 Selamat siang teman!Artikel ini menjelaskan beberapa konsep dari teori musik tempat Web Audio API (WAA) beroperasi. Mengetahui konsep-konsep ini, Anda dapat membuat keputusan berdasarkan informasi saat merancang audio dalam suatu aplikasi. Artikel ini tidak akan menjadikan Anda seorang insinyur suara yang berpengalaman, tetapi ini akan membantu Anda memahami mengapa WAA bekerja sebagaimana mestinya.
Selamat siang teman!Artikel ini menjelaskan beberapa konsep dari teori musik tempat Web Audio API (WAA) beroperasi. Mengetahui konsep-konsep ini, Anda dapat membuat keputusan berdasarkan informasi saat merancang audio dalam suatu aplikasi. Artikel ini tidak akan menjadikan Anda seorang insinyur suara yang berpengalaman, tetapi ini akan membantu Anda memahami mengapa WAA bekerja sebagaimana mestinya.Sirkuit audio
Inti dari WAA adalah untuk melakukan beberapa operasi dengan suara dalam konteks audio. API ini telah dirancang khusus untuk perutean modular. Operasi dasar dengan suara adalah simpul audio, saling berhubungan dan membentuk diagram perutean (grafik perutean audio). Beberapa sumber - dengan berbagai jenis saluran - diproses dalam satu konteks. Desain modular ini memberikan fleksibilitas yang diperlukan untuk membuat fungsi kompleks dengan efek dinamis.Node audio saling terhubung melalui input dan output, membentuk rantai yang dimulai dari satu atau lebih sumber, melewati satu atau lebih node, dan berakhir di tujuan. Pada prinsipnya, Anda dapat melakukannya tanpa tujuan, misalnya, jika kami hanya ingin memvisualisasikan beberapa data audio. Alur kerja audio web biasanya terlihat seperti ini:- Buat konteks audio
- Di dalam konteks, buat sumber - seperti <audio>, osilator (generator suara) atau streaming
- Buat node efek seperti reverb , filter biquad, panner atau kompresor
- Pilih tujuan untuk audio, seperti speaker di komputer pengguna
- Membangun koneksi antara sumber melalui efek ke tujuan

Penunjukan saluran
Jumlah saluran audio yang tersedia sering diindikasikan dalam format numerik, misalnya, 2.0 atau 5.1. Ini disebut penunjukan saluran. Digit pertama menunjukkan rentang frekuensi penuh yang termasuk sinyal. Digit kedua menunjukkan jumlah saluran yang disediakan untuk output efek frekuensi rendah - subwoofer .Setiap input atau output terdiri dari satu atau lebih saluran yang dibangun sesuai dengan sirkuit audio tertentu. Ada berbagai struktur saluran diskrit seperti mono, stereo, quad, 5.1, dll.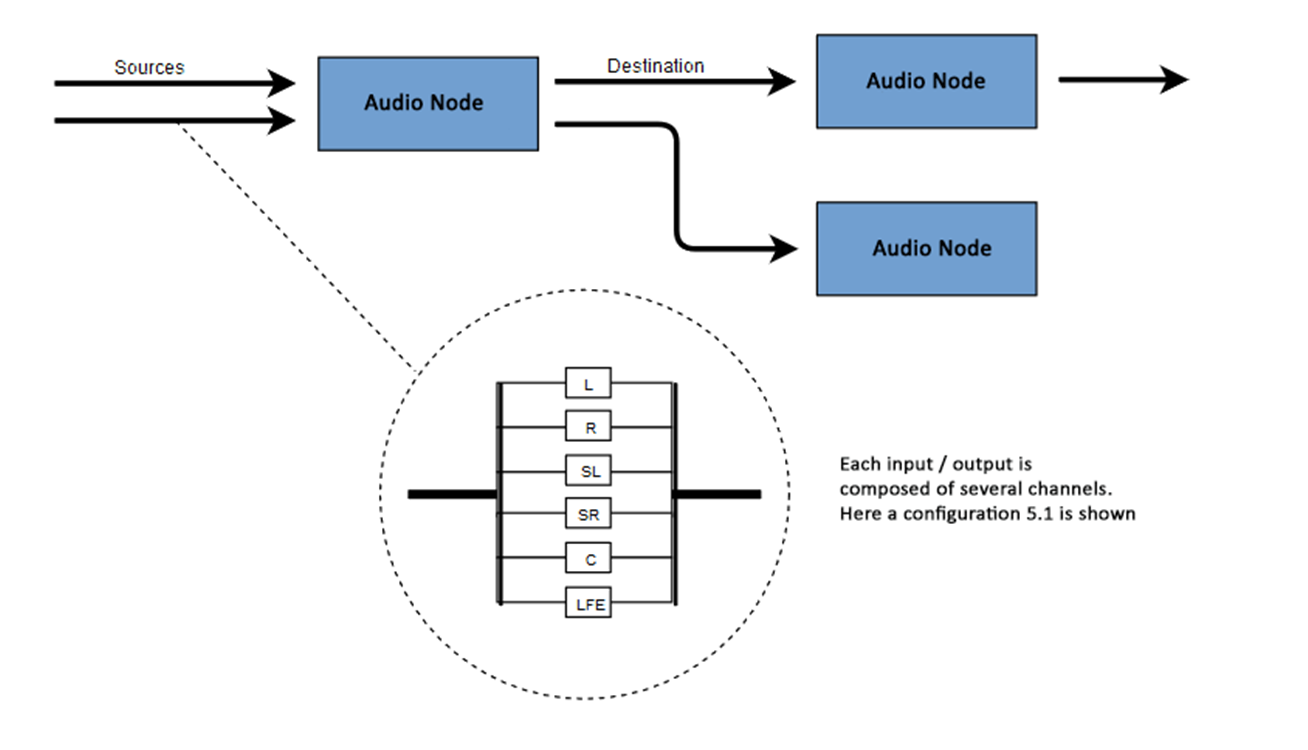 Sumber audio dapat diperoleh dengan berbagai cara. Suara itu mungkin:
Sumber audio dapat diperoleh dengan berbagai cara. Suara itu mungkin:- Dihasilkan oleh JavaScript melalui simpul audio (seperti osilator)
- Dibuat dari data mentah menggunakan PCM (Pulse Code Modulation)
- Berasal dari elemen media HTML (seperti <video> atau <audio>)
- Berasal dari aliran media WebRTC (seperti webcam atau mikrofon)
Data audio: apa yang ada dalam sampel
Pengambilan sampel berarti mengubah sinyal kontinu menjadi sinyal diskrit (terbagi) (analog ke digital). Dengan kata lain, gelombang suara terus menerus, seperti konser langsung, diubah menjadi urutan sampel, yang memungkinkan komputer memproses audio dalam blok yang terpisah.Buffer Audio: Bingkai, Sampel, dan Saluran
AudioBuffer menerima jumlah saluran sebagai parameter (1 untuk mono, 2 untuk stereo, dll.), Panjang - jumlah frame sampel di dalam buffer, dan frekuensi pengambilan sampel - jumlah frame per detik.Sampel adalah nilai titik-mengambang 32-bit sederhana (float32), yang merupakan nilai streaming audio pada titik waktu tertentu dan saluran tertentu (kiri atau kanan, dll.). Kerangka sampel atau bingkai adalah seperangkat nilai semua saluran yang direproduksi pada titik waktu tertentu: semua sampel dari semua saluran direproduksi pada waktu yang sama (dua untuk stereo, enam untuk 5.1, dll.).Laju sampling adalah jumlah sampel (atau bingkai, karena semua sampel dalam satu frame dimainkan pada satu waktu), diputar ulang dalam satu detik, diukur dalam hertz (Hz). Semakin tinggi frekuensinya, semakin baik kualitas suaranya.Mari kita lihat buffer mono dan stereo, masing-masing sepanjang satu detik, direproduksi pada frekuensi 44100 Hz:- Buffer Mono akan memiliki 44100 sampel dan 44100 bingkai. Nilai properti "panjang" adalah 44100
- Buffer stereo akan memiliki 88.200 sampel, tetapi juga 44.100 frame. Nilai properti "length" akan menjadi 44100 - panjangnya sama dengan jumlah bingkai
 Ketika pemutaran buffer dimulai, pertama-tama kita mendengar frame paling kiri dari sampel, kemudian frame kanan terdekat, dll. Dalam hal stereo, kami mendengar kedua saluran secara bersamaan. Frame sampel tidak tergantung pada jumlah saluran dan memberikan peluang untuk pemrosesan audio yang sangat akurat.Catatan: untuk mendapatkan waktu dalam hitungan detik dari jumlah frame, perlu untuk membagi jumlah frame dengan laju sampling. Untuk mendapatkan jumlah bingkai dari jumlah sampel, bagi yang terakhir dengan jumlah saluran.Contoh:
Ketika pemutaran buffer dimulai, pertama-tama kita mendengar frame paling kiri dari sampel, kemudian frame kanan terdekat, dll. Dalam hal stereo, kami mendengar kedua saluran secara bersamaan. Frame sampel tidak tergantung pada jumlah saluran dan memberikan peluang untuk pemrosesan audio yang sangat akurat.Catatan: untuk mendapatkan waktu dalam hitungan detik dari jumlah frame, perlu untuk membagi jumlah frame dengan laju sampling. Untuk mendapatkan jumlah bingkai dari jumlah sampel, bagi yang terakhir dengan jumlah saluran.Contoh:let context = new AudioContext()
let buffer = context.createBuffer(2, 22050, 44100)
Catatan: dalam audio digital, 44100 Hz atau 44,1 kHz adalah frekuensi sampling standar. Tapi mengapa 44,1 kHz?Pertama, karena rentang frekuensi yang dapat didengar (frekuensi yang dapat dibedakan oleh telinga manusia) bervariasi dari 20 hingga 20.000 Hz. Menurut teorema Kotelnikov, frekuensi sampling harus lebih dari dua kali lipat frekuensi tertinggi dalam spektrum sinyal. Oleh karena itu, frekuensi pengambilan sampel harus lebih besar dari 40 kHz.Kedua, sinyal harus disaring menggunakan filter low-pass.sebelum pengambilan sampel, jika tidak akan ada tumpang tindih "ekor" spektral (pertukaran frekuensi, penutupan frekuensi, alias) dan bentuk sinyal yang direkonstruksi akan terdistorsi. Idealnya, filter low-pass harus melewati frekuensi di bawah 20 kHz (tanpa redaman) dan menjatuhkan frekuensi di atas 20 kHz. Dalam prakteknya, beberapa pita transisi diperlukan (antara passband dan pita penekan), di mana frekuensi sebagian dilemahkan. Cara yang lebih mudah dan lebih ekonomis untuk melakukan ini adalah dengan menggunakan filter anti-perubahan. Untuk frekuensi sampling 44,1 kHz, pita transisi adalah 2,05 kHz.Pada contoh di atas, kita mendapatkan buffer stereo dengan dua saluran, direproduksi dalam konteks audio dengan frekuensi 44100 Hz (standar), panjang 0,5 detik (22050 frame / 44100 Hz = 0,5 s).let context = new AudioContext()
let buffer = context.createBuffer(1, 22050, 22050)
Dalam hal ini, kami mendapatkan buffer mono dengan satu saluran, direproduksi dalam konteks audio dengan frekuensi 44100 Hz, itu akan oversampling menjadi 44100 Hz (dan meningkatkan frame menjadi 44100), panjang 1 detik (44100 frame / 44100 Hz = 1 s).Catatan: Audio resampling ("resampling") sangat mirip dengan mengubah ukuran gambar ("resizing"). Misalkan kita memiliki gambar 16x16, tetapi kami ingin mengisi area ini dengan ukuran 32x32. Kami mengubah ukuran. Hasilnya akan kurang berkualitas (mungkin buram atau sobek tergantung pada algoritma zoom), tetapi itu berfungsi. Audio resampled adalah hal yang sama: kami menghemat ruang, tetapi dalam praktiknya tidak mungkin mencapai suara berkualitas tinggi.Planar dan Buffer Bergaris
WAA menggunakan format buffer planar. Saluran kiri dan kanan berinteraksi sebagai berikut:LLLLLLLLLLLLLLLLRRRRRRRRRRRRRRRR ( , 16 )
Dalam hal ini, setiap saluran bekerja secara independen dari yang lain.Alternatifnya adalah menggunakan format bergantian:LRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLR ( , 16 )
Format ini sering digunakan untuk decoding MP3.WAA hanya menggunakan format planar, karena lebih cocok untuk pemrosesan suara. Format planar dikonversi menjadi bergantian ketika data dikirim ke kartu suara untuk diputar. Ketika decoding MP3, kebalikannya dikonversi.Saluran audio
Buffer yang berbeda mengandung jumlah saluran yang berbeda: dari mono sederhana (satu saluran) dan stereo (saluran kiri dan kanan) ke perangkat yang lebih kompleks seperti quad dan 5.1 dengan jumlah sampel yang berbeda di setiap saluran, yang menghasilkan suara yang lebih kaya (lebih kaya). Saluran biasanya diwakili oleh singkatan:Mencampur dan mencampur
