Ribuan manajer dari kantor penjualan di seluruh negeri mencatat puluhan ribu kontak dalam sistem CRM kami setiap hari - fakta-fakta komunikasi dengan potensi atau sudah bekerja dengan pelanggan kami. Dan untuk klien ini Anda harus terlebih dahulu menemukan, dan lebih disukai sangat cepat. Dan ini paling sering terjadi dengan nama.Oleh karena itu, tidak mengherankan bahwa, sekali lagi menganalisis permintaan "berat" di salah satu basis data yang paling banyak dimuat - akun VLSI perusahaan kami sendiri , saya menemukan "di atas" permintaan untuk pencarian "cepat" dengan nama untuk kartu perusahaan.Selain itu, penyelidikan lebih lanjut mengungkapkan contoh yang menarik tentang optimasi dan kemudian penurunan kinerja meminta perbaikan berikutnya oleh beberapa tim, yang masing-masing bertindak semata-mata dari maksud baik.0: apa yang diinginkan pengguna
[KDPV dari sini ]Apa yang biasanya pengguna maksud ketika dia mengatakan pencarian "cepat" dengan nama? Hampir tidak pernah ternyata menjadi pencarian "jujur" pada substring dari tipe ... LIKE '%%'- karena kemudian tidak hanya dan , tetapi bahkan mendapatkan hasilnya . Pengguna menyiratkan pada tingkat rumah tangga bahwa Anda memberinya pencarian di awal kata dalam judul dan menunjukkan lebih relevan apa yang dimulai dengan yang dimasukkan. Dan lakukan hampir secara instan - dengan input interlinear.''' '''' '1: batasi tugas
Dan terlebih lagi, seseorang tidak akan secara khusus memasukkan ' 'sehingga Anda harus mencari setiap awalan kata. Tidak, itu jauh lebih mudah bagi pengguna untuk menanggapi petunjuk cepat untuk kata terakhir daripada dengan sengaja “merindukan” yang sebelumnya - lihat bagaimana mesin pencari bekerja.Secara umum, merumuskan persyaratan dengan benar untuk suatu tugas lebih dari setengah solusi. Kadang-kadang analisis yang cermat dari kasus penggunaan dapat secara signifikan mempengaruhi hasilnya .Apa yang dilakukan pengembang abstrak?1.0: mesin pencari eksternal
Oh, pencarian itu sulit, saya tidak ingin melakukan apa pun - mari berikan kepada para devops! Biarkan mereka menyebarkan kepada kami mesin pencari eksternal relatif terhadap basis data: Sphinx, ElasticSearch, ... Opsi yangberfungsi, meskipun memakan waktu, dalam hal sinkronisasi dan kecepatan perubahan. Tetapi tidak dalam kasus kami, karena pencarian dilakukan untuk setiap klien hanya dalam kerangka data akunnya. Dan data memiliki variabilitas yang agak tinggi - dan jika manajer sekarang memasukkan kartu ' ', maka setelah 5-10 detik dia sudah dapat mengingat bahwa dia lupa menunjukkan email di sana dan ingin menemukan dan memperbaikinya.Karena itu - mari kita cari "langsung di database . " Untungnya, PostgreSQL memungkinkan kami melakukan ini, dan bukan hanya satu opsi - kami akan mempertimbangkannya.1.1: substring "jujur"
Kami berpegang teguh pada kata "substring." Tetapi tepatnya untuk pencarian indeks dengan substring (dan bahkan oleh ekspresi reguler!) Ada pg_trgm modul yang sangat baik ! Hanya dengan demikian perlu menyortir dengan benar.Mari kita coba mengambil piring untuk kesederhanaan model:CREATE TABLE firms(
id
serial
PRIMARY KEY
, name
text
);
Kami mengisi di sana 7,8 juta catatan organisasi dan indeks nyata:CREATE EXTENSION pg_trgm;
CREATE INDEX ON firms USING gin(lower(name) gin_trgm_ops);
Mari kita lihat 10 entri pertama untuk pencarian interline:SELECT
*
FROM
firms
WHERE
lower(name) ~ ('(^|\s)' || '')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
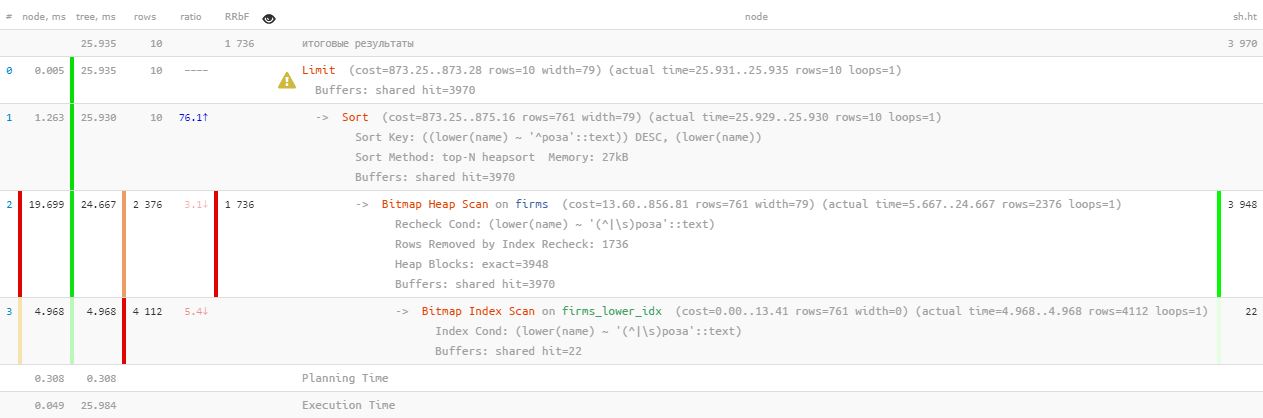 [lihat menjelaskan.tensor.ru]Ya, itu ... 26 ms, 31MB data terbaca dan lebih dari 1,7 ribu catatan yang difilter - untuk 10 orang. Overhead terlalu tinggi, mungkinkah menjadi lebih efisien?
[lihat menjelaskan.tensor.ru]Ya, itu ... 26 ms, 31MB data terbaca dan lebih dari 1,7 ribu catatan yang difilter - untuk 10 orang. Overhead terlalu tinggi, mungkinkah menjadi lebih efisien?1.2: pencarian teks? itu FTS!
Memang, PostgreSQL menyediakan mekanisme yang sangat kuat untuk pencarian teks lengkap (Full Text Search), termasuk kemungkinan pencarian awalan. Opsi hebat, bahkan ekstensi tidak perlu dipasang! Mari mencoba:CREATE INDEX ON firms USING gin(to_tsvector('simple'::regconfig, lower(name)));
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
 [lihat menjelaskan.tensor.ru]Di sini paralelisasi dari eksekusi permintaan membantu kami sedikit, mengurangi waktu menjadi setengah hingga 11ms . Ya, dan kami harus membaca 1,5 kali lebih sedikit - hanya 20MB . Dan di sini, semakin kecil semakin baik, karena semakin besar jumlah yang kami kurangi, semakin tinggi peluang untuk kehilangan cache, dan setiap halaman data tambahan yang dibaca dari disk merupakan "rem" potensial untuk permintaan tersebut.
[lihat menjelaskan.tensor.ru]Di sini paralelisasi dari eksekusi permintaan membantu kami sedikit, mengurangi waktu menjadi setengah hingga 11ms . Ya, dan kami harus membaca 1,5 kali lebih sedikit - hanya 20MB . Dan di sini, semakin kecil semakin baik, karena semakin besar jumlah yang kami kurangi, semakin tinggi peluang untuk kehilangan cache, dan setiap halaman data tambahan yang dibaca dari disk merupakan "rem" potensial untuk permintaan tersebut.1.3: Masih SEPERTI?
Permintaan sebelumnya baik untuk semua orang, tetapi hanya jika Anda menariknya seratus ribu kali sehari, maka data membaca 2TB akan naik . Paling - dari memori, tetapi jika Anda tidak beruntung, maka dari disk. Jadi mari kita coba membuatnya lebih kecil.Ingatlah bahwa pengguna ingin melihat dulu "yang dimulai dengan ..." . Jadi ini dalam bentuk murni pencarian awalan dengan text_pattern_ops! Dan hanya jika kita "tidak cukup" untuk 10 catatan yang diperlukan, maka kita harus membacanya menggunakan pencarian FTS:CREATE INDEX ON firms(lower(name) text_pattern_ops);
SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
LIMIT 10;
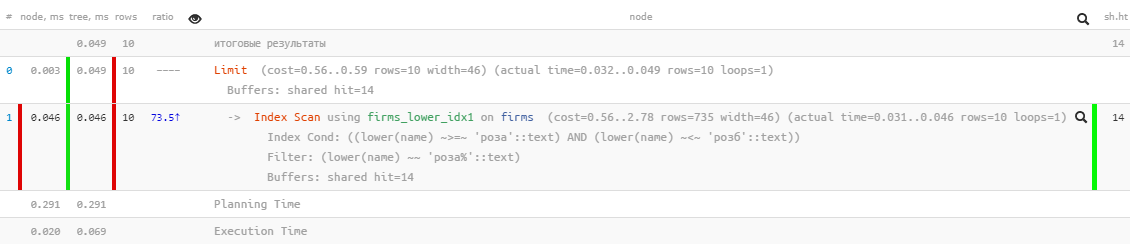 [lihat menjelaskan.tensor.ru]Performa luar biasa - hanya 0,05 ms dan sedikit lebih dari 100KB dibaca! Hanya kami yang lupa untuk mengurutkan berdasarkan nama sehingga pengguna tidak tersesat dalam hasil:
[lihat menjelaskan.tensor.ru]Performa luar biasa - hanya 0,05 ms dan sedikit lebih dari 100KB dibaca! Hanya kami yang lupa untuk mengurutkan berdasarkan nama sehingga pengguna tidak tersesat dalam hasil:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name)
LIMIT 10;
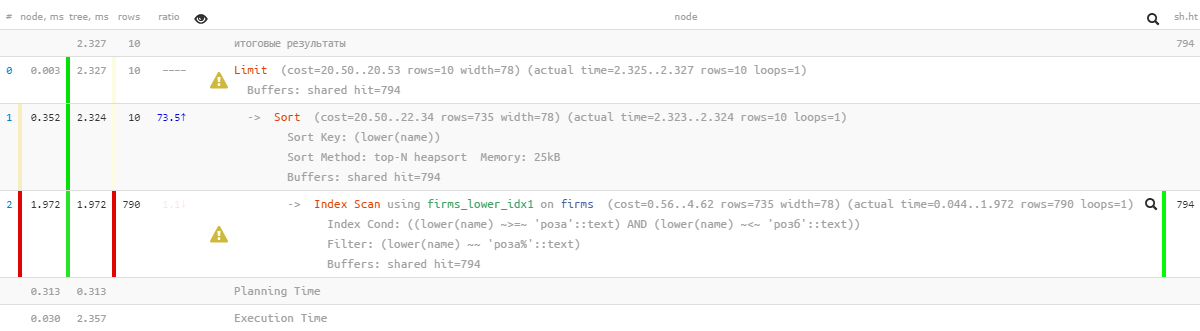 [lihat menjelaskan.tensor.ru]Oh, ada sesuatu yang tidak begitu cantik lagi - tampaknya ada indeks, tetapi menyortir lalat melewatinya ... Itu, tentu saja, berkali-kali lebih efektif daripada versi sebelumnya, tapi ...
[lihat menjelaskan.tensor.ru]Oh, ada sesuatu yang tidak begitu cantik lagi - tampaknya ada indeks, tetapi menyortir lalat melewatinya ... Itu, tentu saja, berkali-kali lebih efektif daripada versi sebelumnya, tapi ...1.4: "modifikasi dengan file"
Tetapi ada indeks yang memungkinkan Anda untuk mencari berdasarkan rentang, dan itu normal untuk menggunakan penyortiran - btree normal !CREATE INDEX ON firms(lower(name));
Hanya permintaan untuk itu yang harus "dirakit secara manual":SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10;
 [lihat menjelaskan.tensor.ru]Hebat - pekerjaan penyortiran dan konsumsi sumber daya tetap "mikroskopis", ribuan kali lebih efisien daripada FTS "murni" ! Tetap mengumpulkan dalam satu permintaan:
[lihat menjelaskan.tensor.ru]Hebat - pekerjaan penyortiran dan konsumsi sumber daya tetap "mikroskopis", ribuan kali lebih efisien daripada FTS "murni" ! Tetap mengumpulkan dalam satu permintaan:(
SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10
)
UNION ALL
(
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*') AND
lower(name) NOT LIKE ('' || '%')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10
)
LIMIT 10;
Saya perhatikan bahwa subquery kedua hanya dieksekusi jika yang pertama kembali kurang dariLIMIT jumlah baris yang diharapkan oleh yang terakhir . Saya sudah menulis tentang metode optimasi kueri ini .Jadi ya, kami sekarang memiliki btree dan gin di atas meja pada saat yang sama, tetapi secara statistik ternyata kurang dari 10% dari permintaan mencapai blok kedua . Artinya, dengan batasan khas yang terkenal untuk tugas tersebut, kami dapat mengurangi total konsumsi sumber daya server hampir seribu kali!1.5 *: membuang file
Di atas LIKEkami dilarang menggunakan jenis yang salah. Tapi itu bisa "diatur di jalur yang benar" dengan menentukan pernyataan USING:Default tersirat ASC. Selain itu, Anda dapat menentukan nama operator pengurutan tertentu dalam kalimat USING. Operator sortir harus anggota kurang dari atau lebih besar dari keluarga tertentu dari operator B-tree. ASCbiasanya setara USING <dan DESCbiasanya setara USING >.
Dalam kasus kami, "kurang" adalah ~<~:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name) USING ~<~
LIMIT 10;
 [lihat menjelaskan.tensor.ru]
[lihat menjelaskan.tensor.ru]2: cara "masam" permintaan
Sekarang kami meninggalkan permintaan kami untuk "bersikeras" selama setengah tahun atau satu tahun, dan dengan mengejutkan kami menemukannya lagi "di atas" dengan indikator total "pemompaan" memori ( buffer hit bersama ) harian di 5.5TB - yaitu, bahkan lebih dari yang semula.Tidak, tentu saja, bisnis kami telah berkembang, dan bebannya telah meningkat, tetapi tidak terlalu banyak! Jadi ada yang kotor di sini - mari kita cari tahu.2.1: kelahiran paging
Pada titik tertentu, tim pengembang lain ingin memungkinkan untuk "melompat" ke dalam registri dari pencarian subskrip cepat dengan hasil yang sama, tetapi diperluas. Dan registri apa tanpa navigasi halaman? Mari kita mengacaukannya!( ... LIMIT <N> + 10)
UNION ALL
( ... LIMIT <N> + 10)
LIMIT 10 OFFSET <N>;
Sekarang mungkin saja tanpa memaksa pengembang untuk menunjukkan daftar hasil pencarian dengan memuat "tipe-halaman".Tentu saja, pada kenyataannya, untuk setiap halaman data berikutnya, semakin banyak yang sedang dibaca (semua waktu sebelumnya, yang kita buang, ditambah "ekor" yang diinginkan) - yaitu, ini adalah antipattern yang tidak ambigu. Dan akan lebih tepat untuk memulai pencarian di iterasi berikutnya dari kunci yang disimpan dalam antarmuka, tetapi tentang hal itu - lain kali.2.2: ingin eksotis
Pada titik tertentu, pengembang ingin mendiversifikasi seleksi yang dihasilkan dengan data dari tabel lain, untuk tujuan mana seluruh permintaan sebelumnya dikirim ke CTE:WITH q AS (
...
LIMIT <N> + 10
)
SELECT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
Dan meskipun demikian - tidak buruk, karena subquery dihitung hanya untuk 10 catatan yang dikembalikan, jika tidak ...2.3: PERBEDAAN tanpa arti dan tanpa ampun
Di suatu tempat dalam proses evolusi seperti itu, suatu kondisi hilangNOT LIKE dari subquery ke-2 . Jelas bahwa setelah itu saya UNION ALLmulai mengembalikan beberapa catatan dua kali - pertama kali ditemukan di awal baris, dan kemudian lagi - di awal kata pertama dari baris ini. Dalam batas itu, semua catatan dari subquery ke-2 dapat bertepatan dengan catatan dari yang pertama.Apa yang dilakukan pengembang alih-alih menemukan alasan? .. Tidak ada pertanyaan!- gandakan ukuran sampel asli
- letakkan DISTINCT sehingga kita hanya mendapatkan satu instance dari setiap baris
WITH q AS (
( ... LIMIT <2 * N> + 10)
UNION ALL
( ... LIMIT <2 * N> + 10)
LIMIT <2 * N> + 10
)
SELECT DISTINCT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
Artinya, jelas bahwa hasilnya, pada akhirnya, persis sama, tetapi kesempatan untuk "terbang" ke subquery CTE ke-2 telah menjadi jauh lebih tinggi, dan tanpa ini, jelas lebih banyak dibaca .Tapi ini bukan yang paling menyedihkan. Karena pengembang meminta saya untuk memilih, DISTINCTbukan secara spesifik, tetapi langsung oleh semua bidang catatan, bidang sub_query, hasil dari subquery, juga tiba di sana secara otomatis. Sekarang, untuk eksekusi DISTINCT, database harus mengeksekusi bukan 10 subquery, tetapi semua <2 * N> + 10 !2.4: kerja sama di atas segalanya!
Jadi, pengembang tetap hidup - mereka tidak peduli, karena dalam registri mereka "ditambal" ke nilai N yang signifikan dengan perlambatan kronis dalam menerima setiap "halaman" berikutnya.Sampai pengembang dari departemen lain datang kepada mereka, dan tidak ingin menggunakan metode yang nyaman untuk pencarian berulang - yaitu, kami mengambil sepotong dari beberapa sampel, menyaring dengan kondisi tambahan, menggambar hasilnya, lalu potongan berikutnya (yang dalam kasus kami dicapai oleh tingkatkan N), dan seterusnya sampai kita mengisi layar.Secara umum, dalam spesimen yang ditangkap N mencapai nilai hampir 17K , dan hanya dalam 24 jam setidaknya 4K permintaan tersebut dieksekusi "dalam rantai". Yang terakhir dari mereka sudah dipindai dengan beraniMemori 1GB di setiap iterasi ...