Dalam beberapa kasus laporan liputan modern agak tidak berguna, dan metode untuk mengukurnya terutama hanya cocok untuk pengembang. Anda selalu dapat mengetahui persentase cakupan atau melihat kode yang tidak digunakan selama pengujian, tetapi bagaimana jika Anda ingin visibilitas, kesederhanaan dan otomatisasi? Di bawah potongan video dan transkrip dari sebuah laporan oleh Artem Eroshenko dari Qameta Software dari konferensi Heisenbug . Dia memperkenalkan beberapa solusi sederhana dan elegan yang dikembangkan yang membantu tim Yandex.Verticals mengevaluasi cakupan tes yang ditulis oleh insinyur otomatisasi uji. Artem akan memberi tahu Anda cara cepat mengetahui apa yang dicakup, seberapa tertutup, tes apa yang telah lulus, dan langsung melihat laporan visual.Nama saya Artyom Eroshenko eroshenkoamSaya telah melakukan otomatisasi pengujian selama lebih dari 10 tahun. Saya adalah manajer otomatisasi pengujian, manajer tim pengembangan alat, pengembang alat.Saat ini saya seorang konsultan di bidang pengujian otomasi, saya bekerja dengan beberapa perusahaan yang dengannya kami membangun proses.Saya juga pengembang dan manajer rahasia Allure Report. Kami baru-baru ini memperbaiki hal yang keren : sekarang di JUnit 5 ada perlengkapan.
Di bawah potongan video dan transkrip dari sebuah laporan oleh Artem Eroshenko dari Qameta Software dari konferensi Heisenbug . Dia memperkenalkan beberapa solusi sederhana dan elegan yang dikembangkan yang membantu tim Yandex.Verticals mengevaluasi cakupan tes yang ditulis oleh insinyur otomatisasi uji. Artem akan memberi tahu Anda cara cepat mengetahui apa yang dicakup, seberapa tertutup, tes apa yang telah lulus, dan langsung melihat laporan visual.Nama saya Artyom Eroshenko eroshenkoamSaya telah melakukan otomatisasi pengujian selama lebih dari 10 tahun. Saya adalah manajer otomatisasi pengujian, manajer tim pengembangan alat, pengembang alat.Saat ini saya seorang konsultan di bidang pengujian otomasi, saya bekerja dengan beberapa perusahaan yang dengannya kami membangun proses.Saya juga pengembang dan manajer rahasia Allure Report. Kami baru-baru ini memperbaiki hal yang keren : sekarang di JUnit 5 ada perlengkapan.Kerangka Atlas
Perkembangan saya adalah Kerangka Atlas . Jika seseorang mulai mengotomatisasi pada 2012, ketika driver web Java baru saja memulai, pada saat itu saya membuat perpustakaan open source yang disebut Elemen HTML .Html Elements memiliki kelanjutan dan pemikiran ulang di perpustakaan Atlas, yang dibangun di atas antarmuka: tidak ada kelas seperti itu, tidak ada bidang, perpustakaan yang sangat nyaman, ringan dan mudah diperluas. Jika Anda memiliki keinginan untuk memahaminya, Anda dapat membaca artikel atau melihat laporannya .Laporan saya dikhususkan untuk masalah otomatisasi uji dan terutama untuk pelapis. Sebagai latar belakang, saya ingin merujuk pada bagaimana proses pengujian diatur dalam Yandex.Verticals.Bagaimana cara otomasi bekerja secara vertikal?
Hanya ada empat orang di tim otomasi pengujian Yandex. Vertikal yang mengotomatisasi empat layanan: Yandex.Avto, Work, Real Estate, dan Suku Cadang. Artinya, ini adalah tim kecil automators yang melakukan banyak hal. Kami mengotomatiskan API, antarmuka web, aplikasi seluler, dan sebagainya. Secara total, kami memiliki sekitar 15,5 ribu tes yang dilakukan pada level yang berbeda.Stabilitas tes dalam tim adalah sekitar 97%, meskipun beberapa rekan saya mengatakan sekitar 99%. Stabilitas tinggi seperti ini dicapai dengan tepat berkat pengujian singkat pada teknologi yang sangat asli. Biasanya, pengujian kami memakan waktu sekitar 15 menit, yang sangat luas, dan kami menjalankannya di sekitar 800 utas. Artinya, kami memiliki 800 browser yang dimulai pada saat yang sama - semacam stress test dari pengujian kami. Sebagai besi kita menggunakan Selenoid (Aerokube). Anda dapat mempelajari lebih lanjut tentang pengujian otomasi di Yandex.Verticals dengan menonton laporan 2017 saya, yang masih relevan.Fitur lain dari tim kami adalah bahwa kami mengotomatiskan segalanya , termasuk penguji manual, yang memberikan kontribusi besar bagi pengembangan otomatisasi pengujian. Bagi mereka, kami mengatur sekolah, mengajari mereka tes, mengajarkan cara menulis tes untuk API, antarmuka web, dan seringkali mereka membantu menyertai tes. Dengan demikian, orang-orang yang bertanggung jawab untuk rilis itu sendiri dapat segera memperbaiki tes, jika perlu.Di Verticals, pengembang pengujian menulis tes, dan mereka sangat tertarik pada pengembangan pengujian sehingga mereka bersaing dengan kami. Anda dapat mempelajari lebih lanjut tentang proses ini dari laporan "Siklus penuh pengujian Bereaksi aplikasi", di mana Alexei Androsov dan Natalya Stus berbicara tentang bagaimana mereka menulis tes Unit pada Puppeteer bersamaan dengan tes Java end-to-end kami.Teknisi otomatisasi uji juga menulis tes di tim kami. Namun seringkali kami mengembangkan beberapa pendekatan baru untuk mengoptimalkannya. Misalnya, kami menerapkan pengujian tangkapan layar, pengujian melalui moki, pengurangan pengujian. Secara umum, area kami sebagian besar adalah pengembang perangkat lunak dalam pengujian (SDET), kami lebih banyak tentang cara menulis tes, dan basis tes sebagian diisi oleh kami dan didukung oleh penguji manual.Pengembang juga membantu kami, dan itu keren.
Masalah yang muncul dalam proses ini adalah bahwa kita tidak selalu memahami apa yang sudah dibahas dan apa yang tidak. Melihat melalui 15 ribu tes, tidak selalu jelas apa yang sebenarnya kita periksa. Ini terutama benar dalam konteks komunikasi dengan manajer, yang, tentu saja, tidak menguji, tetapi memantau dan mengajukan pertanyaan. Khususnya, jika muncul pertanyaan apakah tombol tertentu telah diuji di antarmuka atau aliran, maka sulit untuk dijawab, karena Anda perlu membuka kode tes dan melihat informasi ini.Apa yang diuji dan apa yang tidak?
Jika Anda memiliki banyak tes dalam berbagai bahasa dan ditulis oleh orang-orang dengan berbagai tingkat pelatihan, maka cepat atau lambat muncul pertanyaan, apakah tes ini tidak bersinggungan sama sekali? Dalam konteks masalah ini, masalah cakupan menjadi sangat relevan. Saya akan menguraikan tiga topik utama:- Cara mengukur cakupan secara efektif.
- Cakupan untuk tes API.
- Cakupan untuk tes web.
Pertama-tama, mari kita tentukan bahwa ada dua cara perlindungan: mencakup persyaratan dan mencakup kode produk.Bagaimana cakupan persyaratan diukur
Pertimbangkan cakupan persyaratan menggunakan auto.ru sebagai contoh. Di tempat tester auto.ru, saya akan melakukan hal berikut. Pertama, saya akan google dan segera menemukan tabel persyaratan khusus. Ini adalah dasar dari cakupan persyaratan.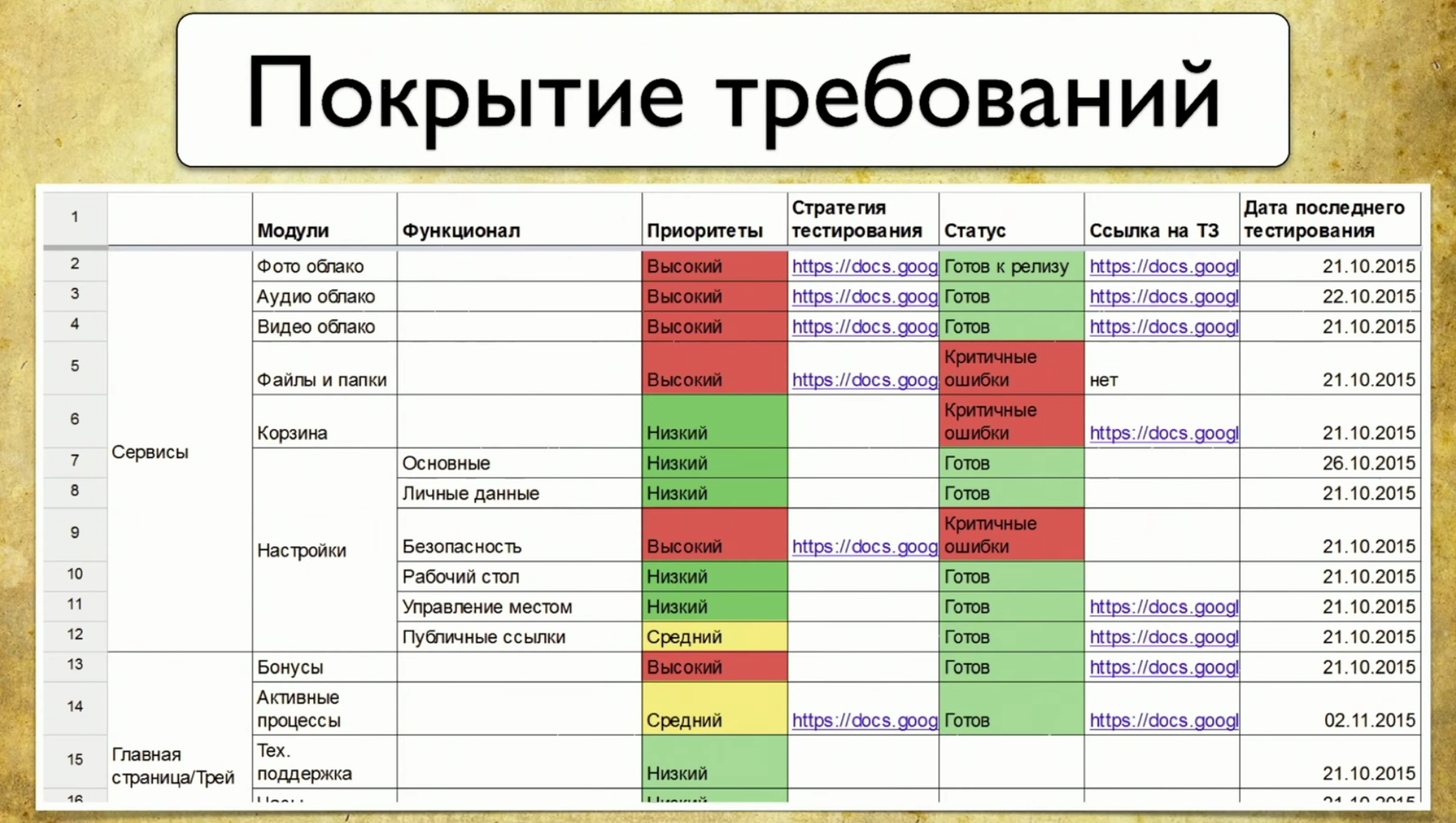 Dalam tabel ini, nama-nama persyaratan ditulis di sebelah kiri. Dalam hal ini: akun, iklan, verifikasi, dan pembayaran, yaitu verifikasi pengumuman. Secara umum, ini adalah liputannya. Detail bagian kiri tergantung pada level tester. Misalnya, insinyur dari Google memiliki 49 jenis pelapis yang diuji pada tingkat yang berbeda.Sisi kanan tabel adalah atribut persyaratan. Kita dapat menggunakan apa pun dalam bentuk atribut, misalnya: prioritas, cakupan, dan status. Ini mungkin tanggal rilis terakhir.
