Setelah menjadi topik yang menarik, apa yang akan ditonjolkan LDA (penempatan dirichlet laten) pada materi "Live Journal". Seperti yang mereka katakan, ada minat - tidak ada masalah.Sebagai permulaan, sedikit tentang LDA di jari, kami tidak akan masuk ke detail matematika (siapa pun yang tertarik - membaca). Jadi, LDA - adalah salah satu algoritma paling umum untuk topik pemodelan. Setiap dokumen (baik itu artikel, buku, atau sumber data tekstual lainnya) adalah campuran dari topik, dan setiap topik adalah campuran dari kata-kata.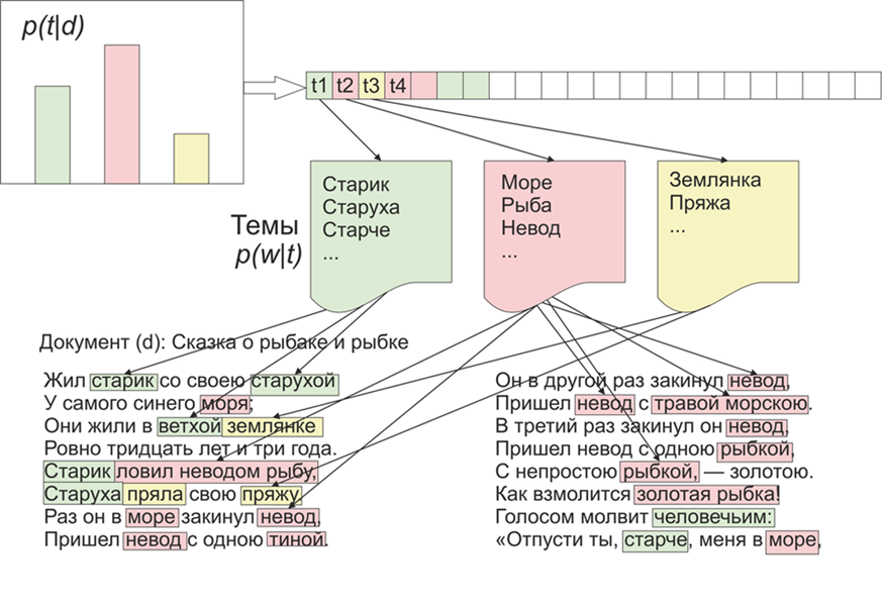 Gambar diambil dari WikipediaDengan demikian, tugas LDA adalah menemukan kelompok kata yang membentuk topik dari kumpulan dokumen. Kemudian, berdasarkan topik, Anda dapat mengelompokkan teks atau hanya menyorot kata kunci.Sekitar 1800 artikel diterima dari situs LifeJournal, semuanya dikonversi ke format jsonl,saya akan meninggalkan artikel-artikel yang tidak bersih pada disk Yandex . Kami akan melakukan pembersihan dan normalisasi data: membuang komentar, menghapus kata-kata penghentian (daftar bersama dengan kode sumber tersedia di github), kami akan membawa semua kata ke ejaan huruf kecil, kami akan menghapus tanda baca dan kata-kata yang mengandung 3 huruf atau kurang. Tetapi salah satu operasi pra-pemrosesan utama: menghapus kata-kata yang sering muncul, pada prinsipnya, dapat dibatasi dengan menghapus hanya kata-kata berhenti, tetapi kemudian kata-kata yang sering digunakan akan dimasukkan dalam hampir semua topik dengan probabilitas tinggi. Dalam hal ini, dimungkinkan untuk memposting dan menghapus kata-kata tersebut. Pilihan ada padamu.
Gambar diambil dari WikipediaDengan demikian, tugas LDA adalah menemukan kelompok kata yang membentuk topik dari kumpulan dokumen. Kemudian, berdasarkan topik, Anda dapat mengelompokkan teks atau hanya menyorot kata kunci.Sekitar 1800 artikel diterima dari situs LifeJournal, semuanya dikonversi ke format jsonl,saya akan meninggalkan artikel-artikel yang tidak bersih pada disk Yandex . Kami akan melakukan pembersihan dan normalisasi data: membuang komentar, menghapus kata-kata penghentian (daftar bersama dengan kode sumber tersedia di github), kami akan membawa semua kata ke ejaan huruf kecil, kami akan menghapus tanda baca dan kata-kata yang mengandung 3 huruf atau kurang. Tetapi salah satu operasi pra-pemrosesan utama: menghapus kata-kata yang sering muncul, pada prinsipnya, dapat dibatasi dengan menghapus hanya kata-kata berhenti, tetapi kemudian kata-kata yang sering digunakan akan dimasukkan dalam hampir semua topik dengan probabilitas tinggi. Dalam hal ini, dimungkinkan untuk memposting dan menghapus kata-kata tersebut. Pilihan ada padamu.stop=open('stop.txt')
stop_words=[]
for line in stop:
stop_words.append(line)
for i in range(0,len(stop_words)):
stop_words[i]=stop_words[i][:-1]
texts=[re.split( r' [\w\.\&\?!,_\-#)(:;*%$№"\@]* ' ,texts[i])[0].replace("\n","") for i in range(0,len(texts))]
texts=[test_re(line) for line in texts]
texts=[t.lower() for t in texts]
texts = [[word for word in document.split() if word not in stop_words] for document in texts]
texts=[[word for word in document if len(word)>=3]for document in texts]
Selanjutnya, kami membawa semua kata ke bentuk normal: untuk ini kami menggunakan pymorphy2 library, yang dapat diinstal melalui pip.morph = pymorphy2.MorphAnalyzer()
for i in range(0,len(texts)):
for j in range(0,len(texts[i])):
texts[i][j] = morph.parse(texts[i][j])[0].normal_form
Ya, kami akan kehilangan informasi tentang bentuk kata, tetapi dalam konteks ini, kami lebih tertarik pada kompatibilitas kata satu sama lain. Di sinilah persiapan awal kami selesai, tidak lengkap, tetapi cukup untuk melihat bagaimana algoritma LDA bekerja.Lebih lanjut, poin yang disebutkan di atas, pada prinsipnya, dapat dihilangkan, tetapi menurut pendapat saya, hasilnya lebih memadai, sekali lagi, ambang apa yang akan, Anda memutuskan, misalnya, Anda dapat membangun fungsi yang tergantung pada panjang rata-rata dokumen dan jumlah mereka :counter = collections.Counter()
for t in texts:
for r in t:
counter[r]+=1
limit = len(texts)/5
too_common = [w for w in counter if counter[w] > limit]
too_common=set(too_common)
texts = [[word for word in document if word not in too_common] for document in texts]
Mari kita lanjutkan langsung ke pelatihan model, untuk ini kita perlu menginstal perpustakaan gensim, yang berisi banyak roti keren. Pertama, Anda perlu menyandikan semua kata, fungsi Kamus akan melakukannya untuk kami, lalu ganti kata-kata itu dengan angka-angka yang setara. Versi panggilan LDA yang dikomentari lebih panjang, karena diperbarui setelah setiap dokumen, Anda dapat bermain dengan pengaturan dan memilih opsi yang sesuai.texts=preposition_text_for_lda(my_r)
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=10)
Setelah pekerjaan program, topik dapat dilihat menggunakan perintahlda.show_topic(i,topn=30)
, di mana saya adalah nomor topik, dan topn adalah jumlah kata dalam topik yang akan ditampilkan.Sekarang bonus kecil untuk memvisualisasikan tema, untuk ini Anda perlu menginstal perpustakaan wordcloud (seperti, utilitas serupa juga di matplotlib). Kode ini memvisualisasikan tema dan menyimpannya di folder saat ini.from wordcloud import WordCloud, STOPWORDS
for i in range(0,10):
a=lda.show_topic(i,topn=30)
wordcloud = WordCloud(
relative_scaling = 1.0,
stopwords = too_common
).generate_from_frequencies(dict(a))
wordcloud.to_file('society'+str(i)+'.png')
Dan akhirnya, beberapa contoh topik yang saya dapatkan:
 Eksperimen dan Anda bisa mendapatkan hasil yang lebih bermakna.
Eksperimen dan Anda bisa mendapatkan hasil yang lebih bermakna.