Ketika Facebook "berbohong", orang berpikir itu karena peretas atau serangan DDoS, tetapi itu bukan. Semua "jatuh" selama beberapa tahun terakhir telah disebabkan oleh perubahan internal atau gangguan. Untuk mengajari karyawan baru agar tidak melanggar Facebook dengan contoh, semua insiden besar diberi nama, misalnya, "Panggil Polisi" atau "CAPSLOCK". Yang pertama dinamai karena ketika suatu hari jaringan sosial jatuh, pengguna menelepon polisi Los Angeles dan meminta untuk memperbaikinya, dan sheriff putus asa di Twitter meminta untuk tidak mengganggu mereka tentang hal ini. Selama insiden kedua pada mesin cache, antarmuka jaringan turun dan tidak naik, dan semua mesin restart dengan tangan.Elina Lobanovatelah bekerja di Facebook selama 4 tahun terakhir di tim Web Foundation. Anggota tim disebut insinyur produksi dan memantau keandalan dan kinerja seluruh backend, mengeluarkan Facebook saat aktif, menulis pemantauan dan otomatisasi untuk membuat hidup lebih mudah bagi diri mereka sendiri dan orang lain. Dalam sebuah artikel berdasarkan laporan Elina tentang HighLoad ++ 2019 , kami akan menunjukkan bagaimana para insinyur produksi memantau backend Facebook, alat apa yang mereka gunakan, yang menyebabkan crash besar dan bagaimana menghadapinya.Nama saya Elina, hampir 5 tahun yang lalu saya dipanggil di Facebook sebagai pengembang biasa, tempat saya pertama kali menemukan sistem yang sarat muatan - ini tidak diajarkan di institut. Perusahaan tidak menyewa tim, tetapi kantor, jadi saya tiba di London, memilih tim yang memantau pekerjaan facebook.com dan berada di antara insinyur produksi.
Dalam sebuah artikel berdasarkan laporan Elina tentang HighLoad ++ 2019 , kami akan menunjukkan bagaimana para insinyur produksi memantau backend Facebook, alat apa yang mereka gunakan, yang menyebabkan crash besar dan bagaimana menghadapinya.Nama saya Elina, hampir 5 tahun yang lalu saya dipanggil di Facebook sebagai pengembang biasa, tempat saya pertama kali menemukan sistem yang sarat muatan - ini tidak diajarkan di institut. Perusahaan tidak menyewa tim, tetapi kantor, jadi saya tiba di London, memilih tim yang memantau pekerjaan facebook.com dan berada di antara insinyur produksi.Insinyur Produksi
Untuk memulai, saya akan memberi tahu Anda apa yang kami lakukan dan mengapa kami disebut Insinyur Produksi, dan bukan SRE seperti Google, misalnya.2009. SRE
Model standar yang masih digunakan di banyak perusahaan adalah "pengembang - penguji - operasi". Seringkali mereka terpecah: mereka duduk di lantai yang berbeda, kadang-kadang bahkan di negara yang berbeda, dan tidak saling berkomunikasi.Pada 2009, Facebook sudah memiliki SRE. Di Google, SRE memulai lebih awal, mereka tahu cara mencapai DevOps, dan telah menuliskannya di buku mereka “ Rekayasa Keandalan Situs ”. Di Facebook pada tahun 2009, tidak ada yang seperti ini. Kami dipanggil SRE, tetapi kami melakukan pekerjaan yang sama dengan Ops di seluruh dunia: tenaga kerja manual, tanpa otomatisasi, penyebaran semua layanan dengan tangan Anda, memantau entah bagaimana, hanya memanggil semua, seperangkat skrip shell.
Di Facebook pada tahun 2009, tidak ada yang seperti ini. Kami dipanggil SRE, tetapi kami melakukan pekerjaan yang sama dengan Ops di seluruh dunia: tenaga kerja manual, tanpa otomatisasi, penyebaran semua layanan dengan tangan Anda, memantau entah bagaimana, hanya memanggil semua, seperangkat skrip shell.2010. SRO dan AppOps
Ini semua tidak skala, karena jumlah pengguna pada waktu itu tumbuh 3 kali per tahun, dan jumlah layanan bertambah. Pada tahun 2010, keputusan yang keras dari Ops dibagi menjadi dua kelompok.Kelompok pertama adalah SRO , di mana "O" adalah "operasi", yang terlibat dalam pengembangan, otomatisasi, dan pemantauan situs.Kelompok kedua adalah AppOps , mereka diintegrasikan ke dalam tim, masing-masing untuk layanan besar. AppOps sudah dekat dengan ide DevOps.Pemisahan untuk sementara waktu menyelamatkan semua orang.2012. Insinyur Produksi
Pada 2012, AppOps hanya mengganti nama insinyur produksi . Selain namanya, tidak ada yang berubah, tetapi telah menjadi lebih nyaman. Saat Anda memanggil kapal pesiar, kapal itu akan berlayar, dan kami tidak ingin berlayar seperti Ops.SRO masih ada, Facebook tumbuh, dan memonitor semua layanan sekaligus sulit. Seseorang yang dipanggil bahkan tidak diizinkan pergi ke toilet: dia meminta seseorang untuk menggantikannya, karena dia terus-menerus terbakar.2014. Menutup SRO
Pada satu titik, pihak berwenang memindahkan semua orang untuk menelepon. "Semua orang" berarti pengembang juga: tulis kode Anda, inilah Anda dan jawab untuk kode ini!Insinyur produksi telah diintegrasikan ke dalam tim yang paling penting untuk bantuan, dan sisanya tidak beruntung. Kami mulai dengan tim besar dan dalam beberapa tahun mentransfer semua orang di Facebook ke panggilan. Di antara pengembang ada kegembiraan besar: seseorang berhenti, seseorang menulis posting yang buruk. Tapi semuanya tenang, dan pada 2014 SRO ditutup karena tidak diperlukan lagi. Jadi kita hidup sampai hari ini.Kata "SRE" di perusahaan itu terkenal, tetapi kami terlihat seperti SRE di Google. Ada perbedaan.- Kami selalu dibangun dalam tim. Kami tidak memiliki pencarian SRE secara umum, seperti di Google, ini untuk setiap layanan pencarian secara terpisah.
- Kami tidak dalam produk , hanya dalam infrastruktur yang dikelola sendiri oleh produk.
- Kami terhubung dengan pengembang.
- Kami memiliki sedikit lebih banyak pengalaman dalam sistem dan jaringan, jadi kami fokus pada pemantauan dan memadamkan layanan ketika mereka menyala dengan cerah. Kami memperbaiki kesalahan sebelumnya yang dapat menyebabkan kerusakan dan memengaruhi arsitektur layanan baru sejak awal, sehingga nantinya dapat berfungsi dengan baik dalam produksi.
Pemantauan
Itu yang paling penting. Bagaimana kita melakukan ini? Seperti semua orang: tanpa sihir hitam, di rumah mereka sendiri. Tetapi iblis, seperti biasa, akan memberi tahu Anda tentang mereka secara terperinci.DI ATAS
Mari kita mulai dari bawah. Semua orang tahu TOP di Linux, dan kami menggunakan ATOP, di mana "A" "maju" - monitor kinerja sistem. Manfaat utama ATOP adalah menyimpan riwayat: Anda dapat mengonfigurasinya untuk menyimpan snapshot ke disk. ATOP kami beroperasi pada semua mesin setiap 5 detik.Berikut adalah contoh server yang menjalankan PHP backend untuk facebook.com. Kami menulis mesin virtual kami untuk mengeksekusi kode PHP, itu disebut HHVM (HipHop Virtual Machine). Menurut metrik yang diekspor, kami menemukan bahwa beberapa mesin tidak memproses hampir satu permintaan dalam satu menit. Mari kita lihat mengapa, buka ATOP 30 detik sebelum hang. Dapat dilihat bahwa dengan masalah prosesor, kami memuatnya terlalu banyak. Ada juga masalah dengan memori, hanya 1,5 GB yang tersisa di cache, dan setelah 5 detik hanya 800 MB.
Dapat dilihat bahwa dengan masalah prosesor, kami memuatnya terlalu banyak. Ada juga masalah dengan memori, hanya 1,5 GB yang tersisa di cache, dan setelah 5 detik hanya 800 MB. Setelah 5 detik berikutnya, CPU dibebaskan, tidak ada yang dijalankan. ATOP mengatakan lihat garis bawahnya, kita menulis ke disk, tapi apa? Ternyata kami menulis swap.
