Kompresi header standar muncul di HTTP / 2, tetapi tubuh nilai URI, Cookie, User-Agent masih bisa puluhan kilobyte dan memerlukan tokenization, pencarian, dan perbandingan substring. Tugas menjadi kritis jika parser HTTP perlu menangani lalu lintas berbahaya yang berat. Pustaka standar menyediakan alat pengolah string yang luas, tetapi string HTTP memiliki spesifikasi sendiri. Untuk kekhususan inilah parser HTTP Tempesta FW dikembangkan. Kinerjanya beberapa kali lebih tinggi dibandingkan dengan solusi Open Source modern dan melampaui yang tercepat di antara mereka.Alexander Krizhanovsky (krizhanovsky) pendiri dan arsitek sistem Tempesta Technologies, seorang ahli dalam komputasi kinerja tinggi di Linux / x86-64. Alexander akan berbicara tentang kekhasan struktur string HTTP, menjelaskan mengapa pustaka standar kurang cocok untuk memprosesnya, dan menyajikan solusi Tempesta FW.Di bawah potongan: bagaimana HTTP Flood mengubah parser HTTP Anda menjadi hambatan, masalah x86-64 dengan salah duga cabang, caching dan kehabisan memori pada tugas parser HTTP biasa, perbandingan FSM dengan lompatan langsung, optimisasi GCC, vektor otomatis, strspn () - dan algoritma seperti strcasecmp () - untuk string HTTP, SSE, AVX2 dan penyaringan serangan injeksi menggunakan AVX2.Di Tempesta Technologies kami mengembangkan perangkat lunak khusus: kami berspesialisasi dalam bidang kompleks yang terkait dengan kinerja tinggi. Kami sangat bangga dengan pengembangan inti dari WAF versi pertama Positive Technologies. Firewall Aplikasi Web (WAF) adalah proksi HTTP: ia berurusan dengan analisis lalu lintas HTTP yang sangat mendalam untuk serangan (Web dan DDoS). Kami menulis inti pertama untuk itu.Selain konsultasi, kami sedang mengembangkan Tempesta FW - ini adalah Application Delivery Controller (ADC). Kami akan membicarakannya.Pengontrol Pengiriman Aplikasi
Pengendali Pengiriman Aplikasi adalah proxy HTTP dengan fungsionalitas yang ditingkatkan. Tetapi saya akan berbicara tentang fitur yang terkait dengan keamanan - tentang memfilter serangan DDoS dan Web. Saya juga akan menyebutkan batasannya, dan saya akan menunjukkan pekerjaan dan fungsinya dengan contoh kode.
Performa
Tempesta FW dibangun ke dalam kernel Linux TCP / IP Stack. Berkat ini dan sejumlah optimasi lainnya, sangat cepat - dapat memproses 1,8 juta permintaan per detik pada perangkat keras yang murah. Ini 3 kali lebih cepat dari Nginx pada beban teratas dan juga cepat jika dibandingkan dengan pendekatan bypass kernel.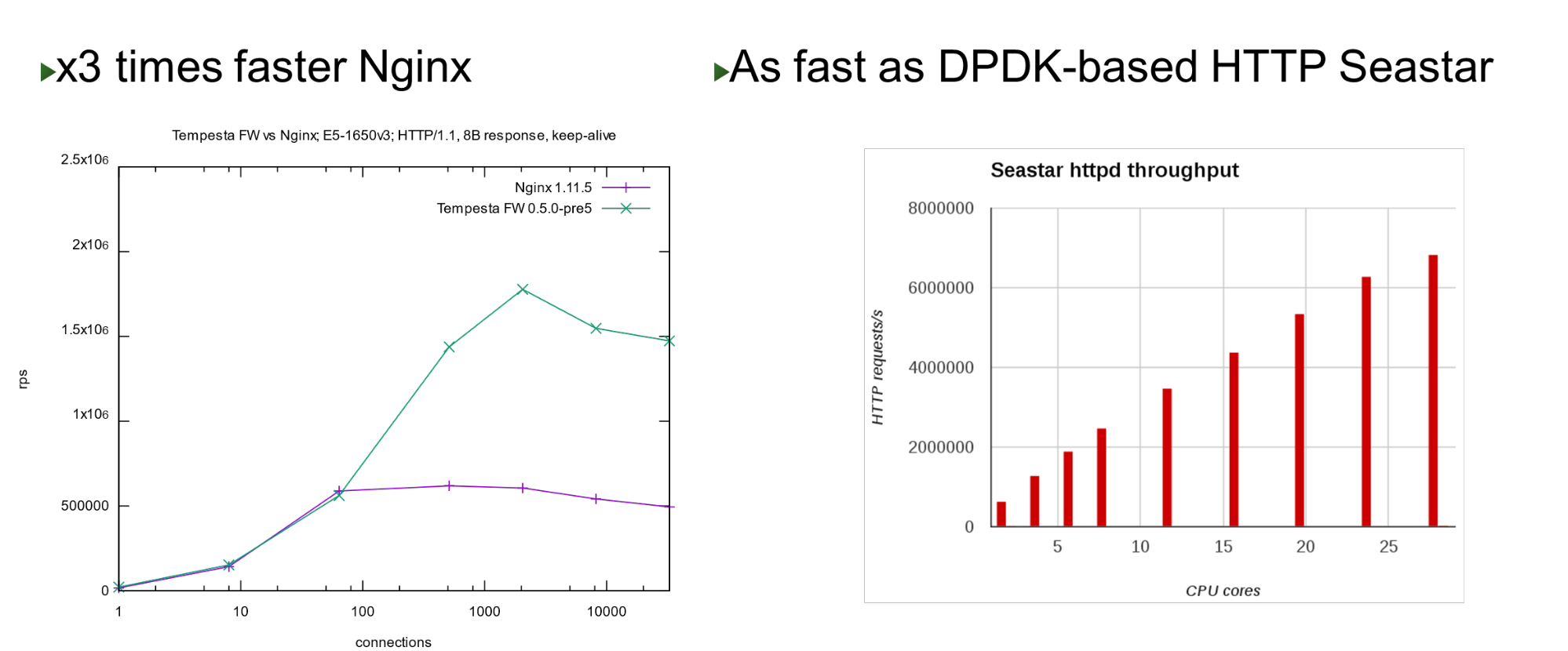 Pada sejumlah kecil core, ini menunjukkan kinerja yang mirip dengan proyek Seastar, yang digunakan dalam ScyllaDB (ditulis dalam DPDK).
Pada sejumlah kecil core, ini menunjukkan kinerja yang mirip dengan proyek Seastar, yang digunakan dalam ScyllaDB (ditulis dalam DPDK).Masalah
Proyek ini lahir ketika kami mulai bekerja di PT AF - pada tahun 2013. WAF ini didasarkan pada satu akselerator HTTP Open Source yang populer. Nginx, HAProxy, Varnish atau Apache Traffic adalah akselerator HTTP yang baik: mereka memberikan konten yang baik, cache, modifikasi, tetapi tidak satupun dari mereka dirancang untuk pemrosesan dan penyaringan lalu lintas besar-besaran .Oleh karena itu, kami berpikir bahwa jika ada firewall tingkat jaringan, mengapa tidak melanjutkan ide ini dan mengintegrasikan ke dalam tumpukan TCP / IP sebagai firewall tingkat aplikasi? Sebenarnya, ternyata Tempesta FW - hibrida akselerator HTTP dan firewall .Catatan: Nginx akan digunakan sebagai contoh dalam laporan karena ini adalah server web yang sederhana dan populer. Sebaliknya, mungkin ada server HTTP Open Source lainnya.HTTP
Mari kita lihat permintaan HTTP kami (HTTP / (1, ~ 2))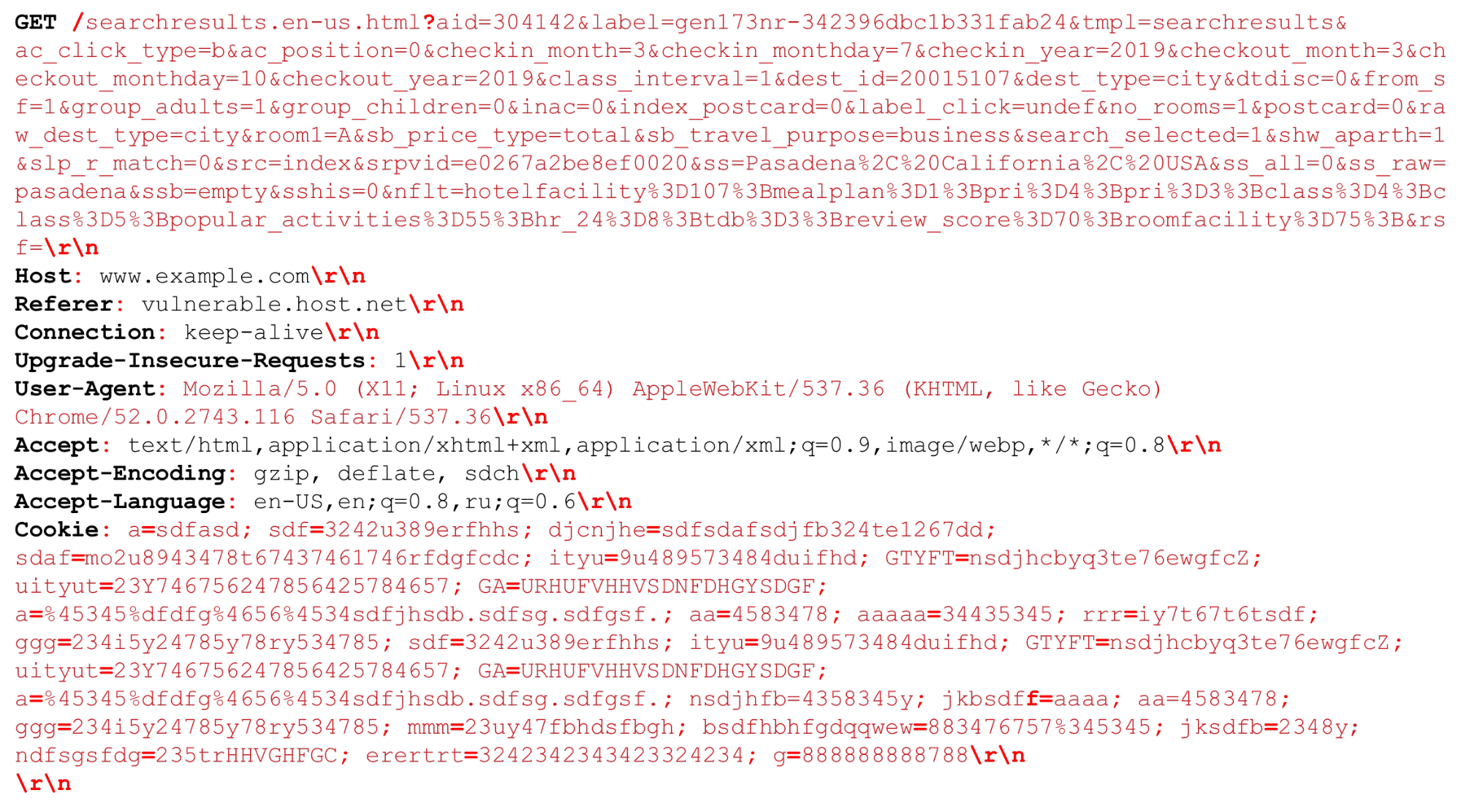 Kita dapat memiliki URI yang sangat besar. Pemisah yang penting pada saat penguraian HTTP disorot dalam huruf tebal merah . Saya akan menyoroti fitur: string besar beberapa kilobyte, serta pembatas yang berbeda, misalnya, tambahan "titik koma" yang perlu kita uraikan, atau urutan "\ r \ n".Sedikit tentang HTTP / 2 juga perlu dikatakan.
