 Halo semuanya!Terlibat dalam pengujian kinerja. Dan saya sangat suka mengatur pemantauan dan menikmati metrik di Grafana . Dan standar untuk menyimpan metrik pada alat beban adalah InfluxDB . Di InfluxDB, Anda dapat menyimpan metrik dari alat populer seperti:Bekerja dengan alat pengujian kinerja dan metrik mereka, saya telah mengumpulkan pilihan resep pemrograman untuk bundel Grafana dan InfluxDB . Saya mengusulkan untuk mempertimbangkan masalah menarik yang muncul ketika ada metrik dengan dua atau lebih tag. Saya pikir ini tidak biasa. Dan dalam kasus umum, tugas terdengar seperti ini: menghitung metrik total untuk grup, yang dibagi menjadi beberapa subkelompok .
Halo semuanya!Terlibat dalam pengujian kinerja. Dan saya sangat suka mengatur pemantauan dan menikmati metrik di Grafana . Dan standar untuk menyimpan metrik pada alat beban adalah InfluxDB . Di InfluxDB, Anda dapat menyimpan metrik dari alat populer seperti:Bekerja dengan alat pengujian kinerja dan metrik mereka, saya telah mengumpulkan pilihan resep pemrograman untuk bundel Grafana dan InfluxDB . Saya mengusulkan untuk mempertimbangkan masalah menarik yang muncul ketika ada metrik dengan dua atau lebih tag. Saya pikir ini tidak biasa. Dan dalam kasus umum, tugas terdengar seperti ini: menghitung metrik total untuk grup, yang dibagi menjadi beberapa subkelompok .Ada tiga opsi:
- Jumlah yang dikelompokkan berdasarkan Jenis tag
- Grafana-way. Kami menggunakan setumpuk nilai
- Jumlah tertinggi dengan subquery
Bagaimana semua ini dimulai
Pemantauan JVM MBean yang dikonfigurasi menggunakan Jolokia , Telegraf , InfluxDB dan Grafana . Dan dia memvisualisasikan metrik pada kumpulan memori - berapa banyak memori yang dialokasikan oleh masing-masing kumpulan memori di HEAP dan seterusnya.Bagan pada kolam memori JVM dan aktivitas pemulung dari 13:00 hari sebelumnya hingga 01:00 malam hari saat ini (periode 12 jam). Di sini Anda dapat melihat bahwa kumpulan memori dibagi menjadi dua kelompok: HEAP dan NON_HEAP . Dan bahwa sekitar pukul 17.00 ada pengumpulan sampah, setelah itu ukuran kolam memori menurun: Untuk metrik mengumpulkan pada kolam memori, saya ditentukan pengaturan berikut di Telegraf file konfigurasi : telegraf.conf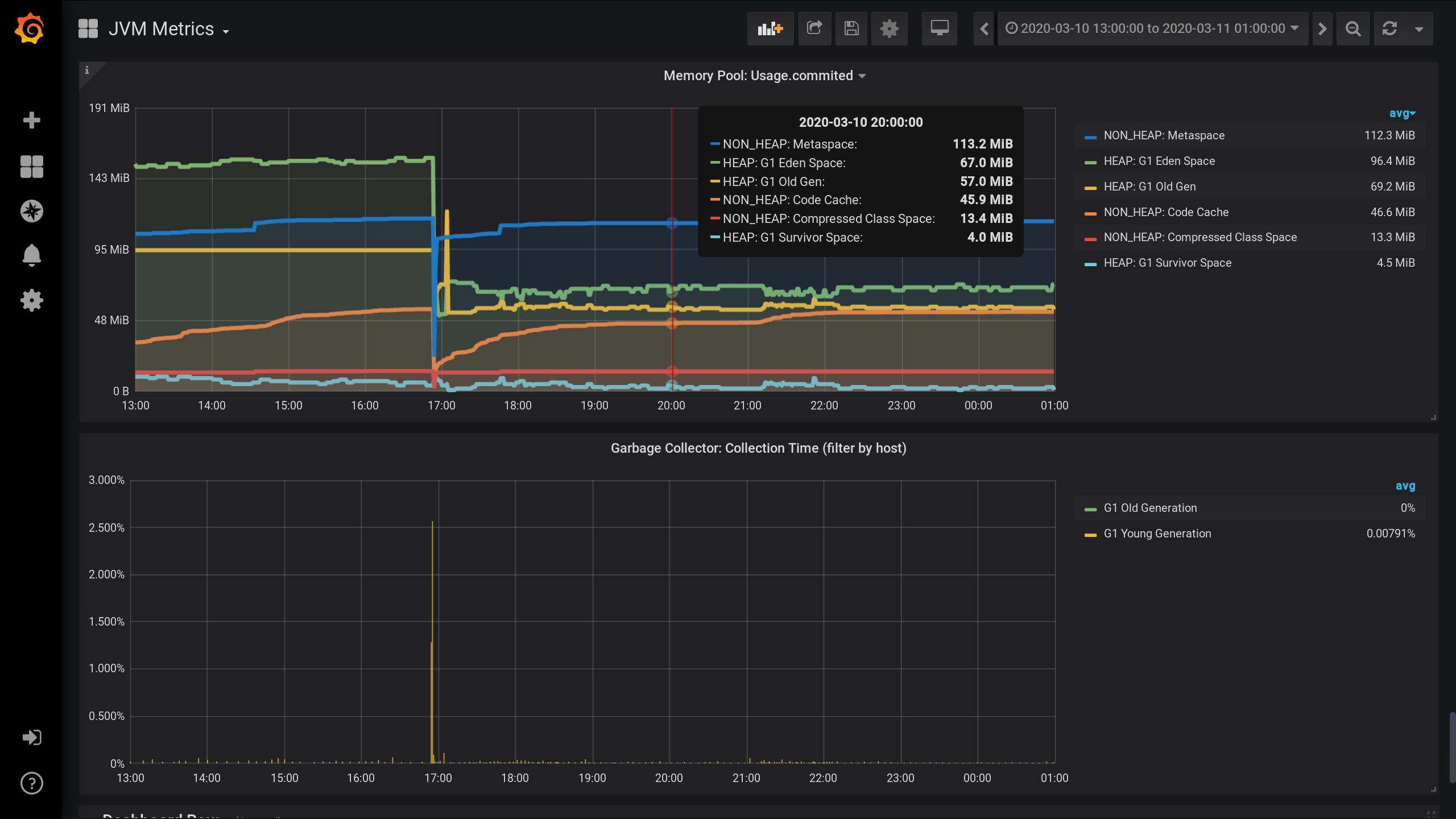
[outputs.influxdb]
urls = ["http://influxdb_server:8086"]
database = "telegraf"
username = "login-InfluxDb"
password = "*****"
retention_policy = "month"
influx_uint_support = false
[agent]
collection_jitter = "2s"
interval = "2s"
precision = "s"
[[inputs.jolokia2_agent]]
username = "login-Jolokia"
password = "*****"
