Catatan perev. : Dalam artikel ini, Banzai Cloud membagikan contoh penggunaan utilitas khusus untuk memfasilitasi pengoperasian Kafka dalam Kubernetes. Instruksi ini menggambarkan bagaimana Anda dapat menentukan ukuran infrastruktur optimal dan mengkonfigurasi Kafka sendiri untuk mencapai throughput yang diperlukan. Apache Kafka adalah platform streaming terdistribusi untuk menciptakan sistem streaming real-time yang andal, dapat diskalakan, dan berkinerja tinggi. Fitur-fiturnya yang mengesankan dapat diperluas dengan Kubernetes. Untuk melakukan ini, kami mengembangkan operator Open Source Kafka dan alat yang disebut Supertubes. Mereka memungkinkan Anda untuk menjalankan Kafka di Kubernetes dan menggunakan berbagai fungsinya, seperti menyempurnakan konfigurasi pialang, penskalaan berdasarkan metrik dengan penyeimbangan ulang, kesadaran rak (kesadaran akan sumber daya perangkat keras), pembaruan bergulir “lunak” (anggun) , dll.
Apache Kafka adalah platform streaming terdistribusi untuk menciptakan sistem streaming real-time yang andal, dapat diskalakan, dan berkinerja tinggi. Fitur-fiturnya yang mengesankan dapat diperluas dengan Kubernetes. Untuk melakukan ini, kami mengembangkan operator Open Source Kafka dan alat yang disebut Supertubes. Mereka memungkinkan Anda untuk menjalankan Kafka di Kubernetes dan menggunakan berbagai fungsinya, seperti menyempurnakan konfigurasi pialang, penskalaan berdasarkan metrik dengan penyeimbangan ulang, kesadaran rak (kesadaran akan sumber daya perangkat keras), pembaruan bergulir “lunak” (anggun) , dll.Coba Supertubes di kluster Anda:
curl https://getsupertubes.sh | sh supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>
Atau lihat dokumentasi . Anda juga dapat membaca tentang beberapa fitur Kafka, yang otomatis dengan bantuan Supertubes dan operator Kafka. Kami sudah menulis tentang mereka di blog:
Ketika Anda memutuskan untuk menggunakan cluster Kafka di Kubernetes, Anda mungkin akan menghadapi masalah menentukan ukuran optimal dari infrastruktur yang mendasarinya dan kebutuhan untuk menyempurnakan konfigurasi Kafka untuk memenuhi persyaratan bandwidth. Kinerja maksimum setiap broker ditentukan oleh kinerja komponen infrastruktur pada intinya, seperti memori, prosesor, kecepatan disk, bandwidth jaringan, dll.Idealnya, konfigurasi broker harus sedemikian rupa sehingga semua elemen infrastruktur digunakan semaksimal kemampuan mereka. Namun, dalam kehidupan nyata, pengaturan ini sangat rumit. Lebih mungkin bahwa pengguna akan mengkonfigurasi broker untuk memaksimalkan penggunaan satu atau dua komponen (disk, memori, atau prosesor). Secara umum, broker menunjukkan kinerja maksimum ketika konfigurasinya memungkinkan Anda untuk menggunakan komponen paling lambat "secara penuh." Jadi kita bisa mendapatkan perkiraan perkiraan beban yang bisa ditangani oleh satu broker.Secara teoritis, kita juga dapat memperkirakan jumlah broker yang dibutuhkan untuk bekerja dengan beban yang diberikan. Namun, dalam praktiknya, ada begitu banyak opsi konfigurasi pada tingkat yang berbeda sehingga sangat sulit (jika bukan tidak mungkin) untuk menilai kinerja potensial dari konfigurasi tertentu. Dengan kata lain, sangat sulit untuk merencanakan konfigurasi, mulai dari beberapa kinerja yang diberikan.Untuk pengguna Supertubes, kami biasanya menggunakan pendekatan berikut: mulai dengan beberapa konfigurasi (infrastruktur + pengaturan), lalu ukur kinerjanya, sesuaikan pengaturan broker dan ulangi prosesnya lagi. Ini terjadi sampai potensi komponen infrastruktur paling lambat dimanfaatkan sepenuhnya.Dengan cara ini, kita mendapatkan ide yang lebih jelas tentang berapa banyak broker yang perlu diatasi oleh suatu cluster (jumlah broker juga tergantung pada faktor-faktor lain, seperti jumlah minimum replika pesan untuk memastikan stabilitas, jumlah pemimpin partisi, dll.). Selain itu, kami mendapatkan gagasan tentang penskalaan vertikal komponen infrastruktur mana yang diinginkan.Artikel ini akan membahas langkah-langkah yang kami ambil untuk "memeras semuanya" dari komponen paling lambat dalam konfigurasi awal dan mengukur throughput cluster Kafka. Konfigurasi yang sangat tangguh membutuhkan setidaknya tiga broker yang berfungsi (min.insync.replicas=3) ditempatkan di tiga zona aksesibilitas berbeda. Untuk mengonfigurasi, skala, dan memonitor infrastruktur Kubernetes, kami menggunakan platform manajemen wadah cloud hybrid kami sendiri - Pipeline . Ini mendukung on-premise (bare metal, VMware) dan lima jenis awan (Alibaba, AWS, Azure, Google, Oracle), serta kombinasi dari semuanya.Pikiran tentang infrastruktur dan konfigurasi cluster Kafka
Untuk contoh di bawah ini, kami memilih AWS sebagai penyedia layanan cloud dan EKS sebagai distribusi Kubernetes. Konfigurasi serupa dapat diimplementasikan menggunakan PKE , distribusi Kubernetes dari Banzai Cloud, disertifikasi oleh CNCF.Disk
Amazon menawarkan berbagai jenis volume EBS . SSD adalah dasar dari gp2 dan io1 , untuk memastikan throughput yang tinggi, gp2 mengkonsumsi akumulasi pinjaman ( kredit I / O) , oleh karena itu kami lebih suka tipe io1 , yang menawarkan throughput tinggi yang stabil.Jenis Instance
Kinerja Kafka sangat tergantung pada cache halaman sistem operasi, jadi kami membutuhkan instance dengan memori yang cukup untuk broker (JVM) dan cache halaman. Instance c5.2xlarge adalah awal yang baik, karena memiliki memori 16 GB dan dioptimalkan untuk bekerja dengan EBS . Kerugiannya adalah mampu memberikan kinerja maksimum tidak lebih dari 30 menit setiap 24 jam. Jika beban kerja Anda membutuhkan kinerja maksimum dalam periode waktu yang lebih lama, lihat jenis kejadian lainnya. Kami melakukan hal itu, berhenti di c5.4xlarge . Ini memberikan throughput maksimum 593,75 Mb / s.. Throughput maksimum volume EBS io1 lebih tinggi daripada instance c5.4xlarge , jadi elemen infrastruktur paling lambat mungkin adalah throughput I / O dari instance ini (yang juga harus dikonfirmasi oleh hasil uji beban kami).Jaringan
Bandwidth jaringan harus cukup besar dibandingkan dengan kinerja instance VM dan disk, jika tidak jaringan menjadi hambatan. Dalam kasus kami, antarmuka jaringan c5.4xlarge mendukung kecepatan hingga 10 Gb / s, yang secara signifikan lebih tinggi dari bandwidth instance I / O dari VM.Penempatan Broker
Broker harus dikerahkan (direncanakan di Kubernetes) ke node khusus untuk menghindari persaingan dengan proses lain untuk prosesor, memori, jaringan, dan sumber daya disk.Versi Java
Pilihan logisnya adalah Java 11, karena itu kompatibel dengan Docker dalam arti bahwa JVM dengan benar menentukan prosesor dan memori yang tersedia untuk wadah di mana broker berjalan. Mengetahui bahwa batas prosesor itu penting, JVM secara internal dan transparan menetapkan jumlah thread GC dan thread compiler JIT. Kami menggunakan gambar Kafka banzaicloud/kafka:2.13-2.4.0yang menyertakan Kafka versi 2.4.0 (Scala 2.13) di Java 11.Jika Anda ingin mempelajari lebih lanjut tentang Java / JVM di Kubernetes, lihat publikasi kami berikut ini:
Pengaturan Memori Broker
Ada dua aspek utama untuk mengatur memori broker: pengaturan untuk JVM dan untuk pod Kubernetes. Batas memori yang diatur untuk pod harus lebih besar dari ukuran heap maksimum sehingga JVM memiliki cukup ruang untuk Java metaspace dalam memorinya sendiri dan untuk cache halaman sistem operasi yang digunakan Kafka secara aktif. Dalam pengujian kami, kami menjalankan pialang Kafka dengan parameter -Xmx4G -Xms2G, dan batas memori untuk podnya 10 Gi. Harap dicatat bahwa pengaturan memori untuk JVM dapat diperoleh secara otomatis menggunakan -XX:MaxRAMPercentagedan -X:MinRAMPercentage, berdasarkan batas memori untuk pod.Pengaturan prosesor pialang
Secara umum, Anda dapat meningkatkan produktivitas dengan meningkatkan konkurensi dengan meningkatkan jumlah utas yang digunakan oleh Kafka. Semakin banyak prosesor yang tersedia untuk Kafka, semakin baik. Dalam pengujian kami, kami mulai dengan batas 6 prosesor dan secara bertahap (iterated) menaikkan jumlahnya menjadi 15. Selain itu, kami menetapkan num.network.threads=12dalam pengaturan broker untuk meningkatkan jumlah stream yang menerima data dari jaringan dan mengirimkannya. Setelah segera mengetahui bahwa broker pengikut tidak dapat menerima replika dengan cukup cepat, mereka naik num.replica.fetcherske 4 untuk meningkatkan kecepatan para broker pengikut mereplikasi pesan dari para pemimpin.Memuat alat generasi
Pastikan bahwa potensi generator beban yang dipilih tidak habis sebelum cluster Kafka (yang benchmark berjalan) mencapai beban maksimum. Dengan kata lain, perlu untuk melakukan penilaian awal terhadap kemampuan alat pembangkit beban, serta memilih jenis instance untuknya dengan jumlah prosesor dan memori yang cukup. Dalam hal ini, alat kami akan menghasilkan lebih banyak beban daripada yang dapat dicerna oleh cluster Kafka. Setelah banyak percobaan, kami menetapkan tiga salinan c5.4xlarge , di mana masing-masing generator diluncurkan.Benchmarking
Pengukuran kinerja adalah proses berulang yang mencakup langkah-langkah berikut:- pengaturan infrastruktur (EKS cluster, cluster Kafka, alat pembangkit beban, serta Prometheus dan Grafana);
- memuat generasi untuk periode tertentu untuk menyaring penyimpangan acak dalam indikator kinerja yang dikumpulkan;
- menyempurnakan infrastruktur dan konfigurasi broker berdasarkan indikator kinerja yang diamati;
- ulangi proses tersebut sampai level yang diperlukan dari bandwidth cluster Kafka tercapai. Pada saat yang sama, itu harus dapat direproduksi secara stabil dan menunjukkan variasi bandwidth minimal.
Bagian selanjutnya menjelaskan langkah-langkah yang dilakukan selama kelompok uji benchmark.Alat
Alat-alat berikut digunakan untuk menyebarkan konfigurasi basis, pembangkitan beban, dan pengukuran kinerja dengan cepat:- Banzai Cloud Pipeline EKS Amazon c Prometheus ( Kafka ) Grafana ( ). Pipeline , , , , , .
- Sangrenel — Kafka.
- Grafana Kafka : Kubernetes Kafka, Node Exporter.
- Supertubes CLI untuk cara termudah untuk mengkonfigurasi cluster Kafka di Kubernetes. Zookeeper, operator Kafka, Utusan dan banyak komponen lainnya dipasang dan dikonfigurasikan dengan benar untuk menjalankan kluster Kafka yang siap untuk produksi di Kubernetes.
- Untuk menginstal CLI supertubes, gunakan instruksi yang diberikan di sini .

EKS Cluster
Mempersiapkan cluster EKS dengan node kerja c5.4xlarge khusus di berbagai zona ketersediaan untuk pod dengan broker Kafka, serta node khusus untuk generator beban dan infrastruktur pemantauan.banzai cluster create -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/cluster_eks_202001.json
Ketika cluster EKS operasional, aktifkan layanan pemantauan terintegrasi - itu akan menyebarkan Prometheus dan Grafana ke cluster.Komponen sistem kafka
Instal komponen sistem Kafka (Zookeeper, operator kafka) di EKS menggunakan supertubes CLI:supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>
Kafka Cluster
Secara default, EKS menggunakan volume gp2 EBS , jadi Anda perlu membuat kelas penyimpanan terpisah berdasarkan volume io1 untuk cluster Kafka:kubectl create -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: "50"
fsType: ext4
volumeBindingMode: WaitForFirstConsumer
EOF
Tetapkan parameter untuk broker min.insync.replicas=3dan sebarkan pod broker pada node di tiga zona ketersediaan berbeda:supertubes cluster create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/kafka_202001_3brokers.yaml --wait --timeout 600
Topik
Kami secara bersamaan meluncurkan tiga contoh generator beban. Masing-masing dari mereka menulis dalam topiknya masing-masing, yaitu, yang kita butuhkan adalah tiga topik:supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest1
spec:
name: perftest1
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest2
spec:
name: perftest2
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest3
spec:
name: perftest3
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
Untuk setiap topik, faktor replikasi adalah 3 - nilai minimum yang disarankan untuk sistem produksi yang sangat tersedia.Memuat alat generasi
Kami meluncurkan tiga contoh generator beban (masing-masing menulis dalam topik terpisah). Untuk pod generator beban, Anda harus mendaftarkan afinitas simpul sehingga hanya direncanakan pada node yang dialokasikan untuk mereka:apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: loadtest
name: perf-load1
namespace: kafka
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: loadtest
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: loadtest
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nodepool.banzaicloud.io/name
operator: In
values:
- loadgen
containers:
- args:
- -brokers=kafka-0:29092,kafka-1:29092,kafka-2:29092,kafka-3:29092
- -topic=perftest1
- -required-acks=all
- -message-size=512
- -workers=20
image: banzaicloud/perfload:0.1.0-blog
imagePullPolicy: Always
name: sangrenel
resources:
limits:
cpu: 2
memory: 1Gi
requests:
cpu: 2
memory: 1Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
Beberapa hal yang perlu diperhatikan:- Generator beban menghasilkan pesan 512-byte dan menerbitkannya ke Kafka dalam kumpulan 500 pesan.
-required-acks=all , Kafka. , , , , . (consumers) , , , .- 20 worker' (
-workers=20). worker 5 producer', worker' Kafka. 100 producer', Kafka.
Pemantauan Cluster
Selama pengujian stres pada kluster Kafka, kami juga memantau kesehatannya untuk memastikan tidak ada restart pod, replika tidak sinkron, dan throughput maksimum dengan fluktuasi minimal:Hasil pengukuran
3 broker, ukuran pesan - 512 byte
Dengan pembagian yang merata di tiga broker, kami berhasil mencapai kinerja ~ 500 Mb / s (sekitar 990 ribu pesan per detik) :

 Konsumsi memori mesin virtual JVM tidak melebihi 2 GB:
Konsumsi memori mesin virtual JVM tidak melebihi 2 GB:

 Bandwidth disk mencapai bandwidth I / O maksimum simpul pada ketiga instance yang dikerjakan broker:
Bandwidth disk mencapai bandwidth I / O maksimum simpul pada ketiga instance yang dikerjakan broker: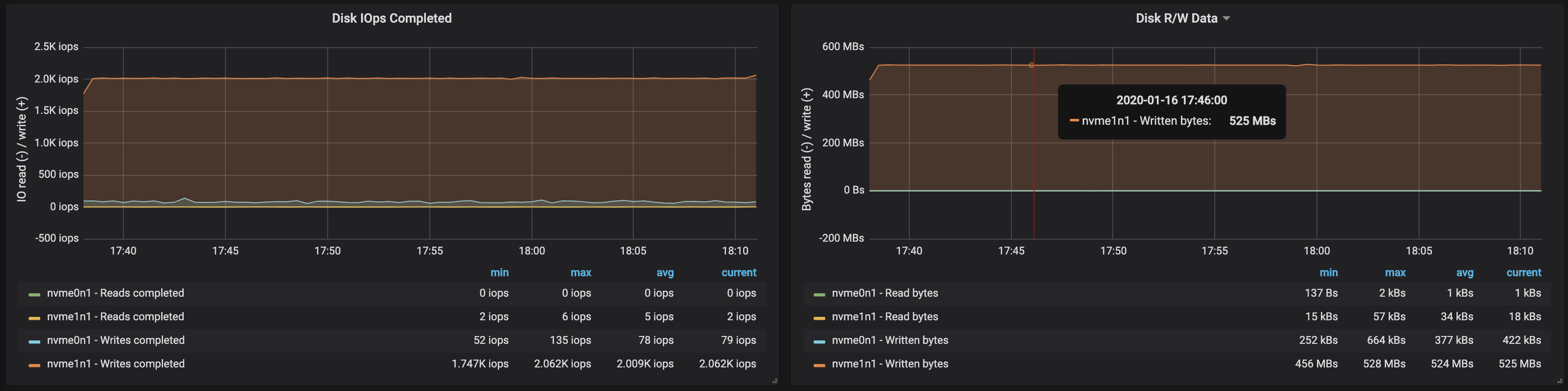

 Dari data penggunaan memori oleh node, berikut bahwa buffering sistem dan caching membutuhkan ~ 10-15 GB:
Dari data penggunaan memori oleh node, berikut bahwa buffering sistem dan caching membutuhkan ~ 10-15 GB:


3 broker, ukuran pesan - 100 byte
Dengan penurunan ukuran pesan, throughput berkurang sekitar 15-20%: waktu yang dihabiskan untuk memproses setiap pesan dipengaruhi. Selain itu, beban prosesor hampir dua kali lipat.

 Karena node broker masih memiliki kernel yang tidak digunakan, Anda dapat meningkatkan kinerja dengan mengubah konfigurasi Kafka. Ini bukan tugas yang mudah, oleh karena itu, untuk meningkatkan throughput, lebih baik bekerja dengan pesan yang lebih besar.
Karena node broker masih memiliki kernel yang tidak digunakan, Anda dapat meningkatkan kinerja dengan mengubah konfigurasi Kafka. Ini bukan tugas yang mudah, oleh karena itu, untuk meningkatkan throughput, lebih baik bekerja dengan pesan yang lebih besar.4 broker, ukuran pesan - 512 byte
Anda dapat dengan mudah meningkatkan kinerja cluster Kafka dengan hanya menambahkan broker baru dan menjaga keseimbangan partisi (ini memastikan distribusi muatan yang merata antar broker). Dalam kasus kami, setelah menambahkan broker, throughput cluster meningkat menjadi ~ 580 Mb / s (~ 1,1 juta pesan per detik) . Pertumbuhan ternyata lebih kecil dari yang diharapkan: ini terutama disebabkan oleh ketidakseimbangan partisi (tidak semua broker bekerja di puncak peluang).


 Konsumsi memori oleh mesin JVM tetap di bawah 2 GB:
Konsumsi memori oleh mesin JVM tetap di bawah 2 GB:


 Ketidakseimbangan partisi memengaruhi operasi broker dengan drive:
Ketidakseimbangan partisi memengaruhi operasi broker dengan drive:



temuan
Pendekatan berulang yang disajikan di atas dapat diperluas untuk mencakup skenario yang lebih kompleks, termasuk ratusan konsumen, partisi ulang, pembaruan bergulir, restart pod, dll. Semua ini memungkinkan kami untuk menilai batas kemampuan cluster Kafka dalam berbagai kondisi, mengidentifikasi kemacetan dalam pekerjaannya dan menemukan cara untuk menghadapinya.Kami mengembangkan Supertubes untuk menyebarkan cluster dengan cepat dan mudah, mengkonfigurasinya, menambah / menghapus broker dan topik, menanggapi peringatan, dan memastikan bahwa Kafka bekerja dengan baik di Kubernetes secara keseluruhan. Tujuan kami adalah membantu berkonsentrasi pada tugas utama ("menghasilkan" dan "mengonsumsi" pesan Kafka), dan menyediakan semua kerja keras untuk Supertubes dan operator Kafka.Jika Anda tertarik dengan teknologi Banzai Cloud dan proyek-proyek Open Source, berlangganan perusahaan di GitHub , LinkedIn atau Twitter .PS dari penerjemah
Baca juga di blog kami: