Ratusan, ribuan, dan dalam beberapa layanan, jutaan antrian, yang dilewati sejumlah besar data, berputar di bawah kap produk kami. Semua ini harus diproses dengan cara magis dan tidak boleh ditembak. Dalam posting ini saya akan memberi tahu Anda apa pendekatan arsitektur yang kami gunakan di rumah, memiliki tumpukan teknologi yang cukup sederhana dan tidak memiliki pusat data kecil di "dapur" kami.
Apa yang kita miliki
Jadi, di satu sisi, kami memiliki tumpukan teknologi yang terkenal: Nginx, PHP, PostgreSQL, Redis. Di sisi lain, puluhan ribu peristiwa terjadi di sistem kami setiap menit, dan di puncaknya dapat mencapai ratusan ribu acara. Untuk memperjelas apa acara-acara ini dan bagaimana kita harus menanggapinya, saya akan membuat penyimpangan produk kecil, setelah itu saya akan memberi tahu Anda bagaimana kami mengembangkan sistem otomatisasi berbasis acara.ManyChat adalah platform untuk otomatisasi pemasaran. Pemilik halaman Facebook dapat menghubungkannya ke platform kami dan mengonfigurasi otomatisasi interaksi dengan pelanggannya (dengan kata lain, buat bot obrolan). Otomasi biasanya terdiri dari banyak rantai interaksi yang mungkin tidak saling berhubungan. Dalam rantai otomatisasi ini, tindakan tertentu dapat terjadi dengan pelanggan, misalnya, menetapkan tag tertentu dalam sistem, atau menetapkan / mengubah nilai suatu bidang dalam kartu pelanggan. Data ini selanjutnya memungkinkan Anda untuk mengelompokkan audiens dan membangun interaksi yang lebih relevan dengan pelanggan halaman.Pelanggan kami benar-benar menginginkan otomatisasi berbasis acara - kemampuan untuk menyesuaikan pelaksanaan suatu tindakan ketika suatu peristiwa tertentu dipicu dalam pelanggan (misalnya, penandaan).Karena peristiwa pemicu dapat bekerja dari rantai otomatisasi yang berbeda, penting bahwa ada satu titik konfigurasi untuk semua tindakan berbasis Acara di sisi klien, dan di sisi pemrosesan kami harus ada satu bus yang memproses perubahan dalam konteks pelanggan dari titik otomatisasi yang berbeda.Dalam sistem kami, ada bus umum di mana semua peristiwa yang terjadi dengan pelanggan lewat. Ini lebih dari 500 juta acara per hari. Pemrosesan mereka agak rumit - ini adalah catatan di gudang data, sehingga pemilik laman memiliki kesempatan untuk melihat secara historis segala sesuatu yang terjadi pada pelanggannya.Tampaknya untuk menerapkan sistem berbasis Acara kami sudah memiliki segalanya, dan cukup bagi kami untuk mengintegrasikan logika bisnis kami ke dalam pemrosesan bus peristiwa umum. Tetapi kami memiliki persyaratan tertentu untuk sistem baru kami:- Kami tidak ingin mendapatkan kinerja terdegradasi dalam memproses bus acara utama
- Penting bagi kami untuk menjaga urutan pemrosesan pesan dalam sistem baru, karena hal ini dapat dikaitkan dengan logika bisnis klien yang mengatur otomatisasi
- Hindari efek dari tetangga yang berisik ketika halaman aktif dengan sejumlah besar pelanggan menyumbat antrian dan memblokir pemrosesan acara halaman "kecil"
Jika kita mengintegrasikan pemrosesan logika kita ke dalam pemrosesan bus peristiwa umum, maka kita akan mendapatkan penurunan kinerja yang serius, karena kita harus memeriksa setiap peristiwa untuk kepatuhan dengan otomatisasi yang dikonfigurasi. Sebagai bagian dari pengaturan otomatisasi, filter tertentu dapat diterapkan (misalnya, mulai otomatisasi ketika suatu peristiwa dipicu hanya untuk klien wanita yang lebih tua dari 30 tahun). Artinya, ketika memproses peristiwa di bus utama, sejumlah besar pertanyaan tambahan ke basis data akan diproses, dan juga logika yang agak berat akan mulai membandingkan konteks pelanggan saat ini dengan pengaturan otomatisasi. Pilihan ini tidak cocok untuk kami, jadi kami berpikir lebih jauh.
