Halo, Habr! Saya ingin memberi tahu Anda bagaimana kami menulis dan mengimplementasikan layanan untuk memantau kualitas data. Kami memiliki banyak sumber data: data dari pasar keuangan, aktivitas perdagangan pelanggan kami, kutipan dan banyak lagi. Semua ini menghasilkan milyaran catatan per hari dalam proses kami. Kelengkapan dan konsistensi data perdagangan adalah komponen penting dari bisnis Exness.Jika Anda dekat dengan masalah jaminan kualitas data dan tertarik pada bagaimana kami menyelesaikan masalah ini di rumah, maka selamat datang di cat. Nama saya Dmitry, saya bekerja di sebuah tim yang menyimpan data mentah dan transformasi, agregasi dan penyediaan semua data perusahaan yang diproses untuk semua departemen perusahaan. Data kami dikonsumsi oleh banyak tim dalam perusahaan, seperti Business Intelligence, Anti-Fraud, Keuangan, dan kami juga memberikannya kepada mitra b2b kami.Bekerja dengan data adalah misi yang bertanggung jawab dan sulit, karena menghentikan satu proses ETL dapat menyebabkan kelumpuhan bagian dari bisnis Exness. Untuk mengatasi masalah ETL, kami menggunakan berbagai alat:
Nama saya Dmitry, saya bekerja di sebuah tim yang menyimpan data mentah dan transformasi, agregasi dan penyediaan semua data perusahaan yang diproses untuk semua departemen perusahaan. Data kami dikonsumsi oleh banyak tim dalam perusahaan, seperti Business Intelligence, Anti-Fraud, Keuangan, dan kami juga memberikannya kepada mitra b2b kami.Bekerja dengan data adalah misi yang bertanggung jawab dan sulit, karena menghentikan satu proses ETL dapat menyebabkan kelumpuhan bagian dari bisnis Exness. Untuk mengatasi masalah ETL, kami menggunakan berbagai alat: Tantangan yang kami hadapi setiap hari:
Tantangan yang kami hadapi setiap hari:- Puluhan juta catatan transaksi setiap hari;
- Billion entri pasar setiap hari (penawaran, dll.);
- Heterogenitas sumber data (seperti sumber eksternal Data Pasar, platform perdagangan yang berbeda);
- Memberikan semantik satu kali untuk data penting (transaksi keuangan);
- Memastikan integritas dan kelengkapan data;
- Memberikan jaminan bahwa untuk waktu yang ditentukan transaksi akan ditambahkan ke semua tabel dan agregat yang diperlukan.
Untuk memberikan jaminan semacam itu, perlu dipelajari untuk melacak, mengukur, dan secara proaktif merespons penyimpangan dalam kualitas data itu sendiri.Mengingat kerumitan proses pengumpulan dan pemrosesan data kami, mengingat kecepatan tinggi pengembangan dan modifikasi proses ETL, menjadi perlu untuk memantau kualitas data yang sudah pada titik akhir. Kami biasanya memiliki database Clickhouse atau PostgreSQL. Metrik seperti itu akan memberi tahu kita seberapa cepat proses kita bekerja:SELECT server,
avg(updated - close_time)
FROM trades
WHERE close_time > subtractHours(Now(), 2)
GROUP BY server
Mereka akan membantu menemukan duplikat dalam data (tidak ada kendala unik di Clickhouse):SELECT SUM(count) FROM (
SELECT
COUNT(*) AS count
FROM trades
GROUP BY order_id
HAVING count > 1
)
Anda dapat menghasilkan satu ton kueri (banyak yang sudah kami gunakan) yang membantu memantau kualitas data: membandingkan jumlah baris di tabel sumber dan tabel tujuan, waktu penyisipan terakhir dalam tabel, membandingkan konten dua kueri dan banyak lagi.Metrik adalah gejala. Sendiri, mereka tidak menunjukkan penyebab masalah, tetapi memungkinkan kami untuk menunjukkan bahwa ada masalah. Ini akan menjadi pemicu bagi insinyur untuk memperhatikan masalah dan mengidentifikasi akar penyebabnya. Analogi: jika seseorang memiliki suhu, maka ada sesuatu yang rusak di tubuhnya. Suhu adalah gejala yang cukup untuk mulai memahami dan menemukan penyebab kerusakan.Kami mencari solusi siap pakai yang dapat mengumpulkan metrik gejala seperti itu untuk kami. Persyaratan kami:- Dukungan untuk berbagai sumber data (database, antrian, http-permintaan);
- ;
- ( , );
- .
Di awal artikel, saya mendaftarkan teknologi yang kami gunakan di ETL. Seperti yang Anda lihat, kami adalah pendukung solusi open-source! Salah satu contoh: kami menggunakan database Clickhouse yang berorientasi kolom sebagai gudang data utama. Tim kami melakukan perubahan pada kode sumber Clickhouse beberapa kali (terutama memperbaiki bug). Sebagai alat untuk bekerja dengan metrik dan seri waktu, kami menggunakan: ekosistem influxdb, metrik prometheus dan victoria, zabbix.Yang mengejutkan kami, ternyata tidak ada alat yang siap pakai dan nyaman untuk memantau kualitas data yang sesuai dengan teknologi yang kami pilih. Atau apakah kita terlihat buruk?Ya, zabbix memiliki kemampuan untuk menjalankan Skrip Kustom , dan telegrafAnda bisa mengajarkan cara menjalankan kueri SQL dan mengubah hasilnya menjadi metrik. Tetapi ini membutuhkan penyelesaian yang serius, dan tidak berhasil seperti yang kita inginkan. Karena itu, kami menulis layanan kami sendiri (daemon) untuk memantau kualitas data. Temui saraf!Fitur saraf
Secara ideologis, saraf dapat digambarkan dengan frasa berikut:Ini adalah layanan yang menjalankan tugas terjadwal, heterogen, dan disesuaikan untuk mengumpulkan nilai numerik, dan menyajikan hasilnya sebagai metrik untuk berbagai sistem pengumpulan metrik.
Fitur utama dari program:- Dukungan untuk berbagai jenis tugas: Permintaan, CompareQueries, dll.
- Kemampuan untuk menulis jenis tugas Anda di Python sebagai plugin runtime;
- Bekerja dengan berbagai jenis sumber daya: Clickhouse, Postgres, dll.
- Metrik data model, seperti pada prometheus
metric_name{label="value"} 123.3 ;
- pull prometheus;
- : crontab-style;
- WEB UI ;
- yaml ;
- Twelve-Factor App.
Tugas dan Sumber Daya adalah entitas dasar untuk mengkonfigurasi dan bekerja dengan keberanian. Tugas - tindakan berkala yang diketik, sebagai hasilnya kami mendapatkan metrik. Sumber Daya - objek yang berisi konfigurasi dan logika khusus untuk bekerja dengan sumber data tertentu. Mari kita lihat bagaimana saraf bekerja dengan sebuah contoh.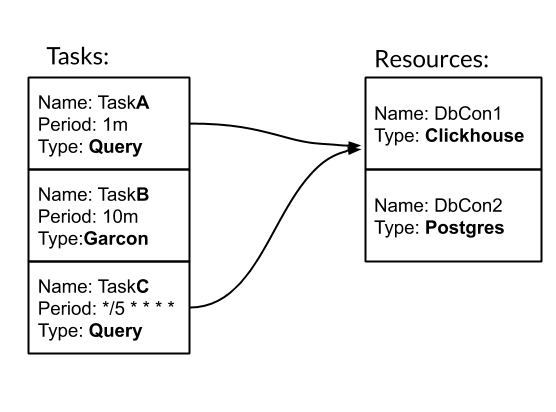 Kami memiliki tiga tugas. Dua di antaranya bertipe Query - SQL query. Salah satunya adalah tipe Garcon - ini adalah tugas khusus yang masuk ke salah satu layanan kami. Frekuensi tugas dapat diatur oleh periode waktu. Misalnya, 10m berarti setiap sepuluh menit sekali. Atau gaya crontab "* / 5 * * * *" - setiap menit penuh kelima. Tugas TaskA dan TaskC dikaitkan dengan sumber DbCon1, yang merupakan tipe Clickhouse. Mari kita lihat bagaimana konfigurasi akan terlihat:
Kami memiliki tiga tugas. Dua di antaranya bertipe Query - SQL query. Salah satunya adalah tipe Garcon - ini adalah tugas khusus yang masuk ke salah satu layanan kami. Frekuensi tugas dapat diatur oleh periode waktu. Misalnya, 10m berarti setiap sepuluh menit sekali. Atau gaya crontab "* / 5 * * * *" - setiap menit penuh kelima. Tugas TaskA dan TaskC dikaitkan dengan sumber DbCon1, yang merupakan tipe Clickhouse. Mari kita lihat bagaimana konfigurasi akan terlihat:tasks:
- name: TaskA
type: Query
resources: DbCon1
period: 1m
config:
query: SELECT COUNT(*) FROM ticks
gauge: metric_count{table="ticks"}
- name: TaskB
type: Garcon
period: 10m
config:
url: "http://hostname:9003/api/v1/orders/backups/"
gauge: backup_ago
- name: TaskC
type: Query
period: "*/5 * * * *"
resources: DbCon1
config:
query: SELECT now() - toDateTime(time_msc/1000)
FROM deals WHERE trade_server= 'Real'
ORDER BY deal DESC LIMIT 1
gauge: orders_lag
resources:
- name: DbCon1
type: Clickhouse
config:
host: clickhouse.env
port: 9000
user: readonly
password: "***"
database: data
results:
common_labels:
env="prod"
task_types_paths:
- "./tasks"
Jalur "./tasks" adalah jalur ke tugas yang disesuaikan. Secara khusus, jenis tugas Garcon didefinisikan di sana. Dalam artikel ini saya akan menghilangkan momen membuat jenis tugas saya.Sebagai hasil dari meluncurkan layanan saraf dengan konfigurasi seperti itu, di WEB UI akan dimungkinkan untuk memantau bagaimana tugas dipenuhi: Dan di / metrik metrik untuk pengumpulan akan tersedia:
Dan di / metrik metrik untuk pengumpulan akan tersedia: Jenis tugas kueri yang paling sering digunakan dalam tim kami. Karenanya, kami telah memperluas kemampuannya untuk bekerja dengan GROUP BY dan templat. Mekanisme ini memungkinkan untuk mengumpulkan banyak informasi tentang data dengan satu permintaan sekaligus:
Jenis tugas kueri yang paling sering digunakan dalam tim kami. Karenanya, kami telah memperluas kemampuannya untuk bekerja dengan GROUP BY dan templat. Mekanisme ini memungkinkan untuk mengumpulkan banyak informasi tentang data dengan satu permintaan sekaligus: Tugas TradesLag akan mengumpulkan keterlambatan maksimum untuk pesanan tertutup untuk memasuki tabel perdagangan setiap lima menit, dengan mempertimbangkan hanya pesanan yang ditutup dalam dua jam terakhir.Beberapa kata tentang implementasinya. Nerve adalah aplikasi multi-threaded python3 ~ 3k LoC yang mudah dijalankan melalui Docker, melengkapinya dengan konfigurasi tugas.
Tugas TradesLag akan mengumpulkan keterlambatan maksimum untuk pesanan tertutup untuk memasuki tabel perdagangan setiap lima menit, dengan mempertimbangkan hanya pesanan yang ditutup dalam dua jam terakhir.Beberapa kata tentang implementasinya. Nerve adalah aplikasi multi-threaded python3 ~ 3k LoC yang mudah dijalankan melalui Docker, melengkapinya dengan konfigurasi tugas.Apa yang terjadi
Dengan keberanian, kami mendapatkan apa yang kami inginkan. Saat ini, selain tim kami, tim lain di Exness telah menunjukkan minat padanya. Ini berputar sekitar 40 tugas dengan frekuensi 30 detik hingga sehari. Saraf mengumpulkan sekitar 500 metrik tentang data kami. Menambahkan metrik baru adalah masalah 5-10 menit. Aliran kerja penuh dengan metrik terlihat seperti ini: nervus → prometheus → Victoria Metrics → Dasbor Grafana → Alerts di PagerDuty.Dengan keberanian, kami juga mulai mengumpulkan metrik bisnis: kami secara berkala memilih peristiwa mentah dalam sistem perdagangan untuk mengevaluasi kondisi perdagangan.Terima kasih, warga Khabrovsk, untuk membaca artikel saya sampai akhir. Saya memperkirakan pertanyaan Anda: di mana tautan ke github? Jawabannya adalah ini: kami belum memposting keberanian di Open Source. Ini membutuhkan pekerjaan tambahan di pihak kami untuk meningkatkan dokumentasi dan menyelesaikan beberapa fitur. Jika artikel ini diterima dengan baik oleh komunitas, ini akan memberi kami insentif tambahan untuk berbagi perkembangan kami dengan Anda!Baik untuk semua!