Hai, saya bekerja di tim proyek RRP KP (daftar data terdistribusi untuk memantau siklus hidup roda). Di sini saya ingin berbagi pengalaman tim kami dalam mengembangkan blockchain korporat untuk proyek ini dalam kondisi yang ditentukan oleh teknologi. Untuk sebagian besar saya akan berbicara tentang Hyperledger Fabric, tetapi pendekatan yang dijelaskan di sini dapat diekstrapolasi ke semua blockchain yang diizinkan. Tujuan akhir dari penelitian kami adalah menyiapkan solusi blockchain korporat sehingga produk akhir menyenangkan untuk digunakan dan tidak terlalu sulit untuk dipelihara.Tidak akan ada penemuan, solusi tak terduga dan tidak ada perkembangan unik akan dibahas di sini (karena saya tidak memilikinya). Saya hanya ingin berbagi pengalaman sederhana saya, untuk menunjukkan bahwa "itu mungkin" dan, mungkin, untuk membaca tentang pengalaman orang lain dalam membuat keputusan yang baik dan tidak begitu baik dalam komentar.Masalah: blockchains belum diskalakan
Saat ini, upaya banyak pengembang ditujukan untuk membuat blockchain teknologi yang sangat nyaman, dan bukan bom waktu dalam bungkus yang indah. Saluran negara, peluncuran optimis, plasma, dan sharding dapat menjadi sehari-hari. Suatu hari nanti. Atau mungkin TON akan kembali menunda peluncuran selama enam bulan, dan Grup Plasma berikutnya akan tidak ada lagi. Kita dapat mempercayai peta jalan lain dan membaca buku putih cemerlang untuk malam itu, tetapi di sini dan sekarang kita perlu melakukan sesuatu dengan apa yang kita miliki. Sialan.Tugas yang ditetapkan untuk tim kami dalam proyek saat ini terlihat seperti ini secara umum: ada banyak entitas yang mencapai beberapa ribu, tidak ingin membangun hubungan berdasarkan kepercayaan; perlu untuk membangun solusi seperti itu pada DLT yang akan bekerja pada PC biasa tanpa persyaratan kinerja khusus dan memberikan pengalaman pengguna tidak lebih buruk daripada sistem akuntansi terpusat. Teknologi yang mendasari solusi harus meminimalkan kemungkinan manipulasi data yang berbahaya - inilah mengapa blockchain ada di sini.Slogan-slogan dari whitepaper dan media menjanjikan kepada kami bahwa perkembangan selanjutnya akan memungkinkan Anda untuk melakukan jutaan transaksi per detik. Apa yang sebenarnyaMainnet Ethereum sekarang beroperasi pada ~ 30 tps. Sudah karena ini, sulit untuk menganggapnya sebagai blockchain yang cocok untuk kebutuhan perusahaan. Di antara solusi yang diizinkan, tolok ukur diketahui, menunjukkan 2.000 tps ( Kuorum ) atau 3000 tps ( Hyperledger Fabric , publikasi sedikit lebih kecil, tetapi Anda perlu mempertimbangkan bahwa tolok ukur dilakukan pada mesin konsensus lama). Ada upaya untuk secara radikal merevisi Fabric , yang tidak memberikan hasil terburuk, 20.000 tps, tetapi sejauh ini hanya penelitian akademik yang menunggu implementasi yang stabil. Tidak mungkin bahwa perusahaan yang mampu mempertahankan departemen pengembang blockchain akan tahan dengan indikator tersebut. Tapi masalahnya bukan hanya throughput, masih ada latensi.Latensi
