 Otak adalah tetangga lama saya. Mempertimbangkan berapa banyak waktu yang kita habiskan, dan berapa banyak kita masih harus bersama, tidak untuk tertarik padanya - ketidakberdayaan semata.Anda berjalan dengan kotak hitam di dalam kotak tengkorak, dan kotak ini mengerti bahwa dia memberikan deskripsi seperti itu pada dirinya sendiri. Ini sangat aneh. Jika mereka memberi saya sepotong besi dengan fitur seperti itu, saya akan menghabiskan seluruh waktu luang saya untuk memahami cara kerjanya. Sebenarnya, saya membunuh. Objek studi selalu bersama saya - sangat nyaman. Sayangnya, Anda tidak bisa menggali ke dalam.Otak merekam dan memproses informasi. Tapi bagaimana caranya? Mengapa sesuatu disimpan untuk waktu yang lama, tetapi ada sesuatu yang terlupakan dalam beberapa hari? Bagaimana ini terkait dengan neuron?Apakah mungkin, berdasarkan informasi dari neurobiologi, untuk membangun model otak yang memberikan perilaku yang mirip dengan otak nyata?Menebak apa? Mari kita coba saja.PENOLAKAN:Tidak akan ada penjelasan lengkap tentang cara kerja otak. Ini adalah deskripsi singkat tentang prinsip-prinsip dasar. Tujuan artikel ini adalah untuk membuat model perkiraan. Terkadang itu tidak akan berhasil. Tapi ini lebih baik daripada tidak punya model.Kita bisa menggambar analogi dengan rumus gesekan dalam fisika. Itu diperoleh secara empiris, dan tidak sepenuhnya akurat. Tetapi cukup akurat untuk membuat estimasi dan menggunakannya dalam perhitungan.Semua tautan di bawah ini untuk studi mendalam. Mereka tidak perlu membaca artikel tersebut. Dan hampir semuanya dalam bahasa Inggris. Internet Rusia buruk dalam informasi yang relevan tentang masalah yang menarik bagi kami.
Otak adalah tetangga lama saya. Mempertimbangkan berapa banyak waktu yang kita habiskan, dan berapa banyak kita masih harus bersama, tidak untuk tertarik padanya - ketidakberdayaan semata.Anda berjalan dengan kotak hitam di dalam kotak tengkorak, dan kotak ini mengerti bahwa dia memberikan deskripsi seperti itu pada dirinya sendiri. Ini sangat aneh. Jika mereka memberi saya sepotong besi dengan fitur seperti itu, saya akan menghabiskan seluruh waktu luang saya untuk memahami cara kerjanya. Sebenarnya, saya membunuh. Objek studi selalu bersama saya - sangat nyaman. Sayangnya, Anda tidak bisa menggali ke dalam.Otak merekam dan memproses informasi. Tapi bagaimana caranya? Mengapa sesuatu disimpan untuk waktu yang lama, tetapi ada sesuatu yang terlupakan dalam beberapa hari? Bagaimana ini terkait dengan neuron?Apakah mungkin, berdasarkan informasi dari neurobiologi, untuk membangun model otak