Halo, hari ini saya ingin berbicara tentang pengalaman saya dalam menganalisis saham Sberbank. Terkadang mereka menunjukkan dinamika yang sedikit berbeda - menarik bagi saya untuk menganalisis pergerakan kutipan mereka.Dalam contoh ini, kami akan mengunduh kutipan dari situs web Finam. Tautan untuk mengunduh Sberbank biasa .Untuk operasi kolom saya akan menggunakan panda, untuk visualisasi matplotlib.Kami mengimpor:import pandas as pd
import matplotlib.pyplot as plt
Agar tabel tidak menyusut, Anda harus menghapus batasan:pd.set_option('display.max_columns', None)
pd.set_option('display.expand_frame_repr', False)
pd.set_option('max_colwidth', 80)
pd.set_option('max_rows', 6000)
Baca data stok
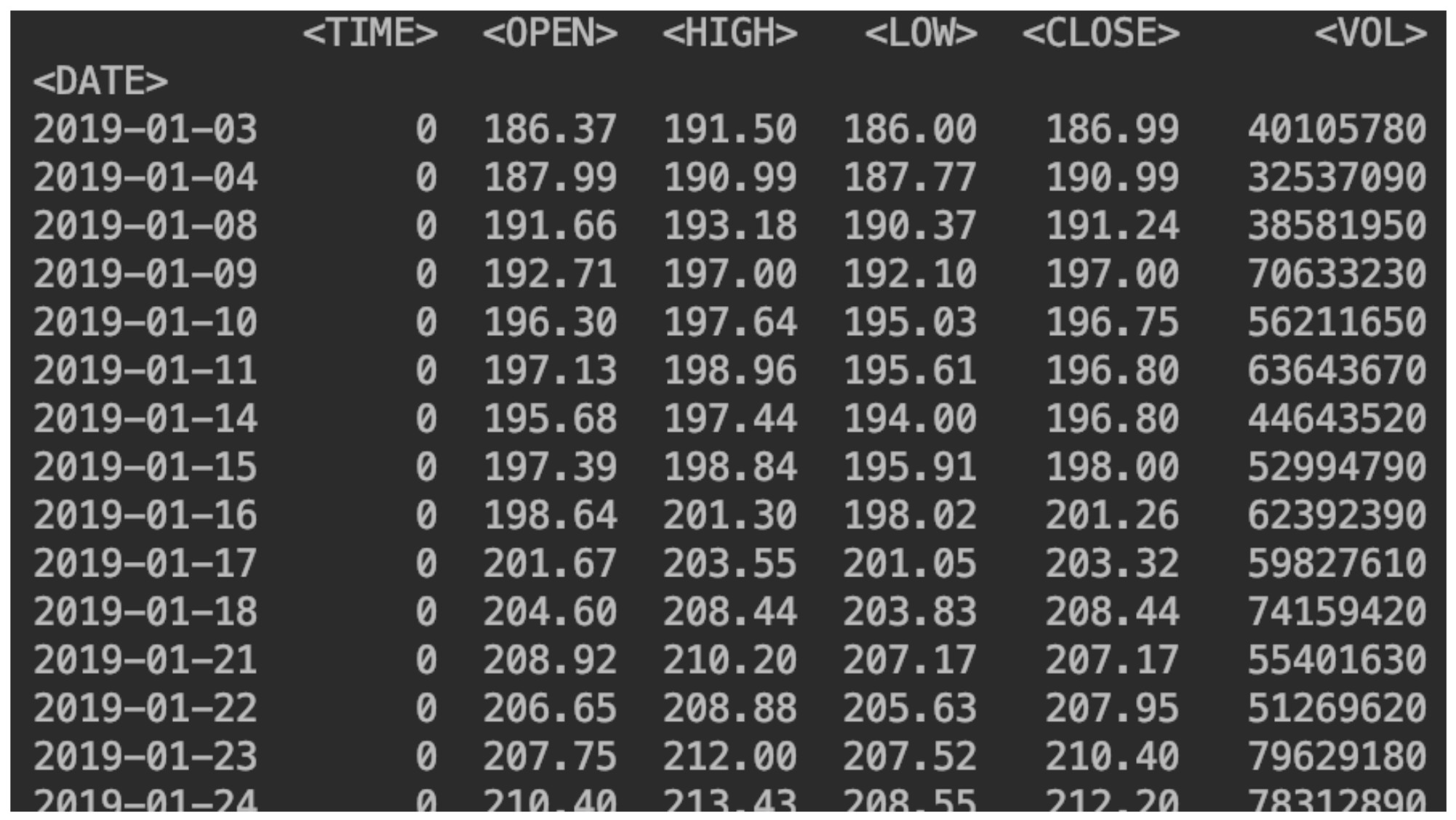