urls = ["http://127.0.0.1:7777/jvm-service"]
[[inputs.jolokia2_agent.metric]]
paths = ["Usage","PeakUsage","CollectionUsage","Type"]
name = "java_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
tag_keys = ["name"]
[[processors.converter]]
[processors.converter.fields]
integer = ["CollectionUsage.*", "PeakUsage.*", "Usage.*"]
tag = ["Type"]
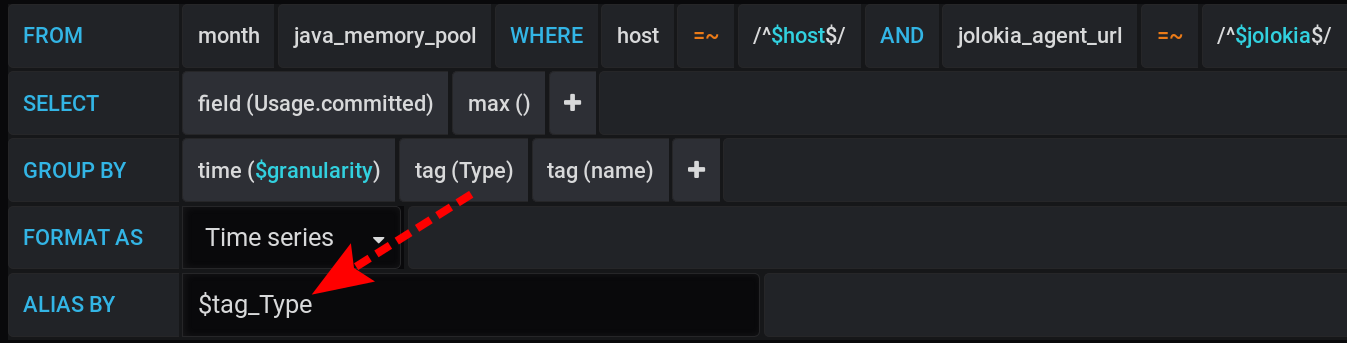
Dan di Grafana, saya membuat kueri untuk InfluxDB untuk menampilkan dalam grafik nilai metrik maksimum Usage.Committeduntuk periode waktu dengan langkah $granularity(1m) dan dikelompokkan berdasarkan dua tag Type(HEAP atau NON_HEAP) dan name(Metaspace, G1 Gen Lama, ...): Kueri yang sama dalam bentuk teks, dengan mempertimbangkan semua variabel Grafana (perhatikan untuk menghindari nilai variabel - ini penting agar kueri berfungsi dengan benar):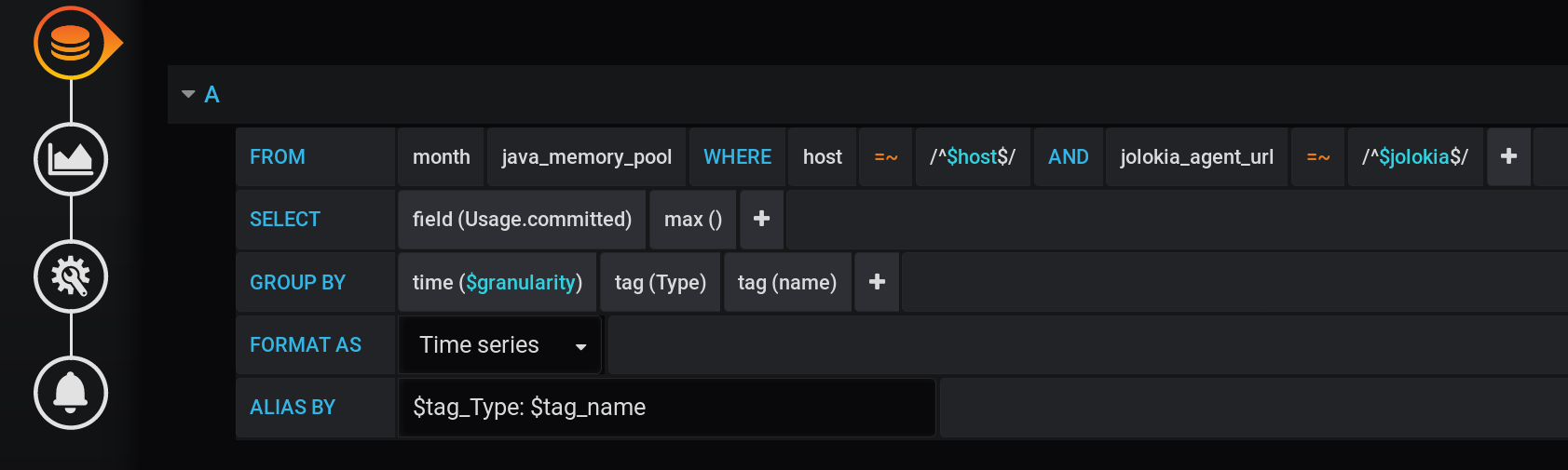
:regexSELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type", "name", time($granularity)
Kueri yang sama dalam bentuk teks, dengan mempertimbangkan nilai spesifik variabel Grafana :SELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^serverName$/ AND
jolokia_agent_url =~ /^http:\/\/127\.0\.0\.1:7777\/jvm-service$/ AND
time >= 1583834400000ms and time <= 1583877600000ms
GROUP BY
"Type", "name", time(1m)
Pengelompokan berdasarkan waktu GROUP BY time($granularity)atau GROUP BY time(1m)digunakan untuk mengurangi jumlah poin pada grafik. Untuk jangka waktu 12 jam dan langkah pengelompokan 1 menit, kita mendapatkan: 12 x 60 = 720 kali atau 721 poin (titik terakhir dengan nilai nol).Ingat bahwa 721 adalah jumlah titik yang diharapkan dalam menanggapi permintaan InfluxDB dengan pengaturan saat ini untuk interval waktu (12 jam) dan langkah pengelompokan (1 menit).
NON_HEAP kumpulan
memori : Metaspace (biru) memimpin dalam konsumsi memori pada pukul 20:00. Dan menurut HEAP: G1 Old Gen (kuning) ada lonjakan lokal kecil di 17:03. Dan pada saat 20:00, secara total, semua NON_HEAP pool tersisa 172,5 MiB (113,2 + 45,9 + 13,4), dan HEAP kolam 128 MiB (67 + 57 + 4).
Ingat nilai-nilai untuk 20:00: NON_HEAP kolam 172,5 MiB , dan HEAP kolam 128 MiB . Kami akan fokus pada nilai-nilai ini di masa depan.
Dalam konteks Tipe : nama , kami memperoleh nilai metrik dengan mudah.Dalam konteks hanya tag nama , nilai metrik juga mudah diperoleh, karena semua nama kumpulan memori unik, dan cukup untuk membiarkan pengelompokan hasil hanya berdasarkan nama .Pertanyaannya tetap: bagaimana cara mendapatkan ukuran apa yang dialokasikan untuk semua kelompok HEAP dan semua kelompok NON_HEAP secara total?
