Halo, habrozhiteli! Sementara berita kami dicetak di percetakan dan kantor di tempat yang terpencil, kami memutuskan untuk berbagi kutipan dari buku Paul dan Harvey Daytel "Python: Intelegensi Buatan, Big Data dan Cloud Computing"Studi Kasus: Pembelajaran Mesin Tanpa Guru, Bagian 2 - K Klaster Rata-rata
Pada bagian ini, mungkin yang paling sederhana dari algoritma pembelajaran mesin tanpa guru akan disajikan - pengelompokan menggunakan metode k rata-rata. Algoritma ini menganalisis sampel yang tidak berlabel dan mencoba menggabungkannya menjadi kelompok. Mari kita jelaskan bahwa k dalam metode “k means” merepresentasikan jumlah cluster di mana data seharusnya dipecah.Algoritma mendistribusikan sampel ke sejumlah cluster yang telah ditentukan menggunakan metrik jarak yang mirip dengan algoritma pengelompokan k tetangga terdekat. Setiap cluster dikelompokkan sekitar centroid - titik pusat cluster. Awalnya, algoritma memilih k centroid acak dari antara kumpulan data sampel, setelah itu sampel yang tersisa didistribusikan di antara cluster dengan centroid terdekat. Selanjutnya, rekalulasi ulang sentroid dilakukan, dan sampel didistribusikan kembali di antara cluster, sampai untuk semua cluster jarak dari centroid yang diberikan ke sampel yang termasuk dalam cluster diminimalkan. Sebagai hasil dari algoritma, array satu dimensi label dibuat yang menunjuk cluster tempat masing-masing sampel, serta array dua dimensi centroid yang mewakili pusat masing-masing cluster.Iris Dataset
Kami akan bekerja dengan dataset Iris populer yang disertakan dengan scikit-learn. Himpunan ini sering dianalisis selama klasifikasi dan pengelompokan. Meskipun dataset diberi label, kami tidak akan menggunakan label ini untuk menunjukkan pengelompokan. Label kemudian akan digunakan untuk menentukan seberapa baik algoritma k-average mengelompokkan sampel.Dataset Iris adalah dataset mainan karena hanya terdiri dari 150 sampel dan empat atribut. Set data menggambarkan 50 sampel dari tiga jenis bunga iris - Iris setosa, Iris versicolor dan Iris virginica (lihat foto di bawah). Karakteristik sampel: panjang lobus perianth luar (panjang sepal), lebar lobus perianth luar (lebar sepal), panjang lobus perianth bagian dalam (panjang petal) dan lebar lobus perianth bagian dalam (lebar kelopak), diukur dalam sentimeter.14.7.1. Unduh Iris Dataset
Mulai IPython dengan perintah ipython --matplotlib, kemudian gunakan fungsi load_iris dari modul sklearn.datasets untuk mendapatkan objek Bunch dengan kumpulan data:In [1]: from sklearn.datasets import load_iris
In [2]: iris = load_iris()
Atribut DESCR dari objek Bunch menunjukkan bahwa kumpulan data terdiri dari 150 Jumlah Contoh contoh, masing-masing memiliki empat Jumlah Atribut. Tidak ada nilai yang hilang dalam dataset. Sampel diklasifikasikan dengan bilangan bulat 0, 1, dan 2, masing-masing mewakili Iris setosa, Iris versicolor, dan Iris virginica. Kami mengabaikan label dan mempercayakan penentuan kelas sampel ke algoritma pengelompokan menggunakan metode k means. Informasi DESCR utama dicetak tebal:In [3]: print(iris.DESCR)
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
...
Memeriksa jumlah sampel, fitur, dan nilai target
Jumlah pola dan atribut dapat ditemukan dalam atribut bentuk array data, dan jumlah nilai target dapat ditemukan dalam atribut bentuk array target:In [4]: iris.data.shape
Out[4]: (150, 4)
In [5]: iris.target.shape
Out[5]: (150,)
Nama target array mengandung nama-nama label numerik dari array. Target ekspresi - dtype = '<U10' berarti bahwa elemen-elemennya adalah string dengan panjang maksimum 10 karakter:In [6]: iris.target_names
Out[6]: array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
Array feature_names berisi daftar nama string untuk setiap kolom dalam array data:In [7]: iris.feature_names
Out[7]:
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
14.7.2. Iris Dataset Research: Statistik Deskriptif di Pandas
Kami menggunakan koleksi DataFrame untuk memeriksa dataset Iris. Seperti halnya dataset Perumahan California, kami menetapkan parameter panda untuk memformat output kolom:In [8]: import pandas as pd
In [9]: pd.set_option('max_columns', 5)
In [10]: pd.set_option('display.width', None)
Buat koleksi DataFrame dengan konten array data, menggunakan konten array fitur_names sebagai nama kolom:In [11]: iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
Kemudian tambahkan kolom dengan nama tampilan untuk masing-masing sampel. Transformasi daftar dalam cuplikan berikut menggunakan setiap nilai dalam larik target untuk mencari nama yang sesuai di larik target_names:In [12]: iris_df['species'] = [iris.target_names[i] for i in iris.target]
Kami akan menggunakan panda untuk mengidentifikasi beberapa sampel. Seperti sebelumnya, jika panda menghasilkan \ di sebelah kanan nama kolom, ini berarti bahwa kolom yang akan ditampilkan di bawah tetap dalam output:In [13]: iris_df.head()
Out[13]:
sepal length (cm) sepal width (cm) petal length (cm) \
0 5.1 3.5 1.4
1 4.9 3.0 1.4
2 4.7 3.2 1.3
3 4.6 3.1 1.5
4 5.0 3.6 1.4
petal width (cm) species
0 0.2 setosa
1 0.2 setosa
2 0.2 setosa
3 0.2 setosa
4 0.2 setosa
Kami menghitung beberapa indikator statistik deskriptif untuk kolom numerik:In [14]: pd.set_option('precision', 2)
In [15]: iris_df.describe()
Out[15]:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
count 150.00 150.00 150.00 150.00
mean 5.84 3.06 3.76 1.20
std 0.83 0.44 1.77 0.76
min 4.30 2.00 1.00 0.10
25% 5.10 2.80 1.60 0.30
50% 5.80 3.00 4.35 1.30
75% 6.40 3.30 5.10 1.80
max 7.90 4.40 6.90 2.50
Memanggil metode uraikan pada kolom 'spesies' menegaskan bahwa itu berisi tiga nilai unik. Kita tahu sebelumnya bahwa data terdiri dari tiga kelas, yang termasuk sampel, meskipun dalam pembelajaran mesin tanpa guru hal ini tidak selalu terjadi.In [16]: iris_df['species'].describe()
Out[16]:
count 150
unique 3
top setosa
freq 50
Name: species, dtype: object
14.7.3. Visualisasi dataset Pairplot
Kami akan memvisualisasikan karakteristik dalam kumpulan data ini. Salah satu cara untuk mengekstrak informasi tentang data Anda adalah untuk melihat bagaimana atribut terkait satu sama lain. Dataset memiliki empat atribut. Kami tidak akan dapat membuat diagram korespondensi satu atribut dengan tiga lainnya dalam satu diagram. Namun demikian, adalah mungkin untuk membuat diagram di mana korespondensi antara kedua fitur akan disajikan. Fragment [20] menggunakan fungsi pairplot dari perpustakaan Seaborn untuk membuat tabel diagram di mana setiap fitur dipetakan ke salah satu fitur lainnya:In [17]: import seaborn as sns
In [18]: sns.set(font_scale=1.1)
In [19]: sns.set_style('whitegrid')
In [20]: grid = sns.pairplot(data=iris_df, vars=iris_df.columns[0:4],
...: hue='species')
...:
Argumen kunci:- koleksi DataFrame dengan dataset yang diplot pada bagan;
- vars - urutan dengan nama variabel yang diplot pada bagan. Untuk koleksi DataFrame, itu berisi nama kolom. Dalam hal ini, empat kolom pertama dari DataFrame digunakan, mewakili panjang (lebar) dari perianth luar dan panjang (lebar) dari perianth dalam, masing-masing;
- hue adalah kolom koleksi DataFrame yang digunakan untuk menentukan warna data yang diplot pada bagan. Dalam hal ini, data diwarnai tergantung pada jenis iris.