yang memberikan perilaku yang mirip dengan otak nyata?Menebak apa? Mari kita coba saja.PENOLAKAN:Tidak akan ada penjelasan lengkap tentang cara kerja otak. Ini adalah deskripsi singkat tentang prinsip-prinsip dasar. Tujuan artikel ini adalah untuk membuat model perkiraan. Terkadang itu tidak akan berhasil. Tapi ini lebih baik daripada tidak punya model.Kita bisa menggambar analogi dengan rumus gesekan dalam fisika. Itu diperoleh secara empiris, dan tidak sepenuhnya akurat. Tetapi cukup akurat untuk membuat estimasi dan menggunakannya dalam perhitungan.Semua tautan di bawah ini untuk studi mendalam. Mereka tidak perlu membaca artikel tersebut. Dan hampir semuanya dalam bahasa Inggris. Internet Rusia buruk dalam informasi yang relevan tentang masalah yang menarik bagi kami.Di mana untuk memulai?
Mari kita kesampingkan model memori dari psikologi untuk saat ini. Semua deskripsi seperti: "jangka pendek - jangka panjang" , "Memori Kerja" , "teori level pemrosesan" , "angka ajaib 7 + -2" sekarang hanya membingungkan kita. Mencoba memahami otak dengan bantuan mereka seperti mencoba menebak perangkat komputer dengan melihat ke monitor dari bawah akun dengan kontrol orangtua. Bagi kami, mereka akan menjadi berguna hanya setelah kita memahami prinsip-prinsip dasar.Kami akan pergi dari bawah dan memulai jalur dengan neuron.Neuron dan Komunikasi
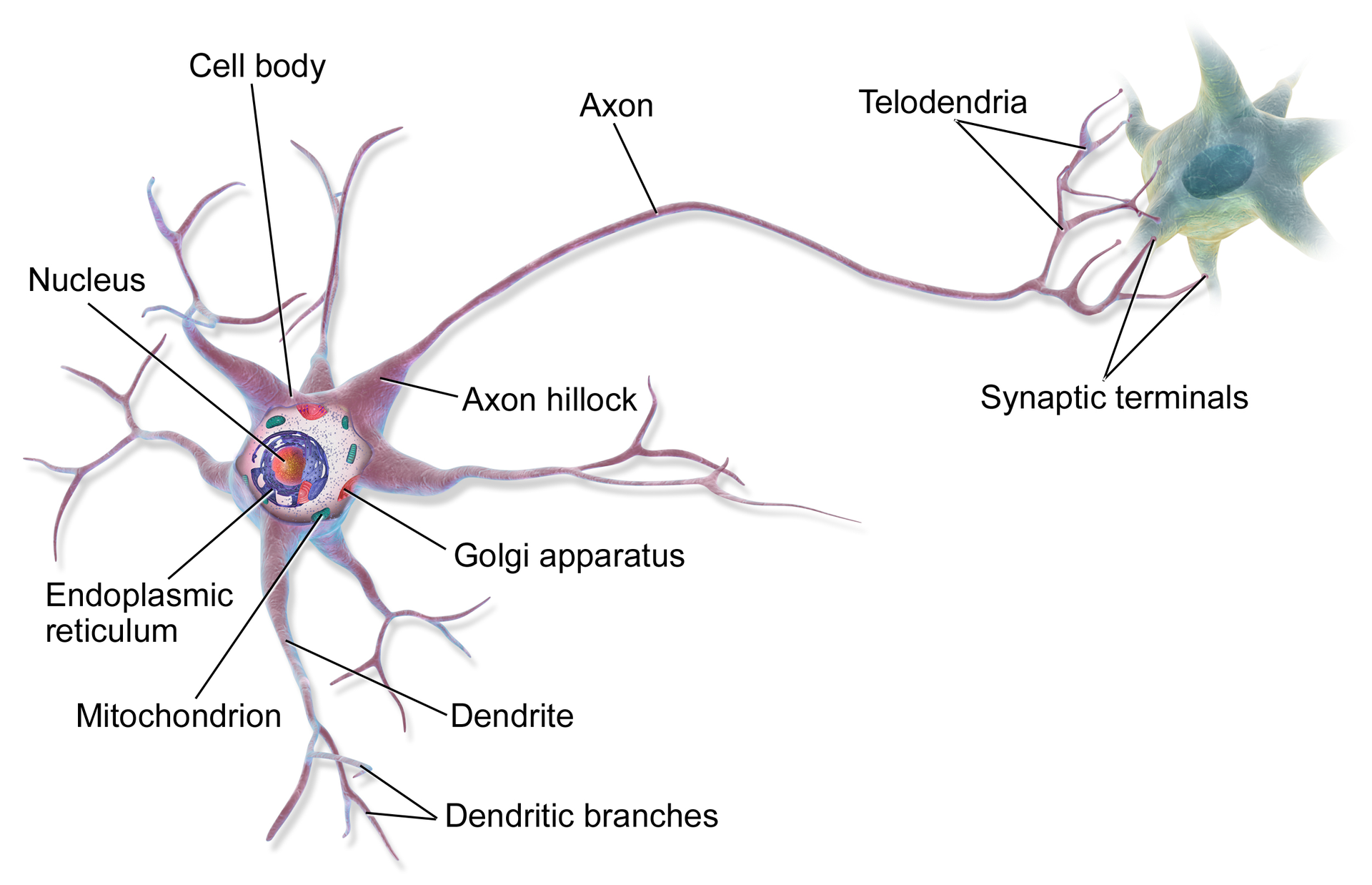 dari: wikiAda banyak jenis neuron. Mereka berbeda dalam jumlah dendrit yang digunakan oleh neurotransmitter , dan banyak parameter lain yang dengannya mereka dapat diklasifikasikan. Kami tidak akan pergi ke hutan implementasi. Mari kita kembali ke dasar - pensinyalan.Jika Anda menggambarkan prosesnya dengan sangat kasar, tampilannya seperti ini:1. Ada neuron yang mengandung ion. Ketika muatannya telah melewati ambang aktivasi (kami telah mengumpulkan banyak partikel bermuatan), ion mulai bergerak di sepanjang akson .
dari: wikiAda banyak jenis neuron. Mereka berbeda dalam jumlah dendrit yang digunakan oleh neurotransmitter , dan banyak parameter lain yang dengannya mereka dapat diklasifikasikan. Kami tidak akan pergi ke hutan implementasi. Mari kita kembali ke dasar - pensinyalan.Jika Anda menggambarkan prosesnya dengan sangat kasar, tampilannya seperti ini:1. Ada neuron yang mengandung ion. Ketika muatannya telah melewati ambang aktivasi (kami telah mengumpulkan banyak partikel bermuatan), ion mulai bergerak di sepanjang akson . from: wiki2. Setelah mencapai ujung akson, ion jatuh ke sinaps . Neurotransmitter disimpan dalam sinaps, dan ion melepaskannya untuk kebebasan.
