Baru-baru ini, tugas pengenalan karakter dalam program aplikasi tidak terlalu sulit - Anda dapat menggunakan banyak pustaka OCR-siap pakai, banyak di antaranya hampir sempurna. Namun demikian, terkadang tugas mungkin muncul untuk mengembangkan algoritme pengenalan Anda sendiri tanpa menggunakan pustaka OCR "canggih" pihak ketiga.
Ini persis tugas yang muncul selama pekerjaan saya, dan ada beberapa alasan mengapa lebih baik untuk tidak menggunakan perpustakaan yang sudah jadi: proyek tertutup, dengan sertifikasi lebih lanjut, pembatasan tertentu pada jumlah baris kode dan ukuran perpustakaan yang terhubung, lebih-lebih karena Anda harus cukup mengenali bidang subjek set karakter tertentu.
Algoritma pengenalan sederhana, dan, tentu saja, tidak berpura-pura sebagai yang paling akurat, cepat dan efektif, tetapi berupaya dengan tugas kecilnya dengan baik.
Misalkan kita memiliki input dalam bentuk gambar pindaian dokumen dalam bentuk terstruktur. Dokumen-dokumen ini memiliki kode satu karakter khusus yang terletak di sudut kiri atas. Tugas kita adalah mengenali simbol ini dan kemudian melakukan beberapa tindakan, misalnya, mengklasifikasikan dokumen sumber sesuai dengan aturan yang diberikan.

Diagram algoritma adalah sebagai berikut:
 Karena kita tahu sebelumnya di mana simbol kita berada, memotong area tertentu tidaklah sulit. Untuk menghapus semua "penyimpangan" dari tepi simbol, kami menerjemahkan gambar menjadi monokrom (hitam dan putih).
Karena kita tahu sebelumnya di mana simbol kita berada, memotong area tertentu tidaklah sulit. Untuk menghapus semua "penyimpangan" dari tepi simbol, kami menerjemahkan gambar menjadi monokrom (hitam dan putih).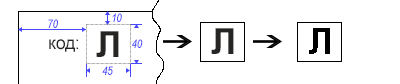
short width = 45, height = 40, offsetTop = -10, offsetLeft = -70;
BufferedImage image = ImageIO.read(file);
BufferedImage symbol = new BufferedImage(width, height, BufferedImage.TYPE_BYTE_BINARY);
Graphics2D g = symbol.createGraphics();
g.drawImage(image, offsetLeft, offsetTop, null);
Selanjutnya, Anda perlu mengubah fragmen "pixel by pixel" yang dihasilkan menjadi string biner, yaitu string di mana, misalnya, '*' berhubungan dengan piksel hitam, dan spasi menjadi putih.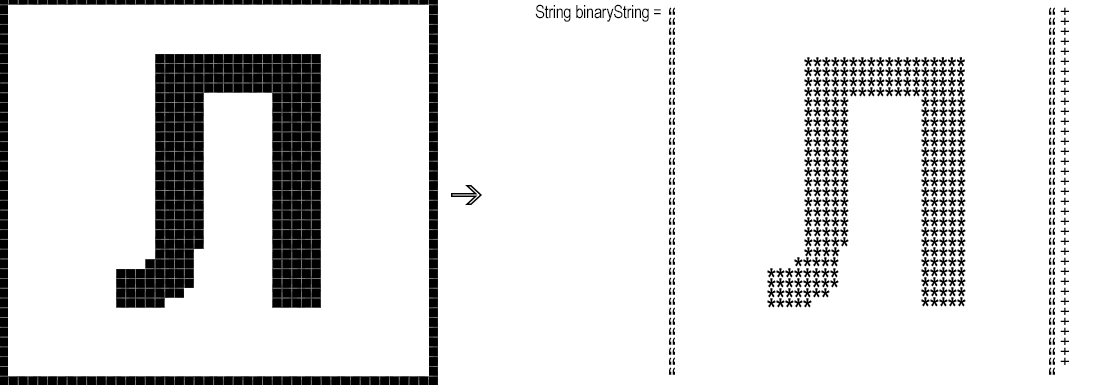
short whiteBg = -1;
StringBuilder binaryString = new StringBuilder();
for (short y = 1; y < height; y++)
for (short x = 1; x < width; x++) {
int rgb = symbol.getRGB(x, y);
binaryString.append(rgb == whiteBg ? " " : "*");
}
Selanjutnya, Anda perlu menemukan jarak Levenshtein minimum antara string yang diterima dan string referensi yang sudah disiapkan sebelumnya (pada kenyataannya, Anda dapat mengambil metode perbandingan string apa pun).int min = 1000000;
char findSymbol = "";
for (Map.Entry<Character, String> entry : originalMap.entrySet()) {
int levenshtein = levenshtein(binaryString.toString(), entry.getValue());
if (levenshtein < min) {
min = levenshtein;
findSymbol = entry.getKey();
}
}
Fungsi menemukan jarak Levenshtein diimplementasikan sebagai metode sesuai dengan algoritma standar:public static int levenshtein(String targetStr, String sourceStr) {
int m = targetStr.length(), n = sourceStr.length();
int[][] delta = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++)
delta[i][0] = i;
for (int j = 1; j <= n; j++)
delta[0][j] = j;
for (int j = 1; j <= n; j++)
for (int i = 1; i <= m; i++) {
if (targetStr.charAt(i - 1) == sourceStr.charAt(j - 1))
delta[i][j] = delta[i - 1][j - 1];
else
delta[i][j] = Math.min(delta[i - 1][j] + 1,
Math.min(delta[i][j - 1] + 1, delta[i - 1][j - 1] + 1));
}
return delta[m][n];
}
FindSymbol yang dihasilkan akan menjadi karakter kita yang dikenali.Algoritma ini dapat dioptimalkan untuk meningkatkan kinerja dan dilengkapi dengan berbagai pemeriksaan untuk meningkatkan efisiensi pengenalan. Banyak indikator bergantung pada area subjek tertentu dari masalah yang sedang dipecahkan (jumlah karakter, variasi font, kualitas gambar, dll.).Dengan cara praktis, ditemukan bahwa metode ini secara kualitatif mengatasi bahkan masalah yang bermasalah seperti “kesamaan” karakter, misalnya, “L” <-> "P", "5" <-> "S", "O" <-> "0". Karena, misalnya, jarak antara string biner "L" dan "P" akan selalu lebih besar daripada antara "L" yang diakui dan string referensi "L", bahkan dengan beberapa "penyimpangan".Secara umum, jika Anda perlu menyelesaikan masalah yang sama (misalnya, pengenalan kartu remi), dengan sejumlah pembatasan pada penggunaan neuron dan solusi siap pakai lainnya, Anda dapat dengan aman mengambil dan memodifikasi metode ini.