Kenari adalah burung kecil yang terus-menerus bernyanyi. Burung-burung ini sensitif terhadap metana dan karbon monoksida. Bahkan dari konsentrasi kecil gas-gas berlebih di udara, mereka kehilangan kesadaran atau mati. Penambang emas dan penambang mengambil burung untuk dimangsa: sementara burung kenari bernyanyi, Anda dapat bekerja, jika Anda tutup mulut, ada gas di tambang dan saatnya untuk pergi. Penambang mengorbankan seekor burung kecil untuk keluar dari tambang hidup-hidup. Praktik serupa telah ditemukan di TI. Misalnya, dalam tugas standar menggunakan versi baru dari layanan atau aplikasi untuk produksi dengan pengujian sebelum itu. Lingkungan pengujian bisa terlalu mahal, pengujian otomatis tidak mencakup semua yang kami inginkan, dan berisiko untuk menguji dan mengorbankan kualitas. Hanya dalam kasus seperti itu, pendekatan Canary Deployment membantu, ketika sedikit lalu lintas produksi nyata diluncurkan pada versi baru. Pendekatan ini membantu untuk aman menguji versi baru untuk produksi, mengorbankan hal-hal kecil untuk tujuan besar. Secara lebih rinci, bagaimana pendekatan itu bekerja, apa yang berguna dan bagaimana mengimplementasikannya, akan memberi tahu Andrey Markelov (Andrey_V_Markelov), menggunakan contoh implementasi di Infobip.Andrey Markelov , seorang insinyur perangkat lunak terkemuka di Infobip, telah mengembangkan aplikasi Java di bidang keuangan dan telekomunikasi selama 11 tahun. Dia mengembangkan produk-produk Open Source, berpartisipasi aktif dalam Komunitas Atlassian dan menulis plugin untuk produk-produk Atlassian. Evangelist Prometheus, Docker, dan Redis.
Praktik serupa telah ditemukan di TI. Misalnya, dalam tugas standar menggunakan versi baru dari layanan atau aplikasi untuk produksi dengan pengujian sebelum itu. Lingkungan pengujian bisa terlalu mahal, pengujian otomatis tidak mencakup semua yang kami inginkan, dan berisiko untuk menguji dan mengorbankan kualitas. Hanya dalam kasus seperti itu, pendekatan Canary Deployment membantu, ketika sedikit lalu lintas produksi nyata diluncurkan pada versi baru. Pendekatan ini membantu untuk aman menguji versi baru untuk produksi, mengorbankan hal-hal kecil untuk tujuan besar. Secara lebih rinci, bagaimana pendekatan itu bekerja, apa yang berguna dan bagaimana mengimplementasikannya, akan memberi tahu Andrey Markelov (Andrey_V_Markelov), menggunakan contoh implementasi di Infobip.Andrey Markelov , seorang insinyur perangkat lunak terkemuka di Infobip, telah mengembangkan aplikasi Java di bidang keuangan dan telekomunikasi selama 11 tahun. Dia mengembangkan produk-produk Open Source, berpartisipasi aktif dalam Komunitas Atlassian dan menulis plugin untuk produk-produk Atlassian. Evangelist Prometheus, Docker, dan Redis.Tentang Infobip
Ini adalah platform telekomunikasi global yang memungkinkan bank, pengecer, toko online, dan perusahaan transportasi untuk mengirim pesan kepada pelanggan mereka menggunakan SMS, push, surat dan pesan suara. Dalam bisnis seperti itu, stabilitas dan keandalan penting agar pelanggan menerima pesan tepat waktu.Infrastruktur TI Infobip dalam angka:- 15 pusat data di seluruh dunia;
- 500 layanan unik dalam operasi;
- 2500 contoh layanan, yang lebih dari sekadar tim;
- 4,5 TB lalu lintas bulanan;
- 4,5 miliar nomor telepon;
Bisnis ini berkembang, dan dengan itu jumlah rilis. Kami melakukan 60 rilis sehari , karena pelanggan menginginkan lebih banyak fitur dan kemampuan. Tetapi ini sulit - ada banyak layanan, tetapi sedikit tim. Anda harus dengan cepat menulis kode yang seharusnya berfungsi dalam produksi tanpa kesalahan.Rilis
Rilis khas dengan kami seperti ini. Misalnya, ada layanan A, B, C, D, dan E, masing-masing dikembangkan oleh tim terpisah.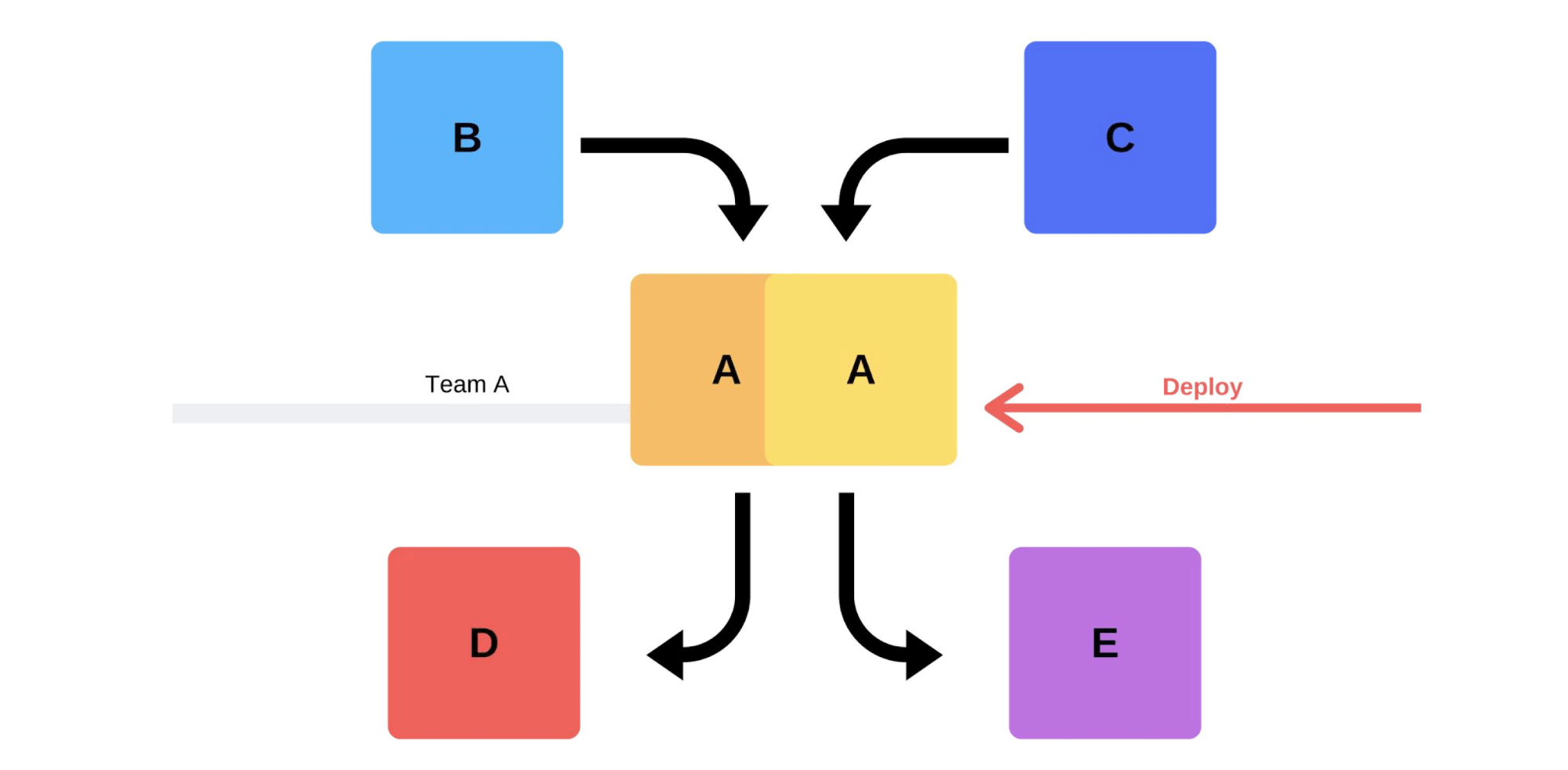 Pada titik tertentu, tim layanan A memutuskan untuk menggunakan versi baru, tetapi tim layanan B, C, D, dan E tidak mengetahui hal ini. Ada dua opsi untuk bagaimana tim layanan A tiba.Akan melakukan rilis tambahan: pertama itu akan menggantikan satu versi, dan kemudian yang kedua.
Pada titik tertentu, tim layanan A memutuskan untuk menggunakan versi baru, tetapi tim layanan B, C, D, dan E tidak mengetahui hal ini. Ada dua opsi untuk bagaimana tim layanan A tiba.Akan melakukan rilis tambahan: pertama itu akan menggantikan satu versi, dan kemudian yang kedua. Tetapi ada opsi kedua: tim akan menemukan kapasitas dan mesin tambahan , menyebarkan versi baru, dan kemudian beralih router, dan versi akan mulai bekerja pada produksi.
Tetapi ada opsi kedua: tim akan menemukan kapasitas dan mesin tambahan , menyebarkan versi baru, dan kemudian beralih router, dan versi akan mulai bekerja pada produksi. Bagaimanapun, hampir selalu akan ada masalah setelah penyebaran, bahkan jika versi diuji. Anda dapat mengujinya dengan tangan Anda, itu bisa otomatis, Anda tidak bisa mengujinya - masalah akan muncul dalam hal apa pun. Cara termudah dan paling benar untuk menyelesaikannya adalah memutar kembali ke versi yang berfungsi. Hanya dengan begitu Anda dapat menangani kerusakan, penyebabnya dan memperbaikinya.Jadi apa yang kita inginkan?Kami tidak membutuhkan masalah. Jika pelanggan menemukan mereka lebih cepat dari kami, itu akan memukul reputasi kami. Karena itu, kita harus menemukan masalah lebih cepat daripada pelanggan . Dengan bersikap proaktif, kami meminimalkan kerusakan.Pada saat yang sama, kami ingin mempercepat penyebaransehingga ini terjadi dengan cepat, mudah, dengan sendirinya dan tanpa tekanan dari tim. Insinyur, insinyur dan programmer DevOps harus dilindungi - rilis versi baru sangat menegangkan. Sebuah tim bukan merupakan bahan habis pakai, kami berusaha untuk secara rasional menggunakan sumber daya manusia .
Bagaimanapun, hampir selalu akan ada masalah setelah penyebaran, bahkan jika versi diuji. Anda dapat mengujinya dengan tangan Anda, itu bisa otomatis, Anda tidak bisa mengujinya - masalah akan muncul dalam hal apa pun. Cara termudah dan paling benar untuk menyelesaikannya adalah memutar kembali ke versi yang berfungsi. Hanya dengan begitu Anda dapat menangani kerusakan, penyebabnya dan memperbaikinya.Jadi apa yang kita inginkan?Kami tidak membutuhkan masalah. Jika pelanggan menemukan mereka lebih cepat dari kami, itu akan memukul reputasi kami. Karena itu, kita harus menemukan masalah lebih cepat daripada pelanggan . Dengan bersikap proaktif, kami meminimalkan kerusakan.Pada saat yang sama, kami ingin mempercepat penyebaransehingga ini terjadi dengan cepat, mudah, dengan sendirinya dan tanpa tekanan dari tim. Insinyur, insinyur dan programmer DevOps harus dilindungi - rilis versi baru sangat menegangkan. Sebuah tim bukan merupakan bahan habis pakai, kami berusaha untuk secara rasional menggunakan sumber daya manusia .Masalah Penempatan
Lalu lintas klien tidak dapat diprediksi . Tidak mungkin untuk memprediksi kapan lalu lintas klien akan minimal. Kami tidak tahu di mana dan kapan klien akan memulai kampanye mereka - mungkin malam ini di India, dan besok di Hong Kong. Mengingat perbedaan waktu yang besar, penyebaran bahkan pada pukul 2 pagi tidak menjamin bahwa pelanggan tidak akan menderita.Masalah penyedia . Utusan dan penyedia adalah mitra kami. Terkadang mereka mengalami kerusakan yang menyebabkan kesalahan selama penerapan versi baru.Tim terdistribusi . Tim yang mengembangkan sisi klien dan backend berada di zona waktu yang berbeda. Karena hal ini, mereka sering tidak dapat sepakat di antara mereka sendiri.Pusat data tidak dapat diulang di atas panggung. Ada 200 rak dalam satu pusat data - untuk mengulanginya di kotak pasir bahkan tidak akan berhasil.Waktu henti tidak diizinkan! Kami memiliki tingkat aksesibilitas yang dapat diterima (Anggaran Kesalahan) ketika kami bekerja 99,99% dari waktu, misalnya, dan persentase sisanya adalah "hak untuk membuat kesalahan". Tidak mungkin mencapai keandalan 100%, tetapi penting untuk terus memantau waktu henti dan henti.Solusi klasik
Tulis kode tanpa bug . Ketika saya masih seorang pengembang muda, manajer mendekati saya dengan permintaan untuk merilis tanpa bug, tetapi ini tidak selalu memungkinkan.Tulis tes . Tes berfungsi, tetapi kadang-kadang itu sama sekali tidak seperti yang diinginkan bisnis. Menghasilkan uang bukanlah tugas ujian.Tes di atas panggung . Selama 3,5 tahun pekerjaan saya di Infobip, saya belum pernah melihat keadaan panggung setidaknya sebagian bertepatan dengan produksi. Kami bahkan mencoba mengembangkan ide ini: pertama kami memiliki tahap, kemudian pra-produksi, dan kemudian pra-produksi pra-produksi. Tetapi ini juga tidak membantu - mereka bahkan tidak bertepatan dalam hal kekuasaan. Dengan panggung, kami dapat menjamin fungsionalitas dasar, tetapi kami tidak tahu bagaimana ini akan berfungsi di bawah beban.Rilis ini dibuat oleh pengembang.Ini adalah praktik yang baik: bahkan jika seseorang mengubah nama komentar, itu segera ditambahkan ke produksi. Ini membantu mengembangkan tanggung jawab dan tidak melupakan perubahan yang dibuat.Ada kesulitan tambahan juga. Untuk seorang pengembang, ini sangat menegangkan - menghabiskan banyak waktu untuk memeriksa semuanya secara manual.Siaran yang Disetujui . Opsi ini biasanya menawarkan manajemen: "Mari kita sepakat bahwa Anda akan menguji dan menambahkan versi baru setiap hari." Ini tidak berhasil: selalu ada tim yang menunggu orang lain atau sebaliknya.
Kami bahkan mencoba mengembangkan ide ini: pertama kami memiliki tahap, kemudian pra-produksi, dan kemudian pra-produksi pra-produksi. Tetapi ini juga tidak membantu - mereka bahkan tidak bertepatan dalam hal kekuasaan. Dengan panggung, kami dapat menjamin fungsionalitas dasar, tetapi kami tidak tahu bagaimana ini akan berfungsi di bawah beban.Rilis ini dibuat oleh pengembang.Ini adalah praktik yang baik: bahkan jika seseorang mengubah nama komentar, itu segera ditambahkan ke produksi. Ini membantu mengembangkan tanggung jawab dan tidak melupakan perubahan yang dibuat.Ada kesulitan tambahan juga. Untuk seorang pengembang, ini sangat menegangkan - menghabiskan banyak waktu untuk memeriksa semuanya secara manual.Siaran yang Disetujui . Opsi ini biasanya menawarkan manajemen: "Mari kita sepakat bahwa Anda akan menguji dan menambahkan versi baru setiap hari." Ini tidak berhasil: selalu ada tim yang menunggu orang lain atau sebaliknya.Tes asap
Cara lain untuk memecahkan masalah penyebaran kami. Mari kita lihat bagaimana tes asap bekerja dalam contoh sebelumnya, ketika tim A ingin menyebarkan versi baru.Pertama, tim menyebarkan satu contoh ke produksi. Pesan ke instance dari mock mensimulasikan lalu lintas nyata sehingga cocok dengan lalu lintas harian normal. Jika semuanya baik-baik saja, tim akan mengalihkan versi baru ke lalu lintas pengguna.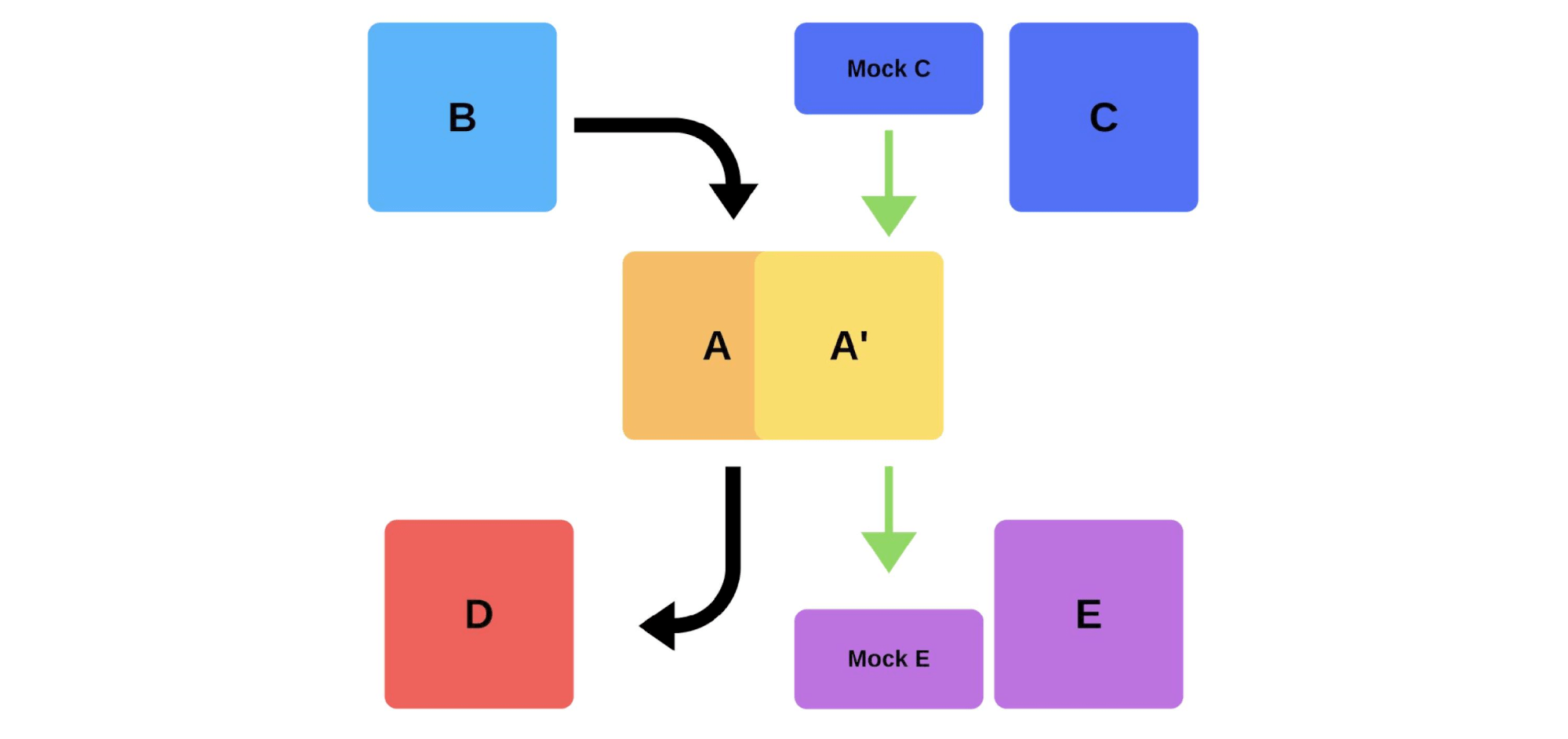 Opsi kedua adalah menggunakan besi tambahan. Tim mengujinya untuk produksi, lalu mengubahnya, dan semuanya berfungsi.
Opsi kedua adalah menggunakan besi tambahan. Tim mengujinya untuk produksi, lalu mengubahnya, dan semuanya berfungsi. Kerugian dari tes asap:
Kerugian dari tes asap:- Tes tidak bisa dipercaya. Di mana mendapatkan lalu lintas yang sama dengan untuk produksi? Anda dapat menggunakan kemarin atau seminggu yang lalu, tetapi tidak selalu bertepatan dengan yang sekarang.
- Sulit dipertahankan. Anda harus mendukung akun uji, secara konstan mengatur ulang sebelum setiap penyebaran, ketika catatan aktif dikirim ke repositori. Ini lebih sulit daripada menulis tes di kotak pasir Anda.
Satu-satunya bonus di sini adalah Anda dapat memeriksa kinerjanya .Canary rilis
Karena kekurangan tes asap, kami mulai menggunakan rilis kenari.Sebuah praktik yang mirip dengan cara para penambang menggunakan burung kenari untuk menunjukkan tingkat gas ditemukan di IT. Kami meluncurkan sedikit lalu lintas produksi nyata ke versi baru , sambil mencoba memenuhi Service Level Agreement (SLA). SLA adalah "hak kami untuk melakukan kesalahan", yang dapat kami gunakan setahun sekali (atau untuk periode waktu lainnya). Jika semuanya berjalan dengan baik, tambahkan lebih banyak lalu lintas. Jika tidak, kami akan mengembalikan versi sebelumnya.
Implementasi dan nuansa
Bagaimana kami menerapkan rilis kenari? Misalnya, sekelompok pelanggan mengirim pesan melalui layanan kami. Penyebarannya seperti ini: hapus satu simpul dari bawah balancer (1), ubah versinya (2) dan secara terpisah mulailah beberapa traffic (3).
Penyebarannya seperti ini: hapus satu simpul dari bawah balancer (1), ubah versinya (2) dan secara terpisah mulailah beberapa traffic (3). Secara umum, semua orang di grup akan bahagia, bahkan jika satu pengguna tidak bahagia. Jika semuanya baik-baik saja - ubah semua versi.
Secara umum, semua orang di grup akan bahagia, bahkan jika satu pengguna tidak bahagia. Jika semuanya baik-baik saja - ubah semua versi. Saya akan menunjukkan secara skematis bagaimana tampilannya untuk layanan microser dalam banyak kasus.Ada Service Discovery dan dua layanan lainnya: S1N1 dan S2. Layanan pertama (S1N1) memberi tahu Discovery Service saat dimulai, dan Service Discovery mengingatnya. Layanan kedua dengan dua node (S2N1 dan S2N2) juga memberi tahu Service Discovery saat startup.
Saya akan menunjukkan secara skematis bagaimana tampilannya untuk layanan microser dalam banyak kasus.Ada Service Discovery dan dua layanan lainnya: S1N1 dan S2. Layanan pertama (S1N1) memberi tahu Discovery Service saat dimulai, dan Service Discovery mengingatnya. Layanan kedua dengan dua node (S2N1 dan S2N2) juga memberi tahu Service Discovery saat startup.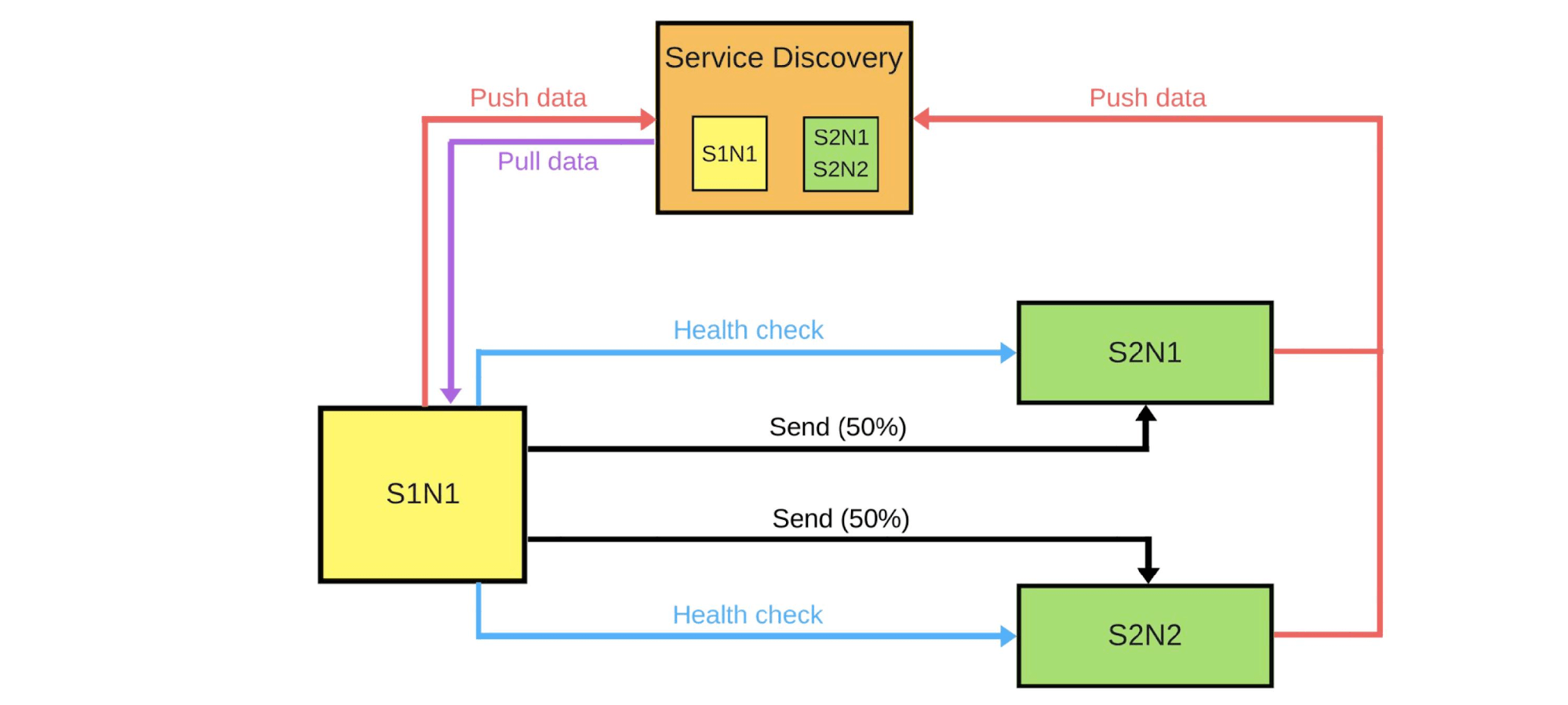 Layanan kedua untuk yang pertama berfungsi sebagai server. Yang pertama meminta informasi tentang servernya dari Service Discovery, dan ketika menerimanya, ia mencari dan memeriksanya ("pemeriksaan kesehatan"). Ketika dia memeriksa, dia akan mengirimi mereka pesan.Ketika seseorang ingin menggunakan versi baru dari layanan kedua, ia memberi tahu Service Discovery bahwa node kedua akan menjadi node kenari: lebih sedikit lalu lintas akan dikirim ke sana, karena akan digunakan sekarang. Kami menghapus simpul kenari dari bawah penyeimbang dan layanan pertama tidak mengirim lalu lintas ke sana.
Layanan kedua untuk yang pertama berfungsi sebagai server. Yang pertama meminta informasi tentang servernya dari Service Discovery, dan ketika menerimanya, ia mencari dan memeriksanya ("pemeriksaan kesehatan"). Ketika dia memeriksa, dia akan mengirimi mereka pesan.Ketika seseorang ingin menggunakan versi baru dari layanan kedua, ia memberi tahu Service Discovery bahwa node kedua akan menjadi node kenari: lebih sedikit lalu lintas akan dikirim ke sana, karena akan digunakan sekarang. Kami menghapus simpul kenari dari bawah penyeimbang dan layanan pertama tidak mengirim lalu lintas ke sana.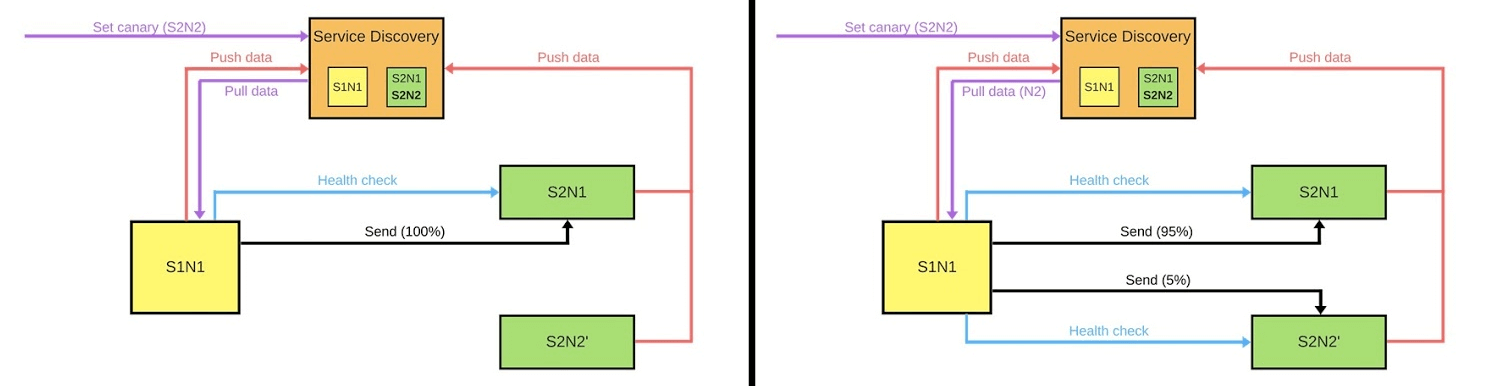 Kami mengubah versi dan Service Discovery tahu bahwa simpul kedua sekarang adalah kenari - Anda dapat mengurangi bebannya (5%). Jika semuanya baik-baik saja, ubah versinya, kembalikan muatannya dan kerjakan.Untuk mengimplementasikan semua ini, kita perlu:
Kami mengubah versi dan Service Discovery tahu bahwa simpul kedua sekarang adalah kenari - Anda dapat mengurangi bebannya (5%). Jika semuanya baik-baik saja, ubah versinya, kembalikan muatannya dan kerjakan.Untuk mengimplementasikan semua ini, kita perlu:- menyeimbangkan;
- , , , ;
- , , ;
- — (deployment pipeline).
 Ini adalah hal pertama yang harus kita pikirkan. Ada dua strategi penyeimbang.Opsi paling sederhana adalah ketika satu simpul selalu canary . Node ini selalu mendapat lebih sedikit lalu lintas dan kami mulai menggunakan darinya. Jika ada masalah, kami akan membandingkan pekerjaannya dengan penyebaran dan selama itu. Misalnya, jika ada kesalahan 2 kali lebih banyak, maka kerusakan telah meningkat 2 kali.Node Canary diatur selama proses penyebaran . Ketika penyebaran berakhir dan kami menghapus status simpul kenari darinya, keseimbangan lalu lintas akan dikembalikan. Dengan mobil yang lebih sedikit, kami mendapat distribusi yang jujur.
Ini adalah hal pertama yang harus kita pikirkan. Ada dua strategi penyeimbang.Opsi paling sederhana adalah ketika satu simpul selalu canary . Node ini selalu mendapat lebih sedikit lalu lintas dan kami mulai menggunakan darinya. Jika ada masalah, kami akan membandingkan pekerjaannya dengan penyebaran dan selama itu. Misalnya, jika ada kesalahan 2 kali lebih banyak, maka kerusakan telah meningkat 2 kali.Node Canary diatur selama proses penyebaran . Ketika penyebaran berakhir dan kami menghapus status simpul kenari darinya, keseimbangan lalu lintas akan dikembalikan. Dengan mobil yang lebih sedikit, kami mendapat distribusi yang jujur.Pemantauan
Landasan rilis kenari. Kita harus mengerti persis mengapa kita melakukan ini dan metrik apa yang ingin kita kumpulkan.Contoh metrik yang kami kumpulkan dari layanan kami.- , . , . , .
- (latency). , .
- (throughput).
- .
- 95% .
- -: . , , .
Contoh metrik di sebagian besar sistem pemantauan populer.Melawan Ini adalah beberapa nilai yang meningkat, misalnya, jumlah kesalahan. Mudah untuk menginterpolasi metrik ini dan mempelajari bagan: kemarin ada 2 kesalahan, dan hari ini 500, lalu ada yang tidak beres.Jumlah kesalahan per menit atau per detik adalah indikator paling penting yang dapat dihitung menggunakan Penghitung. Data ini memberikan gambaran yang jelas tentang operasi sistem dari kejauhan. Mari kita lihat contoh grafik jumlah kesalahan per detik untuk dua versi sistem produksi. Ada beberapa kesalahan dalam versi pertama, audit mungkin tidak berhasil. Di versi kedua, semuanya jauh lebih buruk. Kita dapat mengatakan dengan pasti bahwa ada masalah, jadi kita harus memutar kembali versi ini.Mengukur.Metrik mirip dengan Penghitung, tetapi kami mencatat nilai yang dapat meningkat atau menurun. Misalnya, permintaan waktu eksekusi atau ukuran antrian.Grafik menunjukkan contoh waktu respons (latensi). Grafik menunjukkan bahwa versinya serupa, Anda dapat bekerja dengannya. Tetapi jika Anda melihat dari dekat, terlihat bagaimana kuantitasnya berubah. Jika waktu eksekusi permintaan meningkat ketika pengguna ditambahkan, maka segera jelas bahwa ada masalah - ini tidak terjadi sebelumnya.
Ada beberapa kesalahan dalam versi pertama, audit mungkin tidak berhasil. Di versi kedua, semuanya jauh lebih buruk. Kita dapat mengatakan dengan pasti bahwa ada masalah, jadi kita harus memutar kembali versi ini.Mengukur.Metrik mirip dengan Penghitung, tetapi kami mencatat nilai yang dapat meningkat atau menurun. Misalnya, permintaan waktu eksekusi atau ukuran antrian.Grafik menunjukkan contoh waktu respons (latensi). Grafik menunjukkan bahwa versinya serupa, Anda dapat bekerja dengannya. Tetapi jika Anda melihat dari dekat, terlihat bagaimana kuantitasnya berubah. Jika waktu eksekusi permintaan meningkat ketika pengguna ditambahkan, maka segera jelas bahwa ada masalah - ini tidak terjadi sebelumnya. Ringkasan Salah satu indikator terpenting untuk bisnis adalah persentil. Metrik menunjukkan bahwa dalam 95% kasus, sistem kami bekerja seperti yang kami inginkan. Kita bisa berdamai jika ada masalah di suatu tempat, karena kita memahami kecenderungan umum tentang seberapa baik atau buruk semuanya.
Ringkasan Salah satu indikator terpenting untuk bisnis adalah persentil. Metrik menunjukkan bahwa dalam 95% kasus, sistem kami bekerja seperti yang kami inginkan. Kita bisa berdamai jika ada masalah di suatu tempat, karena kita memahami kecenderungan umum tentang seberapa baik atau buruk semuanya.Alat
Tumpukan kayu . Anda dapat menerapkan kenari menggunakan Elasticsearch - kami menulis kesalahan ketika peristiwa terjadi. Cukup memanggil API, Anda bisa mendapatkan kesalahan setiap saat, dan membandingkannya dengan segmen sebelumnya: GET /applg/_cunt?q=level:errr.Prometheus. Dia menunjukkan dirinya dengan baik di Infobip. Ini memungkinkan Anda untuk menerapkan metrik multidimensi karena label digunakan.Kita dapat menggunakan level, instance, service, untuk menggabungkan mereka dalam satu sistem. Dengan menggunakannya offset, Anda dapat melihat, misalnya, nilai seminggu yang lalu hanya dengan satu perintah GET /api/v1/query?query={query}, di mana {query}:rate(logback_appender_total{
level="error",
instance=~"$instance"
}[5m] offset $offset_value)
Analisis Versi
Ada beberapa strategi pembuatan versi.Lihat metrik hanya node kenari. Salah satu opsi paling sederhana: menyebarkan versi baru dan hanya mempelajari karya. Tetapi jika insinyur saat ini mulai mempelajari log, terus-menerus dengan gelisah memuat ulang halaman, maka solusi ini tidak berbeda dari yang lain.Sebuah simpul kenari dibandingkan dengan simpul lainnya . Ini adalah perbandingan dengan contoh lain yang berjalan pada lalu lintas penuh. Misalnya, jika dengan lalu lintas kecil hal-hal yang lebih buruk, atau tidak lebih baik daripada dalam kasus nyata, maka ada sesuatu yang salah.Node kenari dibandingkan dengan dirinya sendiri di masa lalu. Node yang dialokasikan untuk kenari dapat dibandingkan dengan data historis. Misalnya, jika seminggu yang lalu semuanya baik-baik saja, maka kita dapat fokus pada data ini untuk memahami situasi saat ini.Otomatisasi
Kami ingin membebaskan insinyur dari perbandingan manual, jadi penting untuk menerapkan otomatisasi. Proses pemasangan pipa biasanya terlihat seperti ini:- kami mulai;
- menghapus simpul dari bawah penyeimbang;
- mengatur simpul kenari;
- nyalakan alat penyeimbang yang sudah memiliki jumlah lalu lintas terbatas;
- membandingkan.
 Pada titik ini, kami menerapkan perbandingan otomatis . Bagaimana tampilan dan mengapa itu lebih baik daripada memeriksa setelah penyebaran, kami akan mempertimbangkan contoh dari Jenkins.Ini adalah saluran pipa ke Groovy.
Pada titik ini, kami menerapkan perbandingan otomatis . Bagaimana tampilan dan mengapa itu lebih baik daripada memeriksa setelah penyebaran, kami akan mempertimbangkan contoh dari Jenkins.Ini adalah saluran pipa ke Groovy.while (System.currentTimeMillis() < endCanaryTs) {
def isOk = compare(srv, canary, time, base, offset, metrics)
if (isOk) {
sleep DEFAULT SLEEP
} else {
echo "Canary failed, need to revert"
return false
}
}
Di sini, di siklus kita mengatur bahwa kita akan membandingkan node baru selama satu jam. Jika proses kenari belum selesai, kami memanggil fungsinya. Dia melaporkan bahwa semuanya baik-baik atau tidak: def isOk = compare(srv, canary, time, base, offset, metrics).Jika semuanya baik-baik saja - sleep DEFAULT SLEEPmisalnya, sebentar, dan lanjutkan. Jika tidak, kami keluar - penyebaran gagal.Deskripsi metrik. Mari kita lihat bagaimana sebuah fungsi terlihat comparepada contoh DSL.metric(
'errorCounts',
'rate(errorCounts{node=~"$canaryInst"}[5m] offset $offset)',
{ baseValue, canaryValue ->
if (canaryValue > baseValue * 1.3) return false
return true
}
)
Misalkan kita membandingkan jumlah kesalahan dan ingin mengetahui jumlah kesalahan per detik dalam 5 menit terakhir.Kami memiliki dua nilai: basis dan kenari node. Nilai dari simpul kenari adalah yang sekarang. Basic - baseValueadalah nilai dari simpul non-kenari lainnya. Kami membandingkan nilai satu sama lain sesuai dengan rumus, yang kami tetapkan berdasarkan pengalaman dan pengamatan kami. Jika nilainya canaryValueburuk, maka pemasangan gagal, dan kami memutar kembali.Mengapa semua ini perlu?Manusia tidak dapat memeriksa ratusan dan ribuan metrikterutama untuk melakukannya dengan cepat. Perbandingan otomatis membantu memeriksa semua metrik dan dengan cepat memberi tahu Anda tentang masalah. Waktu pemberitahuan sangat penting: jika sesuatu terjadi dalam 2 detik terakhir, maka kerusakannya tidak akan sebesar jika terjadi 15 menit yang lalu. Sampai seseorang melihat ada masalah, tulis dukungan, dan kami bisa kehilangan pelanggan untuk menarik kembali dukungan.Jika prosesnya berjalan dengan baik dan semuanya baik-baik saja, kami akan menggunakan semua node lainnya secara otomatis. Insinyur tidak melakukan apa pun saat ini. Hanya ketika mereka menjalankan kenari mereka memutuskan metrik mana yang akan diambil, berapa lama untuk melakukan perbandingan, strategi apa yang digunakan. Jika ada masalah, kami secara otomatis memutar kembali simpul kenari, bekerja pada versi sebelumnya dan memperbaiki kesalahan yang kami temukan. Dengan metrik, mereka mudah ditemukan dan melihat kerusakan dari versi baru.
Jika ada masalah, kami secara otomatis memutar kembali simpul kenari, bekerja pada versi sebelumnya dan memperbaiki kesalahan yang kami temukan. Dengan metrik, mereka mudah ditemukan dan melihat kerusakan dari versi baru.Rintangan
Untuk mengimplementasikan ini, tentu saja, tidak mudah. Pertama-tama, kita membutuhkan sistem pemantauan bersama . Insinyur memiliki metrik sendiri, dukungan, dan analis memiliki metrik yang berbeda, dan bisnis memiliki ketiga. Sistem umum adalah bahasa umum yang digunakan oleh bisnis dan pengembangan.Penting untuk memeriksa dalam praktek stabilitas metrik. Verifikasi membantu untuk memahami set metrik minimum yang diperlukan untuk memastikan kualitas .Bagaimana cara mencapai ini? Gunakan layanan kenari bukan pada saat penempatan . Kami menambahkan layanan tertentu pada versi lama, yang setiap saat akan dapat mengambil simpul yang dialokasikan, mengurangi lalu lintas tanpa penyebaran. Setelah kami membandingkan: kami mempelajari kesalahan dan mencari garis itu ketika kami mencapai kualitas.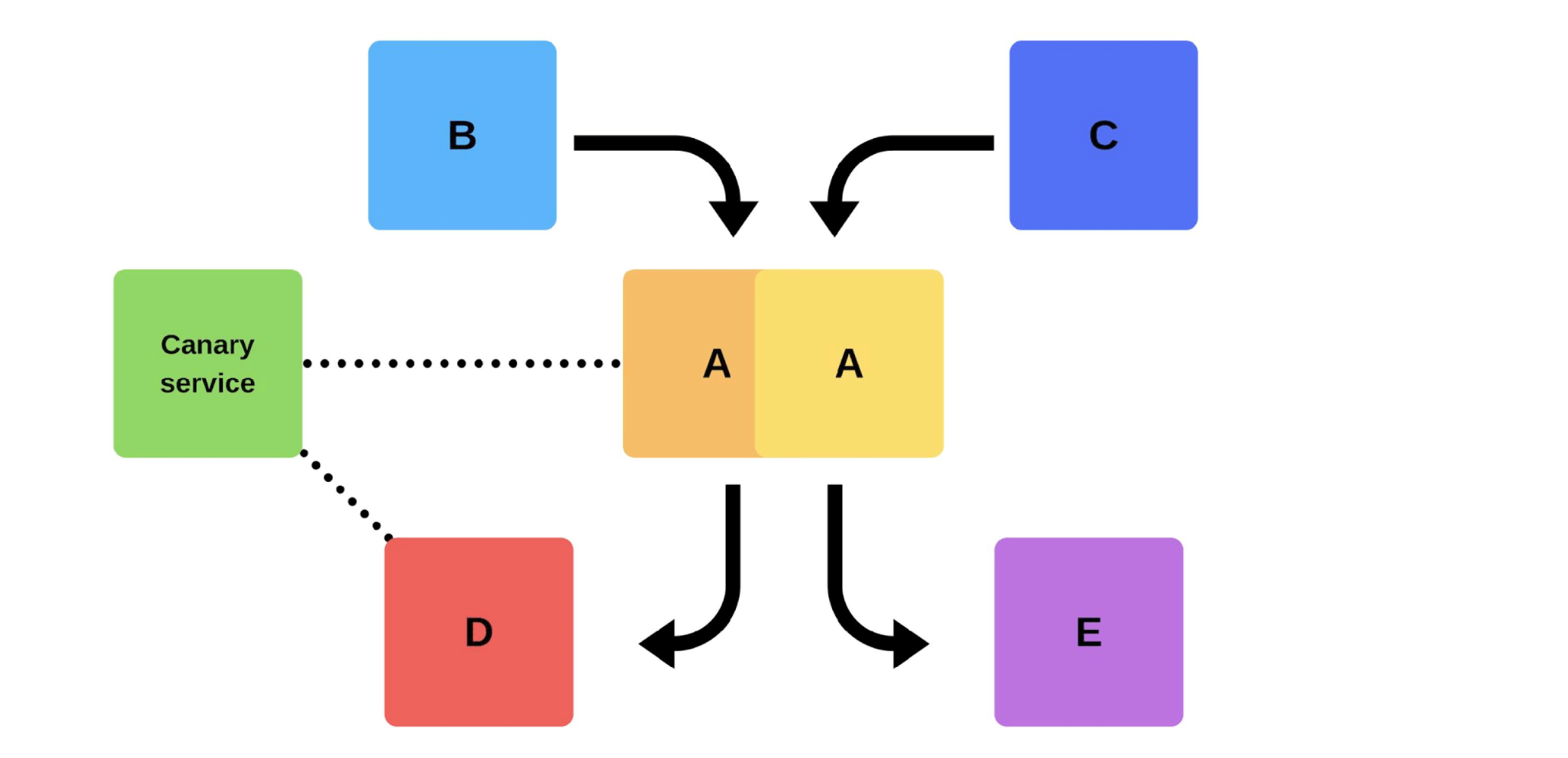
Apa manfaat yang kita dapatkan dari rilis kenari
Meminimalkan persentase kerusakan dari bug. Sebagian besar kesalahan penggunaan terjadi karena ketidakkonsistenan dalam beberapa data atau prioritas. Kesalahan seperti itu menjadi jauh lebih kecil, karena kita dapat menyelesaikan masalah di detik-detik pertama.Mengoptimalkan kerja tim. Pemula memiliki "hak untuk membuat kesalahan": mereka dapat menyebar ke produksi tanpa takut kesalahan, muncul inisiatif tambahan, insentif untuk bekerja. Jika mereka merusak sesuatu, maka itu tidak akan menjadi kritis, dan orang yang salah tidak akan dipecat.Penempatan otomatis . Ini bukan lagi proses manual, seperti sebelumnya, tetapi proses otomatis yang nyata. Tapi itu butuh waktu lebih lama.Metrik penting yang disorot. Seluruh perusahaan, mulai dari bisnis dan insinyur, memahami apa yang benar-benar penting dalam produk kami, yang metrik, misalnya, arus keluar dan masuknya pengguna. Kami mengontrol proses: kami menguji metrik, memperkenalkan yang baru, melihat bagaimana yang lama bekerja membangun sistem yang akan menghasilkan uang lebih produktif.Kami memiliki banyak praktik dan sistem keren yang membantu kami. Meskipun demikian, kami berusaha untuk menjadi profesional dan melakukan pekerjaan kami secara efisien, terlepas dari apakah kami memiliki sistem yang akan membantu kami atau tidak.— TechLead Conf. , , — .
TechLead Conf 8 9 . , , — , .