Halo Khabrovites, dalam contoh kecil ini saya ingin menunjukkan bagaimana Anda dapat menguraikan halaman, data yang dimuat menggunakan widget javascript. Selain itu, bahkan jika halaman dalam contoh ini mudah disimpan, Anda masih tidak dapat menguraikan semua foto yang diperlukan darinya karena widget ini. Dalam hal ini, saya menggunakan cian.ru sebagai contoh , yang memiliki api sendiri , yang tidak akan saya gunakan, sebagai gantinya saya akan menggunakan Selenium. Saya tidak bekerja di cian.ru, saya hanya menggunakan situs ini sebagai contoh. Kode dalam parser sederhana dan dirancang untuk pemula.
Pengantar singkat - ketika di waktu senggang saya melihat contoh-contoh perbaikan di cian.ru, saya pikir akan lebih baik untuk menyimpan foto yang saya sukai, tetapi secara manual menyimpannya akan lama, selain ini bukan metode kami, jadi saya memutuskan untuk menulis ini pengurai.
Parser ditulis dalam python3 dari distribusi Anaconda , Selenium dan chromedriver binary, saya instal secara terpisah dari tautan ini. (Dan tentu saja, browser Google Chrome harus diinstal pada sistem )
Di bawah ini adalah kode parser lengkap, maka saya akan menganalisis poin utama secara terpisah.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
import chromedriver_binary
import urllib
import time
print('start...')
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
i = 0
while True:
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
i += 1
print(i, url)
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
time.sleep(2)
print('done.')
https://www.cian.ru/sale/flat/222059642/ . driver get. , Headless Chrome, .. webdriver.Chrome() --headless, , , chrome_options , .
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
, , , .. "next".
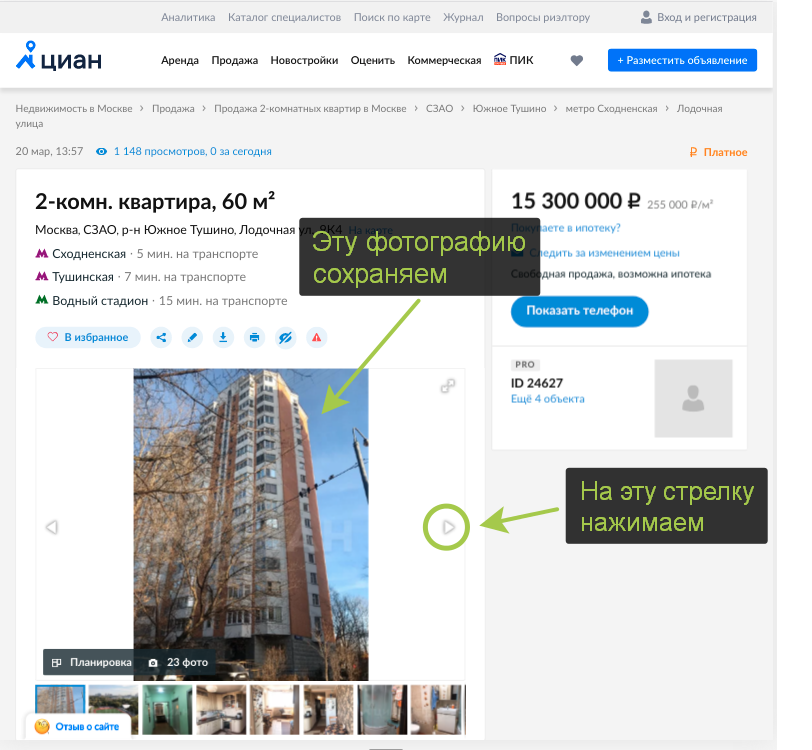
url , try/except NoSuchElementException, , Selenium .
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
.
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
urllib.
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
, . ( Selenium)
time.sleep(2)
Selenium, , , - .
.