Ketika tahun yang berbuah berakhir, saya ingin melihat ke belakang, mengambil stok dan menunjukkan apa yang bisa kami lakukan selama waktu ini. Perpustakaan #DeepPavlov, sebentar, sudah berusia dua tahun, dan kami senang bahwa komunitas kami berkembang setiap hari.Selama setahun bekerja di perpustakaan, kami telah mencapai:- Unduhan perpustakaan meningkat sepertiga dibandingkan tahun lalu. Sekarang DeepPavlov memiliki lebih dari 100 ribu instalasi dan lebih dari 10 ribu instalasi kontainer.
- Jumlah solusi komersial telah meningkat karena teknologi tercanggih yang diterapkan di DeepPavlov, di berbagai industri mulai dari ritel hingga industri.
- Rilis pertama DeepPavlov Agent telah dirilis .
- Jumlah anggota masyarakat yang aktif telah meningkat 5 kali lipat.
- Tim mahasiswa sarjana dan pascasarjana kami dipilih untuk berpartisipasi dalam Tantangan Alexb Prize Sosialbot 3 .
- Perpustakaan telah menjadi pemenang kontes dari perusahaan Google «Didukung oleh TensorFlow Challenge».
Apa yang membantu mencapai hasil seperti itu dan mengapa DeepPavlov sumber terbuka terbaik untuk membangun AI percakapan? Kami akan kirim di artikel kami.
#DeepPavlov membidik hasilnya
Baru-baru ini, sistem dialog telah menjadi standar untuk interaksi manusia-mesin. Chatbots digunakan di hampir semua industri, menyederhanakan interaksi antara orang dan komputer. Mereka berintegrasi dengan mulus ke situs web, platform pengiriman pesan, dan perangkat. Banyak perusahaan saat ini lebih suka mendelegasikan tugas rutin ke sistem interaktif yang dapat menangani beberapa permintaan pengguna sekaligus, menghemat biaya tenaga kerja.Namun, seringkali perusahaan tidak tahu harus mulai dari mana ketika mengembangkan bot untuk memenuhi kebutuhan bisnis mereka. Secara historis, chatbots dapat dibagi menjadi dua kelompok besar: berdasarkan aturan dan berdasarkan data. Jenis pertama bergantung pada perintah dan templat yang telah ditentukan. Setiap perintah ini harus ditulis oleh pengembang chatbot menggunakan ekspresi reguler dan analisis data teks. Sebaliknya, bot obrolan berbasis data bergantung pada model pembelajaran mesin yang telah dilatih sebelumnya tentang data dialog.Perpustakaan Sumber Terbuka - DeepPavlovmenawarkan solusi gratis dan mudah digunakan untuk membangun sistem interaktif. DeepPavlov hadir dengan beberapa komponen pra-terlatih untuk menyelesaikan masalah yang terkait dengan pemrosesan bahasa alami (NLP). DeepPavlov memecahkan masalah seperti: klasifikasi teks, koreksi kesalahan ketik, pengakuan entitas bernama, jawaban atas pertanyaan pada basis pengetahuan dan banyak lainnya. Dan Anda dapat menginstal DeepPavlov dalam satu baris dengan menjalankan:pip install -q deeppavlov
* Kerangka kerja ini memungkinkan Anda untuk melatih dan menguji model, serta menyesuaikan hiperparameter mereka. Perpustakaan mendukung platform Linux dan Windows. Anda dapat mencoba ini dan model lain di versi demo perpustakaan .Saat ini, hasil modern dalam banyak tugas telah dicapai melalui penggunaan model berdasarkan BERT. Tim DeepPavlov mengintegrasikan BERT ke dalam tiga tugas berikut: klasifikasi teks, pengakuan entitas yang disebutkan, dan jawaban atas pertanyaan. Sebagai hasilnya, kami telah melakukan peningkatan yang signifikan dalam semua tugas ini.1. BERT DeepPavlov Models
BERT untuk klasifikasi teks
Model klasifikasi teks berdasarkan BERT DeepPavlov berfungsi, misalnya, untuk memecahkan masalah mendeteksi penghinaan. Model ini mencakup memprediksi apakah komentar yang dipublikasikan dalam diskusi publik dianggap menyinggung salah satu peserta. Untuk kasus ini, klasifikasi dilakukan hanya dalam dua kelas: penghinaan dan bukan penghinaan.Setiap model pra-terlatih dapat digunakan untuk keluaran baik melalui antarmuka baris perintah (CLI) maupun melalui Python. Sebelum menggunakan model, pastikan bahwa semua paket yang diperlukan diinstal menggunakan perintah:python -m deeppavlov install insults_kaggle_bert
python -m deeppavlov interact insults_kaggle_bert -d
BERT untuk Pengakuan Entitas Bernama
Selain model klasifikasi teks, DeepPavlov menyertakan model berbasis BERT untuk bernama entitas recognition (NER). Ini adalah salah satu tugas paling umum di NLP dan model perpustakaan kami yang paling banyak digunakan. Pada saat yang sama, NER memiliki banyak aplikasi bisnis. Misalnya, sebuah model dapat mengekstraksi informasi penting dari resume untuk memfasilitasi pekerjaan spesialis sumber daya manusia. Selain itu, APM dapat digunakan untuk mengidentifikasi entitas yang relevan dalam permintaan pelanggan, seperti spesifikasi produk, nama perusahaan, atau informasi cabang perusahaan.Tim DeepPavlov melatih model NER dalam paket OntoNotes berbahasa Inggris, yang memiliki 19 jenis markup, termasuk PER (orang), LOC (lokasi), ORG (organisasi), dan banyak lainnya. Untuk berinteraksi dengan, Anda harus menginstalnya dengan perintah:python -m deeppavlov install ner_ontonotes_bert_mult
python -m deeppavlov interact ner_ontonotes_bert_mult [-d]
BERT untuk menjawab pertanyaan Sebuah
jawaban kontekstual untuk sebuah pertanyaan adalah tugas untuk menemukan jawaban atas sebuah pertanyaan dalam konteks tertentu (misalnya, paragraf dari Wikipedia), di mana jawaban untuk setiap pertanyaan adalah segmen konteks. Misalnya, tiga konteks, pertanyaan dan jawaban di bawah ini membentuk triplet yang benar untuk tugas menjawab pertanyaan.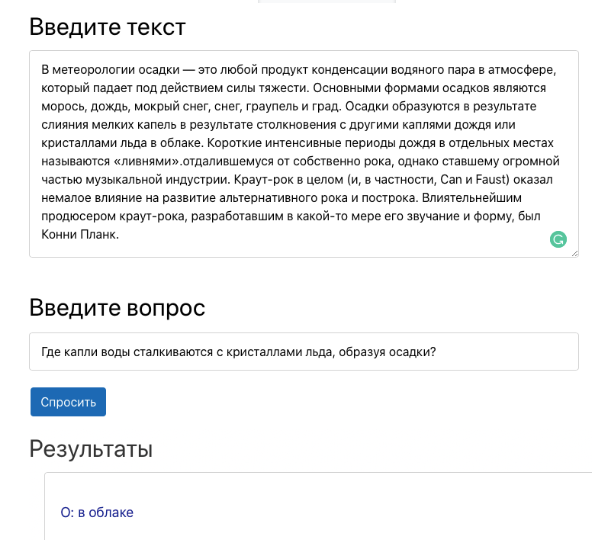 Presentasi karya sistem tanya jawab dalam sebuah demo.Sistem jawaban untuk pertanyaan dapat mengotomatiskan banyak proses dalam bisnis. Misalnya, ini dapat membantu pengusaha mendapatkan jawaban berdasarkan dokumentasi internal perusahaan. Selain itu, model ini akan membantu menguji kemampuan siswa untuk memahami teks dalam proses pembelajaran. Namun, baru-baru ini, tugas menjawab pertanyaan berdasarkan konteks telah menarik perhatian para ilmuwan. Salah satu titik balik utama dalam bidang ini adalah pelepasan Stanford Question Answer Set (SQuAD). Dataset SQuAD telah menyebabkan banyak pendekatan untuk memecahkan masalah sistem tanya jawab. Salah satu yang paling sukses adalah model DeepPavlov BERT. Ini melampaui semua yang lain dan saat ini menghasilkan hasil yang berbatasan dengan karakteristik manusia.Untuk menggunakan model QA berbasis BERT dengan DeepPavlov, Anda harus:
Presentasi karya sistem tanya jawab dalam sebuah demo.Sistem jawaban untuk pertanyaan dapat mengotomatiskan banyak proses dalam bisnis. Misalnya, ini dapat membantu pengusaha mendapatkan jawaban berdasarkan dokumentasi internal perusahaan. Selain itu, model ini akan membantu menguji kemampuan siswa untuk memahami teks dalam proses pembelajaran. Namun, baru-baru ini, tugas menjawab pertanyaan berdasarkan konteks telah menarik perhatian para ilmuwan. Salah satu titik balik utama dalam bidang ini adalah pelepasan Stanford Question Answer Set (SQuAD). Dataset SQuAD telah menyebabkan banyak pendekatan untuk memecahkan masalah sistem tanya jawab. Salah satu yang paling sukses adalah model DeepPavlov BERT. Ini melampaui semua yang lain dan saat ini menghasilkan hasil yang berbatasan dengan karakteristik manusia.Untuk menggunakan model QA berbasis BERT dengan DeepPavlov, Anda harus:python -m deeppavlov install squad_bert
