Kondisi umum untuk menerapkan CI / CD di Kubernetes: aplikasi harus dapat berhenti menerima permintaan klien baru sebelum berhenti, dan yang paling penting, berhasil menyelesaikan yang sudah ada. Kepatuhan dengan kondisi ini memungkinkan Anda untuk mencapai nol downtime selama pemasangan. Namun, bahkan ketika menggunakan bundel yang sangat populer (seperti NGINX dan PHP-FPM), Anda dapat menemukan kesulitan yang akan mengarah pada gelombang kesalahan dengan setiap penyebaran ...
Kepatuhan dengan kondisi ini memungkinkan Anda untuk mencapai nol downtime selama pemasangan. Namun, bahkan ketika menggunakan bundel yang sangat populer (seperti NGINX dan PHP-FPM), Anda dapat menemukan kesulitan yang akan mengarah pada gelombang kesalahan dengan setiap penyebaran ...Teori. Bagaimana pod hidup
Kami telah menerbitkan artikel ini secara terperinci tentang siklus hidup pod . Dalam konteks topik ini, kami tertarik pada hal-hal berikut: pada saat ketika pod memasuki status Pengakhiran , permintaan baru berhenti dikirim ke sana (pod dihapus dari daftar titik akhir untuk layanan). Jadi, untuk menghindari downtime selama penyebaran, untuk bagian kami, cukup untuk menyelesaikan masalah aplikasi berhenti dengan benar.Harus diingat juga bahwa masa tenggang adalah 30 detik secara default : setelah ini, pod akan dihentikan dan aplikasi harus mengatur untuk memproses semua permintaan sebelum periode ini. Catatan: meskipun setiap permintaan yang berjalan lebih dari 5-10 detik sudah bermasalah, dan shutdown yang anggun tidak akan membantunya lagi ...Untuk lebih memahami apa yang terjadi ketika pod menyelesaikan tugasnya, cukup mempelajari skema berikut: A1, B1 - Mendapatkan perubahan tentang status
A1, B1 - Mendapatkan perubahan tentang status
A2: Mengirim SIGTERM
B2 - Menghapus pod dari titik akhir
B3 - Mendapatkan perubahan (daftar titik akhir telah berubah)
B4 - Memperbarui aturan iptablesCatatan: menghapus pod titik akhir dan mengirim SIGTERM tidak dilakukan secara berurutan, tetapi secara paralel. Dan karena fakta bahwa Ingress tidak menerima daftar terbaru Endpoints segera, permintaan baru dari klien akan dikirim ke pod, yang akan menyebabkan 500 kesalahan selama penghentian pod(kami menerjemahkan materi yang lebih rinci tentang masalah ini ) . Anda perlu mengatasi masalah ini dengan cara berikut:- Kirim di header Koneksi: respons dekat (jika menyangkut aplikasi HTTP).
- Jika tidak ada cara untuk membuat perubahan pada kode, maka artikel tersebut menjelaskan solusi yang akan memungkinkan Anda untuk memproses permintaan hingga akhir periode anggun.
Teori. Bagaimana NGINX dan PHP-FPM Mengakhiri Prosesnya
Nginx
Mari kita mulai dengan NGINX, karena semuanya kurang lebih jelas dengannya. Tenggelam dalam teori, kita belajar bahwa NGINX memiliki satu proses utama dan beberapa "pekerja" - ini adalah proses anak yang memproses permintaan klien. Fitur yang mudah disediakan: menggunakan perintah untuk nginx -s <SIGNAL>menghentikan proses baik dalam mode shutdown cepat atau dalam shutdown anggun. Jelas, kami benar-benar tertarik pada opsi yang terakhir.Maka semuanya sederhana: Anda perlu menambahkan perintah ke kait preStop yang akan mengirim sinyal tentang shutdown yang anggun. Ini bisa dilakukan di Penempatan, di blok penampung: lifecycle:
preStop:
exec:
command:
- /usr/sbin/nginx
- -s
- quit
Sekarang, saat pod menyelesaikan pekerjaannya di log kontainer NGINX, kita akan melihat yang berikut:2018/01/25 13:58:31 [notice] 1#1: signal 3 (SIGQUIT) received, shutting down
2018/01/25 13:58:31 [notice] 11#11: gracefully shutting down
Dan itu akan berarti apa yang kita butuhkan: NGINX menunggu penyelesaian kueri, dan kemudian membunuh prosesnya. Namun, masalah umum akan dibahas di bawah ini, karena itu, bahkan jika ada perintah, nginx -s quitproses tidak selesai dengan benar.Dan pada tahap ini kami telah selesai dengan NGINX: setidaknya Anda dapat memahami dari log bahwa semuanya berfungsi sebagaimana mestinya.Bagaimana dengan PHP-FPM? Bagaimana cara menangani shutdown yang anggun? Mari kita perbaiki.PHP-FPM
Dalam hal PHP-FPM, informasinya sedikit kurang. Jika Anda fokus pada manual resmi pada PHP-FPM, maka ia akan memberi tahu Anda bahwa sinyal POSIX berikut diterima:SIGINT, SIGTERM- shutdown cepat;SIGQUIT - Shutdown anggun (apa yang kita butuhkan).
Sisa dari sinyal dalam masalah ini tidak diperlukan, oleh karena itu, analisisnya dihilangkan. Untuk menyelesaikan proses dengan benar, Anda harus menulis kait preStop berikut: lifecycle:
preStop:
exec:
command:
- /bin/kill
- -SIGQUIT
- "1"
Pada pandangan pertama, ini adalah semua yang diperlukan untuk melakukan shutdown yang anggun di kedua wadah. Namun, tugasnya lebih rumit dari yang terlihat. Selanjutnya, kami memeriksa dua kasus di mana shutdown yang anggun tidak bekerja dan menyebabkan tidak dapat diaksesnya jangka pendek proyek selama penyebaran.Praktek. Kemungkinan masalah dengan shutdown yang anggun
Nginx
Pertama-tama, penting untuk diingat: selain mengeksekusi perintah, nginx -s quitada langkah lain yang harus Anda perhatikan. Kami mengalami masalah ketika NGINX alih-alih sinyal SIGQUIT mengirim SIGTERM, karena itu permintaan tidak selesai dengan benar. Kasus serupa dapat ditemukan, misalnya di sini . Sayangnya, kami tidak dapat menetapkan alasan spesifik untuk perilaku ini: ada kecurigaan terhadap versi NGINX, tetapi itu tidak dikonfirmasi. Gejalanya adalah bahwa dalam log wadah NGINX pesan "open socket # 10 tersisa di koneksi 5" diamati , setelah itu pod berhenti.Kita dapat mengamati masalah seperti itu, misalnya, dengan jawaban atas Ingress yang kita butuhkan: Indikator kode status pada saat penyebaranDalam hal ini, kami hanya mendapatkan kode kesalahan 503 dari Ingress sendiri: ia tidak dapat mengakses wadah NGINX, karena tidak lagi tersedia. Jika Anda melihat log kontainer dengan NGINX, mereka berisi yang berikut ini:
Indikator kode status pada saat penyebaranDalam hal ini, kami hanya mendapatkan kode kesalahan 503 dari Ingress sendiri: ia tidak dapat mengakses wadah NGINX, karena tidak lagi tersedia. Jika Anda melihat log kontainer dengan NGINX, mereka berisi yang berikut ini:[alert] 13939#0: *154 open socket #3 left in connection 16
[alert] 13939#0: *168 open socket #6 left in connection 13
Setelah mengubah sinyal berhenti, wadah mulai berhenti dengan benar: ini dikonfirmasi oleh fakta bahwa kesalahan 503 tidak lagi diamati.Jika Anda mengalami masalah yang sama, masuk akal untuk mencari tahu sinyal berhenti mana yang digunakan dalam wadah dan bagaimana kait preStop terlihat persis. Ada kemungkinan bahwa alasannya justru terletak pada hal ini.PHP-FPM ... dan banyak lagi
Masalah dengan PHP-FPM dijelaskan secara sepele: ia tidak menunggu penyelesaian proses anak, menghentikannya, karena yang ada 502 kesalahan selama penyebaran dan operasi lainnya. Sejak 2005 ada beberapa pesan kesalahan pada bugs.php.net (misalnya, di sini dan di sini ) yang menjelaskan masalah ini. Tapi Anda mungkin tidak akan melihat apa pun di log: PHP-FPM akan mengumumkan penyelesaian prosesnya tanpa kesalahan atau pemberitahuan pihak ketiga.Perlu diperjelas bahwa masalah itu sendiri mungkin, pada tingkat lebih rendah atau lebih besar, tergantung pada aplikasi itu sendiri dan mungkin tidak muncul, misalnya, dalam pemantauan. Jika Anda masih menemukannya, maka solusi sederhana muncul di benak Anda: tambahkan kait preStop dengansleep(30). Ini akan memungkinkan Anda untuk menyelesaikan semua permintaan sebelumnya (kami tidak menerima yang baru, karena pod sudah dalam status Pengakhiran ), dan setelah 30 detik pod itu sendiri akan berakhir dengan sinyal SIGTERM.Ternyata lifecycleuntuk wadah akan terlihat seperti ini: lifecycle:
preStop:
exec:
command:
- /bin/sleep
- "30"
Namun, karena indikasi 30 detik, sleepkami akan secara signifikan meningkatkan waktu penyebaran, karena setiap pod akan diakhiri selama setidaknya 30 detik, yang mana adalah buruk. Apa yang bisa dilakukan dengan ini?Mari kita beralih ke pihak yang bertanggung jawab untuk eksekusi langsung aplikasi. Dalam kasus kami, ini adalah PHP-FPM , yang secara default tidak memantau pelaksanaan proses turunannya : proses master dihentikan segera. Perilaku ini dapat diubah menggunakan arahan process_control_timeoutyang menentukan batas waktu untuk menunggu sinyal dari master oleh proses anak. Jika Anda menetapkan nilai ke 20 detik, ini akan mencakup sebagian besar permintaan yang berjalan di wadah, dan setelah selesai, proses master akan dihentikan.Dengan pengetahuan ini, kami akan kembali ke masalah terakhir kami. Seperti yang telah disebutkan, Kubernetes bukan platform monolitik: butuh beberapa waktu untuk interaksi antara berbagai komponennya. Ini terutama benar ketika kami mempertimbangkan pekerjaan Ingresss dan komponen terkait lainnya, karena karena keterlambatan pada saat penempatan, mudah untuk mendapatkan lonjakan 500 kesalahan. Misalnya, kesalahan dapat terjadi pada tahap mengirim permintaan ke hulu, tetapi "jeda waktu" interaksi antara komponen agak pendek - kurang dari satu detik.Oleh karena itu, dalam hubungannya dengan arahan yang telah disebutkan process_control_timeout, konstruksi berikut dapat digunakan untuk lifecycle:lifecycle:
preStop:
exec:
command: ["/bin/bash","-c","/bin/sleep 1; kill -QUIT 1"]
Dalam hal ini, kami mengkompensasi keterlambatan oleh tim sleepdan tidak secara signifikan meningkatkan waktu penyebaran: apakah ada perbedaan yang nyata antara 30 detik dan satu? ... Pada dasarnya process_control_timeout, ini mengambil "pekerjaan utama" , tetapi lifecyclehanya digunakan sebagai "jaring pengaman" jika terjadi kelambatan.Secara umum, perilaku yang dijelaskan dan solusi terkait tidak hanya PHP-FPM . Situasi serupa mungkin muncul dengan satu atau lain cara ketika menggunakan bahasa / kerangka kerja lain. Jika Anda tidak dapat memperbaiki shutdown anggun dengan cara lain - misalnya, menulis ulang kode sehingga aplikasi memproses sinyal terminasi dengan benar - Anda dapat menggunakan metode yang dijelaskan. Ini mungkin bukan yang paling indah, tetapi berhasil.Praktek. Muat pengujian untuk memverifikasi kinerja pod
Pengujian beban adalah salah satu cara untuk memeriksa cara kerja wadah, karena prosedur ini membawa Anda lebih dekat ke kondisi pertempuran nyata ketika pengguna mengunjungi situs. Anda dapat menggunakan Yandex.Tank untuk menguji rekomendasi di atas : sempurna mencakup semua kebutuhan kita. Berikut ini adalah tips dan trik untuk pengujian dengan jelas - terima kasih kepada grafik Grafana dan Yandex.Tank sendiri - contoh dari pengalaman kami.Yang paling penting di sini adalah memeriksa perubahan secara bertahap.. Setelah menambahkan perbaikan baru, jalankan pengujian dan lihat apakah hasilnya telah berubah dibandingkan dengan peluncuran sebelumnya. Kalau tidak, akan sulit untuk mengidentifikasi solusi yang tidak efektif, dan di masa depan Anda hanya dapat membahayakan (misalnya, menambah waktu penempatan).Peringatan lain - lihat log wadah selama penghentiannya. Apakah informasi shutdown yang baik dicatat di sana? Apakah ada kesalahan dalam log ketika mengakses sumber daya lain (misalnya, wadah PHP-FPM tetangga)? Kesalahan aplikasi itu sendiri (seperti dalam kasus NGINX yang dijelaskan di atas)? Saya berharap bahwa informasi pengantar dari artikel ini akan membantu untuk lebih memahami apa yang terjadi pada wadah selama penghentiannya.Jadi, uji coba pertama berlangsung tanpa lifecycledan tanpa arahan tambahan untuk server aplikasi (process_control_timeoutdalam PHP-FPM). Tujuan dari tes ini adalah untuk mengidentifikasi perkiraan jumlah kesalahan (dan apakah mereka ada sama sekali). Juga, dari informasi tambahan, harus diketahui bahwa waktu penyebaran rata-rata setiap perapian adalah sekitar 5-10 detik untuk keadaan kesiapan penuh. Hasilnya adalah sebagai berikut: Percikan 502 kesalahan terlihat pada panel informasi Yandex.Tank, yang terjadi pada saat penyebaran dan rata-rata berlangsung hingga 5 detik. Agaknya ini menghentikan permintaan yang ada ke pod lama ketika dihentikan. Setelah itu, 503 kesalahan muncul, yang merupakan hasil dari wadah NGINX yang terhenti, yang juga terputus karena backend (karena itu Ingress tidak dapat terhubung ke sana).Mari kita lihat caranya
Percikan 502 kesalahan terlihat pada panel informasi Yandex.Tank, yang terjadi pada saat penyebaran dan rata-rata berlangsung hingga 5 detik. Agaknya ini menghentikan permintaan yang ada ke pod lama ketika dihentikan. Setelah itu, 503 kesalahan muncul, yang merupakan hasil dari wadah NGINX yang terhenti, yang juga terputus karena backend (karena itu Ingress tidak dapat terhubung ke sana).Mari kita lihat caranyaprocess_control_timeoutdalam PHP-FPM akan membantu kita menunggu selesainya proses anak, yaitu perbaiki kesalahan tersebut. Penempatan berulang menggunakan arahan ini: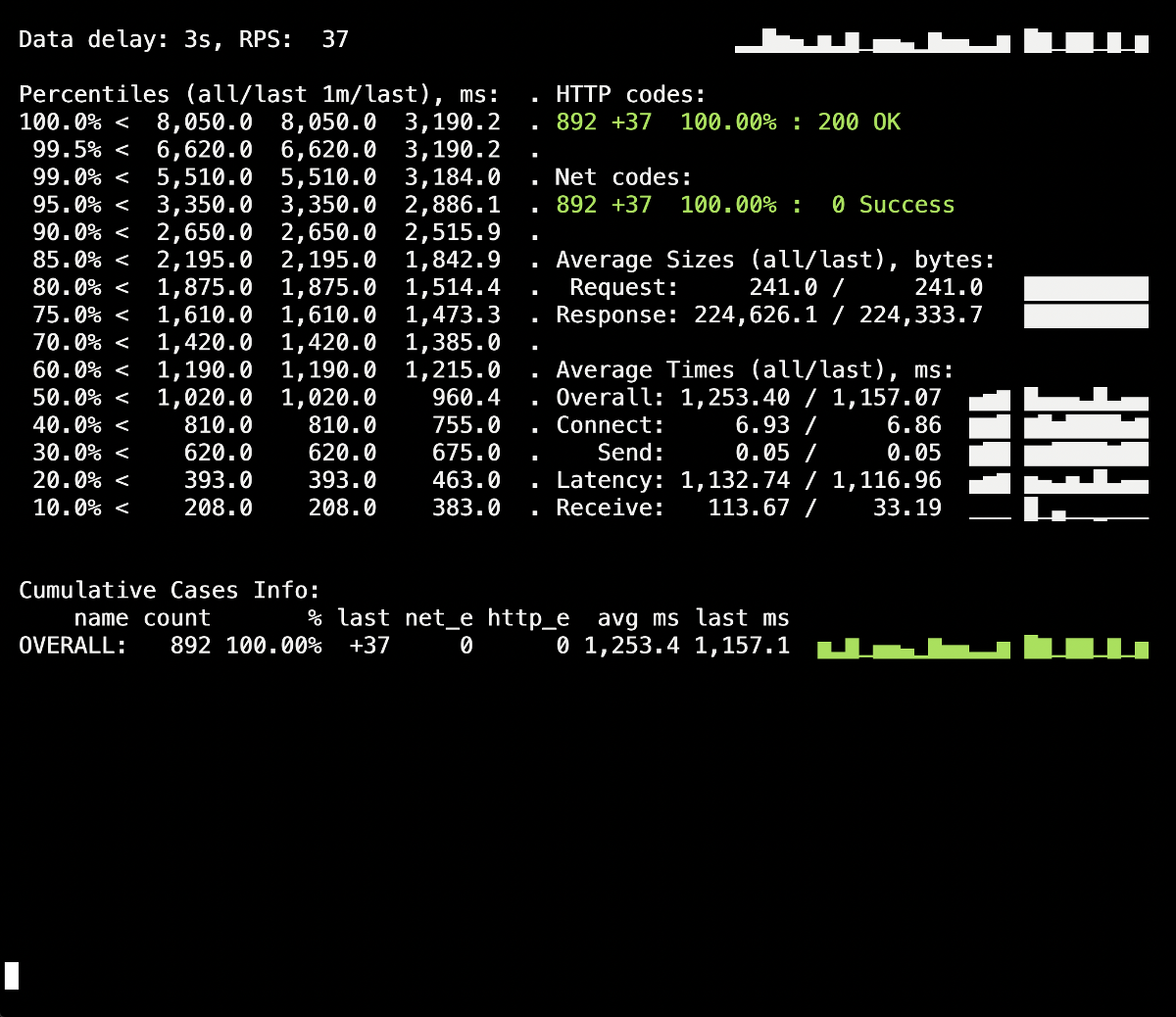 Tidak ada lagi kesalahan selama penyebaran 500-an! Penyebaran berhasil, shutdown yang anggun bekerja.Namun, ada baiknya mengingat momen dengan wadah Ingress, sebagian kecil kesalahan di mana kita bisa mendapatkan karena jeda waktu. Untuk menghindarinya, tetap tambahkan konstruksi dengan
Tidak ada lagi kesalahan selama penyebaran 500-an! Penyebaran berhasil, shutdown yang anggun bekerja.Namun, ada baiknya mengingat momen dengan wadah Ingress, sebagian kecil kesalahan di mana kita bisa mendapatkan karena jeda waktu. Untuk menghindarinya, tetap tambahkan konstruksi dengan sleepdan ulangi penyebaran. Namun, dalam kasus khusus kami, tidak ada perubahan yang terlihat (tidak ada kesalahan lagi).Kesimpulan
Untuk penyelesaian proses yang benar, kami mengharapkan perilaku berikut dari aplikasi:- Tunggu beberapa detik, lalu berhenti menerima koneksi baru.
- Tunggu semua permintaan untuk menyelesaikan dan menutup semua koneksi keepalive yang tidak menjalankan permintaan.
- Selesaikan proses Anda.
Namun, tidak semua aplikasi dapat bekerja dengan cara ini. Salah satu solusi untuk masalah dalam realitas Kubernetes adalah:- Menambahkan kait pre-stop yang akan menunggu beberapa detik
- mempelajari file konfigurasi backend kami untuk parameter yang relevan.
Contoh NGINX memungkinkan kita untuk memahami bahwa bahkan suatu aplikasi yang pada awalnya harus memproses dengan benar sinyal untuk penyelesaian mungkin tidak melakukan ini, sehingga sangat penting untuk memeriksa 500 kesalahan selama penyebaran aplikasi. Ini juga memungkinkan Anda untuk melihat masalah secara lebih luas dan tidak berkonsentrasi pada pod atau wadah yang terpisah, tetapi melihat keseluruhan infrastruktur secara keseluruhan.Yandex.Tank dapat digunakan sebagai alat pengujian bersama dengan sistem pemantauan (dalam kasus kami, data dari Grafana dengan backend dalam bentuk Prometheus diambil untuk pengujian). Masalah dengan shutdown anggun terlihat jelas di bawah beban berat yang dapat dihasilkan patokan, dan pemantauan membantu menganalisis situasi secara lebih rinci selama atau setelah pengujian.Menanggapi umpan balik pada artikel: perlu disebutkan bahwa masalah dan solusi dijelaskan di sini sehubungan dengan NGINX Ingress. Untuk kasus lain, ada solusi lain yang, mungkin, akan kita bahas dalam materi siklus berikut.PS
Lainnya dari siklus tips & trik K8: