Beberapa waktu yang lalu, saya memulai perjalanan yang luar biasa ke dunia kompiler JIT untuk menemukan tempat di mana Anda dapat memasukkan tangan Anda dan mempercepat sesuatu, karena Dalam perjalanan pekerjaan utama, sejumlah kecil pengetahuan dalam LLVM dan pengoptimalannya telah terakumulasi. Dalam artikel ini, saya ingin berbagi daftar peningkatan saya di JIT (dalam. NET disebut RyuJIT untuk menghormati beberapa naga atau anime - Saya tidak mengetahuinya), yang sebagian besar telah mencapai master dan akan tersedia di .NET (Core) 5 Optimalisasi saya memengaruhi berbagai fase JIT, yang dapat ditampilkan secara sangat skematis sebagai berikut: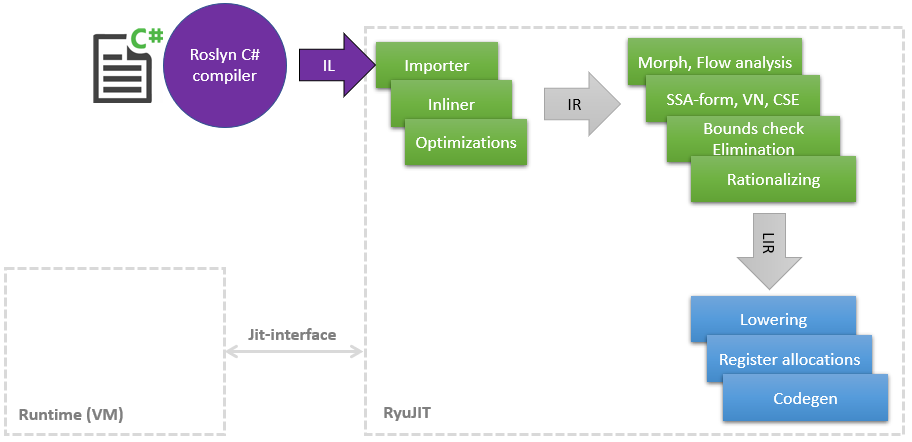 Seperti yang dapat dilihat dari diagram, JIT adalah modul terpisah yang terkait dengan Jit-Interface sempit , di mana JIT berkonsultasi tentang beberapa hal, misalnya, apakah mungkinmelemparkan satu kelas ke kelas lain. Semakin lama JIT mengkompilasi metode ke Tier1, semakin banyak informasi yang dapat diberikan runtime, misalnya, bahwa
Seperti yang dapat dilihat dari diagram, JIT adalah modul terpisah yang terkait dengan Jit-Interface sempit , di mana JIT berkonsultasi tentang beberapa hal, misalnya, apakah mungkinmelemparkan satu kelas ke kelas lain. Semakin lama JIT mengkompilasi metode ke Tier1, semakin banyak informasi yang dapat diberikan runtime, misalnya, bahwa static readonlybidang dapat diganti dengan konstanta, karena kelas sudah diinisialisasi secara statis.Jadi, mari kita mulai dengan daftarnya.PR # 1817 : Optimasi tinju / unboxing dalam pencocokan pola
Fase: ImportirBanyak fitur C # baru sering berdosa dengan memasukkan kotak / unbox opcode CIL . Ini adalah operasi yang sangat mahal, yang pada dasarnya adalah alokasi objek baru pada heap, menyalin nilai dari stack ke dalamnya, dan kemudian juga memuat GC pada akhirnya. Sudah ada sejumlah optimasi dalam JIT untuk kasus ini, tetapi saya menemukan pencocokan pola yang hilang di C # 8, misalnya:public static int Case1<T>(T o)
{
if (o is int x)
return x;
return 0;
}
public static int Case2<T>(T o) => o is int n ? n : 42;
public static int Case3<T>(T o)
{
return o switch
{
int n => n,
string str => str.Length,
_ => 0
};
}
Dan mari kita lihat asm-codegen sebelum optimasi saya (misalnya, untuk spesialisasi int) untuk ketiga metode: Dan sekarang setelah peningkatan saya:
Dan sekarang setelah peningkatan saya: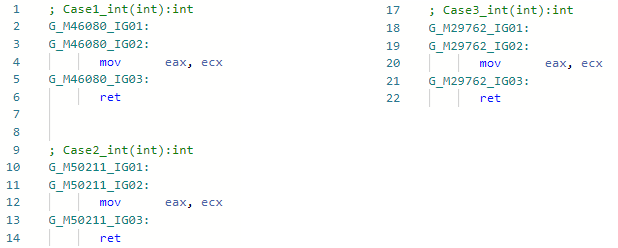 Faktanya adalah optimasi telah menemukan pola kode IL
Faktanya adalah optimasi telah menemukan pola kode ILbox !!T
isinst Type1
unbox.any Type2
ketika mengimpor dan memiliki informasi tentang jenis, saya bisa mengabaikan opcodes ini dan tidak memasukkan tinju-anbox. Omong-omong, saya menerapkan optimasi yang sama di Mono juga. Selanjutnya, tautan ke Tarik-Permintaan terdapat di header deskripsi optimisasi.PR # 1157 typeof (T) .IsValueType ⇨ benar / salah
Fase: ImportirDi sini saya melatih JIT untuk segera mengganti Type.IsValueType dengan konstanta jika memungkinkan. Ini adalah minus tantangan dan kemampuan untuk memotong seluruh kondisi dan cabang di masa depan, contohnya:void Foo<T>()
{
if (!typeof(T).IsValueType)
Console.WriteLine("not a valuetype");
}
Dan mari kita lihat codegen untuk spesialisasi <int> Foo sebelum perbaikan: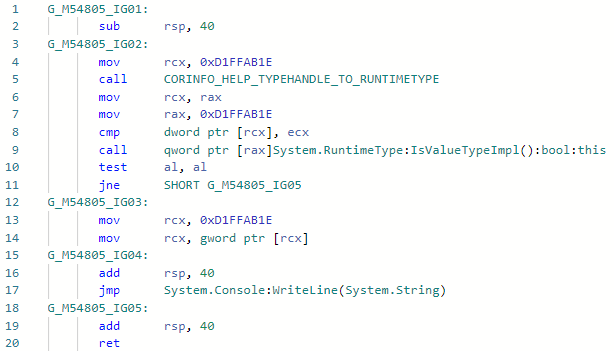 Dan setelah perbaikan: Hal yang
Dan setelah perbaikan: Hal yang sama dapat dilakukan dengan properti Type lainnya jika perlu.
sama dapat dilakukan dengan properti Type lainnya jika perlu.PR # 1157 typeof(T1).IsAssignableFrom(typeof(T2)) ⇨ true/false
Fase: ImportirHampir sama - sekarang Anda dapat memeriksa hierarki dalam metode generik tanpa takut ini tidak dioptimalkan, misalnya:void Foo<T1, T2>()
{
if (!typeof(T1).IsAssignableFrom(typeof(T2)))
Console.WriteLine("T1 is not assignable from T2");
}
Dengan cara yang sama, itu akan digantikan oleh konstanta true/falsedan kondisinya dapat dihapus seluruhnya. Dalam optimasi seperti itu, tentu saja, ada beberapa kasus sudut yang harus selalu Anda ingat: Sistem .__ Canon berbagi generik, array, variabilitas co (ntr), nullables, objek COM, dll.PR # 1378 "Hello".Length ⇨ 5
Fase: ImportirTerlepas dari kenyataan bahwa optimasi sejelas dan sesederhana mungkin, saya harus banyak berkeringat untuk mengimplementasikannya di JIT-e. Masalahnya adalah bahwa JIT tidak tahu tentang isi string, ia melihat string literal ( GT_CNS_STR ), tetapi tidak tahu apa-apa tentang konten spesifik dari string. Saya harus membantunya dengan menghubungi VM (untuk memperluas JIT-Interface yang disebutkan sebelumnya), dan optimasi itu sendiri pada dasarnya adalah beberapa baris kode . Ada banyak kasus pengguna, selain yang jelas, seperti: str.IndexOf("foo") + "foo".Lengthuntuk yang tidak jelas yang melibatkan inlining (saya ingatkan Anda: Roslyn tidak berurusan dengan inlining, jadi pengoptimalan ini tidak akan efektif di dalamnya, selain itu, seperti yang lainnya), misalnya:bool Validate(string str) => str.Length > 0 && str.Length <= 100;
bool Test() => Validate("Hello");
Mari kita lihat codegen untuk Test ( Validate inline):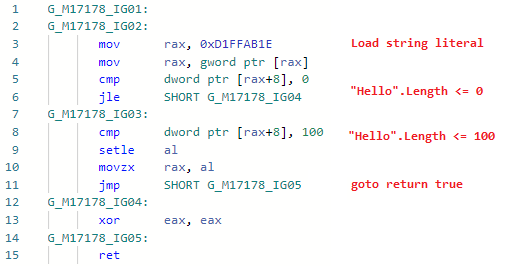 dan sekarang codegen setelah menambahkan optimasi:
dan sekarang codegen setelah menambahkan optimasi: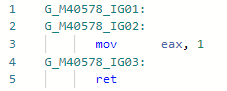 i.e. sebaris metode, ganti variabel dengan string literal, ganti .Panjang dari literal dengan panjang string nyata, lipat konstanta, hapus kode mati. Omong-omong, karena JIT sekarang dapat memeriksa isi string, pintu telah terbuka untuk optimisasi lain yang terkait dengan string string. Optimasi itu sendiri disebutkan dalam pengumuman pratinjau pertama. NET 5.0: devblogs.microsoft.com/dotnet/announcing-net-5-0-preview-1 di bagian peningkatan kualitas Kode bagian di RyuJIT .
i.e. sebaris metode, ganti variabel dengan string literal, ganti .Panjang dari literal dengan panjang string nyata, lipat konstanta, hapus kode mati. Omong-omong, karena JIT sekarang dapat memeriksa isi string, pintu telah terbuka untuk optimisasi lain yang terkait dengan string string. Optimasi itu sendiri disebutkan dalam pengumuman pratinjau pertama. NET 5.0: devblogs.microsoft.com/dotnet/announcing-net-5-0-preview-1 di bagian peningkatan kualitas Kode bagian di RyuJIT .PR # 1644: Mengoptimalkan Cek Terikat.
Fase: Batas Memeriksa PenghapusanBagi banyak orang, itu tidak akan menjadi rahasia bahwa setiap kali Anda mengakses array dengan indeks, JIT menyisipkan cek untuk Anda bahwa array tidak melampaui dan melempar pengecualian jika ini terjadi - dalam kasus logika yang salah, Anda tidak bisa untuk membaca memori acak, dapatkan nilai dan lanjutkan.int Foo(int[] array, int index)
{
return array[index];
}
Pemeriksaan semacam itu bermanfaat, tetapi dapat sangat memengaruhi kinerja: pertama, ia menambah operasi perbandingan dan membuat kode Anda tidak bercabang, dan kedua, itu menambahkan kode panggilan pengecualian ke metode Anda dengan semua konsekuensinya. Namun, dalam banyak kasus, JIT dapat menghapus cek ini jika dapat membuktikan kepada dirinya sendiri bahwa indeks tidak akan pernah melampaui itu, atau bahwa sudah ada beberapa cek lainnya dan Anda tidak perlu menambahkan satu lagi - Batas (Rentang) Eliminasi Batas. Saya menemukan beberapa kasus di mana dia tidak bisa mengatasi dan memperbaikinya (dan di masa depan saya merencanakan beberapa perbaikan lebih lanjut dari fase ini).var item = array[index & mask];
Di sini, dalam kode ini, saya memberi tahu JIT bahwa & maskpada dasarnya membatasi indeks dari atas ke nilai mask, mis. jika nilai maskdan panjang array diketahui oleh JIT , Anda tidak bisa memasukkan cek terikat. Hal yang sama berlaku untuk operasi%, (& x >> y). Contoh menggunakan optimasi ini di aspnetcore .Juga, jika kita tahu bahwa dalam array kita, misalnya, ada 256 elemen atau lebih, maka jika pengindeks tidak dikenal kita adalah tipe byte, tidak peduli seberapa keras ia mencoba, itu tidak akan pernah bisa keluar dari batas. PR: github.com/dotnet/coreclr/pull/25912PR # 24584: x / 2 ⇨ x * 0.5
Fase: MorphC PR ini dan memulai penyelaman menakjubkan saya ke dunia optimasi JIT. Operasi "divisi" lebih lambat dari operasi "perkalian" (dan jika untuk bilangan bulat dan secara umum - urutan besarnya). Bekerja untuk konstanta hanya setara dengan kekuatan dua, contoh:static float DivideBy2(float x) => x / 2;
Codegen sebelum optimasi: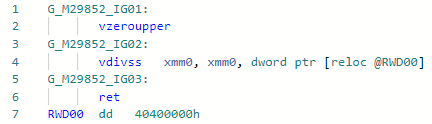 dan setelah:
dan setelah: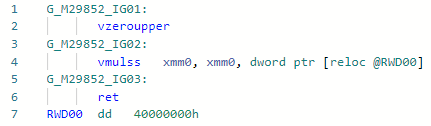 Jika kita membandingkan dua instruksi ini untuk Haswell, maka semuanya akan menjadi jelas:
Jika kita membandingkan dua instruksi ini untuk Haswell, maka semuanya akan menjadi jelas:vdivss (Latency: 10-20, R.Throughput: 7-14)
vmulss (Latency: 5, R.Throughput: 0.5)
Ini akan diikuti oleh optimisasi yang masih dalam tahap tinjauan kode dan bukan fakta bahwa mereka akan diterima.PR # 31978: Math.Pow(x, 2) ⇨ x * x
Fase: ImportirSemuanya sederhana di sini: alih-alih memanggil pow (f) untuk kasus yang agak populer, ketika derajatnya konstan 2 (well, gratis untuk 1, -1, 0), Anda dapat mengembangkannya menjadi x * x sederhana. Anda dapat memperluas derajat lainnya, tetapi untuk ini Anda harus menunggu implementasi mode "matematika cepat" di .NET, di mana spesifikasi IEEE-754 dapat diabaikan untuk kinerja. Contoh:static float Pow2(float x) => MathF.Pow(x, 2);
Codegen sebelum optimasi: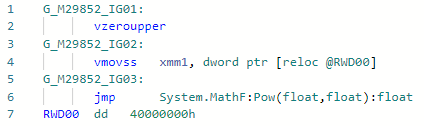 dan setelah:
dan setelah: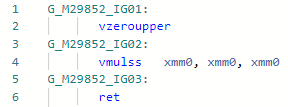
PR # 33024: x * 2 ⇨ x + x
Fase: MenurunkanJuga optimisasi piphol mikro (nano) yang cukup sederhana, memungkinkan Anda untuk mengalikan 2 tanpa memuat konstanta ke dalam register.static float MultiplyBy2(float x) => x * 2;
Codegen sebelum optimisasi: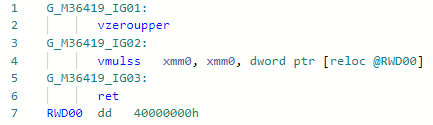 Setelah:
Setelah: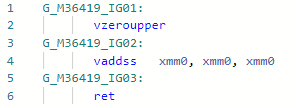 Secara umum, instruksi
Secara umum, instruksi mul(ss/sd/ps/pd)sama dalam latensi dan throughput add(ss/sd/ps/pd), tetapi kebutuhan untuk memuat konstanta "2" dapat sedikit memperlambat pekerjaan. Di sini, dalam contoh codegen di atas, saya vaddssmelakukan semuanya dalam register yang sama.PR # 32368: Optimalisasi Array. Panjang / c (atau% s)
Fase: MorphKebetulan bidang Panjang Array adalah tipe yang ditandatangani, dan pembagian dan sisanya oleh konstanta jauh lebih efisien untuk dilakukan dari tipe yang tidak ditandatangani (dan bukan hanya kekuatan dua), bandingkan saja codegen ini: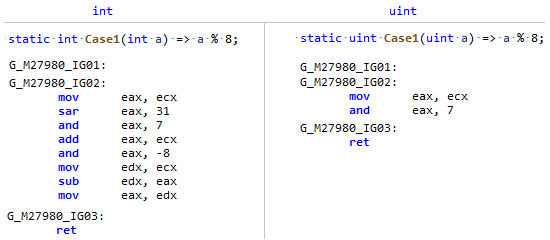 PR saya hanya mengingatkan JIT bahwa
PR saya hanya mengingatkan JIT bahwa Array.Lengthmeskipun signifikan, tetapi pada kenyataannya, panjang array TIDAK PERNAH ( kecuali Anda seorang anarkis ) bisa kurang dari nol, yang berarti Anda dapat melihatnya sebagai angka yang tidak ditandatangani dan menerapkan beberapa optimasi seperti untuk uint.PR # 32716: Optimalisasi perbandingan sederhana dalam kode tanpa cabang
Fase: Analisis aliranIni adalah kelas optimisasi lain yang beroperasi dengan blok dasar alih-alih ekspresi dalam satu. Di sini JIT agak konservatif dan memiliki ruang untuk perbaikan, misalnya memasukkan cmove jika memungkinkan. Saya mulai dengan optimasi sederhana untuk kasus ini:x = condition ? A : B;
jika A dan B adalah konstanta dan perbedaannya adalah satu, misalnya, condition ? 1 : 2maka kita, mengetahui bahwa operasi perbandingan itu sendiri mengembalikan 0 atau 1, dapat menggantikan lompatan dengan add. Dalam hal RyuJIT, tampilannya seperti ini: Saya sarankan untuk melihat deskripsi PR itu sendiri, saya harap semuanya dijelaskan dengan jelas di sana.
sarankan untuk melihat deskripsi PR itu sendiri, saya harap semuanya dijelaskan dengan jelas di sana.Tidak semua optimasi sama-sama bermanfaat.
Optimalisasi memerlukan biaya yang agak tinggi:* Meningkatkan = kompleksitas kode yang ada untuk dukungan dan membaca* Potensi bug: menguji optimisasi kompiler gila-gilaan sulit dan mudah ketinggalan sesuatu dan mendapatkan semacam segfault dari pengguna.* Kompilasi yang lambat* Meningkatkan ukuran binar JITSeperti yang sudah Anda pahami, tidak semua ide dan prototipe optimasi diterima dan perlu untuk membuktikan bahwa mereka memiliki hak untuk hidup. Salah satu cara yang diterima untuk membuktikan hal ini di .NET adalah dengan menjalankan utilitas jit-utils, yang akan AOT mengkompilasi seperangkat pustaka (semua BCL dan corelib) dan membandingkan kode assembler untuk semua metode sebelum dan setelah optimisasi, ini adalah cara laporan ini mencari pengoptimalan"str".Length. Selain laporan tersebut, ada juga lingkaran orang-orang tertentu (seperti jkotas ) yang, sekilas, dapat mengevaluasi kegunaan dan meretas segala sesuatu dari puncak pengalaman mereka dan memahami tempat-tempat mana di .NET bisa menjadi hambatan dan mana yang tidak bisa. Dan satu hal lagi: jangan menilai optimasi dengan argumen "tidak ada yang menulis", "akan lebih baik untuk hanya menampilkan peringatan di Roslyn" - Anda tidak pernah tahu bagaimana kode Anda akan menjaga JIT menguraikan segala sesuatu yang mungkin dan mengisi konstanta.