Dalam tabel ini, nama-nama persyaratan ditulis di sebelah kiri. Dalam hal ini: akun, iklan, verifikasi, dan pembayaran, yaitu verifikasi pengumuman. Secara umum, ini adalah liputannya. Detail bagian kiri tergantung pada level tester. Misalnya, insinyur dari Google memiliki 49 jenis pelapis yang diuji pada tingkat yang berbeda.Sisi kanan tabel adalah atribut persyaratan. Kita dapat menggunakan apa pun dalam bentuk atribut, misalnya: prioritas, cakupan, dan status. Ini mungkin tanggal rilis terakhir. Dengan demikian, beberapa data muncul dalam tabel. Anda dapat menggunakan alat profesional untuk mempertahankan tabel persyaratan, misalnya, TestRail.Ada informasi tentang pohon di sebelah kanan: folder menunjukkan persyaratan apa yang kita miliki, bagaimana mereka dapat dicakup. Ada test case dan sebagainya.
Dengan demikian, beberapa data muncul dalam tabel. Anda dapat menggunakan alat profesional untuk mempertahankan tabel persyaratan, misalnya, TestRail.Ada informasi tentang pohon di sebelah kanan: folder menunjukkan persyaratan apa yang kita miliki, bagaimana mereka dapat dicakup. Ada test case dan sebagainya. Dalam Vertikal, proses ini terlihat seperti ini: penguji manual menjelaskan persyaratan dan kasus uji, kemudian meneruskannya ke otomatisasi uji, dan alat otomatis menulis kode untuk pengujian ini. Selain itu, sebelumnya kami diberi uji kasus rinci di mana penguji manual menggambarkan seluruh struktur. Kemudian seseorang membuat komitmen pada github, dan tes mulai menguntungkan.Apa pro dan kontra dari pendekatan ini? Kelebihannya adalah bahwa pendekatan ini menjawab pertanyaan kami. Jika manajer bertanya apa yang telah kita bahas, saya akan membuka tablet dan menunjukkan fitur apa saja yang dicakup. Di sisi lain, persyaratan ini harus selalu diperbarui, dan menjadi usang dengan sangat cepat.Ketika Anda memiliki 15 ribu tes, melihat TestRail seperti melihat bintang di ruang angkasa: itu meledak untuk waktu yang lama, dan cahaya telah mencapai Anda sekarang. Anda melihat test case saat ini, dan itu sudah usang sejak lama dan tidak dapat dibatalkan.Masalah ini sulit dipecahkan. Bagi kami, ini umumnya dua dunia yang berbeda: ada dunia otomatisasi yang berputar sesuai dengan hukumnya sendiri, di mana setiap pengujian yang gagal segera diperbaiki, dan ada dunia pengujian manual dan kartu persyaratan. Dinding di antara mereka tidak bisa ditembus, kecuali Anda menggunakan Allure Server. Kami sekarang hanya memecahkan masalah ini untuk mereka.Poin ketiga dari “pro dan kontra” adalah perlunya pekerjaan manual. Dalam proyek baru, Anda perlu membuat kembali peta persyaratan, menulis semua kasus uji, dan sebagainya. Itu selalu membutuhkan kerja manual, dan itu sebenarnya sangat menyedihkan.
Dalam Vertikal, proses ini terlihat seperti ini: penguji manual menjelaskan persyaratan dan kasus uji, kemudian meneruskannya ke otomatisasi uji, dan alat otomatis menulis kode untuk pengujian ini. Selain itu, sebelumnya kami diberi uji kasus rinci di mana penguji manual menggambarkan seluruh struktur. Kemudian seseorang membuat komitmen pada github, dan tes mulai menguntungkan.Apa pro dan kontra dari pendekatan ini? Kelebihannya adalah bahwa pendekatan ini menjawab pertanyaan kami. Jika manajer bertanya apa yang telah kita bahas, saya akan membuka tablet dan menunjukkan fitur apa saja yang dicakup. Di sisi lain, persyaratan ini harus selalu diperbarui, dan menjadi usang dengan sangat cepat.Ketika Anda memiliki 15 ribu tes, melihat TestRail seperti melihat bintang di ruang angkasa: itu meledak untuk waktu yang lama, dan cahaya telah mencapai Anda sekarang. Anda melihat test case saat ini, dan itu sudah usang sejak lama dan tidak dapat dibatalkan.Masalah ini sulit dipecahkan. Bagi kami, ini umumnya dua dunia yang berbeda: ada dunia otomatisasi yang berputar sesuai dengan hukumnya sendiri, di mana setiap pengujian yang gagal segera diperbaiki, dan ada dunia pengujian manual dan kartu persyaratan. Dinding di antara mereka tidak bisa ditembus, kecuali Anda menggunakan Allure Server. Kami sekarang hanya memecahkan masalah ini untuk mereka.Poin ketiga dari “pro dan kontra” adalah perlunya pekerjaan manual. Dalam proyek baru, Anda perlu membuat kembali peta persyaratan, menulis semua kasus uji, dan sebagainya. Itu selalu membutuhkan kerja manual, dan itu sebenarnya sangat menyedihkan.Bagaimana cakupan kode diukur
Alternatif untuk pendekatan ini adalah cakupan kode. Ini sepertinya menjadi solusi untuk masalah kita. Ini adalah bagaimana cakupan kode produk terlihat: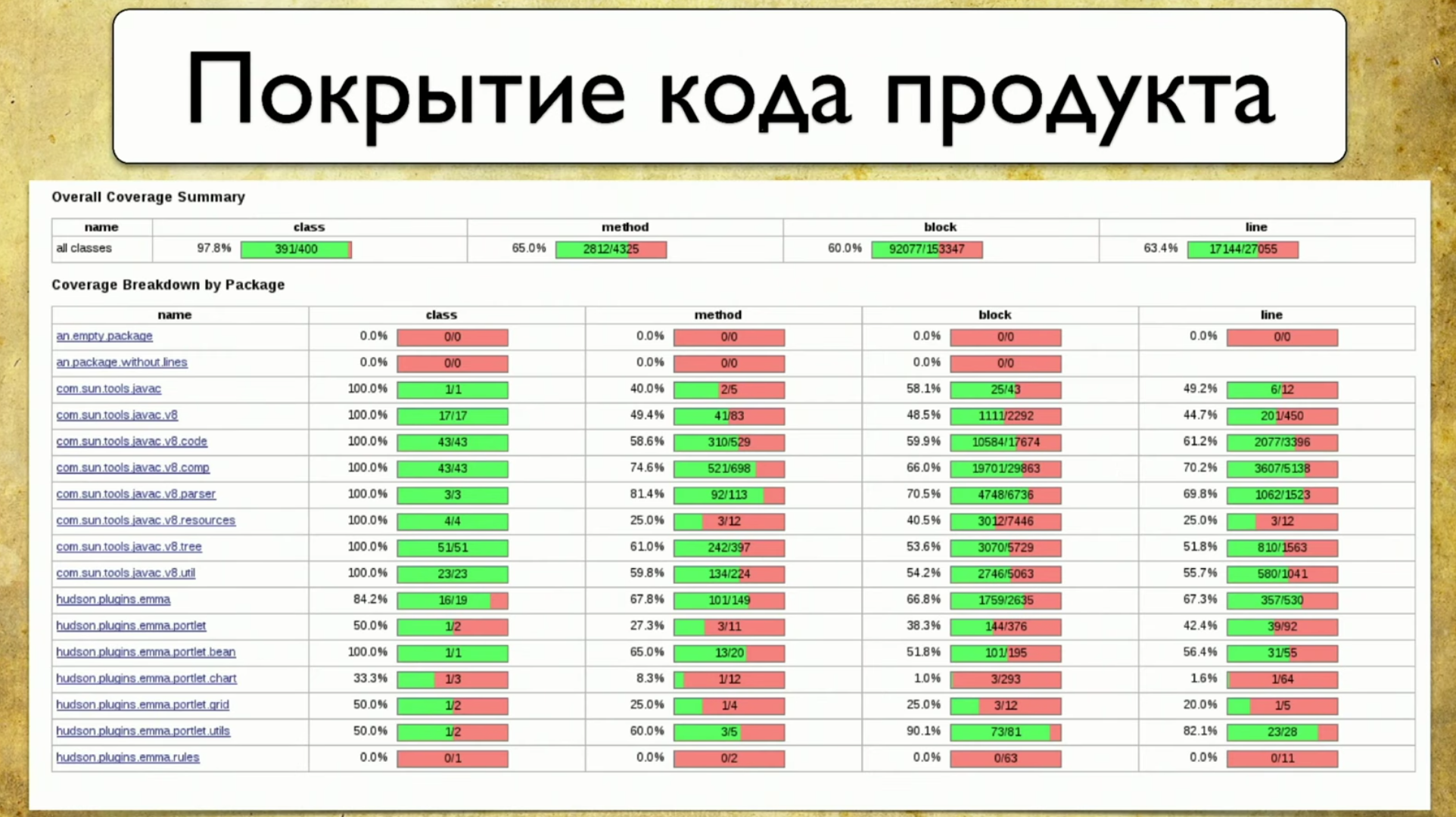 Ini mencerminkan cakupan paket, atau lebih tepatnya sebagian kecil dari apa yang sebenarnya dimiliki produk. Paket ditulis di sebelah kiri, karena fitur ditulis sebelumnya. Artinya, lapisan kami akhirnya melekat pada beberapa hal yang nyata, dalam hal ini - Paket. Atribut ditulis di sebelah kanan: cakupan dengan kelas, cakupan dengan metode, cakupan dengan blok kode dan cakupan dengan baris kode.Proses pengumpulan pertanggungan adalah untuk memahami baris kode mana yang lulus uji dan mana yang tidak. Ini adalah tugas yang cukup sederhana, tetapi baru-baru ini sangat relevan.
Ini mencerminkan cakupan paket, atau lebih tepatnya sebagian kecil dari apa yang sebenarnya dimiliki produk. Paket ditulis di sebelah kiri, karena fitur ditulis sebelumnya. Artinya, lapisan kami akhirnya melekat pada beberapa hal yang nyata, dalam hal ini - Paket. Atribut ditulis di sebelah kanan: cakupan dengan kelas, cakupan dengan metode, cakupan dengan blok kode dan cakupan dengan baris kode.Proses pengumpulan pertanggungan adalah untuk memahami baris kode mana yang lulus uji dan mana yang tidak. Ini adalah tugas yang cukup sederhana, tetapi baru-baru ini sangat relevan.Penyebutan pertama tentang cakupan kode kembali pada tahun 1963, tetapi kemajuan serius dalam arah ini hanya muncul sekarang.
Jadi, kami memiliki tes yang berinteraksi dengan sistem. Tidak masalah bagaimana dia berinteraksi dengannya: melalui front-end, API atau langsung merayap ke back-end - kita hanya akan berasumsi bahwa kita memilikinya.Maka instrumentasi harus dilakukan. Ini adalah beberapa proses yang memungkinkan Anda untuk memahami baris kode mana yang diperiksa dan mana yang tidak. Anda tidak perlu mempelajarinya secara terperinci, Anda hanya perlu mencari nama kerangka kerja Anda, di mana Anda menulis, berkata, Musim semi , lalu instrumentasi , dan liputan - dengan tiga kata ini Anda akan memahami bagaimana ini dilakukan.Saat pengujian Anda memeriksa baris kode mana yang terkena uji dan yang tidak kena, mereka menyimpan file dengan informasi tentang baris mana yang dicakup. Berdasarkan informasi ini, Anda memiliki data.Apa pro dan kontra dari cakupan kode?
Cakupan kode saya akan segera memanggil minus . Anda tidak akan datang ke manajer, Anda tidak akan menunjukkan pelat ini dan Anda tidak akan mengatakan bahwa semua orang telah otomatis, karena data ini tidak dapat dibaca, ia akan meminta Anda untuk mengembalikan data yang jelas sehingga Anda dapat dengan cepat melihat dan memahami segalanya.Laporan cakupan kode lebih dekat dengan pengembangan. Itu tidak dapat digunakan sebagai pendekatan normal untuk menyediakan semua data ke tim jika kami ingin seluruh tim dapat menonton. Keuntungan dari pendekatan ini adalah selalu menyediakan data yang relevan. Anda tidak harus melakukan banyak pekerjaan, semuanya otomatis untuk Anda. Cukup colokkan perpustakaan, sampul Anda mulai lepas landas - dan itu sangat keren.Keuntungan lain dari pendekatan ini adalah hanya membutuhkan penyesuaian. Tidak ada yang istimewa untuk dilakukan di sana - cukup dengan instruksi spesifik, sesuaikan cakupannya, dan ini bekerja secara otomatis.Cakupan persyaratan mengungkapkan persyaratan yang tidak terpenuhi, tetapi tidak memungkinkan untuk mengevaluasi kelengkapan terkait dengan kode. Misalnya, Anda mulai menulis fitur baru "otorisasi", cukup masukkan "fitur otorisasi", Anda mulai melemparkan kasus uji di atasnya. Anda tidak dapat langsung melihat cakupan ini dalam kode, bahkan jika Anda menulis beberapa kelas baru, masih tidak ada informasi - ada celah. Di sisi lain, ini adalah persyaratan otorisasi, bahkan ketika itu sudah akan diterapkan, ketika Anda menghitung cakupan di atasnya, bagian ini tidak dapat relevan, itu harus tetap up to date secara manual.Karena itu, kami punya ide: bagaimana jika kami mengambil yang terbaik dari semua orang? Agar liputan menjawab pertanyaan kami, itu selalu relevan dan hanya memerlukan penyesuaian. Kita hanya perlu melihat lapisan dari sudut yang berbeda, yaitu, mengambil sistem lain sebagai dasar lapisan tersebut. Pada saat yang sama, pastikan bahwa itu dikumpulkan sepenuhnya secara otomatis dan membawa banyak manfaat. Dan untuk ini kita akan membahas cakupan untuk tes API.
Keuntungan dari pendekatan ini adalah selalu menyediakan data yang relevan. Anda tidak harus melakukan banyak pekerjaan, semuanya otomatis untuk Anda. Cukup colokkan perpustakaan, sampul Anda mulai lepas landas - dan itu sangat keren.Keuntungan lain dari pendekatan ini adalah hanya membutuhkan penyesuaian. Tidak ada yang istimewa untuk dilakukan di sana - cukup dengan instruksi spesifik, sesuaikan cakupannya, dan ini bekerja secara otomatis.Cakupan persyaratan mengungkapkan persyaratan yang tidak terpenuhi, tetapi tidak memungkinkan untuk mengevaluasi kelengkapan terkait dengan kode. Misalnya, Anda mulai menulis fitur baru "otorisasi", cukup masukkan "fitur otorisasi", Anda mulai melemparkan kasus uji di atasnya. Anda tidak dapat langsung melihat cakupan ini dalam kode, bahkan jika Anda menulis beberapa kelas baru, masih tidak ada informasi - ada celah. Di sisi lain, ini adalah persyaratan otorisasi, bahkan ketika itu sudah akan diterapkan, ketika Anda menghitung cakupan di atasnya, bagian ini tidak dapat relevan, itu harus tetap up to date secara manual.Karena itu, kami punya ide: bagaimana jika kami mengambil yang terbaik dari semua orang? Agar liputan menjawab pertanyaan kami, itu selalu relevan dan hanya memerlukan penyesuaian. Kita hanya perlu melihat lapisan dari sudut yang berbeda, yaitu, mengambil sistem lain sebagai dasar lapisan tersebut. Pada saat yang sama, pastikan bahwa itu dikumpulkan sepenuhnya secara otomatis dan membawa banyak manfaat. Dan untuk ini kita akan membahas cakupan untuk tes API.API Cakupan Tes
Apa dasar dari cakupan? Untuk melakukan ini, kami menggunakan Swagger - ini adalah API dokumentasi. Sekarang saya tidak bisa membayangkan pekerjaan saya tanpa kesombongan, itu adalah alat yang saya terus gunakan untuk pengujian. Jika Anda tidak menggunakan kesombongan, saya sangat merekomendasikan mengunjungi situs dan membiasakan diri. Di sana Anda akan segera melihat contoh penggunaan yang sangat intuitif dan mudah dipahami.Sebenarnya, kesombongan adalah dokumentasi yang dihasilkan oleh layanan Anda. Itu mengandung:- Daftar permintaan.
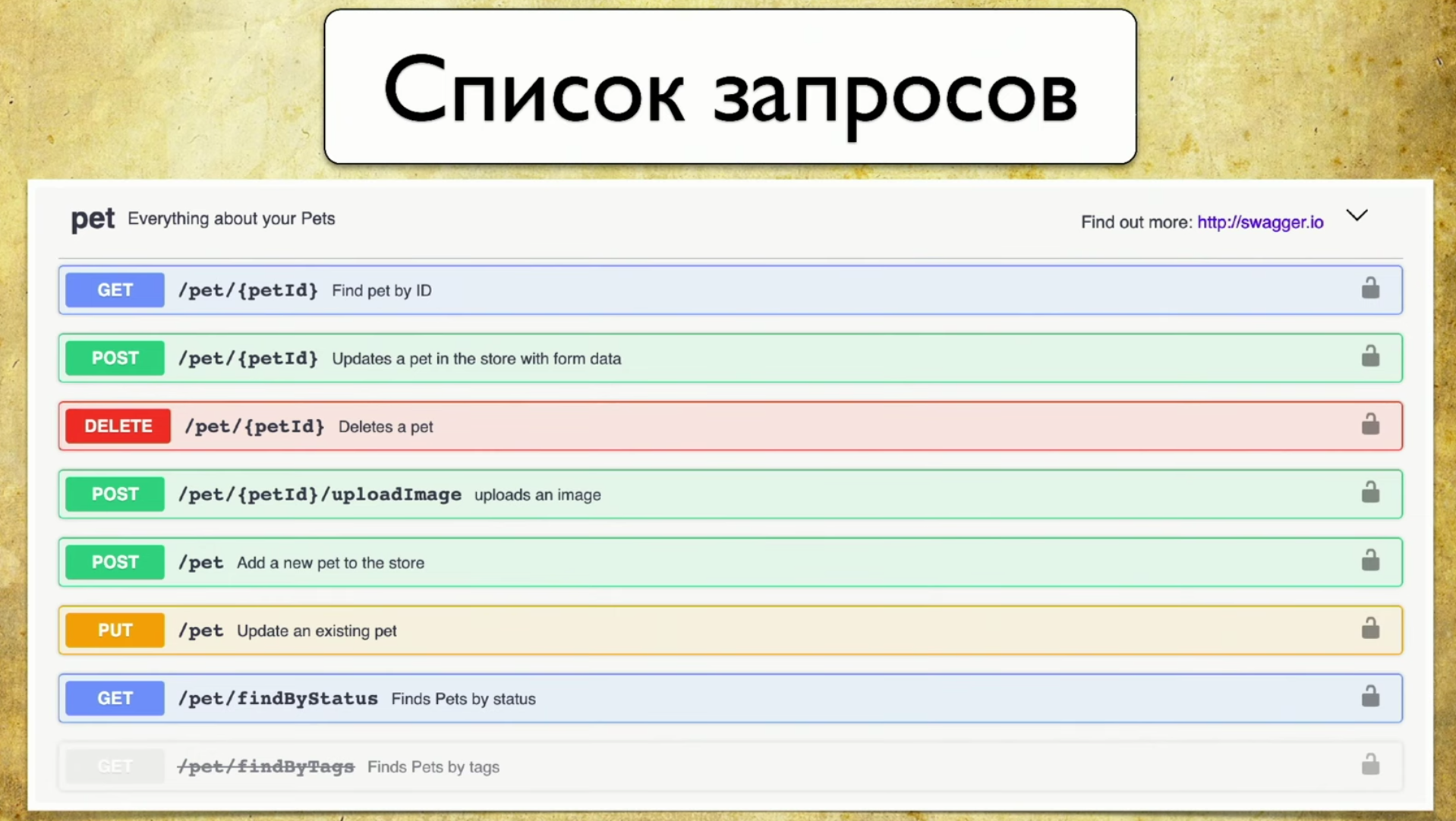
- Parameter permintaan: tidak perlu menarik pengembang dan menanyakan parameter apa.
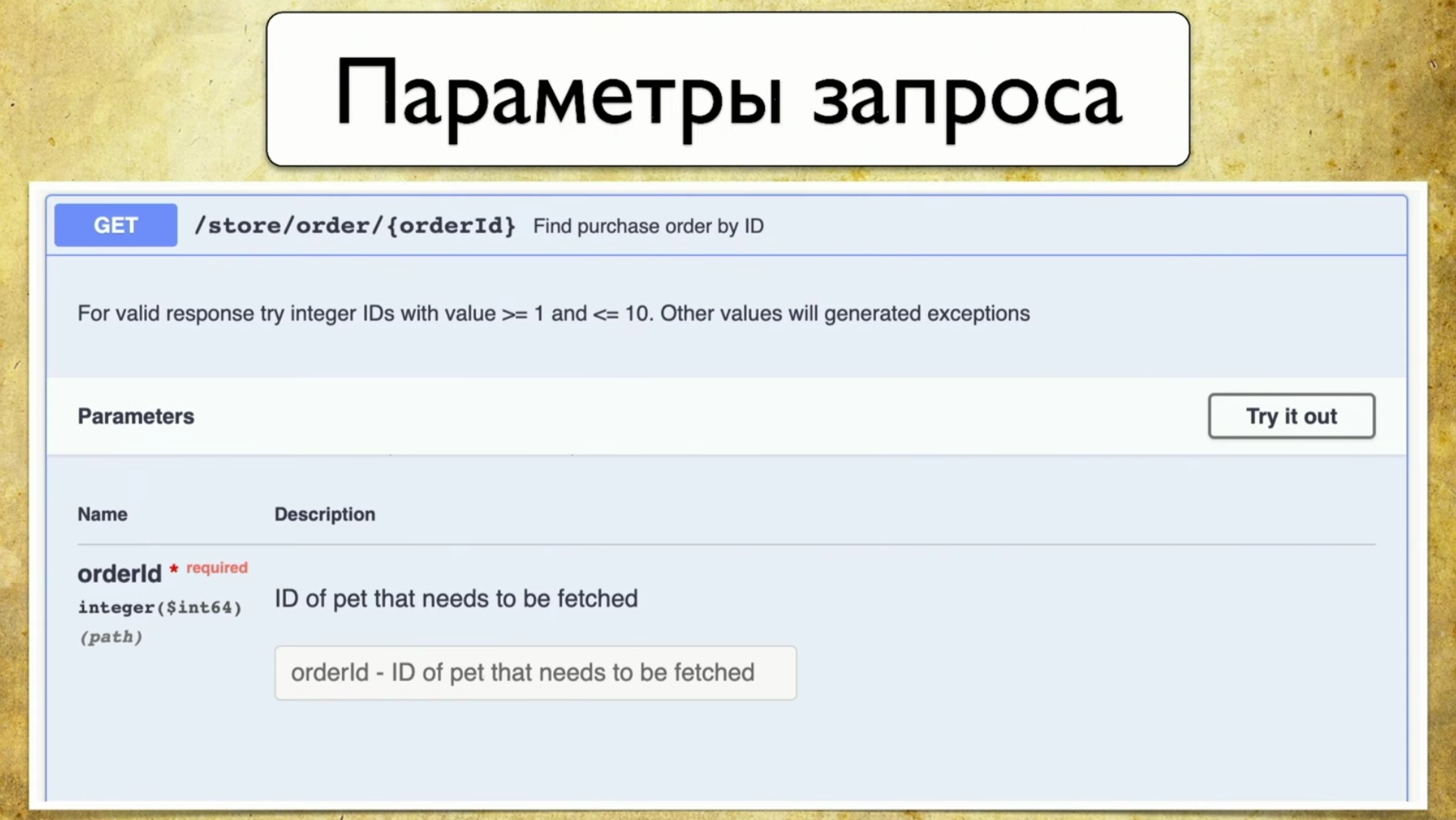
- Kode Jawaban

Prinsip operasi kesombongan adalah generasi. Tidak masalah kerangka mana yang Anda gunakan. Katakanlah Spring atau Go Server, Anda menggunakan komponen Codegen Swagger dan menghasilkan swagger.json . Ini adalah beberapa spesifikasi, atas dasar itulah UI yang indah kemudian ditarik.Penting bagi kami bahwa swagger.json digunakan : dukungannya tersedia untuk semua bahasa yang banyak digunakan.Kami memiliki spesifikasi Open API swagger.json . Ini terlihat seperti ini: Permintaan terlihat seperti ini: ringkasan, deskripsi, kode respons dan "pegangan" (jalur: / pengguna). Ada juga informasi tentang parameter kueri: semuanya terstruktur, ada parameter ID pengguna, ada di jalur tempat diperlukan, seperti deskripsi dan tipe - integer.
Permintaan terlihat seperti ini: ringkasan, deskripsi, kode respons dan "pegangan" (jalur: / pengguna). Ada juga informasi tentang parameter kueri: semuanya terstruktur, ada parameter ID pengguna, ada di jalur tempat diperlukan, seperti deskripsi dan tipe - integer. Ada kode jawaban, semuanya juga didokumentasikan:
Ada kode jawaban, semuanya juga didokumentasikan: Dan idenya datang kepada kami: kami memiliki layanan yang dihasilkan oleh Swagger, dan kami ingin menjaga Swagger yang sama dalam pengujian sehingga kami dapat membandingkannya nanti. Dengan kata lain, ketika tes berjalan, mereka menghasilkan Swagger yang persis sama, kami melemparkannya ke Swagger Diff, kami memahami parameter, pegangan, kode status apa yang telah kami periksa, dan sebagainya. Ini adalah instrumentasi yang sama, cakupan yang sama, hanya akhirnya dalam persyaratan yang kami pahami.
Dan idenya datang kepada kami: kami memiliki layanan yang dihasilkan oleh Swagger, dan kami ingin menjaga Swagger yang sama dalam pengujian sehingga kami dapat membandingkannya nanti. Dengan kata lain, ketika tes berjalan, mereka menghasilkan Swagger yang persis sama, kami melemparkannya ke Swagger Diff, kami memahami parameter, pegangan, kode status apa yang telah kami periksa, dan sebagainya. Ini adalah instrumentasi yang sama, cakupan yang sama, hanya akhirnya dalam persyaratan yang kami pahami.Tetapi bagaimana jika Anda membangun diff?
Kami menoleh ke perpustakaan Swagger diff , yang kami butuhkan untuk ini. Prinsip operasinya adalah seperti ini: Anda memiliki versi 1.0, dengan V versi API 1.1, keduanya menghasilkan swagger.json , lalu Anda melemparkannya ke Swagger diff dan melihat hasilnya.Hasilnya terlihat seperti ini: Anda memiliki informasi yang ada, misalnya, pena baru. Anda juga memiliki informasi tentang apa yang dihapus. Ini berarti saatnya untuk menghapus tes, mereka tidak lagi relevan. Dengan munculnya informasi tentang perubahan, parameternya juga berubah, jadi jelas bahwa tes Anda akan jatuh pada saat itu.Kami menyukai ide ini, dan kami mulai menerapkan. Saat kami memutuskan untuk melakukannya: kami memiliki "referensi" Swagger yang dihasilkan dari kode pengembang, kami juga memiliki tes API yang akan menghasilkan Swagger kami, dan kami akan berbeda di antara mereka.Jadi, kami menjalankan tes untuk layanan: kami memiliki Istirahat Tertanggung , yang dengan sendirinya mengakses layanan di API. Dan kami instrumen itu. Ada pendekatan: Anda dapat membuat filter, permintaan pergi ke sana - dan itu menyimpan informasi tentang permintaan dalam bentuk swagger.json langsung untuk dirinya sendiri.Berikut adalah seluruh kode yang perlu kami tulis, ada 69-70 baris - ini adalah kode yang sangat sederhana.
Anda memiliki informasi yang ada, misalnya, pena baru. Anda juga memiliki informasi tentang apa yang dihapus. Ini berarti saatnya untuk menghapus tes, mereka tidak lagi relevan. Dengan munculnya informasi tentang perubahan, parameternya juga berubah, jadi jelas bahwa tes Anda akan jatuh pada saat itu.Kami menyukai ide ini, dan kami mulai menerapkan. Saat kami memutuskan untuk melakukannya: kami memiliki "referensi" Swagger yang dihasilkan dari kode pengembang, kami juga memiliki tes API yang akan menghasilkan Swagger kami, dan kami akan berbeda di antara mereka.Jadi, kami menjalankan tes untuk layanan: kami memiliki Istirahat Tertanggung , yang dengan sendirinya mengakses layanan di API. Dan kami instrumen itu. Ada pendekatan: Anda dapat membuat filter, permintaan pergi ke sana - dan itu menyimpan informasi tentang permintaan dalam bentuk swagger.json langsung untuk dirinya sendiri.Berikut adalah seluruh kode yang perlu kami tulis, ada 69-70 baris - ini adalah kode yang sangat sederhana. Yang lucu adalah kami menggunakan klien asli untuk Swagger, menulis di sana. Kami bahkan tidak perlu membuat biner, kami hanya mengisi spesifikasi Swagger.
Yang lucu adalah kami menggunakan klien asli untuk Swagger, menulis di sana. Kami bahkan tidak perlu membuat biner, kami hanya mengisi spesifikasi Swagger. Kami punya banyak file .json yang harus kami lakukan sesuatu - mereka menulis agregator Swagger. Ini adalah program yang sangat sederhana yang bekerja sesuai dengan prinsip berikut:
Kami punya banyak file .json yang harus kami lakukan sesuatu - mereka menulis agregator Swagger. Ini adalah program yang sangat sederhana yang bekerja sesuai dengan prinsip berikut:- Dia memenuhi permintaan baru, jika tidak ada dalam database kami, tambahnya.
- Dia memenuhi permintaan, dia memiliki parameter baru - menambahkan.
- Hal yang sama dengan kode status.
Dengan demikian, kami mendapatkan informasi tentang semua pena, parameter, dan kode status yang kami gunakan. Selain itu, di sini Anda dapat mengumpulkan data yang dengannya permintaan ini dilakukan: nama pengguna, login, dan sebagainya. Kami belum menemukan cara untuk menggunakan informasi ini, karena semuanya dibuat dengan kami, tetapi Anda dapat memahami dengan parameter apa permintaan dipanggil.Jadi, kami hampir sepelemparan batu dari kemenangan, tetapi sebagai hasilnya kami menolak Swagger Diff, karena itu bekerja dalam konsep yang sedikit berbeda - dalam konsep diferensial.
Swagger Diff mengatakan apa yang telah berubah, bukan apa yang dibahas, tetapi kami ingin menampilkan hasil liputan. Ada banyak data tambahan, ia menyimpan informasi tentang deskripsi, ringkasan, dan informasi meta lainnya, tetapi kami tidak memiliki informasi ini. Dan ketika kami membuat Diff, mereka menulis kepada kami bahwa "pena ini tidak memiliki deskripsi", tetapi itu tidak ada.Laporan sendiri
Kami membuat implementasi kami, dan berfungsi sebagai berikut: kami memiliki banyak file yang berasal dari autotest, kami memiliki API layanan Swagger, dan kami menghasilkan laporan berdasarkan itu.Laporan sederhana terlihat seperti ini: di atas Anda dapat melihat informasi tentang berapa banyak pena (349) secara total, informasi yang sepenuhnya tercakup (setiap parameter, kode status, dan sebagainya). Anda dapat memilih kriteria Anda sendiri, misalnya, mencakup beberapa parameter.Ada juga informasi di sini bahwa 40% tertutup sebagian - ini berarti bahwa kami telah melakukan tes untuk pena ini, tetapi beberapa hal belum tercakup, dan Anda perlu melihat dengan cermat di sana. Cakupan kosong juga tercermin.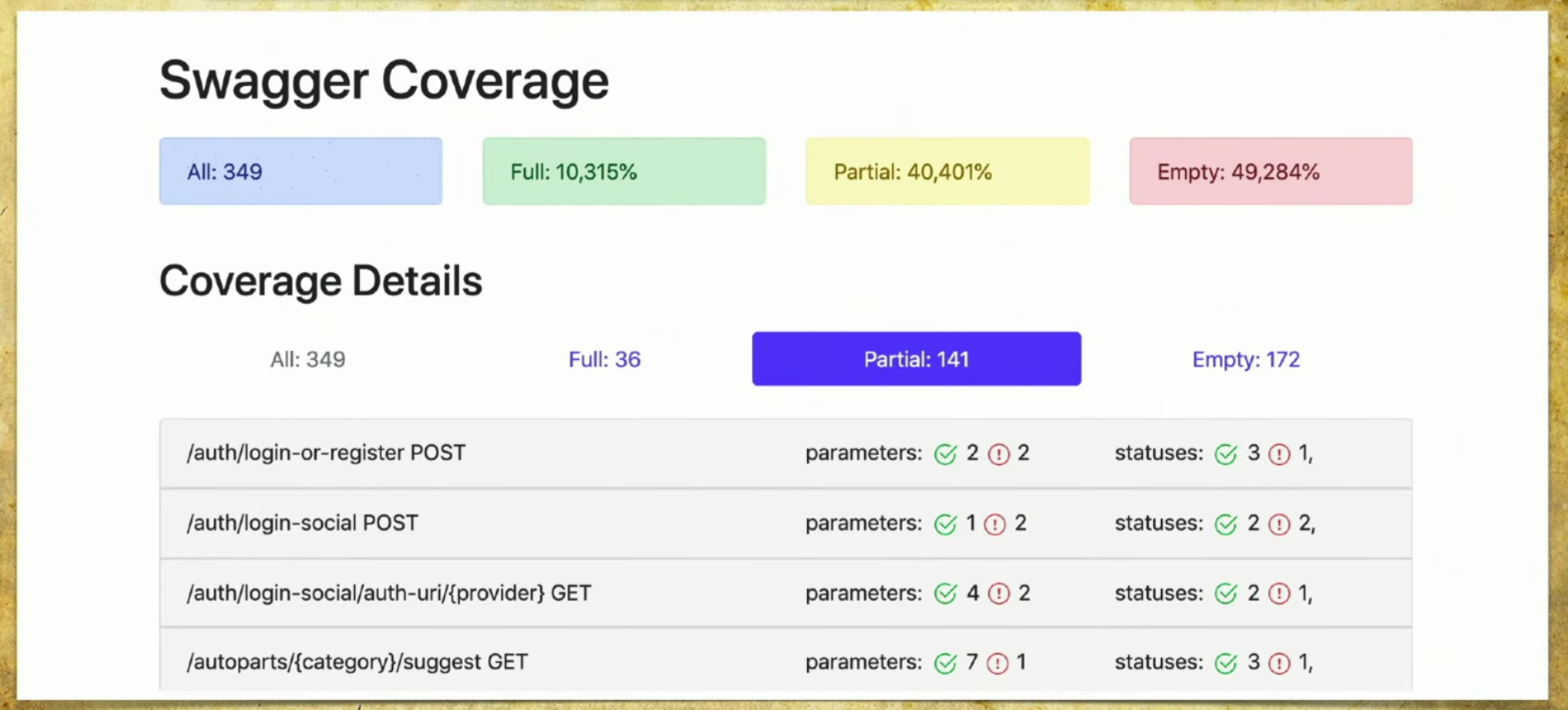 Mari kita buka tab. Ini adalah cakupan penuh , kami melihat semua parameter yang kami miliki, yang tercakup, kode status dan sebagainya.
Mari kita buka tab. Ini adalah cakupan penuh , kami melihat semua parameter yang kami miliki, yang tercakup, kode status dan sebagainya.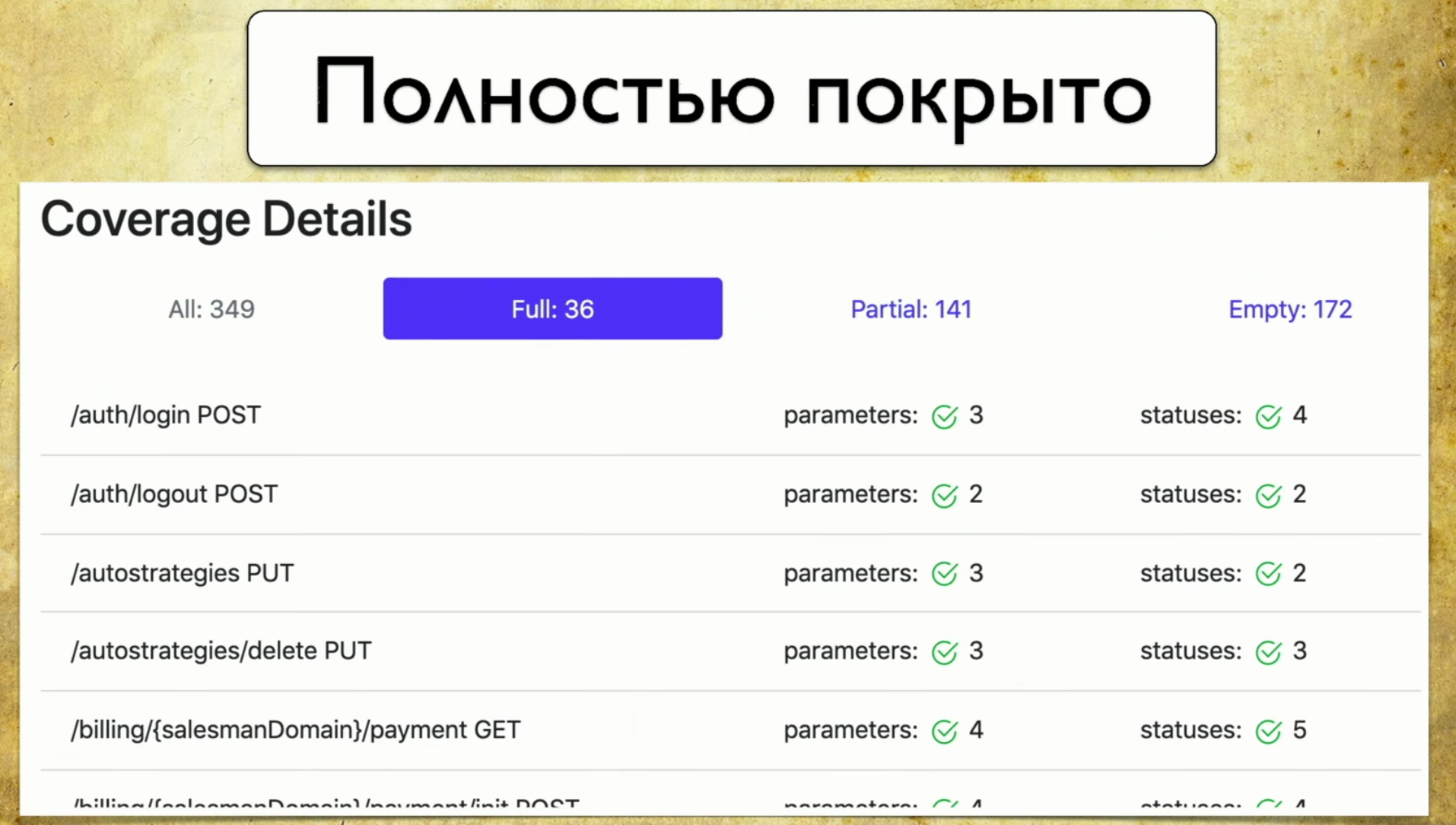 Kemudian kami memiliki cakupan parsial . Kita melihat bahwa pada pegangan login-sosial satu parameter tertutup, dan dua tidak. Dan kita dapat mengembangkannya dan melihat parameter dan kode status apa yang dicakup. Dan pada saat ini menjadi sangat nyaman bagi pengembang: versi aplikasi roll sangat cepat, dan kita sering dapat melupakan beberapa parameter.
Kemudian kami memiliki cakupan parsial . Kita melihat bahwa pada pegangan login-sosial satu parameter tertutup, dan dua tidak. Dan kita dapat mengembangkannya dan melihat parameter dan kode status apa yang dicakup. Dan pada saat ini menjadi sangat nyaman bagi pengembang: versi aplikasi roll sangat cepat, dan kita sering dapat melupakan beberapa parameter. Alat ini memungkinkan Anda untuk selalu dalam kondisi yang baik dan memahami apa yang telah kami bahas sebagian, parameter mana yang dilupakan, dan sebagainya.Terakhir - Kemuliaan rasa malu, kita masih harus melakukannya. Ketika Anda melihat halaman ini dan melihat Kosong di sana: 172 - tangan Anda jatuh, dan kemudian Anda mulai mengajar para penguji tangan bagaimana menulis autotest, itu intinya.
Alat ini memungkinkan Anda untuk selalu dalam kondisi yang baik dan memahami apa yang telah kami bahas sebagian, parameter mana yang dilupakan, dan sebagainya.Terakhir - Kemuliaan rasa malu, kita masih harus melakukannya. Ketika Anda melihat halaman ini dan melihat Kosong di sana: 172 - tangan Anda jatuh, dan kemudian Anda mulai mengajar para penguji tangan bagaimana menulis autotest, itu intinya.
Apa manfaat yang kita dapatkan ketika kita meluncurkan solusi kita?
Pertama, kami mulai menulis tes lebih bermakna. Kami memahami bahwa kami sedang menguji, dan pada saat yang sama kami memiliki dua strategi. Pertama, kami mengotomatiskan sesuatu yang tidak ada ketika penguji manual datang dan mengatakan bahwa untuk layanan tertentu sangat penting bahwa satu permintaan dieksekusi setidaknya sekali, dan kami membuka Kosong.Opsi kedua - kita tidak melupakan ekornya. Seperti yang saya katakan, API akan dirilis dengan sangat cepat, mungkin ada beberapa rilis dua atau tiga kali sehari. Beberapa parameter terus ditambahkan di sana: dalam lima ribu tes, tidak mungkin untuk memahami apa yang diperiksa dan apa yang tidak. Oleh karena itu, ini adalah satu-satunya cara untuk secara sadar memilih strategi pengujian dan setidaknya melakukan sesuatu.Keuntungan ketiga adalah proses yang sepenuhnya otomatis. Kami telah meminjam pendekatan, dan otomasi berfungsi: kita tidak perlu melakukan apa pun, semuanya dikumpulkan secara otomatis.Gagasan pengembangan
Pertama, saya benar-benar tidak ingin menyimpan laporan kedua, tetapi saya ingin mengintegrasikannya ke UI Swagger. Ini adalah "laporan Edisi Photoshop" favorit saya: sebuah chip yang saya kembangkan belakangan ini. Di sini segera ada informasi tentang parameter yang telah kami uji dan yang tidak. Dan akan sangat keren untuk memberikan informasi ini segera dengan Swagger. Misalnya, front-end dapat melihat sendiri parameter apa yang belum diuji, memprioritaskan dan memutuskan bahwa sementara mereka tidak perlu diambil ke dalam pengembangan, tidak diketahui seberapa baik mereka bekerja. Atau backend menulis pena baru, melihat penguji merah dan tendangan sehingga semuanya hijau. Ini cukup mudah dilakukan, kita menuju ke arah ini.Gagasan kedua adalah mendukung alat lain. Bahkan, saya tidak ingin menulis filter untuk implementasi spesifik: untuk Java, Python, dan sebagainya. Ada ide untuk membuat semacam proxy yang akan melewati semua permintaan sendiri, dan menyimpan informasi Swagger untuk dirinya sendiri. Dengan demikian, kami akan memiliki perpustakaan universal yang dapat digunakan apa pun bahasa yang Anda miliki.Gagasan pengembangan ketiga adalah integrasi dengan Allure Report. Saya melihatnya seperti ini:
Misalnya, front-end dapat melihat sendiri parameter apa yang belum diuji, memprioritaskan dan memutuskan bahwa sementara mereka tidak perlu diambil ke dalam pengembangan, tidak diketahui seberapa baik mereka bekerja. Atau backend menulis pena baru, melihat penguji merah dan tendangan sehingga semuanya hijau. Ini cukup mudah dilakukan, kita menuju ke arah ini.Gagasan kedua adalah mendukung alat lain. Bahkan, saya tidak ingin menulis filter untuk implementasi spesifik: untuk Java, Python, dan sebagainya. Ada ide untuk membuat semacam proxy yang akan melewati semua permintaan sendiri, dan menyimpan informasi Swagger untuk dirinya sendiri. Dengan demikian, kami akan memiliki perpustakaan universal yang dapat digunakan apa pun bahasa yang Anda miliki.Gagasan pengembangan ketiga adalah integrasi dengan Allure Report. Saya melihatnya seperti ini: Sebagai aturan, ketika parameter "diuji", ini tidak selalu memberi tahu kami bagaimana itu diuji. Dan saya ingin menunjukkan parameter ini dan melihat langkah-langkah spesifik dari tes ini.
Sebagai aturan, ketika parameter "diuji", ini tidak selalu memberi tahu kami bagaimana itu diuji. Dan saya ingin menunjukkan parameter ini dan melihat langkah-langkah spesifik dari tes ini.Cakupan Pengujian Web
Poin berikutnya yang ingin saya bicarakan adalah cakupan untuk tes Web. Cakupan didasarkan pada situs yang Anda uji, menulis tes di situs. Tapi Anda bisa menjadikannya antarmuka web untuk jangkauan Anda. Misalnya, akan terlihat seperti ini: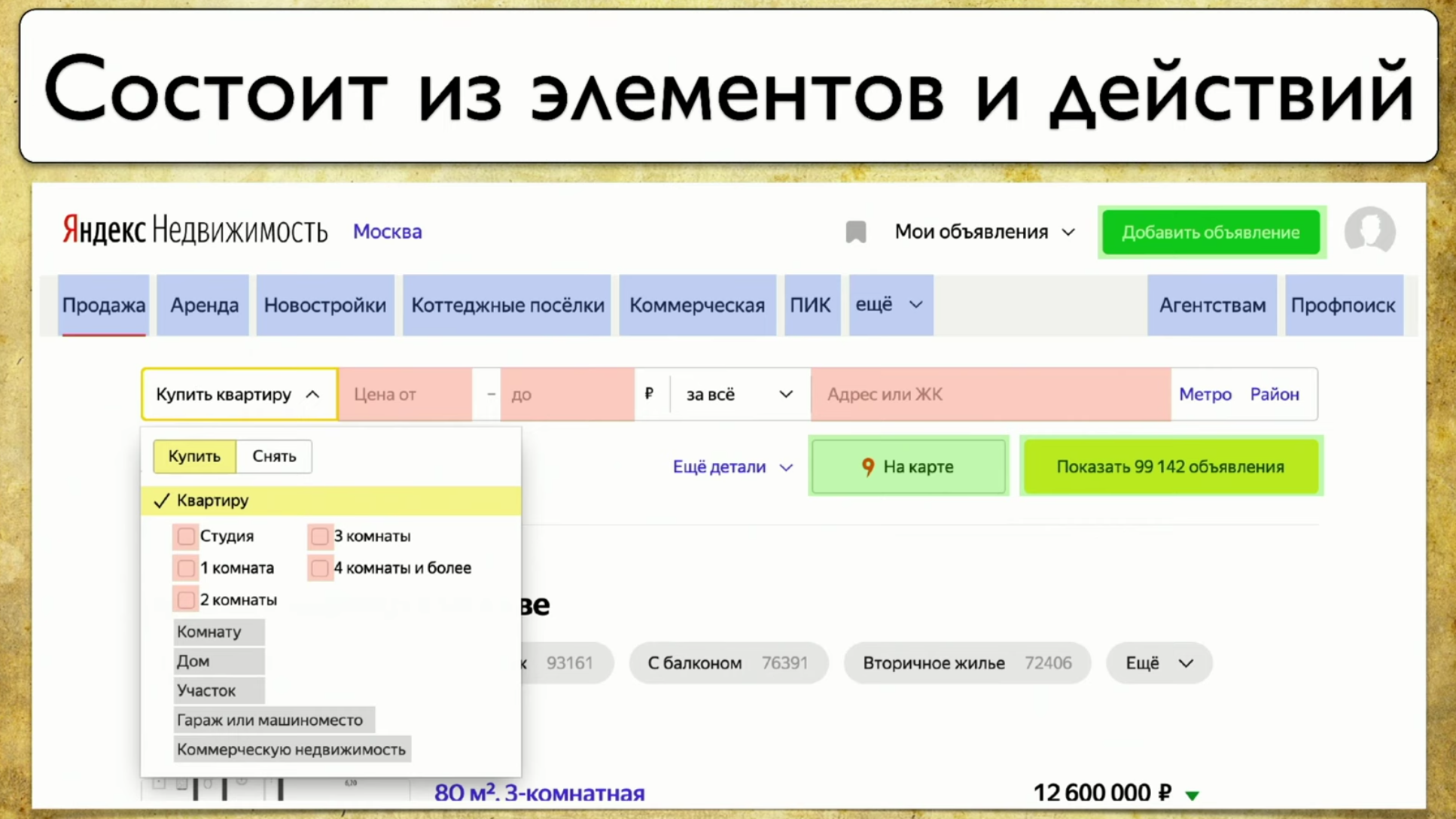 Jika Anda melihat situs Anda - ini adalah sejumlah elemen dan cara untuk berinteraksi dengannya. Ini adalah deskripsi lengkap: "elemen adalah cara untuk berinteraksi dengannya." Anda dapat mengklik tautan, Anda dapat menyalin teks, Anda dapat mengarahkan sesuatu ke input. Situs secara keseluruhan terdiri dari elemen dan cara interaksi mereka:
Jika Anda melihat situs Anda - ini adalah sejumlah elemen dan cara untuk berinteraksi dengannya. Ini adalah deskripsi lengkap: "elemen adalah cara untuk berinteraksi dengannya." Anda dapat mengklik tautan, Anda dapat menyalin teks, Anda dapat mengarahkan sesuatu ke input. Situs secara keseluruhan terdiri dari elemen dan cara interaksi mereka: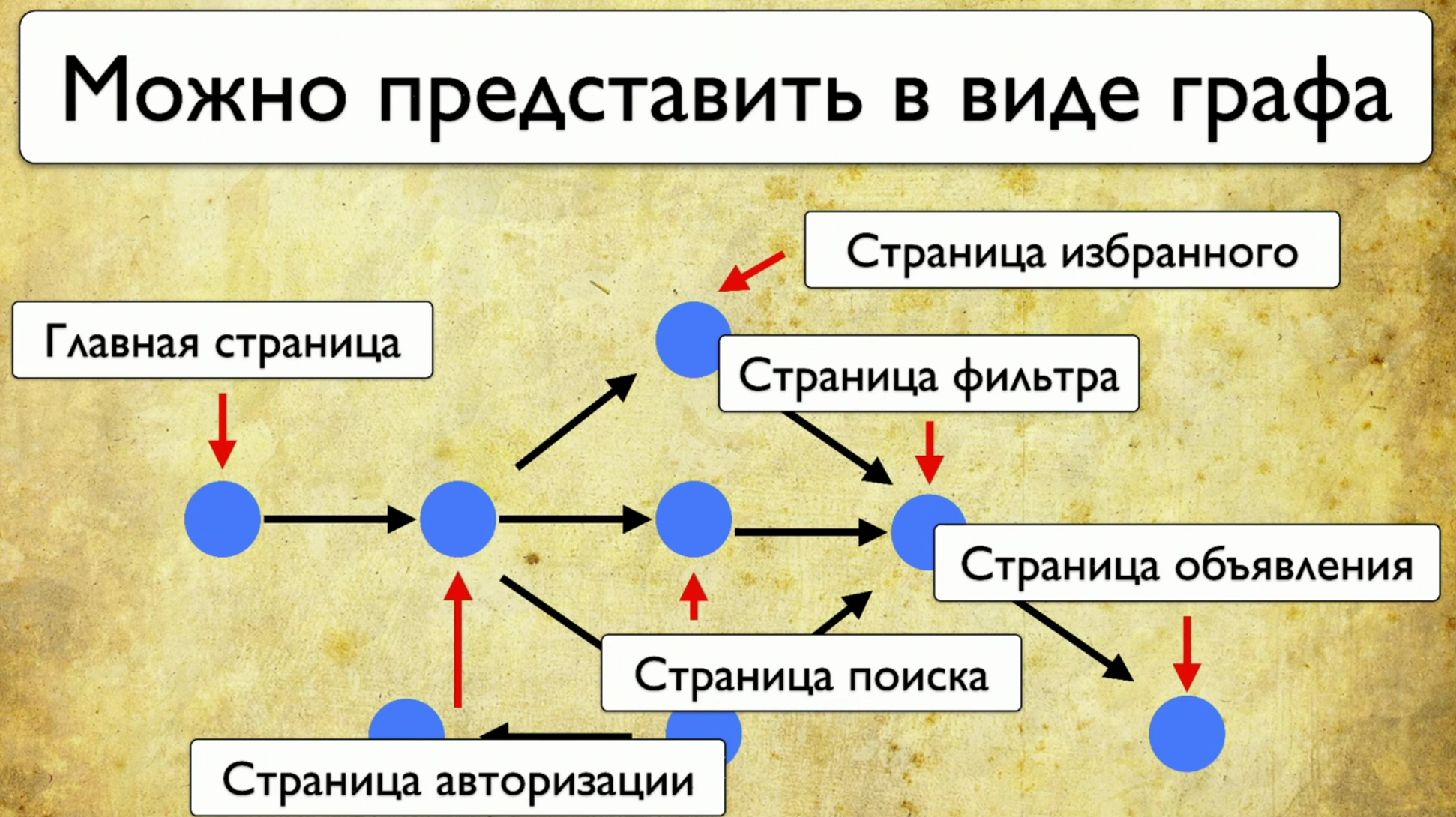 Bagaimana tes berjalan: mereka mulai dari beberapa titik, lalu, misalnya, mengisi beberapa formulir, katakanlah, formulir otorisasi, lalu sebar ke halaman lain, lalu yang lain ke yang lain dan berakhir .Jika manajer bertanya apakah tombol tertentu sedang diuji, tetapi pertanyaan ini sulit dijawab: Anda perlu membuka kode atau pergi ke TestRail, maka saya ingin melihat solusi untuk masalah ini:
