Terjemahan artikel disiapkan sebelum dimulainya kursus Pembelajaran Mesin dari OTUS.
Tugas
Dalam panduan ini, kami menggunakan dataset Bitcoin vs USD .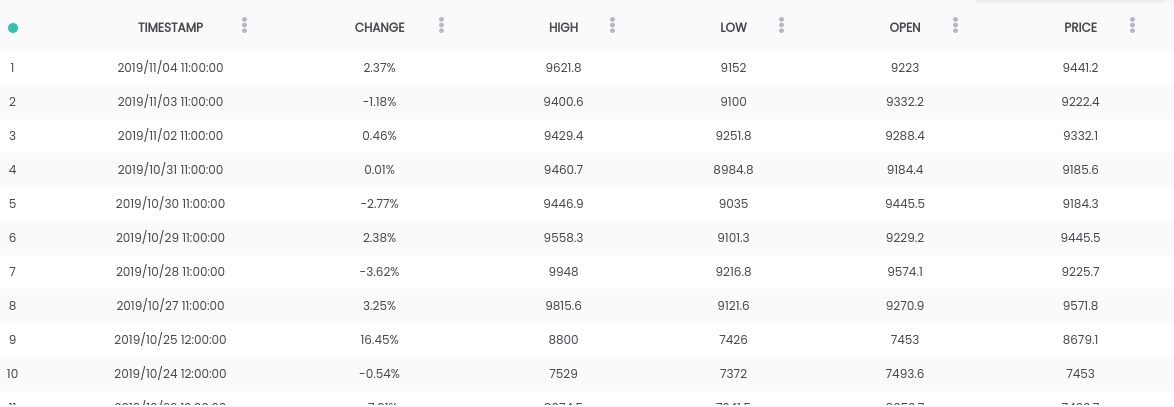 Dataset di atas berisi ringkasan harga harian, di mana kolom CHANGE adalah perubahan harga sebagai persentase dari harga hari sebelumnya ( PRICE ) versus yang baru ( OPEN ).Sasaran: Untuk mempermudah tugas, kami akan fokus memprediksi apakah harga akan naik ( GANTI> 0 ) atau turun ( GANTI <0 ) pada hari berikutnya. (Jadi kita berpotensi menggunakan prediksi "dalam kehidupan nyata").Persyaratan
Dataset di atas berisi ringkasan harga harian, di mana kolom CHANGE adalah perubahan harga sebagai persentase dari harga hari sebelumnya ( PRICE ) versus yang baru ( OPEN ).Sasaran: Untuk mempermudah tugas, kami akan fokus memprediksi apakah harga akan naik ( GANTI> 0 ) atau turun ( GANTI <0 ) pada hari berikutnya. (Jadi kita berpotensi menggunakan prediksi "dalam kehidupan nyata").Persyaratan- Python 2.6+ atau 3.1+ harus diinstal pada sistem
- Instal panda , sklearn , dan openblender (menggunakan pip)
$ pip install pandas OpenBlender scikit-learn
Langkah 1. Dapatkan Data Bitcoin
Untuk memulai, mari impor perpustakaan yang diperlukan:import OpenBlender
import pandas as pd
import json
Sekarang tarik data melalui API OpenBlender .Pertama, mari kita tentukan parameternya (dalam kasus kami, ini hanya id dari dataset bitcoin ):
parameters = {
'id_dataset':'5d4c3af79516290b01c83f51'
}
Catatan: Anda harus membuat akun di openblender.io (gratis) dan menambahkan token (Anda akan menemukannya di tab "Akun"):parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51'
}
Sekarang mari kita letakkan data dalam Dataframe 'df' :
def pullObservationsToDF(parameters):
action = 'API_getObservationsFromDataset'
df = pd.read_json(json.dumps(OpenBlender.call(action,parameters)['sample']), convert_dates=False,convert_axes=False) .sort_values('timestamp', ascending=False)
df.reset_index(drop=True, inplace=True)
return df
df = pullObservationsToDF(parameters)
Dan lihat mereka: Catatan: nilainya dapat bervariasi, karena dataset diperbarui setiap hari !
Catatan: nilainya dapat bervariasi, karena dataset diperbarui setiap hari !Langkah 2. Persiapan Data
Untuk memulainya, kita perlu membuat target perkiraan, yang akan menjadi apakah " PERUBAHAN " akan meningkat atau menurun. Untuk melakukan ini, tambahkan 'success_thr_over': 0 ke parameter ambang batas target:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change', 'success_thr_over': 0}
}
Jika kami menarik data dari API lagi:df = pullObservationsToDF(parameters)
df.head()
 Atribut "CHANGE" telah digantikan oleh atribut baru 'change_over_0', yang menjadi 1 jika "CHANGE" positif dan 0 jika tidak. Ini akan menjadi target pembelajaran mesin.Jika kami ingin memprediksi pengamatan untuk "besok", kami tidak akan dapat menggunakan informasi mulai besok, jadi mari kita tambahkan penundaan satu periode.
Atribut "CHANGE" telah digantikan oleh atribut baru 'change_over_0', yang menjadi 1 jika "CHANGE" positif dan 0 jika tidak. Ini akan menjadi target pembelajaran mesin.Jika kami ingin memprediksi pengamatan untuk "besok", kami tidak akan dapat menggunakan informasi mulai besok, jadi mari kita tambahkan penundaan satu periode.parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change','success_thr_over' : 0},
'lag_target_feature':{'feature':'change_over_0', 'periods' : 1}
}
df = pullObservationsToDF(parameters)
df.head()
 Ini hanya menyelaraskan 'change_over_0' dengan data untuk hari sebelumnya (periode) dan mengubah namanya menjadi 'TARGET_change_over_0' .Mari kita lihat ketergantungannya:
Ini hanya menyelaraskan 'change_over_0' dengan data untuk hari sebelumnya (periode) dan mengubah namanya menjadi 'TARGET_change_over_0' .Mari kita lihat ketergantungannya:target_variable = 'TARGET_change_over_0'
df = df.dropna()
df.corr()[target_variable].sort_values()
 Mereka independen secara linear dan tidak mungkin berguna.
Mereka independen secara linear dan tidak mungkin berguna.Langkah 3. Dapatkan Data Berita Bisnis
Setelah mencari dependensi di OpenBlender , saya menemukan dataset Fox Business News yang akan membantu menghasilkan perkiraan yang baik untuk target kami. Kita perlu menemukan cara untuk mengonversi nilai kolom 'judul' ke karakteristik numerik dengan menghitung pengulangan kata dan kelompok kata dalam ringkasan berita, dan membandingkannya tepat waktu dengan dataset bitcoin kami. Itu lebih mudah daripada kedengarannya.Pertama, Anda perlu membuat TextVectorizer untuk atribut 'title' dari berita:
Kita perlu menemukan cara untuk mengonversi nilai kolom 'judul' ke karakteristik numerik dengan menghitung pengulangan kata dan kelompok kata dalam ringkasan berita, dan membandingkannya tepat waktu dengan dataset bitcoin kami. Itu lebih mudah daripada kedengarannya.Pertama, Anda perlu membuat TextVectorizer untuk atribut 'title' dari berita:action = 'API_createTextVectorizer'
vectorizer_parameters = {
'token' : 'your_token',
'name' : 'Fox Business TextVectorizer',
'sources':[{'id_dataset' : '5d571f9e9516293a12ad4f6d',
'features' : ['title']}],
'ngram_range' : {'min' : 1, 'max' : 2},
'language' : 'en',
'remove_stop_words' : 'on',
'min_count_limit' : 2
}
Kami akan membuat vektorizer untuk mendapatkan semua tanda sebagai kata-kata token dalam bentuk angka. Di atas, kami menunjukkan yang berikut:- nama : sebut saja 'Fox Business TextVectorizer' ;
- jangkar : id dataset dan nama karakteristik yang perlu kita gunakan sebagai sumber (dalam kasus kami, hanya kolom 'judul' );
- ngram_range : panjang minimum dan maksimum dari serangkaian kata untuk tokenization;
- bahasa : Inggris
- remove_stop_words : untuk menghapus kata-kata berhenti dari sumber;
- min_count_limit : jumlah minimum pengulangan yang harus dianggap sebagai token (kejadian tunggal jarang berguna).
Sekarang jalankan ini:res = OpenBlender.call(action, vectorizer_parameters)
res
Menjawab:{
'message' : 'TextVectorizer created successfully.'
'id_textVectorizer' : '5dc1a404951629331f6359dd',
'num_ngrams': 4270
}
TextVectorizer
telah dibuat , yang menghasilkan 4270 n-gram sesuai dengan konfigurasi kami. Beberapa saat kemudian kita akan membutuhkan id yang dihasilkan:5dc1a404951629331f6359ddLangkah 4. Ringkasan berita yang kompatibel dengan dataset bitcoin
Sekarang kita perlu membandingkan ringkasan berita dan data nilai tukar bitcoin tepat waktu. Secara umum, ini berarti Anda harus menggabungkan dua set data menggunakan cap waktu sebagai kunci. Mari tambahkan data gabungan ke opsi ekstraksi data asli kami:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'specifications':{'time_interval_size' : 3600*12 }}]
}
Di atas, kami menunjukkan yang berikut:- id_blend : id dari textVectorizer kami;
- blend_type : 'text_ts' sehingga Python memahami bahwa itu adalah campuran teks dan cap waktu;
- pembatasan : 'prediktif' , sehingga tidak ada "pencampuran" berita dari masa depan dengan semua pengamatan, tetapi hanya dengan yang dipublikasikan lebih awal dari waktu yang ditentukan.
