 Gambar yang Anda lihat diambil dari situs DeepMind dan menunjukkan 57 game di mana Agent57 pengembangan terbaru mereka ( review dari artikel tentang Habré ) telah mencapai kesuksesan. Angka 57 itu sendiri tidak diambil dari langit-langit - persis begitu banyak game yang dipilih kembali pada tahun 2012 untuk menjadi semacam patokan di antara para pengembang AI untuk game-game Atari, setelah itu berbagai peneliti mengukur pencapaian mereka pada dataset khusus ini.Dalam posting ini, saya akan mencoba melihat pencapaian ini dari sudut yang berbeda untuk menilai nilai mereka untuk tugas yang diterapkan, dan membenarkan mengapa saya tidak percaya bahwa ini adalah masa depan. Yah dan ya, akan ada banyak gambar di bawah potongan, saya memperingatkan.Di tautan di atas, pengembang menulis hal yang benar, mengatakan itu
Gambar yang Anda lihat diambil dari situs DeepMind dan menunjukkan 57 game di mana Agent57 pengembangan terbaru mereka ( review dari artikel tentang Habré ) telah mencapai kesuksesan. Angka 57 itu sendiri tidak diambil dari langit-langit - persis begitu banyak game yang dipilih kembali pada tahun 2012 untuk menjadi semacam patokan di antara para pengembang AI untuk game-game Atari, setelah itu berbagai peneliti mengukur pencapaian mereka pada dataset khusus ini.Dalam posting ini, saya akan mencoba melihat pencapaian ini dari sudut yang berbeda untuk menilai nilai mereka untuk tugas yang diterapkan, dan membenarkan mengapa saya tidak percaya bahwa ini adalah masa depan. Yah dan ya, akan ada banyak gambar di bawah potongan, saya memperingatkan.Di tautan di atas, pengembang menulis hal yang benar, mengatakan ituSo although average scores have increased, until now, the number of above human games has not. As an illustrative example, consider a benchmark consisting of twenty tasks. Suppose agent A obtains a score of 500% on eight tasks, 200% on four tasks, and 0% on eight tasks (mean = 240%, median = 200%), while agent B obtains a score of 150% on all tasks (mean = median = 150%). On average, agent A performs better than agent B. However, agent B possesses a more general ability: it obtains human-level performance on more tasks than agent A.
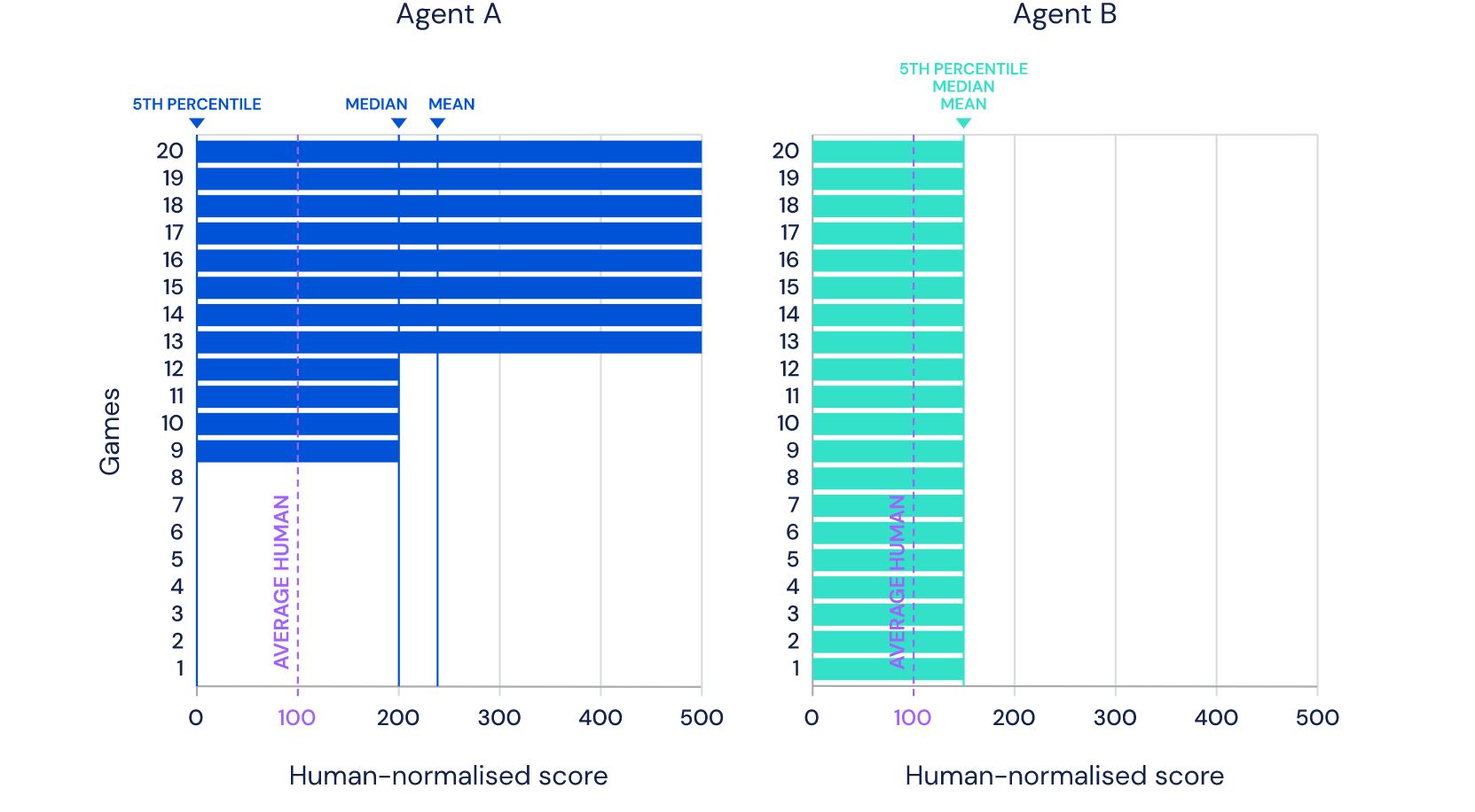 Yang dengan jari berarti bahwa sebelum semua orang diukur dalam kedudukan “rata-rata”, mengibaskan koper yang sulit untuk komputer, tetapi sekarang mereka baru memulainya. Dan dengan cara ini mereka mencapai keunggulan nyata atas manusia, dan bukan hasil super pada kasus ramah komputer.Tapi mari kita lihat masalahnya secara global untuk memahami apakah ini benar. Apa interaksi DeepMind AI dengan video gameTanda bintang selanjutnya akan menunjukkan entitas yang diperoleh dengan algoritma yang dibuat bukan dengan bantuan AI, tetapi dengan bantuan pendapat ahli.Sebelum membongkar sirkuit, mari kita lihat pendekatan alternatif:
Yang dengan jari berarti bahwa sebelum semua orang diukur dalam kedudukan “rata-rata”, mengibaskan koper yang sulit untuk komputer, tetapi sekarang mereka baru memulainya. Dan dengan cara ini mereka mencapai keunggulan nyata atas manusia, dan bukan hasil super pada kasus ramah komputer.Tapi mari kita lihat masalahnya secara global untuk memahami apakah ini benar. Apa interaksi DeepMind AI dengan video gameTanda bintang selanjutnya akan menunjukkan entitas yang diperoleh dengan algoritma yang dibuat bukan dengan bantuan AI, tetapi dengan bantuan pendapat ahli.Sebelum membongkar sirkuit, mari kita lihat pendekatan alternatif:Ringkasan Video- + ,

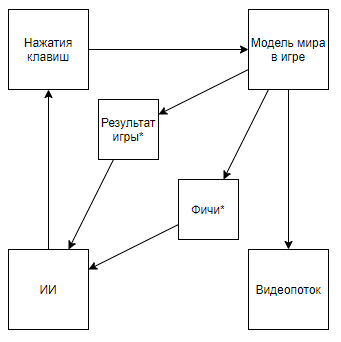 Skemanya menjadi seperti ini. Dan jika Anda naik di saluran penulis, Anda dapat menemukan aplikasinya ke game retro. Mengubah skema yang satu ini, kita sampai pada kesimpulan bahwa kecepatan dan efektifitas pelatihan meningkat berdasarkan urutan besarnya, tetapi nilai ilmiah dan rekayasa dari pencapaian perjalanan semacam itu mendekati 0 (dan ya, saya tidak memperhitungkan nilai popularisasi).Kita dapat mengasumsikan bahwa intinya adalah bahwa video dilemparkan dari pipa, tetapi pertimbangkan skema berikut (saya yakin seseorang menerapkan sesuatu yang serupa, tetapi tidak ada tautan di tangan):Yang diimplementasikan ketika seorang ahli yang mengetahui fitur-fitur yang diperlukan menulis parser aliran video yang menghitung fitur menggunakan piksel kunci.Atau bahkan skema semacam itu:Di mana pertama, AI1 dilatih untuk mengekstrak fitur yang dipilih oleh seorang ahli dari video.Dan kemudian AI2 diajarkan untuk bermain dengan fitur yang diekstrak dari aliran video menggunakan AI1. Jadi kami mendapat skema bahwa:
Skemanya menjadi seperti ini. Dan jika Anda naik di saluran penulis, Anda dapat menemukan aplikasinya ke game retro. Mengubah skema yang satu ini, kita sampai pada kesimpulan bahwa kecepatan dan efektifitas pelatihan meningkat berdasarkan urutan besarnya, tetapi nilai ilmiah dan rekayasa dari pencapaian perjalanan semacam itu mendekati 0 (dan ya, saya tidak memperhitungkan nilai popularisasi).Kita dapat mengasumsikan bahwa intinya adalah bahwa video dilemparkan dari pipa, tetapi pertimbangkan skema berikut (saya yakin seseorang menerapkan sesuatu yang serupa, tetapi tidak ada tautan di tangan):Yang diimplementasikan ketika seorang ahli yang mengetahui fitur-fitur yang diperlukan menulis parser aliran video yang menghitung fitur menggunakan piksel kunci.Atau bahkan skema semacam itu:Di mana pertama, AI1 dilatih untuk mengekstrak fitur yang dipilih oleh seorang ahli dari video.Dan kemudian AI2 diajarkan untuk bermain dengan fitur yang diekstrak dari aliran video menggunakan AI1. Jadi kami mendapat skema bahwa:- Menggunakan aliran video, dan tidak memiliki akses langsung ke model dunia.
- Tidak mengandalkan parser aliran video yang ditulis oleh seorang ahli
- Ini akan dilatih pada waktu yang lebih mudah dan lebih efisien daripada pengembangan DeepMind
Tapi ... kita sampai pada hal yang sama. Implementasi seperti itu, sekali lagi, tidak akan memiliki nilai ilmiah atau rekayasa dalam konteks aplikasi untuk game retro, karena AI1 adalah tugas yang sudah lama diselesaikan dan sangat primitif untuk algoritma pemrosesan gambar modern, dan AI2 juga dibuat dengan sangat cepat dan sederhana, yang mengonfirmasi pembuat video di atas .Jadi, apa nilai algoritma DeepMind untuk game Atari? Saya akan mencoba merangkum: nilainyaAlgoritma DeepMind dapat menemukan strategi perilaku optimal untuk game dengan model primitif dunia MM dalam kondisi ketika keadaan model dunia S (MM, t) diwakili dengan distorsi signifikan oleh fungsi distorsi tertentu F (S (MM, t)), hanya kualitas keputusan yang dibuat dapat dievaluasi sebuah fungsi yang menerima urutan nilai F (S (MM, t)) dan reaksi algoritma, dan urutan ini memiliki panjang yang tidak diketahui (permainan dapat berakhir dalam jumlah langkah yang berbeda), tetapi Anda dapat mengulangi percobaan dalam jumlah tak terbatas beberapa kali .Mengantisipasi masalah, . S(MM, t) , , . F(S(MM, t)) , .
Sekarang mari kita coba untuk mengevaluasi penerapan nilai seperti itu untuk memecahkan masalah dunia nyata yang entah bagaimana berkorelasi dengan alat, yaitu, mereka mewakili keadaan nyata dengan distorsi yang signifikan, menyiratkan bahwa lingkungan merespon tindakan agen, memberikan penilaian hanya setelah urutan keputusan yang panjang, dan Namun, mereka memungkinkan percobaan dilakukan berkali-kali.Sekilas, aplikasi yang menarik sepertinya adalah game yang dipertukarkan. Bahkan petunjuk Google, mengkhianati itu sebagai satu-satunya petunjuk dengan penggunaan di dunia nyata, mengisyaratkan bahwa topiknya panas.Saya akan segera menunjukkan poin penting - hampir semua pendekatan untuk analisis pasar (tidak termasuk pendekatan yang menganalisis objek dunia nyata, seperti tempat parkir di depan supermarket, berita, sebutan saham di Twitter) dapat dibagi menjadi dua jenis. Tipe pertama adalah pendekatan yang mewakili pasar sebagai rangkaian waktu. Kedua, sebagai aliran aplikasi.Entah bagaimana para pendukung pendekatan tipe pertama melihat pasar Tetapi perbedaan mendasar bukan pada data yang digunakan, tetapi pada kenyataan bahwa, sebagai suatu peraturan, mereka yang menganalisis pasar, sebagai rangkaian waktu, mengabaikan pengaruh mereka terhadap pasar, percaya bahwa, secara kondisional, pada interval harian, transaksi mereka tidak akan mempengaruhi dinamika pasar lebih lanjut. Sementara para pendukung pendekatan kedua dapat mengabaikan, percaya bahwa volumenya tidak signifikan dalam kaitannya dengan likuiditas pasar, dan menganggap pasar sebagai sistem umpan balik, percaya bahwa tindakan mereka mempengaruhi perilaku pemain lain (misalnya, studi dan pendekatan yang terkait dengan pelaksanaan optimal pesanan besar, pembuatan pasar, perdagangan frekuensi tinggi).Setelah melihat melalui hasil pencarian, jelas bahwa semua artikel dan posting yang ditujukan untuk perdagangan menggunakan pelatihan penguatan (topik terdekat dengan keberhasilan DeepMind) dikhususkan untuk pendekatan pertama. Tetapi muncul pertanyaan yang masuk akal tentang proporsionalitas pendekatan terhadap masalah tersebut.Pertama, mari kita menggambar diagram yang mirip dengan game Atari.Realitas objektif, . , , , , — . , , . , , , , , . , .
Tampaknya semuanya jatuh dengan indah. Dan, saya curiga bahwa kesamaan ini juga menghangatkan hype. Tapi, bagaimana jika kita sedikit memperjelas skema: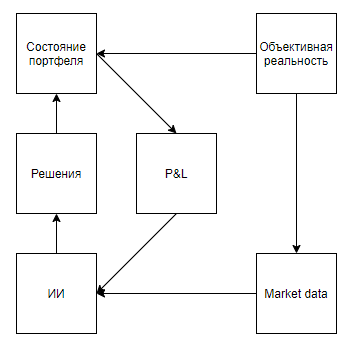
Mengantisipasi pertanyaan sampel yang diproduksi sendiri, , , . , , . , , . , , , , , .
Pendekatan kedua (dengan aliran aplikasi) terlihat lebih menjanjikan. Kaca yang disebutsering diisi dengan aplikasi robot yang memburu sebagian kecil dari harga, bersaing di tempat dalam antrian, dan sering membuat aplikasi hanya untuk membuat permintaan atau pasokan muncul, dan memprovokasi bot lain untuk tindakan yang tidak menguntungkan. Tampaknya, jika Anda bermimpi, bahwa jika Anda membuat emulator pertukaran dan menempatkan bot HFT di dalamnya, yang, dengan mengambil miliaran keputusan, akan belajar sendiri, bermain dengan klon sendiri, dan dengan demikian mengembangkan strategi ideal yang akan memperhitungkan semua strategi kontra yang optimal ... Sangat disayangkan bahwa jika sesuatu seperti ini terjadi, maka sekitar 5 orang di seluruh dunia akan mengetahuinya - prinsip-prinsip bisnis dari pedagang frekuensi tinggi menyiratkan kerahasiaan absolut, dan menolak untuk mempublikasikan hasil yang tidak berhasil bahkan untuk memberi kesempatan pada musuh untuk melangkah pada penggaruk yang sama.Saya pikir itu terutama tidak layak berfokus pada ketidakmungkinan menerapkan pendekatan seperti itu dalam pemasaran, SDM, penjualan, manajemen dan area lain di mana objeknya adalah seseorang, karena untuk aplikasi yang benar diperlukan untuk memungkinkan AI membuat jutaan, atau bahkan milyaran eksperimen. Dan, bahkan jika banyak perusahaan memiliki sejuta interaksi dengan objek di mana AI dapat membuat keputusan (memilih spanduk untuk ditampilkan kepada klien potensial berdasarkan profilnya, keputusan untuk memecat karyawan), maka tidak ada yang akan mendapatkan sejuta eksperimen dengan hal yang sama objek, yang persis apa yang diperlukan untuk aplikasi berkualitas tinggi. Tetapi yang layak untuk difokuskan adalah antifraud dan cybersecurity.Saya tidak tahu, untungnya atau sayangnya, tetapi di dunia modern sangat banyak hubungan ekonomi didasarkan pada pemberian nilai kecil tanpa kewajiban dengan imbalan mengharapkan nilai besar di masa depan, yang memunculkan banyak sumber freebie dan potensi penipuan.Contoh:- Perjalanan gratis pertama dalam agregator taksi
- Pembayaran $ 70 untuk BPA dalam perjudian, untuk pemain yang membawa $ 5
- Tes $ 300 dari penyedia cloud dan periode uji coba
Selain itu, potensi penipuan dari sistem ekonomi modern didukung oleh tingkat perlindungan yang rendah untuk transaksi kartu kredit, karena pedagang sering dengan sengaja menolak keamanan 3D yang sama untuk menyederhanakan pengalaman pengguna. Jadi, untuk pembeli kartu curian dengan% kecil dari saldo mereka, daftar ini dapat ditambahkan hampir tanpa batas.Masalah utama dalam perang melawan kasus-kasus semacam itu terletak pada ketidakmampuan untuk mengumpulkan dataset dari volume yang cukup -% operasi penipuan adalah 1-6 urutan besarnya lebih rendah dari persentase operasi yang baik tergantung pada bisnis. Ada juga masalah dalam fleksibilitas pengawas, yang dengan mudah memotong algoritma statis, beradaptasi dengan sistem antifraud yang telah dilatih pada pengalaman masa lalu.Dan, sepertinya, ini dia. Algoritma seperti Agent57 yang diluncurkan di kotak pasir akan memungkinkan Anda untuk membuat penipu yang ideal, terus-menerus memperbarui keterampilannya, dan pada saat yang sama menyelesaikan masalah terbalik - menjaga algoritma untuk mengidentifikasinya. Tapi ada satu peringatan. Menang melawan model dunia yang tertanam dalam permainan Atari sama sekali tidak sama dengan menang dari sistem antifraud yang sudah dilatih berdasarkan perilaku jutaan pemain, dan banyak tindakan dengan penipuan tidak proporsional dengan banyak aksi pemain dalam permainan retro. Misalnya, bahkan tindakan sederhana seperti memasukkan login pada formulir pendaftaran sudah membawa miliaran opsi untuk melakukan ini. Mulai dari agen pengguna mana yang ditransfer ke server, dan diakhiri dengan berapa milidetik untuk menunggu antara memasukkan karakter login kedua dan ketiga ...Secara umum, saya melihat semuanya entah bagaimana. Cukup suram. Dan saya sangat berharap bahwa saya salah, dan di suatu tempat saya tidak memperhitungkan sesuatu dalam model. Saya akan berterima kasih jika saya melihat contoh tandingan di komentar.