Ketika jumlah saluran pada input dan output tidak cocok, terapkan pencampuran naik atau turun. Pencampuran dikontrol oleh properti AudioNode.channelInterpretation:Visualisasi
Visualisasi didasarkan pada penerimaan data audio output, seperti data pada amplitudo atau frekuensi, dan pemrosesan selanjutnya menggunakan teknologi grafis apa pun. WAA memiliki AnalyzerNode yang tidak mengubah sinyal yang melewatinya. Pada saat yang sama, ia dapat mengekstrak data dari audio dan mentransfernya lebih lanjut, misalnya, ke & ltcanvas>.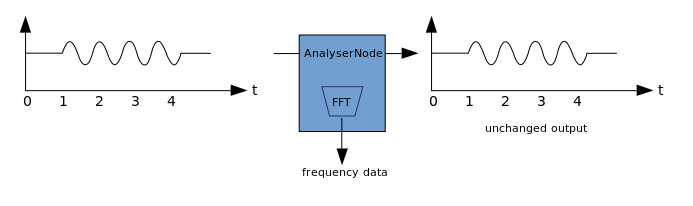 Metode berikut dapat digunakan untuk mengekstraksi data:
Metode berikut dapat digunakan untuk mengekstraksi data:- AnalyzerNode.getFloatByteFrequencyData () - menyalin data frekuensi saat ini ke Float32Array
- AnalyzerNode.getByteFrequencyData () - menyalin data frekuensi saat ini ke Uint8Array (array byte yang tidak ditandatangani)
- AnalyserNode.getFloatTimeDomainData() — Float32Array
- AnalyserNode.getByteTimeDomainData() — Uint8Array
Spasialisasi audio (diproses oleh PannerNode dan AudioListener) memungkinkan Anda untuk mensimulasikan posisi dan arah sinyal pada titik tertentu dalam ruang, serta posisi pendengar.Posisi panner dijelaskan menggunakan koordinat Cartesian tangan kanan; untuk gerakan, vektor kecepatan yang diperlukan untuk membuat efek Doppler digunakan , untuk arah, kerucut directivity digunakan. Kerucut ini bisa sangat besar dalam hal sumber suara multidirectional. Posisi pendengar dijelaskan sebagai berikut: gerakan - menggunakan vektor kecepatan, arah di mana kepala pendengar - menggunakan dua vektor directional, depan dan atas. Gertakan dilakukan ke bagian atas kepala dan hidung pendengar di sudut kanan.
Posisi pendengar dijelaskan sebagai berikut: gerakan - menggunakan vektor kecepatan, arah di mana kepala pendengar - menggunakan dua vektor directional, depan dan atas. Gertakan dilakukan ke bagian atas kepala dan hidung pendengar di sudut kanan.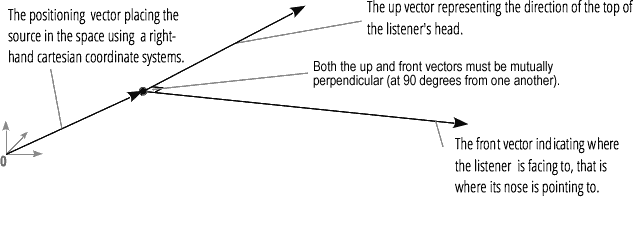
Persimpangan dan percabangan
Koneksi menggambarkan proses di mana ChannelMergerNode menerima beberapa sumber mono input dan menggabungkannya menjadi sinyal output multi-saluran tunggal.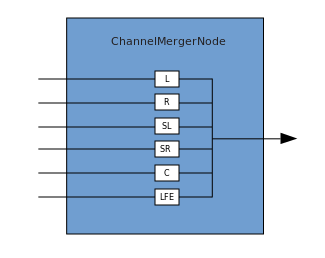 Percabangan adalah proses kebalikan (diimplementasikan melalui ChannelSplitterNode).
Percabangan adalah proses kebalikan (diimplementasikan melalui ChannelSplitterNode).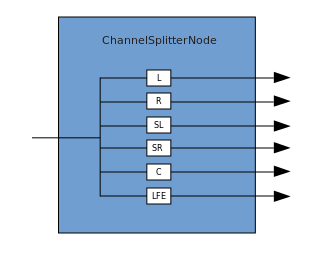 Contoh bekerja dengan WAA dapat ditemukan di sini . Kode sumber untuk contoh ada di sini . Inilah artikel tentang cara kerjanya.Terima kasih atas perhatian Anda.
Contoh bekerja dengan WAA dapat ditemukan di sini . Kode sumber untuk contoh ada di sini . Inilah artikel tentang cara kerjanya.Terima kasih atas perhatian Anda.