python -m deeppavlov interact squad_bert -d
Lebih banyak model dapat ditemukan dalam dokumentasi . Dan jika Anda memerlukan tutorial tentang cara menggunakan komponen perpustakaan, maka cari di blog resmi kami .2. DeepPavlov Agent - platform untuk membuat bot obrolan multi-tasking
Saat ini, ada beberapa pendekatan untuk pengembangan agen interaktif. Saat mengembangkan agen percakapan, arsitektur modular terutama digunakan untuk dialog terfokus di mana skrip dibuka. Namun, seringkali pengguna perlu menggabungkan dialog yang terfokus, misalnya, dengan fungsi lain - menjawab pertanyaan atau mencari informasi, serta mempertahankan percakapan. Dengan demikian, agen dialog yang ideal adalah asisten pribadi yang menggabungkan berbagai jenis agen, beralih antara fungsi dan karakternya, tergantung pada tugas apa yang digunakan. Pada saat yang sama, agen harus mengumpulkan informasi tentang esensinya, menyesuaikan algoritmenya dengan pengguna tertentu. Di sisi lain, harus dapat berintegrasi dengan layanan eksternal. Contohnya,membuat pertanyaan ke database eksternal, mendapatkan informasi dari sana, memprosesnya, menyoroti yang penting dan mengirimkannya ke pengguna. Untuk mengatasi masalah ini, pada Oktober 2019, rilis pertama DeepPavlov Agent 1.0, platform untuk membuat bot obrolan multi-tasking, dirilis. Agen membantu pengembang chatbots produksi mengatur beberapa model NLP dalam satu pipa.Baca lebih lanjut tentang platform dan fitur dalam dokumentasi .3. Implementasi DeepPavlov NLP SaaS
Untuk menyederhanakan pekerjaan dengan model NLP pra-terlatih dari DeepPavlov, pada bulan September 2019, layanan SaaS diluncurkan. DeepPavlov Cloud memungkinkan Anda untuk menganalisis teks, serta menyimpan dokumen di cloud. Untuk menggunakan model, Anda harus mendaftar di layanan kami dan mendapatkan token di bagian Token di akun pribadi Anda. Saat ini, layanan ini mendukung beberapa model NLP yang sudah dilatih sebelumnya dalam bahasa Rusia dan sedang dalam proses pengujian sistem.4. Partisipasi dalam DSCT8 atau sistem dialog yang ditargetkan
Penggunaan asisten virtual seperti Amazon Alexa dan Google Assistant telah membuka peluang untuk mengembangkan aplikasi yang memungkinkan kita menyederhanakan pelaksanaan banyak tugas sehari-hari, seperti memesan taksi, memesan meja di restoran, dan banyak lainnya. Untuk mengatasi masalah tersebut, digunakan sistem dialog terfokus.Dialogue State Traking (DST) adalah komponen kunci dalam sistem dialog semacam itu. DST bertanggung jawab untuk menerjemahkan ucapan dalam bahasa manusia ke dalam representasi semantik bahasa, khususnya, untuk mengekstraksi maksud dan pasangan nilai slot yang sesuai dengan tujuan pengguna.Selama partisipasi tim dalam DSTC8Model GOLOMB (Pelacak status dialog berbasis BERT Multi-tugas yang berorientasi GOAL) dikembangkan - model multi-tugas berorientasi tujuan yang didasarkan pada BERT untuk melacak keadaan dialog. Untuk memprediksi keadaan dialog, model memecahkan beberapa masalah klasifikasi dan tugas menemukan substring. Segera model ini akan muncul di perpustakaan DeepPavlov. Sementara itu, Anda dapat membaca artikel selengkapnya di sini . Presentasi poster di konferensi AAAI-20 di New York (AS).
Presentasi poster di konferensi AAAI-20 di New York (AS).
5. Partisipasi dalam Tantangan Grand Alexb Prize Socialbot
Tim DeepPavlov, yang terdiri dari mahasiswa dan mahasiswa pascasarjana dari Institut Fisika dan Teknologi Moskwa, dipilih untuk berpartisipasi dalam Alexa Prize Socialbot Grand Challenge 3 - sebuah kompetisi internasional yang didedikasikan untuk pengembangan teknologi AI percakapan. Tujuan dari kompetisi ini adalah untuk menciptakan bot yang dapat berkomunikasi secara bebas dengan orang-orang tentang topik yang relevan. Dari 375 aplikasi, komite Hadiah Alexa memilih 10 finalis, termasuk tim kami - MIMPI. Saat ini, tim telah pindah ke perempat final kompetisi dan berjuang untuk mencapai semifinal. Anda dapat mengikuti berita dan mendukung kami di halaman resmi , dan jangan lupa untuk berlangganan Twitter . Komposisi tim Tim Impian.
Komposisi tim Tim Impian.
6. Partisipasi dalam Tantangan Powered by TF
Seperti yang dinyatakan sebelumnya, DeepPavlov hadir dengan beberapa komponen pra-dilatih yang ditenagai oleh TensorFlow dan Keras. Dan tahun ini, tim DeepPavlov memenangkan kontes Google Powered by TF Challenge untuk proyek pembelajaran mesin terbaik yang menggunakan perpustakaan TensorFlow. Dari lebih dari 600 peserta kontes, Google memilih lima proyek terbaik, salah satunya adalah perpustakaan DeepPavlov. Proyek ini dipresentasikan di blog resmi TensorFlow . Perlu dicatat bahwa fleksibilitas TensorFlow memungkinkan kita untuk membuat arsitektur jaringan saraf apa pun yang dapat kita pikirkan. Dan khususnya, kami menggunakan TensorFlow untuk integrasi tanpa batas dengan model berbasis BERT.
7. Pengembangan masyarakat
Tujuan global dari proyek kami adalah untuk memungkinkan pengembang dan peneliti di bidang kecerdasan buatan percakapan untuk menggunakan alat yang paling canggih untuk menciptakan sistem interaktif generasi mendatang, serta untuk menjadi platform yang signifikan secara internasional di bidang AI untuk pertukaran pengalaman dan pengajaran teknologi canggih.Untuk mencapai ini, karyawan DeepPavlovmelakukan kursus pelatihan semester gratis untuk siswa dan staf yang terlibat dalam Ilmu Komputer. Salah satunya adalah kursus: "Pembelajaran mendalam dalam pemrosesan bahasa alami" ", yang meliputi seminar dan lokakarya. Kelas mencakup topik-topik seperti: membangun sistem dialog, metode untuk mengevaluasi sistem dialog dengan kemampuan untuk menghasilkan respons, berbagai kerangka kerja untuk sistem dialog, metode untuk memperkirakan jumlah remunerasi karena optimalisasi kebijakan dialog, jenis permintaan pengguna, pertimbangan pemodelan panggilan call-center. Pada tahun 2020, kami meluncurkan rekrutmen baru dan sudah 900 siswa dan karyawan menjalani pelatihan gratis. Anda dapat mengikuti berita dan set untuk ini dan kursus lainnya di situs web kami . Dan jika Anda melewatkan kursus, tetapi ingin belajar lebih banyak - maka pada kamiSaluran youtube Anda selalu dapat menemukannya dalam catatan.Hari ini, perpustakaan DeepPavlov menyediakan komponen siap AI untuk bekerja dengan teks, yang digunakan di 92 negara di dunia. Pada Februari 2020, jumlah unduhan perpustakaan mencapai 100.000 ribu, dan dinamika instalasi mendapatkan momentum. Juga, lebih dari 30 perusahaan di Rusia telah menerapkan dan berhasil menggunakan solusi berdasarkan DeepPavlov. Ini menunjukkan bahwa solusi semacam itu sangat populer di seluruh dunia.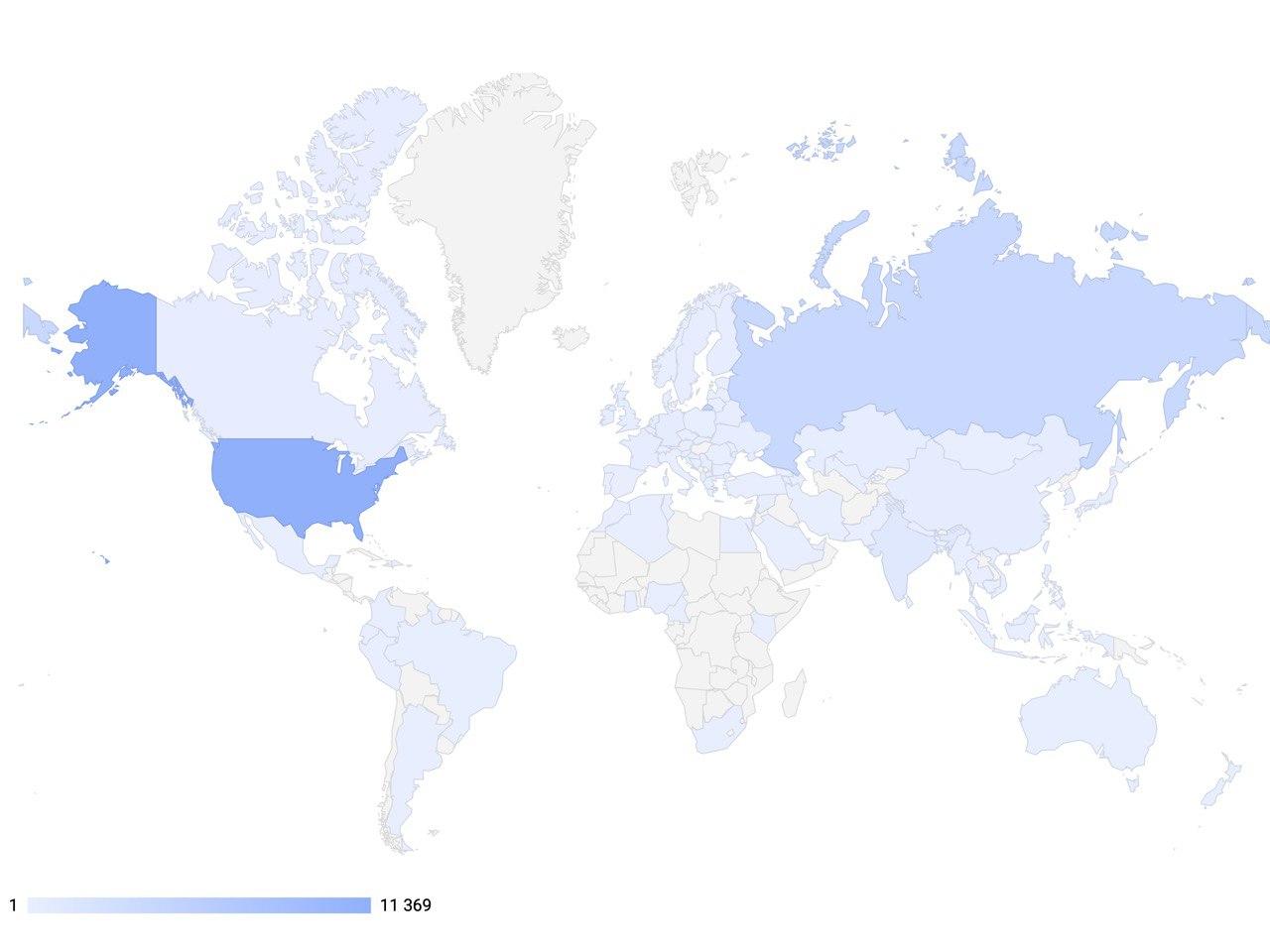
Apa berikutnya?
Kami senang berbagi kesuksesan kami dengan Anda, jadi kami telah menyiapkan acara untuk komunitas kami. Kami ingin berbagi pengalaman dan pengetahuan dari proyek produksi nyata tentang cara membuat asisten AI terbaik. Bergabunglah dengan pertemuan para pengguna dan pengembang perpustakaan terbuka DeepPavlov pada 28 Februari untuk berbicara tentang kecerdasan buatan dan aplikasinya, serta bertemu dengan anggota komunitas lainnya. Acara ini akan diadakan sebagai bagian dari minggu AI mulai 25 hingga 28 Februari. Kami menunggu semua orang yang menggunakan DeepPavlov atau ingin mengenal teknologi kami.Semua informasi tentang pembicara dan program dapat ditemukan di situs, pendaftaran diperlukan untuk menghadiri acara tersebut.Bergabunglah: DeepPavlov 2 tahun
Industri AI akan terus berkembang, dan kami percaya bahwa DeepPavlov akan menjadi teknologi canggih yang akan digunakan setiap pengembang untuk memahami bahasa alami. Tahun depan, kami akan bekerja untuk menggandakan komunitas kami, meningkatkan alat sumber terbuka, dan meningkatkan penelitian pembelajaran mesin. Dan jangan lupa bahwa DeepPavlov memiliki forum - ajukan pertanyaan Anda tentang perpustakaan dan model. Terimakasih atas perhatiannya!