Organisasi riam antrian
Karena logika bisnis kami yang terkait dengan sistem berbasis peristiwa dipisahkan dengan sangat baik dari logika untuk memproses peristiwa dari bus utama, kami memutuskan untuk meletakkan jenis peristiwa yang kami butuhkan dari bus bersama dalam antrian terpisah untuk diproses lebih lanjut dalam aliran data terpisah. Dengan demikian, kami menghilangkan masalah yang terkait dengan penurunan kinerja dalam memproses bus acara utama.Pada tahap yang sama, kami memutuskan apa yang akan keren untuk mentransfer acara ke antrian kaskade berikutnya untuk menempatkan acara ini dalam antrian terpisah untuk setiap bot. Dengan demikian, mengisolasi aktivitas masing-masing bot dengan kerangka gilirannya, yang memungkinkan kita untuk menyelesaikan masalah yang terkait dengan efek tetangga yang berisik.Diagram alir data kami sekarang terlihat seperti ini: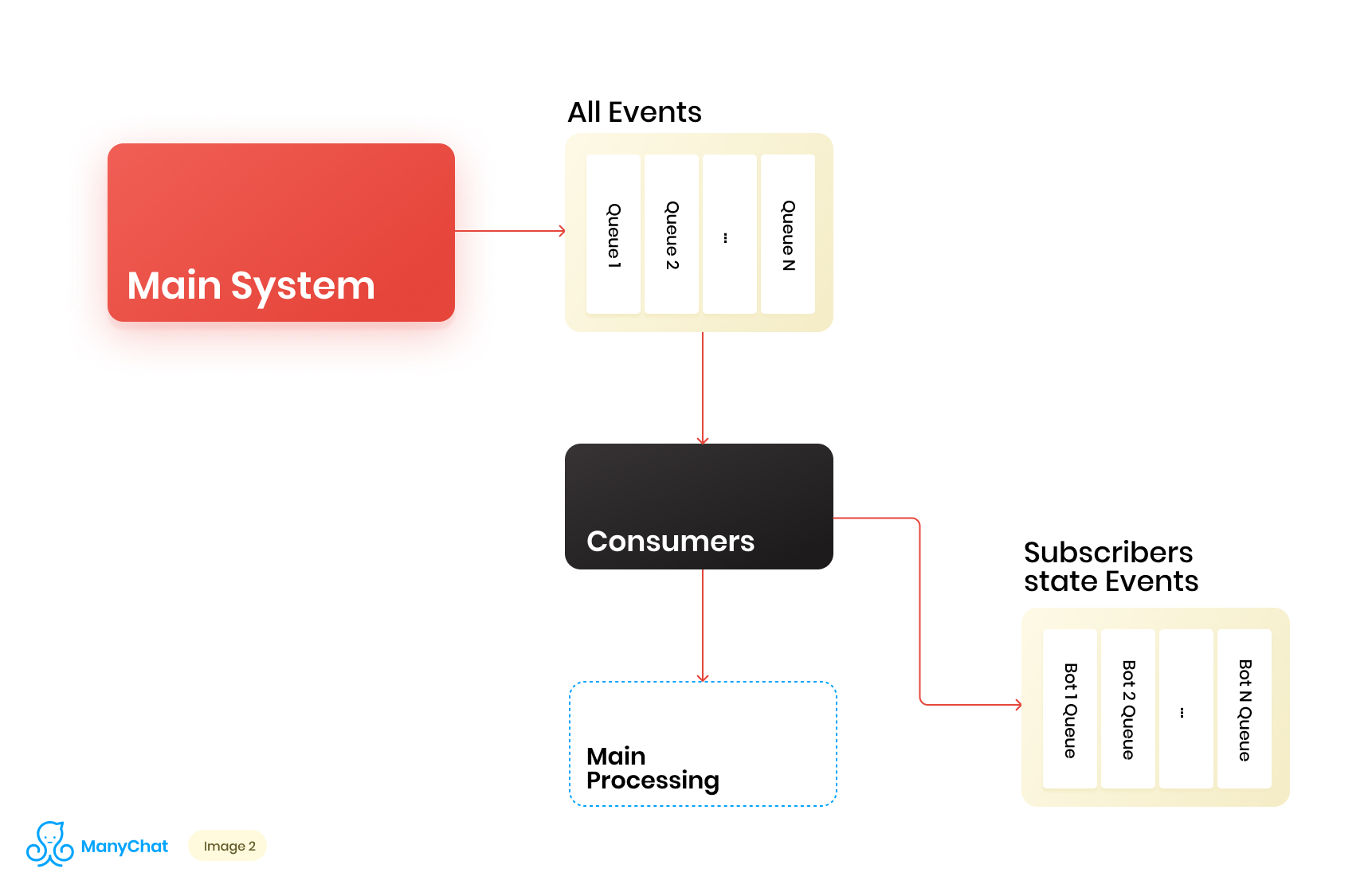 Namun, agar skema ini berfungsi, kita perlu menyelesaikan masalah pemrosesan antrian baru.Ada lebih dari 1 juta halaman yang terhubung (bot) di platform kami, yang berarti bahwa kita berpotensi mendapatkan ~ 1 juta antrian dalam skema kita, hanya pada tingkat lapisan berbasis peristiwa. Dari sudut pandang teknis, ini tidak menakutkan bagi kami. Sebagai server antrian, kami menggunakan Redis dengan tipe data standarnya, seperti LIST, SORTED SET, dan lainnya. Ini berarti siapa setiap antrian adalah struktur data standar untuk Redis dalam RAM, yang dapat dibuat atau dihapus dengan cepat, yang memungkinkan kita untuk dengan mudah dan fleksibel mengoperasikan sejumlah besar antrian di sistem kami. Saya akan berbicara lebih dalam tentang penggunaan Redis sebagai server antrian dengan detail teknis di pos terpisah, tetapi untuk sekarang mari kita kembali ke arsitektur kita.Jelas bahwa setiap bot memiliki aktivitas yang berbeda, dan bahwa kemungkinan mendapatkan 1 juta antrian dalam status "perlu diproses sekarang" sangat kecil. Tetapi pada satu titik waktu, sangat mungkin bahwa kita akan memiliki beberapa puluhan ribu antrian aktif yang memerlukan pemrosesan. Jumlah antrian ini terus berubah. Antrian ini sendiri juga berubah, beberapa di antaranya dikurangi sepenuhnya dan dihapus, beberapa di antaranya dibuat secara dinamis dan diisi dengan acara untuk diproses. Karena itu, kita perlu menemukan cara yang efektif untuk menanganinya.