Bagaimana tes berjalan: mereka mulai dari beberapa titik, lalu, misalnya, mengisi beberapa formulir, katakanlah, formulir otorisasi, lalu sebar ke halaman lain, lalu yang lain ke yang lain dan berakhir .Jika manajer bertanya apakah tombol tertentu sedang diuji, tetapi pertanyaan ini sulit dijawab: Anda perlu membuka kode atau pergi ke TestRail, maka saya ingin melihat solusi untuk masalah ini: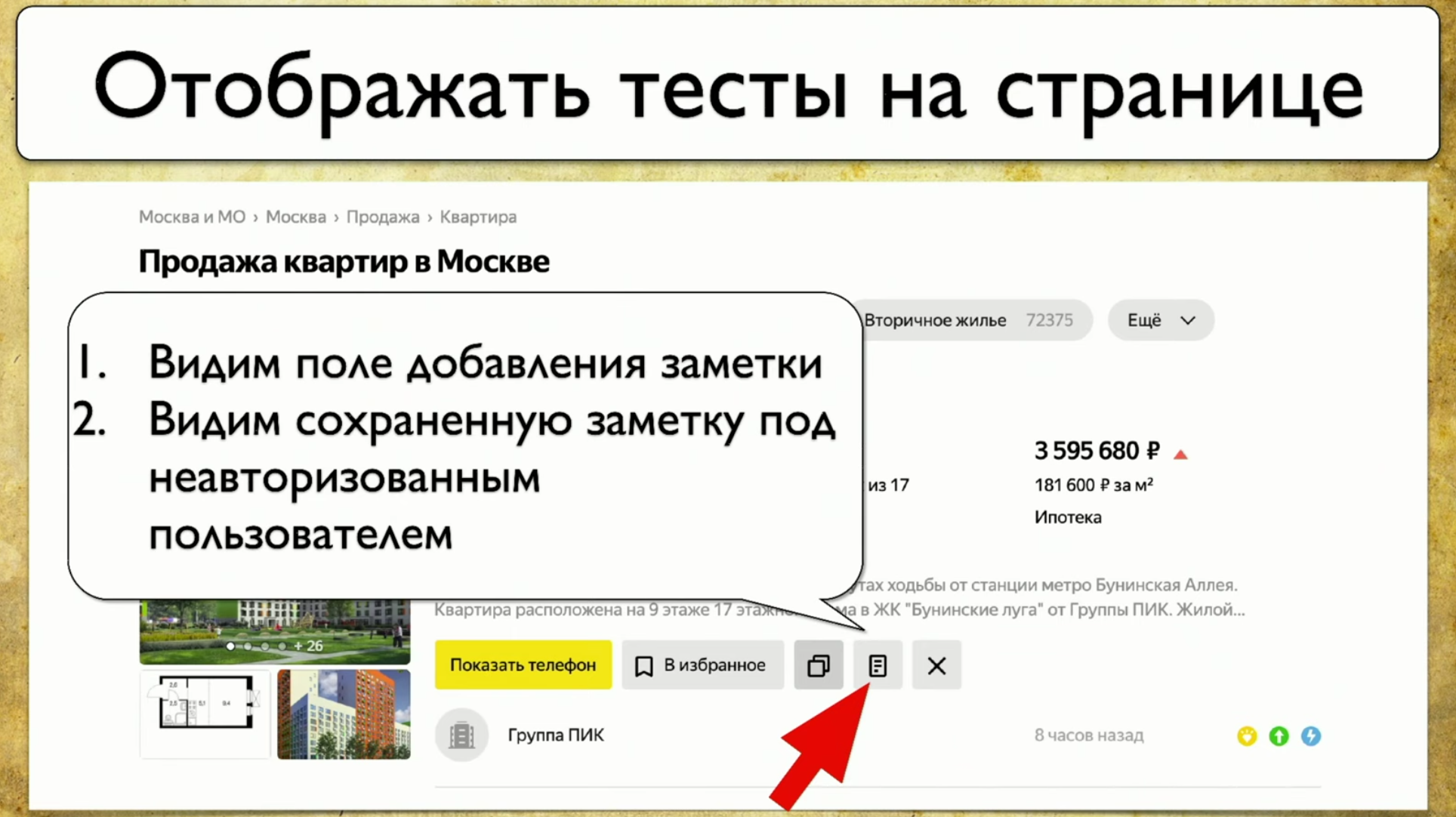 Saya ingin menunjukkan elemen ini dan melihat semua tes yang kami miliki pada item ini. Jika ada instrumen seperti itu, saya akan senang. Ketika kami mulai memikirkan ide ini, pertama-tama kami melihat Yandex.Metrica. Mereka sebenarnya memiliki fungsi yang kira-kira sama dengan tautan peta. Sebuah ide bagus.Intinya adalah bahwa mereka disorot tepat seolah-olah mereka sudah memberikan informasi yang kami butuhkan. Mereka mengatakan: "Di sini kami telah melewati tautan ini 14 kali", yang dalam terjemahan ke dalam bahasa pengujian berarti: "14 tes diuji dalam tautan ini" dan entah bagaimana melewatinya. Tapi tautan merah ini mengambil sebanyak 120 tes, tes yang menarik!Anda dapat menggambar segala macam tren, menambahkan meta-informasi, tetapi apa yang terjadi jika kita mengambil semuanya dan menarik dari sudut pandang pengujian? Jadi, kami memiliki tugas: menunjuk beberapa elemen dan mendapatkan catatan dengan daftar tes.
Saya ingin menunjukkan elemen ini dan melihat semua tes yang kami miliki pada item ini. Jika ada instrumen seperti itu, saya akan senang. Ketika kami mulai memikirkan ide ini, pertama-tama kami melihat Yandex.Metrica. Mereka sebenarnya memiliki fungsi yang kira-kira sama dengan tautan peta. Sebuah ide bagus.Intinya adalah bahwa mereka disorot tepat seolah-olah mereka sudah memberikan informasi yang kami butuhkan. Mereka mengatakan: "Di sini kami telah melewati tautan ini 14 kali", yang dalam terjemahan ke dalam bahasa pengujian berarti: "14 tes diuji dalam tautan ini" dan entah bagaimana melewatinya. Tapi tautan merah ini mengambil sebanyak 120 tes, tes yang menarik!Anda dapat menggambar segala macam tren, menambahkan meta-informasi, tetapi apa yang terjadi jika kita mengambil semuanya dan menarik dari sudut pandang pengujian? Jadi, kami memiliki tugas: menunjuk beberapa elemen dan mendapatkan catatan dengan daftar tes. Untuk menerapkan ini, Anda perlu mengklik ikon, lalu menulis catatan, dan ini adalah keseluruhan pengujian kami. Kami menggunakan Atlas di tempat kami, dan integrasi sejauh ini hanya dengan itu.Atlas terlihat seperti ini:
Untuk menerapkan ini, Anda perlu mengklik ikon, lalu menulis catatan, dan ini adalah keseluruhan pengujian kami. Kami menggunakan Atlas di tempat kami, dan integrasi sejauh ini hanya dengan itu.Atlas terlihat seperti ini:SearchPage.open ();
SearchPage.offersList().should(hasSizeGreaterThan(0));
Kami ingin setidaknya satu hasil ditampilkan, jika tidak kami tidak akan mengujinya. Lalu kami memindahkan kursor ke elemen, lalu klik di atasnya.searchPage.offer(FIRST).moveCursor();
searchPage.offer(FIRST).actionBar().note().click();
Kemudian kita simpan di input User_Text dan kirimkan.searchPage.offer(FIRST).addNoteInput().sendKeys(USER_TEXT);
searchPage.offer(FIRST).saveNote().click();
Setelah itu, kami memeriksa bahwa teksnya persis seperti yang seharusnya. searchPage.offer(FIRST).addNoteInput().should(hasValue(USER_TEXT));
Tes dijalankan di browser, Atlas adalah proxy untuk tes ini, kami menerapkan pendekatan yang sama di sini yang digunakan semua orang saat mengumpulkan cakupan: kami akan membuat locator dengan .json. Kami akan menyimpan informasi di sana tentang semua pembukaan halaman, semua iterasi dengan elemen, siapa yang mengirim, siapa yang mengirim kunci, siapa yang mengklik, ID mana dan seterusnya - kami akan menyimpan log lengkap.Kemudian kami lampirkan log ini ke Allure dalam bentuk setiap tes, dan ketika kami memiliki banyak locators.json , kami menghasilkan meta.json . Skema ini sama untuk semua elemen.Kami memiliki plugin untuk Google Chrome. Kami ingin membuat keputusan dalam bentuk plugin. Saya secara khusus membuat tangkapan layar kurva sehingga satu detail penting terlihat pada slide - path ke locators.json . Jika Anda membuat laporan sekarang, maka ada peta cakupan untuk hari ini. Jika Anda mengambil laporan untuk dua minggu sebelumnya dan menempelkannya di sini, peta cakupan untuk periode dua minggu yang lalu akan muncul. Anda punya mesin waktu!Namun, ketika Anda mencolokkan plugin ini, itu menarik antarmuka yang tidak terlalu ramah.
Jika Anda membuat laporan sekarang, maka ada peta cakupan untuk hari ini. Jika Anda mengambil laporan untuk dua minggu sebelumnya dan menempelkannya di sini, peta cakupan untuk periode dua minggu yang lalu akan muncul. Anda punya mesin waktu!Namun, ketika Anda mencolokkan plugin ini, itu menarik antarmuka yang tidak terlalu ramah. Setiap elemen memiliki sejumlah tes yang melewatinya: jelas bahwa 40 tes melewati "beli apartemen", tajuk diuji satu tes pada satu waktu, itu keren, dan opsi "apartemen" juga ditampilkan. Anda mendapatkan peta cakupan lengkap.Jika Anda mengarahkan kursor ke beberapa elemen, ia akan mengambil data dan mencetak tes Anda yang sebenarnya dari tms Anda, Allure Board dan sebagainya. Hasilnya adalah informasi lengkap tentang apa yang sedang diuji dan bagaimana.Harap dicatat bahwa dari setiap tes Anda dapat gagal secara langsung dalam laporan Allure.
Setiap elemen memiliki sejumlah tes yang melewatinya: jelas bahwa 40 tes melewati "beli apartemen", tajuk diuji satu tes pada satu waktu, itu keren, dan opsi "apartemen" juga ditampilkan. Anda mendapatkan peta cakupan lengkap.Jika Anda mengarahkan kursor ke beberapa elemen, ia akan mengambil data dan mencetak tes Anda yang sebenarnya dari tms Anda, Allure Board dan sebagainya. Hasilnya adalah informasi lengkap tentang apa yang sedang diuji dan bagaimana.Harap dicatat bahwa dari setiap tes Anda dapat gagal secara langsung dalam laporan Allure. Ketika Anda membuka sesuatu, itu memuat penyeleksi baru: jika Anda memiliki tes yang melalui penyeleksi ini dan Anda melakukan sesuatu dengan situs, itu akan memproses dan menampilkan seluruh gambar.
Ketika Anda membuka sesuatu, itu memuat penyeleksi baru: jika Anda memiliki tes yang melalui penyeleksi ini dan Anda melakukan sesuatu dengan situs, itu akan memproses dan menampilkan seluruh gambar.Apa untungnya?
Segera setelah kami menerapkan pendekatan sederhana ini, maka, terutama, kami mulai memahami apa yang kami uji dalam tes.
Sekarang siapa pun dapat masuk dan menemukan "utas" apa pun yang mengarah ke skrip. Misalnya, Anda menganggap bahwa Anda perlu menguji pembayaran. Pembayaran, jelas, mengarah melalui tombol pembayaran: klik - semua tes yang muncul melalui tombol pembayaran muncul. Ini bagus! Anda masuk ke salah satu dari mereka dan melihat skrip.Apalagi Anda mengerti apa yang sudah diuji sebelumnya. Kami menghasilkan file statis, Anda dapat menentukan lintasan ke sana dan menunjukkan tes mana yang dua minggu lalu. Jika manajer mengatakan ada bug dalam produksi dan menanyakan apakah kami menguji fungsionalitas ini atau itu beberapa minggu yang lalu, Anda mengambil laporan Allure, katakanlah, misalnya, bahwa Anda tidak mengujinya.Keuntungan lain adalah ulasan setelah pengujian otomatisasi. Sebelum itu, kami memiliki ulasan sebelum menguji otomatisasi, sekarang Anda dapat melakukan tes Anda persis seperti yang Anda lihat. Jika Anda ingin melakukan tes - selesai, ambil beberapa cabang, luncurkan Allure, jatuhkan tautan ke plug-in ke penguji manual dan minta untuk melihat tes. Ini persis proses yang akan memungkinkan Anda untuk memperkuat strategi Agile: pemimpin tim membuat tinjauan kode, dan penguji manual melakukan tes Anda (skrip).Keuntungan lain dari pendekatan ini adalah elemen yang sering digunakan. Jika kita menimpa blok ini, di mana ada 87 tes, maka semuanya akan jatuh. Anda mulai mengerti bagaimana kekurang tes Anda. Dan jika blok "harga dari" dibatalkan, maka tidak apa-apa, satu tes akan jatuh, seseorang akan memperbaikinya. Jika Anda mengubah blok dengan 87 tes, maka cakupan akan melorot jauh, karena 87 tes tidak akan lulus dan tidak akan memeriksa hasil apa pun. Blok ini membutuhkan peningkatan perhatian. Maka Anda perlu memberi tahu pengembang bahwa blok ini harus dengan ID, karena jika itu pergi, semuanya akan berantakan.
Dan jika blok "harga dari" dibatalkan, maka tidak apa-apa, satu tes akan jatuh, seseorang akan memperbaikinya. Jika Anda mengubah blok dengan 87 tes, maka cakupan akan melorot jauh, karena 87 tes tidak akan lulus dan tidak akan memeriksa hasil apa pun. Blok ini membutuhkan peningkatan perhatian. Maka Anda perlu memberi tahu pengembang bahwa blok ini harus dengan ID, karena jika itu pergi, semuanya akan berantakan.Bagaimana Anda bisa berkembang lebih jauh?
Misalnya, Anda dapat mengikuti jalur pengembangan dukungan untuk alat lain, misalnya, untuk Selenide. Saya bahkan ingin mendukung bukan Selenide tertentu, tetapi implementasi driver yang akan memungkinkan Anda mengumpulkan pelacak, terlepas dari alat yang Anda gunakan. Proxy ini akan membuang informasi dan kemudian menampilkannya.Gagasan lain adalah untuk menampilkan hasil tes saat ini. Misalnya, mudah untuk segera membuang gambar seperti itu ke penguji manual: Anda tidak perlu memikirkan tes mana yang rusak, karena Anda dapat pergi ke situs tersebut, mengklik tes tersebut dan meneruskannya dengan tangan tanpa memeriksa tes lain. Ini mudah, Anda dapat mengambil informasi ini dari Allure dan menariknya di sini.Anda juga dapat menambahkan Skor Total, karena semua orang menyukai grafik, karena saya ingin berurusan dengan tes duplikat yang sangat mirip satu sama lain, yang bagian tengahnya sama, dan bagian awal dan ekornya telah sedikit berubah.
Anda tidak perlu memikirkan tes mana yang rusak, karena Anda dapat pergi ke situs tersebut, mengklik tes tersebut dan meneruskannya dengan tangan tanpa memeriksa tes lain. Ini mudah, Anda dapat mengambil informasi ini dari Allure dan menariknya di sini.Anda juga dapat menambahkan Skor Total, karena semua orang menyukai grafik, karena saya ingin berurusan dengan tes duplikat yang sangat mirip satu sama lain, yang bagian tengahnya sama, dan bagian awal dan ekornya telah sedikit berubah. Saya juga ingin segera melihat jumlah penyeleksi duplikat. Jika tinggi, maka pada halaman ini Anda perlu melakukan refactoring dan menjalankan tes, jika tidak mereka akan jatuh dalam bundel yang terlalu besar. Hal yang sama berlaku untuk jumlah elemen yang berinteraksi dengan kami. Ini adalah beberapa gejala umum. Namun, segera setelah Anda berinteraksi dengan halaman, angka tersebut akan dilewati karena elemen baru dan jumlah total kasus uji, jadi Anda perlu menambahkan beberapa jenis analitik, itu tidak akan berlebihan.Anda juga dapat menambahkan distribusi tes secara berlapis-lapis, karena Anda ingin melihat tidak hanya bahwa kami memiliki tes-tes ini, tetapi semua jenis tes yang ada di halaman ini, bahkan mungkin tes manual.Jadi, jika ada tes Java dan tes pada Puppeteer yang ditulis oleh tim lain, kita dapat melihat halaman tertentu dan langsung mengatakan di mana tes kami berpotongan. Artinya, kita akan berbicara bahasa yang sama dengan mereka, dan kita tidak perlu mengumpulkan informasi ini sedikit demi sedikit. Jika kita memiliki alat yang menunjukkan segalanya di antarmuka web, maka tugas membandingkan tes di Java dan Puppeteer tampaknya tidak lagi dapat dipecahkan.Akhirnya, mari kita bicara tentang strategi umum. Kita sudah bicara tentang jenis cakupan apa, yang dinamai dua, muncul dengan jenis pelapisan ketiga, yang hasilnya kita gunakan. Jadi kami hanya mengambil dan melihat masalah ini dari sudut yang berbeda.
Saya juga ingin segera melihat jumlah penyeleksi duplikat. Jika tinggi, maka pada halaman ini Anda perlu melakukan refactoring dan menjalankan tes, jika tidak mereka akan jatuh dalam bundel yang terlalu besar. Hal yang sama berlaku untuk jumlah elemen yang berinteraksi dengan kami. Ini adalah beberapa gejala umum. Namun, segera setelah Anda berinteraksi dengan halaman, angka tersebut akan dilewati karena elemen baru dan jumlah total kasus uji, jadi Anda perlu menambahkan beberapa jenis analitik, itu tidak akan berlebihan.Anda juga dapat menambahkan distribusi tes secara berlapis-lapis, karena Anda ingin melihat tidak hanya bahwa kami memiliki tes-tes ini, tetapi semua jenis tes yang ada di halaman ini, bahkan mungkin tes manual.Jadi, jika ada tes Java dan tes pada Puppeteer yang ditulis oleh tim lain, kita dapat melihat halaman tertentu dan langsung mengatakan di mana tes kami berpotongan. Artinya, kita akan berbicara bahasa yang sama dengan mereka, dan kita tidak perlu mengumpulkan informasi ini sedikit demi sedikit. Jika kita memiliki alat yang menunjukkan segalanya di antarmuka web, maka tugas membandingkan tes di Java dan Puppeteer tampaknya tidak lagi dapat dipecahkan.Akhirnya, mari kita bicara tentang strategi umum. Kita sudah bicara tentang jenis cakupan apa, yang dinamai dua, muncul dengan jenis pelapisan ketiga, yang hasilnya kita gunakan. Jadi kami hanya mengambil dan melihat masalah ini dari sudut yang berbeda.Di satu sisi, ada liputan yang telah ditendang sejak 1963, di sisi lain, ada penguji manual yang terbiasa hidup di dunia yang lebih nyata daripada kode. Tetap hanya menggabungkan dua pendekatan ini.
Mereka yang tertarik selalu dapat bergabung dengan komunitas kami. Berikut adalah dua repositori dari orang-orang kami yang menangani masalah cakupan: