Panda tidak perlu diperkenalkan: hari ini itu adalah alat utama untuk menganalisis data dengan Python. Saya bekerja sebagai spesialis analisis data, dan terlepas dari kenyataan bahwa saya menggunakan panda setiap hari, saya tidak pernah berhenti terkejut dengan keragaman fungsi perpustakaan ini. Dalam artikel ini saya ingin berbicara tentang lima fungsi panda yang kurang dikenal yang baru-baru ini saya pelajari dan sekarang digunakan secara produktif.Untuk pemula: Pandas adalah toolkit berkinerja tinggi untuk analisis data dalam Python dengan struktur data yang sederhana dan nyaman. Nama ini berasal dari konsep "data panel", istilah ekonometrik yang mengacu pada data pada pengamatan subjek yang sama selama periode waktu yang berbeda.Di sini Anda dapat mengunduh Jupyter Notebook dengan contoh-contoh dari artikel tersebut.1. Date Ranges [Date Ranges]
Seringkali Anda perlu menentukan rentang tanggal saat meminta data dari API atau basis data eksternal. Panda tidak akan meninggalkan kita dalam masalah. Hanya untuk kasus-kasus ini, ada fungsi data_range , yang mengembalikan array tanggal bertambah hari, bulan, tahun, dll.Katakanlah kita membutuhkan rentang tanggal berdasarkan hari:date_from = "2019-01-01"
date_to = "2019-01-12"
date_range = pd.date_range(date_from, date_to, freq="D")
date_range
 Kami akan mengubah yang dihasilkan dari
