tetapi dengan interval target yang berbeda.future_target = 72
x_train_multi, y_train_multi = multivariate_data(dataset, dataset[:, 1], 0,
TRAIN_SPLIT, past_history,
future_target, STEP)
x_val_multi, y_val_multi = multivariate_data(dataset, dataset[:, 1],
TRAIN_SPLIT, None, past_history,
future_target, STEP)
Periksa pilihan.print ('Single window of past history : {}'.format(x_train_multi[0].shape))
print ('\n Target temperature to predict : {}'.format(y_train_multi[0].shape))
Single window of past history : (120, 3)
Target temperature to predict : (72,)
train_data_multi = tf.data.Dataset.from_tensor_slices((x_train_multi, y_train_multi))
train_data_multi = train_data_multi.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_data_multi = tf.data.Dataset.from_tensor_slices((x_val_multi, y_val_multi))
val_data_multi = val_data_multi.batch(BATCH_SIZE).repeat()
Tambahan: perbedaan dalam pembentukan vektor target untuk "model interval" dari "model titik" terlihat pada gambar berikut. Kami akan menyiapkan visualisasi.
Kami akan menyiapkan visualisasi.def multi_step_plot(history, true_future, prediction):
plt.figure(figsize=(12, 6))
num_in = create_time_steps(len(history))
num_out = len(true_future)
plt.plot(num_in, np.array(history[:, 1]), label='History')
plt.plot(np.arange(num_out)/STEP, np.array(true_future), 'bo',
label='True Future')
if prediction.any():
plt.plot(np.arange(num_out)/STEP, np.array(prediction), 'ro',
label='Predicted Future')
plt.legend(loc='upper left')
plt.show()
Pada grafik ini dan selanjutnya yang serupa, riwayat dan data masa depan adalah setiap jam.for x, y in train_data_multi.take(1):
multi_step_plot(x[0], y[0], np.array([0]))
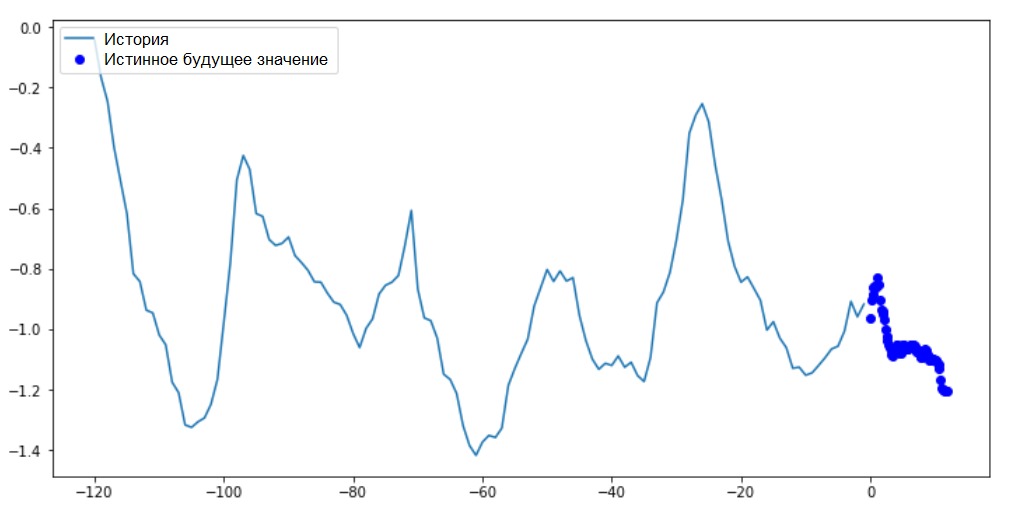 Karena tugas ini sedikit lebih rumit dari yang sebelumnya, model akan terdiri dari dua lapisan LSTM. Akhirnya, karena 72 prediksi dilakukan, layer output memiliki 72 neuron.
Karena tugas ini sedikit lebih rumit dari yang sebelumnya, model akan terdiri dari dua lapisan LSTM. Akhirnya, karena 72 prediksi dilakukan, layer output memiliki 72 neuron.multi_step_model = tf.keras.models.Sequential()
multi_step_model.add(tf.keras.layers.LSTM(32,
return_sequences=True,
input_shape=x_train_multi.shape[-2:]))
multi_step_model.add(tf.keras.layers.LSTM(16, activation='relu'))
multi_step_model.add(tf.keras.layers.Dense(72))
multi_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(clipvalue=1.0), loss='mae')
Kami akan memeriksa sampel kami dan mendapatkan kurva kehilangan pada tahap pelatihan dan verifikasi.for x, y in val_data_multi.take(1):
print (multi_step_model.predict(x).shape)
(256, 72)
multi_step_history = multi_step_model.fit(train_data_multi, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_data_multi,
validation_steps=50)
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] - 21s 103ms/step - loss: 0.4952 - val_loss: 0.3008
Epoch 2/10
200/200 [==============================] - 18s 89ms/step - loss: 0.3474 - val_loss: 0.2898
Epoch 3/10
200/200 [==============================] - 18s 89ms/step - loss: 0.3325 - val_loss: 0.2541
Epoch 4/10
200/200 [==============================] - 18s 89ms/step - loss: 0.2425 - val_loss: 0.2066
Epoch 5/10
200/200 [==============================] - 18s 89ms/step - loss: 0.1963 - val_loss: 0.1995
Epoch 6/10
200/200 [==============================] - 18s 90ms/step - loss: 0.2056 - val_loss: 0.2119
Epoch 7/10
200/200 [==============================] - 18s 91ms/step - loss: 0.1978 - val_loss: 0.2079
Epoch 8/10
200/200 [==============================] - 18s 89ms/step - loss: 0.1957 - val_loss: 0.2033
Epoch 9/10
200/200 [==============================] - 18s 90ms/step - loss: 0.1977 - val_loss: 0.1860
Epoch 10/10
200/200 [==============================] - 18s 88ms/step - loss: 0.1904 - val_loss: 0.1863
plot_train_history(multi_step_history, 'Multi-Step Training and validation loss')
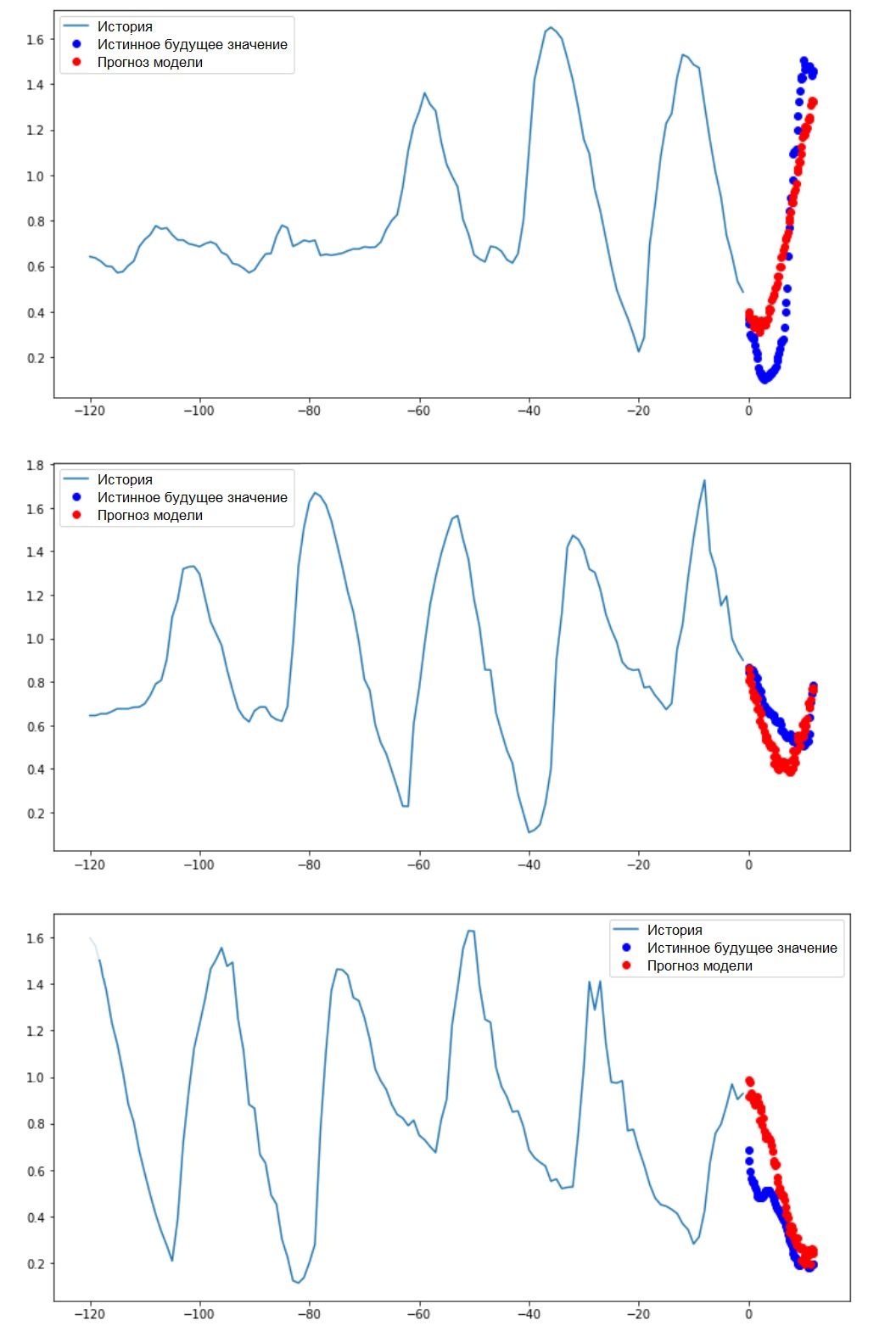
 Melakukan Prediksi IntervalJadi, mari kita cari tahu seberapa sukses JST yang terlatih mengatasi dengan perkiraan nilai suhu di masa depan.
Melakukan Prediksi IntervalJadi, mari kita cari tahu seberapa sukses JST yang terlatih mengatasi dengan perkiraan nilai suhu di masa depan.for x, y in val_data_multi.take(3):
multi_step_plot(x[0], y[0], multi_step_model.predict(x)[0])
Langkah selanjutnya
Panduan ini adalah pengantar singkat untuk perkiraan seri waktu menggunakan RNS. Sekarang Anda dapat mencoba memprediksi pasar saham dan menjadi miliarder (seperti aslinya, begitu saja :). - Catatan penerjemah) .Selain itu, Anda dapat menulis generator sendiri untuk menyiapkan data alih-alih fungsi uni / multivariate_data untuk menggunakan memori lebih efisien. Anda juga dapat membiasakan diri dengan karya " time series windowing " dan membawa ide-idenya ke panduan ini.Untuk pemahaman lebih lanjut, Anda disarankan untuk membaca Bab 15 buku “Pembelajaran Mesin Terapan dengan Scikit-Learn, Keras, dan TensorFlow” (Aurelien Geron, Edisi 2) dan Bab 6 buku"Belajar Dalam dengan Python" (Francois Scholl).Penambahan akhir
Saat tinggal di rumah, jaga kesehatan Anda tidak hanya, tetapi juga kasihan pada komputer dengan mengeksekusi contoh manual pada set data terpotong. Misalnya, dengan mempertimbangkan proporsi 70x30 (pelatihan / pengujian), Anda dapat membatasi sebagai berikut:dataset = features[300000:].values
TRAIN_SPLIT = 85000