from: wiki2. Setelah mencapai ujung akson, ion jatuh ke sinaps . Neurotransmitter disimpan dalam sinaps, dan ion melepaskannya untuk kebebasan.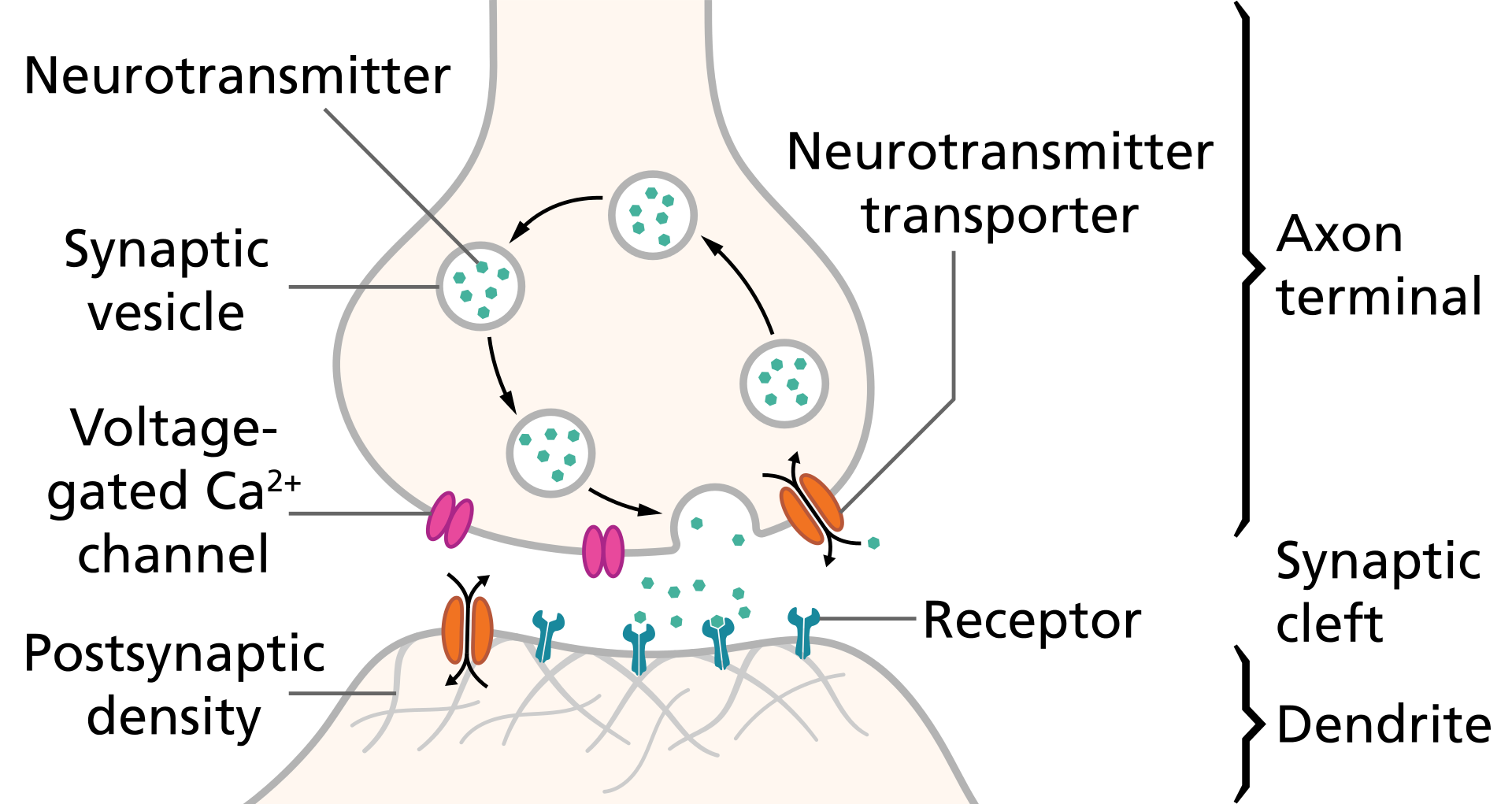 dari:wiki3. Di bawah ini adalah neuron lain yang memiliki reseptor . Mereka menerima neurotransmitter yang dilepaskan dan saluran terbuka untuk pengisian ion neuron berikutnya. Singkatnya, neurotransmitter adalah kuncinya. Begitu berada di kunci reseptor yang sesuai, itu membuka neuron untuk mengisi.
dari:wiki3. Di bawah ini adalah neuron lain yang memiliki reseptor . Mereka menerima neurotransmitter yang dilepaskan dan saluran terbuka untuk pengisian ion neuron berikutnya. Singkatnya, neurotransmitter adalah kuncinya. Begitu berada di kunci reseptor yang sesuai, itu membuka neuron untuk mengisi.Tentang zat yang diizinkan dan tidak terlalu., , — .
— , . , , « ». , .
— . , — () . .. , , . .
— , , .
, !
— .
Satu neuron dapat menerima sinyal dari beberapa, melalui dendrit . Dan satu akson dapat dihubungkan ke beberapa neuron.Sekarang mari kita peras semuanya:- Neuron dapat mengaktifkan dan mengirimkan sinyal ke neuron lain.
- Neuron lain, setelah menerima sinyal, dibebankan, dan mendekati aktivasi.
- Satu neuron dapat menerima sinyal dari beberapa neuron.
- Ketika neuron diaktifkan, ia mentransmisikan sinyal ke semua neuron yang terkait dengannya.
Atau, dalam hal lingkaran dan panah: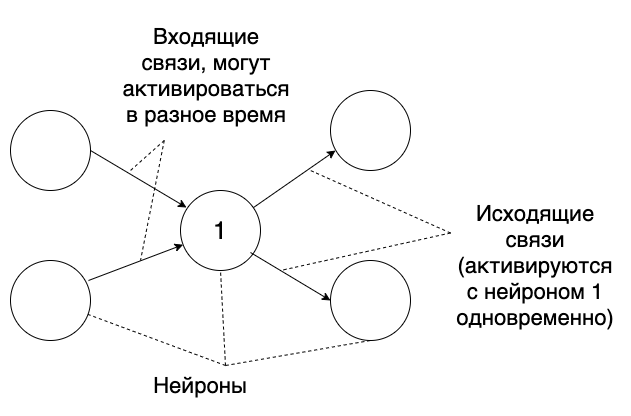 Ini semua sangat informatif, tetapi di mana datanya? Bagaimana cara menyimpan informasi dalam neuron, cara membaca dan cara menulis?
Ini semua sangat informatif, tetapi di mana datanya? Bagaimana cara menyimpan informasi dalam neuron, cara membaca dan cara menulis?Penyimpanan dan membaca
Untuk penyimpanan dan perekaman, ada mekanisme yang disebut plastisitas sinaptik .Di jari, dapat dijelaskan sebagai berikut: koneksi antara neuron memiliki "kekuatan" yang berbeda. Semakin kuat koneksi, semakin terisi daya penerima neuron saat diaktifkan.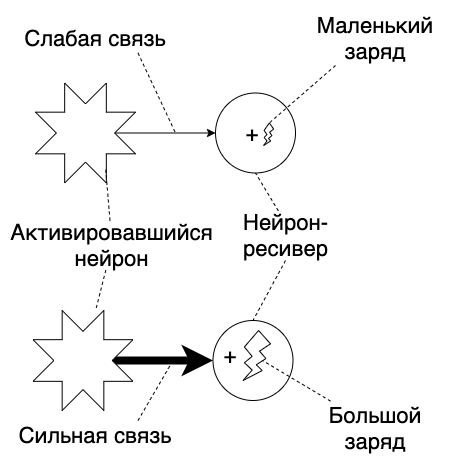 Dan sekarang momen yang mungkin agak sulit dimengerti. Kekuatan ikatan adalah data kami. Anda melihat teks ini - ini adalah aktivasi neuron di otak Anda. "Pola aktivasi" yang dihasilkannya dalam jaringan saraf kita adalah apa yang kita sebut "lihat". Dan saya juga mendengar, merasakan, membayangkan, mengingat, dan sebagainya. Semua ini adalah aktivasi urutan neuron tertentu.Dengan kata lain, jika Anda menemukan di bagian visual korteks otak bagian yang diaktifkan ketika kita melihat sendok, bawa kabel ke sana dan potong arus- Otak akan melihat sendok, dan ia tidak akan pergi ke mana pun. "Saya melihat sendok" = aktivasi neuron di korteks visual karena sinyal dari fotoreseptor di mata.Selamat datang di dunia nyata, Neo. Sendok ada, fotoreseptor ada, neuron ada, dan semua upaya untuk melihat sesuatu dengan upaya mental akan gagal. Meskipun, tidak - Anda bisa menutup mata.Area spesifik otak apa yang akan diaktifkan tergantung pada bagaimana sinyal melewati koneksi. Ini ditentukan oleh kekuatan obligasi.Tambahan gambar kami:Informasi di otak disimpan dalam bentuk koneksi kekuatan yang berbeda antara neuron.Membaca informasi ini dilakukan dengan menggunakan aktivasi neuron. Bagaimana "pola aktivasi" akan terlihat tergantung pada koneksi dan kekuatan mereka.
Dan sekarang momen yang mungkin agak sulit dimengerti. Kekuatan ikatan adalah data kami. Anda melihat teks ini - ini adalah aktivasi neuron di otak Anda. "Pola aktivasi" yang dihasilkannya dalam jaringan saraf kita adalah apa yang kita sebut "lihat". Dan saya juga mendengar, merasakan, membayangkan, mengingat, dan sebagainya. Semua ini adalah aktivasi urutan neuron tertentu.Dengan kata lain, jika Anda menemukan di bagian visual korteks otak bagian yang diaktifkan ketika kita melihat sendok, bawa kabel ke sana dan potong arus- Otak akan melihat sendok, dan ia tidak akan pergi ke mana pun. "Saya melihat sendok" = aktivasi neuron di korteks visual karena sinyal dari fotoreseptor di mata.Selamat datang di dunia nyata, Neo. Sendok ada, fotoreseptor ada, neuron ada, dan semua upaya untuk melihat sesuatu dengan upaya mental akan gagal. Meskipun, tidak - Anda bisa menutup mata.Area spesifik otak apa yang akan diaktifkan tergantung pada bagaimana sinyal melewati koneksi. Ini ditentukan oleh kekuatan obligasi.Tambahan gambar kami:Informasi di otak disimpan dalam bentuk koneksi kekuatan yang berbeda antara neuron.Membaca informasi ini dilakukan dengan menggunakan aktivasi neuron. Bagaimana "pola aktivasi" akan terlihat tergantung pada koneksi dan kekuatan mereka.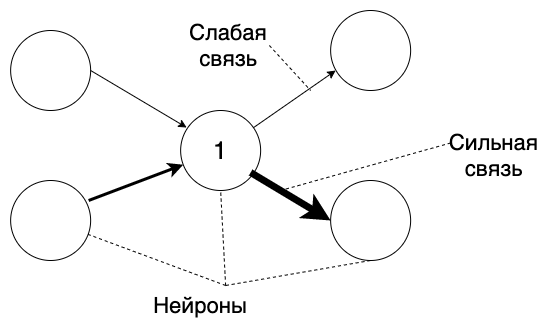 Setiap orang yang terlibat dalam matematika diskrit akan mengenali digraf berbobot dalam gambar ini . Oke, tetapi bagaimana Anda mengubah kekuatan hubungan dan menulis data?
