Saya sudah lama tahu tentang situs Have I Been Pwned (HIBP) . Benar, sampai saat ini, dia belum pernah ke sana. Saya selalu punya dua kata sandi. Salah satu dari mereka berulang kali digunakan untuk sampah dan beberapa akun di situs asing. Tetapi saya harus menolaknya, karena surat itu diretas. Dan jujur saja, saya berterima kasih kepada hacker karena acara ini membuat saya meninjau kata sandi saya - cara saya menggunakan dan menyimpannya.Tentu saja, saya mengubah kata sandi pada semua akun di mana ada kata sandi yang dikompromikan. Lalu saya bertanya-tanya apakah kata sandi yang bocor ada di database HIBP. Saya tidak ingin memasukkan kata sandi di situs, jadi saya mengunduh database (pwned-passwords-sha1-ordered-by-count-v5) Basisnya sangat mengesankan. Ini adalah file teks 22,8 GB dengan satu set hash SHA-1, satu di setiap baris dengan penghitung, berapa kali kata sandi dengan hash ini terjadi dalam kebocoran. Saya menemukan SHA-1 dari kata sandi saya yang retak dan mencoba menemukannya.Isi
[G] rep
Kami memiliki file teks dengan hash di setiap baris. Mungkin tempat terbaik untuk pergi adalah grep.grep -m 1 '^XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' pwned-passwords-sha1-ordered-by-count-v5.txtKata sandi saya ada di bagian atas daftar dengan frekuensi lebih dari 1.500 kali, jadi sangat menyebalkan. Dengan demikian, hasil pencarian kembali hampir secara instan.Tetapi tidak semua orang memiliki kata sandi yang lemah. Saya ingin memeriksa berapa lama untuk menemukan skenario terburuk - hash terakhir dalam file:time grep -m 1 '^4541A1E4605EEBF3F4C166329C18502DF75D348A' pwned-passwords-sha1-ordered-by-count-v5.txtHasil: 33,35s user 23,39s system 41% cpu 2:15,35 totalIni menyedihkan. Lagi pula, karena surel saya diretas, saya ingin memeriksa keberadaan semua kata sandi lama dan baru saya di basis data. Tapi grep dua menit tidak memungkinkan Anda melakukan ini dengan nyaman. Tentu saja, saya bisa menulis naskah, menjalankannya dan berjalan-jalan, tetapi ini bukan pilihan. Saya ingin mencari solusi yang lebih baik dan belajar sesuatu.Struktur trie
Gagasan pertama adalah menggunakan struktur data trie. Struktur ini tampaknya ideal untuk menyimpan hash SHA-1. Alfabetnya kecil, jadi simpulnya juga kecil, seperti halnya file yang dihasilkan. Mungkin bahkan pas di RAM? Pencarian kunci harus sangat cepat.Jadi saya menerapkan struktur ini. Kemudian ia mengambil 1.000.000 hash pertama dari database sumber untuk membangun file yang dihasilkan dan memeriksa apakah semuanya ada dalam file yang dibuat.Ya, saya bisa menemukan semuanya di dalam file, jadi strukturnya bekerja dengan baik. Masalahnya berbeda.File yang dihasilkan dirilis dalam ukuran 2283686592B (2,2 GB). Ini tidak bagus. Mari kita hitung dan lihat apa yang terjadi. Node adalah struktur sederhana dengan nilai 16-bit. Nilai adalah "pointer" ke node berikut dengan simbol hash SHA-1 yang ditentukan. Jadi, satu simpul membutuhkan 16 * 4 byte = 64 byte. Sepertinya sedikit? Tetapi jika Anda memikirkannya, satu simpul mewakili satu karakter dalam hash. Jadi, dalam kasus terburuk, hash SHA-1 akan mengambil 40 * 64 byte = 2560 byte. Ini jauh lebih buruk daripada, misalnya, representasi tekstual hash yang hanya memakan 40 byte.Struktur trie memiliki keuntungan menggunakan kembali node. Jika Anda memiliki dua kata aaadan abb, maka simpul untuk karakter pertama digunakan kembali, karena karakternya sama - a.Mari kita kembali ke masalah kita. Mari kita hitung berapa banyak node yang disimpan dalam file yang dihasilkan: file_size / node_size = 2283686592 / 64 = 35682603Sekarang mari kita lihat berapa banyak node yang akan dibuat dalam case terburuk dari sejuta hashes: 1000000 * 40 = 40000000Jadi, struktur trie hanya menggunakan kembali 40000000 - 35682603 = 4317397node, yang merupakan 10,8% dari skenario terburuk.Dengan indikator tersebut, file yang dihasilkan untuk seluruh basis data HIBP akan mengambil 1421513361920 byte (1,02 TB). Saya bahkan tidak punya cukup hard drive untuk memeriksa kecepatan pencarian kunci.Hari itu, saya menemukan bahwa struktur trie tidak cocok untuk data yang relatif acak.Mari kita cari solusi lain.Pencarian biner
Hash SHA-1 memiliki dua fitur bagus: mereka sebanding satu sama lain dan mereka semua memiliki ukuran yang sama.Berkat ini, kami dapat memproses database HIBP asli dan membuat file dari nilai SHA-1 yang diurutkan.Tetapi bagaimana cara mengurutkan file 22 GB?Pertanyaan. Mengapa mengurutkan file sumber? HIBP mengembalikan file dengan string yang sudah diurutkan berdasarkan hash.
Menjawab. Saya hanya tidak memikirkannya. Pada saat itu saya tidak tahu tentang file yang diurutkan.Penyortiran
Menyortir semua hash dalam RAM bukan pilihan, saya tidak punya banyak RAM. Solusinya adalah ini:- Pisahkan file besar menjadi lebih kecil yang sesuai dengan RAM.
- Unduh data dari file kecil, ketik RAM dan tulis kembali ke file.
- Gabungkan semua file kecil yang diurutkan menjadi satu besar.
Dengan file besar yang diurutkan, Anda dapat mencari hash kami menggunakan pencarian biner. Masalah akses hard drive. Mari kita hitung berapa banyak klik yang diperlukan dalam pencarian biner: log2(555278657) = 29.0486367039yaitu, 30 hit. Tidak begitu buruk.Pada tahap pertama, optimasi dapat dilakukan. Konversi hash teks ke data biner. Ini akan mengurangi ukuran data yang dihasilkan setengah: dari 22 hingga 11 GB. Baik.Mengapa bergabung kembali?
Pada saat itu, saya menyadari bahwa Anda dapat melakukannya dengan lebih cerdas. Bagaimana jika Anda tidak menggabungkan file kecil menjadi satu besar, tetapi melakukan pencarian biner dalam file kecil yang diurutkan dalam RAM? Masalahnya adalah bagaimana menemukan file yang diinginkan untuk mencari kunci. Solusinya sangat sederhana. Pendekatan baru:- Buat 256 file dengan nama "00" ... "FF".
- Saat membaca hash dari file besar, tulis hash yang dimulai dengan "00 .." ke file bernama "00", hash yang dimulai dengan "01 .." - ke file "01" dan seterusnya.
- Unduh data dari file kecil, ketik RAM dan tulis kembali ke file.
Semuanya sangat sederhana. Selain itu, opsi pengoptimalan lain muncul. Jika hash disimpan dalam file "00", maka kita tahu bahwa itu dimulai dengan "00". Jika hash disimpan dalam file "F2", maka dimulai dengan "F2". Jadi, ketika menulis hash ke file kecil, kita bisa menghilangkan byte pertama dari setiap hash! Ini adalah 5% dari semua data. 555 MB disimpan secara total.Paralelisme
Pemisahan menjadi file yang lebih kecil memberikan peluang lain untuk optimisasi. File tidak tergantung satu sama lain, sehingga kita dapat mengurutkannya secara paralel. Kami ingat bahwa semua prosesor Anda suka berkeringat pada saat yang sama;)Jangan menjadi bajingan egois
Ketika saya menerapkan solusi di atas, saya menyadari bahwa orang lain mungkin memiliki masalah yang sama. Mungkin banyak orang lain juga mengunduh dan mencari basis data HIBP. Jadi saya memutuskan untuk membagikan pekerjaan saya.Sebelum itu, saya sekali lagi merevisi pendekatan saya dan menemukan beberapa masalah yang ingin saya perbaiki sebelum memposting kode dan alat di Github.Pertama, sebagai pengguna akhir, saya tidak ingin menggunakan alat yang membuat banyak file aneh dengan nama-nama aneh, di mana tidak jelas apa yang disimpan, dll.Nah, ini bisa diselesaikan dengan menggabungkan file "00" .. "FF" di satu file besar.Sayangnya, memiliki satu file besar untuk disortir menimbulkan masalah baru. Bagaimana jika saya ingin memasukkan hash dalam file ini? Hanya satu hash. Ini hanya 20 byte. Oh, hash dimulai dengan "000000000 ..". Baik. Mari kosongkan ruang untuk itu dengan memindahkan 11 GB hash lainnya ...Anda mengerti apa masalahnya. Memasukkan data di tengah file bukan operasi tercepat.Kelemahan lain dari pendekatan ini adalah bahwa Anda perlu menyimpan byte pertama lagi - itu adalah 555 MB data.Dan yang tak kalah pentingnya, pencarian biner pada data yang tersimpan di hard drive Anda jauh lebih lambat daripada mengakses RAM. Maksud saya, ini adalah 30 disk membaca versus 0 disk membaca.B3
Lagi. Apa yang kita miliki dan apa yang ingin kita raih.Kami memiliki nilai biner 11 GB. Semua nilai sebanding dan memiliki ukuran yang sama. Kami ingin mengetahui apakah ada kunci tertentu dalam data yang disimpan, dan juga ingin mengubah database. Dan agar semuanya bekerja dengan cepat.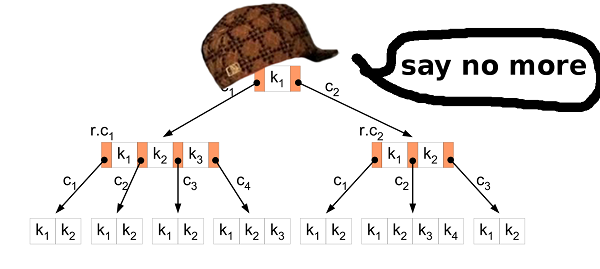 Pohon-B? BaikB-tree memungkinkan Anda meminimalkan akses ke disk saat mencari, memodifikasi, dll. B-tree memiliki lebih banyak fitur, tetapi kami membutuhkan keduanya.
Pohon-B? BaikB-tree memungkinkan Anda meminimalkan akses ke disk saat mencari, memodifikasi, dll. B-tree memiliki lebih banyak fitur, tetapi kami membutuhkan keduanya.Penyisipan Sortir
Langkah pertama adalah mengubah data dari file sumber HIBP ke B-tree. Ini berarti Anda perlu mengekstrak semua hash secara bergantian dan memasukkannya ke dalam struktur. Algoritma penyisipan yang biasa cocok untuk ini. Tetapi dalam kasus kami, Anda dapat melakukan yang lebih baik.Memasukkan banyak data mentah ke dalam B-tree adalah skenario yang terkenal. Orang bijak telah menemukan pendekatan yang lebih baik untuk ini daripada insert biasa. Pertama-tama, Anda perlu mengurutkan data. Ini dapat dilakukan seperti dijelaskan di atas (pisahkan file menjadi lebih kecil dan urutkan dalam RAM). Kemudian masukkan data ke dalam pohon.Dalam algoritma biasa, jika Anda menemukan simpul daun di mana Anda ingin memasukkan nilai dan itu diisi, maka Anda membuat simpul baru (di sebelah kanan) dan mendistribusikan nilai secara merata antara dua simpul, kiri dan kanan (ditambah satu nilai pergi ke simpul induk tapi itu tidak penting di sini). Singkatnya, nilai-nilai di simpul kiri selalu kurang dari nilai-nilai di sebelah kanan. Faktanya adalah bahwa ketika Anda memasukkan data yang diurutkan, Anda tahu bahwa nilai yang lebih kecil tidak akan lagi dimasukkan ke dalam pohon, jadi tidak ada lagi nilai yang akan pergi ke simpul kiri. Node kiri tetap setengah kosong sepanjang waktu. Selain itu, jika Anda memasukkan nilai yang cukup, Anda mungkin menemukan bahwa simpul kanan penuh, jadi Anda perlu memindahkan setengah nilai ke simpul kanan baru. Split node tetap setengah kosong, seperti pada kasus sebelumnya. Dll…Akibatnya, setelah semua sisipan, Anda mendapatkan pohon di mana hampir semua node setengah kosong. Ini bukan penggunaan ruang yang sangat efisien. Kita bisa melakukan yang lebih baik.Terpisah atau tidak?
Dalam hal memasukkan data yang diurutkan, Anda dapat membuat sedikit modifikasi pada algoritma penyisipan. Jika simpul tempat Anda ingin menempelkan nilai sudah penuh, jangan pecahkan. Cukup buat simpul baru yang kosong dan tempel nilai ke simpul induk. Kemudian, ketika Anda memasukkan nilai-nilai berikut (yang lebih besar dari yang sebelumnya), Anda memasukkannya ke dalam simpul kosong yang baru.Untuk mempertahankan sifat-sifat B-tree, setelah semua penyisipan, perlu untuk memilah node paling kanan di setiap lapisan pohon (kecuali root) dan membagi nilai-nilai node ekstrim ini dan tetangga kirinya secara merata. Jadi Anda mendapatkan pohon sekecil mungkin.Properti Pohon HIBP
Saat mendesain B-tree, Anda harus memilih urutannya. Ini menunjukkan berapa banyak nilai yang dapat disimpan dalam satu simpul, serta berapa banyak anak yang dimiliki simpul tersebut. Dengan memanipulasi parameter ini, kita dapat memanipulasi ketinggian pohon, ukuran biner dari simpul, dll.Dalam HIBP, kita memiliki 555278657hash. Misalkan kita menginginkan pohon dengan tinggi tiga (jadi kita tidak perlu lebih dari tiga operasi baca untuk memeriksa keberadaan hash). Kita perlu menemukan nilai M sedemikian rupa logM(555278657) < 3. Saya memilih 1024. Ini bukan nilai terkecil yang mungkin, tetapi memungkinkan untuk memasukkan lebih banyak hash dan mempertahankan ketinggian pohon.Berkas keluaran
File sumber HIBP memiliki ukuran 22,8 GB. File output dengan B-tree adalah 12,4 GB. Butuh sekitar 11 menit untuk membuatnya di komputer saya (Intel Core i7-6700, 3,4 GHz, 16 GB RAM), hard disk (bukan SSD).Tolak ukur
Opsi B-tree menunjukkan hasil yang cukup bagus:| | waktu [μs] | % |
| -----------------: | ------------: | ------------: |
| okon | 49 | 100 |
| grep '^ hash' | 135'350'000 | 276'224'489 |
| grep | 135'480'000 | 276'489'795 |
| C ++ baris demi baris | 135'720'201 | 276'980'002 |
okon - perpustakaan dan CLI
Seperti yang saya katakan, saya ingin berbagi pekerjaan saya dengan dunia. Saya menerapkan pustaka dan antarmuka baris perintah untuk memproses database HIBP dan dengan cepat mencari hash. Pencarian sangat cepat sehingga dapat, misalnya, diintegrasikan ke dalam pengelola kata sandi dan memberikan umpan balik kepada pengguna setiap kali tombol ditekan. Ada banyak kegunaan yang mungkin.Perpustakaan memiliki antarmuka C, sehingga dapat digunakan hampir di mana-mana. CLI adalah CLI. Anda cukup membangun dan menjalankan (:Kode ada di repositori saya .Penafian: okon belum menyediakan antarmuka untuk memasukkan nilai ke dalam B-tree yang dibuat. Itu hanya dapat memproses file HIBP, membuat B-tree dan mencari di dalamnya. Fungsi-fungsi ini bekerja dengan sangat baik, jadi saya memutuskan untuk membagikan kode dan terus mengerjakan penyisipan dan fungsi-fungsi lain yang mungkin.Tautan dan diskusi
Terima kasih sudah membaca
(: