Untuk mengantisipasi dimulainya kursus Insinyur Data, kami menyiapkan terjemahan materi yang kecil namun menarik.
Pada artikel ini, saya akan berbicara tentang bagaimana Parket mengkompres dataset besar menjadi file footprint kecil, dan bagaimana kita dapat mencapai bandwidth yang jauh melebihi bandwidth dari aliran I / O menggunakan concurrency (multithreading).Apache Parket: Terbaik di Data Entropi Rendah
Seperti yang dapat Anda pahami dari spesifikasi format Apache Parket, ini berisi beberapa level pengkodean yang dapat mencapai pengurangan signifikan dalam ukuran file, di antaranya adalah:- Pengkodean (kompresi) menggunakan kamus (mirip dengan panda. Cara kategorikal menyajikan data, tetapi konsepnya sendiri berbeda);
- Kompresi halaman data (Snappy, Gzip, LZO atau Brotli);
- Pengkodean panjang eksekusi (untuk null-pointer dan indeks kamus) dan integer bit packing;
Untuk menunjukkan kepada Anda bagaimana ini bekerja, mari kita lihat dataset:['banana', 'banana', 'banana', 'banana', 'banana', 'banana',
'banana', 'banana', 'apple', 'apple', 'apple']
Hampir semua implementasi Parket menggunakan kamus default untuk kompresi. Dengan demikian, data yang disandikan adalah sebagai berikut:dictionary: ['banana', 'apple']
indices: [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1]
Indeks dalam kamus juga dikompres oleh algoritma pengulangan pengulangan:dictionary: ['banana', 'apple']
indices (RLE): [(8, 0), (3, 1)]
Mengikuti jalur balik, Anda dapat dengan mudah mengembalikan array string asli.Dalam artikel saya sebelumnya , saya membuat dataset yang kompres sangat baik dengan cara ini. Saat bekerja dengan pyarrow, kami dapat mengaktifkan dan menonaktifkan pengkodean menggunakan kamus (yang diaktifkan secara default) untuk melihat bagaimana ini akan mempengaruhi ukuran file:import pyarrow.parquet as pq
pq.write_table(dataset, out_path, use_dictionary=True,
compression='snappy)
Kumpulan data yang membutuhkan 1 GB (1024 MB) pandas.DataFrame, dengan kompresi dan kompresi Snappy menggunakan kamus, hanya membutuhkan 1,436 MB, yang bahkan dapat ditulis ke disket. Tanpa kompresi menggunakan kamus, itu akan menempati 44,4 MB.Pembacaan bersamaan di parket-cpp menggunakan PyArrow
Dalam implementasi Apache Parquet di C ++ - parquet-cpp , yang kami sediakan untuk Python di PyArrow, kemampuan untuk membaca kolom secara paralel ditambahkan.Untuk mencoba fitur ini, instal PyArrow dari conda-forge :conda install pyarrow -c conda-forge
Sekarang saat membaca file Parket, Anda dapat menggunakan argumen nthreads:import pyarrow.parquet as pq
table = pq.read_table(file_path, nthreads=4)
Untuk data dengan entropi rendah, dekompresi dan dekode sangat terkait dengan prosesor. Karena C ++ melakukan semua pekerjaan untuk kami, tidak ada masalah dengan GIL concurrency dan kami dapat mencapai peningkatan kecepatan yang signifikan. Lihat apa yang dapat saya capai dengan membaca dataset 1 GB dalam panda DataFrame pada laptop quad-core (Xeon E3-1505M, NVMe SSD):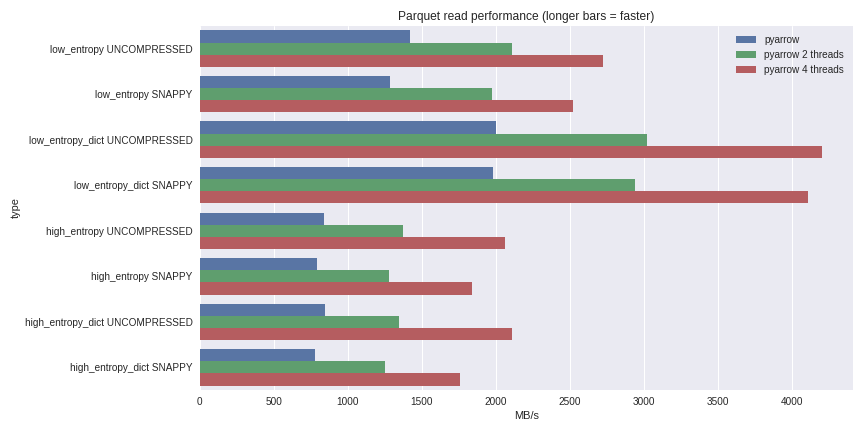 Anda dapat melihat skenario pembandingan penuh di sini .Saya telah menyertakan kinerja di sini untuk kedua kasus kompresi menggunakan kamus dan kasus tanpa menggunakan kamus. Untuk data dengan entropi rendah, terlepas dari kenyataan bahwa semua file kecil (~ 1,5 MB menggunakan kamus dan ~ 45 MB tanpa), kompresi menggunakan kamus secara signifikan mempengaruhi kinerja. Dengan 4 utas, kinerja membaca panda meningkat menjadi 4 GB / s. Ini jauh lebih cepat daripada format Feather atau yang lainnya yang saya tahu.
Anda dapat melihat skenario pembandingan penuh di sini .Saya telah menyertakan kinerja di sini untuk kedua kasus kompresi menggunakan kamus dan kasus tanpa menggunakan kamus. Untuk data dengan entropi rendah, terlepas dari kenyataan bahwa semua file kecil (~ 1,5 MB menggunakan kamus dan ~ 45 MB tanpa), kompresi menggunakan kamus secara signifikan mempengaruhi kinerja. Dengan 4 utas, kinerja membaca panda meningkat menjadi 4 GB / s. Ini jauh lebih cepat daripada format Feather atau yang lainnya yang saya tahu.Kesimpulan
Dengan rilis versi 1.0 parket-cpp (Apache Parket di C ++), Anda dapat melihat sendiri peningkatan kinerja I / O yang sekarang tersedia untuk pengguna Python.Karena semua mekanisme dasar diimplementasikan dalam C ++, dalam bahasa lain (misalnya, R), Anda dapat membuat antarmuka untuk Panah Apache (struktur data berbentuk kolom) dan parket-cpp . Python binding adalah cangkang ringan dari pustaka libarrow inti dan libparquet C ++.Itu saja. Jika Anda ingin mempelajari lebih lanjut tentang kursus kami, daftar untuk hari terbuka , yang akan diadakan hari ini!