1. Jumlah yang dikelompokkan berdasarkan Jenis tag
1.1. Jumlah yang dikelompokkan berdasarkan tag
Solusi pertama yang mungkin terlintas dalam pikiran adalah mengelompokkan nilai-nilai dengan tag Jenis dan menghitung jumlah nilai-nilai dalam setiap kelompok. Kueri seperti itu akan terlihat seperti ini: Representasi tekstual dari permintaan penghitungan penjumlahan dikelompokkan berdasarkan Jenis tag dengan semua variabel Grafana :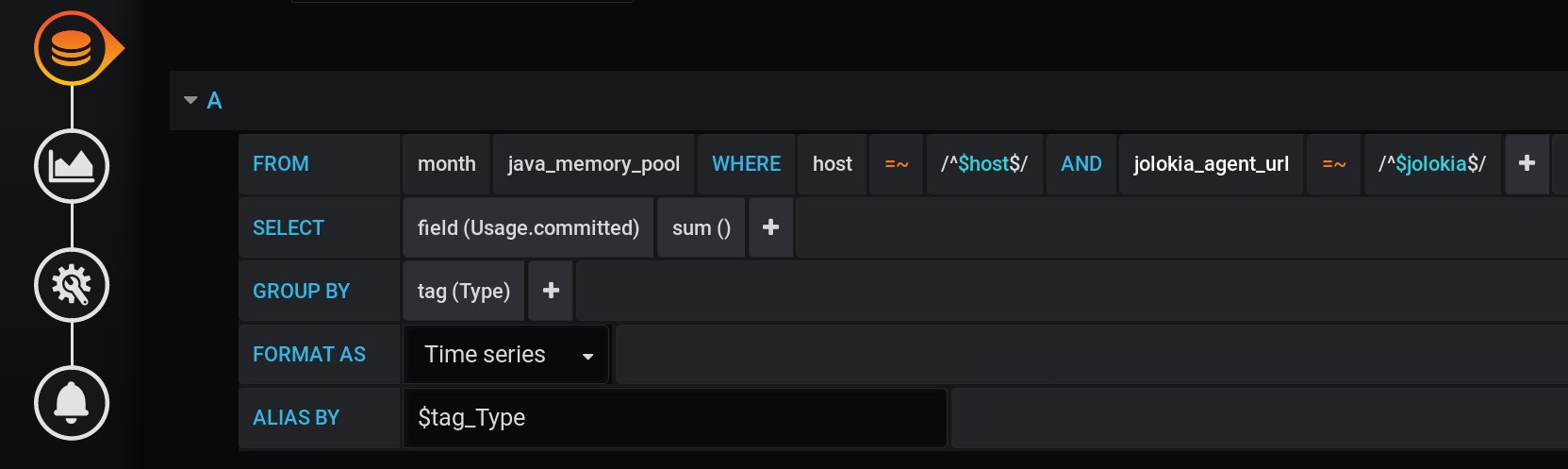
SELECT sum("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type"
Ini adalah kueri yang valid, tetapi hanya akan mengembalikan dua poin: jumlahnya akan dihitung dengan pengelompokan hanya dengan tag Jenis dengan dua nilai (HEAP dan NON_HEAP). Kami bahkan tidak akan melihat jadwal. Akan ada dua poin yang berdiri sendiri dengan nilai dalam jumlah besar (lebih dari 3 TiB): Jumlah seperti itu tidak cocok, diperlukan penguraian dalam interval waktu.
1.2. Jumlah yang dikelompokkan berdasarkan tag per menit
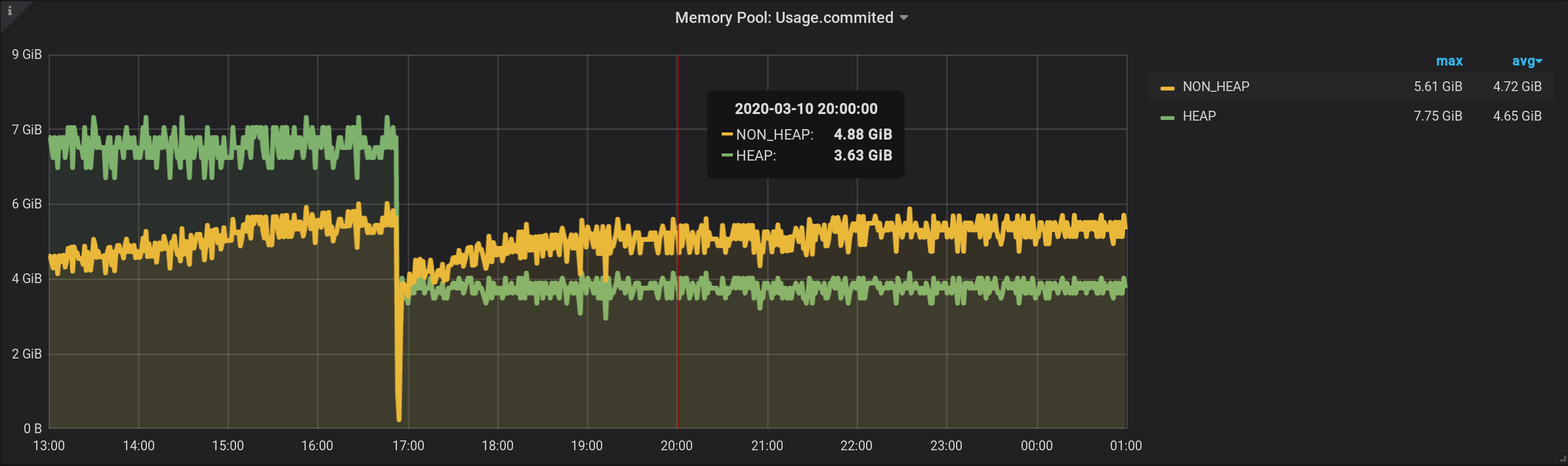
Dalam kueri asli, kami mengelompokkan metrik berdasarkan interval $ granularity khusus . Mari lakukan pengelompokan sekarang dengan interval khusus.Kueri ini akan berubah, tambahnya GROUP BY time($granularity): Kami mendapatkan nilai yang meningkat, alih-alih 172,5 MiB oleh NON_HEAP kita melihat 4,88 GiB: Karena metrik dikirim ke InfluxDB setiap 2 detik sekali (lihat telegraf.conf di atas), jumlah bacaan dalam satu menit tidak akan memberikan jumlah pada saat ini, dan jumlah dari tiga puluh jumlah tersebut. Kami tidak dapat membagi hasilnya dengan konstanta 30 . Karena $ granularity adalah parameter, ia dapat disetel menjadi 1 menit dan 10 menit. Dan nilai jumlahnya akan berubah.
1.3. Tag dikelompokkan per detik
Untuk mendapatkan nilai metrik dengan benar untuk intensitas pengumpulan metrik saat ini (2 detik), Anda perlu menghitung jumlah untuk interval tetap yang tidak melebihi intensitas pengumpulan metrik.Mari kita coba menampilkan statistik dengan pengelompokan dalam hitungan detik. Tambahkan ke GROUP BYpengelompokan time(1s): Dengan granularity kecil seperti itu, kami mendapatkan sejumlah besar poin untuk interval waktu kami 12 jam (12 jam * 60 menit * 60 detik = interval 43.200, 43.201 poin per baris, yang terakhir adalah nol): 43.201 poin di setiap baris grafik. Ada banyak poin sehingga InfluxDB akan membentuk respons untuk waktu yang lama, Grafana akan mengambil respons lebih lama, dan kemudian browser akan menarik sejumlah besar poin untuk waktu yang lama.
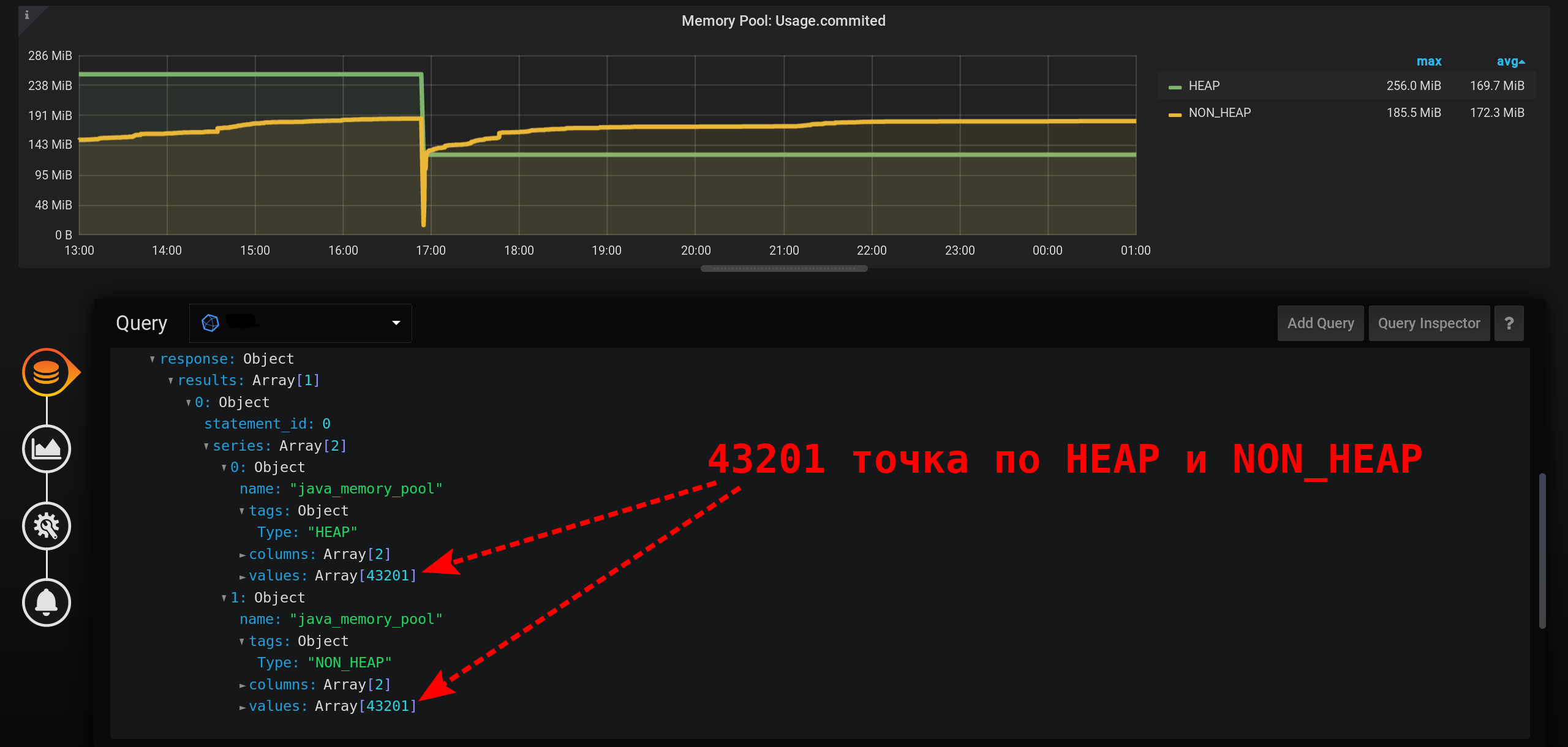 Dan tidak dalam setiap detik ada poin: metrik dikumpulkan setiap 2 detik, dan pengelompokan setiap detik, yang berarti bahwa setiap titik kedua akan menjadi nol. Untuk melihat garis yang halus, konfigurasikan koneksi nilai yang tidak kosong. Kalau tidak, kita tidak akan melihat grafik: Sebelumnya, Grafana sedemikian rupa sehingga browser tergantung selama menggambar sejumlah besar poin. Sekarang versi Grafana memiliki kemampuan untuk menggambar beberapa puluh ribu poin: browser cukup melompati beberapa dari mereka, menggambar grafik menggunakan data yang diencerkan. Tetapi grafik diperhalus. Tertinggi ditampilkan sebagai tertinggi rata-rata.
Dan tidak dalam setiap detik ada poin: metrik dikumpulkan setiap 2 detik, dan pengelompokan setiap detik, yang berarti bahwa setiap titik kedua akan menjadi nol. Untuk melihat garis yang halus, konfigurasikan koneksi nilai yang tidak kosong. Kalau tidak, kita tidak akan melihat grafik: Sebelumnya, Grafana sedemikian rupa sehingga browser tergantung selama menggambar sejumlah besar poin. Sekarang versi Grafana memiliki kemampuan untuk menggambar beberapa puluh ribu poin: browser cukup melompati beberapa dari mereka, menggambar grafik menggunakan data yang diencerkan. Tetapi grafik diperhalus. Tertinggi ditampilkan sebagai tertinggi rata-rata. Akibatnya, ada grafik, ditampilkan secara akurat, metrik pada pukul 20:00 dihitung dengan benar, metrik dalam legenda grafik dihitung dengan benar. Tapi grafiknya halus: semburan tidak terlihat di atasnya dengan akurasi 1 detik. Secara khusus, lonjakan HEAP pada 17:03 menghilang dari grafik, grafik HEAP sangat halus: minus dalam kinerja jelas akan memanifestasikan dirinya dalam interval waktu yang lebih lama. Jika Anda mencoba membuat grafik dalam sebulan (720 jam), dan tidak dalam 12 jam, maka semuanya akan membeku dengan rincian kecil (1 detik), akan ada terlalu banyak poin. Dan ada minus dengan tidak adanya puncak, paradoks - karena akurasi yang tinggi dalam mendapatkan metrik, kami mendapatkan akurasi rendah dari tampilan mereka .
Akibatnya, ada grafik, ditampilkan secara akurat, metrik pada pukul 20:00 dihitung dengan benar, metrik dalam legenda grafik dihitung dengan benar. Tapi grafiknya halus: semburan tidak terlihat di atasnya dengan akurasi 1 detik. Secara khusus, lonjakan HEAP pada 17:03 menghilang dari grafik, grafik HEAP sangat halus: minus dalam kinerja jelas akan memanifestasikan dirinya dalam interval waktu yang lebih lama. Jika Anda mencoba membuat grafik dalam sebulan (720 jam), dan tidak dalam 12 jam, maka semuanya akan membeku dengan rincian kecil (1 detik), akan ada terlalu banyak poin. Dan ada minus dengan tidak adanya puncak, paradoks - karena akurasi yang tinggi dalam mendapatkan metrik, kami mendapatkan akurasi rendah dari tampilan mereka .
2. Cara Grafana. Kami menggunakan setumpuk nilai
Itu tidak mungkin untuk membuat solusi sederhana dan efisien dengan InfluxDB dan desainer permintaan Grafana . Kami hanya akan mencoba menggunakan alat Grafana untuk merangkum metrik yang ditampilkan dalam bagan asli. Dan ya, ini mungkin!2.1. Cukup buat Hover tooltip / Stacked value: kummulative
Kami akan membiarkan permintaan untuk memilih metrik tidak berubah, sama seperti pada bagian "Bagaimana semuanya dimulai": Metrik akan dikelompokkan berdasarkan Jenis dan nama . Tapi kami hanya akan menampilkan tag Jenis dalam nama grafik : Dan dalam pengaturan visualisasi, kami akan mengelompokkan metrik berdasarkan tumpukan Grafana : Pertama, tambahkan pemisahan dua tag menjadi dua tumpukan A dan B yang berbeda, sehingga nilainya tidak berpotongan: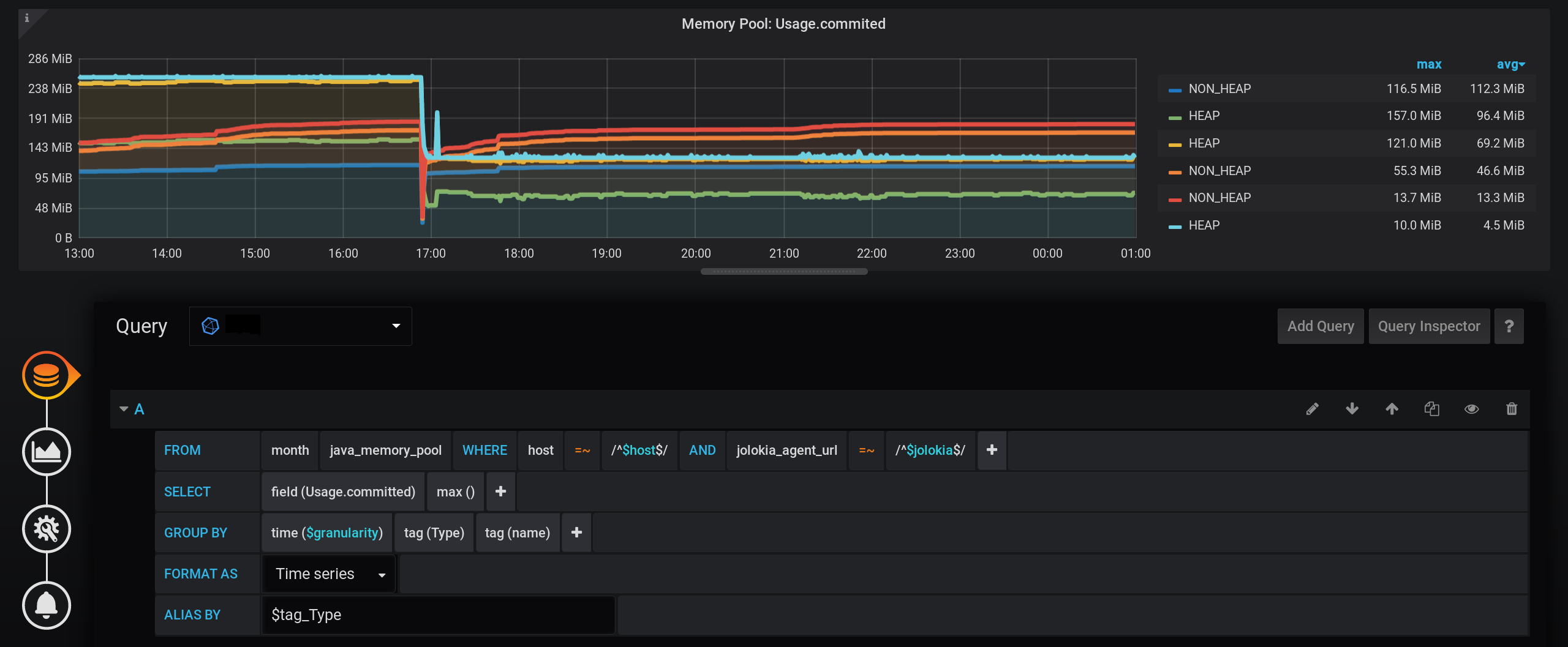
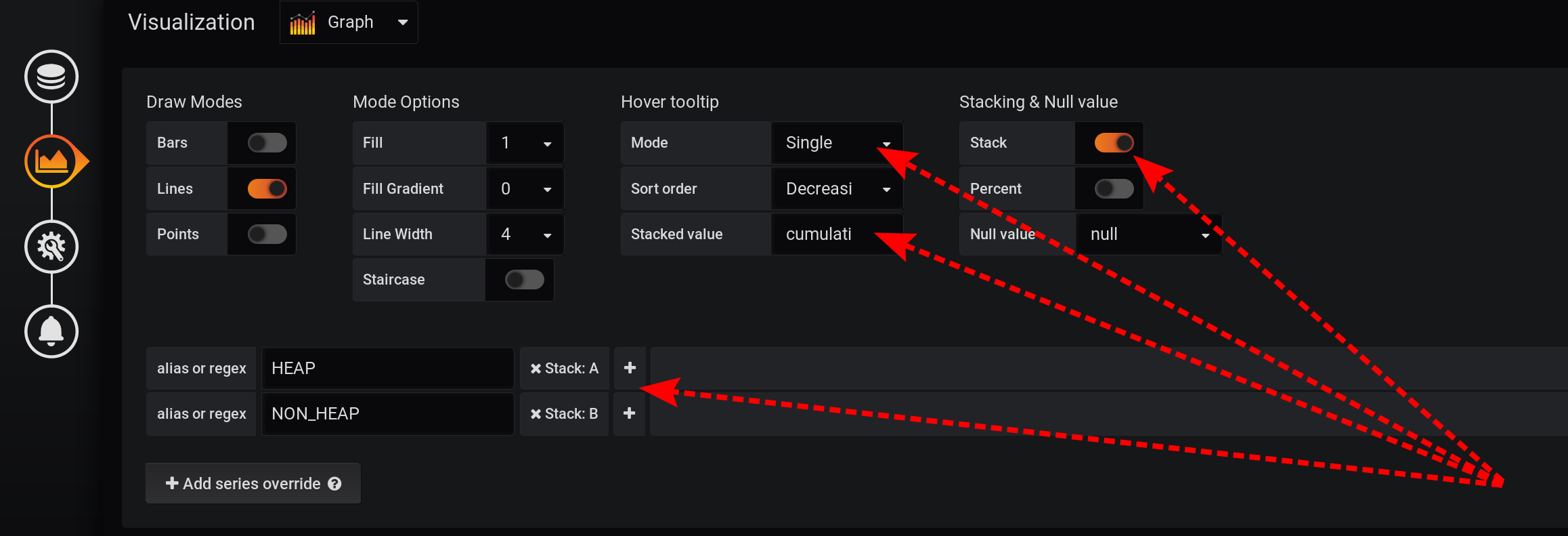
- Tambahkan seri override / HEAP / Stack : A
- Tambahkan seri override / NON_HEAP / Stack : B
Kemudian konfigurasikan visualisasi metrik untuk menampilkan nilai total dalam tooltip dengan grafik:- Stacking & Null value / Stack : On
- Arahkan tooltip / nilai tumpukan : kumulatif
- Arahkan tooltip / mode : tunggal
Karena berbagai fitur Grafana, Anda perlu melakukan tindakan dalam urutan itu. Jika Anda mengubah urutan tindakan atau meninggalkan beberapa bidang dengan pengaturan default, sesuatu tidak akan berfungsi:- Stack A B Stacking & Null value / Stack: On, ;
- Hover tooltip / Mode , Single, Hover tooltip .
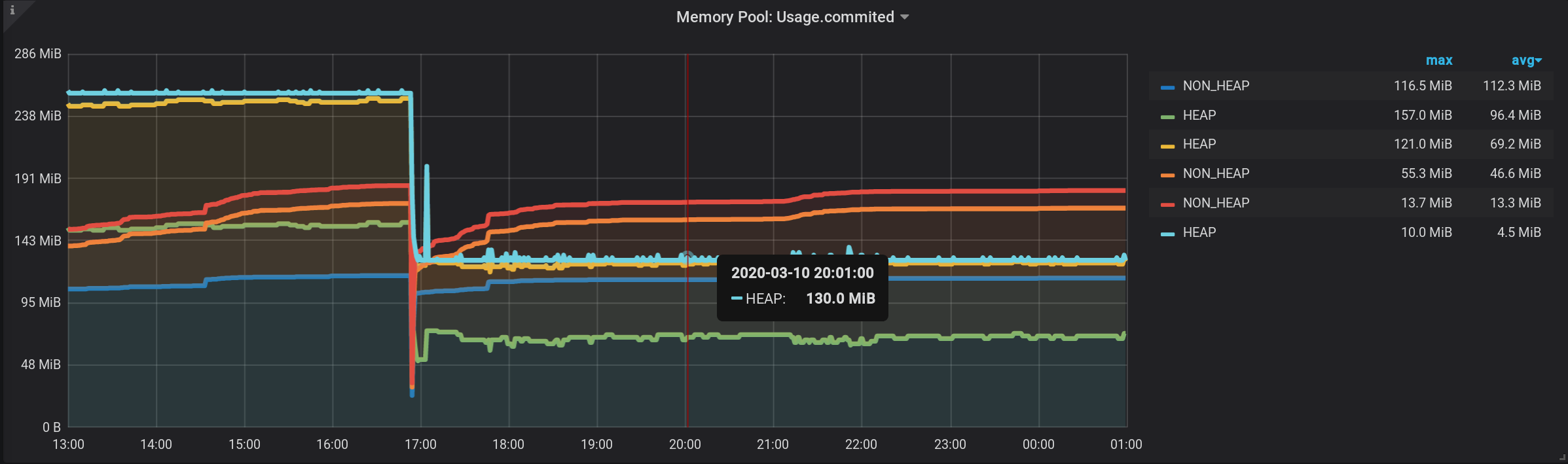
Dan sekarang, kita melihat banyak garis, seperti diri kita sendiri. Tapi! Jika Anda mengarahkan kursor ke NON_HEAP teratas , tooltip akan menampilkan jumlah nilai semua NON_HEAP . Jumlahnya dianggap benar, sudah oleh Grafana berarti : Dan jika Anda mengarahkan kursor ke grafik paling atas dengan nama HEAP , kita akan melihat jumlahnya dengan HEAP . Grafik ditampilkan dengan benar. Bahkan gelombang HEAP pada 17:03 terlihat: Secara formal, tugas selesai. Tetapi ada kontra - banyak grafik tambahan yang ditampilkan. Anda perlu mengarahkan kursor ke atas. Dan dalam legenda untuk grafik, bukan kumulatif, tetapi nilai-nilai individual ditampilkan, sehingga legenda menjadi tidak berguna.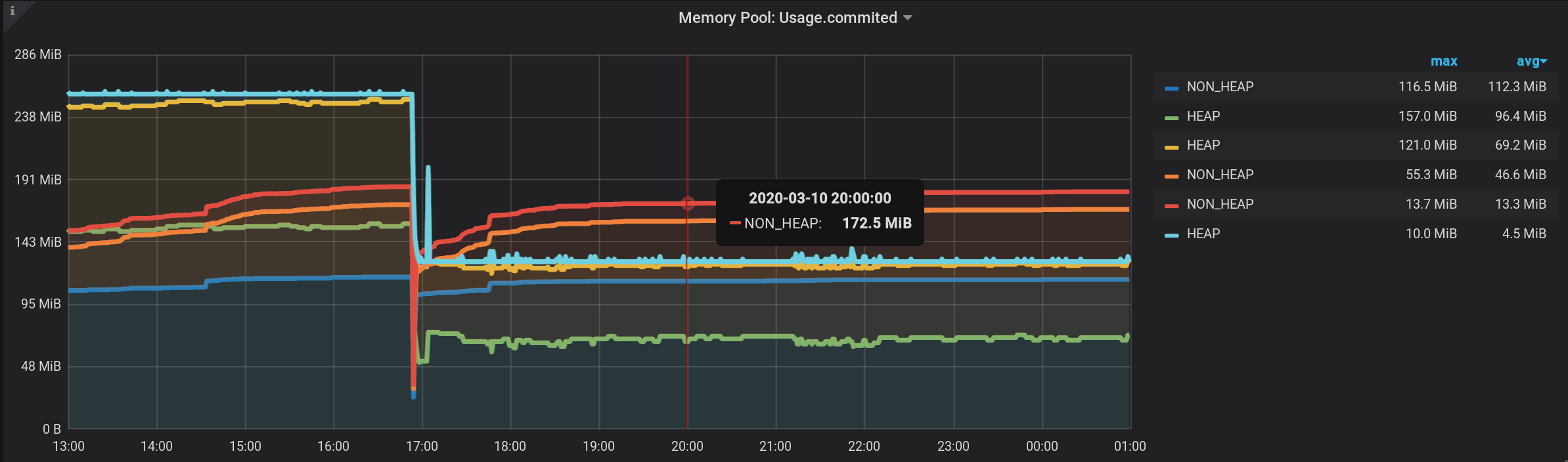
2.2. Nilai susun: kumulatif dengan menyembunyikan garis tengah
Mari kita perbaiki minus pertama dari solusi sebelumnya: pastikan bahwa grafik tambahan tidak ditampilkan.Untuk ini:- Tambahkan metrik baru dengan nama dan nilai 0 yang berbeda ke hasil.
- Tambahkan metrik baru ke Stack A dan Stack B , ke atas tumpukan.
- Sembunyikan dari tampilan - garis asli HEAP dan NON_HEAP .
Kami menambahkan dua yang baru setelah permintaan utama: permintaan B untuk menerima seri dengan nilai 0 dan nama [NON_HEAP] dan permintaan C untuk menerima seri dengan nilai 0 dan nama [HEAP] . Untuk mendapatkan 0, kami mengambil nilai pertama bidang "Usage.committed" di setiap grup waktu dan mengurangi: pertama ("Usage.committed") - pertama ("Usage.committed") - kami mendapatkan kestabilan 0. Nama-nama grafik diubah tanpa kehilangan makna karena tanda kurung: [NON_HEAP] dan [HEAP] : [HEAP] dan HEAP digabungkan menjadi Stack A , dan juga menyembunyikan semua HEAP . [NON_HEAP]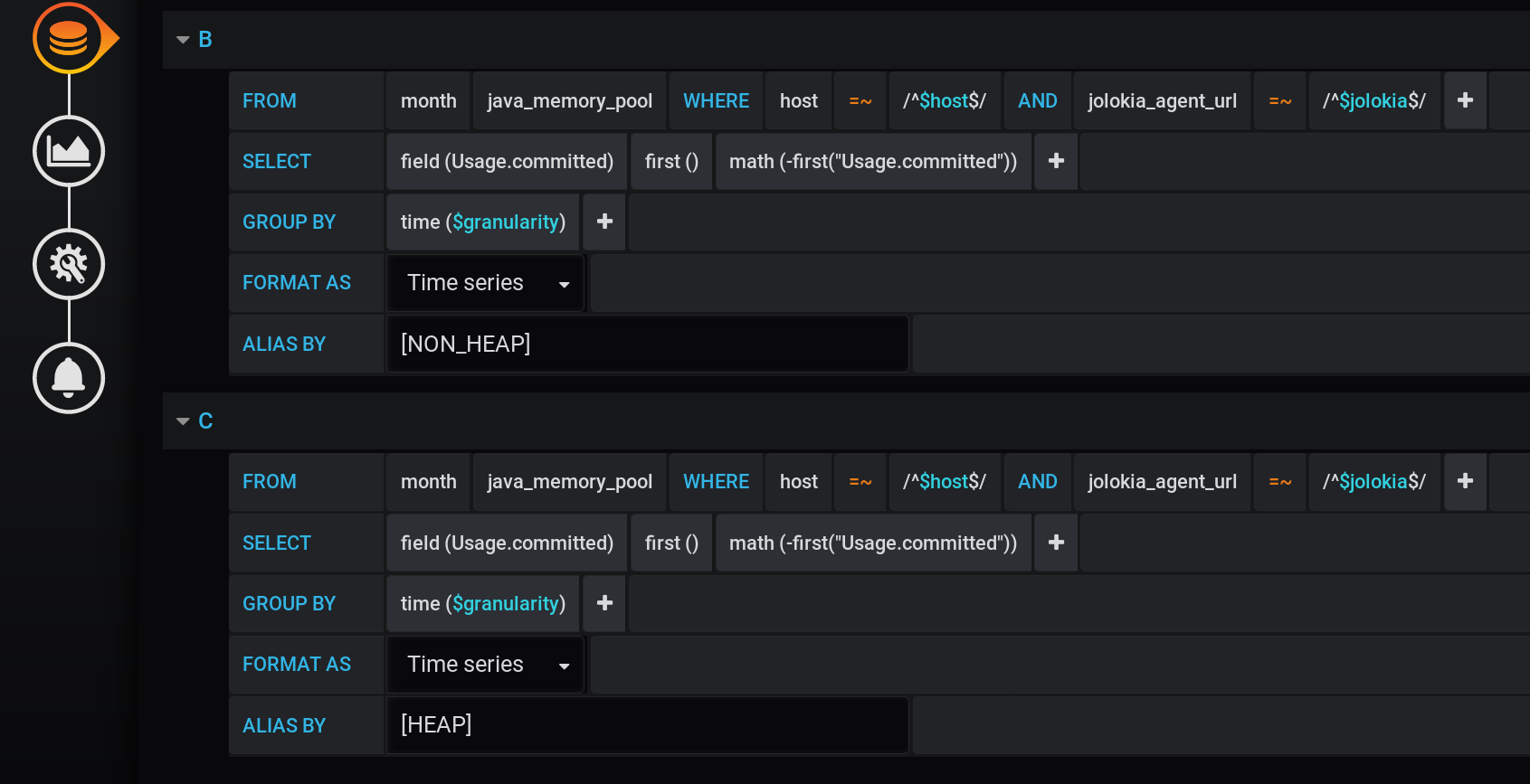 dan gabungkan NON_HEAP di Stack B dan sembunyikan NON_HEAP : Dapatkan
jumlah yang benar dengan [NON_HEAP] di Tooltip saat melayang di atas bagan: Dapatkan jumlah yang benar dengan [HEAP] di Tooltip saat melayang di atas bagan. Dan bahkan semua semburan terlihat: Dan jadwal terbentuk dengan cepat. Tapi legenda selalu menampilkan 0, legenda itu menjadi tidak berguna. Semuanya berhasil! Bypass sejati adalah melalui tumpukan Grafana . Karena itulah artikel tersebut ditambahkan ke kategori Pemrograman Abnormal .
dan gabungkan NON_HEAP di Stack B dan sembunyikan NON_HEAP : Dapatkan
jumlah yang benar dengan [NON_HEAP] di Tooltip saat melayang di atas bagan: Dapatkan jumlah yang benar dengan [HEAP] di Tooltip saat melayang di atas bagan. Dan bahkan semua semburan terlihat: Dan jadwal terbentuk dengan cepat. Tapi legenda selalu menampilkan 0, legenda itu menjadi tidak berguna. Semuanya berhasil! Bypass sejati adalah melalui tumpukan Grafana . Karena itulah artikel tersebut ditambahkan ke kategori Pemrograman Abnormal .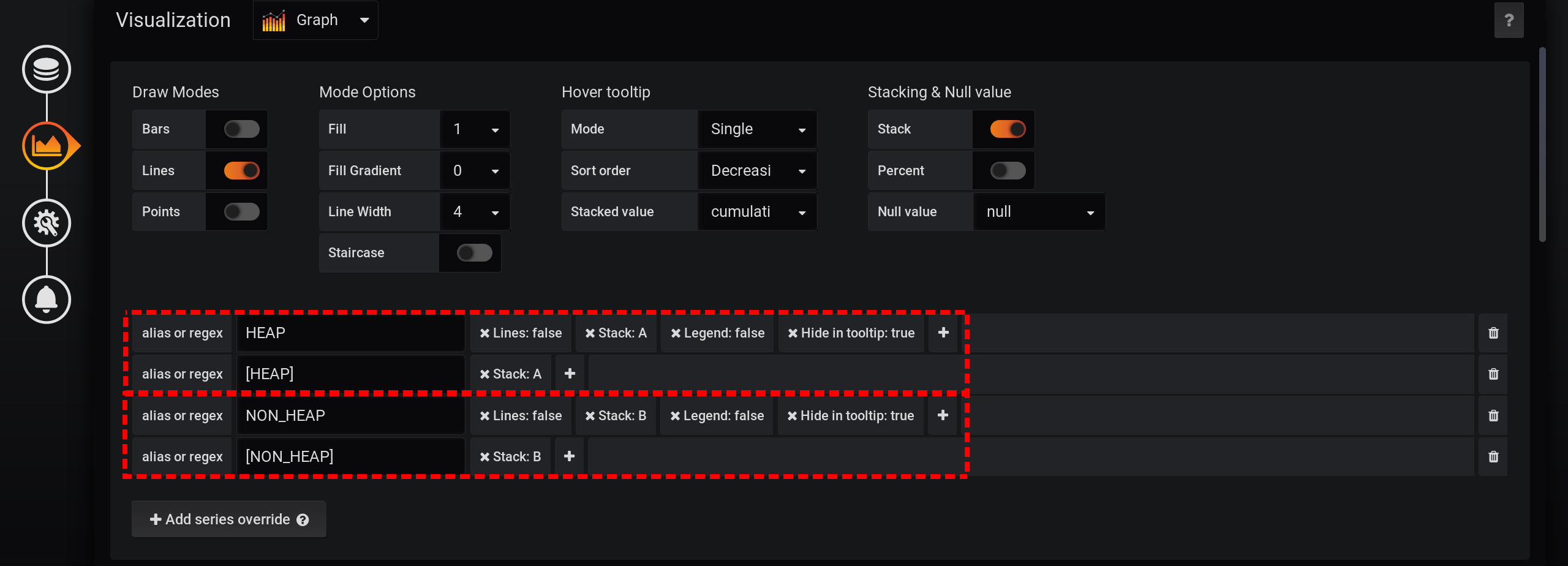


3. Jumlah tertinggi dengan subquery
Karena kita telah memulai jalur pemrograman abnormal dengan sekelompok Grafana dan InfluxDB , mari kita lanjutkan. Mari kita buat InfluxDB mengembalikan sejumlah kecil poin dan membuat legenda itu muncul.3.1 Jumlah penambahan jumlah kumulatif maxima
Mari kita selidiki kemungkinan InfluxDB . Sebelumnya, saya sering membantu dengan mengambil turunan dari jumlah kumulatif, jadi kami akan mencoba menerapkan pendekatan ini sekarang. Mari kita beralih ke mode pengeditan permintaan secara manual: Mari buat permintaan seperti itu:
SELECT sum("U") FROM (
SELECT non_negative_difference(cumulative_sum(max("Usage.committed"))) AS "U"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
GROUP BY "Type", time($granularity)
Di sini nilai maksimum metrik dalam grup berdasarkan waktu diambil dan jumlah nilai tersebut sejak referensi dimulai, dikelompokkan berdasarkan Jenis dan tag nama . Akibatnya, pada setiap momen waktu akan ada jumlah semua indikasi berdasarkan jenis ( HEAP atau NON_HEAP ) dengan pemisahan berdasarkan nama kumpulan, tetapi tidak 30 nilai dijumlahkan, seperti halnya dalam versi 1.2, tetapi hanya satu yang maksimum.Dan jika kita mengambil kenaikan non_negative_difference dari jumlah kumulatif untuk langkah terakhir, maka kita akan mendapatkan nilai jumlah semua kumpulan data yang dikelompokkan berdasarkan Jenis dan tag nama di awal interval waktu.Sekarang, untuk mendapatkan jumlah hanya dengan tagKetik , tanpa pengelompokan berdasarkan tag nama , Anda perlu membuat permintaan tingkat atas dengan parameter pengelompokan yang serupa, tetapi tanpa pengelompokan berdasarkan nama .Sebagai hasil dari query yang kompleks, kami mendapatkan jumlah semua tipe.Jadwal sempurna. Jumlah maksimal dihitung dengan benar. Ada legenda dengan nilai yang benar, bukan nol. Di tooltip Anda dapat menampilkan semua metrik, bukan hanya Tunggal. Bahkan semburan HEAP ditampilkan : Satu hal tetapi - permintaan ternyata sulit: jumlah kenaikan jumlah kumulatif maxima dengan perubahan tingkat pengelompokan.
3.2 Jumlah tertinggi dengan perubahan pada tingkat pengelompokan
Bisakah Anda melakukan sesuatu yang lebih sederhana daripada di versi 3.1? Kotak Pandora sudah terbuka, kami beralih ke mode edit kueri manual.Ada kecurigaan bahwa menerima kenaikan dari jumlah kumulatif menyebabkan efek nol - yang satu memadamkan yang lain. Singkirkan non_negative_difference (cumulative_sum (...)) .Sederhanakan permintaan.Kami cukup meninggalkan jumlah maxima, dengan penurunan tingkat pengelompokan:SELECT sum("A")
FROM (
SELECT max("Usage.committed") as "A"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
WHERE $timeFilter
GROUP BY time($granularity), "Type"
Ini adalah kueri sederhana cepat yang mengembalikan hanya 721 poin per seri dalam 12 jam, ketika dikelompokkan berdasarkan menit: 12 (jam) * 60 (menit) = 720 interval, 721 poin (kosong terakhir). Harap perhatikan bahwa filter waktu diduplikasi. Itu ada dalam subquery dan dalam permintaan pengelompokan: Tanpa $ timeFilter, dalam permintaan pengelompokan eksternal, jumlah poin yang dikembalikan tidak akan 721 dalam 12 jam, tetapi lebih. Karena subquery dikelompokkan untuk interval dari ... ke , dan pengelompokan permintaan eksternal tanpa filter akan menjadi untuk interval dari ... sekarang . Dan jika dalam Grafana interval waktu tidak berlangsung X-jam dipilih (tidak seperti itu untuk = sekarang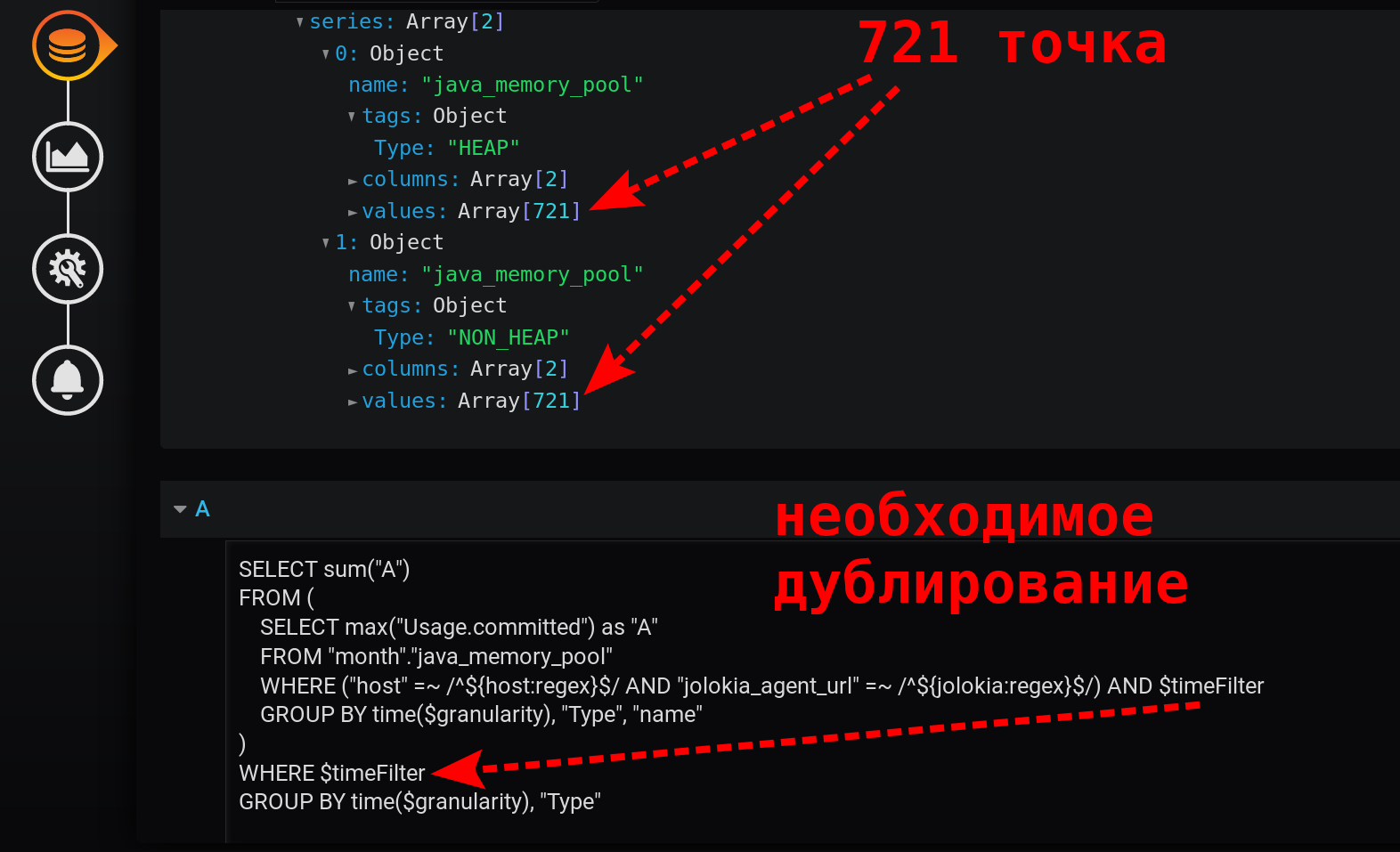 ), tetapi untuk interval dari masa lalu ( ke < sekarang ), maka poin kosong dengan nilai nol di akhir seleksi akan muncul.Grafik yang dihasilkan ternyata sederhana, cepat, benar. Dengan legenda yang menampilkan metrik ringkasan. Dengan tooltip untuk beberapa baris sekaligus. Dan juga dengan tampilan semua semburan nilai: Hasilnya tercapai!
), tetapi untuk interval dari masa lalu ( ke < sekarang ), maka poin kosong dengan nilai nol di akhir seleksi akan muncul.Grafik yang dihasilkan ternyata sederhana, cepat, benar. Dengan legenda yang menampilkan metrik ringkasan. Dengan tooltip untuk beberapa baris sekaligus. Dan juga dengan tampilan semua semburan nilai: Hasilnya tercapai!Referensi (bukan referensi)
Distribusi alat yang digunakan dalam artikel:Dokumentasi tentang kemampuan alat yang digunakan dalam artikel:The kombinasi Grafana dan InfluxDB perlu dikenal insinyur pengujian kinerja. Dan dalam bundel ini, banyak tugas sederhana sangat menarik, dan mereka tidak selalu dapat diselesaikan dengan metode pemrograman normal.Kadang-kadang Anda mungkin memerlukan keterampilan pemrograman abnormal dengan fitur Grafana dan seluk-beluk bahasa permintaan InfluxDB .Dalam artikel tersebut, empat langkah diperhitungkan dalam penerapan meringkas metrik dengan pengelompokan dengan satu tag, tetapi memiliki beberapa tag. Tugas itu menarik. Dan ada banyak tugas seperti itu.Saya sedang menyiapkan laporan tentang seluk beluk pemrograman dengan Grafana dan InfluxDB. Saya akan secara berkala menerbitkan materi tentang topik ini. Sementara itu, saya akan senang dengan pertanyaan Anda di artikel saat ini.