df = pd.read_csv("SBER_190101_200105.csv",sep=';', header=0, index_col='<DATE>', parse_dates=True)
(tentukan pemisah, di mana nama kolom berada, kolom mana yang akan menjadi indeks, aktifkan penguraian tanggal).Juga menunjukkan jenisnya:df = df.sort_values(by='<DATE>')
Kami menampilkan data kami:print(df)
 Tambahkan kolom dengan perubahan harga
Tambahkan kolom dengan perubahan hargadf['returns']=(df['<CLOSE>']/df['<CLOSE>'].shift(1))-1
Jadi dimungkinkan untuk mendapatkan persentase persisnya:df['returns_pers']=((df['<CLOSE>']/df['<CLOSE>'].shift(1))-1)*100

Tambahkan bagian kedua
Lakukan dengan cara yang persis sama.df2 = pd.read_csv("SBERP_190101_200105.csv",sep=';', header=0, index_col='<DATE>', parse_dates=True)
df = df.sort_values(by='<DATE>')
df2['returns_pers']=((df2['<CLOSE>']/df2['<CLOSE>'].shift(1))-1)*100
df2['returns']=(df2['<CLOSE>']/df2['<CLOSE>'].shift(1))-1
print(df2)
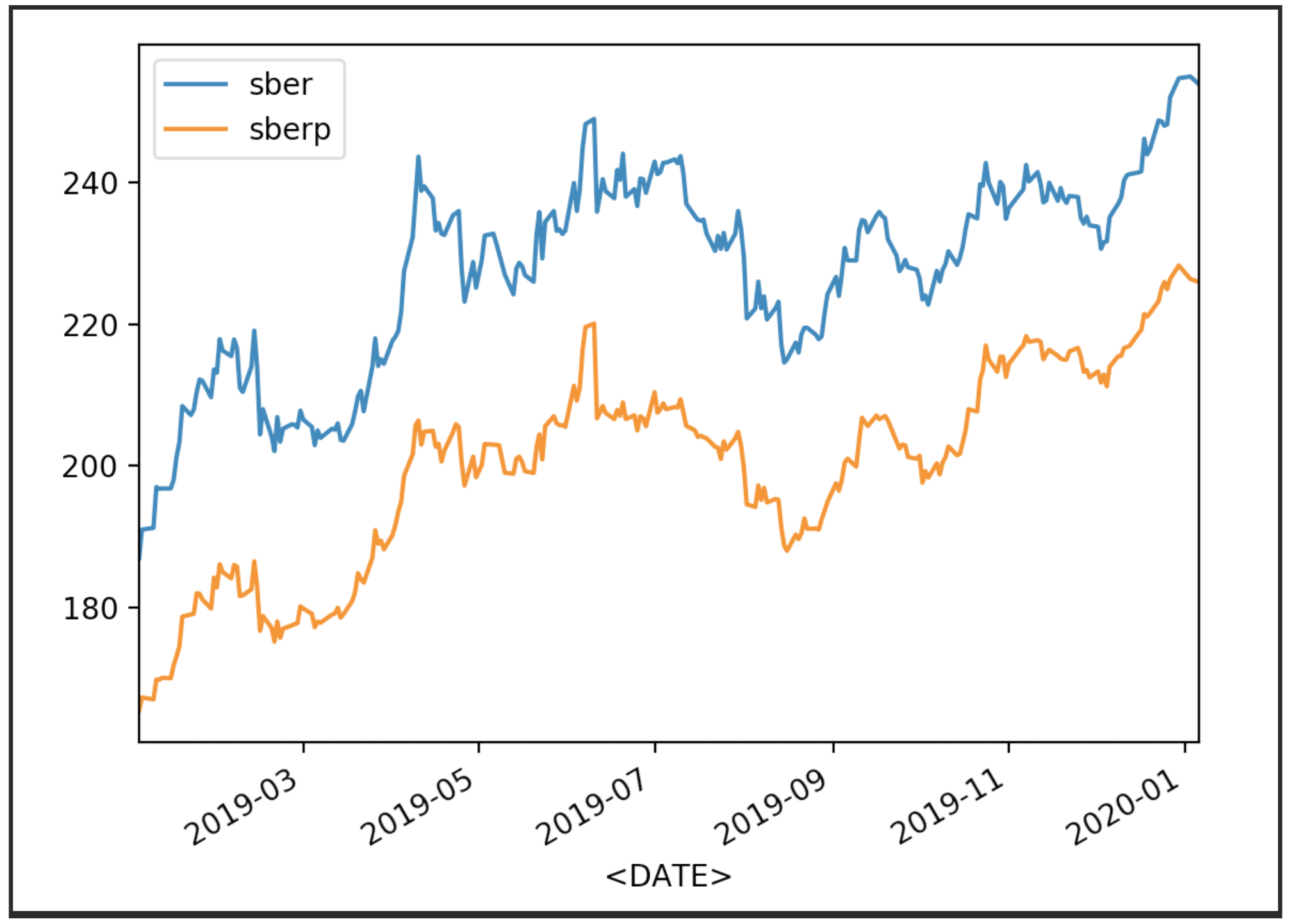
Kami memvisualisasikan harga saham kami
df['<CLOSE>'].plot(label='sber')
df2['<CLOSE>'].plot(label='sberp')
plt.legend()
plt.show()
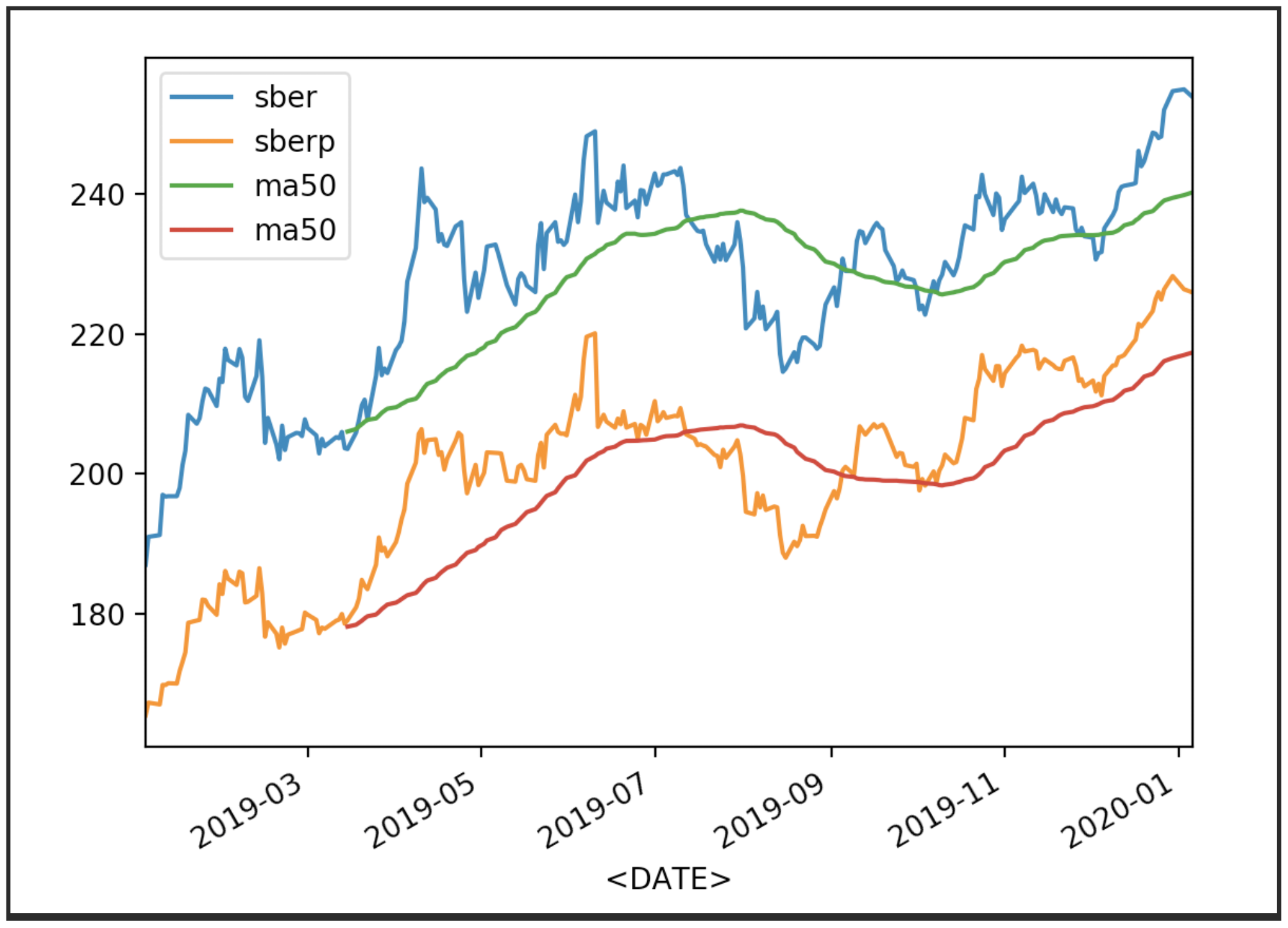
 Sekarang tampilkan kutipan dengan rata-rata (MA 50):
Sekarang tampilkan kutipan dengan rata-rata (MA 50):df['<CLOSE>'].plot(label='sber')
df2['<CLOSE>'].plot(label='sberp')
df['ma50'] = df['<OPEN>'].rolling(50).mean().plot(label='ma50')
df2['ma50'] = df2['<OPEN>'].rolling(50).mean().plot(label='ma50')
plt.legend()
plt.show()
 Rata-rata lainnya juga dapat ditampilkan.
Rata-rata lainnya juga dapat ditampilkan.df['<CLOSE>'].plot(label='sber')
df2['<CLOSE>'].plot(label='sberp')
df['ma100'] = df['<OPEN>'].rolling(100).mean().plot(label='ma100')
df2['ma100'] = df2['<OPEN>'].rolling(100).mean().plot(label='ma100')
plt.legend()
plt.show()
 Sekarang kita akan menampilkan omset untuk saham:Tambahkan juga nama sumbu Ydan ukuran kanvas
Sekarang kita akan menampilkan omset untuk saham:Tambahkan juga nama sumbu Ydan ukuran kanvasdf['total_trade'] = df['<OPEN>']*df['<VOL>']
df2['total_trade'] = df2['<OPEN>']*df2['<VOL>']
df['total_trade'].plot(label='sber',figsize=(16,8))
df2['total_trade'].plot(label='sberp',figsize=(16,8))
plt.legend()
plt.ylabel('Total Traded')
plt.show()

Analisis korelasi
Sekarang mari kita melihat lebih dekat pada korelasinya. diagram matriksakan membantu kita dalam hal ini. Buat tabel baru dengan kolom untuk kedua saham dan beri mereka nama.all_sber = pd.concat([df['<OPEN>'],df2['<OPEN>']],axis=1)
all_sber.columns = ['sber_open','sberp_open']
print(all_sber)
 Sekarang kami mengimpor jadwal yang diperlukan
Sekarang kami mengimpor jadwal yang diperlukanfrom pandas.plotting import scatter_matrix
Dan output itu:scatter_matrix(all_sber,figsize=(8,8),alpha=0.2,hist_kwds={'bins':100});
plt.show()
Harus diklarifikasi bahwa kita perlu menambahkan transparansi (alpha = 0,2) untuk melihat tumpang tindih poin.Jika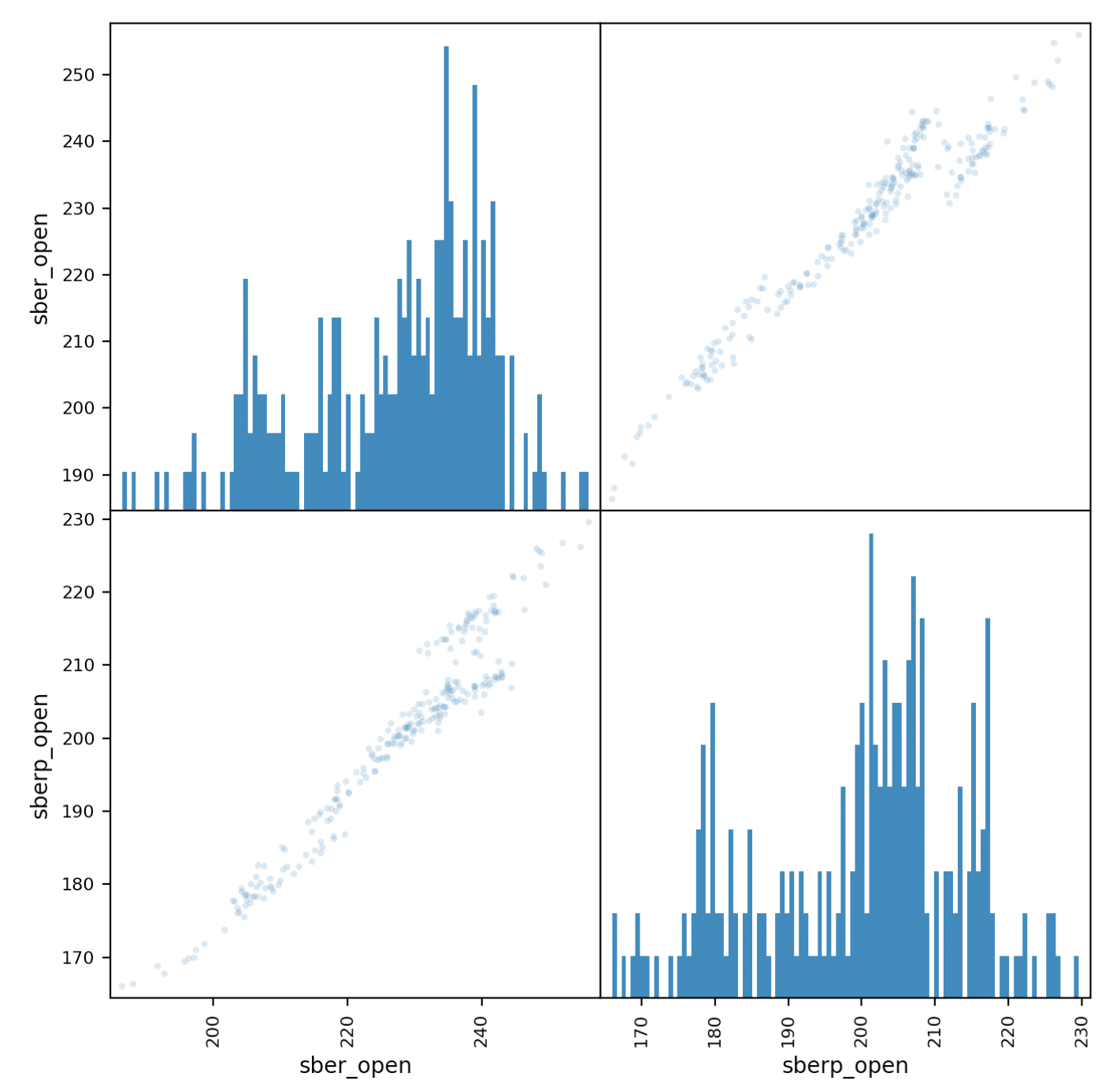 poin "pergi" sepanjang diagonal, korelasi diamati.
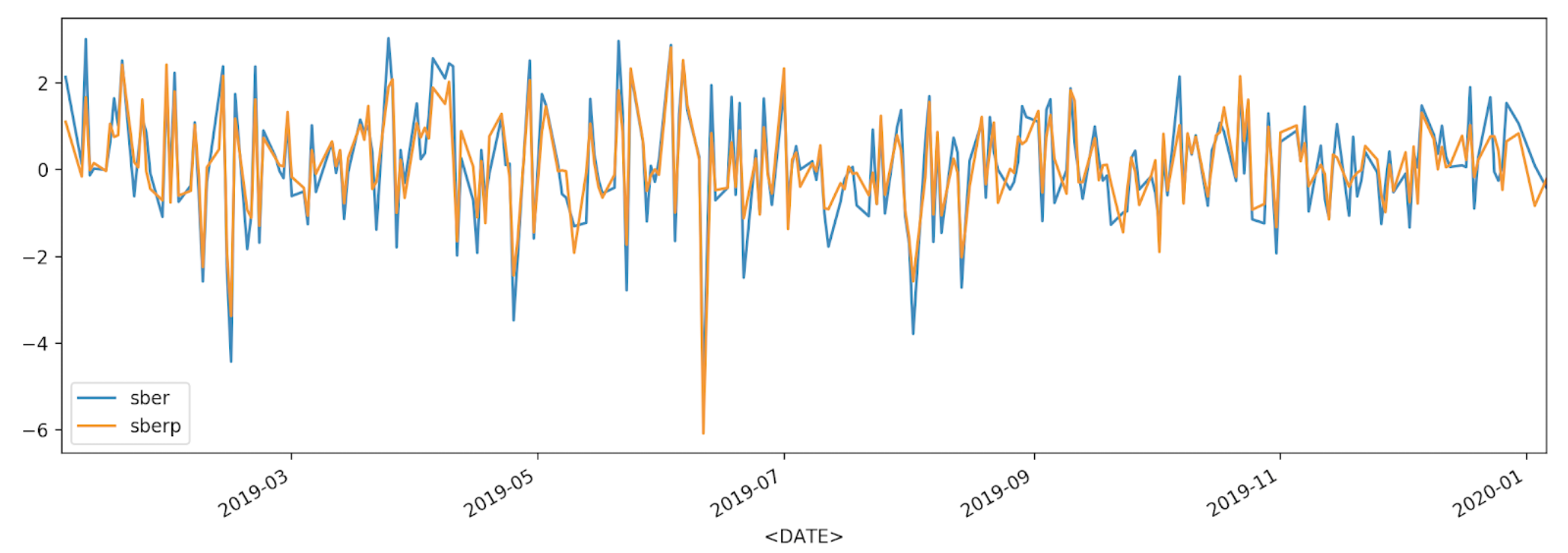
poin "pergi" sepanjang diagonal, korelasi diamati.Penilaian Volatilitas Efek
df['returns_pers'].plot(label='sber')
df2['returns_pers'].plot(label='sberp')
plt.legend()
plt.show()
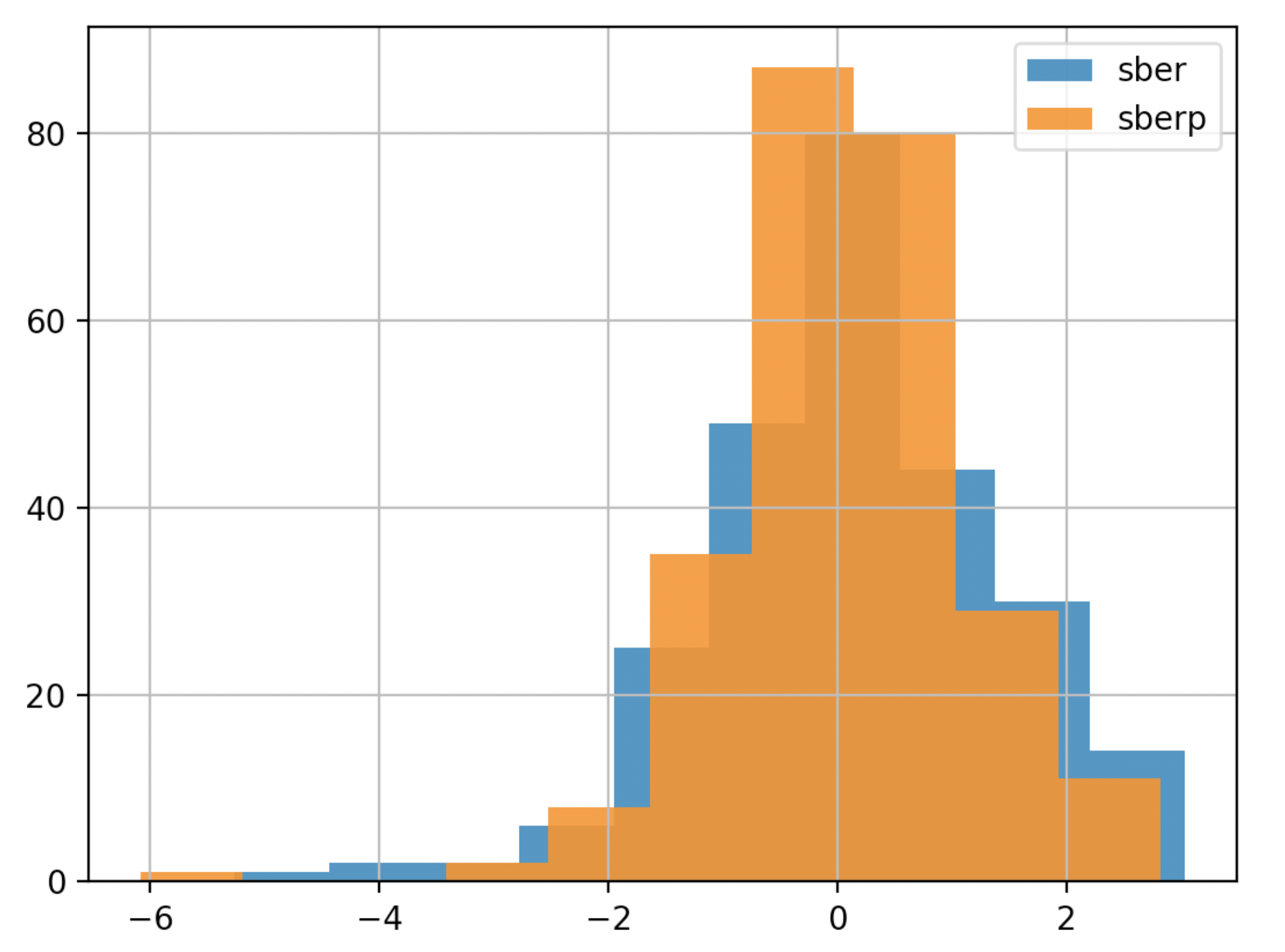
 Untuk pemahaman yang lebih baik, kami akan menampilkan volatilitas pada grafik lain - histogram
Untuk pemahaman yang lebih baik, kami akan menampilkan volatilitas pada grafik lain - histogramdf['returns_pers'].hist(bins=100,label='sber',alpha=0.5)
df2['returns_pers'].hist(bins=100,label='sberp',alpha=0.5)
plt.legend()
plt.show()
 Untuk membuat kesimpulan lebih cepat, Anda dapat menyederhanakan jadwal (kami akan membuat bagan kurang detail dan kurang transparan):
Untuk membuat kesimpulan lebih cepat, Anda dapat menyederhanakan jadwal (kami akan membuat bagan kurang detail dan kurang transparan):df['returns_pers'].hist(bins=10,label='sber',alpha=0.9)
df2['returns_pers'].hist(bins=10,label='sberp',alpha=0.9)
plt.legend()
plt.show()
Analisis Pendapatan Akumulasi
Sekarang kami menurunkan persentase perubahan dalam nilai saham.Untuk melakukan ini, masukkan kolom dengan akumulasi pendapatan.df['Cumulative Return'] = (1+ df['returns']).cumprod()
df2['Cumulative Return'] = (1+ df2['returns']).cumprod()
print(df)
print(df2)
df['Cumulative Return'].plot(label='sber')
df2['Cumulative Return'].plot(label='sberp')
plt.legend()
plt.show()
 Pada grafik kita dapat melihat interval waktu ketika salah satu saham diremehkan atau dinilai kembali relatif terhadap yang lain. Dalam keadaan saat ini (ceteris paribus, harap dicatat) ini akan membantu kami memilih saham untuk rata-rata ketika kapitalisasi Sberbank turun.
Pada grafik kita dapat melihat interval waktu ketika salah satu saham diremehkan atau dinilai kembali relatif terhadap yang lain. Dalam keadaan saat ini (ceteris paribus, harap dicatat) ini akan membantu kami memilih saham untuk rata-rata ketika kapitalisasi Sberbank turun.