Setiap orang yang terlibat dalam matematika diskrit akan mengenali digraf berbobot dalam gambar ini . Oke, tetapi bagaimana Anda mengubah kekuatan hubungan dan menulis data?Merekam
Ada hal seperti itu, yang disebut teori Ibrani , atau aturanIbrani : Neuron yang hidup bersama - terhubung bersama. (Neuron yang menyala bersama - kawat bersama).Di tingkat yang lebih rendah, ini disediakan oleh mekanisme E-LTP (Early Long-Term Potentiation atau LTP1).Itu dapat dirumuskan ulang sebagai berikut:Jika kita mengaktifkan satu neuron dan yang berikutnya diaktifkan, koneksi akan menjadi lebih kuat.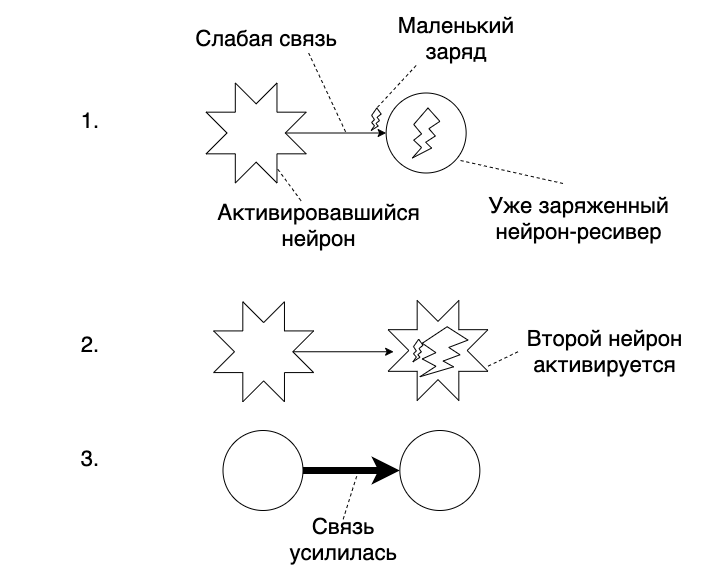 Karena kenyataan bahwa kita dapat mengaktifkan neuron otak dari luar, misalnya menggunakan penglihatan atau pendengaran, kita dapat merekam informasi tentang mereka. Mereka akan diaktifkan bersama, kekuatan komunikasi akan berubah. Lain kali, informasi dapat diperoleh dengan mengaktifkan awal "rantai" ikatan yang kuat.Tapi itu tidak sesederhana itu. Masalahnya adalah kita cenderung melupakan sesuatu. Dan ini berarti bahwa hubungan tidak hanya menguat, tetapi juga melemah. Dan pada saat yang sama, degradasi hubungan terjadi tidak merata - beberapa dari mereka menjadi lebih cepat lebih cepat, yang lain - bertahan lama. Bagaimana lagi untuk menjelaskan fakta bahwa saya tidak ingat ujian kimia di kelas 11, tetapi saya ingat hari ulang tahun saya pada periode yang sama?Anda dapat membuat sistem aktivasi loop tertutup yang rumit, dan mendapatkan koneksi yang terus dipertahankan. Tetapi otak sebenarnya memiliki metode yang lebih sederhana, itu disebut Late Long-Term Potentiation , atau L-LTP.Alih-alih mempertahankan komunikasi melalui aktivasi yang konstan, otak hanya menangkap kondisi saat ini.Oke, dengan "hanya" aku melangkah terlalu jauh. Ada penelitian yang mendukung fakta bahwa proses ini diluncurkan menggunakan sintesis protein khusus . Ada penelitian lain yang mengklaim bahwa penghambatan sintesis protein tidak mempengaruhi L-LTP. Setelah membaca tentang ini, saya menyimpulkan bahwa tidak ada yang meragukan hipotesis memperbaiki negara untuk waktu yang lama. Tetapi saya tidak dapat menemukan detail prosesnya.Untungnya, di dunia panah dan lingkaran sederhana kami, detail ini tidak. Untuk saat ini, kami hanya ingat bahwa koneksi dapat mempertahankan status dan tidak melemah seiring waktu.
Karena kenyataan bahwa kita dapat mengaktifkan neuron otak dari luar, misalnya menggunakan penglihatan atau pendengaran, kita dapat merekam informasi tentang mereka. Mereka akan diaktifkan bersama, kekuatan komunikasi akan berubah. Lain kali, informasi dapat diperoleh dengan mengaktifkan awal "rantai" ikatan yang kuat.Tapi itu tidak sesederhana itu. Masalahnya adalah kita cenderung melupakan sesuatu. Dan ini berarti bahwa hubungan tidak hanya menguat, tetapi juga melemah. Dan pada saat yang sama, degradasi hubungan terjadi tidak merata - beberapa dari mereka menjadi lebih cepat lebih cepat, yang lain - bertahan lama. Bagaimana lagi untuk menjelaskan fakta bahwa saya tidak ingat ujian kimia di kelas 11, tetapi saya ingat hari ulang tahun saya pada periode yang sama?Anda dapat membuat sistem aktivasi loop tertutup yang rumit, dan mendapatkan koneksi yang terus dipertahankan. Tetapi otak sebenarnya memiliki metode yang lebih sederhana, itu disebut Late Long-Term Potentiation , atau L-LTP.Alih-alih mempertahankan komunikasi melalui aktivasi yang konstan, otak hanya menangkap kondisi saat ini.Oke, dengan "hanya" aku melangkah terlalu jauh. Ada penelitian yang mendukung fakta bahwa proses ini diluncurkan menggunakan sintesis protein khusus . Ada penelitian lain yang mengklaim bahwa penghambatan sintesis protein tidak mempengaruhi L-LTP. Setelah membaca tentang ini, saya menyimpulkan bahwa tidak ada yang meragukan hipotesis memperbaiki negara untuk waktu yang lama. Tetapi saya tidak dapat menemukan detail prosesnya.Untungnya, di dunia panah dan lingkaran sederhana kami, detail ini tidak. Untuk saat ini, kami hanya ingat bahwa koneksi dapat mempertahankan status dan tidak melemah seiring waktu.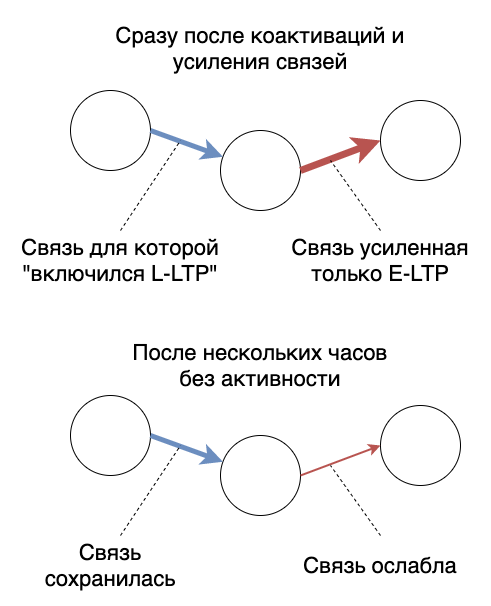
Ringkasan
Mari kita simpulkan hasil sementara dari kunjungan singkat kami ke dunia neurobiologi:- Ada neuron. Dalam gambar kita itu adalah bola. Mereka mengakumulasi biaya, dan diaktifkan ketika melebihi ambang tertentu.
- . . , — , - . .
- . — . , -, .
- . , - . , , E-LTP.
- . — , — , — . L-LTP.
, :
Jika Anda tertarik pada model neuron yang lebih akurat, dan daftar perbedaan karakteristik neuron biologis dari model mereka di JST, lihat artikel ini . Sebagai bagian dari posting ini, saya hanya menjelaskan apa yang akan saya butuhkan di masa depan.Bagian penelitian ini memakan waktu 4 bulan. Saya membaca artikel dan menerobos lusinan istilah yang tidak jelas bagi saya, berubah menjadi bidang yang salah dan menemukan informasi yang sudah ketinggalan zaman tentang pertanyaan saya.Naik tingkat. Subnet dan objek
Kami mendapat model proses yang terjadi di otak dengan neuron. Sayangnya, kita tidak memiliki deskripsi terperinci tentang struktur yang lebih besar, "subnet" otak kita. Tetapi kami memiliki dasar untuk membangunnya sendiri. Sekarang kita akan melakukan eksperimen dan mengumpulkan informasi tentang perilaku otak. Dan kemudian berdasarkan model dasar kita akan membangun penjelasan tentang hasil eksperimen. Jika kita membangunnya dengan benar, itu tidak hanya akan menjelaskan apa yang sudah kita ketahui, tetapi juga memprediksi hasil percobaan lebih lanjut.Hal pertama yang saya perhatikan adalah bahwa kita memiliki konsep objek. Atau keseluruhannya. Secara umum, semua yang dapat dianggap bilangan asli: meja, kursi, rumah, pohon, daun, otak ... Otak jelas menyukai konsep ini, ia intuitif. Tetapi kita tahu bahwa dunia tidak terdiri dari objek, seperti yang kita lihat. Monitor yang Anda baca teks ini bukan benda padat. Kita bisa memecahnya menjadi komponen-komponennya. Ini memiliki piksel, ada bingkai ... Jika kita lanjutkan, kita akan mencapai molekul dan atom. Tetapi atom dan molekul juga bukan keseluruhan, mereka tersusun dari partikel lain.Tetapi mengapa otak benar-benar menyukai konsep partikel? Serius, cara terbaik untuk istirahat ru adalah untuk mendapatkan ru tugas tidak dinyatakan dalam bilangan bulat ru untuk diproses .Dan saya pikir - bagaimana jika keberadaan objek persepsi dunia dijelaskan oleh struktur jaringan saraf kita? Bagaimana jika "objek" adalah kata yang menggambarkan aktivasi area yang terhubung? Ini menjelaskan mengapa kita memandang kursi atau meja secara keseluruhan - mereka memiliki satu kontur yang menonjol dengan latar belakang umum. Mungkin ini menyebabkan aktivasi simultan dari seluruh subnet di korteks visual?Demikian pula, kata dan huruf dapat dikenali. Untuk menyederhanakannya, maka dalam gambar kita akan terlihat seperti ini: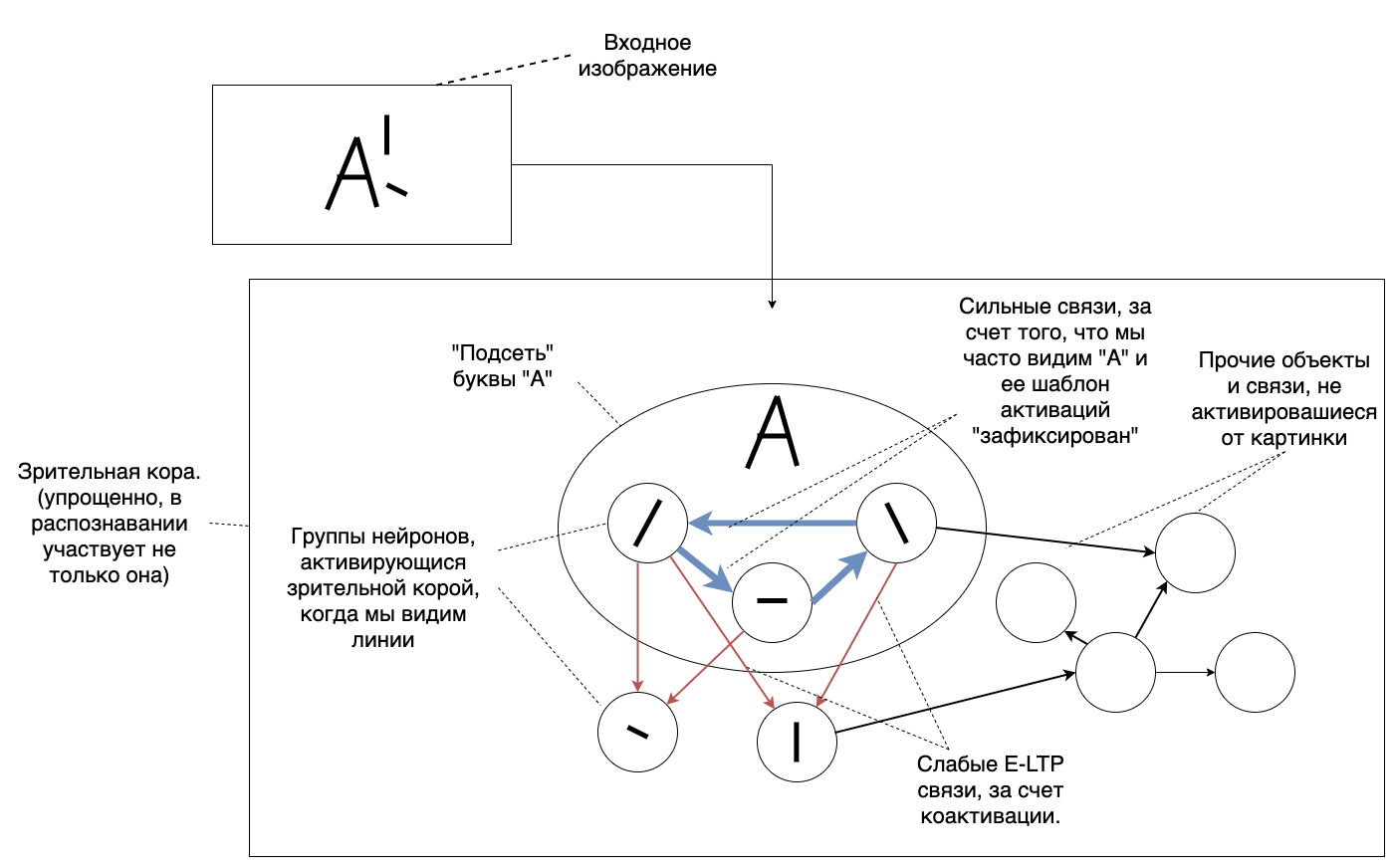 Saya merumuskan hipotesis: Ada area di otak dengan koneksi kuat antara neuron. Aktivasi mereka memberikan rasa "integritas" atau "kehadiran suatu objek." Sekarang Anda perlu memeriksa kekuatannya.Konsekuensi pertama yang dapat diperoleh adalah bahwa jika kita memiliki subnet yang sangat terhubung, maka diaktifkan bahkan dengan informasi yang tidak lengkap . Kita harus mampu menyelesaikan pola yang sudah dikenal secara mandiri. Dan sebaliknya - jika tidak ada template seperti itu, otak tidak akan dapat mengembalikannya. Di sini saya menemukan beberapa artikel menarik tentang ilusi optik dan gangguan dalam pemrosesan informasi melalui penglihatan. Ini salah satunya. Saya juga menghabiskan banyak waktu memaksa teman dan kolega saya untuk mengisi kuesioner dengan surat yang hilang. Saya membagi kata dengan kelalaian menjadi 3 kategori:
Saya merumuskan hipotesis: Ada area di otak dengan koneksi kuat antara neuron. Aktivasi mereka memberikan rasa "integritas" atau "kehadiran suatu objek." Sekarang Anda perlu memeriksa kekuatannya.Konsekuensi pertama yang dapat diperoleh adalah bahwa jika kita memiliki subnet yang sangat terhubung, maka diaktifkan bahkan dengan informasi yang tidak lengkap . Kita harus mampu menyelesaikan pola yang sudah dikenal secara mandiri. Dan sebaliknya - jika tidak ada template seperti itu, otak tidak akan dapat mengembalikannya. Di sini saya menemukan beberapa artikel menarik tentang ilusi optik dan gangguan dalam pemrosesan informasi melalui penglihatan. Ini salah satunya. Saya juga menghabiskan banyak waktu memaksa teman dan kolega saya untuk mengisi kuesioner dengan surat yang hilang. Saya membagi kata dengan kelalaian menjadi 3 kategori:- Konsep umum.
- Istilah khusus yang diketahui oleh orang yang menjalani survei.
- Istilah khusus dari area sempit yang tidak diketahui subjeknya.
Sebagai contoh, saya memberi kolega kepada pemrogram sebuah kuesioner yang mencakup kata-kata sehari-hari, seperti "tabel" dan "kursi", kata-kata dari domain TI, seperti " pola " dan " tabel hash ", dan kata-kata dari bidang biologi dan genetika, seperti " polyadenylation " atau " adenosin monofosfat ".Ternyata orang-orang berhasil mengisi kekosongan dengan kata-kata yang akrab dan tidak bisa melakukan ini dengan orang asing. Ini sesuai dengan apa yang saya baca di sumber lain dan dengan hipotesis saya.Untuk mendengar, ini juga berhasil. Orang-orang dengan sempurna mengenali ucapan yang akrab bagi mereka, bahkan dengan sinyal yang buruk, tetapi tidak dapat mengatasi jika mereka bertemu dengan pola yang tidak dikenal.Jika Anda memiliki pertanyaan tentang format: Mengapa Anda memeriksa sendiri hal-hal yang sudah jelas?, , , , . , . , — .
, , . , , . , , . ! , . , — .
. , , — . , . , « » — , . , . — .
, , « » « », . , , ,
. — .
. Saya menguji asumsi saya selama 3 bulan dan ternyata berhasil dengan baik.Anda mengirimkan template yang sangat terhubung ke input - orang mengatakan bahwa itu membangkitkan rasa keseluruhan, mendefinisikannya sebagai 1 objek. Breaking order, mencoba membuat pola aktivasi yang berbeda - keseluruhan dibagi menjadi beberapa bagian dan menjadi beberapa objek.Misalnya: "Fields", "Theory", "Unified" / "Unified", "Theory", "Fields" (Saya mencoba menemukan contoh dalam bahasa Rusia selama 7 menit. Siapa yang muncul dengan ide menyinkronkan persepsi kata melalui bentuknya? Lebih mudah dengan bahasa Inggris: Relativitas Khusus / Relativitas Khusus, Persamaan Lapangan Einstein / Persamaan Lapangan Einstein)Jadi saya sampai pada Hipotesis 1 :Ada jaringan neuron yang sangat terhubung di otak. Aktivasi jaringan semacam itu menimbulkan rasa "satu objek" atau "keseluruhan". Menulis objek baru ke memori terjadi melalui penciptaan area baru yang sangat terhubung.Dengan kata lain, saya percaya bahwa kemampuan untuk membedakan antara objek disediakan oleh konektivitas dan penundaan waktu aktivasi.PSSaya akan membuat reservasi bahwa kemungkinan besar ada pembatasan pada ukuran subnet. Tidak peduli bagaimana Anda mempelajari ayat itu, seluruh teks tidak akan menjadi satu objek, itu akan menjadi aktivasi berurutan di sepanjang rantai.Pro:- Menjelaskan pemulihan informasi berdasarkan data yang tidak lengkap dan keberadaan ilusi optik, melalui mekanisme aktivasi subnet secara keseluruhan.
- -> -> -> , . , .
- , , .. . -> -> .
- UX-.
- SRP. , , « ». , . , , .
- Daftarnya berlanjut.
Cons:Tidak jelas persis bagaimana "rasa integritas" muncul. Di mana pesan itu sampai pada bagian otak yang kita anggap sebagai Diri bahwa bagian lain "menutup gestalt"?Kriteria pemalsuan:Hipotesis ini akan dibuang ke tempat sampah jika:- Neuron tidak membentuk subnet yang stabil dan sangat terhubung.
- Ada cara untuk membuktikan secara eksperimental bahwa kemampuan untuk "menyorot objek individual" tidak terkait dengan aktivasi jaringan dari titik di atas.
- Akan ada penjelasan tentang semua item dari daftar "plus", menggunakan lebih sedikit entitas. Pada saat yang sama, itu harus direduksi menjadi neuron, atau benda lain yang ada di otak.
- Metode penyangkalan formal atau eksperimental lainnya. Kontradiksi logis, konsekuensi yang tidak dikonfirmasi, dll.
Program karunia pemalsuan:Hipotesis berpartisipasi dalam program hadiah berpikir kritis: $ 50 per bantahan.Deskripsi tambahan di bawah spoiler di bawah ini:Kondisi:50 , .
, . . , — . , (, , , ).
:
, …, ..., , .
:
« , ?» — .
« , ...» — , - .
« ?» — , . , .
« ?» — . . .
« , , 4 »:
1 — , , .
2 — , . , .
3 — . , , , ---… , , «» - ---.
4 — , , — . , , .
"Subnet neuron yang terhubung dengan kuat" Saya sebut "objek". Saya terlalu malas untuk menulis 3 kata. Semua teori ingatan psikologis bekerja dengan tepat konsep ini, dan dalam kehidupan sehari-hari masuk akal "apa yang dapat dibedakan secara keseluruhan."Secara subyektif, , — .
, , .
«» . .
Seperti yang Anda pahami, objek dikaitkan dengan objek lain. Jika hasilnya adalah subnet yang aktif secara instan, kami akan menganggap bahwa kami telah membentuk objek baru. Jika koneksi tidak cukup kuat atau ada terlalu banyak sub-objek untuk aktivasi instan, saya akan menyebut konfigurasi ini sebagai "model".Saya mengusulkan untuk memanggil seluruh rangkaian objek dan koneksi di antara mereka Grafik Pengetahuan dan menunjuknya pada KDPV.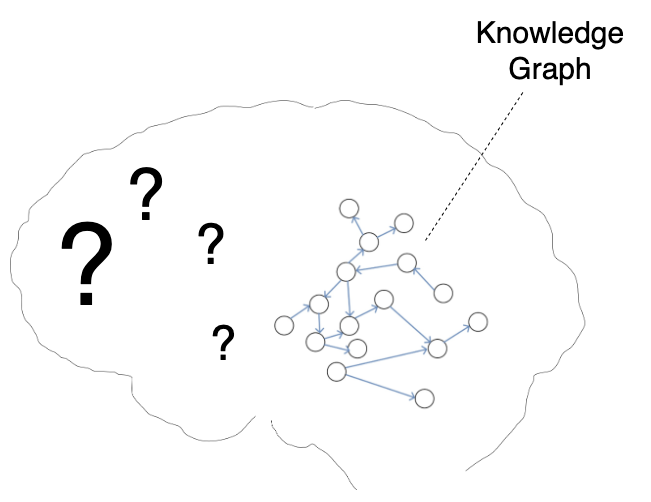
Ringkasan
Kami melihat bagaimana neuron diatur dan disusun model matematisnya (ya, panah dan lingkaran adalah teori grafik). Sedikit menyentuh tentang bagaimana antidepresan dan antipsikotik bekerja di otak - mereka mengatur kadar neurotransmiter dan dengan demikian mempengaruhi aktivasi neuron (pada kenyataannya, mereka mengubah kekuatan koneksi). Kami belajar tentang aturan Hebb (neuron yang hidup bersama - terhubung bersama), dan mekanisme E-LTP, yang bertanggung jawab untuk memori jangka pendek. Kami melihat bagaimana otak memecahkan masalah menghafal jangka panjang - dengan memperbaiki kekuatan komunikasi melalui L-LTP.Berdasarkan model kami, kami memperkirakan keberadaan subnet neuron dengan koneksi yang kuat.Menggunakan asumsi ini, kami mencoba menjelaskan beberapa efek yang kami amati: ilusi optik, menebak dan menebak objek berdasarkan informasi yang tidak lengkap, keberadaan sensasi "satu objek". Cukup aneh - ternyata. Kami dapat menggunakan mekanisme yang sama untuk menyusun struktur yang lebih kompleks - model dan objek kompleks. Dan itu juga berhasil.Tampaknya bagi saya ini adalah hasil antara yang baik, tetapi sejauh ini kami memiliki lebih banyak pertanyaan daripada jawaban:- Mengapa memori tidak digunakan "seluruhnya"? Di mana akses instan ke semua yang kita tahu? Dengan kata lain, mengapa kita harus ingat, dan bagaimana cara kerjanya?
- Pada titik mana L-LTP menyala dan informasinya masuk ke memori jangka panjang?
- , , ? : « ?» « ?» — , .
UPD: . - , ? ?
- ?
Kami akan membicarakannya di artikel berikut.NB.Jika Anda memiliki pertanyaan tentang bagian mana pun - saya dapat menyatakan sesuatu secara lebih rinci dalam komentar atau menulis artikel klarifikasi. Yang ini dan itu mengacu pada Longrid, untuk menyatakan bahkan lebih detail - kita mendapatkan seluruh buku. Tidak yakin apakah ini cocok dengan format Habr.Jika Anda memiliki saran tentang gaya presentasi - saya akan senang mendengarnya.Lisensi: CC BY-NC-ND 4.0