Kita dapat memiliki URI yang sangat besar. Pemisah yang penting pada saat penguraian HTTP disorot dalam huruf tebal merah . Saya akan menyoroti fitur: string besar beberapa kilobyte, serta pembatas yang berbeda, misalnya, tambahan "titik koma" yang perlu kita uraikan, atau urutan "\ r \ n".Sedikit tentang HTTP / 2 juga perlu dikatakan.Fitur HTTP / 2
HTTP / 2 adalah campuran dari string dan data biner . Campuran ini lebih tentang mengoptimalkan bandwidth koneksi daripada menghemat sumber daya server.HTTP / 2 di HPACK menggunakan tabel dinamis . Permintaan pertama dari klien tidak dioptimalkan, tidak ada dalam tabel. Anda harus menguraikannya sehingga ditambahkan ke tabel. Jika HTTP / 2 DDoS mendatangi Anda, ini masalahnya. Dalam kasus normal, HTTP / 2 adalah protokol biner, tetapi Anda masih perlu mem-parsing teks: nama header teks, data.Pengodean Huffman. Ini adalah pengkodean sederhana, tetapi Huffman sangat sulit diprogram dengan cepat untuk kompresi: pengkodean Huffman melintasi batas byte, Anda tidak dapat menggunakan ekstensi vektor dan Anda harus menggunakan byte. Anda tidak akan dapat dengan cepat memproses data dalam 32 atau 16 byte.Cookie, User-Agent, Referer, URI bisa sangat besar . Pertama, hapus Huffman, lalu kirim ke parser HTTP biasa, sama seperti pada HTTP / 1. Meskipun diizinkan oleh RFC, cookie tidak disarankan untuk dikompres, karena ini adalah data rahasia - Anda tidak boleh memberikan informasi kepada penyerang tentang ukurannya.Pemrosesan HTTP lambat . Semua server HTTP pertama mendekode HTTP / 2 dan kemudian mengirim baris-baris ini ke parser HTTP / 1 yang sudah menggunakan HTTP / 1.Apa masalah dengan penguraian HTTP / 1?- Anda perlu memprogram mesin negara dengan cepat.
- Anda perlu memproses garis berturut-turut dengan cepat.
Lalu lintas berbahaya menargetkan bagian proses paling lambat (terlemah). Karena itu, jika kita ingin membuat filter, kita harus memperhatikan bagian yang lambat sehingga mereka juga bekerja dengan cepat.Profil nginx
Mari kita lihat profil nginx di bawah banjir HTTP. Nonaktifkan log akses agar sistem file tidak melambat. Ketika bahkan halaman indeks reguler diminta, parser naik di bagian atas.Kiri - "Profil datar". Menariknya, tempat terpanas di dalamnya tidak jauh lebih berat daripada yang berikutnya, dan setelah itu profil turun dengan lancar. Ini berarti, misalnya, bahwa mengoptimalkan fungsi pertama dua kali tidak akan membantu meningkatkan kinerja secara signifikan. Itu sebabnya kami tidak mengoptimalkan Nginx yang sama, tetapi membuat proyek baru yang akan meningkatkan kinerja seluruh ekor profil.Bagaimana parser HTTP reguler dikodekan
Biasanya kami memiliki loop ( while) yang berjalan di sepanjang baris, dan dua variabel: state ( state) dan data saat ini ( str_ptr).Kami memasuki siklus (1) dan melihat kondisi saat ini (kondisi cek). Kami meneruskan ke data yang diterima (simbol 'b') dan menerapkan beberapa logika. Kami lolos ke kondisi kedua (2). Pergi ke akhir
Pergi ke akhir switch(3) - ini adalah transisi kedua relatif ke awal kode kita dan, mungkin, ketinggalan kedua dalam cache instruksi. Lalu kita pergi ke permulaan while(4), makan karakter berikutnya ... ... dan lagi mencari keadaan dalam instruksi di dalam
... dan lagi mencari keadaan dalam instruksi di dalam case 2:.Ketika suatu variabel telah diberi statenilai2, kita bisa langsung ke instruksi selanjutnya. Tetapi sebaliknya, mereka naik lagi dan turun lagi. Kami "memotong lingkaran" dengan kode alih-alih hanya turun. Parser normal tidak, misalnya, Ragel menghasilkan parser dengan transisi langsung.
Nginx HTTP Parser
Beberapa kata tentang parser nginx dan lingkungannya.Nginx berfungsi dengan API soket normal - data yang masuk ke adaptor disalin ke ruang pengguna. Akibatnya, kami memiliki potongan data besar di mana kami mencari yang kami butuhkan.Nginx menggunakan algoritma yang bekerja dalam dua lintasan: pertama mencari panjang, lalu memeriksa. Pada langkah pertama, ia memindai string untuk token, mencari token pertama ("percobaan"). Pada yang kedua, itu token, memeriksa akhir permintaan ( Get) dan mulai switch, sesuai dengan ukuran token.for (p = b->pos; p < b->last; p++) {
...
switch (state) {
...
case sw_method:
if (ch == ' ') {
m = r->request_start;
switch (p - m) {
case 3:
if (ngx_str3_cmp(m, 'G', 'E', 'T', ' ')) {
...
}
if ((ch < 'A' || ch > 'Z') && ch != '_' && ch != '-')
return NGX_HTTP_PARSE_INVALID_METHOD;
break;
...
"Dapatkan" selalu dalam potongan data yang sama . Tempesta FW bekerja dengan zero-copy. Ini berarti bahwa data dapat datang dengan ukuran yang sepenuhnya arbitrer: masing-masing 1 byte atau 1000 byte. "Mekanisme" ini tidak cocok untuk kita.Mari kita lihat cara kerjanya switchdi GCC.Gcc
Tabel pencarian . Di sebelah kiri adalah contoh khas enum: mulai dengan 0, lalu label berurutan, 26 konstanta, dan kemudian beberapa kode yang memproses semuanya. Di sebelah kanan adalah kode yang dihasilkan oleh kompiler. Pertama, bandingkan variabel
Pertama, bandingkan variabel statedalam register EAX dengan konstanta. Selanjutnya, kami menyajikan semua label dalam bentuk array berurutan dari pointer 8 byte (tabel pencarian). Pada instruksi ini kita meneruskan offset dalam array ini - itu adalah dereferencing ganda dari pointer. Kanan bawah adalah kode yang kita beralih dari tabel ini.Ternyata dereferencing ganda memori: jika kami menerima data rahasia, maka dengan byte kami menemukan alamat dalam array dan pergi ke pointer ini. Penting untuk diketahui bahwa dalam kehidupan ini masih lebih buruk daripada dalam contoh - untuk tabel pencarian yang dihasilkan oleh kompilerkode lebih rumit dalam kasus skrip untuk serangan Spectre.Pencarian biner . Kasus berikutnya switchbukan dengan konstanta berurutan, tetapi dengan yang sewenang-wenang. Kodenya sama, tetapi sekarang GCC tidak dapat mengkompilasi array yang begitu besar dan menggunakan konstanta sebagai indeks dari array. Dia beralih ke pencarian biner. Di sebelah kanan kita melihat perbandingan berurutan, transisi ke alamat dan kelanjutan perbandingan - pencarian biner adalah dengan kode.Pengurai HTTP nginx. Mari kita lihat apa itu mesin nginx. Ini memiliki 9 kilobyte kode - ini tiga kali lebih sedikit dari cache level pertama pada mesin tempat benchmark diluncurkan (seperti pada kebanyakan prosesor x86-64).