Penundaan sejak saat transaksi dimulai hingga persetujuan finalnya oleh sistem tidak hanya bergantung pada kecepatan pesan yang melewati semua tahap validasi dan pemesanan, tetapi juga pada parameter pembentukan blok. Bahkan jika blockchain kami memungkinkan kami untuk berkomitmen pada kecepatan 1.000.000 tps, tetapi butuh 10 menit untuk membentuk blok 488 MB, akankah itu menjadi lebih mudah bagi kami?Mari kita lihat lebih dekat siklus hidup transaksi di Hyperledger Fabric untuk memahami apa waktu yang dihabiskan dan bagaimana hubungannya dengan parameter pembentukan blok.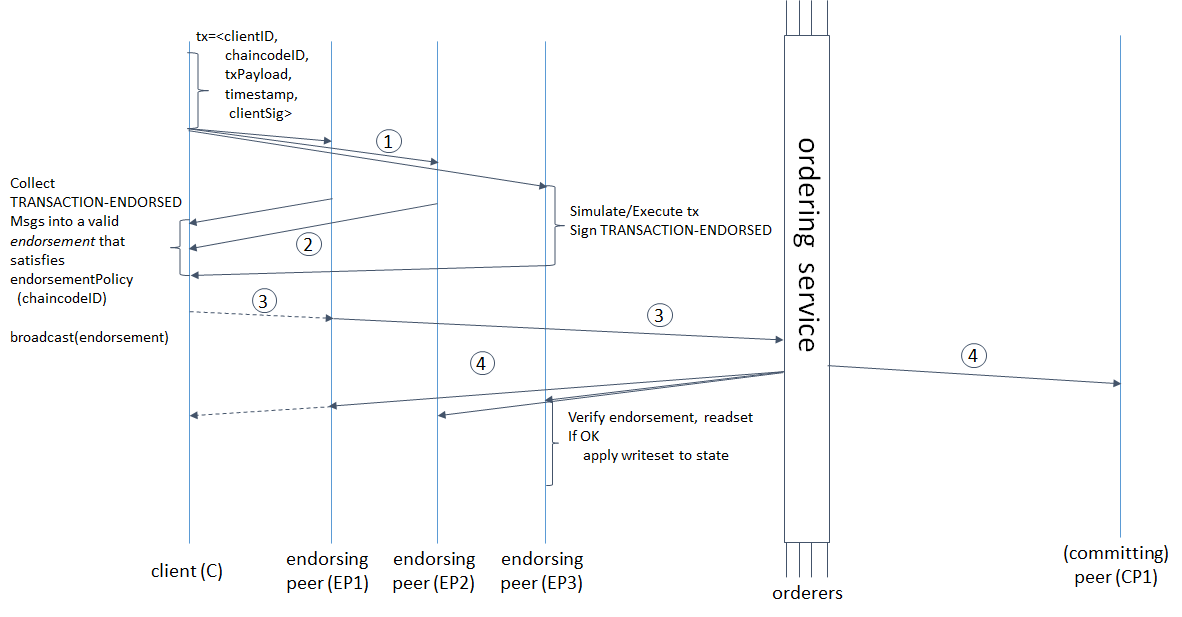 diambil dari sini : hyperledger-fabric.readthedocs.io/en/release-1.4/arch-deep-dive.html#swimlane(1) Klien menghasilkan transaksi, mengirimkannya ke endorsing peer, yang terakhir mensimulasikan transaksi (menerapkan perubahan yang dilakukan oleh kode rantai ke kondisi saat ini, tetapi tidak melakukan komitmen ke buku besar) dan mendapatkan RWSet - nama kunci, versi dan nilai yang diambil dari koleksi di CouchDB, ( 2) endorser mengirim kembali RWSet yang telah ditandatangani kepada klien, (3) klien memeriksa tanda tangan dari semua rekan yang diperlukan (endorser), dan kemudian mengirimkan transaksi ke layanan pemesanan, atau mengirimkannya tanpa verifikasi (verifikasi masih akan berlangsung kemudian), memesan layanan membentuk blok dan ( 4) mengirim kembali ke semua rekan, bukan hanya pendukung; rekan memeriksa bahwa versi kunci dalam set baca cocok dengan versi dalam database, tanda tangan dari semua endorser, dan akhirnya melakukan blokir.Tapi itu belum semuanya. Kata-kata "pesanan membentuk blok" tidak hanya menyembunyikan pemesanan transaksi, tetapi juga 3 permintaan jaringan berturut-turut dari pemimpin ke pengikut dan sebaliknya: pemimpin menambahkan pesan ke log, mengirim pengikut, yang terakhir menambahkan ke log, mengirim konfirmasi keberhasilan replikasi kepada pemimpin, pemimpin melakukan pesan , mengirimkan konfirmasi komit kepada pengikut, pengikut komit. Semakin kecil ukuran dan waktu pembentukan blok, semakin sering diperlukan layanan pemesanan untuk menetapkan konsensus. Hyperledger Fabric memiliki dua parameter pembentukan blok: BatchTimeout - waktu pembentukan blok dan BatchSize - ukuran blok (jumlah transaksi dan ukuran blok itu sendiri dalam byte). Segera setelah salah satu parameter mencapai batas, blok baru dilepaskan. Semakin banyak waran, semakin lama waktu yang dibutuhkan. Karena itu, Anda perlu meningkatkan BatchTimeout dan BatchSize. Tetapi karena RWSets sudah diversi, semakin kita membuat blok, semakin tinggi kemungkinan konflik MVCC. Selain itu, dengan peningkatan BatchTimeout, UX sangat merusak. Menurut saya masuk akal dan jelas skema berikut untuk menyelesaikan masalah ini.
diambil dari sini : hyperledger-fabric.readthedocs.io/en/release-1.4/arch-deep-dive.html#swimlane(1) Klien menghasilkan transaksi, mengirimkannya ke endorsing peer, yang terakhir mensimulasikan transaksi (menerapkan perubahan yang dilakukan oleh kode rantai ke kondisi saat ini, tetapi tidak melakukan komitmen ke buku besar) dan mendapatkan RWSet - nama kunci, versi dan nilai yang diambil dari koleksi di CouchDB, ( 2) endorser mengirim kembali RWSet yang telah ditandatangani kepada klien, (3) klien memeriksa tanda tangan dari semua rekan yang diperlukan (endorser), dan kemudian mengirimkan transaksi ke layanan pemesanan, atau mengirimkannya tanpa verifikasi (verifikasi masih akan berlangsung kemudian), memesan layanan membentuk blok dan ( 4) mengirim kembali ke semua rekan, bukan hanya pendukung; rekan memeriksa bahwa versi kunci dalam set baca cocok dengan versi dalam database, tanda tangan dari semua endorser, dan akhirnya melakukan blokir.Tapi itu belum semuanya. Kata-kata "pesanan membentuk blok" tidak hanya menyembunyikan pemesanan transaksi, tetapi juga 3 permintaan jaringan berturut-turut dari pemimpin ke pengikut dan sebaliknya: pemimpin menambahkan pesan ke log, mengirim pengikut, yang terakhir menambahkan ke log, mengirim konfirmasi keberhasilan replikasi kepada pemimpin, pemimpin melakukan pesan , mengirimkan konfirmasi komit kepada pengikut, pengikut komit. Semakin kecil ukuran dan waktu pembentukan blok, semakin sering diperlukan layanan pemesanan untuk menetapkan konsensus. Hyperledger Fabric memiliki dua parameter pembentukan blok: BatchTimeout - waktu pembentukan blok dan BatchSize - ukuran blok (jumlah transaksi dan ukuran blok itu sendiri dalam byte). Segera setelah salah satu parameter mencapai batas, blok baru dilepaskan. Semakin banyak waran, semakin lama waktu yang dibutuhkan. Karena itu, Anda perlu meningkatkan BatchTimeout dan BatchSize. Tetapi karena RWSets sudah diversi, semakin kita membuat blok, semakin tinggi kemungkinan konflik MVCC. Selain itu, dengan peningkatan BatchTimeout, UX sangat merusak. Menurut saya masuk akal dan jelas skema berikut untuk menyelesaikan masalah ini.Hindari menunggu finalisasi blok dan tidak kehilangan kemampuan untuk melacak status transaksi
Semakin lama waktu pembentukan dan ukuran blok, semakin tinggi throughput blockchain. Satu dari yang lain tidak mengikuti secara langsung, tetapi harus diingat bahwa membangun konsensus di RAFT memerlukan tiga permintaan jaringan dari pemimpin kepada pengikut dan sebaliknya. Semakin banyak node pesanan, semakin lama waktu yang dibutuhkan. Semakin kecil ukuran dan waktu pembentukan blok, semakin banyak interaksi tersebut. Bagaimana cara menambah waktu pembentukan dan ukuran blok tanpa menambah waktu tunggu untuk respons sistem bagi pengguna akhir?Pertama, Anda harus menyelesaikan konflik MVCC yang disebabkan oleh ukuran blok yang besar, yang dapat menyertakan RWSets yang berbeda dengan versi yang sama. Jelas, di sisi klien (dalam kaitannya dengan jaringan blockchain, ini bisa sangat menjadi backend, dan maksud saya) kita membutuhkan penanganan konflik MVCC, yang dapat berupa layanan terpisah atau dekorator reguler melalui panggilan yang memicu transaksi dengan coba lagi logika.Coba lagi dapat diimplementasikan dengan strategi eksponensial, tetapi kemudian latensi akan menurun secara eksponensial. Jadi, Anda harus menggunakan percobaan ulang acak dalam batas kecil tertentu, atau yang permanen. Dengan memperhatikan kemungkinan konflik dalam perwujudan pertama.Langkah selanjutnya adalah membuat interaksi klien dengan sistem tidak sinkron sehingga tidak menunggu 15, 30, atau 10.000.000 detik, yang akan kami tetapkan sebagai BatchTimeout. Tetapi pada saat yang sama, Anda perlu menyimpan kesempatan untuk memastikan bahwa perubahan yang dilakukan oleh transaksi ditulis / tidak ditulis ke blockchain.Anda dapat menggunakan database untuk menyimpan status transaksi. Opsi termudah adalah CouchDB karena kemudahan penggunaan: database memiliki UI di luar kotak, REST API, dan Anda dapat dengan mudah mengkonfigurasi replikasi dan sharding untuk itu. Anda bisa membuat koleksi terpisah di instance CouchDB yang sama yang digunakan Fabric untuk menyimpan status dunianya. Kita perlu menyimpan dokumen semacam ini.{
Status string
TxID: string
Error: string
}
Dokumen ini ditulis ke database sebelum transaksi ditransfer ke rekan-rekan, ID entitas dikembalikan ke pengguna (ID yang sama digunakan sebagai kunci) jika ini adalah operasi untuk membuat sesuatu, dan kemudian bidang Status, TxID dan Kesalahan diperbarui ketika informasi yang relevan dari rekan diterima. Dalam skema ini, pengguna tidak menunggu sampai blok akhirnya terbentuk, menonton roda berputar di layar selama 10 detik, ia menerima respons instan dari sistem dan terus bekerja.Kami memilih BoltDB untuk menyimpan status transaksi, karena kami perlu menghemat memori dan tidak ingin menghabiskan waktu untuk interaksi jaringan dengan server database yang berdiri sendiri, terutama ketika interaksi ini terjadi menggunakan protokol teks biasa. Omong-omong, Anda menggunakan CouchDB untuk mengimplementasikan skema yang dijelaskan di atas atau hanya untuk menyimpan negara dunia, dalam hal apa pun, masuk akal untuk mengoptimalkan cara data disimpan di CouchDB. Secara default, di CouchDB, ukuran node b-tree adalah 1279 byte, yang jauh lebih kecil dari ukuran sektor pada disk, yang berarti bahwa baik membaca dan menyeimbangkan pohon akan membutuhkan lebih banyak akses disk fisik. Ukuran optimal sesuai dengan standar Format Lanjutan dan 4 kilobyte. Untuk optimasi, kita perlu mengatur parameter btree_chunk_size ke 4096dalam file konfigurasi CouchDB. Untuk BoltDB, intervensi manual seperti itu tidak diperlukan .
Dalam skema ini, pengguna tidak menunggu sampai blok akhirnya terbentuk, menonton roda berputar di layar selama 10 detik, ia menerima respons instan dari sistem dan terus bekerja.Kami memilih BoltDB untuk menyimpan status transaksi, karena kami perlu menghemat memori dan tidak ingin menghabiskan waktu untuk interaksi jaringan dengan server database yang berdiri sendiri, terutama ketika interaksi ini terjadi menggunakan protokol teks biasa. Omong-omong, Anda menggunakan CouchDB untuk mengimplementasikan skema yang dijelaskan di atas atau hanya untuk menyimpan negara dunia, dalam hal apa pun, masuk akal untuk mengoptimalkan cara data disimpan di CouchDB. Secara default, di CouchDB, ukuran node b-tree adalah 1279 byte, yang jauh lebih kecil dari ukuran sektor pada disk, yang berarti bahwa baik membaca dan menyeimbangkan pohon akan membutuhkan lebih banyak akses disk fisik. Ukuran optimal sesuai dengan standar Format Lanjutan dan 4 kilobyte. Untuk optimasi, kita perlu mengatur parameter btree_chunk_size ke 4096dalam file konfigurasi CouchDB. Untuk BoltDB, intervensi manual seperti itu tidak diperlukan .Backpressure: strategi penyangga
Tetapi bisa ada banyak pesan. Lebih dari sistem yang mampu memproses, berbagi sumber daya dengan selusin layanan lain selain yang ditunjukkan dalam diagram - dan semua ini harus bekerja tanpa gagal bahkan pada mesin yang meluncurkan Ide Intellij akan sangat membosankan.Masalah throughput yang berbeda dari sistem komunikasi, produsen dan konsumen, diselesaikan dengan cara yang berbeda. Mari kita lihat apa yang bisa kita lakukan.Menjatuhkan : kita dapat mengklaim tidak dapat memproses lebih dari X transaksi dalam T detik. Semua permintaan yang melebihi batas ini diatur ulang. Ini cukup sederhana, tetapi kemudian Anda bisa melupakan UX.Mengontrol: konsumen harus memiliki beberapa antarmuka di mana, tergantung pada beban, ia akan dapat mengontrol tps produsen. Tidak buruk, tetapi membebankan kewajiban pada pengembang klien yang membuat beban untuk mengimplementasikan antarmuka ini. Bagi kami, ini tidak dapat diterima, karena blockchain di masa depan akan diintegrasikan ke dalam sejumlah besar sistem yang sudah lama ada.Buffering : Alih-alih ingin menahan input stream data, kita dapat buffer stream ini dan memprosesnya pada kecepatan yang diperlukan. Tentunya, ini adalah solusi terbaik jika kami ingin memberikan pengalaman pengguna yang baik. Kami menerapkan buffer menggunakan antrian di RabbitMQ. Dua tindakan baru ditambahkan ke skema: (1) setelah menerima permintaan untuk API, pesan dengan parameter yang diperlukan untuk memanggil transaksi di antri, dan klien menerima pesan bahwa transaksi diterima oleh sistem, (2) backend membaca data dengan kecepatan yang ditentukan dalam konfigurasi. dari antrian; memulai transaksi dan memperbarui data di penyimpanan status.Sekarang Anda dapat meningkatkan waktu pembentukan dan memblokir kapasitas sebanyak yang Anda inginkan, menyembunyikan penundaan dari pengguna.
Dua tindakan baru ditambahkan ke skema: (1) setelah menerima permintaan untuk API, pesan dengan parameter yang diperlukan untuk memanggil transaksi di antri, dan klien menerima pesan bahwa transaksi diterima oleh sistem, (2) backend membaca data dengan kecepatan yang ditentukan dalam konfigurasi. dari antrian; memulai transaksi dan memperbarui data di penyimpanan status.Sekarang Anda dapat meningkatkan waktu pembentukan dan memblokir kapasitas sebanyak yang Anda inginkan, menyembunyikan penundaan dari pengguna.Alat lainnya
Tidak ada yang dikatakan di sini tentang chaincode, karena, sebagai aturannya, tidak ada yang dioptimalkan di dalamnya. Chaincode harus sesederhana dan seaman mungkin - hanya itu yang diperlukan. Cheynkod menulis dengan sederhana dan aman sangat membantu kita membuat kerangka SSKit dari S7 Techlab dan analisa statis Revive ^ CC .Selain itu, tim kami sedang mengembangkan satu set utilitas untuk membuat bekerja dengan Fabric sederhana dan menyenangkan: seorang blockchain explorer , sebuah utilitas untuk secara otomatis mengubah konfigurasi jaringan (menambah / menghapus organisasi, node RAFT), sebuah utilitas untuk mencabut sertifikat dan menghapus identitas . Jika Anda ingin berkontribusi - selamat datang.Kesimpulan
Pendekatan ini memudahkan untuk mengganti Hyperledger Fabric dengan Quorum, jaringan Ethereum pribadi lainnya (PoA atau bahkan PoW), secara signifikan mengurangi bandwidth nyata, tetapi pada saat yang sama mempertahankan UX normal (baik untuk pengguna di browser dan untuk sistem terintegrasi). Saat mengganti Fabric dengan Ethereum dalam skema, Anda hanya perlu mengubah logika coba layanan / dekorator dari memproses konflik MVCC ke tingkat kenaikan atom dan mengirim ulang. Buffer dan penyimpanan status diperbolehkan untuk memisahkan waktu respons dari waktu pembentukan blok. Sekarang Anda dapat menambahkan ribuan node pesanan dan jangan takut bahwa blok terlalu sering terbentuk dan memuat layanan pemesanan.Secara umum, itu saja yang ingin saya bagikan. Saya akan senang jika ini membantu seseorang dalam pekerjaan mereka.