Beberapa bulan yang lalu, kami mengumumkan menjelaskan.tensor.ru , layanan publik untuk mem-parsing dan memvisualisasikan rencana permintaan untuk PostgreSQL.Selama waktu yang lalu, Anda telah menggunakannya lebih dari 6.000 kali, tetapi salah satu fungsi praktis tidak diperhatikan - ini adalah petunjuk struktural yang terlihat seperti ini: Dengarkan dan permintaan Anda akan “menjadi halus dan halus.” :)Tetapi serius, banyak situasi yang membuat permintaan lambat dan "rakus" dalam hal sumber daya adalah khas dan dapat dikenali oleh struktur dan data rencana .Dalam hal ini, setiap pengembang individu tidak perlu mencari opsi pengoptimalan sendiri, hanya mengandalkan pengalaman mereka - kami dapat memberitahunya apa yang terjadi di sini, apa yang bisa menjadi alasan, dan bagaimana cara mendekati solusi . Yang kami lakukan.
Dengarkan dan permintaan Anda akan “menjadi halus dan halus.” :)Tetapi serius, banyak situasi yang membuat permintaan lambat dan "rakus" dalam hal sumber daya adalah khas dan dapat dikenali oleh struktur dan data rencana .Dalam hal ini, setiap pengembang individu tidak perlu mencari opsi pengoptimalan sendiri, hanya mengandalkan pengalaman mereka - kami dapat memberitahunya apa yang terjadi di sini, apa yang bisa menjadi alasan, dan bagaimana cara mendekati solusi . Yang kami lakukan. Mari kita lihat lebih dekat pada kasus-kasus ini - bagaimana mereka ditentukan dan rekomendasi apa yang mereka tuju.Untuk wawasan yang lebih baik tentang topik ini, pertama-tama Anda dapat mendengarkan blok yang sesuai dari laporan saya di PGConf.Russia 2020 , dan baru kemudian melanjutkan ke analisis terperinci dari setiap contoh:
Mari kita lihat lebih dekat pada kasus-kasus ini - bagaimana mereka ditentukan dan rekomendasi apa yang mereka tuju.Untuk wawasan yang lebih baik tentang topik ini, pertama-tama Anda dapat mendengarkan blok yang sesuai dari laporan saya di PGConf.Russia 2020 , dan baru kemudian melanjutkan ke analisis terperinci dari setiap contoh:# 1: indeks "undersorting"
Kapan muncul
Perlihatkan faktur terakhir untuk klien "LLC Bell".Cara mengenali
-> Limit
-> Sort
-> Index [Only] Scan [Backward] | Bitmap Heap Scan
Rekomendasi
Gunakan indeks yang digunakan untuk mengurutkan bidang .Contoh:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_cli);
SELECT
*
FROM
tbl
WHERE
fk_cli = 1
ORDER BY
pk DESC
LIMIT 1;
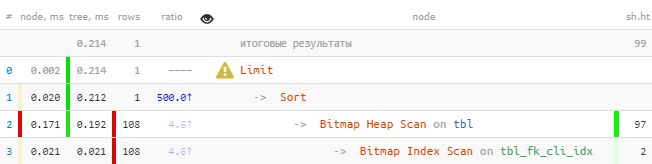 [lihat menjelaskan.tensor.ru] Andadapat segera melihat bahwa indeks mengurangi lebih dari 100 entri, yang kemudian diurutkan, dan kemudian satu-satunya yang tersisa.Kami memperbaiki:
[lihat menjelaskan.tensor.ru] Andadapat segera melihat bahwa indeks mengurangi lebih dari 100 entri, yang kemudian diurutkan, dan kemudian satu-satunya yang tersisa.Kami memperbaiki:DROP INDEX tbl_fk_cli_idx;
CREATE INDEX ON tbl(fk_cli, pk DESC);
 [lihat menjelaskan.tensor.ru]Bahkan pada sampel primitif seperti itu - 8,5 kali lebih cepat dan 33 kali lebih sedikit bacaan . Efeknya akan lebih terlihat semakin banyak "fakta" yang Anda miliki untuk setiap nilai
[lihat menjelaskan.tensor.ru]Bahkan pada sampel primitif seperti itu - 8,5 kali lebih cepat dan 33 kali lebih sedikit bacaan . Efeknya akan lebih terlihat semakin banyak "fakta" yang Anda miliki untuk setiap nilai fk.Saya perhatikan bahwa indeks seperti itu akan berfungsi sebagai "awalan" tidak lebih buruk daripada yang sebelumnya untuk pertanyaan lain fk, di mana pktidak ada penyortiran dan penyortiran (lebih lanjut tentang ini dapat ditemukan dalam artikel saya tentang menemukan indeks yang tidak efisien ). Secara khusus, ini akan memberikan dukungan normal untuk kunci asing eksplisit di bidang ini.# 2: persimpangan indeks (BitmapAnd)
Kapan muncul
Tunjukkan semua kontrak untuk klien LLC Kolokolchik yang diselesaikan atas nama NAO Buttercup.Cara mengenali
-> BitmapAnd
-> Bitmap Index Scan
-> Bitmap Index Scan
Rekomendasi
Buat indeks komposit untuk bidang dari sumber atau memperluas salah satu bidang yang ada dari yang kedua.Contoh:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 100)::integer fk_org
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_org);
CREATE INDEX ON tbl(fk_cli);
SELECT
*
FROM
tbl
WHERE
(fk_org, fk_cli) = (1, 999);
 [lihat menjelaskan.tensor.ru]Benar:
[lihat menjelaskan.tensor.ru]Benar:DROP INDEX tbl_fk_org_idx;
CREATE INDEX ON tbl(fk_org, fk_cli);
 [lihat menjelaskan.tensor.ru]Di sini keuntungannya kurang, karena Bitmap Heap Scan cukup efektif. Namun masih 7 kali lebih cepat dan bacaan 2,5 kali lebih sedikit .
[lihat menjelaskan.tensor.ru]Di sini keuntungannya kurang, karena Bitmap Heap Scan cukup efektif. Namun masih 7 kali lebih cepat dan bacaan 2,5 kali lebih sedikit .# 3: kumpulan indeks (BitmapOr)
Kapan muncul
Perlihatkan 20 aplikasi "milik sendiri" tertua atau yang belum ditetapkan untuk diproses, dan prioritasnya.Cara mengenali
-> BitmapOr
-> Bitmap Index Scan
-> Bitmap Index Scan
Rekomendasi
Gunakan UNION [ALL] untuk menggabungkan subqueries untuk setiap blok kondisi ATAU.Contoh:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer
END fk_own;
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
fk_own = 1 OR
fk_own IS NULL
ORDER BY
pk
, (fk_own = 1) DESC
LIMIT 20;
 [lihat menjelaskan.tensor.ru]Benar:
[lihat menjelaskan.tensor.ru]Benar:(
SELECT
*
FROM
tbl
WHERE
fk_own = 1
ORDER BY
pk
LIMIT 20
)
UNION ALL
(
SELECT
*
FROM
tbl
WHERE
fk_own IS NULL
ORDER BY
pk
LIMIT 20
)
LIMIT 20;
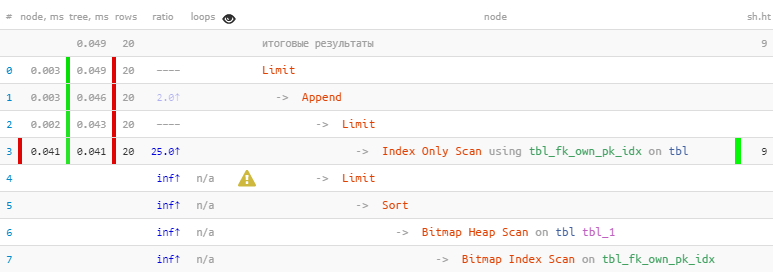 [lihat menjelaskan.tensor.ru]Kami mengambil keuntungan dari fakta bahwa semua 20 catatan yang diperlukan segera diterima di blok pertama, jadi yang kedua, dengan Pemindaian Tumpukan Bitmap yang lebih “mahal”, bahkan tidak dilakukan - sebagai hasilnya , 22 kali lebih cepat, dalam 44 kali lebih sedikit bacaan !
[lihat menjelaskan.tensor.ru]Kami mengambil keuntungan dari fakta bahwa semua 20 catatan yang diperlukan segera diterima di blok pertama, jadi yang kedua, dengan Pemindaian Tumpukan Bitmap yang lebih “mahal”, bahkan tidak dilakukan - sebagai hasilnya , 22 kali lebih cepat, dalam 44 kali lebih sedikit bacaan !Sebuah cerita yang lebih rinci tentang metode optimasi ini menggunakan contoh-contoh spesifik dapat ditemukan di artikel PostgreSQL Antipatterns: BERGABUNG berbahaya dan OR dan Antipatterns PostgreSQL: sebuah kisah tentang perbaikan berulang pencarian dengan nama, atau "Optimasi di sana dan kembali" .
Versi umum dari pemilihan yang diurutkan dengan beberapa kunci (dan bukan hanya oleh pasangan const / NULL) dipertimbangkan dalam artikel SQL HowTo: kami menulis loop-sementara secara langsung dalam kueri, atau "Elementary three-way" .
# 4: banyak membaca yang tidak perlu
Kapan muncul
Sebagai aturan, itu muncul jika Anda ingin "mempercepat filter lain" ke permintaan yang ada."Dan kamu tidak memiliki yang sama, tetapi dengan kancing mutiara ?" film "Tangan Berlian"
Misalnya, memodifikasi tugas di atas, menunjukkan 20 aplikasi “kritis” tertua tertua untuk diproses, apa pun tujuannya.Cara mengenali
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& 5 × rows < RRbF -- >80%
&& loops × RRbF > 100 -- 100
Rekomendasi
Buat indeks kustom [lainnya] dengan klausa WHERE atau sertakan bidang tambahan dalam indeks.Jika kondisi filter "statis" untuk tugas Anda - yaitu, itu tidak melibatkan perluasan daftar nilai di masa mendatang - lebih baik menggunakan indeks WHERE. Status boolean / enum yang berbeda cocok dengan kategori ini.
Jika kondisi filter dapat mengambil nilai yang berbeda , maka lebih baik untuk memperluas indeks dengan bidang ini - seperti dalam situasi dengan BitmapDan di atas.
Contoh:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer
END fk_own
, (random() < 1::real/50) critical;
CREATE INDEX ON tbl(pk);
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
critical
ORDER BY
pk
LIMIT 20;
 [lihat menjelaskan.tensor.ru]Benar:
[lihat menjelaskan.tensor.ru]Benar:CREATE INDEX ON tbl(pk)
WHERE critical;
 [lihat menjelaskan.tensor.ru]Seperti yang Anda lihat, pemfilteran telah sepenuhnya hilang dari rencana, dan permintaannya menjadi 5 kali lebih cepat .
[lihat menjelaskan.tensor.ru]Seperti yang Anda lihat, pemfilteran telah sepenuhnya hilang dari rencana, dan permintaannya menjadi 5 kali lebih cepat .# 5: tabel jarang
Kapan muncul
Berbagai upaya untuk membuat antrian tugas pemrosesan sendiri ketika sejumlah besar pembaruan / penghapusan catatan di atas meja menyebabkan situasi sejumlah besar catatan "mati".Cara mengenali
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- 1KB
&& shared hit + shared read > 64
Rekomendasi
Lakukan VACUUM [FULL]
secara manual atau lakukan uji autovacuum autofrequently dengan menyempurnakan parameternya, termasuk untuk tabel tertentu .Dalam kebanyakan kasus, masalah-masalah ini disebabkan oleh permintaan yang tidak terstruktur dengan buruk ketika melakukan panggilan dari logika bisnis, seperti yang dibahas dalam PostgreSQL Antipatterns: memerangi gerombolan "orang mati" .
Tetapi Anda perlu memahami bahwa VACUUM FULL mungkin tidak selalu membantu. Untuk kasus seperti itu, Anda harus membiasakan diri dengan algoritma dari artikel DBA: ketika VACUUM lewat, kami membersihkan tabel secara manual .
# 6: membaca dari tengah indeks
Kapan muncul
Tampaknya mereka tidak banyak membaca, dan semuanya berdasarkan indeks, dan mereka tidak memfilter apa pun ekstra - tapi bagaimanapun, secara signifikan lebih banyak halaman dibaca daripada yang kita inginkan.Cara mengenali
-> Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- 1KB
&& shared hit + shared read > 64
Rekomendasi
Lihat dengan cermat struktur indeks yang digunakan dan bidang kunci yang ditentukan dalam permintaan - kemungkinan besar, bagian dari indeks tidak ditentukan . Kemungkinan besar, Anda harus membuat indeks yang serupa, tetapi tanpa bidang awalan atau belajar cara mengulangi nilai-nilai mereka .Contoh:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 100)::integer fk_org
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_org, fk_cli);
SELECT
*
FROM
tbl
WHERE
fk_cli = 999
LIMIT 20;
 [lihat menjelaskan.tensor.ru] Segalanyatampak baik-baik saja, bahkan berdasarkan indeks, tetapi entah bagaimana mencurigakan - untuk masing-masing dari 20 catatan baca saya harus mengurangi 4 halaman data, 32KB per catatan - bukankah itu tebal? Ya, dan nama indeksnya sugestif. Kami memperbaiki:
[lihat menjelaskan.tensor.ru] Segalanyatampak baik-baik saja, bahkan berdasarkan indeks, tetapi entah bagaimana mencurigakan - untuk masing-masing dari 20 catatan baca saya harus mengurangi 4 halaman data, 32KB per catatan - bukankah itu tebal? Ya, dan nama indeksnya sugestif. Kami memperbaiki:tbl_fk_org_fk_cli_idxCREATE INDEX ON tbl(fk_cli);
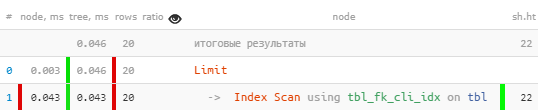 [lihat menjelaskan.tensor.ru]Tiba-tiba - 10 kali lebih cepat dan 4 kali lebih sedikit membaca !
[lihat menjelaskan.tensor.ru]Tiba-tiba - 10 kali lebih cepat dan 4 kali lebih sedikit membaca !Contoh lain dari situasi penggunaan indeks yang tidak efisien dapat dilihat pada artikel DBA: Temukan Indeks Tidak Berguna .
# 7: CTE × CTE
Kapan muncul
Dalam kueri kami mengetik CTE "gemuk" dari tabel yang berbeda, dan kemudian memutuskan untuk melakukannya di antara mereka JOIN.Kasing ini relevan untuk versi di bawah v12 atau permintaan dari WITH MATERIALIZED.Cara mengenali
-> CTE Scan
&& loops > 10
&& loops × (rows + RRbF) > 10000
-- CTE
Rekomendasi
Menganalisis permintaan dengan cermat - apakah CTE diperlukan di sini ? Jika semua sama, maka terapkan "merobek" di hstore / json sesuai dengan model yang dijelaskan dalam PostgreSQL Antipatterns: tekan kamus dengan BERGABUNG berat .# 8: swap ke disk (temp ditulis)
Kapan muncul
Pemrosesan satu kali (pengurutan atau unikisasi) sejumlah besar catatan tidak sesuai dengan memori yang dialokasikan untuk ini.Cara mengenali
-> *
&& temp written > 0
Rekomendasi
Jika jumlah memori yang digunakan oleh operasi tidak jauh melebihi nilai yang ditetapkan dari parameter work_mem , ada baiknya menyesuaikannya. Anda dapat langsung di konfigurasi untuk semua orang, tetapi Anda dapat melewatinya SET [LOCAL]untuk permintaan / transaksi tertentu.Contoh:SHOW work_mem;
SELECT
random()
FROM
generate_series(1, 1000000)
ORDER BY
1;
 [lihat menjelaskan.tensor.ru]Benar:
[lihat menjelaskan.tensor.ru]Benar:SET work_mem = '128MB';
 [lihat menjelaskan.tensor.ru]Untuk alasan yang jelas, jika hanya memori yang digunakan, bukan disk, maka permintaan akan dieksekusi lebih cepat. Pada saat yang sama, sebagian beban dari HDD juga dihapus.Tetapi Anda perlu memahami bahwa mengalokasikan banyak memori selalu tidak berhasil - itu tidak akan cukup untuk semua orang.
[lihat menjelaskan.tensor.ru]Untuk alasan yang jelas, jika hanya memori yang digunakan, bukan disk, maka permintaan akan dieksekusi lebih cepat. Pada saat yang sama, sebagian beban dari HDD juga dihapus.Tetapi Anda perlu memahami bahwa mengalokasikan banyak memori selalu tidak berhasil - itu tidak akan cukup untuk semua orang.# 9: statistik yang tidak relevan
Kapan muncul
Mereka menuangkan banyak sekaligus ke dalam database, tetapi tidak berhasil mengusir mereka ANALYZE.Cara mengenali
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& ratio >> 10
Rekomendasi
Lakukan hal yang sama ANALYZE.Situasi ini dijelaskan lebih terinci dalam Antipattern PostgreSQL: statistik ada di kepala .
# 10: "Ada yang salah"
Kapan muncul
Ada harapan kunci yang dipaksakan oleh permintaan yang bersaing, atau tidak ada cukup sumber daya perangkat keras CPU / hypervisor.Cara mengenali
-> *
&& (shared hit / 8K) + (shared read / 1K) < time / 1000
-- RAM hit = 64MB/s, HDD read = 8MB/s
&& time > 100ms -- ,
Rekomendasi
Gunakan sistem eksternal untuk memonitor server untuk mengunci atau konsumsi sumber daya yang tidak normal. Tentang versi kami dari organisasi proses ini untuk ratusan server, kami sudah berbicara di sini dan di sini .