Sekarang pemrograman menembus lebih dalam dan lebih dalam ke semua bidang kehidupan. Dan mungkin itu menjadi berkat python yang sangat populer sekarang. Jika 5 tahun yang lalu, untuk analisis data, Anda harus menggunakan seluruh paket berbagai alat: C # untuk membongkar (atau pena), Excel, MatLab, SQL, dan terus-menerus "melompat" ke sana, membersihkan, memeriksa, dan merekonsiliasi data. Sekarang python, berkat sejumlah besar pustaka dan modul yang sangat baik, pada pendekatan pertama dengan aman menggantikan semua alat ini, dan dalam hubungannya dengan SQL, secara umum, "pegunungan dapat digulung".Jadi apa yang saya lakukan. Saya menjadi tertarik untuk mempelajari python yang begitu populer. Dan cara terbaik untuk mempelajari sesuatu, seperti yang Anda tahu, adalah berlatih. Dan saya juga tertarik pada real estat. Dan saya menemukan masalah yang menarik tentang real estat di Moskow: untuk memberi peringkat distrik Moskow dengan biaya sewa rata-rata dari odnushka rata-rata? Ayah, saya pikir, di sini Anda memiliki geolokasi, dan mengunggah dari situs, dan analisis data - tugas praktis yang hebat.Terinspirasi oleh artikel-artikel indah di Habré (di akhir artikel saya akan menambahkan tautan), mari kita mulai!Tugas kita adalah untuk pergi melalui alat yang ada di dalam python, membongkar teknik - cara mengatasi masalah seperti itu dan menghabiskan waktu dengan senang hati, dan tidak hanya dengan manfaat.- Menggores Cyan
- Bingkai data tunggal
- Pemrosesan bingkai data
- hasil
- Sedikit tentang bekerja dengan geodata
Menggores Cyan
Pada pertengahan Maret 2020, adalah mungkin untuk mengumpulkan hampir 9 ribu proposal untuk menyewa apartemen 1 kamar di Moskow di cyan, situs ini menampilkan 54 halaman. Kami akan bekerja dengan jupyter-notebook 6.0.1, python 3.7. Kami mengunggah data dari situs dan menyimpannya ke file menggunakan pustaka permintaan .Agar situs tidak mencekal kami, kami akan menyamar sebagai orang dengan menambahkan penundaan permintaan dan mengatur tajuk sehingga dari sisi situs kami terlihat seperti orang yang sangat pintar membuat permintaan melalui browser. Jangan lupa untuk memeriksa respons dari situs setiap kali, kalau tidak kita tiba-tiba ditemukan dan sudah dilarang. Anda dapat membaca lebih banyak dan lebih rinci tentang pengikisan situs web, misalnya, di sini: Menggores Web menggunakan python .Lebih nyaman menambahkan dekorator untuk mengevaluasi kecepatan fungsi dan pencatatan kami. Pengaturan level = logging.INFO memungkinkan Anda menentukan jenis pesan yang ditampilkan dalam log. Anda juga dapat mengkonfigurasi modul untuk mengeluarkan log ke file teks, bagi kami ini tidak perlu.Kodedef timer(f):
def wrap_timer(*args, **kwargs):
start = time.time()
result = f(*args, **kwargs)
delta = time.time() - start
print (f' {f.__name__} {delta} ')
return result
return wrap_timer
def log(f):
def wrap_log(*args, **kwargs):
logging.info(f" {f.__doc__}")
result = f(*args, **kwargs)
logging.info(f": {result}")
return result
return wrap_log
logging.basicConfig(level=logging.INFO)
@timer
@log
def requests_site(N):
headers = ({'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15'})
pages = [106 + i for i in range(N)]
n = 0
for i in pages:
s = f"https://www.cian.ru/cat.php?deal_type=rent&engine_version=2&page={i}&offer_type=flat®ion=1&room1=1&type=-2"
response = requests.get(s, headers = headers)
if response.status_code == 200:
name = f'sheets/sheet_{i}.txt'
with open(name, 'w') as f:
f.write(response.text)
n += 1
logging.info(f" {i}")
else:
print(f" {i} response.status_code = {response.status_code}")
time.sleep(np.random.randint(7,13))
return f" {n} "
requests_site(300)
Bingkai data tunggal
Untuk memo halaman, pilih BeautifulSoup dan lxml . Kami menggunakan "sup yang indah" hanya untuk namanya yang keren, meskipun, mereka mengatakan bahwa lxml lebih cepat.Anda dapat melakukannya dengan indah, mengambil daftar file dari folder menggunakan os library , memfilter ekstensi yang kita butuhkan dan menjelajahinya. Tapi kami akan membuatnya lebih mudah, karena kami tahu jumlah file dan nama persisnya. Kecuali kami menambahkan dekorasi dalam bentuk progress bar, menggunakan perpustakaan tqdmKode
from bs4 import BeautifulSoup
import re
import pandas as pd
from dateutil.parser import parse
from datetime import datetime, date, time
def read_file(filename):
with open(filename) as input_file:
text = input_file.read()
return text
import tqdm
site_texts = []
pages = [1 + i for i in range(309)]
for i in tqdm.tqdm(pages):
name = f'sheets/sheet_{i}.txt'
site_texts.append(read_file(name))
print(f" {len(site_texts)} .")
def parse_tag(tag, tag_value, item):
key = tag
value = "None"
if item.find('div', {'class': tag_value}):
if key == 'link':
value = item.find('div', {'class': tag_value}).find('a').get('href')
elif (key == 'price' or key == 'price_meter'):
value = parse_digits(item.find('div', {'class': tag_value}).text, key)
elif key == 'pub_datetime':
value = parse_date(item.find('div', {'class': tag_value}).text)
else:
value = item.find('div', {'class': tag_value}).text
return key, value
def parse_digits(string, type_digit):
digit = 0
try:
if type_digit == 'flats_counts':
digit = int(re.sub(r" ", "", string[:string.find("")]))
elif type_digit == 'price':
digit = re.sub(r" ", "", re.sub(r"₽", "", string))
elif type_digit == 'price_meter':
digit = re.sub(r" ", "", re.sub(r"₽/²", "", string))
except:
return -1
return digit
def parse_date(string):
now = datetime.strptime("15.03.20 00:00", "%d.%m.%y %H:%M")
s = string
if string.find('') >= 0:
s = "{} {}".format(now.day, now.strftime("%b"))
s = string.replace('', s)
elif string.find('') >= 0:
s = "{} {}".format(now.day - 1, now.strftime("%b"))
s = string.replace('',s)
if (s.find('') > 0):
s = s.replace('','mar')
if (s.find('') > 0):
s = s.replace('','feb')
if (s.find('') > 0):
s = s.replace('','jan')
return parse(s).strftime('%Y-%m-%d %H:%M:%S')
def parse_text(text, index):
tag_table = '_93444fe79c--wrapper--E9jWb'
tag_items = ['_93444fe79c--card--_yguQ', '_93444fe79c--card--_yguQ']
tag_flats_counts = '_93444fe79c--totalOffers--22-FL'
tags = {
'link':('c6e8ba5398--info-section--Sfnx- c6e8ba5398--main-info--oWcMk','undefined c6e8ba5398--main-info--oWcMk'),
'desc': ('c6e8ba5398--title--2CW78','c6e8ba5398--single_title--22TGT', 'c6e8ba5398--subtitle--UTwbQ'),
'price': ('c6e8ba5398--header--1df-X', 'c6e8ba5398--header--1dF9r'),
'price_meter': 'c6e8ba5398--term--3kvtJ',
'metro': 'c6e8ba5398--underground-name--1efZ3',
'pub_datetime': 'c6e8ba5398--absolute--9uFLj',
'address': 'c6e8ba5398--address-links--1tfGW',
'square': ''
}
res = []
flats_counts = 0
soup = BeautifulSoup(text)
if soup.find('div', {'class': tag_flats_counts}):
flats_counts = parse_digits(soup.find('div', {'class': tag_flats_counts}).text, 'flats_counts')
flats_list = soup.find('div', {'class': tag_table})
if flats_list:
items = flats_list.find_all('div', {'class': tag_items})
for i, item in enumerate(items):
d = {'index': index}
index += 1
for tag in tags.keys():
tag_value = tags[tag]
key, value = parse_tag(tag, tag_value, item)
d[key] = value
results[index] = d
return flats_counts, index
from IPython.display import clear_output
sum_flats = 0
index = 0
results = {}
for i, text in enumerate(site_texts):
flats_counts, index = parse_text(text, index)
sum_flats = len(results)
clear_output(wait=True)
print(f" {i + 1} flats = {flats_counts}, {sum_flats} ")
print(f" sum_flats ({sum_flats}) = flats_counts({flats_counts})")
Nuansa yang menarik adalah bahwa angka yang ditunjukkan di bagian atas halaman dan menunjukkan jumlah apartemen yang ditemukan berdasarkan permintaan berbeda dari halaman ke halaman. Jadi, dalam contoh kami, 5.402 kalimat yang diurutkan secara default ini berkisar antara 5343 hingga 5402, secara bertahap berkurang dengan peningkatan jumlah halaman permintaan (tetapi tidak oleh jumlah iklan yang ditampilkan). Selain itu, dimungkinkan untuk terus membongkar halaman di luar batas jumlah halaman yang ditunjukkan di situs. Dalam kasus kami, hanya 54 halaman yang ditawarkan di situs, tetapi kami dapat menurunkan 309 halaman, dengan hanya iklan yang lebih tua, dengan total 8640 iklan sewa apartemen.Investigasi fakta ini akan ditinggalkan di luar ruang lingkup artikel ini.Pemrosesan bingkai data
Jadi, kami memiliki kerangka data tunggal dengan data mentah pada 8640 penawaran. Kami akan melakukan analisis permukaan dari harga rata-rata dan median di distrik, menghitung harga sewa rata-rata per meter persegi apartemen dan biaya apartemen di distrik "rata-rata".Kami akan melanjutkan dari asumsi berikut untuk studi kami:- Kurangnya pengulangan: semua apartemen yang ditemukan adalah apartemen yang benar-benar ada. Pada tahap pertama, kami mengeliminasi apartemen yang berulang di alamat dan quadrature, tetapi jika apartemen memiliki quadrature atau alamat yang sedikit berbeda, kami menganggap opsi ini sebagai apartemen yang berbeda.
- — .
— «» ? ( ) , , , , . , , , . «» : . «» ( ) , .
Kami akan membutuhkan:price_per_month - harga sewa bulanan di rubelsquare - areaokrug - distrik, dalam penelitian ini seluruh alamat tidak menarik bagi kamiprice_meter - harga sewa per 1 meter persegiKodedf['price_per_month'] = df['price'].str.strip('/.').astype(int)
new_desc = df["desc"].str.split(",", n = 3, expand = True)
df["square"]= new_desc[1].str.strip(' ²').astype(int)
df["floor"]= new_desc[2]
new_address = df['address'].str.split(',', n = 3, expand = True)
df['okrug'] = new_address[1].str.strip(" ")
df['price_per_meter'] = (df['price_per_month'] / df['square']).round(2)
df = df.drop(['index','metro', 'price_meter','link', 'price','desc','address','pub_datetime','floor'], axis='columns')
Sekarang kita akan "mengurus" emisi secara manual sesuai jadwal. Untuk memvisualisasikan data, mari kita lihat tiga perpustakaan: matplotlib , seaborn dan plotly .Histogram data . Matplotlib memungkinkan Anda menampilkan semua bagan untuk grup data yang menarik bagi kami dengan cepat dan mudah, kami tidak perlu lagi. Gambar di bawah ini, yang menurutnya hanya 1 proposal di Mitino yang tidak dapat berfungsi sebagai penilaian kualitatif dari rata-rata apartemen, dihapus. Gambar lain yang menarik di Southern Administrative Okrug: mayoritas penawaran (lebih dari 500 unit) dengan nilai sewa di bawah 1000 rubel, dan lonjakan penawaran (hampir 300 unit) dengan 1.700 rubel per meter persegi. Di masa depan, Anda dapat melihat mengapa hal ini terjadi - mencari-cari indikator lain untuk apartemen ini.Hanya satu baris kode yang memberikan histogram di sana untuk kumpulan data yang dikelompokkan:hists = df['price_per_meter'].hist(by=df['okrug'], figsize=(16, 14), color = "tab:blue", grid = True)
 Penyebaran nilai . Di bawah ini disajikan grafik menggunakan ketiga perpustakaan. seaborn secara default lebih indah dan cerah, tetapi plotly memungkinkan Anda untuk segera menampilkan nilai ketika Anda mengarahkan mouse, yang sangat nyaman bagi kami untuk memilih nilai-nilai "pencilan" yang akan kami hapus.matplotlib
Penyebaran nilai . Di bawah ini disajikan grafik menggunakan ketiga perpustakaan. seaborn secara default lebih indah dan cerah, tetapi plotly memungkinkan Anda untuk segera menampilkan nilai ketika Anda mengarahkan mouse, yang sangat nyaman bagi kami untuk memilih nilai-nilai "pencilan" yang akan kami hapus.matplotlibfig, axes = plt.subplots(nrows=4,ncols=3,figsize=(15,15))
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
axes = axes.flatten()
axes[i].scatter(group['price_per_meter'],group['square'], color ='blue')
axes[i].set_title(name)
axes[i].set(xlabel=' 1 ..', ylabel=', 2')
fig.tight_layout()
 seaboarn
seaboarnsns.pairplot(vars=["price_per_meter","square"], data=df_copy, hue="okrug", height=5)
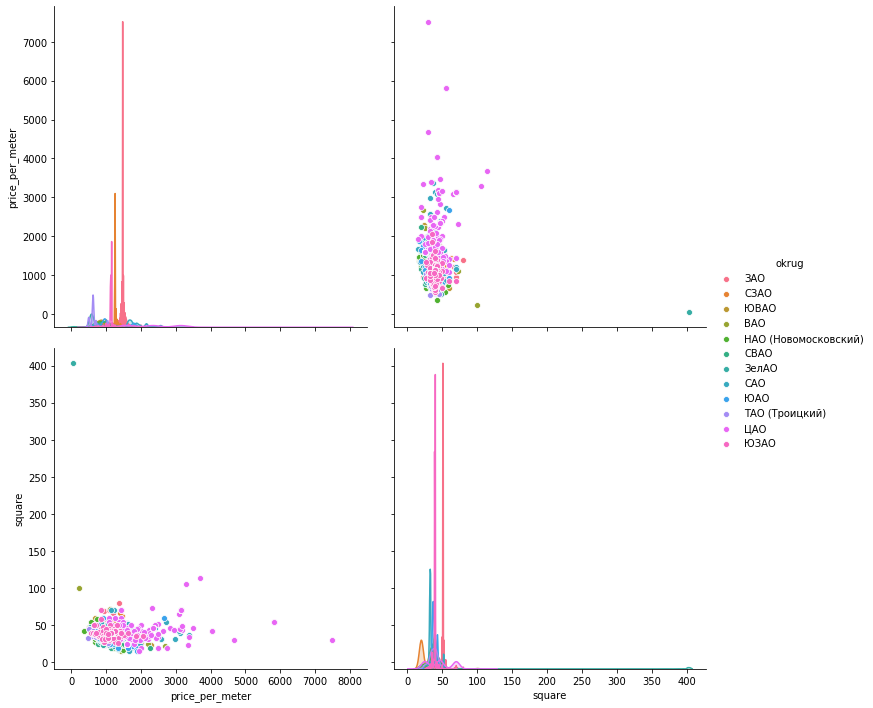 plotlySaya pikir akan ada cukup contoh untuk satu kabupaten.
plotlySaya pikir akan ada cukup contoh untuk satu kabupaten.import plotly.express as px
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
fig = px.scatter(group, x="price_per_meter", y="square", facet_col="okrug",
width=400, height=400)
fig.update_layout(
margin=dict(l=20, r=20, t=20, b=20),
paper_bgcolor="LightSteelBlue",
)
fig.show()
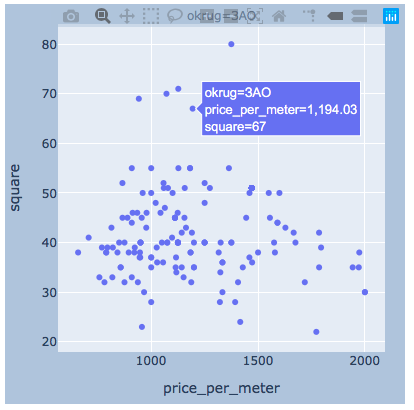
hasil
Jadi, setelah membersihkan data, dengan ahli menghilangkan emisi, kami memiliki 8602 penawaran "bersih".Selanjutnya, kami menghitung statistik utama sesuai dengan data: rata-rata, median, standar deviasi, kami mendapatkan peringkat berikut dari distrik Moskow karena biaya sewa rata-rata untuk apartemen rata-rata berkurang: Anda dapat menggambar histogram yang indah dengan membandingkan, misalnya, harga rata-rata dan median di kabupaten:
Anda dapat menggambar histogram yang indah dengan membandingkan, misalnya, harga rata-rata dan median di kabupaten: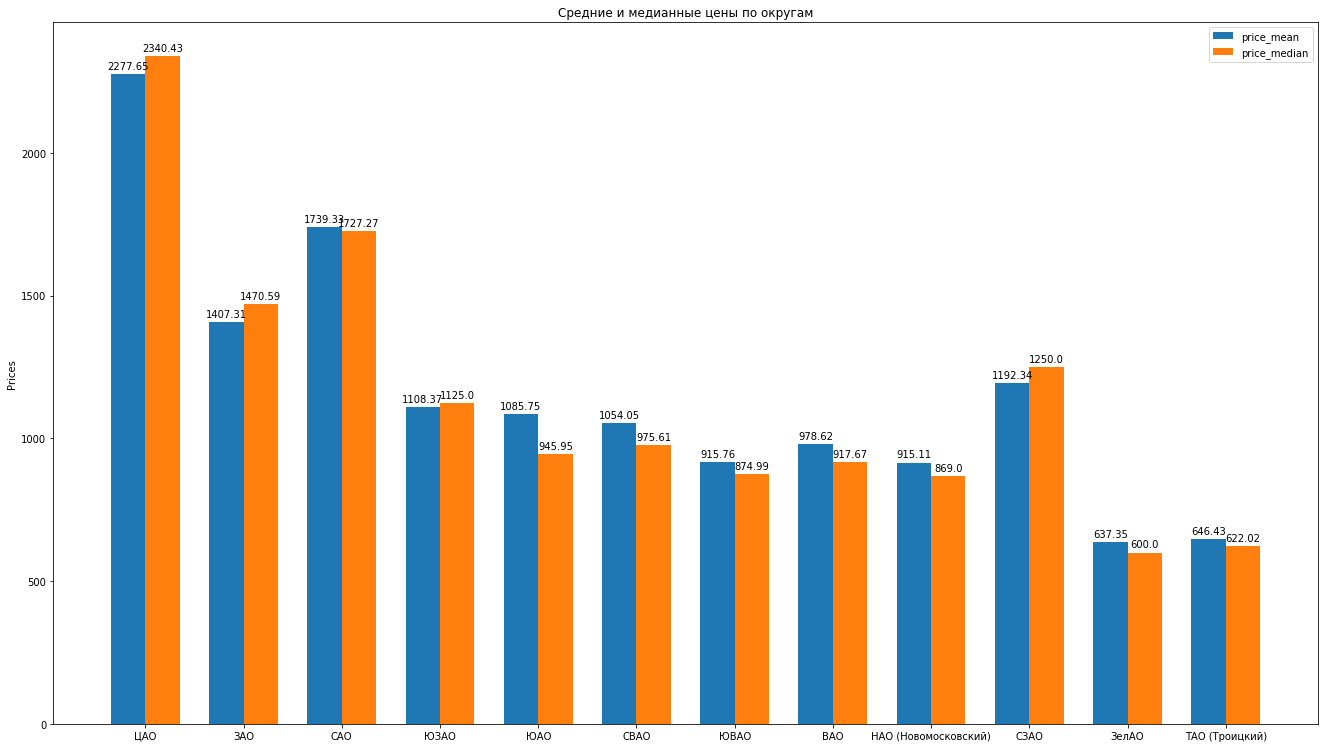 Apa lagi yang bisa katakan tentang struktur proposal untuk apartemen sewa berdasarkan data:
Apa lagi yang bisa katakan tentang struktur proposal untuk apartemen sewa berdasarkan data:- , , , . “” , ( ). , , , , , , “” . , , .
- . . « ». , «» — . . . , , , , , - , , . . .
- , “” , . , , — .
Bab terpisah, sangat menarik dan indah adalah topik geodata, tampilan data kami sehubungan dengan peta. Anda dapat melihat dengan sangat detail dan terperinci, misalnya, dalam artikel:Visualisasi hasil pemilihan di Moskow pada peta di Jupyter NotebookLikbez pada proyeksi kartografi dengan gambarOpenStreetMap sebagai sumber geodataSecara singkat, OpenStreetMap adalah segalanya bagi kami, alat yang mudah digunakan adalah: geopandas , cartoframes (mereka mengatakan itu sudah mati?) dan folium , yang akan kita gunakan.Beginilah data kami akan terlihat seperti pada peta interaktif.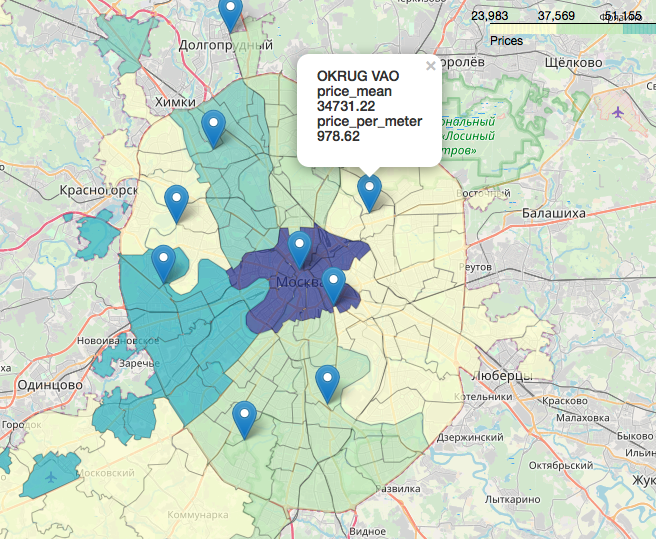 Bahan-bahan yang ternyata bermanfaat dalam pengerjaan artikel:Saya harap Anda tertarik, seperti saya.Terima kasih telah membaca. Kritik konstruktif dipersilahkan.Sumber dan kumpulan data diposting di github di sini .
Bahan-bahan yang ternyata bermanfaat dalam pengerjaan artikel:Saya harap Anda tertarik, seperti saya.Terima kasih telah membaca. Kritik konstruktif dipersilahkan.Sumber dan kumpulan data diposting di github di sini .