Namun, agar skema ini berfungsi, kita perlu menyelesaikan masalah pemrosesan antrian baru.Ada lebih dari 1 juta halaman yang terhubung (bot) di platform kami, yang berarti bahwa kita berpotensi mendapatkan ~ 1 juta antrian dalam skema kita, hanya pada tingkat lapisan berbasis peristiwa. Dari sudut pandang teknis, ini tidak menakutkan bagi kami. Sebagai server antrian, kami menggunakan Redis dengan tipe data standarnya, seperti LIST, SORTED SET, dan lainnya. Ini berarti siapa setiap antrian adalah struktur data standar untuk Redis dalam RAM, yang dapat dibuat atau dihapus dengan cepat, yang memungkinkan kita untuk dengan mudah dan fleksibel mengoperasikan sejumlah besar antrian di sistem kami. Saya akan berbicara lebih dalam tentang penggunaan Redis sebagai server antrian dengan detail teknis di pos terpisah, tetapi untuk sekarang mari kita kembali ke arsitektur kita.Jelas bahwa setiap bot memiliki aktivitas yang berbeda, dan bahwa kemungkinan mendapatkan 1 juta antrian dalam status "perlu diproses sekarang" sangat kecil. Tetapi pada satu titik waktu, sangat mungkin bahwa kita akan memiliki beberapa puluhan ribu antrian aktif yang memerlukan pemrosesan. Jumlah antrian ini terus berubah. Antrian ini sendiri juga berubah, beberapa di antaranya dikurangi sepenuhnya dan dihapus, beberapa di antaranya dibuat secara dinamis dan diisi dengan acara untuk diproses. Karena itu, kita perlu menemukan cara yang efektif untuk menanganinya.Memproses kumpulan antrian yang sangat besar
Jadi kami memiliki banyak antrian. Pada setiap titik waktu, mungkin ada jumlah acak. Kondisi penting untuk memproses setiap antrian, yang disebutkan di awal postingnya, adalah bahwa peristiwa dalam setiap halaman harus diproses secara ketat secara berurutan. Ini berarti bahwa pada satu titik waktu, setiap antrian tidak dapat diproses oleh lebih dari satu pekerja untuk menghindari masalah persaingan.Tetapi untuk membuat perbandingan antrian dengan penangan 1: 1 adalah tugas yang meragukan. Jumlah antrian terus berubah, baik naik maupun turun. Jumlah penangan yang berjalan juga tidak terbatas, setidaknya kami memiliki batasan pada bagian dari sistem operasi dan perangkat keras, dan kami tidak ingin pekerja berdiri diam di antrian kosong. Untuk mengatasi masalah interaksi antara penangan dan antrian, kami menerapkan sistem round robin untuk memproses kumpulan antrian kami.Dan di sini garis kontrol datang membantu kami. Ketika acara diteruskan dari bus bersama ke antrian berbasis acara bot tertentu, kami juga menempatkan pengidentifikasi antrian bot ini di antrian kontrol. Antrian kontrol menyimpan hanya pengidentifikasi antrian yang ada di kumpulan dan perlu diproses. Hanya nilai unik yang disimpan dalam antrian kontrol, yaitu, pengidentifikasi antrian bot yang sama akan disimpan dalam antrian kontrol hanya sekali, terlepas dari berapa kali itu ditulis di sana. Pada Redis, ini diimplementasikan menggunakan struktur data SET SORTED.Selanjutnya, kita dapat membedakan sejumlah pekerja tertentu, yang masing-masing akan menerima dari antrian kontrol pengenalnya dari antrian bot untuk diproses. Dengan demikian, setiap pekerja akan secara mandiri memproses chunk dari antrian yang ditugaskan kepadanya, setelah memproses chunk, mengembalikan pengidentifikasi dari antrian yang diproses ke kontrol, sehingga mengembalikannya ke round robin kami. Hal utama adalah jangan lupa untuk memberikan semuanya dengan kunci, sehingga dua pekerja tidak bisa memproses antrian bot yang sama secara paralel. Situasi ini dimungkinkan jika bot identifier memasuki antrian kontrol ketika sudah diproses oleh pekerja. Untuk kunci, kami juga menggunakan Redis sebagai kunci: menyimpan nilai dengan TTL.Ketika kami mengambil tugas dengan pengidentifikasi antrian bot dari antrian kontrol, kami menaruh kunci TTL pada antrian yang diambil dan mulai memprosesnya. Jika konsumen lain mengambil tugas dengan antrian yang sudah diproses dari antrian kontrol, ia tidak akan dapat mengunci, mengembalikan tugas ke antrian kontrol dan menerima tugas berikutnya. Setelah memproses antrian bot oleh konsumen, ia menghapus kunci dan pergi ke antrian kontrol untuk tugas berikutnya.Skema terakhir adalah sebagai berikut:
Ketika acara diteruskan dari bus bersama ke antrian berbasis acara bot tertentu, kami juga menempatkan pengidentifikasi antrian bot ini di antrian kontrol. Antrian kontrol menyimpan hanya pengidentifikasi antrian yang ada di kumpulan dan perlu diproses. Hanya nilai unik yang disimpan dalam antrian kontrol, yaitu, pengidentifikasi antrian bot yang sama akan disimpan dalam antrian kontrol hanya sekali, terlepas dari berapa kali itu ditulis di sana. Pada Redis, ini diimplementasikan menggunakan struktur data SET SORTED.Selanjutnya, kita dapat membedakan sejumlah pekerja tertentu, yang masing-masing akan menerima dari antrian kontrol pengenalnya dari antrian bot untuk diproses. Dengan demikian, setiap pekerja akan secara mandiri memproses chunk dari antrian yang ditugaskan kepadanya, setelah memproses chunk, mengembalikan pengidentifikasi dari antrian yang diproses ke kontrol, sehingga mengembalikannya ke round robin kami. Hal utama adalah jangan lupa untuk memberikan semuanya dengan kunci, sehingga dua pekerja tidak bisa memproses antrian bot yang sama secara paralel. Situasi ini dimungkinkan jika bot identifier memasuki antrian kontrol ketika sudah diproses oleh pekerja. Untuk kunci, kami juga menggunakan Redis sebagai kunci: menyimpan nilai dengan TTL.Ketika kami mengambil tugas dengan pengidentifikasi antrian bot dari antrian kontrol, kami menaruh kunci TTL pada antrian yang diambil dan mulai memprosesnya. Jika konsumen lain mengambil tugas dengan antrian yang sudah diproses dari antrian kontrol, ia tidak akan dapat mengunci, mengembalikan tugas ke antrian kontrol dan menerima tugas berikutnya. Setelah memproses antrian bot oleh konsumen, ia menghapus kunci dan pergi ke antrian kontrol untuk tugas berikutnya.Skema terakhir adalah sebagai berikut: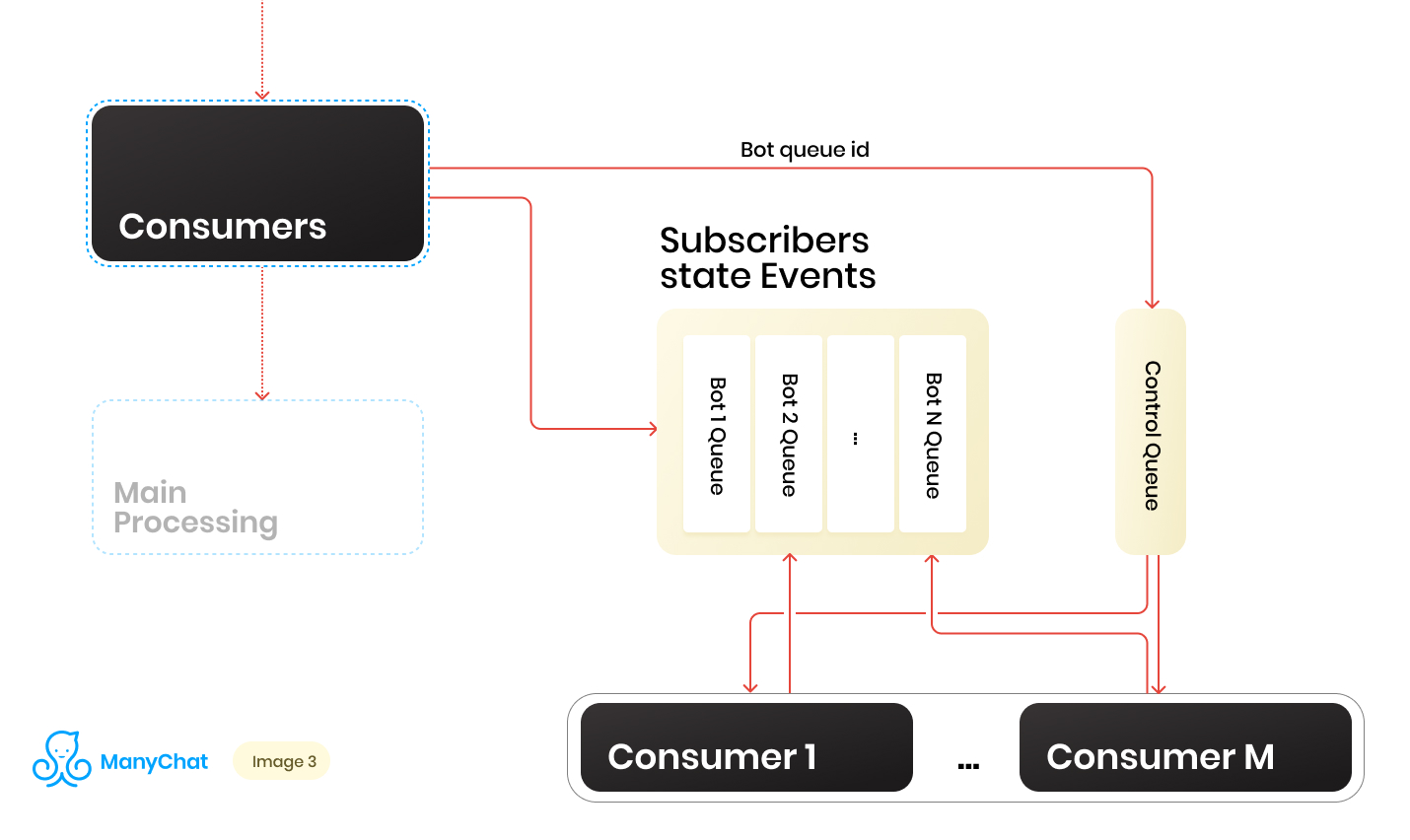 Sebagai hasilnya, dengan skema saat ini, kami memecahkan masalah utama yang diidentifikasi:
Sebagai hasilnya, dengan skema saat ini, kami memecahkan masalah utama yang diidentifikasi:- Penurunan kinerja di bus acara utama
- Pelanggaran Penanganan Acara
- Efek tetangga berisik
Bagaimana cara menangani beban dinamis?
Skema ini berfungsi, tetapi di dalamnya kami memiliki jumlah konsumen tetap untuk jumlah antrian yang dinamis. Tentunya, dengan pendekatan ini, kami akan melorot dalam memproses antrian setiap kali jumlah mereka meningkat tajam. Tampaknya akan baik bagi pekerja kita untuk memulai atau memadamkan secara dinamis saat dibutuhkan. Akan lebih baik jika ini tidak menyulitkan proses mengeluarkan kode baru. Pada saat-saat seperti itu, tangan sangat gatal untuk pergi dan menulis manajer proses Anda. Di masa depan, kami melakukan hal itu, tetapi cerita ini berbeda.Berpikir, kami memutuskan, mengapa tidak sekali lagi menggunakan semua alat yang akrab dan akrab. Jadi kami mendapatkan API internal kami, yang berfungsi pada bundel standar NGINX + PHP-FPM. Akibatnya, kami dapat mengganti kumpulan pekerja tetap kami dengan API, dan membiarkan NGINX + PHP-FPM menyelesaikan dan mengelola sendiri pekerja, dan cukup bagi kami untuk memiliki antara antrean kontrol dan API internal kami hanya satu konsumen kontrol yang akan mengirimkan pengidentifikasi antrian ke API kami untuk memproses, dan antrian itu sendiri akan diproses pada pekerja yang diangkat oleh PHP-FPM.Skema baru adalah sebagai berikut: Itu terlihat indah, tetapi konsumen kontrol kami bekerja dalam satu utas, dan API kami bekerja secara serempak. Ini berarti bahwa konsumen akan hang setiap saat sementara PHP-FPM sedang menggulung antrian. Ini tidak cocok untuk kita.