- blend_class : 'proximity_observation' , sehingga hanya pengamatan terdekat yang "dicampur";
- spesifikasi : jumlah waktu maksimum yang dimungkinkan untuk transfer pengamatan, dalam hal ini 12 jam (3600 * 12). Ini berarti bahwa setiap pengamatan harga bitcoin akan diprediksi berdasarkan berita 12 jam terakhir.
Akhirnya, kami hanya menambahkan filter berdasarkan tanggal 'date_filter' , mulai 20 Agustus, karena saat itulah Fox News mulai mengumpulkan data, dan 'drop_non_numeric' sehingga kami hanya mendapatkan nomor:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'blend_class' : 'closest_observation',
'specifications':{'time_interval_size' : 3600*12 }}],
'date_filter':{'start_date':'2019-08-20T16:59:35.825Z',
'end_date':'2019-11-04T17:59:35.825Z'},
'drop_non_numeric' : 1
}
Catatan : Saya menunjukkan 4 November sebagai 'end_date' , karena itu adalah hari saya menulis kode ini, Anda dapat mengubah tanggal.Mari kita dapatkan data lagi:df = pullObservationsToDF(parameters)
print(df.shape)
df.head()
(57, 2115) Sekarang kami memiliki lebih dari 2000 tanda dengan token dan 57 pengamatan.
Sekarang kami memiliki lebih dari 2000 tanda dengan token dan 57 pengamatan.Langkah 5. Terapkan ML ke target prediksi
Sekarang, akhirnya, kami memiliki dataset yang bersih, dan tampilannya persis seperti yang kami butuhkan, dengan offset waktu dari target dan data numerik terkait.Mari kita lihat korelasi tertinggi dengan 'Target_change_over_0' : Sekarang kita memiliki beberapa atribut yang saling berkorelasi. Mari kita membagi dataset menjadi pelatihan dan uji dalam urutan kronologis sehingga kita bisa melatih model dalam pengamatan awal dan menguji yang berikutnya.
Sekarang kita memiliki beberapa atribut yang saling berkorelasi. Mari kita membagi dataset menjadi pelatihan dan uji dalam urutan kronologis sehingga kita bisa melatih model dalam pengamatan awal dan menguji yang berikutnya.X = df.loc[:, df.columns != target_variable].values
y = df.loc[:,[target_variable]].values
div = int(round(len(X) * 0.29))
X_test = X[:div]
y_test = y[:div]
print(X_test.shape)
print(y_test.shape)
X_train = X[div:]
y_train = y[div:]
print(X_train.shape)
print(y_train.shape)
 Kami memiliki 40 pengamatan untuk pelatihan dan 17 untuk pengujian.Sekarang kami mengimpor perpustakaan yang diperlukan:
Kami memiliki 40 pengamatan untuk pelatihan dan 17 untuk pengujian.Sekarang kami mengimpor perpustakaan yang diperlukan:from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_score
from sklearn import metrics
Sekarang, mari kita gunakan hutan acak (RandomForest) dan membuat prediksi:rf = RandomForestRegressor(n_estimators = 1000)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
Untuk mempermudah, mari letakkan prediksi dan y_test di dalam Dataframe:df_res = pd.DataFrame({'y_test':y_test[:,0], 'y_pred':y_pred})
df_res.head()
'Y_test'
kami yang sebenarnya adalah biner, tetapi perkiraan kami adalah tipe float , jadi mari kita mengumpulkannya, dengan asumsi bahwa jika mereka lebih besar dari 0,5, ini berarti kenaikan harga, dan jika kurang dari 0,5 - penurunan.threshold = 0.5
preds = [1 if val > threshold else 0 for val in df_res['y_pred']]
Sekarang, untuk lebih memahami hasil, kami mendapatkan AUC, matriks kesalahan dan indikator akurasi:print(roc_auc_score(preds, df_res['y_test']))
print(metrics.confusion_matrix(preds, df_res['y_test']))
print(accuracy_score(preds, df_res['y_test']))
 Kami mendapat 64,7% dari prediksi yang benar dengan 0,65 AUC.
Kami mendapat 64,7% dari prediksi yang benar dengan 0,65 AUC.- 9 kali kami memperkirakan penurunan, dan harga menurun (kanan);
- 5 kali kami memperkirakan penurunan, dan harga naik (salah);
- 1 kali kami memperkirakan kenaikan, tetapi harga turun secara tidak benar);
- 2 kali kami memperkirakan kenaikan, dan harga naik (benar).
Pelajari lebih lanjut tentang kursus .