Kami akan mengubah yang dihasilkan dari date_rangepasangan tanggal "dari" dan "ke", yang dapat ditransfer ke fungsi yang sesuai.for i, (date_from, date_to) in enumerate(zip(date_range[:-1], date_range[1:]), 1):
date_from = date_from.date().isoformat()
date_to = date_to.date().isoformat()
print("%d. date_from: %s, date_to: %s" % (i, date_from, date_to))
1. date_from: 2019-01-01, date_to: 2019-01-02
2. date_from: 2019-01-02, date_to: 2019-01-03
3. date_from: 2019-01-03, date_to: 2019-01-04
4. date_from: 2019-01-04, date_to: 2019-01-05
5. date_from: 2019-01-05, date_to: 2019-01-06
6. date_from: 2019-01-06, date_to: 2019-01-07
7. date_from: 2019-01-07, date_to: 2019-01-08
8. date_from: 2019-01-08, date_to: 2019-01-09
9. date_from: 2019-01-09, date_to: 2019-01-10
10. date_from: 2019-01-10, date_to: 2019-01-11
11. date_from: 2019-01-11, date_to: 2019-01-12
2. Gabungkan dengan indikator sumber [Gabungkan dengan indikator]
Menggabungkan dua set data, anehnya, proses menggabungkan dua set data menjadi satu yang barisnya dipetakan berdasarkan kolom atau properti umum.Salah satu dari dua argumen untuk fungsi gabungan, yang entah bagaimana saya lewatkan, adalah indicator. "Indikator" menambahkan kolom _mergeke DataFrame yang menunjukkan dari mana asal baris, dari kiri, kanan, atau kedua DataFrames. Kolom _mergebisa sangat berguna ketika bekerja dengan kumpulan data besar untuk memverifikasi bahwa penggabungan tersebut benar.left = pd.DataFrame({"key": ["key1", "key2", "key3", "key4"], "value_l": [1, 2, 3, 4]})
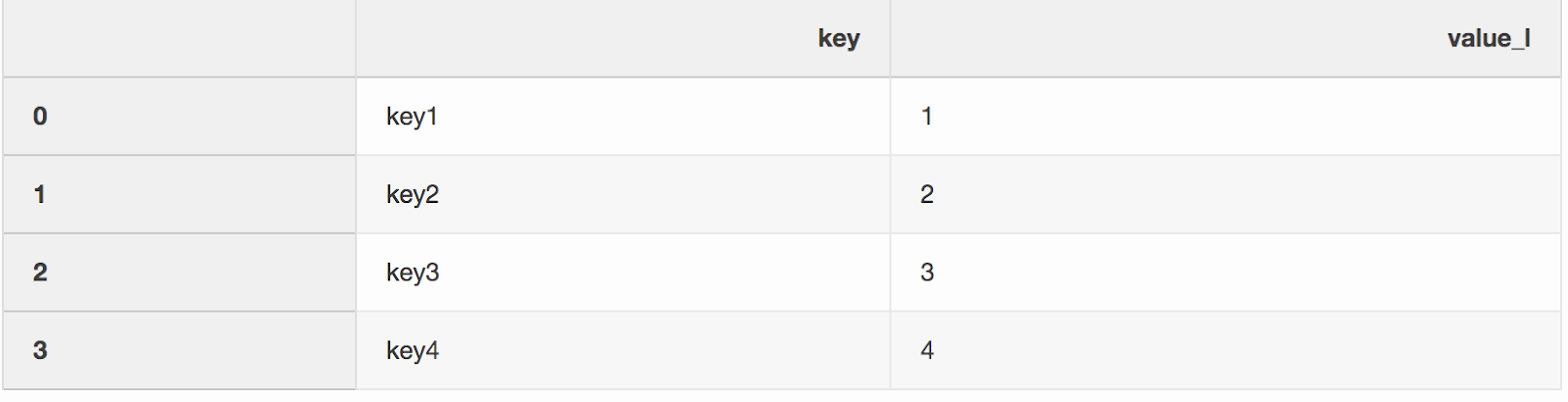
right = pd.DataFrame({"key": ["key3", "key2", "key1", "key6"], "value_r": [3, 2, 1, 6]})
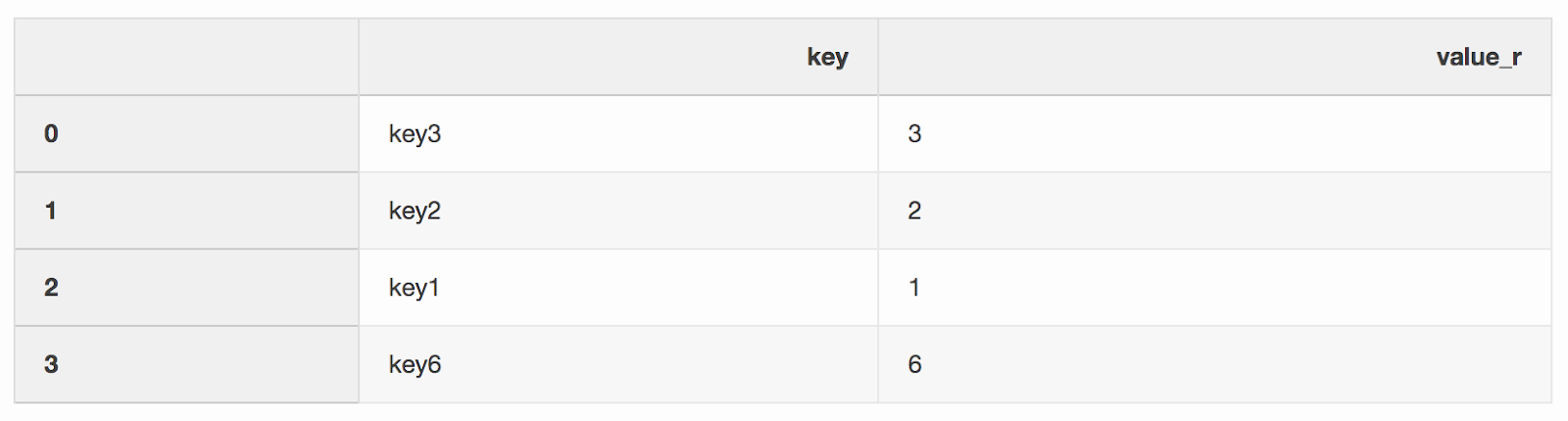
df_merge = left.merge(right, on='key', how='left', indicator=True)
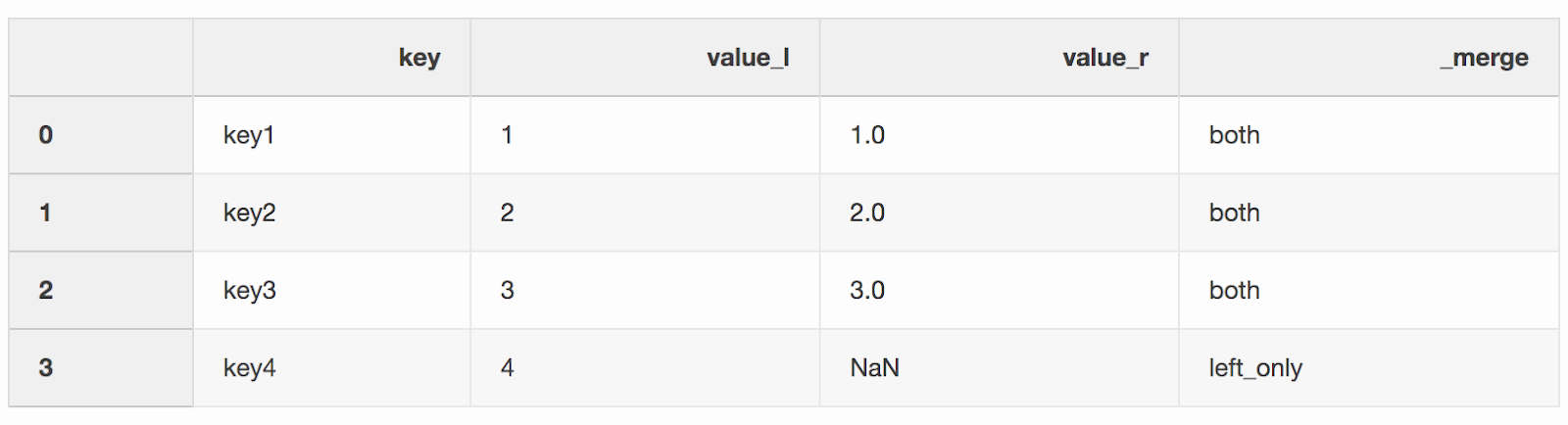 Kolom
Kolom _mergedapat digunakan untuk memeriksa apakah jumlah baris yang benar dengan data diambil dari kedua DataFrames.df_merge._merge.value_counts()
both 3
left_only 1
right_only 0
Name: _merge, dtype: int64
3. Gabungkan dengan nilai terdekat [Gabungkan terdekat]
Ketika bekerja dengan data keuangan, seperti cryptocurrency dan sekuritas, mungkin perlu membandingkan kuotasi (perubahan harga) dengan transaksi. Katakanlah kita ingin menggabungkan setiap perdagangan dengan penawaran yang diperbarui beberapa milidetik sebelum perdagangan. Panda memiliki fungsi merge_asofyang memungkinkan untuk menggabungkan DataFrames dengan nilai kunci terdekat ( timestampdalam kasus kami). Kumpulan data dengan penawaran dan penawaran diambil dari contoh panda .DataFrame quotes("penawaran") berisi perubahan harga untuk berbagai saham. Sebagai aturan, ada lebih banyak penawaran daripada penawaran.quotes = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.023", "MSFT", 51.95, 51.96],
["2016-05-25 13:30:00.030", "MSFT", 51.97, 51.98],
["2016-05-25 13:30:00.041", "MSFT", 51.99, 52.00],
["2016-05-25 13:30:00.048", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.049", "AAPL", 97.99, 98.01],
["2016-05-25 13:30:00.072", "GOOG", 720.50, 720.88],
["2016-05-25 13:30:00.075", "MSFT", 52.01, 52.03],
],
columns=["timestamp", "ticker", "bid", "ask"],
)
quotes['timestamp'] = pd.to_datetime(quotes['timestamp'])
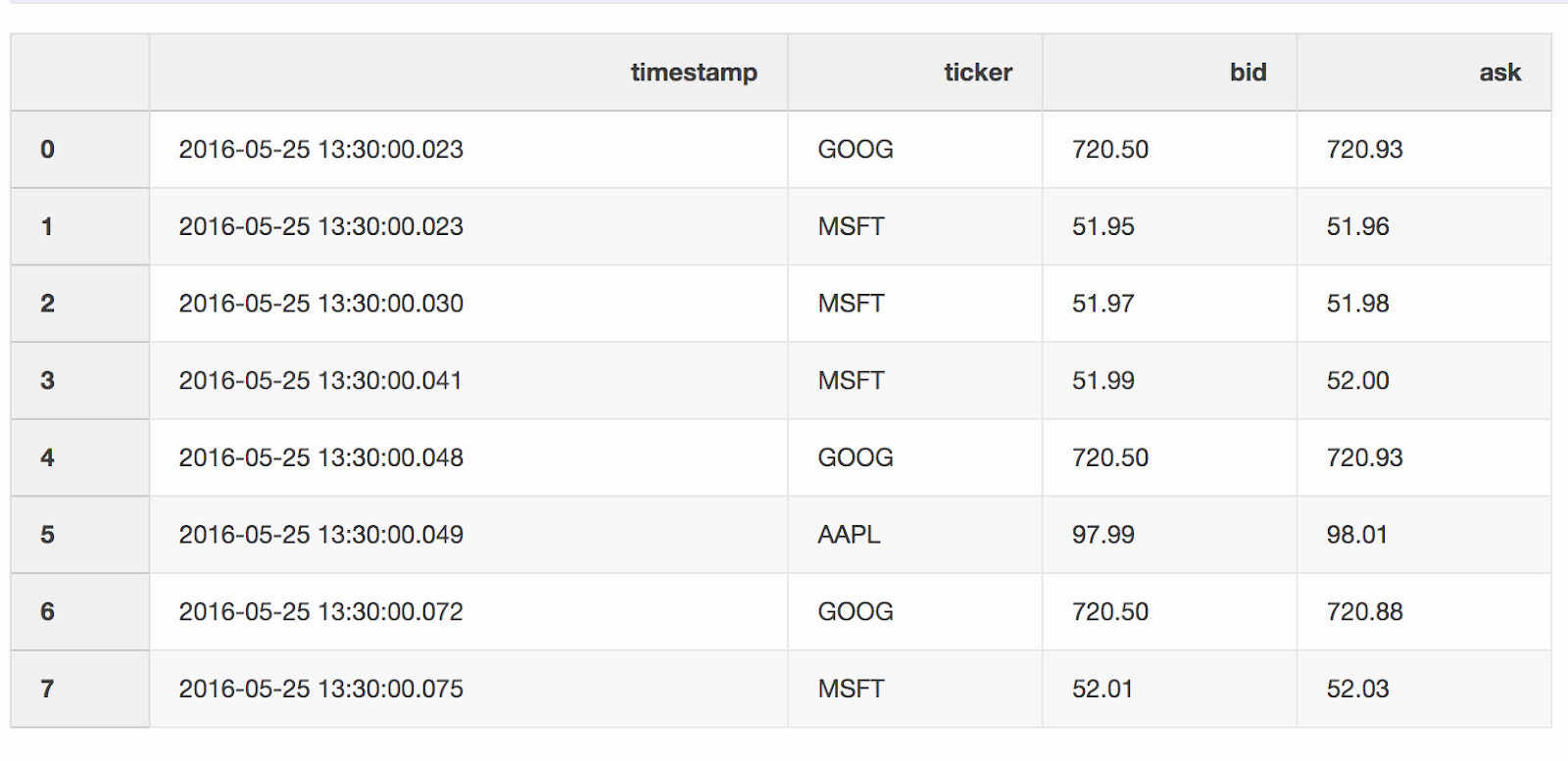 DataFrame
DataFrame tradesberisi penawaran untuk berbagai saham.trades = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "MSFT", 51.95, 75],
["2016-05-25 13:30:00.038", "MSFT", 51.95, 155],
["2016-05-25 13:30:00.048", "GOOG", 720.77, 100],
["2016-05-25 13:30:00.048", "GOOG", 720.92, 100],
["2016-05-25 13:30:00.048", "AAPL", 98.00, 100],
],
columns=["timestamp", "ticker", "price", "quantity"],
)
trades['timestamp'] = pd.to_datetime(trades['timestamp'])
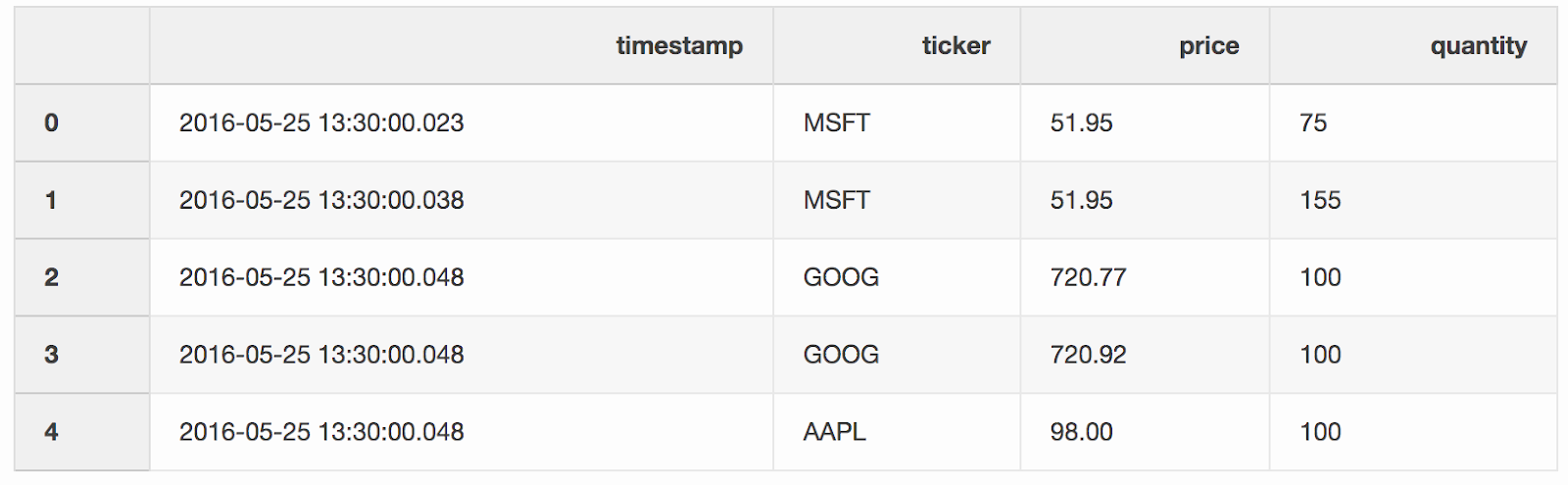 Kami menggabungkan transaksi dan penawaran dengan ticker (instrumen yang dikutip, seperti saham), dengan ketentuan bahwa
Kami menggabungkan transaksi dan penawaran dengan ticker (instrumen yang dikutip, seperti saham), dengan ketentuan bahwa timestampkutipan terakhir mungkin 10 ms lebih kecil dari transaksi. Jika kuotasi muncul sebelum transaksi selama lebih dari 10 ms, bid (harga yang siap dibayar oleh pembeli) dan tanyakan (harga di mana penjual siap menjual) untuk penawaran ini null(ticker AAPL dalam contoh ini).pd.merge_asof(trades, quotes, on="timestamp", by='ticker', tolerance=pd.Timedelta('10ms'), direction='backward')

4. Membuat laporan Excel
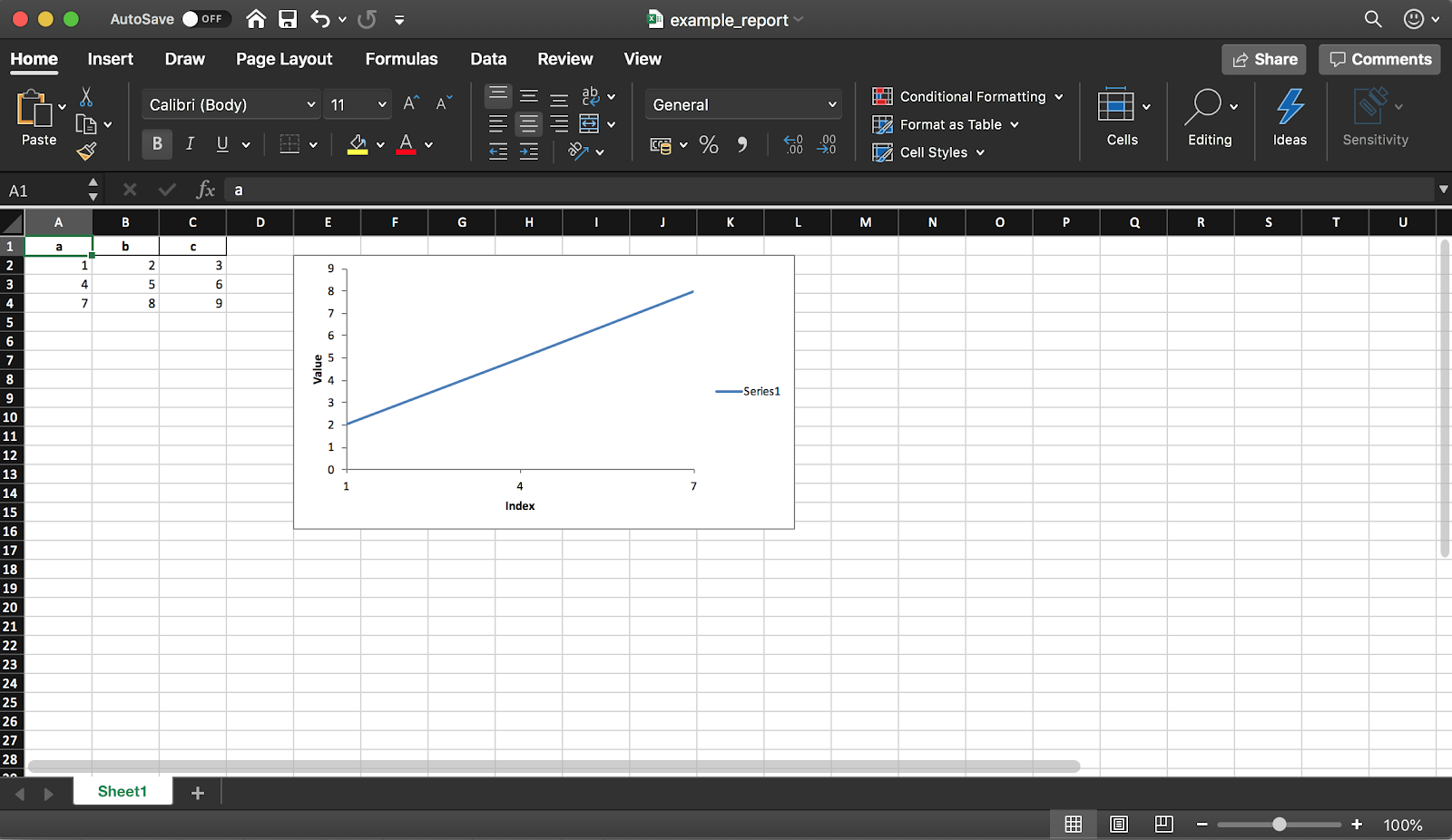 Pandas (dengan pustaka XlsxWriter) memungkinkan Anda membuat laporan Excel dari DataFrame. Ini menghemat banyak waktu - tidak ada lagi mengekspor DataFrame ke CSV dan pemformatan manual ke Excel. Semua jenis diagram , dll. Juga tersedia .
Pandas (dengan pustaka XlsxWriter) memungkinkan Anda membuat laporan Excel dari DataFrame. Ini menghemat banyak waktu - tidak ada lagi mengekspor DataFrame ke CSV dan pemformatan manual ke Excel. Semua jenis diagram , dll. Juga tersedia .df = pd.DataFrame(pd.np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=["a", "b", "c"])
Cuplikan kode di bawah ini membuat tabel dalam format Excel. Batalkan komentar pada baris untuk menyimpannya ke file writer.save().report_name = 'example_report.xlsx'
sheet_name = 'Sheet1'
writer = pd.ExcelWriter(report_name, engine='xlsxwriter')
df.to_excel(writer, sheet_name=sheet_name, index=False)
Seperti yang disebutkan sebelumnya, menggunakan perpustakaan Anda juga dapat menambahkan grafik ke laporan. Anda perlu mengatur jenis bagan (linear dalam contoh kami) dan rentang data untuk itu (rentang data harus dalam tabel Excel).
workbook = writer.book
worksheet = writer.sheets[sheet_name]
chart = workbook.add_chart({'type': 'line'})
chart.add_series({
'categories': [sheet_name, 1, 0, 3, 0],
'values': [sheet_name, 1, 1, 3, 1],
})
chart.set_x_axis({'name': 'Index', 'position_axis': 'on_tick'})
chart.set_y_axis({'name': 'Value', 'major_gridlines': {'visible': False}})
worksheet.insert_chart('E2', chart)
writer.save()
5. Menghemat ruang disk
Bekerja pada sejumlah besar proyek analisis data biasanya meninggalkan bekas dalam bentuk sejumlah besar data yang diproses dari berbagai percobaan. SSD pada laptop terisi cukup cepat. Panda memungkinkan Anda untuk mengompres data sambil menyimpan data ke disk dan kemudian membacanya lagi dari format terkompresi.Buat DataFrame besar dengan angka acak.df = pd.DataFrame(pd.np.random.randn(50000,300))
 Jika Anda menyimpannya sebagai CSV, file akan memakan hampir 300 MB pada hard drive Anda.
Jika Anda menyimpannya sebagai CSV, file akan memakan hampir 300 MB pada hard drive Anda.df.to_csv('random_data.csv', index=False)
Satu argumen compression='gzip'mengurangi ukuran file menjadi 136 MB.df.to_csv('random_data.gz', compression='gzip', index=False)
File terkompresi dibaca dengan cara yang sama seperti file biasa, jadi kami tidak kehilangan fungsionalitas apa pun.df = pd.read_csv('random_data.gz')
Kesimpulan
Trik kecil ini telah meningkatkan produktivitas pekerjaan harian saya dengan panda. Saya harap Anda belajar dari artikel ini tentang beberapa fitur berguna yang akan membantu Anda menjadi lebih produktif juga.Apa trik favorit Anda dengan panda?