Itu terlihat indah, tetapi konsumen kontrol kami bekerja dalam satu utas, dan API kami bekerja secara serempak. Ini berarti bahwa konsumen akan hang setiap saat sementara PHP-FPM sedang menggulung antrian. Ini tidak cocok untuk kita.Membuat API kami tidak sinkron
Tetapi bagaimana jika kita bisa mengirim tugas ke API kita, dan membiarkannya mengirik logika bisnis di sana, dan konsumen kontrol kita akan mengikuti tugas berikutnya dalam antrian kontrol, setelah itu akan ditarik kembali ke API, dan seterusnya. Tidak lebih cepat dikatakan daripada dilakukan.Implementasinya membutuhkan beberapa baris kode, dan Bukti Konsep terlihat seperti ini:class Api {
public function actionDoSomething()
{
$data = $_POST;
$this->dropFPMSession();
}
protected function dropFPMSession()
{
ignore_user_abort(true);
ob_end_flush();
flush();
@session_write_close();
fastcgi_finish_request();
}
}
Dalam metode dropFPMSession (), kami memutuskan koneksi dengan klien, memberikan respons 200, setelah itu kami dapat menjalankan logika berat apa pun dalam postprocessing. Klien dalam kasus kami adalah konsumen kontrol. Penting baginya untuk menyebarkan tugas dengan cepat dari antrian kontrol ke pemrosesan pada API dan untuk mengetahui bahwa tugas tersebut telah mencapai API.Dengan menggunakan pendekatan ini, kami melepas banyak sakit kepala yang terkait dengan kontrol dinamis konsumen dan penskalaan otomatis mereka.Lebih scalable
Akibatnya, arsitektur subsistem kami mulai terdiri dari tiga lapisan: Lapisan Data, Proses dan API Internal. Pada saat yang sama, informasi melewati semua aliran data tentang bot mana dari acara / tugas yang diproses. Jelas, kita dapat menggunakan pengenal kunci / bot kami untuk sharding, sambil terus skala sistem kami secara horizontal.Jika kita membayangkan arsitektur kita sebagai unit yang solid, akan terlihat seperti ini: Setelah menambah jumlah unit seperti itu, kita dapat menempatkan penyeimbang tipis di depannya, yang akan menyebarkan acara / tugas kita ke unit yang diperlukan, tergantung pada kunci sharding.
Setelah menambah jumlah unit seperti itu, kita dapat menempatkan penyeimbang tipis di depannya, yang akan menyebarkan acara / tugas kita ke unit yang diperlukan, tergantung pada kunci sharding. Dengan demikian, kami mendapatkan margin besar untuk penskalaan horizontal sistem kami.Saat menerapkan logika bisnis, Anda tidak boleh melupakan konsep keselamatan benang, jika tidak, Anda bisa mendapatkan hasil yang tidak terduga.Skema semacam itu dengan kaskade antrian dan penghapusan logika bisnis berat ke pemrosesan asinkron telah digunakan di beberapa bagian sistem selama lebih dari dua tahun. Beban selama waktu ini untuk masing-masing subsistem telah tumbuh puluhan kali, dan implementasi yang diusulkan memungkinkan kita untuk dengan mudah dan cepat mengukur. Pada saat yang sama, kami terus bekerja pada tumpukan utama kami, tanpa memperluasnya dengan alat / bahasa baru dan tanpa bertambah, sehingga menambah pengenalan dan dukungan alat baru.
Dengan demikian, kami mendapatkan margin besar untuk penskalaan horizontal sistem kami.Saat menerapkan logika bisnis, Anda tidak boleh melupakan konsep keselamatan benang, jika tidak, Anda bisa mendapatkan hasil yang tidak terduga.Skema semacam itu dengan kaskade antrian dan penghapusan logika bisnis berat ke pemrosesan asinkron telah digunakan di beberapa bagian sistem selama lebih dari dua tahun. Beban selama waktu ini untuk masing-masing subsistem telah tumbuh puluhan kali, dan implementasi yang diusulkan memungkinkan kita untuk dengan mudah dan cepat mengukur. Pada saat yang sama, kami terus bekerja pada tumpukan utama kami, tanpa memperluasnya dengan alat / bahasa baru dan tanpa bertambah, sehingga menambah pengenalan dan dukungan alat baru.