Nama saya Pavel Parkhomenko, saya seorang pengembang ML. Pada artikel ini, saya ingin berbicara tentang desain layanan Yandex.Zen dan berbagi peningkatan teknis, yang perkenalannya memungkinkan peningkatan kualitas rekomendasi. Dari pos Anda akan belajar bagaimana menemukan yang paling relevan bagi pengguna di antara jutaan dokumen hanya dalam beberapa milidetik; bagaimana melakukan dekomposisi terus-menerus dari matriks besar (terdiri dari jutaan kolom dan puluhan juta baris) sehingga dokumen baru menerima vektornya dalam puluhan menit; cara menggunakan kembali dekomposisi matriks artikel pengguna untuk mendapatkan representasi vektor yang baik untuk video. Basis data rekomendasi kami berisi jutaan dokumen dengan berbagai format: artikel teks yang dibuat di platform kami dan diambil dari situs eksternal, video, narasi, dan pos pendek. Pengembangan layanan semacam itu dikaitkan dengan sejumlah besar tantangan teknis. Inilah beberapa di antaranya:
Basis data rekomendasi kami berisi jutaan dokumen dengan berbagai format: artikel teks yang dibuat di platform kami dan diambil dari situs eksternal, video, narasi, dan pos pendek. Pengembangan layanan semacam itu dikaitkan dengan sejumlah besar tantangan teknis. Inilah beberapa di antaranya:- Tugas komputasi terpisah: melakukan semua operasi berat secara offline, dan secara real time hanya menjalankan aplikasi model yang cepat untuk bertanggung jawab atas 100-200 ms.
- Pertimbangkan tindakan pengguna dengan cepat. Untuk ini, perlu bahwa semua acara langsung dikirim ke pemberi rekomendasi dan mempengaruhi hasil dari model.
- Buat rekaman itu agar pengguna baru cepat beradaptasi dengan perilaku mereka. Orang yang baru saja memasuki sistem harus merasa bahwa umpan balik mereka memengaruhi rekomendasi.
- Pahami siapa yang merekomendasikan artikel baru dengan cepat.
- Menanggapi dengan cepat kemunculan konten baru yang konstan. Puluhan ribu artikel diterbitkan setiap hari, dan banyak di antaranya memiliki umur yang terbatas (misalnya, berita). Ini perbedaan mereka dari film, musik, dan pembuatan konten lain yang berumur panjang dan mahal.
- Mentransfer pengetahuan dari satu domain ke domain lainnya. Jika sistem anjuran telah melatih model untuk artikel teks dan kami menambahkan video ke dalamnya, Anda dapat menggunakan kembali model yang ada sehingga jenis konten yang baru memiliki peringkat yang lebih baik.
Saya akan memberitahu Anda bagaimana kami memecahkan masalah ini.Seleksi Calon
Bagaimana dalam beberapa milidetik untuk mengurangi set dokumen yang dipertimbangkan ribuan kali, tanpa secara praktis memperburuk kualitas peringkat?Misalkan kita melatih banyak model ML, menghasilkan atribut berdasarkan pada mereka, dan melatih model lain yang memeringkat dokumen untuk pengguna. Semuanya akan baik-baik saja, tetapi Anda tidak bisa hanya mengambil dan menghitung semua tanda untuk semua dokumen secara waktu nyata, jika ada jutaan dokumen ini, dan rekomendasi harus dibuat dalam 100-200 ms. Tugasnya adalah memilih dari jutaan subset tertentu yang akan diberi peringkat untuk pengguna. Langkah ini biasa disebut seleksi kandidat. Ini memiliki beberapa persyaratan. Pertama, pemilihan harus berlangsung sangat cepat, sehingga waktu sebanyak mungkin tetap pada peringkat itu sendiri. Kedua, dengan sangat mengurangi jumlah dokumen untuk peringkat, kita harus menjaga agar dokumen tetap relevan bagi pengguna selengkap mungkin.Prinsip pemilihan kandidat kami telah berkembang secara evolusioner, dan saat ini kami telah mencapai skema multi-tahap: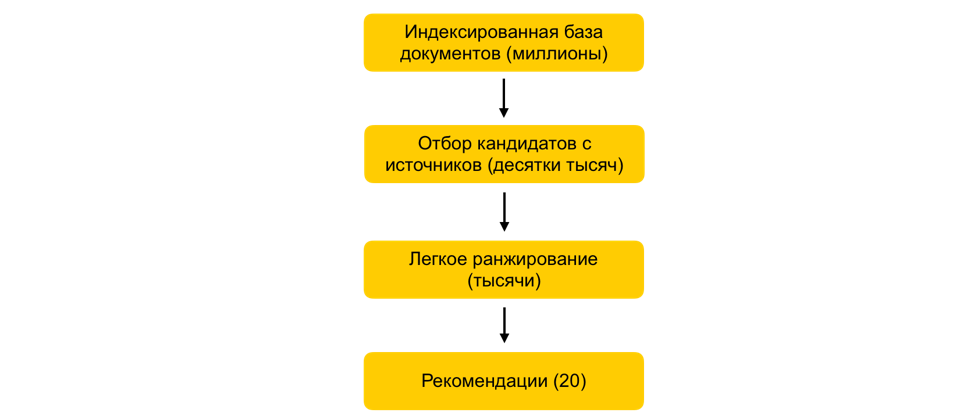 Pertama, semua dokumen dibagi menjadi kelompok-kelompok, dan dokumen yang paling populer diambil dari masing-masing kelompok. Grup dapat berupa situs, topik, kluster. Untuk setiap pengguna, berdasarkan kisahnya, grup yang paling dekat dengannya dipilih dan dokumen terbaik sudah diambil dari mereka. Kami juga menggunakan indeks kNN untuk memilih dokumen yang paling dekat dengan pengguna secara real time. Ada beberapa metode untuk membangun indeks kNN, kami memiliki HNSW terbaik(Grafik Hierarchical Navigable Small World). Ini adalah model hierarkis yang memungkinkan Anda menemukan N vektor terdekat untuk pengguna dari database sepersejuta dalam beberapa milidetik. Sebelumnya, kami offline mengindeks seluruh basis data dokumen kami. Karena pencarian dalam indeks bekerja cukup cepat, jika ada beberapa embeddings yang kuat, Anda dapat membuat beberapa indeks (satu indeks untuk setiap embedding) dan mengakses masing-masing secara real time.Kami masih memiliki puluhan ribu dokumen untuk setiap pengguna. Ini masih banyak untuk menghitung semua atribut, jadi pada tahap ini kami menerapkan peringkat mudah - model peringkat berat ringan dengan atribut lebih sedikit. Tugasnya adalah untuk memprediksi dokumen apa yang model berat akan miliki di atas. Dokumen-dokumen dengan prediksi tertinggi akan digunakan dalam model berat, yaitu, pada tahap peringkat terakhir. Pendekatan ini memungkinkan puluhan milidetik untuk mengurangi database dokumen yang dipertimbangkan untuk pengguna dari jutaan menjadi ribuan.
Pertama, semua dokumen dibagi menjadi kelompok-kelompok, dan dokumen yang paling populer diambil dari masing-masing kelompok. Grup dapat berupa situs, topik, kluster. Untuk setiap pengguna, berdasarkan kisahnya, grup yang paling dekat dengannya dipilih dan dokumen terbaik sudah diambil dari mereka. Kami juga menggunakan indeks kNN untuk memilih dokumen yang paling dekat dengan pengguna secara real time. Ada beberapa metode untuk membangun indeks kNN, kami memiliki HNSW terbaik(Grafik Hierarchical Navigable Small World). Ini adalah model hierarkis yang memungkinkan Anda menemukan N vektor terdekat untuk pengguna dari database sepersejuta dalam beberapa milidetik. Sebelumnya, kami offline mengindeks seluruh basis data dokumen kami. Karena pencarian dalam indeks bekerja cukup cepat, jika ada beberapa embeddings yang kuat, Anda dapat membuat beberapa indeks (satu indeks untuk setiap embedding) dan mengakses masing-masing secara real time.Kami masih memiliki puluhan ribu dokumen untuk setiap pengguna. Ini masih banyak untuk menghitung semua atribut, jadi pada tahap ini kami menerapkan peringkat mudah - model peringkat berat ringan dengan atribut lebih sedikit. Tugasnya adalah untuk memprediksi dokumen apa yang model berat akan miliki di atas. Dokumen-dokumen dengan prediksi tertinggi akan digunakan dalam model berat, yaitu, pada tahap peringkat terakhir. Pendekatan ini memungkinkan puluhan milidetik untuk mengurangi database dokumen yang dipertimbangkan untuk pengguna dari jutaan menjadi ribuan.Langkah ALS dalam runtime
Bagaimana cara memperhitungkan umpan balik pengguna segera setelah klik?Faktor penting dalam rekomendasi adalah waktu respons terhadap umpan balik pengguna. Ini sangat penting bagi pengguna baru: ketika seseorang baru mulai menggunakan sistem rekomendasi, ia menerima aliran dokumen yang tidak dipersonalisasi dari berbagai topik. Begitu dia membuat klik pertama, Anda harus segera mempertimbangkan ini dan beradaptasi dengan minatnya. Jika semua faktor dihitung secara offline, respons sistem yang cepat menjadi tidak mungkin karena keterlambatan. Jadi, Anda perlu memproses tindakan pengguna secara real time. Untuk tujuan ini, kami menggunakan langkah ALS dalam runtime untuk membangun representasi vektor pengguna.Misalkan kita memiliki representasi vektor untuk semua dokumen. Sebagai contoh, kita dapat membangun secara offline berdasarkan embedding teks artikel menggunakan ELMo, BERT atau model pembelajaran mesin lainnya. Bagaimana seseorang bisa mendapatkan representasi vektor pengguna di ruang yang sama berdasarkan interaksi mereka dalam sistem?Prinsip umum pembentukan dan dekomposisi dari matriks dokumen penggunam n . . m x n: , — . , ́ , . (, , ) - — , 1, –1.
: P (m x d) Q (d x n), d — ( ). d- ( — P, — Q). . , , .

Salah satu cara dekomposisi matriks yang mungkin adalah ALS (Alternating Least Squares). Kami akan mengoptimalkan fungsi kerugian berikut:
Di sini r ui adalah interaksi pengguna u dengan dokumen i, q i adalah vektor dokumen i, p u adalah vektor pengguna u.Kemudian vektor pengguna yang optimal dari sudut pandang kesalahan kuadrat rata-rata (untuk vektor dokumen tetap) ditemukan secara analitik dengan menyelesaikan regresi linier yang sesuai.Ini disebut langkah ALS. Dan algoritma ALS itu sendiri terdiri dari fakta bahwa kami secara bergantian memperbaiki salah satu matriks (pengguna dan artikel) dan memperbarui yang lain, menemukan solusi optimal.Untungnya, menemukan representasi vektor pengguna adalah operasi yang cukup cepat yang dapat dilakukan dalam runtime menggunakan instruksi vektor. Trik ini memungkinkan Anda untuk segera mempertimbangkan umpan balik pengguna di peringkat. Penyematan yang sama dapat digunakan dalam indeks kNN untuk meningkatkan pemilihan kandidat.Penyaringan Kolaboratif Terdistribusi
Bagaimana cara melakukan faktorisasi matriks terdistribusi secara bertahap dan dengan cepat menemukan representasi vektor dari artikel baru?Konten bukan satu-satunya sumber sinyal untuk rekomendasi. Informasi kolaboratif adalah sumber penting lainnya. Tanda-tanda yang baik dalam peringkat secara tradisional dapat diperoleh dari dekomposisi dari matriks dokumen-pengguna. Tetapi ketika mencoba melakukan dekomposisi ini, kami menemui masalah:1. Kami memiliki jutaan dokumen dan puluhan juta pengguna. Matriks tidak sepenuhnya cocok pada satu mesin, dan dekomposisi akan sangat panjang.2. Sebagian besar konten dalam sistem memiliki masa hidup yang singkat: dokumen tetap relevan hanya beberapa jam. Oleh karena itu, perlu untuk membangun representasi vektor mereka secepat mungkin.3. Jika Anda membuat dekomposisi segera setelah publikasi dokumen, cukup banyak pengguna tidak akan punya waktu untuk mengevaluasinya. Oleh karena itu, representasi vektornya kemungkinan tidak terlalu baik.4. Jika pengguna suka atau tidak suka, kami tidak akan dapat segera mempertimbangkan hal ini dalam ekspansi.Untuk mengatasi masalah ini, kami menerapkan dekomposisi terdistribusi dari matriks dokumen pengguna dengan pembaruan bertahap yang sering. Bagaimana tepatnya cara kerjanya?Misalkan kita memiliki sekelompok mesin N (N dalam ratusan) dan kami ingin membuat dekomposisi terdistribusi dari matriks pada mereka, yang tidak sesuai pada satu mesin. Pertanyaannya adalah bagaimana melakukan dekomposisi ini sehingga, di satu sisi, ada cukup data pada setiap mesin dan, di sisi lain, sehingga perhitungannya independen?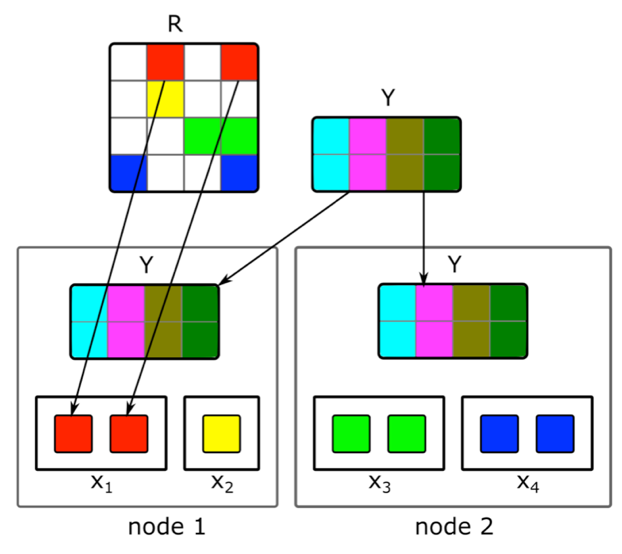 Kami akan menggunakan algoritma dekomposisi ALS yang dijelaskan di atas. Pertimbangkan cara melakukan satu langkah ALS secara terdistribusi - sisa langkahnya akan serupa. Misalkan kita memiliki matriks dokumen yang tetap dan kami ingin membangun matriks pengguna. Untuk melakukan ini, kami membaginya menjadi N bagian dalam baris, setiap bagian akan berisi kira-kira jumlah baris yang sama. Kami akan mengirimkan ke setiap mesin sel yang tidak kosong dari baris yang sesuai, serta matriks embeddings dokumen (secara keseluruhan). Karena tidak terlalu besar, dan matriks dokumen pengguna biasanya sangat jarang, data ini akan sesuai pada mesin biasa.Trik semacam itu dapat diulang untuk beberapa era sampai model bertemu, bergantian mengubah matriks tetap. Tetapi bahkan kemudian, dekomposisi matriks dapat berlangsung beberapa jam. Dan ini tidak menyelesaikan masalah perlunya dengan cepat menerima embeddings dari dokumen baru dan memperbarui embeddings dari mereka yang hanya ada sedikit informasi ketika membangun model.Pengenalan pembaruan tambahan cepat dari model membantu kami. Misalkan kita memiliki model terlatih saat ini. Sejak pelatihannya, artikel baru telah muncul yang berinteraksi dengan pengguna kami, serta artikel yang memiliki sedikit interaksi dengan pelatihan. Untuk menyematkan artikel tersebut dengan cepat, kami menggunakan embeddings pengguna yang diperoleh selama pelatihan model besar pertama dan mengambil satu langkah ALS untuk menghitung matriks dokumen dengan matriks pengguna tetap. Ini memungkinkan Anda untuk menerima embeddings dengan cepat - dalam beberapa menit setelah publikasi dokumen - dan sering memperbarui embeddings dari dokumen baru.Untuk segera mempertimbangkan tindakan manusia untuk rekomendasi, pada saat runtime kami tidak menggunakan sematan pengguna yang diterima secara offline. Sebagai gantinya, kami mengambil langkah ALS dan mendapatkan vektor pengguna saat ini.
Kami akan menggunakan algoritma dekomposisi ALS yang dijelaskan di atas. Pertimbangkan cara melakukan satu langkah ALS secara terdistribusi - sisa langkahnya akan serupa. Misalkan kita memiliki matriks dokumen yang tetap dan kami ingin membangun matriks pengguna. Untuk melakukan ini, kami membaginya menjadi N bagian dalam baris, setiap bagian akan berisi kira-kira jumlah baris yang sama. Kami akan mengirimkan ke setiap mesin sel yang tidak kosong dari baris yang sesuai, serta matriks embeddings dokumen (secara keseluruhan). Karena tidak terlalu besar, dan matriks dokumen pengguna biasanya sangat jarang, data ini akan sesuai pada mesin biasa.Trik semacam itu dapat diulang untuk beberapa era sampai model bertemu, bergantian mengubah matriks tetap. Tetapi bahkan kemudian, dekomposisi matriks dapat berlangsung beberapa jam. Dan ini tidak menyelesaikan masalah perlunya dengan cepat menerima embeddings dari dokumen baru dan memperbarui embeddings dari mereka yang hanya ada sedikit informasi ketika membangun model.Pengenalan pembaruan tambahan cepat dari model membantu kami. Misalkan kita memiliki model terlatih saat ini. Sejak pelatihannya, artikel baru telah muncul yang berinteraksi dengan pengguna kami, serta artikel yang memiliki sedikit interaksi dengan pelatihan. Untuk menyematkan artikel tersebut dengan cepat, kami menggunakan embeddings pengguna yang diperoleh selama pelatihan model besar pertama dan mengambil satu langkah ALS untuk menghitung matriks dokumen dengan matriks pengguna tetap. Ini memungkinkan Anda untuk menerima embeddings dengan cepat - dalam beberapa menit setelah publikasi dokumen - dan sering memperbarui embeddings dari dokumen baru.Untuk segera mempertimbangkan tindakan manusia untuk rekomendasi, pada saat runtime kami tidak menggunakan sematan pengguna yang diterima secara offline. Sebagai gantinya, kami mengambil langkah ALS dan mendapatkan vektor pengguna saat ini.Transfer ke area domain lain
Bagaimana cara menggunakan umpan balik pengguna untuk artikel teks untuk membangun representasi vektor video?Awalnya, kami merekomendasikan hanya artikel teks, jadi banyak dari algoritma kami berfokus pada jenis konten ini. Tetapi ketika menambahkan konten dari jenis yang berbeda, kami dihadapkan dengan kebutuhan untuk mengadaptasi model. Bagaimana kami mengatasi masalah ini menggunakan video contoh? Salah satu opsi adalah melatih ulang semua model dari awal. Tetapi ini adalah waktu yang lama, di samping itu, beberapa algoritma menuntut volume sampel pelatihan, yang belum dalam jumlah yang tepat untuk jenis konten baru pada saat-saat pertama kehidupannya di layanan.Kami pergi ke arah lain dan menggunakan kembali model teks untuk video. Dalam membuat representasi vektor dari video, trik yang sama dengan ALS membantu kami. Kami mengambil representasi vektor pengguna berdasarkan artikel teks dan mengambil langkah ALS menggunakan informasi tentang tampilan video. Jadi kami dengan mudah mendapatkan representasi vektor dari video. Dan dalam runtime, kami cukup menghitung kedekatan antara vektor pengguna yang diperoleh dari artikel teks dan vektor video.Kesimpulan
Pengembangan inti dari sistem pemberi rekomendasi waktu-nyata penuh dengan banyak tugas. Penting untuk memproses data dengan cepat dan menerapkan metode ML untuk secara efektif menggunakan data ini; Membangun sistem terdistribusi kompleks yang mampu memproses sinyal pengguna dan unit konten baru dalam waktu minimum; dan banyak tugas lainnya.Dalam sistem saat ini, perangkat yang saya jelaskan, kualitas rekomendasi untuk pengguna tumbuh dengan aktivitasnya dan durasi layanan. Tapi tentu saja, di sinilah letak kesulitan utama: sulit bagi sistem untuk segera memahami minat seseorang yang sedikit berinteraksi dengan konten. Meningkatkan rekomendasi untuk pengguna baru adalah perhatian utama kami. Kami akan terus mengoptimalkan algoritme agar konten yang relevan dengan orang tersebut masuk ke umpannya lebih cepat dan tidak relevan tidak muncul.