 Ilustrasi dibuat untuk A Journey With Go dari seorang gopher asli yang diciptakan oleh Rene French.Dalam hal kinerja, penggunaan pointer secara sistematis alih-alih menyalin struktur itu sendiri untuk membagikan struktur kepada banyak pengembang Go tampaknya menjadi pilihan terbaik. Untuk memahami efek dari menggunakan pointer daripada salinan struktur, kami akan mempertimbangkan dua kasus penggunaan.
Ilustrasi dibuat untuk A Journey With Go dari seorang gopher asli yang diciptakan oleh Rene French.Dalam hal kinerja, penggunaan pointer secara sistematis alih-alih menyalin struktur itu sendiri untuk membagikan struktur kepada banyak pengembang Go tampaknya menjadi pilihan terbaik. Untuk memahami efek dari menggunakan pointer daripada salinan struktur, kami akan mempertimbangkan dua kasus penggunaan.Distribusi data yang intensif
Mari kita lihat contoh sederhana ketika Anda ingin berbagi struktur untuk mengakses nilainya:type S struct {
a, b, c int64
d, e, f string
g, h, i float64
}
Berikut adalah struktur dasar, akses yang dapat dibagikan dengan copy atau pointer:func byCopy() S {
return S{
a: 1, b: 1, c: 1,
e: "foo", f: "foo",
g: 1.0, h: 1.0, i: 1.0,
}
}
func byPointer() *S {
return &S{
a: 1, b: 1, c: 1,
e: "foo", f: "foo",
g: 1.0, h: 1.0, i: 1.0,
}
}
Berdasarkan dua metode ini, kita dapat menulis 2 tolok ukur. Yang pertama adalah di mana struktur dilewatkan dengan salinan:func BenchmarkMemoryStack(b *testing.B) {
var s S
f, err := os.Create("stack.out")
if err != nil {
panic(err)
}
defer f.Close()
err = trace.Start(f)
if err != nil {
panic(err)
}
for i := 0; i < b.N; i++ {
s = byCopy()
}
trace.Stop()
b.StopTimer()
_ = fmt.Sprintf("%v", s.a)
}
Yang kedua - sangat mirip dengan yang pertama - di mana struktur dilewatkan oleh pointer:func BenchmarkMemoryHeap(b *testing.B) {
var s *S
f, err := os.Create("heap.out")
if err != nil {
panic(err)
}
defer f.Close()
err = trace.Start(f)
if err != nil {
panic(err)
}
for i := 0; i < b.N; i++ {
s = byPointer()
}
trace.Stop()
b.StopTimer()
_ = fmt.Sprintf("%v", s.a)
}
Mari kita jalankan tolok ukur:go test ./... -bench=BenchmarkMemoryHeap -benchmem -run=^$ -count=10 > head.txt && benchstat head.txt
go test ./... -bench=BenchmarkMemoryStack -benchmem -run=^$ -count=10 > stack.txt && benchstat stack.txt
Kami mendapatkan statistik berikut:name time/op
MemoryHeap-4 75.0ns ± 5%
name alloc/op
MemoryHeap-4 96.0B ± 0%
name allocs/op
MemoryHeap-4 1.00 ± 0%
------------------
name time/op
MemoryStack-4 8.93ns ± 4%
name alloc/op
MemoryStack-4 0.00B
name allocs/op
MemoryStack-4 0.00
Menggunakan salinan struktur adalah 8 kali lebih cepat daripada menggunakan pointer ke sana!Untuk memahami alasannya, mari kita lihat grafik yang dihasilkan oleh jejak: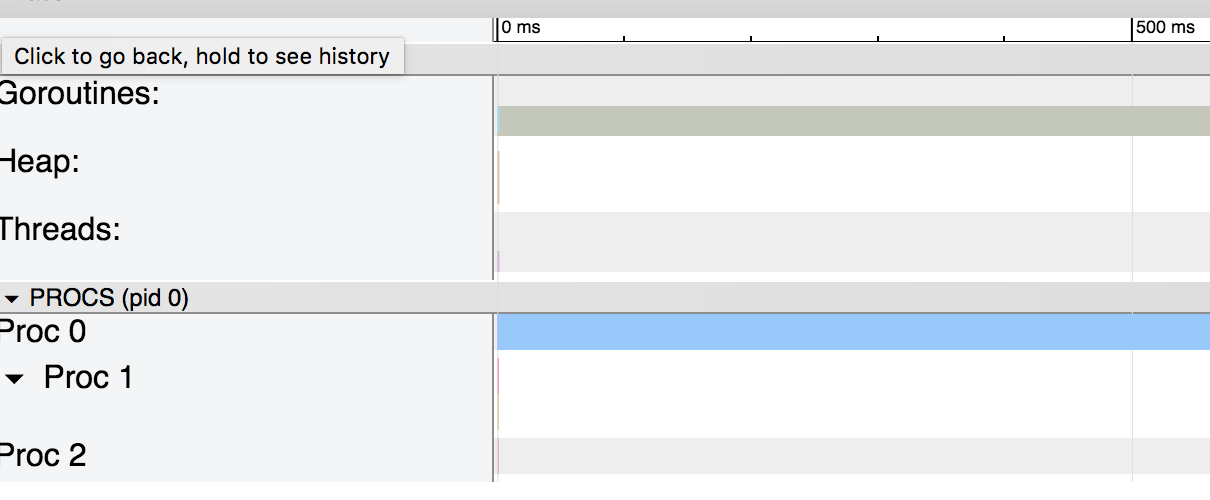 grafik untuk struktur yang dilewati oleh salinan
grafik untuk struktur yang dilewati oleh salinan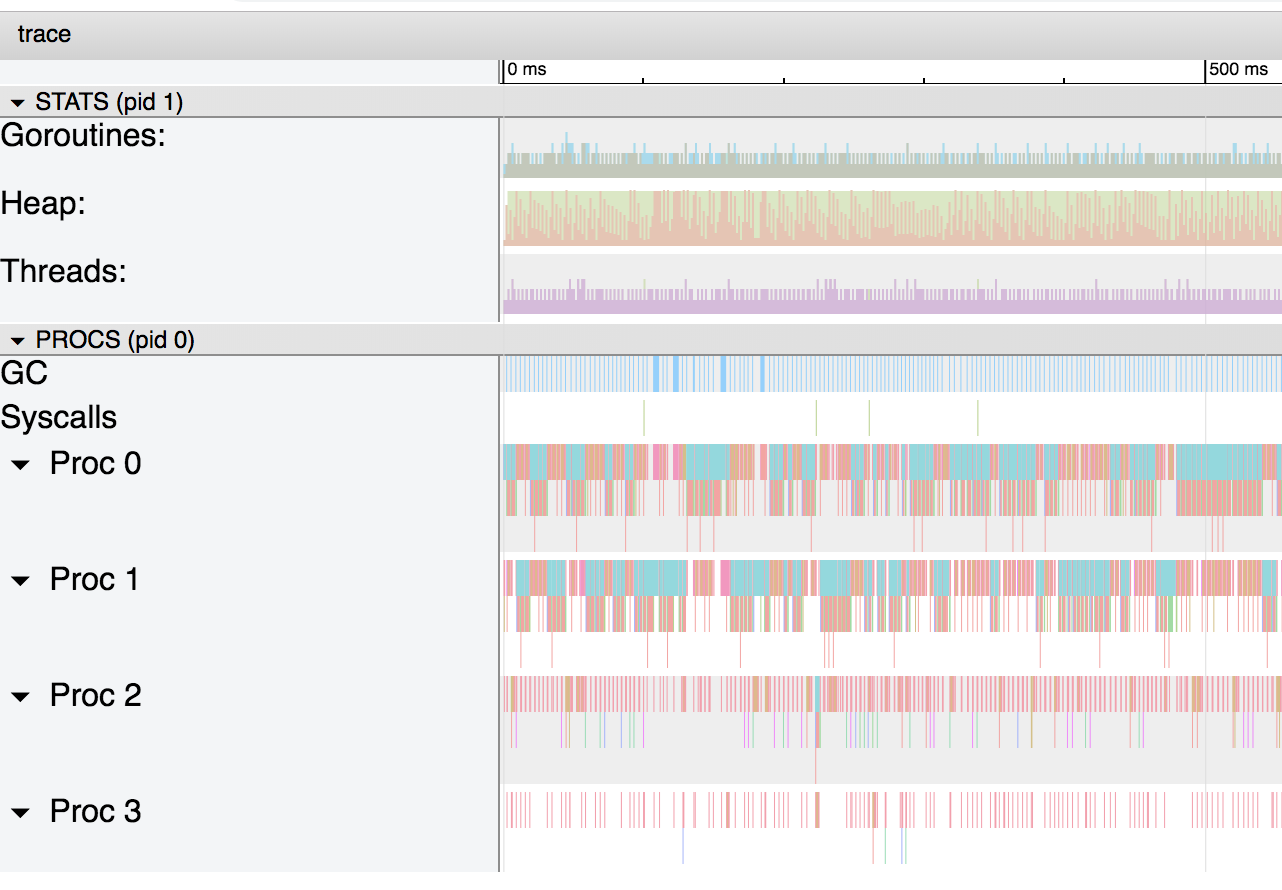 grafik untuk struktur yang dilewati oleh penunjuk. Grafik pertama cukup sederhana. Karena tumpukan tidak digunakan, tidak ada pengumpul sampah dan kelebihan gorutin.Dalam kasus kedua, menggunakan pointer menyebabkan kompiler Go untuk memindahkan variabel ke heap dan bekerja sebagai pengumpul sampah. Jika kita meningkatkan skala grafik, kita akan melihat bahwa pengumpul sampah menempati bagian penting dari proses:
grafik untuk struktur yang dilewati oleh penunjuk. Grafik pertama cukup sederhana. Karena tumpukan tidak digunakan, tidak ada pengumpul sampah dan kelebihan gorutin.Dalam kasus kedua, menggunakan pointer menyebabkan kompiler Go untuk memindahkan variabel ke heap dan bekerja sebagai pengumpul sampah. Jika kita meningkatkan skala grafik, kita akan melihat bahwa pengumpul sampah menempati bagian penting dari proses: Grafik ini menunjukkan bahwa pengumpul sampah dimulai setiap 4 ms.Jika kita memperbesar lagi, kita bisa mendapatkan informasi terperinci tentang apa yang sebenarnya terjadi: Garis-
Grafik ini menunjukkan bahwa pengumpul sampah dimulai setiap 4 ms.Jika kita memperbesar lagi, kita bisa mendapatkan informasi terperinci tentang apa yang sebenarnya terjadi: Garis-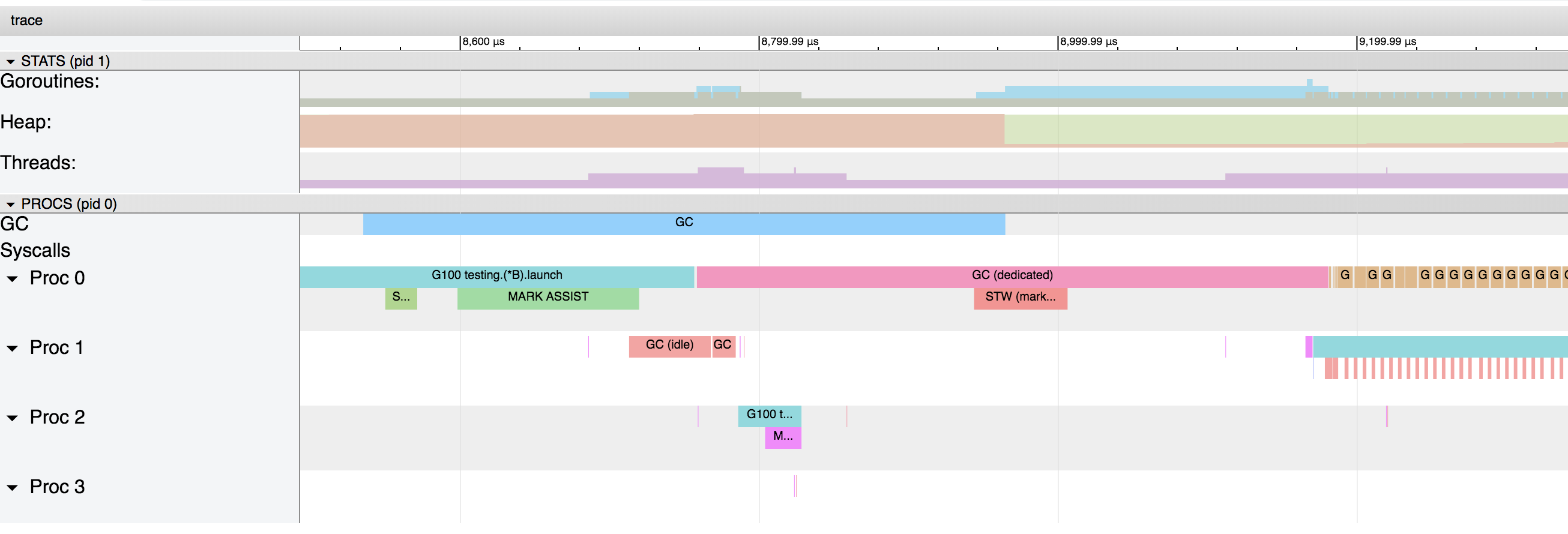 garis biru, merah muda dan merah adalah fase dari pengumpul sampah, dan yang coklat dikaitkan dengan alokasi dalam tumpukan (ditandai "runtime.bgsweep" pada grafik):
garis biru, merah muda dan merah adalah fase dari pengumpul sampah, dan yang coklat dikaitkan dengan alokasi dalam tumpukan (ditandai "runtime.bgsweep" pada grafik):Sweeping adalah pelepasan dari tumpukan bagian memori terkait data yang tidak ditandai sebagai digunakan. Tindakan ini terjadi ketika goroutine mencoba untuk mengisolasi nilai-nilai baru dalam memori tumpukan. Penundaan Sweeping ditambahkan ke biaya melakukan alokasi dalam memori tumpukan dan tidak berlaku untuk setiap keterlambatan yang terkait dengan pengumpulan sampah.
www.ardanlabs.com/blog/2018/12/garbage-collection-in-go-part1-semantics.html
Bahkan jika contoh ini agak ekstrem, kita melihat betapa mahal untuk mengalokasikan variabel di heap daripada di stack. Dalam contoh kami, struktur jauh lebih cepat dialokasikan pada stack dan disalin daripada dibuat di heap dan alamatnya dibagikan.Jika Anda tidak terbiasa dengan tumpukan / tumpukan, dan jika Anda ingin tahu lebih banyak tentang detail internal mereka, Anda dapat menemukan banyak informasi di Internet, misalnya, artikel ini oleh Paul Gribble.
Hal-hal dapat menjadi lebih buruk jika kita membatasi prosesor menjadi 1 menggunakan GOMAXPROCS = 1:name time/op
MemoryHeap 114ns ± 4%
name alloc/op
MemoryHeap 96.0B ± 0%
name allocs/op
MemoryHeap 1.00 ± 0%
------------------
name time/op
MemoryStack 8.77ns ± 5%
name alloc/op
MemoryStack 0.00B
name allocs/op
MemoryStack 0.00
Jika tolok ukur untuk menempatkan pada tumpukan tidak berubah, maka indikator pada tumpukan menurun dari 75ns / op ke 114ns / op.Panggilan fungsi intensif
Kami akan menambahkan dua metode kosong ke struktur kami dan sedikit menyesuaikan tolok ukur kami:func (s S) stack(s1 S) {}
func (s *S) heap(s1 *S) {}
Patokan dengan penempatan pada tumpukan akan membuat struktur dan memberikannya salinan:func BenchmarkMemoryStack(b *testing.B) {
var s S
var s1 S
s = byCopy()
s1 = byCopy()
for i := 0; i < b.N; i++ {
for i := 0; i < 1000000; i++ {
s.stack(s1)
}
}
}
Dan patokan untuk heap akan melewati struktur dengan pointer:func BenchmarkMemoryHeap(b *testing.B) {
var s *S
var s1 *S
s = byPointer()
s1 = byPointer()
for i := 0; i < b.N; i++ {
for i := 0; i < 1000000; i++ {
s.heap(s1)
}
}
}
Seperti yang diharapkan, hasilnya sangat berbeda sekarang:name time/op
MemoryHeap-4 301µs ± 4%
name alloc/op
MemoryHeap-4 0.00B
name allocs/op
MemoryHeap-4 0.00
------------------
name time/op
MemoryStack-4 595µs ± 2%
name alloc/op
MemoryStack-4 0.00B
name allocs/op
MemoryStack-4 0.00
Kesimpulan
Menggunakan pointer bukan salinan struktur yang digunakan tidak selalu baik. Untuk memilih semantik yang baik untuk data Anda, saya sangat merekomendasikan membaca posting tentang semantik nilai / pointer yang ditulis oleh Bill Kennedy . Ini akan memberi Anda ide yang lebih baik tentang strategi yang dapat Anda gunakan dengan struktur dan tipe bawaan Anda. Selain itu, profil penggunaan memori pasti akan membantu Anda memahami apa yang terjadi dengan alokasi dan tumpukan Anda.