Di sebelah kanan kita melihat perbandingan berurutan, transisi ke alamat dan kelanjutan perbandingan - pencarian biner adalah dengan kode.Pengurai HTTP nginx. Mari kita lihat apa itu mesin nginx. Ini memiliki 9 kilobyte kode - ini tiga kali lebih sedikit dari cache level pertama pada mesin tempat benchmark diluncurkan (seperti pada kebanyakan prosesor x86-64).$ nm -S /opt/nginx-1.11.5/sbin/nginx
| grep http_parse | cut -d' ' -f 2
| perl -le '$a += hex($_) while (<>); print $a'
9220
$ getconf LEVEL1_ICACHE_SIZE
32768
$ grep -c 'case sw_' src/http/ngx_http_parse.c
84
Pengurai header nginx ngx_http_parse_header_line ()adalah tokenizer sederhana. Itu tidak melakukan apa-apa dengan nilai header dan nama mereka, tetapi hanya menempatkan token dari header HTTP ke dalam hash. Jika Anda membutuhkan nilai header apa pun, pindai tabel header dan ulangi analisisnya.Kita harus benar - benar memeriksa nama dan nilai header untuk alasan keamanan .Tempesta FW: validasi string dari string HTTP
Mesin negara kami adalah urutan besarnya lebih kuat: kami melakukan validasi header RFC dan segera, di parser, memproses hampir semuanya. Jika nginx memiliki 80 negara, maka kami memiliki 520, dan ada lebih banyak dari mereka. Jika kita melaju switch, maka itu akan menjadi 10 kali lebih besar.Kami memiliki nol-salinan I / O - potongan ukuran yang berbeda dapat memotong data di tempat yang berbeda. potongan yang berbeda dapat memotong data kami. Dalam zero-copy I / O, misalnya, "GET" dapat (jarang) muncul sebagai "GET", "GE" dan "T" atau "G", "E" dan "T", sehingga Anda perlu menyimpan status di antara potongan data . Kami praktis menghapus biaya I / O, tetapi dalam profil itu terbang - semuanya buruk. Parser HTTP besar adalah salah satu tempat paling kritis dalam proyek.$ grep -c '__FSM_STATE\|__FSM_TX\|__FSM_METH_MOVE\|__TFW_HTTP_PARSE_' http_parser.c
520
7.64% [tempesta_fw] [k] tfw_http_parse_req
2.79% [e1000] [k] e1000_xmit_frame
2.32% [tempesta_fw] [k] __tfw_strspn_simd
2.31% [tempesta_fw] [k] __tfw_http_msg_add_str_data
1.60% [tempesta_fw] [k] __new_pgfrag
1.58% [kernel] [k] skb_release_data
1.55% [tempesta_fw] [k] __str_grow_tree
1.41% [kernel] [k] __inet_lookup_established
1.35% [tempesta_fw] [k] tfw_cache_do_action
1.35% [tempesta_fw] [k] __tfw_strcmpspn
Apa yang harus dilakukan untuk memperbaiki situasi ini?Referensi Langsung FSM
Hal pertama yang kita lakukan adalah menggunakan bukan loop, tetapi transisi langsung dengan label ( go to) . Generator pengurai normal seperti Ragel melakukan ini. Kami menyandikan setiap negara bagian kami dengan label di
Kami menyandikan setiap negara bagian kami dengan label di switchdan label di C dengan nama yang sama . Setiap kali kami ingin pergi, kami menemukan label di switchatau mengakses negara yang sama langsung dari kode. Pertama kali kami melewati switch, dan kemudian di dalamnya kami langsung menuju label yang diinginkan.Kerugian : ketika kita ingin beralih ke keadaan berikutnya, kita harus segera mengevaluasi apakah kita masih memiliki data yang tersedia (karena zero-copy I / O). Kondisi tubuhforIni disalin ke masing-masing negara: alih-alih satu kondisi dalam FSM switch-driven biasa, kami memiliki 500 dari mereka sesuai dengan jumlah negara. Menghasilkan kode untuk setiap negara bagian tidak bagus.Dalam kasus mesin negara besar, karena fordengan bagian switchdalam yang besar , GTC juga mengulangi kondisi forbeberapa kali di dalam kode.Ganti dengan switchtransisi langsung. Optimasi berikutnya adalah bahwa kami tidak menggunakannya switchdan beralih ke lompatan langsung ke alamat meta yang disimpan. Kami ingin segera pergi ke titik yang diinginkan segera setelah kami memasuki fungsi. GCC memungkinkan Anda melakukan ini. GCC memiliki ekstensi standar yang dapat membantu. Kami mengambil nama label (ini dia
GCC memiliki ekstensi standar yang dapat membantu. Kami mengambil nama label (ini dia from) dan menetapkan alamatnya untuk beberapa variabel-C melalui double ampersand (&&). Sekarang kita bisa membuat instruksi lompat langsungjmpke alamat label ini dengan goto.Mari kita lihat apa yang terjadi.Kinerja Konversi Langsung
Pada sejumlah kecil negara, generator kode transisi langsung bahkan sedikit lebih lambat dari biasanya switch. Tetapi untuk mesin negara besar, produktivitas berlipat ganda. Jika mesin negara kecil, lebih baik menggunakan yang biasa switch.$ grep -m 2 'model name\|bugs' /proc/cpuinfo
model name : Intel(R) Core(TM) i7-6500U CPU @ 2.50GHz
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf
$ gcc --version|head -1
gcc (GCC) 8.2.1 20181105 (Red Hat 8.2.1-5)
States Switch-driven automaton Goto-driven automaton
7 header_line: 139ms header_line: 156ms
27 request_line: 210ms request_line: 186ms
406 big_header_line: 1406ms goto_big_header_line: 727ms
Catatan: Kode Tempesta lebih rumit dari contoh. GitHub memiliki semua tolok ukur sehingga Anda dapat melihat semuanya secara detail. Kode parser asli tersedia di tautan (parser HTTP utama). Selain itu, di Tempesta FW ada parser kecil yang menggunakan FSM lebih mudah.Mengapa transisi langsung mungkin lebih lambat
Di mesin negara, kita melalui banyak kode, jadi (diharapkan) akan ada banyak salah duga cabang. Mari kita melakukan "profiling" berdasarkan prediksi branch-misses:perf record -e branch-misses -g ./http_benchmark
406 states: switch - 38% on switch(),
direct jumps - 13% on header value parsing
7,27 states: switch - <18% switch(), up to 40% for()
direct jumps – up to 46% on header & URI parsing
Pada mesin negara besar dengan 406 negara bagian, kami menghabiskan 38% dari waktu pemrosesan transisi di switch. Pada mesin keadaan dengan transisi langsung, hotspot adalah penguraian garis. Parsing string di setiap negara termasuk memeriksa kondisi ujung string: kondisi fordi mesin negara aktif switch.perf stat -e L1-icache-load-misses ./http_benchmark
Switch-driven automaton Goto-driven automaton
big FSM code size: 29156 49202
L1-icache-load-misses: 4M 2M
Selanjutnya, kita melihat profil dari kedua jenis mesin negara oleh peristiwa L1 cache cache instruksi - hampir 30 kilobyte untuk switchdan 50 kilobyte untuk lompatan langsung (lebih dari cache instruksi tingkat pertama).Tampaknya jika kita tidak cocok dengan cache, seharusnya ada banyak cache yang hilang untuk mesin keadaan seperti itu. Tapi tidak, mereka 2 kali lebih sedikit. Itu karena cache berfungsi lebih baik: kami bekerja dengan kode secara berurutan dan berhasil menarik data dari cache yang lebih lama.Kompiler mengubah urutan kode
Saat kami memprogram kode mesin keadaan go to, pertama-tama kita memiliki status yang akan dipanggil pertama ketika data diterima: metode HTTP, URI, dan kemudian header HTTP. Tampaknya logis bahwa kode akan dimuat ke cache prosesor secara berurutan, dari atas ke bawah, sama seperti kita melalui data. Tapi ini sepenuhnya salah. Jika Anda melihat kode assembler, Anda akan melihat hal-hal luar biasa. Di sebelah kiri adalah apa yang kami program: pertama kami parsing metode
Di sebelah kiri adalah apa yang kami program: pertama kami parsing metode GETdan POSTkemudian di suatu tempat jauh di bawah metode yang tidak mungkin UNLOCK. Oleh karena itu, kami berharap dapat melihat parsing GETdan pada awal assembler POST, dan kemudian UNLOCK. Tapi semuanya justru sebaliknya: GETdi tengah, POSTdi akhir, dan di UNLOCKatas.Ini karena kompiler tidak mengerti bagaimana data datang kepada kita. Dia mendistribusikan kode sesuai dengan gambar kode indahnya. Agar dia mengatur kode dalam urutan yang benar, kita harus menggunakan penghalang kompiler .Penghalang kompiler adalah boneka perakitan yang tidak akan disusun ulang oleh pengompil. Dengan hanya menempatkan hambatan seperti itu, kami meningkatkan produktivitas sebesar 4% .STATE(sw_method) {
...
MATCH(NGX_HTTP_GET, "GET ");
MATCH(NGX_HTTP_POST, "POST");
__asm__ __volatile__("": : :"memory");
...
METH_MOVE(Req_MethU, 'N', Req_MethUn);
METH_MOVE(Req_MethUn, 'L', Req_MethUnl);
METH_MOVE(Req_MethUnl, 'O', Req_MethUnlo);
METH_MOVE(Req_MethUnlo, 'C', Req_MethUnloc);
METH_MOVE_finish(Req_MethUnloc, 'K', NGX_HTTP_UNLOCK)
Tulis kode dengan cara Anda sendiri
Karena kompiler tidak mengatur data seperti yang kita inginkan, kami akan melakukan optimasi dipandu profiler (optimasi di bawah kendali profiler). Profiler guided optimization (PGO) adalah jumlah total sampel, bukan urutan panggilan. Misalnya, URI menerima lebih banyak sampel daripada analisis metode, sehingga URI akan memposisikan kode pemrosesan sebelum memproses metode.Bagaimana itu bekerja? Kami akan menulis kode, menjalankan tolok ukur di atasnya, memberikan hasil profil ke kompiler, dan itu akan menghasilkan kode optimal untuk beban kami. Tetapi masalahnya adalah ia hanya mengkompilasi bagian kode yang terpanas, tetapi tidak melacak ketergantungan waktu. Jika URI terbesar di muat, maka ini akan menjadi tempat terpanas. URI akan naik ke atas fungsi, dan PGO tidak akan menunjukkan bahwa nama metode selalu sebelum URI. Dengan demikian, PGO tidak berfungsi.Req_Method: {
if (likely(PI(p) == CHAR4_INT('G', 'E', 'T', ' '))) {
...
goto Req_Uri;
}
if (likely(PI(p) == CHAR4_INT('P', 'O', 'S', 'T'))) {
...
goto Req_UriSpace;
}
goto Req_Meth_SlowPath;
}
...
Req_Uri:
...
Req_Meth_SlowPath:
...
Apa yang berhasil?likely/ unlikely macro (untuk kode kernel Linux, GCC intrinsik tersedia di ruang pengguna __builtin_expect()). Mereka mengatakan kode mana yang harus ditempatkan lebih dekat. Misalnya, kemungkinan melaporkan bahwa badan permintaan harus segera ketinggalan if. Kemudian mengambil kode terlebih dahulu (mengambil prosesor terlebih dahulu) akan memilih kode itu dan semuanya akan cepat. Gambar menunjukkan awal dari metode parsing, akhir dan penghalang. Kami tidak berharap melihat kode di balik penghalang. Tampaknya ini tidak seharusnya - kami telah memasang penghalang.Tetapi apa yang terjadi dalam kenyataan? Kompilator melihat
Gambar menunjukkan awal dari metode parsing, akhir dan penghalang. Kami tidak berharap melihat kode di balik penghalang. Tampaknya ini tidak seharusnya - kami telah memasang penghalang.Tetapi apa yang terjadi dalam kenyataan? Kompilator melihat likelykondisi - kemungkinan besar kita akan memasuki tubuh kondisi dan di sana kita akan beralih ke lompatan tanpa syarat ke labelReq_Uri. Ternyata kode itu setelah kondisi kita tidak diproses di "hot path". Kompiler memindahkan kode di bawah label di belakang if, meskipun ada penghalang, karena kondisi kode panas terpenuhi.Untuk ini tidak, GCC memiliki ekstensi: atribut hotdan coldlabel. Mereka mengatakan label mana yang panas (kemungkinan besar) dan mana yang dingin (kecil kemungkinannya). Di sini kita sepakat tentang apa yang
Di sini kita sepakat tentang apa yang GETlebih mungkin POSTdan serahkan padanya likely. Dalam kondisi tersebut, pemrosesan URI naik, dan POSTmasuk di bawah. Semua kode lain untuk mesin keadaan paling tidak mungkin tetap di bawah karena labelnya dingin.Ambigu -O3
Mari kita lihat optimasi kompiler. Hal pertama yang terlintas dalam pikiran adalah untuk menggunakan bukan O2, tetapi O3 - itu harus lebih cepat. Tapi ini tidak benar - O3 terkadang menghasilkan kode yang lebih buruk. O3 adalah kumpulan dari beberapa optimasi . Jika kami menambahkannya ke O2 secara terpisah, kami mendapatkan opsi yang berbeda: beberapa bantuan optimasi, beberapa mengganggu. Untuk kode spesifik kami, kami memilih hanya optimasi yang menghasilkan kode lebih baik. Kami memberikan hasil terbaik - ini adalah 1.820 detik relatif ke 1.838 dan 1.858.Beberapa opsi disorot dalam warna hijau - ini adalah auto-vektorisasi.
O3 adalah kumpulan dari beberapa optimasi . Jika kami menambahkannya ke O2 secara terpisah, kami mendapatkan opsi yang berbeda: beberapa bantuan optimasi, beberapa mengganggu. Untuk kode spesifik kami, kami memilih hanya optimasi yang menghasilkan kode lebih baik. Kami memberikan hasil terbaik - ini adalah 1.820 detik relatif ke 1.838 dan 1.858.Beberapa opsi disorot dalam warna hijau - ini adalah auto-vektorisasi.Autovectorization
Contoh siklus dari panduan GCC .int a[256], b[256], c[256];
void foo () {
for (int i = 0; i < 256; i++)
a[i] = b[i] + c[i];
}
Jika kita memiliki beberapa variabel array yang berulang, kita dapat mengoptimalkan siklus - terurai menjadi vektor. Secara default, auto- vektorisasi diaktifkan pada tingkat ketiga optimasi -O3 : GCC menghasilkan kode vektor di mana ia bisa. Tetapi tidak semua kode dapat secara otomatis di-vectorized (walaupun pada prinsipnya vectorized).Kami dapat mengaktifkan opsi GCC -fopt-info-vec-all, yang menunjukkan apa yang telah menjadi vektor dan apa yang tidak. Kami mendapatkan bahwa untuk tolok ukur kami tidak ada yang di vektorisasi, tetapi kode masih dihasilkan lebih buruk. Oleh karena itu, vektorisasi tidak selalu berfungsi: kadang-kadang memperlambat kode. Tetapi kita selalu dapat melihat apa yang telah di-vektor-kan dan mana yang tidak, dan mematikan vektorisasi, jika perlu.Alignment: bagaimana cara membandingkan string dengan GET?
Kami membuat retasan kecil, seperti pada nginx: kami tidak menguraikan baris demi byte, tetapi menghitung intdan membandingkan baris dengan mereka.#define CHAR4_INT(a, b, c, d) ((d << 24) | (c << 16) | (b << 8) | a)
if (p == CHAR4_INT('G', 'E', 'T', ' ')))
Kita tahu bahwa jika inttidak selaras, maka akan melambat 2-3 kali. Kami menulis patokan kecil yang membuktikan ini.$ ./int_align
Unaligned access = 6.20482
Aligned access = 2.87012
Read four bytes = 2.45249
Kemudian cobalah untuk menyelaraskan int. Kami akan melihat, jika alamat intdisejajarkan, kemudian membandingkan dengan int, jika tidak, byte. (((long)(p) & 3)
? ((unsigned int)((p)[0]) | ((unsigned int)((p)[1]) << 8)
| ((unsigned int)((p)[2]) << 16) | ((unsigned int)((p)[3]) << 24))
: *(unsigned int *)(p));
Tetapi ternyata pendekatan ini bekerja lebih buruk:full request line: no difference
method only: unaligned - 214ms
aligned - 231ms
bytes - 216ms
Singkatnya: ada perbedaan antara kode benchmark yang terisolasi, tidak dapat dioptimalkan, dan kode parser sebaris, yang kehilangan optimasinya karena jumlah kode yang besar. Tidak ada penalti dalam pembuatan profil.Catatan: diskusi terperinci tentang mengapa hal ini terjadi dalam tugas kita dapat dibaca di GitHub .Mengapa string HTTP penting bagi kami?
Misalnya, ini adalah URI normal: Jika Anda cukup pilih-pilih tentang hotel, buka Pemesanan dan atur beberapa filter, dapatkan URI lebih dari satu kilobyte.Nginx memiliki mesin parsing yang cukup besar di
Jika Anda cukup pilih-pilih tentang hotel, buka Pemesanan dan atur beberapa filter, dapatkan URI lebih dari satu kilobyte.Nginx memiliki mesin parsing yang cukup besar di switch/ case. Itu tidak bekerja dengan sangat cepat. Selain itu, dalam kasus Tempesta FW, kita tidak hanya perlu menguraikan URI, tetapi juga memeriksanya untuk injeksi.case sw_check_uri:
if (usual[ch >> 5] & (1U << (ch & 0x1f)))
break;
switch (ch) {
case '/':
r->uri_ext = NULL;
state = sw_after_slash_in_uri;
break;
case '.':
r->uri_ext = p + 1;
break;
case ' ':
r->uri_end = p;
state = sw_check_uri_http_09;
break;
case CR:
r->uri_end = p;
r->http_minor = 9;
state = sw_almost_done;
break;
case LF:
r->uri_end = p;
r->http_minor = 9;
goto done;
case '%':
r->quoted_uri = 1;
...
URI lain: /redir_lang.jsp?lang=foobar%0d%0aContent-Length:%200%0d%0a% 0d% 0aHTTP / 1,1% 20200% 20OK% 0d% 0aContent-Type:% 20text /html% 0d% 0aContent -Panjang:% 2019% 0d% 0a% 0d% 0aShazam </html>.Sepertinya yang pertama, tetapi memiliki suntikan. Anda harus menggali cukup dalam untuk memahami hal ini.Mari kita jalankan tes : ambil URI pertama, beri makan wrk, atur ke nginx dan lihat bahwa parsing nginx menjadi sangat panas. Jika pada permintaan indeks reguler sebelumnya sudah jelas bahwa parser sudah ada di atas, ini semakin panas.
Jika pada permintaan indeks reguler sebelumnya sudah jelas bahwa parser sudah ada di atas, ini semakin panas.8.62% nginx [.] ngx_http_parse_request_line
2.52% nginx [.] ngx_http_parse_header_line
1.42% nginx [.] ngx_palloc
0.90% [kernel] [k] copy_user_enhanced_fast_string
0.85% nginx [.] ngx_strstrn
0.78% libc-2.24.so [.] _int_malloc
0.69% nginx [.] ngx_hash_find
0.66% [kernel] [k] tcp_recvmsg
Apa yang istimewa tentang string HTTP? Ada pemisah yang berbeda ' : 'dan ' , ', dan bahkan akhir baris, yang dapat berupa byte ganda \r\natau byte tunggal \n, yang telah dibahas di awal. Tidak ada terminasi 0-C-line - untuk alasan keamanan kami ingin lebih akurat memeriksa apa yang datang kepada kami. Kami memiliki dua fungsi standar yang membantu dalam pengurai.strspn: memeriksa alfabet, karakter yang tersedia dalam string, secara dinamis mengkompilasi alfabet yang valid, meskipun diketahui pada tahap kompilasi program.strcasecmp(). Tidak perlu untuk kasus mengkonversi untuk membandingkan xdengan Foo:. Dalam kebanyakan kasus strcasecmp(), hanya kepatuhan / ketidakpatuhan yang diperlukan untuk , dan Anda tidak perlu mengetahui posisi di baris tersebut.
Mereka bekerja dengan lambat. Mari kita lihat tolok ukur dan pahami apa yang salah dengan mereka.Parser cepat
Ada beberapa pengurai.Nginx adalah parser paling sederhana, parser, yang ketat memeriksa kepatuhan RFC. Ada juga picoHTTPParser (H2O) dan parser Cloudflare. Mereka memproses data lebih cepat, tetapi dapat melewati karakter yang tidak diizinkan oleh RFC.PCMESTRI. Parser menggunakan beberapa pendekatan berbeda. Yang pertama adalah instruksi PCMESTRI, yang digunakan dalam pengurai Pico.Kami menetapkan rentang dalam instruksi. Sayangnya, kami dapat memuat 16 karakter atau 8 rentang. Jika rentang hanya terdiri dari satu karakter - ulangi saja. Karena keterbatasan ini, pengurai Pico tidak dapat sepenuhnya memverifikasi kepatuhan RFC, karena RFC memiliki lebih dari 8 rentang di lokasi ini. Kami memuat alfabet ke dalam register, memuat string, menjalankan instruksi. Di pintu keluar, kita cepat melihat apakah ada kebetulan atau tidak.AVX2 - Pendekatan CloudFlare. Parser CloudFlare, menggunakan AVX2, memproses 32 byte string pada suatu waktu, bukan 16 byte dengan pengurai Pico. Parsing lebih baik di CloudFlare karena ditransfer ke AVX2.
Kami memuat alfabet ke dalam register, memuat string, menjalankan instruksi. Di pintu keluar, kita cepat melihat apakah ada kebetulan atau tidak.AVX2 - Pendekatan CloudFlare. Parser CloudFlare, menggunakan AVX2, memproses 32 byte string pada suatu waktu, bukan 16 byte dengan pengurai Pico. Parsing lebih baik di CloudFlare karena ditransfer ke AVX2. Kami memeriksa semua karakter ke spasi di tabel ASCII, semua karakter lebih besar dari 128 dan mengambil rentang di antara mereka. Kode sederhana cepat.Bandingkan PCMESTRI dan AVX2. Bagi kami, batas saat ini adalah 1500. Ini adalah ukuran paket maksimum yang datang kepada kami. Kita melihat bahwa kode AVX2 pada data besar jauh lebih cepat daripada pengurai Pico. Tetapi bekerja lebih lambat pada data kecil, karena instruksi lebih berat di AVX2.
Kami memeriksa semua karakter ke spasi di tabel ASCII, semua karakter lebih besar dari 128 dan mengambil rentang di antara mereka. Kode sederhana cepat.Bandingkan PCMESTRI dan AVX2. Bagi kami, batas saat ini adalah 1500. Ini adalah ukuran paket maksimum yang datang kepada kami. Kita melihat bahwa kode AVX2 pada data besar jauh lebih cepat daripada pengurai Pico. Tetapi bekerja lebih lambat pada data kecil, karena instruksi lebih berat di AVX2. Sebanding dengan
Sebanding denganstrspn. Jika kita memutuskan untuk menggunakan strspn, segalanya menjadi lebih buruk, terutama pada data besar. Dalam parser "tempur" tidak dapat digunakan strspn.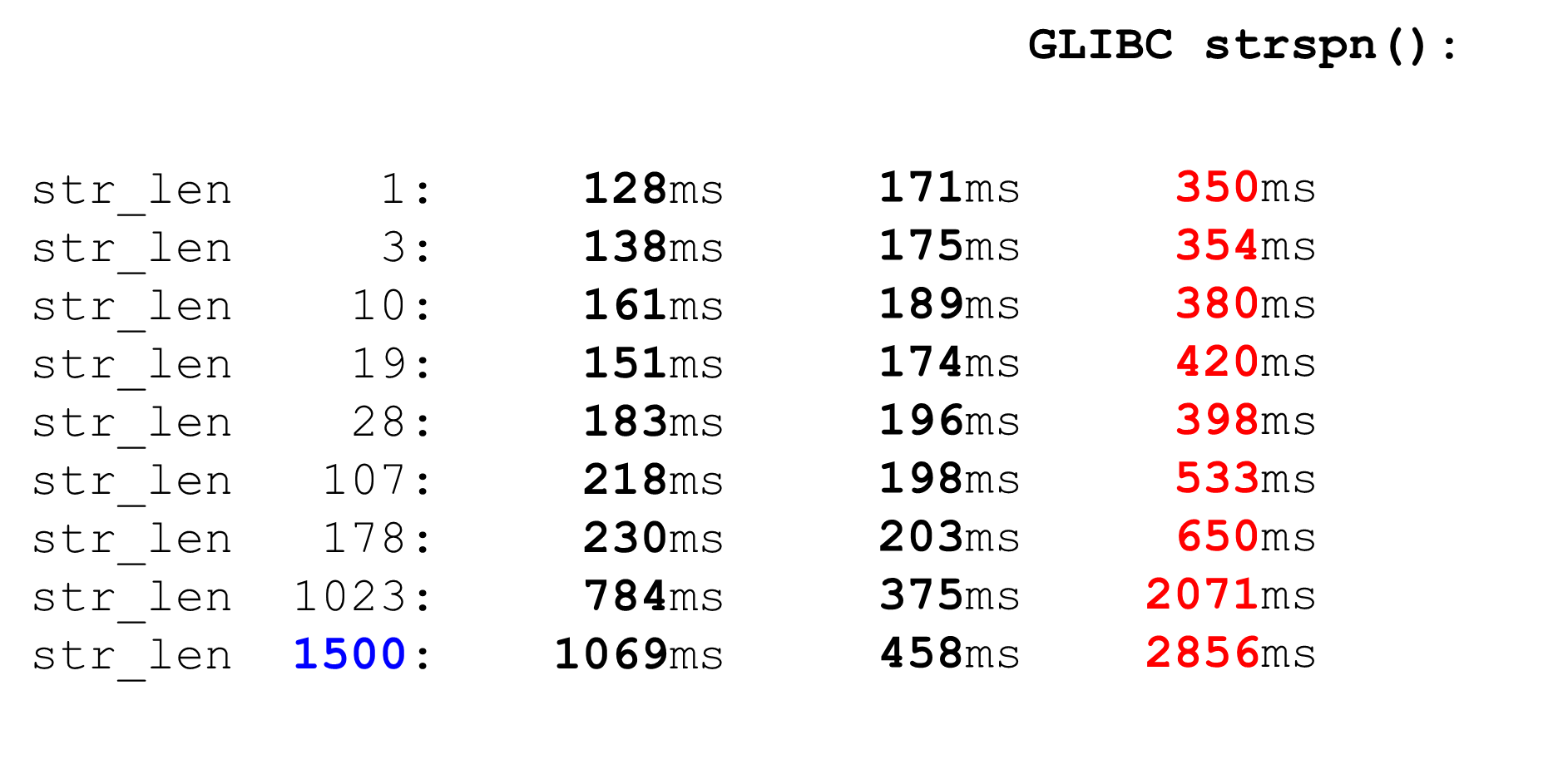
Pencocokan Tempesta lebih cepat dan lebih akurat
Pengurai kecepatan kami seperti keduanya. Pada data kecil, ini secepat Pico parser, pada CloudFlare besar. Namun, itu tidak melewati karakter yang tidak valid. Bagaimana pengaturan parser? Kami, sebagai nginx, mendefinisikan array byte dan memeriksa data input olehnya - ini adalah prolog fungsi. Di sini kami bekerja hanya dengan jangka pendek, kami menggunakannya
Bagaimana pengaturan parser? Kami, sebagai nginx, mendefinisikan array byte dan memeriksa data input olehnya - ini adalah prolog fungsi. Di sini kami bekerja hanya dengan jangka pendek, kami menggunakannya likelykarena salah prediksi cabang lebih menyakitkan untuk garis pendek daripada panjang. Kami mengambil kode ini. Kami memiliki batas 4 karena baris terakhir - kami harus menulis kondisi yang cukup kuat. Jika kami memproses lebih dari 4 byte, kondisinya akan lebih sulit dan kodenya lebih lambat.static const unsigned char uri_a[] __attribute__((aligned(64))) = {
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
if (likely(len <= 4)) {
switch (len) {
case 0:
return 0;
case 4:
c3 = uri_a[s[3]];
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
return (c0 & c1) == 0 ? c0 : 2 + (c2 ? c2 + c3 : 0);
}
Loop utama dan ekor besar. Dalam siklus pemrosesan utama, kami membagi data: jika cukup lama, kami memproses 128, 64, 32, atau 16 byte masing-masing. Masuk akal untuk memproses masing-masing 128: secara paralel, kami menggunakan beberapa saluran prosesor (beberapa pipa) dan prosesor superscalar.for ( ; unlikely(s + 128 <= end); s += 128) {
n = match_symbols_mask128_c(__C.URI_BM, s);
if (n < 128)
return s - (unsigned char *)str + n;
}
if (unlikely(s + 64 <= end)) {
n = match_symbols_mask64_c(__C.URI_BM, s);
if (n < 64)
return s - (unsigned char *)str + n;
s += 64;
}
if (unlikely(s + 32 <= end)) {
n = match_symbols_mask32_c(__C.URI_BM, s);
if (n < 32)
return s - (unsigned char *)str + n;
s += 32;
}
if (unlikely(s + 16 <= end)) {
n = match_symbols_mask16_c(__C.URI_BM128, s);
if (n < 16)
return s - (unsigned char *)str + n;
s += 16;
}
Ekor. Akhir fungsi mirip dengan awal. Jika kita memiliki kurang dari 16 byte, maka kita memproses 4 byte dalam satu lingkaran, dan kemudian tidak lebih dari 3 byte pada akhirnya.while (s + 4 <= end) {
c0 = uri_a[s[0]];
c1 = uri_a[s[1]];
c2 = uri_a[s[2]];
c3 = uri_a[s[3]];
if (!(c0 & c1 & c2 & c3)) {
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + (c2 ? c2 + c3 : 0);
}
s += 4;
}
c0 = c1 = c2 = 0;
switch (end - s) {
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + c2;
Kami memuat topeng bit dan data - ini adalah algoritma utama dari tubuh utama fungsi. Kami menyajikan tabel ASCII (seperti pada gambar) dengan 16 baris dan 8 kolom. Pertama, kami menyandikan baris tabel kami di register pertama BM URI: baris pertama dan kedua.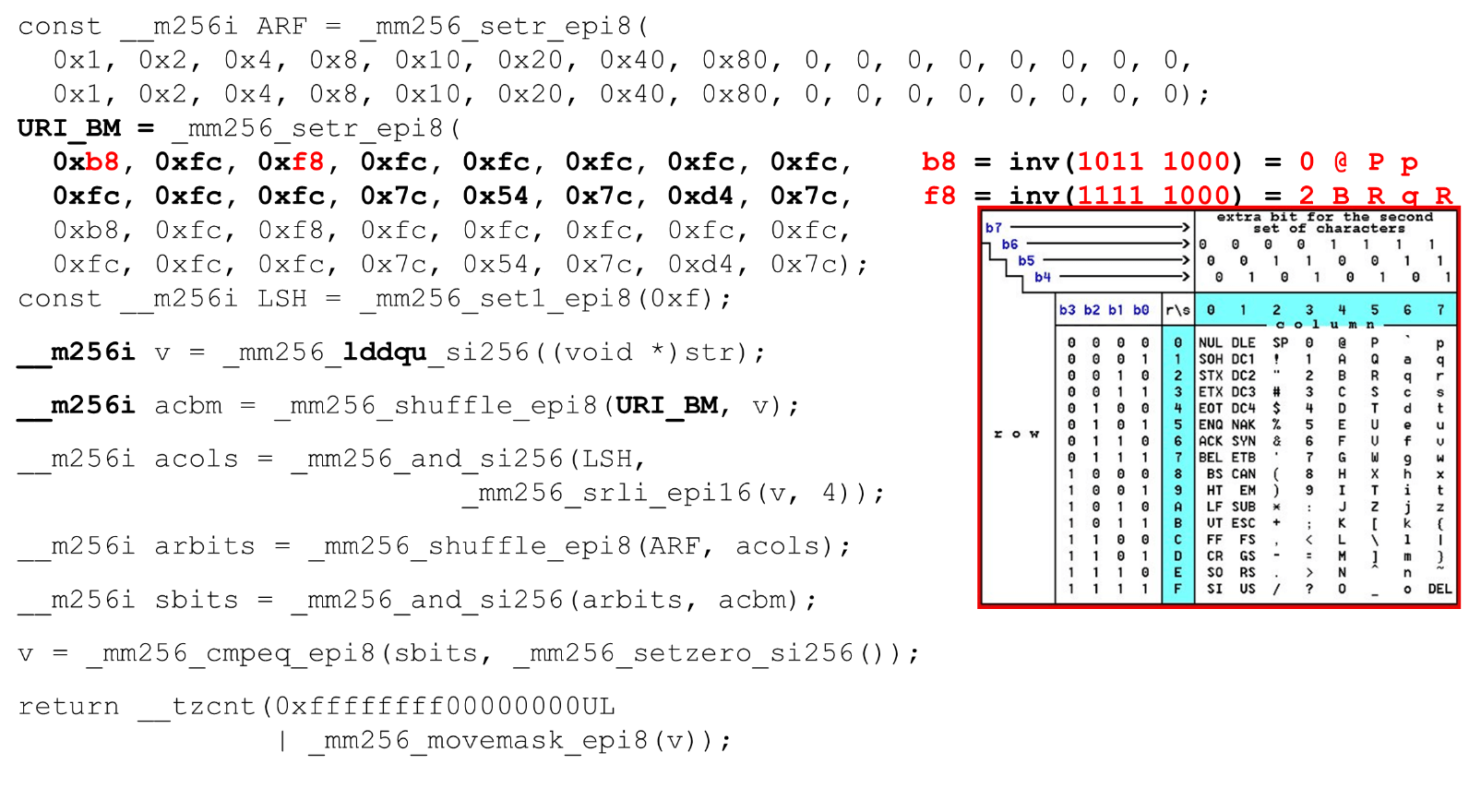 Simbol aktual yang kami izinkan adalah
Simbol aktual yang kami izinkan adalah 0 @ P pdan 2 B R q R. Mereka dikodekan sebagai berikut: b8 = inv(1011 1000) = 0 @ P p, f8 = inv(1111 1000) = 2 B R q R.Kami menyandikan dalam urutan terbalik: kita mulai dari 0, karakter layanan pertama tidak diperbolehkan, dan kemudian unit adalah apa yang diizinkan.Atur bit ASCII mask. Misalnya, sebuah baris muncul "pr": karakter pertama dari baris pertama adalah ASCII, yang kedua dari baris kedua. Kami menjalankan pernyataan acak, yang mengocok baris tabel kami yang disandikan sesuai dengan urutan karakter ini dalam input. ID kolom untuk input. Selanjutnya, kami menempatkan kolom tabel ASCII di register yang berbeda. Kemudian kita "melewati" register kolom dan baris, dan kita mendapatkan korespondensi: karakter kita atau tidak.Karena kolom adalah 4 bit paling signifikan dari byte, kami bergeser ke kiri. AVX memiliki offset hanya 2 byte, jadi pertama-tama ubah byte, lalu n dengan mask kami untuk mendapatkan bit yang signifikan saja.
ID kolom untuk input. Selanjutnya, kami menempatkan kolom tabel ASCII di register yang berbeda. Kemudian kita "melewati" register kolom dan baris, dan kita mendapatkan korespondensi: karakter kita atau tidak.Karena kolom adalah 4 bit paling signifikan dari byte, kami bergeser ke kiri. AVX memiliki offset hanya 2 byte, jadi pertama-tama ubah byte, lalu n dengan mask kami untuk mendapatkan bit yang signifikan saja. Mengatur Kolom ASCII Jalankan pengocokan kedua, pindahkan kolom ke posisi yang diinginkan. Dalam kedua kasus, input byte dari kolom terakhir, jadi di posisi pertama dan kedua kita mendapatkan kolom yang sama.
Mengatur Kolom ASCII Jalankan pengocokan kedua, pindahkan kolom ke posisi yang diinginkan. Dalam kedua kasus, input byte dari kolom terakhir, jadi di posisi pertama dan kedua kita mendapatkan kolom yang sama.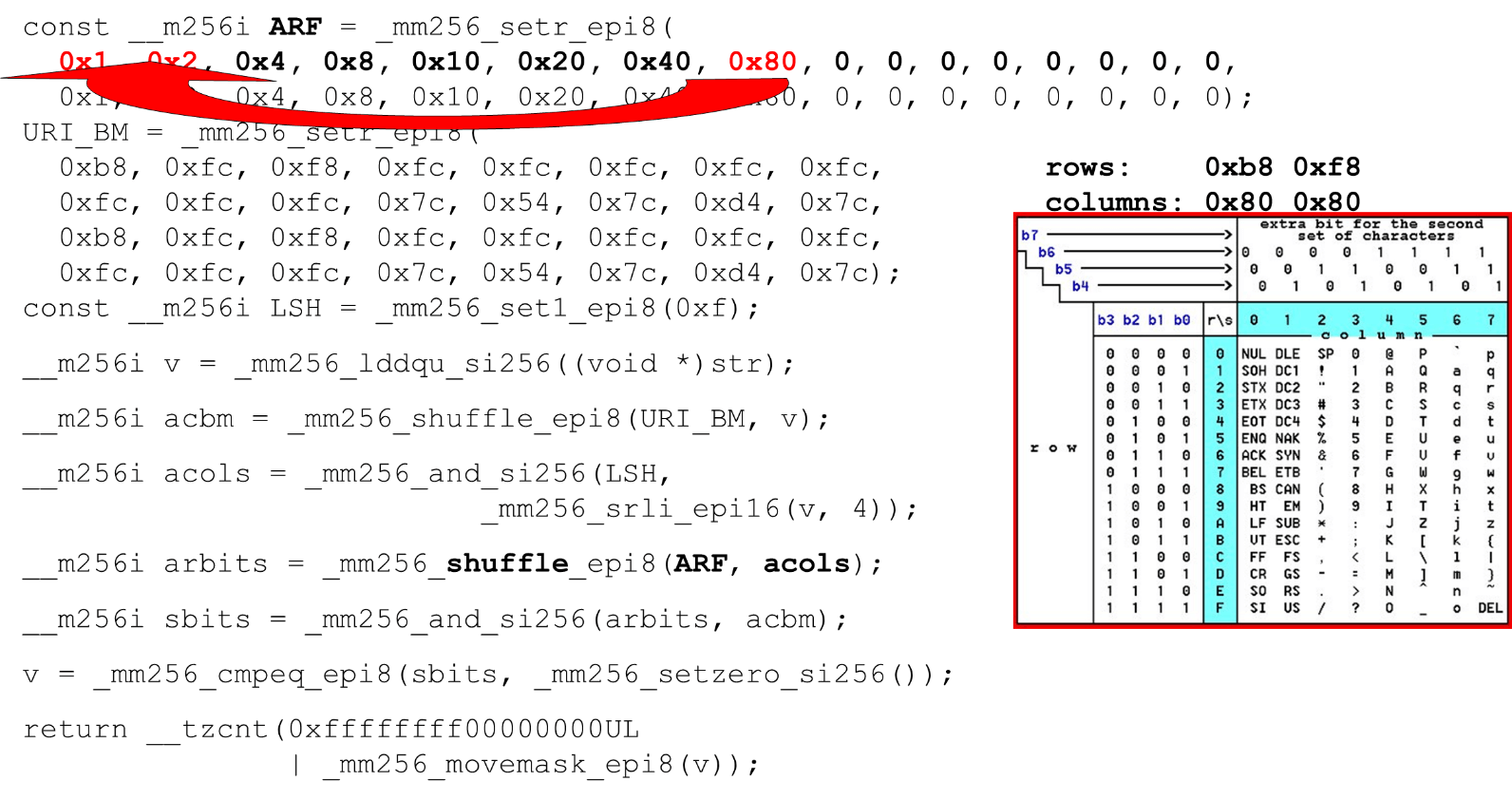 Persimpangan kolom dan barisan topeng . Kami melakukan
Persimpangan kolom dan barisan topeng . Kami melakukan and("lintas" kolom dengan kolom) dan kami mendapatkan bahwa data input valid - hasilnyaanddari persimpangan kolom dan baris bukan nol. Hitung jumlah nol di bagian akhir. Kami mengumpulkan semuanya dari vektor masuk
Hitung jumlah nol di bagian akhir. Kami mengumpulkan semuanya dari vektor masuk intdan mengembalikannya ke output - cukup sederhana.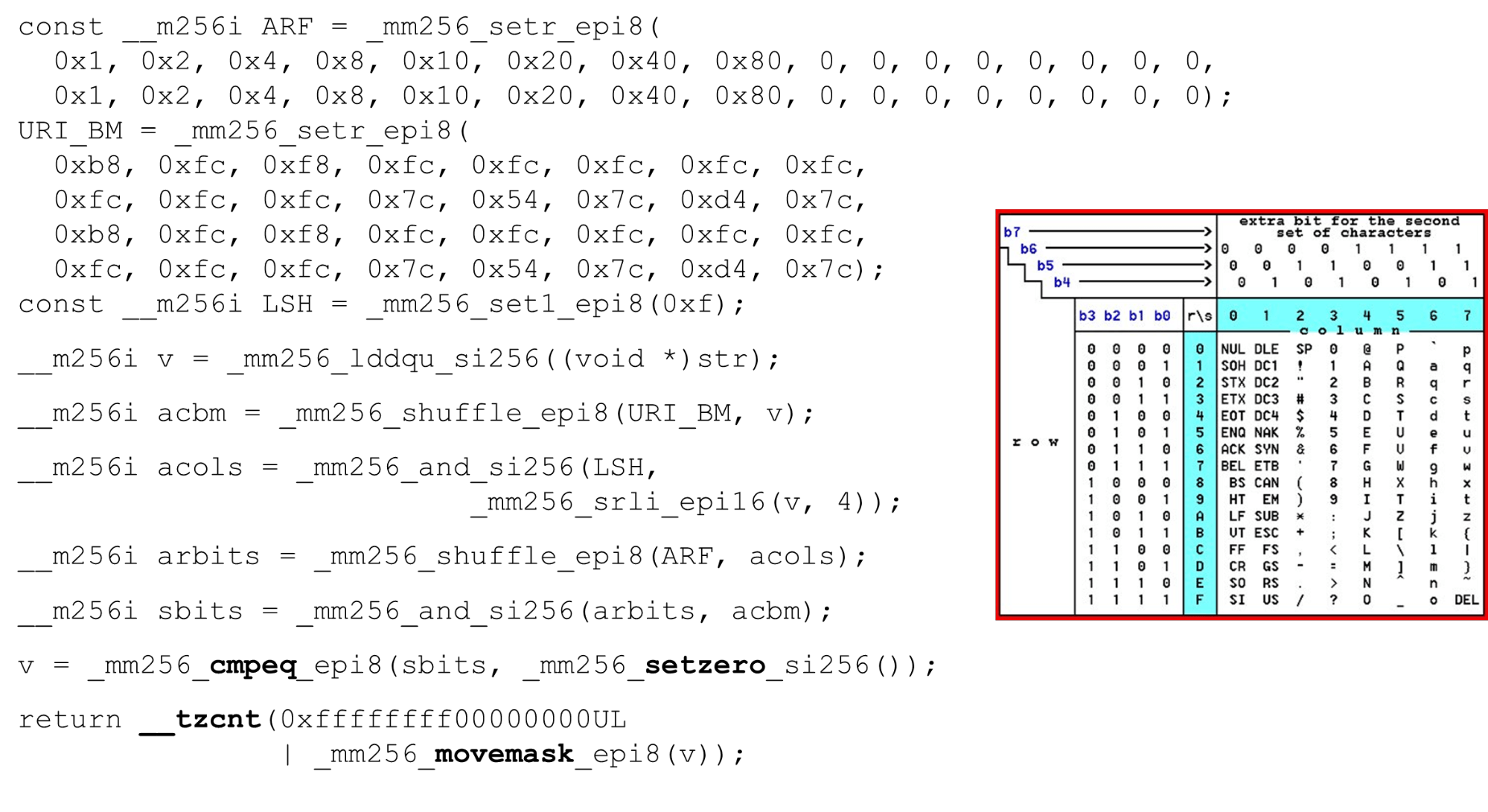 Sesuaikan huruf. Bekerja dengan tabel ASCII, kami mendapatkan fitur murah: kami menggunakan tabel statis, tetapi tidak ada yang menghalangi kami untuk menanyakan kepada pengguna alfabet apa yang tersedia untuk URI, nama dan nilai header yang berbeda. Permintaan HTTP URI dan header menggunakan 8 huruf (plus atau minus) untuk menguraikan satu permintaan HTTP. Tabel-tabel ini dapat dimuat ke dalam kode yang sama dan dibandingkan dalam alfabet tunggal yang ditentukan oleh pengguna, sebuah URI yang valid. Jika tidak, ini berbeda.
Sesuaikan huruf. Bekerja dengan tabel ASCII, kami mendapatkan fitur murah: kami menggunakan tabel statis, tetapi tidak ada yang menghalangi kami untuk menanyakan kepada pengguna alfabet apa yang tersedia untuk URI, nama dan nilai header yang berbeda. Permintaan HTTP URI dan header menggunakan 8 huruf (plus atau minus) untuk menguraikan satu permintaan HTTP. Tabel-tabel ini dapat dimuat ke dalam kode yang sama dan dibandingkan dalam alfabet tunggal yang ditentukan oleh pengguna, sebuah URI yang valid. Jika tidak, ini berbeda.Serangan
Beberapa kasus saat ini mungkin bermanfaat.Serangan SSRF dengan BlackHat'17 ("Era Baru SSRF"): http://foo@evil.com:80@google.com/- simbol ampersand yang tidak mungkin. Dalam beberapa aplikasi digunakan, dalam beberapa tidak. Tetapi jika Anda tidak menggunakannya, Anda dapat mengecualikannya dari alfabet yang valid dan serangan itu akan diblokir.RCE-serangan: «efektif adalah melakukan serangan injeksi perintah seperti», BSides'16: User-Agent: ...;echo NAELBD$((26+58))$echo(echo NAELBD)NAELBD.... User-Agent adalah header statis, tetapi ada kasus serangan RCE ketika beberapa datang shelldengan karakter atipikal untuk User-Agent. Kami melindungi diri sendiri kecuali tanda dolar.Path Relative Timpa . Kasus terakhir adalah apa yang dimiliki Google pada tahun 2016. Kurung kurawal, titik dua, datang ke URI .../gallery?q=%0a{}*{background:red}/..//apis/howto_guide.html. Ini adalah karakter yang tidak mungkin yang dapat dikeluarkan dari alfabet.strcasecmp ()
Ini adalah kode yang cukup sepele. Kami juga membandingkan string 32 byte, masing-masing dua array.__m256i CASE = _mm256_set1_epi8(0x20);
__m256i A = _mm256_set1_epi8('A' – 0x80);
__m256i D = _mm256_set1_epi8('Z' - 'A' + 1 – 0x80);
__m256i sub = _mm256_sub_epi8(str1, A);
__m256i cmp_r = _mm256_cmpgt_epi8(D, sub);
__m256i lc = _mm256_and_si256(cmp_r, CASE);
__m256i vl = _mm256_or_si256(str1, lc);
__m256i eq = _mm256_cmpeq_epi8(vl, str2);
return ~_mm256_movemask_epi8(eq);
Kami hanya memberi register satu baris, karena pada baris kedua kami memprogram konstanta dalam parser dalam huruf kecil. Karena kami memiliki perbandingan yang signifikan, kami mengurangi 128 dari setiap byte (sebuah trik dari Hacker's Delight).Kami juga membandingkan rentang karakter yang valid: apakah kami dapat mendaftar untuk string ini atau tidak, apakah itu huruf atau tidak. Pada saat memeriksa ini, alih-alih dua perbandingan dari a ke z, kita hanya dapat menggunakan satu perbandingan (trik dari Hacker's Delight) dan beralih ke konstanta.Kinerja strcasecmp ()
Tempesta jauh lebih cepat daripada GLIBC, bahkan versi baru (18 atau 19). Kode ini strcasecmp()juga menggunakan AVX, tetapi bukan versi kedua. AVX2 lebih cepat, jadi Tempesta memiliki kode lebih cepat.
FPU kernel Linux
Kami menggunakan ekstensi prosesor vektor - tersedia di kernel. Instruksi vektor diproses oleh modul prosesor FPU. Ini bukan modul prosesor utama, bukan register utama, tetapi cukup produktif.Karena itu, ada optimasi di Linux. Jika kita beralih dari kernel ke ruang pengguna dan kembali, kami tidak menyimpan konteks register FPU (XMM, YMM, ZMM): kami mengubah konteks hanya register dari modul prosesor utama. Diasumsikan bahwa kernel OS tidak bekerja dengan ekstensi vektor prosesor. Tetapi jika Anda membutuhkannya, misalnya, kriptografi dapat melakukannya, tetapi perlu menggunakan fpu_begindan fpu_endmenyimpan serta memulihkan konteks register FPU:__kernel_fpu_begin_bh();
memcpy_avx(dst, src, n);
__kernel_fpu_end_bh();
Ini adalah makro asli yang menyimpan dan mengembalikan status modul prosesor , yang bertanggung jawab untuk register vektor. Ini adalah sumber daya yang cukup lambat.AVX dan SSE
Sebelum tolok ukur menyimpan dan memulihkan konteks FPU, beberapa kata tentang operasi vektor. Mengapa terkadang masuk akal untuk bekerja dengan assembler? Terkadang GCC menghasilkan kode suboptimal. Masalahnya adalah bahwa pada model prosesor yang lebih lama, ada penalti yang signifikan dari transisi dari SSE ke AVX. GCC memiliki kunci baru vzeroupper- gunakanlah sehingga tidak menghasilkan instruksi ini vzeroupper, yang menghapus register dan menghapus hukuman ini.Anda perlu menggunakan instruksi ini hanya jika Anda bekerja dengan kode lama yang dikompilasi untuk SSE oleh beberapa pihak ketiga. Ini bukan kasus kami dan kami dapat dengan aman membuang instruksi ini.FPU
Kami memiliki vektorisasi otomatis di prosesor. Ini berarti bahwa dalam kode ruang pengguna mana pun akan ada operasi vektor. Dua proses dalam sistem menggunakan ekstensi prosesor vektor. Ketika proses Anda menuju ke kernel dan kembali, Anda tidak membuang waktu menghemat dan mengembalikan keadaan vektor prosesor. Tetapi jika Anda beralih dari satu ruang pengguna ke yang lain (saklar konteks), maka selain fakta bahwa cache tingkat pertama dinonaktifkan di sana, modul sakelar konteks pada FPU mulai / berakhir juga bekerja dengan buruk. Operasi ini cukup mahal - microbenchmark.Dalam microbenchmark, semuanya selalu dramatis, tetapi operasinya sangat mahal. Oleh karena itu, di ruang pengguna, alihkan konteks untuk waktu yang lama. Di kernel, kami tidak memiliki pengalihan konteks, jadi semuanya cepat. Kami menyimpan dan mengembalikan prosesor vektor hanya sekali untuk paket yang cukup besar.
Dua proses dalam sistem menggunakan ekstensi prosesor vektor. Ketika proses Anda menuju ke kernel dan kembali, Anda tidak membuang waktu menghemat dan mengembalikan keadaan vektor prosesor. Tetapi jika Anda beralih dari satu ruang pengguna ke yang lain (saklar konteks), maka selain fakta bahwa cache tingkat pertama dinonaktifkan di sana, modul sakelar konteks pada FPU mulai / berakhir juga bekerja dengan buruk. Operasi ini cukup mahal - microbenchmark.Dalam microbenchmark, semuanya selalu dramatis, tetapi operasinya sangat mahal. Oleh karena itu, di ruang pengguna, alihkan konteks untuk waktu yang lama. Di kernel, kami tidak memiliki pengalihan konteks, jadi semuanya cepat. Kami menyimpan dan mengembalikan prosesor vektor hanya sekali untuk paket yang cukup besar.Intelpocalypse
Pada awalnya, saya menunjukkan opsi tabel pencarian untuk mengoptimalkan kode switch: proses panjang, enum, kompilasi tabel switch ke dalam array dan ikuti dereferencing ganda dari pointer yang melompati array ini. Ini adalah skenario untuk serangan Spectre yang mengeksploitasi eksekusi spekulatif.Google memiliki artikel yang bagus tentang bagaimana pointer dereferensi ganda dalam kompiler modern diatur sekarang (sejak awal 2018). Itu tidak bekerja dengan baik. Jika sebelumnya dalam register beberapa alamat disimpan dan kami pergi ke alamat ini, sekarang kami memiliki kode yang berbeda.jmp *%r11
call l1
l0: pause
lfence
jmp l0
l1: mov %r11, (%rsp)
ret
Bagaimana cara kerjanya? Kami “memanggil” fungsi pada l1, prosesnya masuk ke label ini dan kami membuat peretasan: seolah-olah kita kembali dari fungsi (yang tidak), tetapi kami menulis ulang alamat pengirim. Ketika kita melakukan instruksi call, kita menempatkan alamat pengirim, alamat saat ini di tumpukan, menulis ulang dengan isi register yang diperlukan dan pergi ke l1. Tetapi prosesor, ketika prefetcher-nya berjalan, melihat bahwa ada fungsi, dan kemudian penghalang. Karena itu, semuanya akan lambat - ia membuang prefetching dan kami menyingkirkan kerentanan Spectre. Kode ini lambat, kinerja turun 15%.Serangan relatif baru berikutnya adalah Meltdown.. Ini khusus untuk proses ruang pengguna saja. Sangat menyakitkan membaca memori kernel dari ruang pengguna. Serangan dicegah oleh Isolasi Kernel Pate Table (KPTI), yang mengkompilasi kernel baru secara default. Tetapi KPTI sangat mahal, hingga 30-40% penurunan kinerja ( seperti yang diukur oleh MariaDB ).Ini disebabkan oleh kenyataan bahwa Anda tidak lagi memiliki malas optimasi TLB: ruang alamat kernel dan prosesor sepenuhnya dipisahkan dalam tabel halaman yang berbeda (sebelumnya, malas TLB terus memetakan ruang kernel ke tabel halaman setiap proses). Ini menyakitkan untuk ruang pengguna, tetapi tidak untuk Tempesta FW, yang bekerja sepenuhnya di kernel.Beberapa tautan bermanfaat:Saint HighLoad++ . , 6 -- ( , Saint HighLoad++) , web .
PHP Russia: 13 , . — KnowledgeConf, ++ TechLead Conf — . , , .