Panggilan pairplot sebelumnya membangun tabel diagram 4 × 4 berikut: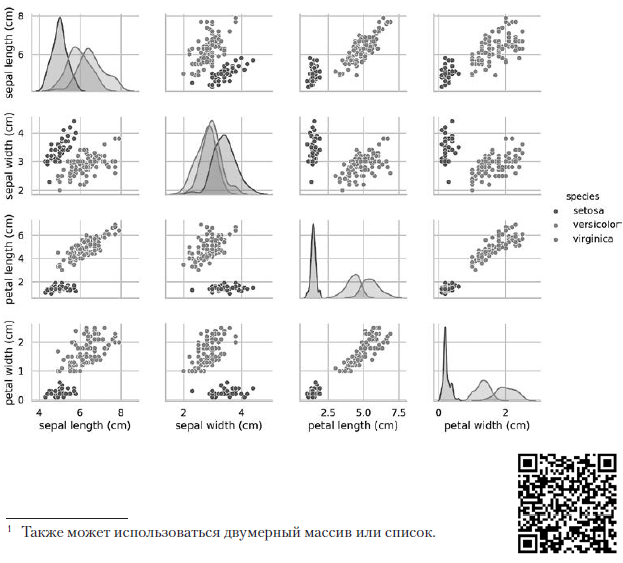 Diagram pada diagonal yang mengarah dari kiri atas ke sudut kanan bawah menunjukkan distribusi atribut yang ditampilkan dalam kolom ini dengan rentang nilai (dari kiri ke kanan) dan jumlah sampel dengan nilai-nilai ini (dari atas ke bawah) . Ambil distribusi panjang perianth luar:
Diagram pada diagonal yang mengarah dari kiri atas ke sudut kanan bawah menunjukkan distribusi atribut yang ditampilkan dalam kolom ini dengan rentang nilai (dari kiri ke kanan) dan jumlah sampel dengan nilai-nilai ini (dari atas ke bawah) . Ambil distribusi panjang perianth luar: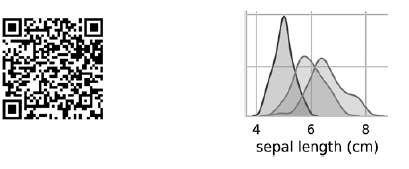 Daerah teduh tertinggi menunjukkan bahwa kisaran panjang lobus perianth luar (sepanjang sumbu x) untuk spesies Iris setosa adalah sekitar 4-6 cm, dan untuk sebagian besar sampel Iris setosa, nilainya terletak di tengah kisaran ini (sekitar 5 cm). Daerah yang diarsir paling kanan menunjukkan bahwa kisaran panjang lobus perianth luar (sepanjang sumbu x) untuk spesies Iris virginica adalah sekitar 4-8,5 cm, dan untuk sebagian besar sampel Iris virginica, nilainya antara 6 dan 7 cm.Di diagram lain, kolom menyajikan diagram sebaran data dengan karakteristik lain relatif terhadap karakteristik sepanjang sumbu x. Pada kolom pertama, dalam tiga diagram pertama, sumbu y menunjukkan lebar perianth luar, panjang perianth bagian dalam, dan lebar perianth bagian dalam, dan sumbu x menunjukkan panjang perianth bagian luar.Ketika kode ini dieksekusi, gambar berwarna muncul di layar, menunjukkan hubungan antara berbagai jenis iris pada tingkat karakter individu. Menariknya, dalam semua diagram, titik-titik biru Iris setosa jelas terpisah dari titik-titik oranye dan hijau dari spesies lain; ini menunjukkan bahwa Iris setosa memang kelas yang terpisah. Anda juga dapat memperhatikan bahwa dua spesies lainnya kadang-kadang bisa bingung, seperti yang ditunjukkan oleh titik-titik oranye dan hijau yang tumpang tindih. Sebagai contoh, diagram lebar dan panjang lobus perianth bagian luar menunjukkan bahwa titik Iris versicolor dan Iris virginica bercampur. Ini menunjukkan bahwa jika hanya pengukuran lobus perianth luar yang tersedia, maka akan sulit untuk membedakan antara kedua spesies ini.
Daerah teduh tertinggi menunjukkan bahwa kisaran panjang lobus perianth luar (sepanjang sumbu x) untuk spesies Iris setosa adalah sekitar 4-6 cm, dan untuk sebagian besar sampel Iris setosa, nilainya terletak di tengah kisaran ini (sekitar 5 cm). Daerah yang diarsir paling kanan menunjukkan bahwa kisaran panjang lobus perianth luar (sepanjang sumbu x) untuk spesies Iris virginica adalah sekitar 4-8,5 cm, dan untuk sebagian besar sampel Iris virginica, nilainya antara 6 dan 7 cm.Di diagram lain, kolom menyajikan diagram sebaran data dengan karakteristik lain relatif terhadap karakteristik sepanjang sumbu x. Pada kolom pertama, dalam tiga diagram pertama, sumbu y menunjukkan lebar perianth luar, panjang perianth bagian dalam, dan lebar perianth bagian dalam, dan sumbu x menunjukkan panjang perianth bagian luar.Ketika kode ini dieksekusi, gambar berwarna muncul di layar, menunjukkan hubungan antara berbagai jenis iris pada tingkat karakter individu. Menariknya, dalam semua diagram, titik-titik biru Iris setosa jelas terpisah dari titik-titik oranye dan hijau dari spesies lain; ini menunjukkan bahwa Iris setosa memang kelas yang terpisah. Anda juga dapat memperhatikan bahwa dua spesies lainnya kadang-kadang bisa bingung, seperti yang ditunjukkan oleh titik-titik oranye dan hijau yang tumpang tindih. Sebagai contoh, diagram lebar dan panjang lobus perianth bagian luar menunjukkan bahwa titik Iris versicolor dan Iris virginica bercampur. Ini menunjukkan bahwa jika hanya pengukuran lobus perianth luar yang tersedia, maka akan sulit untuk membedakan antara kedua spesies ini.Output pairplot menghasilkan satu warna
Jika Anda menghapus argumen kunci hue, maka fungsi pairplot hanya menggunakan satu warna untuk menampilkan semua data, karena tidak tahu bagaimana membedakan antara tampilan dalam output:In [21]: grid = sns.pairplot(data=iris_df, vars=iris_df.columns[0:4])
Seperti dapat dilihat dari diagram berikut, dalam hal ini, diagram pada diagonal adalah histogram dengan distribusi semua nilai atribut ini, apa pun jenisnya. Saat mempelajari diagram, sepertinya hanya ada dua kelompok, meskipun kita tahu bahwa kumpulan data berisi tiga jenis. Jika jumlah cluster tidak diketahui sebelumnya, maka Anda dapat menghubungi seorang pakar di bidang subjek yang sangat mengenal data tersebut. Seorang ahli mungkin tahu bahwa ada tiga jenis data dalam dataset; informasi ini dapat berguna ketika melakukan pembelajaran mesin dengan data.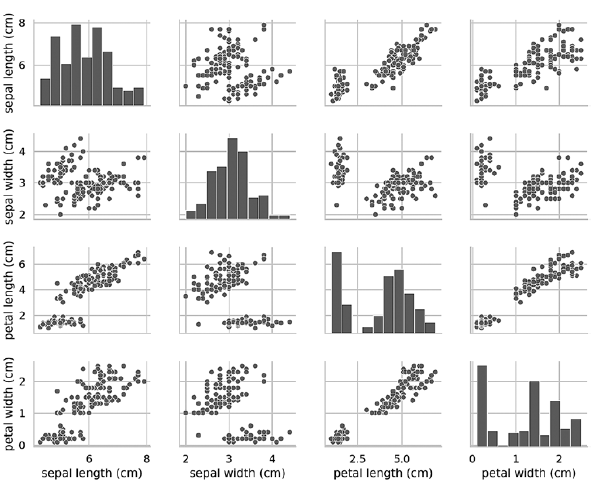 Diagram Pairplot bekerja dengan baik dengan sejumlah kecil fitur atau sejumlah fitur sehingga jumlah baris dan kolom terbatas, dan dengan sejumlah pola yang relatif kecil sehingga titik data dapat terlihat. Ketika jumlah fitur dan pola bertambah, diagram pencar data menjadi terlalu kecil untuk membaca data. Dalam kumpulan data besar, Anda dapat memplot subset fitur pada bagan dan, secara opsional, subset pola yang dipilih secara acak untuk mendapatkan beberapa gagasan tentang data.»Informasi lebih lanjut tentang buku dapat ditemukan dan dibeli di situs web
Diagram Pairplot bekerja dengan baik dengan sejumlah kecil fitur atau sejumlah fitur sehingga jumlah baris dan kolom terbatas, dan dengan sejumlah pola yang relatif kecil sehingga titik data dapat terlihat. Ketika jumlah fitur dan pola bertambah, diagram pencar data menjadi terlalu kecil untuk membaca data. Dalam kumpulan data besar, Anda dapat memplot subset fitur pada bagan dan, secara opsional, subset pola yang dipilih secara acak untuk mendapatkan beberapa gagasan tentang data.»Informasi lebih lanjut tentang buku dapat ditemukan dan dibeli di situs web