Setelah 5 detik berikutnya, CPU dibebaskan, tidak ada yang dijalankan. ATOP mengatakan lihat garis bawahnya, kita menulis ke disk, tapi apa? Ternyata kami menulis swap. Siapa yang melakukan ini? Proses yang diambil dari memori 0,5 GB dan dimasukkan ke swap. Di tempat mereka muncul dua proses Python yang mencurigakan, yang kemudian dapat dilihat sebagai baris perintah.
Siapa yang melakukan ini? Proses yang diambil dari memori 0,5 GB dan dimasukkan ke swap. Di tempat mereka muncul dua proses Python yang mencurigakan, yang kemudian dapat dilihat sebagai baris perintah.
ATOP itu indah, kami menggunakannya terus-menerus.
Jika Anda tidak memilikinya, saya sangat merekomendasikan menggunakannya. Jangan takut untuk drive, ATOP makan hanya 200-300 MB per hari setiap 5 detik.HTTP Malloc
Kepada Bahama dan insiden besar, kami memberi nama. Ada satu bug menyenangkan yang terkait dengan ATOP yang disebut Malloc HTTP. Kami memulai debutnya dengan ATOP dan strace.Kami menggunakan barang bekas di mana-mana sebagai RPC. Dalam versi awal parsernya ada bug luar biasa yang bekerja seperti ini: sebuah pesan tiba di mana 4 byte pertama adalah ukuran data, lalu data itu sendiri, dan byte pertama ditambahkan ke pesan berikutnya.Tapi begitu salah satu program daripada pergi ke layanan Thrift, saya pergi ke HTTP, dan mendapat respon «HTTP Bad Meminta»: HTTP/1.1 400.Setelah itu mengambil HTTP dan dialokasikan menggunakan malloc HTTP jumlah byte.Thrift message
HTTP/1.1 400
"HTTP" == 0x48545450
Tidak apa-apa, kami memiliki overkomit, mari mengalokasikan lebih banyak memori! Kami dialokasikan dengan malloc, dan sampai kami menulis dan membaca di sana, mereka tidak akan memberi kami memori nyata.Tapi itu tidak ada di sana! Jika kita ingin melakukan fork, fork akan mengembalikan kesalahan - tidak ada cukup memori.malloc("HTTP")
pid = fork(); // errno = ENOMEM
Tapi mengapa, ada ingatan? Memahami manual, kami menemukan bahwa semuanya sangat sederhana: konfigurasi overcommit saat ini sedemikian rupa sehingga merupakan heuristik ajaib, dan kernel itu sendiri memutuskan kapan banyak dan kapan tidak:malloc("HTTP")
pid = fork(); // errno = ENOMEM
// 0: heuristic overcommit
vm.overcommit_memory = 0
Untuk proses kerja, ini normal, Anda dapat memilih malloc hingga TB, tetapi untuk proses baru - tidak. Dan bagian dari pemantauan pada kami terkait dengan fakta bahwa proses utama bercabang skrip kecil untuk pengumpulan data. Akibatnya, bagian pemantauan kami rusak, karena kami tidak bisa lagi bercabang.FB303
FB303 adalah sistem pemantauan dasar kami. Itu dinamai synthesizer bass standar 1982. Prinsipnya sederhana, oleh karena itu, ia masih berfungsi: setiap layanan mengimplementasikan antarmuka getCounters Thrift.
Prinsipnya sederhana, oleh karena itu, ia masih berfungsi: setiap layanan mengimplementasikan antarmuka getCounters Thrift.Service FacebookService {
map<string, i64> getCounters()
}
Bahkan, dia tidak mengimplementasikannya, karena perpustakaan sudah ditulis, semuanya dilakukan dalam kode incrementatau set.incrementCounter(string& key);
setCounter(string& key, int64_t value);
Akibatnya, setiap layanan mengekspor penghitung di port yang terdaftar dengan Service Discovery. Di bawah ini adalah contoh dari mesin yang menghasilkan feed berita dan mengekspor sekitar 5,5 ribu pasang (string, angka): memori, produksi, apa pun. Setiap mesin menjalankan proses biner yang melewati semua layanan di sekitar, mengumpulkan penghitung ini dan menempatkannya di penyimpanan.Ini adalah apa yang tampak seperti GUI penyimpanan .
Setiap mesin menjalankan proses biner yang melewati semua layanan di sekitar, mengumpulkan penghitung ini dan menempatkannya di penyimpanan.Ini adalah apa yang tampak seperti GUI penyimpanan . Sangat mirip dengan Prometheus dan Grafana, tetapi ternyata tidak. Entri FB303 pertama di GitHub adalah pada tahun 2009, dan Prometheus pada tahun 2012. Ini adalah penjelasan dari semua "do-it-yourselfers" dari Facebook: kami melakukannya ketika tidak ada yang normal di Open Source.Misalnya, ada pencarian nama-nama penghitung.
Sangat mirip dengan Prometheus dan Grafana, tetapi ternyata tidak. Entri FB303 pertama di GitHub adalah pada tahun 2009, dan Prometheus pada tahun 2012. Ini adalah penjelasan dari semua "do-it-yourselfers" dari Facebook: kami melakukannya ketika tidak ada yang normal di Open Source.Misalnya, ada pencarian nama-nama penghitung. Grafiknya sendiri terlihat seperti ini.
Grafiknya sendiri terlihat seperti ini. Gambar dari grup dalam tempat kami memposting gambar yang indah.Perbedaan penting antara tumpukan pemantauan kami dan Prometheus dan Grafana adalah bahwa kami menyimpan data selamanya . Pemantauan kami akan sampel ulang data, dan setelah 2 minggu kami akan memiliki satu poin untuk setiap 5 menit, dan setelah satu tahun untuk setiap jam. Karena itu, mereka dapat disimpan begitu banyak. Secara otomatis ini tidak dikonfigurasi di mana saja.Tetapi jika kita berbicara tentang fitur pemantauan Facebook, maka saya akan menggambarkannya dengan satu kata Inggris " observability" .
Gambar dari grup dalam tempat kami memposting gambar yang indah.Perbedaan penting antara tumpukan pemantauan kami dan Prometheus dan Grafana adalah bahwa kami menyimpan data selamanya . Pemantauan kami akan sampel ulang data, dan setelah 2 minggu kami akan memiliki satu poin untuk setiap 5 menit, dan setelah satu tahun untuk setiap jam. Karena itu, mereka dapat disimpan begitu banyak. Secara otomatis ini tidak dikonfigurasi di mana saja.Tetapi jika kita berbicara tentang fitur pemantauan Facebook, maka saya akan menggambarkannya dengan satu kata Inggris " observability" .Observabilitas
Ada "kotak hitam", ada "kotak putih", dan kami memiliki "kotak" transparan kaca. Ini berarti bahwa ketika kita menulis kode, kita menulis semua yang mungkin dalam log, dan tidak secara selektif. Pengambilan sampel dilakukan dengan baik di mana-mana, sehingga backend untuk penyimpanan, penghitung, dan yang lainnya hidup dengan baik.Pada saat yang sama, kami dapat membangun dasbor kami di atas penghitung yang ada. Dalam hal mempelajari dasbor ini, ini bukan titik akhir dengan 10 grafik, tetapi yang pertama, dari mana kita pergi ke UI kita dan menemukan segala sesuatu di sana yang mungkin.Scuba
Inilah klimaks dari gagasan observabilitas. Ini adalah tumpukan ELK kami. Prinsipnya sama: kita menulis dalam JSON tanpa skema khusus, lalu kita meminta dalam bentuk tabel , rangkaian waktu data, atau 10 opsi visualisasi lainnya.Log scuba dalam urutan ratusan gigabyte per detik. Semuanya diminta dengan sangat cepat, karena itu bukan Elasticsearch, dan semuanya ada di memori pada mesin yang kuat. Ya, uang dihabiskan untuk itu, tetapi betapa indahnya itu!Misalnya, di bawah Scuba UI, salah satu tabel paling populer dibuka di dalamnya, di mana semua klien dari semua layanan Hemat menulis log.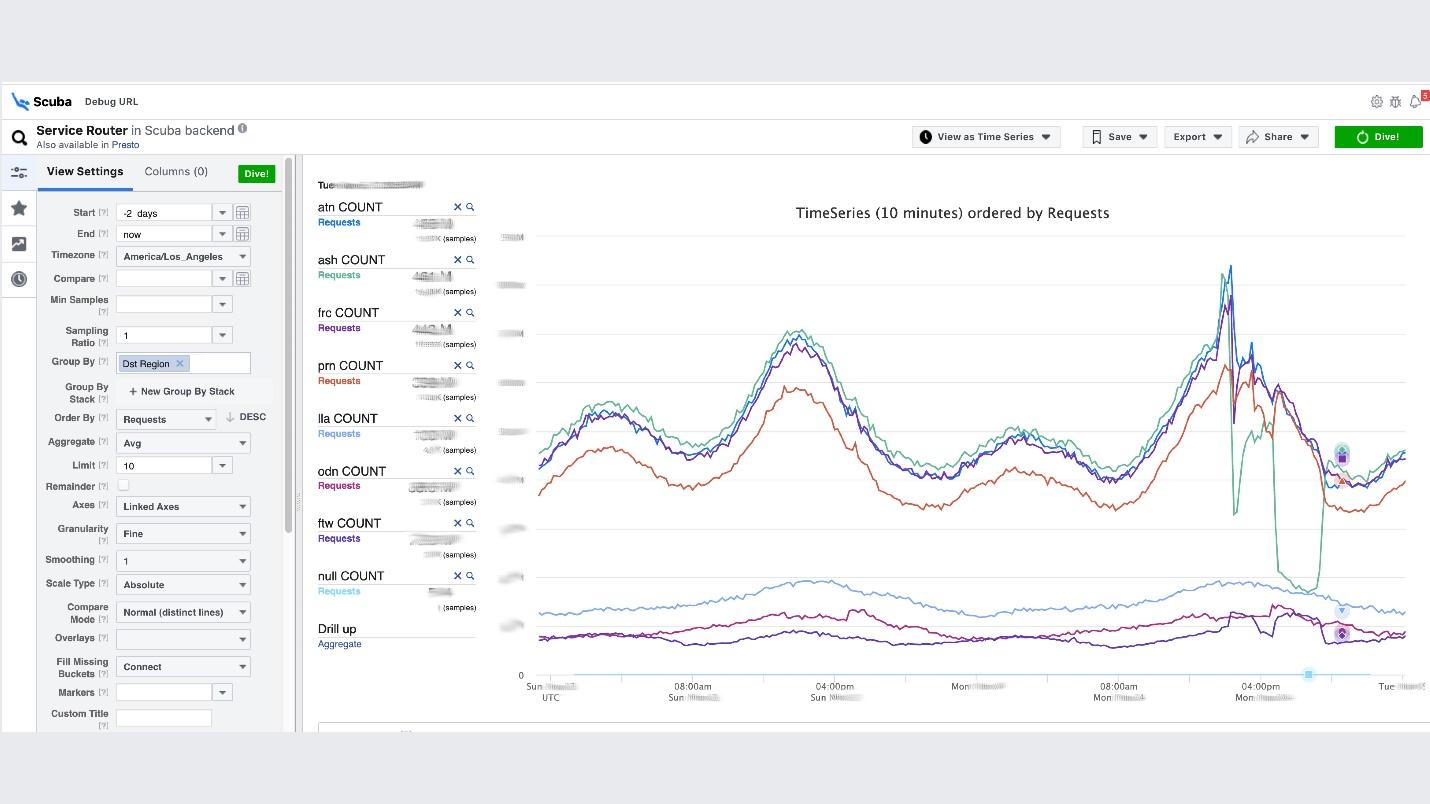 Grafik menunjukkan bahwa pada akhirnya, ada yang salah dalam layanan. Untuk mengetahui penundaan, buka daftar penghitung, pilih penundaan, agregasi, klik "Menyelam".
Grafik menunjukkan bahwa pada akhirnya, ada yang salah dalam layanan. Untuk mengetahui penundaan, buka daftar penghitung, pilih penundaan, agregasi, klik "Menyelam".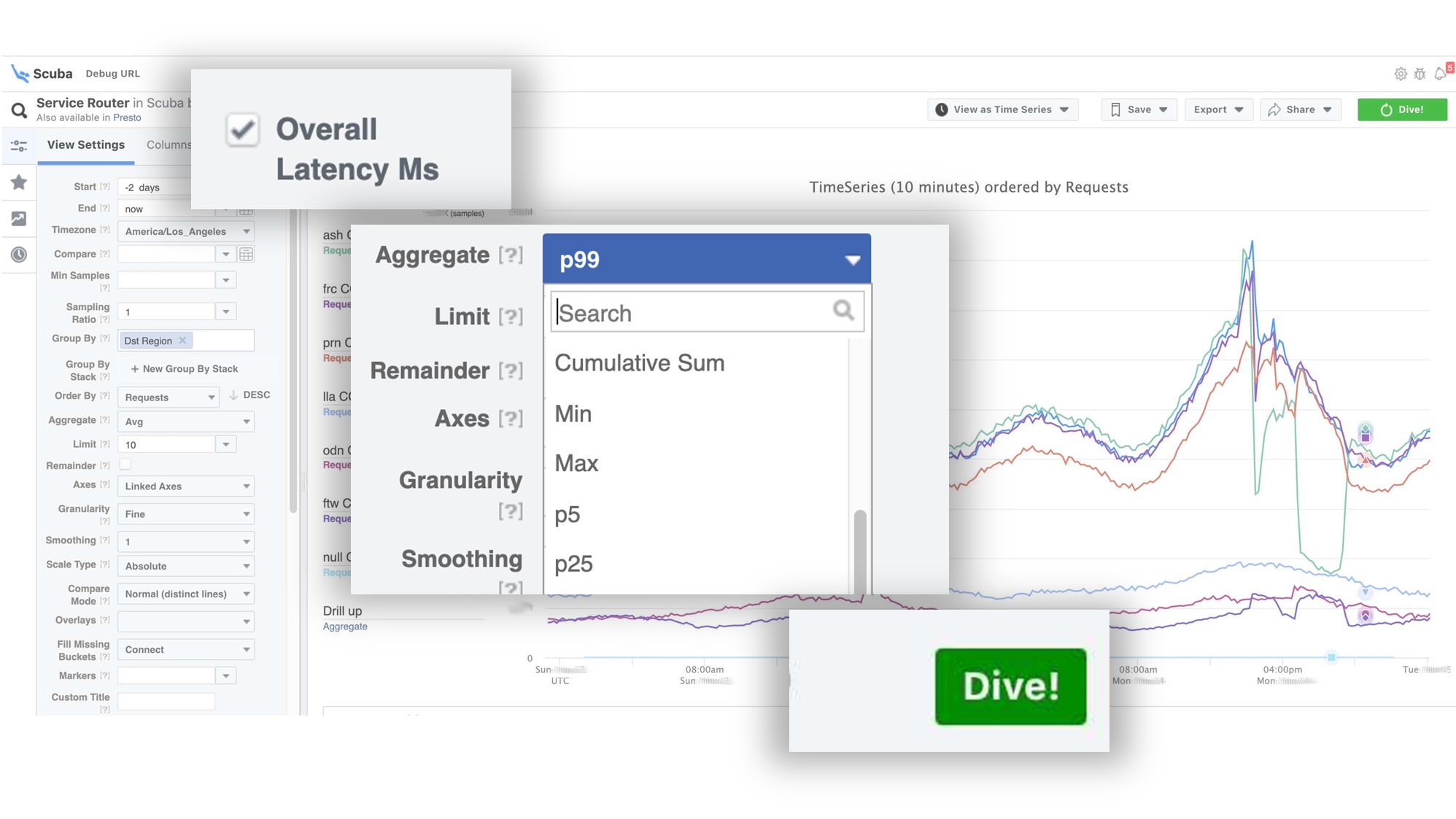 Jawabannya datang dalam 2 detik.
Jawabannya datang dalam 2 detik.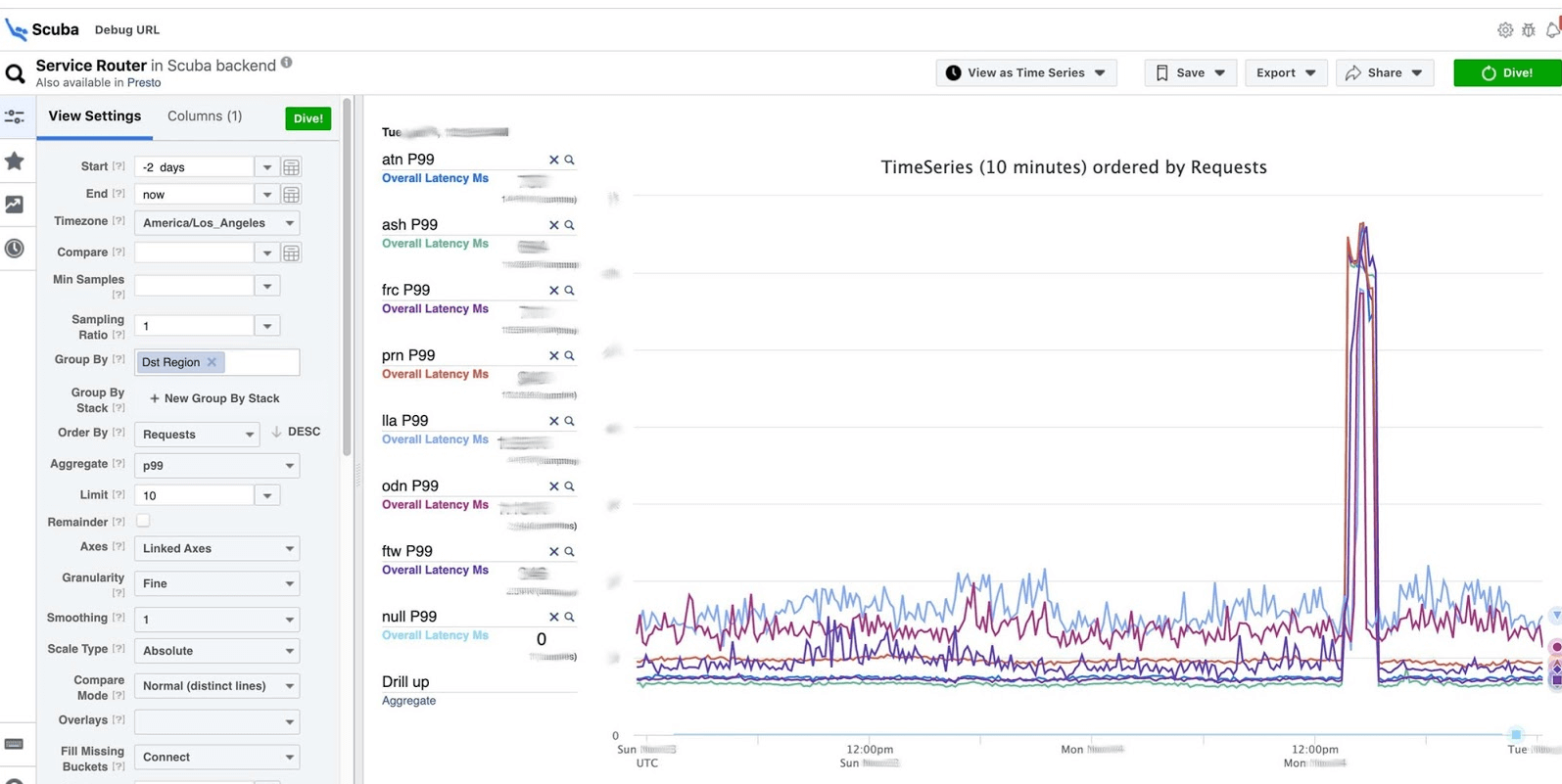 Dapat dilihat bahwa pada saat itu sesuatu terjadi dan penundaan meningkat secara signifikan. Untuk mempelajari lebih lanjut, Anda dapat mengelompokkan berdasarkan parameter yang berbeda.Ada ratusan meja seperti itu.
Dapat dilihat bahwa pada saat itu sesuatu terjadi dan penundaan meningkat secara signifikan. Untuk mempelajari lebih lanjut, Anda dapat mengelompokkan berdasarkan parameter yang berbeda.Ada ratusan meja seperti itu.- Tabel yang memperlihatkan versi file biner, paket, berapa banyak memori yang dimakan pada jutaan mesin. Pada setiap host, PS dibuat satu jam sekali dan dikirim ke Scuba.
- Semua dmesg, semua dump memori, dikirim ke tabel lain. Kami menjalankan Perf sekali setiap 10 menit pada setiap mesin, jadi kami tahu jejak tumpukan yang kami miliki di kernel dan apa yang dapat dimuat CPU global.
Debug PHP
Scuba juga menyediakan backend untuk alat debugging inti PHP kami. Ribuan insinyur menulis kode PHP, dan entah bagaimana Anda perlu menyimpan repositori global dari hal-hal buruk.Bagaimana cara kerjanya? PHP juga menulis jejak stack untuk setiap log. Scuba (Elasticsearch kami) tidak dapat menampung jejak stack dari semua log dari semua mesin. Sebelum memasukkan log ke dalam Scuba, kami mengonversi jejak tumpukan menjadi hash, sampel dengan hash dan hanya menyimpannya. Jejak tumpukan itu sendiri dikirim ke Memcached. Kemudian, di alat internal, Anda dapat menarik jejak tumpukan tertentu dari Memcached dengan cukup cepat. Visualisasi dengan pengelompokan hash dari log dan jejak stack.Kami men-debug kode menggunakan metode pencocokan pola : buka Scuba, lihat bagaimana grafik kesalahannya.
Visualisasi dengan pengelompokan hash dari log dan jejak stack.Kami men-debug kode menggunakan metode pencocokan pola : buka Scuba, lihat bagaimana grafik kesalahannya.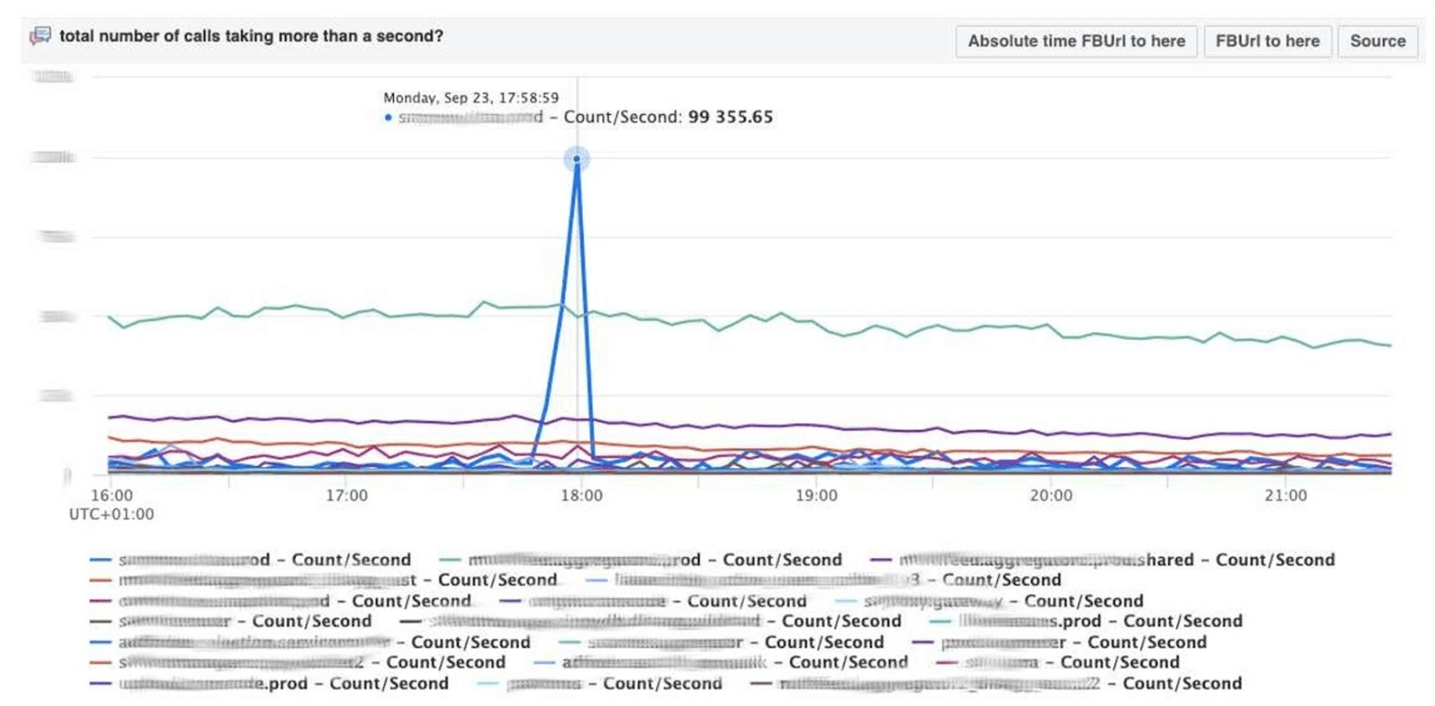 Kami pergi ke LogView, ada kesalahan yang sudah dikelompokkan berdasarkan jejak tumpukan.
Kami pergi ke LogView, ada kesalahan yang sudah dikelompokkan berdasarkan jejak tumpukan. Jejak tumpukan dimuat dari Memcached, dan di atasnya Anda sudah dapat menemukan diff (komit dalam repositori PHP), yang diposting pada waktu yang hampir bersamaan, dan memutar kembali. Siapa pun dapat mundur dan berkomitmen dengan kami, tidak ada izin yang diperlukan untuk ini.
Jejak tumpukan dimuat dari Memcached, dan di atasnya Anda sudah dapat menemukan diff (komit dalam repositori PHP), yang diposting pada waktu yang hampir bersamaan, dan memutar kembali. Siapa pun dapat mundur dan berkomitmen dengan kami, tidak ada izin yang diperlukan untuk ini.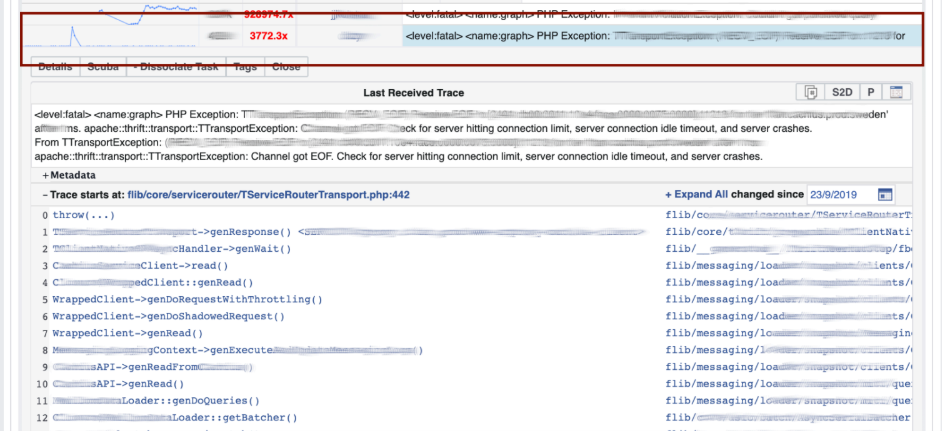
Dasbor
Saya akan mengakhiri topik pemantauan dengan dasbor. Kami memiliki beberapa dari mereka - hanya dua per tiga indikator. Dasbornya sendiri agak tidak biasa. Saya ingin berbicara lebih banyak tentang dia. Di bawah ini adalah dasbor standar dengan satu set grafik.Sayangnya, tidak begitu sederhana dengannya. Faktanya adalah bahwa garis ungu pada satu grafik adalah layanan yang sama dengan garis biru sesuai dengan pada grafik lainnya, dan grafik lain dapat dalam satu hari dan lainnya dalam sebulan.Kami menggunakan dasbor kami berdasarkan Cubism - pustaka JS Open Source. Itu ditulis di Square dan dirilis di bawah lisensi Apache. Mereka memiliki dukungan bawaan untuk Graphite dan Cube. Tetapi mudah untuk berkembang, yang telah kami lakukan.Dasbor di bawah ini menunjukkan satu hari pada satu piksel per menit. Setiap baris adalah wilayah: pusat data yang ada di dekatnya. Mereka menampilkan jumlah log yang ditulis backend Facebook dalam byte per detik. Di bawah ini adalah penjelasan untuk tim di Amerika untuk melihat apa yang telah kami perbaiki dari apa yang terjadi pada siang hari. Sangat mudah untuk mencari korelasi dalam gambar ini.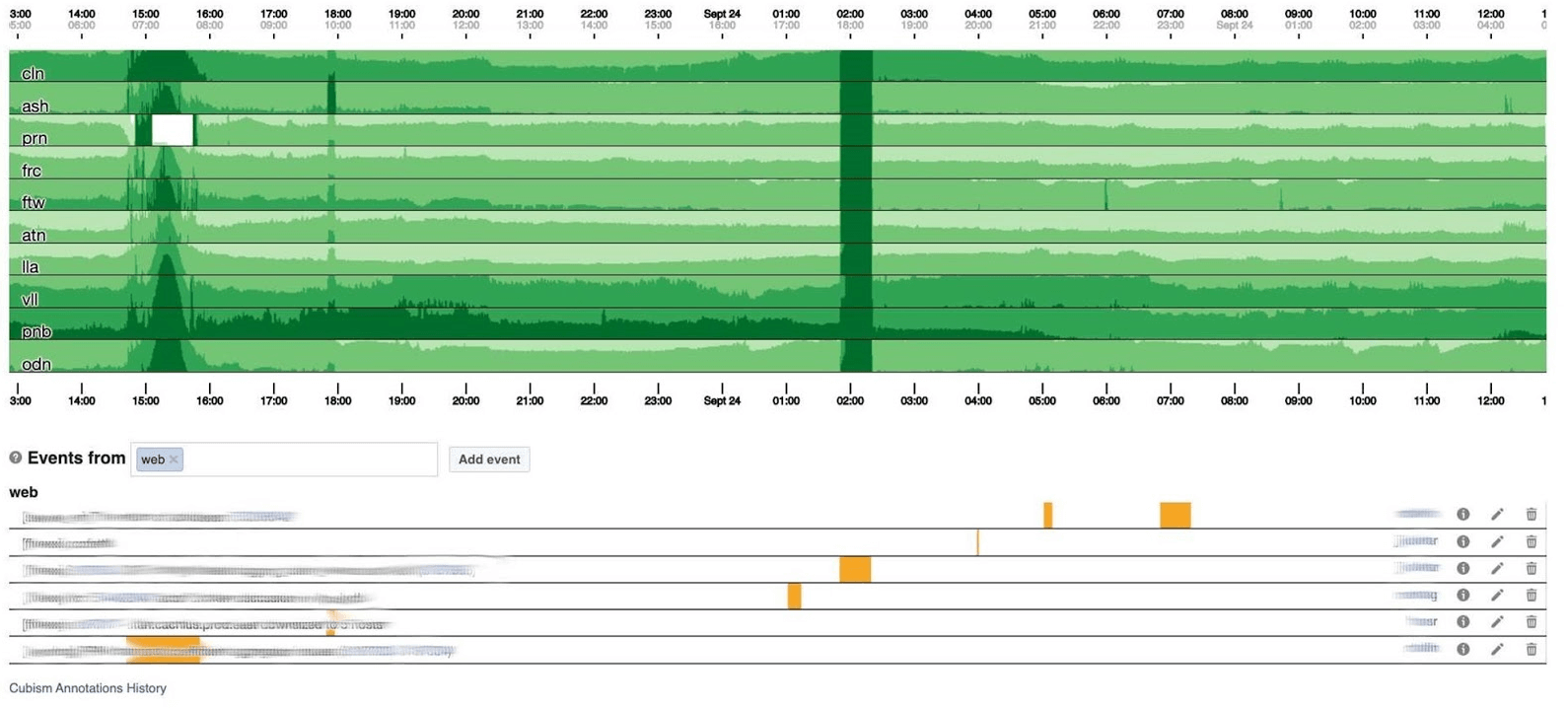 Di bawah ini adalah jumlah kesalahan 500. Apa di sebelah kiri tidak masalah bagi pengguna, dan jelas mereka tidak suka garis hijau gelap di tengah.
Di bawah ini adalah jumlah kesalahan 500. Apa di sebelah kiri tidak masalah bagi pengguna, dan jelas mereka tidak suka garis hijau gelap di tengah.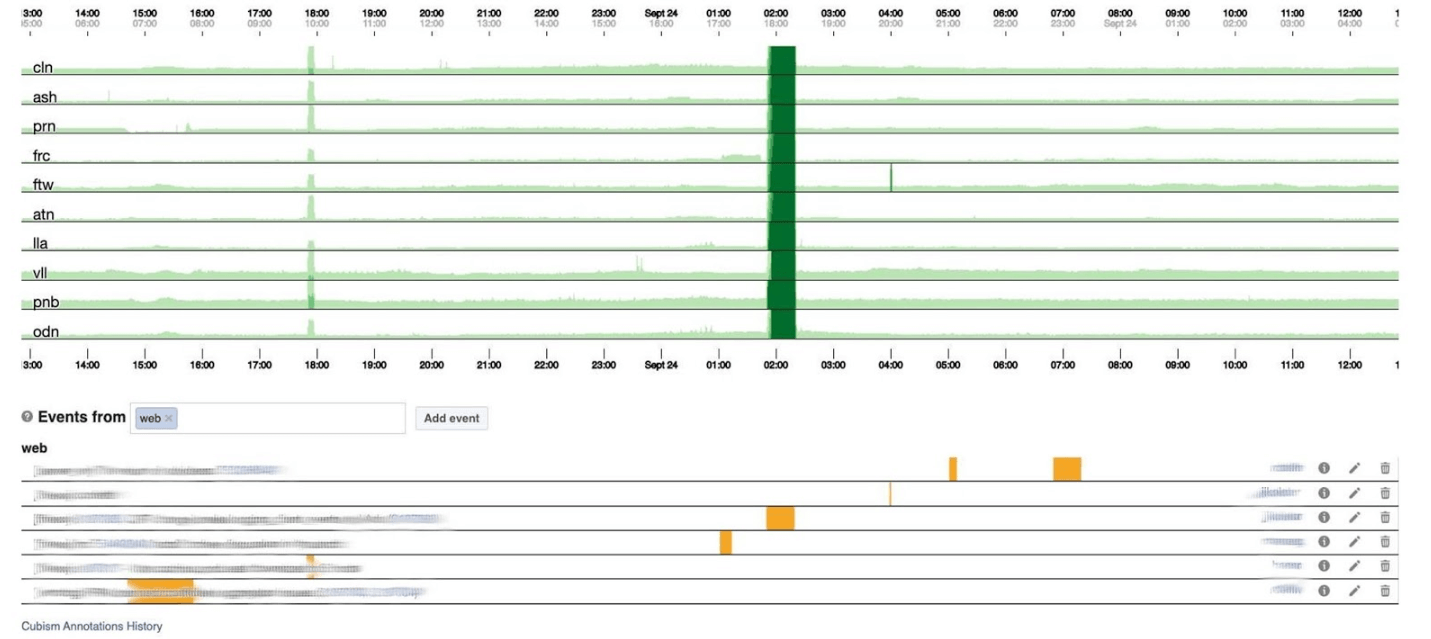 Berikutnya adalah latensi persentil ke-99. Pada saat yang sama, seperti pada grafik di atas, dapat dilihat bahwa latensi menurun. Untuk mengembalikan kesalahan, tidak perlu menghabiskan banyak waktu.
Berikutnya adalah latensi persentil ke-99. Pada saat yang sama, seperti pada grafik di atas, dapat dilihat bahwa latensi menurun. Untuk mengembalikan kesalahan, tidak perlu menghabiskan banyak waktu.
Bagaimana itu bekerja
Pada grafik setinggi 120 piksel, semuanya terlihat. Tetapi banyak dari ini tidak dapat ditempatkan di satu dasbor, jadi kami akan menekan ke 30. Sayangnya, kemudian kami mendapatkan semacam boa constrictor. Mari kita kembali dan melihat apa yang dilakukan Kubisme dengannya. Dia memecah grafik menjadi 4 bagian: semakin tinggi, semakin gelap, dan kemudian runtuh.
Sayangnya, kemudian kami mendapatkan semacam boa constrictor. Mari kita kembali dan melihat apa yang dilakukan Kubisme dengannya. Dia memecah grafik menjadi 4 bagian: semakin tinggi, semakin gelap, dan kemudian runtuh. Sekarang kita memiliki jadwal yang sama seperti sebelumnya, tetapi semuanya terlihat jelas: semakin gelap hijau, semakin buruk. Sekarang jauh lebih jelas apa yang terjadi.Di sebelah kiri Anda dapat melihat gelombang ketika naik, dan di tengah, di mana hijau gelap, semuanya sangat buruk.
Sekarang kita memiliki jadwal yang sama seperti sebelumnya, tetapi semuanya terlihat jelas: semakin gelap hijau, semakin buruk. Sekarang jauh lebih jelas apa yang terjadi.Di sebelah kiri Anda dapat melihat gelombang ketika naik, dan di tengah, di mana hijau gelap, semuanya sangat buruk.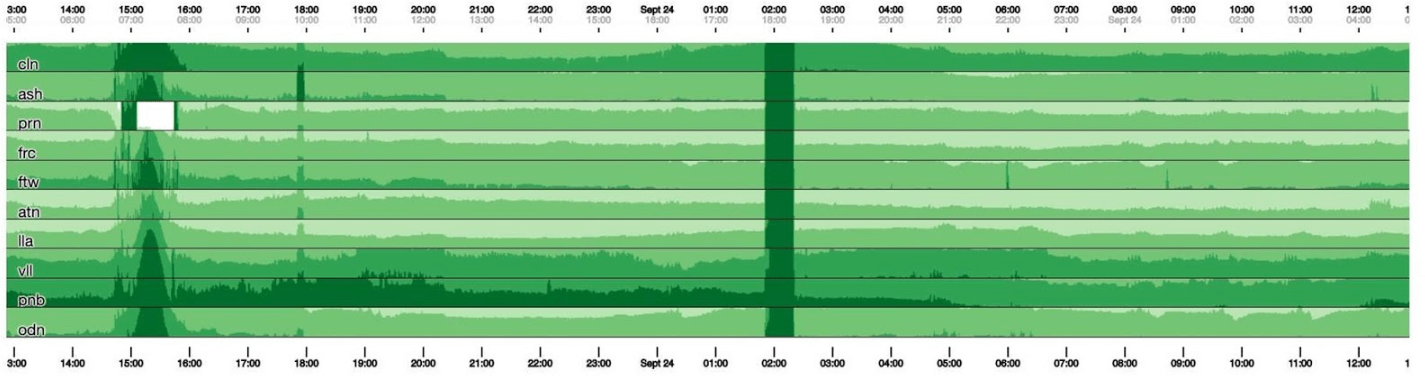 Kubisme hanyalah awal. Diperlukan untuk visualisasi, untuk memahami apakah semuanya buruk sekarang atau tidak. Untuk setiap tabel, sudah ada dashboard dengan grafik terperinci.
Kubisme hanyalah awal. Diperlukan untuk visualisasi, untuk memahami apakah semuanya buruk sekarang atau tidak. Untuk setiap tabel, sudah ada dashboard dengan grafik terperinci. Pemantauan dengan sendirinya membantu untuk memahami keadaan sistem dan merespons jika rusak. Di Facebook, setiap karyawan yang dipanggil harus dapat memperbaiki semuanya. Jika menyala terang, maka semuanya dihidupkan, tetapi terutama insinyur produksi dengan pengalaman administrator sistem, karena mereka tahu bagaimana menyelesaikan masalah dengan cepat.
Pemantauan dengan sendirinya membantu untuk memahami keadaan sistem dan merespons jika rusak. Di Facebook, setiap karyawan yang dipanggil harus dapat memperbaiki semuanya. Jika menyala terang, maka semuanya dihidupkan, tetapi terutama insinyur produksi dengan pengalaman administrator sistem, karena mereka tahu bagaimana menyelesaikan masalah dengan cepat.Saat Facebook berbaring
Terkadang insiden terjadi, dan Facebook berbohong. Biasanya orang berpikir bahwa Facebook berbohong karena diserang DDoS atau peretas, tetapi dalam 5 tahun itu tidak pernah terjadi. Alasannya selalu menjadi insinyur kami. Mereka tidak sengaja: sistemnya sangat kompleks dan dapat rusak di mana Anda tidak menunggu.Kami memberikan nama untuk semua insiden besar sehingga mudah untuk menyebutkan dan memberi tahu pendatang baru tentang mereka agar tidak mengulangi kesalahan di masa depan. Sang juara dengan nama terlucu adalah insiden Call the Cops . Orang-orang memanggil polisi Los Angeles dan meminta untuk memperbaiki Facebook karena berbohong. Sherif Los Angeles begitu muak sehingga ia menulis tweet, "Tolong jangan panggil kami!" Kami tidak bertanggung jawab untuk ini! " Kejadian favorit saya di mana saya berpartisipasi disebut CAPSLOCK.. Sangat menarik karena menunjukkan bahwa apa pun bisa terjadi. Dan inilah yang terjadi. Ini alamat obychnyyIP:
Kejadian favorit saya di mana saya berpartisipasi disebut CAPSLOCK.. Sangat menarik karena menunjukkan bahwa apa pun bisa terjadi. Dan inilah yang terjadi. Ini alamat obychnyyIP: fd3b:5679:92eb:9ce4::1.Facebook menggunakan Chef untuk menyesuaikan OS. Inventaris Layanan menyimpan konfigurasi host dalam basis datanya, dan Chef menerima file konfigurasi dari layanan. Setelah layanan mengubah versinya, mulai membaca alamat IP dari database segera dalam format MySQL dan meletakkannya dalam file. Alamat baru sekarang ditulis di ibukota: FD3B:5679:92EB:9CE4::1.Dia melihat file baru dan melihat bahwa alamat IP telah "berubah" karena membandingkan, bukan dalam bentuk biner, tetapi dengan string. Alamat IP adalah "baru", yang berarti Anda harus menurunkan antarmuka dan menaikkan antarmuka. Pada semua jutaan mobil dalam 15 menit, antarmuka turun dan naik.Tampaknya tidak apa-apa - kapasitas menurun saat jaringan terbaring di beberapa mesin. Tetapi sebuah bug tiba-tiba terbuka di driver jaringan kartu jaringan khusus kami: saat startup, mereka membutuhkan 0,5 GB memori fisik berurutan. Pada mesin cache, 0,5 GB itu menghilang saat kami menurunkan dan menaikkan antarmuka. Oleh karena itu, pada mesin cache, antarmuka jaringan turun dan tidak naik, dan tidak ada yang berhasil tanpa cache. Kami duduk dan menyalakan kembali mesin-mesin ini dengan tangan kami. Itu menyenangkan.Portal Manajer Insiden
Ketika Facebook "terbakar", diperlukan untuk mengatur pekerjaan "pemadam kebakaran", dan yang paling penting, untuk memahami di mana ia terbakar, karena di sebuah perusahaan besar ia dapat "mencium bau terbakar" di satu tempat, tetapi masalahnya ada di tempat lain. Alat UI yang disebut Portal Insiden Manajer membantu kami dalam hal ini . Itu ditulis oleh insinyur produksi, dan ini terbuka untuk semua. Segera setelah sesuatu terjadi, kami memulai insiden di sana: nama, awal, deskripsi.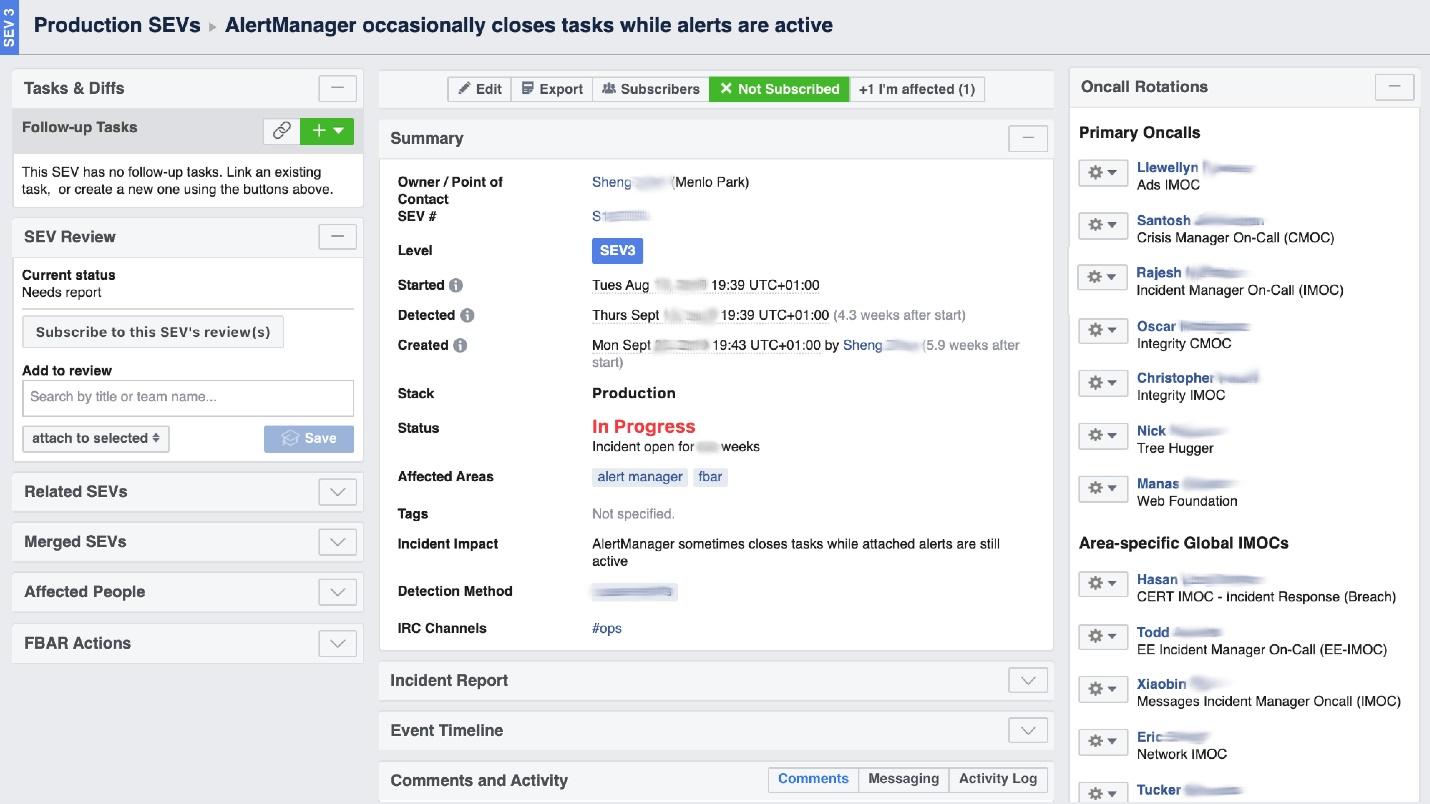 Kami memiliki orang yang terlatih khusus - Incident Manager On-Call (IMOC). Ini bukan posisi permanen; manajer secara teratur berubah. Dalam kasus kebakaran besar, IMOC mengatur dan mengoordinasikan orang untuk diperbaiki, tetapi tidak harus memperbaikinya sendiri. Segera setelah insiden dengan tingkat bahaya tinggi dibuat, IMOC menerima SMS dan mulai membantu mengatur segalanya. Dalam sistem yang besar, orang-orang seperti itu tidak dapat disingkirkan.
Kami memiliki orang yang terlatih khusus - Incident Manager On-Call (IMOC). Ini bukan posisi permanen; manajer secara teratur berubah. Dalam kasus kebakaran besar, IMOC mengatur dan mengoordinasikan orang untuk diperbaiki, tetapi tidak harus memperbaikinya sendiri. Segera setelah insiden dengan tingkat bahaya tinggi dibuat, IMOC menerima SMS dan mulai membantu mengatur segalanya. Dalam sistem yang besar, orang-orang seperti itu tidak dapat disingkirkan.Pencegahan
Facebook tidak begitu umum. Sebagian besar waktu kami tidak memadamkan api dan tidak me-restart mesin cache, tapi kami memperbaiki bug sebelumnya, dan, jika mungkin, untuk semua orang sekaligus.Setelah kami menemukan dan memperbaiki "masalah antrian." Jumlah permintaan meningkat sebesar 50%, dan kesalahan sebesar 100%, karena tidak ada pelambatan yang mengimplementasikan terlebih dahulu, terutama dalam layanan kecil.Kami menemukan contoh beberapa layanan dan secara kasar mendefinisikan model perilaku.- Di bawah beban normal, permintaan tiba, diproses dan dikembalikan ke klien.
- Dengan beban tinggi, permintaan menunggu dalam antrian karena semua utas untuk memproses permintaan sibuk. Penundaan meningkat, tetapi sejauh ini semuanya baik-baik saja.
- Garis tumbuh, beban meningkat. Pada titik tertentu, semua yang dijalankan server pada klien diakhiri dengan batas waktu respons, dan klien terjatuh karena kesalahan. Pada titik ini, hasil dari server dapat dibuang begitu saja.
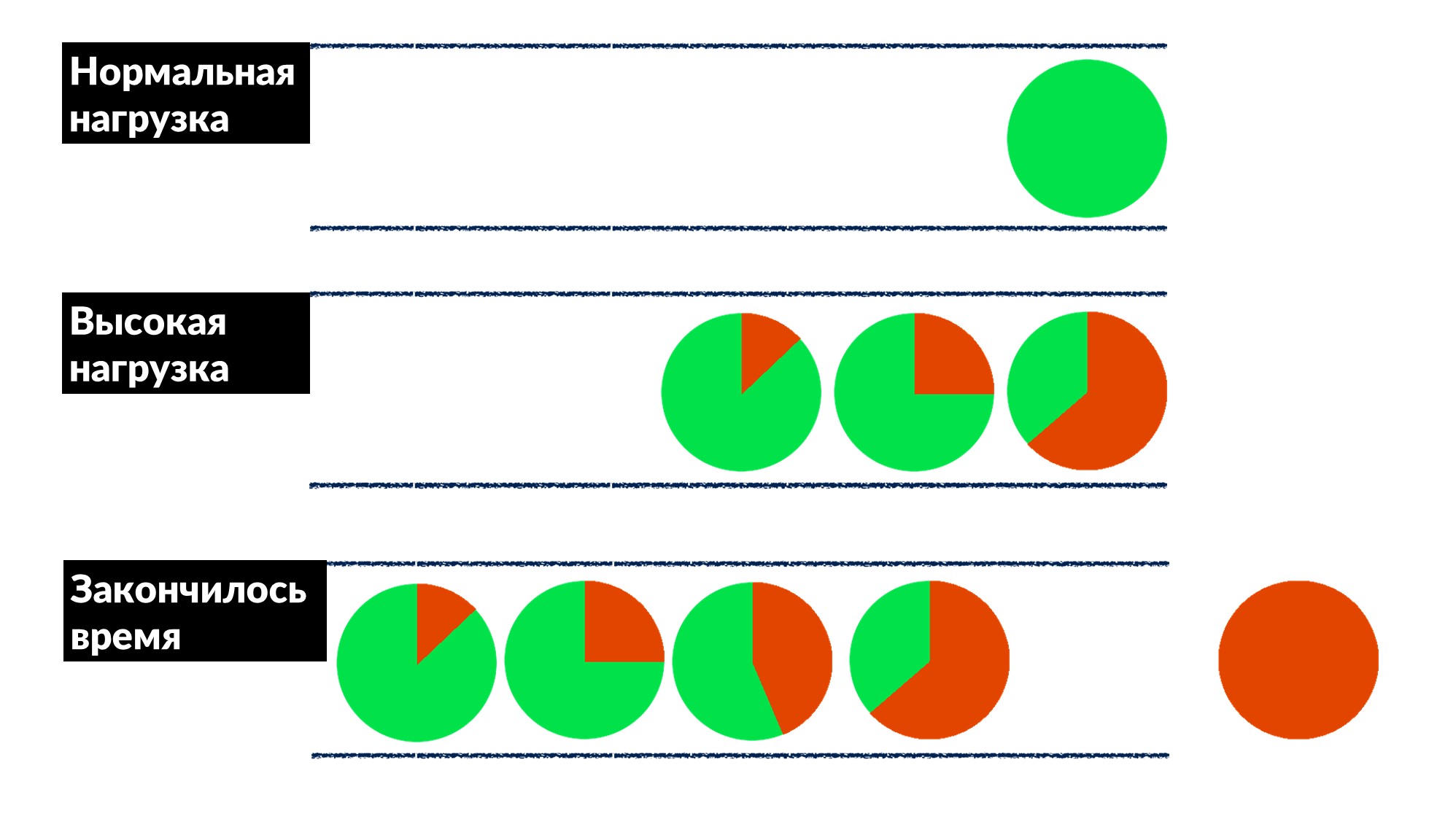 Batas waktu klien disorot dalam warna merah.Dan klien mengulangi lagi! Ternyata semua permintaan yang kami jalankan dibuang ke tempat sampah dan tidak ada yang membutuhkannya lagi.Bagaimana mengatasi masalah ini untuk semua orang sekaligus? Memperkenalkan batas waktu tunggu dalam antrian. Jika permintaan dalam antrian lebih dari yang diharapkan, kami membuangnya dan tidak memprosesnya di server, kami tidak membuang CPU di atasnya. Kami mendapatkan permainan yang jujur: kami membuang semua yang tidak dapat kami proses, dan semua yang kami bisa - diproses.Pembatasan ini memungkinkan, sambil meningkatkan beban hingga 50% di atas batas maksimum, untuk tetap memproses 66% permintaan dan hanya menerima 33% kesalahan. Pengembang kerangka kerja untuk Dispatch menerapkan ini di sisi server, dan kami, insinyur produksi, dengan lembut menyelesaikan batas waktu 100 ms dalam antrian untuk semua orang. Jadi semua layanan segera mendapat pembatasan dasar murah.
Batas waktu klien disorot dalam warna merah.Dan klien mengulangi lagi! Ternyata semua permintaan yang kami jalankan dibuang ke tempat sampah dan tidak ada yang membutuhkannya lagi.Bagaimana mengatasi masalah ini untuk semua orang sekaligus? Memperkenalkan batas waktu tunggu dalam antrian. Jika permintaan dalam antrian lebih dari yang diharapkan, kami membuangnya dan tidak memprosesnya di server, kami tidak membuang CPU di atasnya. Kami mendapatkan permainan yang jujur: kami membuang semua yang tidak dapat kami proses, dan semua yang kami bisa - diproses.Pembatasan ini memungkinkan, sambil meningkatkan beban hingga 50% di atas batas maksimum, untuk tetap memproses 66% permintaan dan hanya menerima 33% kesalahan. Pengembang kerangka kerja untuk Dispatch menerapkan ini di sisi server, dan kami, insinyur produksi, dengan lembut menyelesaikan batas waktu 100 ms dalam antrian untuk semua orang. Jadi semua layanan segera mendapat pembatasan dasar murah.Alat
Ideologi SRE mengatakan bahwa jika Anda memiliki armada besar mobil, banyak layanan, dan tidak ada hubungannya dengan tangan Anda, maka Anda perlu mengotomatisasi. Karena itu, separuh waktu kita menulis kode dan membangun alat.- Kubisme terintegrasi ke dalam sistem.
- FBAR adalah "pekerja keras" yang datang dan memperbaiki, jadi tidak ada yang khawatir tentang satu mobil yang rusak. Ini adalah tugas utama FBAR, tetapi sekarang ia memiliki lebih banyak tugas.
- Coredumper , yang kami tulis bersama dua rekan . Ini memantau coredumps pada semua mesin dan menjatuhkan mereka di satu tempat bersama dengan jejak tumpukan dengan semua informasi host: di mana letaknya, bagaimana menemukan ukuran apa. Tapi yang paling penting, jejak stack gratis, tanpa memulai GDB menggunakan program BPF.
Polling
Hal terakhir yang kami lakukan adalah berbicara dengan orang-orang, mewawancarai mereka. Tampaknya bagi kita ini sangat penting.Satu jajak pendapat yang berguna adalah tentang keandalan. Kami bertanya tentang sudah menjalankan layanan dalam kutipan kunci dari kuesioner kami:"Tanggung jawab utama perangkat lunak sistem harus terus berjalan. Memberikan layanan harus dilihat sebagai efek samping yang menguntungkan dari kelanjutan operasi »
Ini berarti bahwa tugas utama sistem adalah untuk terus bekerja, dan fakta bahwa ia menyediakan semacam layanan adalah bonus tambahan.Survei hanya untuk layanan menengah, yang besar sendiri mengerti. Kami memberikan kuesioner di mana kami menanyakan hal-hal dasar tentang arsitektur, SLO, pengujian, misalnya.- "Apa yang terjadi jika sistem Anda mendapat 10% dari beban?" Ketika orang berpikir: "Tapi sungguh, apa?" - wawasan muncul, dan bahkan banyak yang memerintah sistem mereka. Sebelumnya, mereka tidak memikirkannya, tetapi setelah pertanyaan ada alasan.
- "Siapa yang pertama kali biasanya melihat masalah dengan layanan Anda - Anda atau pengguna Anda?" Pengembang mulai mengingat ketika ini terjadi dan: "... Mungkin Anda perlu menambahkan peringatan."
- "Apa rasa sakit terbesarmu saat menelepon?" Ini tidak biasa bagi pengembang, terutama yang baru. Mereka segera berkata: “Kami memiliki banyak peringatan! Mari kita bersihkan dan singkirkan yang tidak. ”
- "Seberapa sering pelepasanmu?" Pertama mereka ingat bahwa mereka melepaskannya dengan tangan mereka, dan kemudian mereka memiliki penyebaran kustom mereka sendiri.
Tidak ada pengkodean dalam kuesioner, itu terstandarisasi dan berubah setiap enam bulan. Ini adalah dokumen dua halaman yang kami bantu isi 2-3 minggu lagi. Dan kemudian kami mengatur reli dua jam dan menemukan solusi untuk banyak rasa sakit. Alat sederhana ini bekerja dengan baik bersama kami dan dapat membantu Anda.6-7 Saint HighLoad++, . (, , ).
telegram- . !