Pada artikel ini, saya akan berbicara tentang beberapa trik sederhana yang berguna ketika bekerja dengan data yang tidak sesuai dengan mesin lokal, tetapi masih terlalu kecil untuk disebut Besar. Mengikuti analogi bahasa Inggris (besar tapi tidak besar), kami akan menyebut data ini tebal. Kita berbicara tentang ukuran unit dan puluhan gigabyte.[Penafian] Jika Anda menyukai SQL, semua yang ditulis di bawah ini dapat menyebabkan Anda memiliki emosi negatif yang cerah dan kemungkinan besar, di Belanda ada 49262 Tesla, 427 di antaranya adalah taksi, lebih baik tidak membaca lebih lanjut [/ Penafian]. Titik awalnya adalah artikel di hub dengan deskripsi kumpulan data yang menarik - daftar lengkap kendaraan yang terdaftar di Belanda, 14 juta jalur, semuanya dari traktor truk hingga sepeda listrik dengan kecepatan di atas 25 km / jam.Perangkat ini menarik, membutuhkan 7 GB, Anda dapat mengunduhnya di situs web organisasi yang bertanggung jawab.Upaya untuk mengarahkan data seperti yang ada di panda untuk menyaring dan membersihkannya berakhir dengan kegagalan (tuan-tuan dari prajurit berkuda SQL, saya memperingatkan!). Panda jatuh dari kekurangan memori di desktop dengan 8 GB. Dengan sedikit pertumpahan darah, pertanyaannya dapat diatasi jika Anda ingat bahwa panda dapat membaca file csv dalam ukuran sedang. Ukuran fragmen dalam baris ditentukan oleh parameter chunksize.Untuk mengilustrasikan pekerjaan, kami akan menulis fungsi sederhana yang membuat permintaan dan menentukan berapa total mobil Tesla dan berapa proporsi mereka yang bekerja di taksi. Tanpa trik dengan membaca fragmen, permintaan seperti itu pertama-tama memakan semua memori, kemudian menderita untuk waktu yang lama, dan pada akhirnya ramp jatuh.Dengan membaca fragmen, fungsi kita akan terlihat seperti ini:
Titik awalnya adalah artikel di hub dengan deskripsi kumpulan data yang menarik - daftar lengkap kendaraan yang terdaftar di Belanda, 14 juta jalur, semuanya dari traktor truk hingga sepeda listrik dengan kecepatan di atas 25 km / jam.Perangkat ini menarik, membutuhkan 7 GB, Anda dapat mengunduhnya di situs web organisasi yang bertanggung jawab.Upaya untuk mengarahkan data seperti yang ada di panda untuk menyaring dan membersihkannya berakhir dengan kegagalan (tuan-tuan dari prajurit berkuda SQL, saya memperingatkan!). Panda jatuh dari kekurangan memori di desktop dengan 8 GB. Dengan sedikit pertumpahan darah, pertanyaannya dapat diatasi jika Anda ingat bahwa panda dapat membaca file csv dalam ukuran sedang. Ukuran fragmen dalam baris ditentukan oleh parameter chunksize.Untuk mengilustrasikan pekerjaan, kami akan menulis fungsi sederhana yang membuat permintaan dan menentukan berapa total mobil Tesla dan berapa proporsi mereka yang bekerja di taksi. Tanpa trik dengan membaca fragmen, permintaan seperti itu pertama-tama memakan semua memori, kemudian menderita untuk waktu yang lama, dan pada akhirnya ramp jatuh.Dengan membaca fragmen, fungsi kita akan terlihat seperti ini:def pandas_chunky_query():
print('reading csv file with pandas in chunks')
filtered_chunk_list=[]
for chunk in pd.read_csv('C:\Open_data\RDW_full.CSV', chunksize=1E+6):
filtered_chunk=chunk[chunk['Merk'].isin(['TESLA MOTORS','TESLA'])]
filtered_chunk_list.append(filtered_chunk)
model_df = pd.concat(filtered_chunk_list)
print(model_df['Taxi indicator'].value_counts())
Dengan menentukan jutaan baris yang masuk akal, Anda dapat menjalankan kueri dalam 1:46 dan menggunakan memori 1965 M pada puncaknya. Semua angka untuk desktop bisu dengan sesuatu yang kuno, delapan inti sekitar 8 GB memori dan di bawah Windows ketujuh.
 Jika Anda mengubah chunksize, maka konsumsi memori puncak mengikutinya secara harfiah, waktu eksekusi tidak banyak berubah. Untuk jalur 0,5 M, permintaan membutuhkan 1:44 dan 1063 MB, untuk 2M 1:53 dan 3762 MB.Kecepatannya tidak terlalu menyenangkan, bahkan kurang menyenangkan adalah bahwa membaca file dalam fragmen memaksa Anda untuk menulis disesuaikan untuk fungsi ini, bekerja dengan daftar fragmen yang kemudian harus dikumpulkan dalam bingkai data. Juga, format csv itu sendiri tidak terlalu senang, yang memakan banyak ruang dan perlahan dibaca.Karena kita dapat mengarahkan data ke ramp, format Apachev yang jauh lebih ringkas dapat digunakan untuk penyimpananparket di mana ada kompresi, dan, berkat skema data, itu jauh lebih cepat dibaca ketika dibaca. Dan jalannya cukup bisa bekerja dengannya. Hanya sekarang tidak bisa membacanya dalam fragmen. Apa yang harus dilakukan?- Ayo bersenang-senang, ambil aksara
Jika Anda mengubah chunksize, maka konsumsi memori puncak mengikutinya secara harfiah, waktu eksekusi tidak banyak berubah. Untuk jalur 0,5 M, permintaan membutuhkan 1:44 dan 1063 MB, untuk 2M 1:53 dan 3762 MB.Kecepatannya tidak terlalu menyenangkan, bahkan kurang menyenangkan adalah bahwa membaca file dalam fragmen memaksa Anda untuk menulis disesuaikan untuk fungsi ini, bekerja dengan daftar fragmen yang kemudian harus dikumpulkan dalam bingkai data. Juga, format csv itu sendiri tidak terlalu senang, yang memakan banyak ruang dan perlahan dibaca.Karena kita dapat mengarahkan data ke ramp, format Apachev yang jauh lebih ringkas dapat digunakan untuk penyimpananparket di mana ada kompresi, dan, berkat skema data, itu jauh lebih cepat dibaca ketika dibaca. Dan jalannya cukup bisa bekerja dengannya. Hanya sekarang tidak bisa membacanya dalam fragmen. Apa yang harus dilakukan?- Ayo bersenang-senang, ambil aksara tombol Dask dan percepat!Dask! Pengganti untuk jalan keluar dari kotak, dapat membaca file besar, mampu bekerja secara paralel pada beberapa core, dan menggunakan perhitungan malas. Yang mengejutkan saya tentang Dask di Habré hanya ada 4 publikasi .Jadi, kami mengambil dask, kami mengarahkan csv asli ke dalamnya dan dengan konversi minimal, kami mendorongnya ke lantai. Saat membaca, dask bersumpah pada ambiguitas tipe data dalam beberapa kolom, jadi kami menetapkannya secara eksplisit (demi kejelasan, hal yang sama dilakukan untuk ramp, waktu operasi lebih tinggi dengan mempertimbangkan faktor ini, kamus dengan dtypes dipotong untuk semua pertanyaan untuk kejelasan), sisanya untuk dirinya sendiri . Selanjutnya, untuk verifikasi, kami melakukan perbaikan kecil di lantai, yaitu, kami mencoba mengurangi tipe data menjadi yang paling ringkas, mengganti sepasang kolom dengan teks ya / tidak dengan yang Boolean, dan mengonversi data lain ke tipe yang paling ekonomis (untuk jumlah silinder mesin, uint8 sudah pasti cukup). Kami menyimpan lantai yang dioptimalkan secara terpisah dan melihat apa yang kami dapatkan.Hal pertama yang menyenangkan ketika bekerja dengan Dask adalah bahwa kita tidak perlu menulis sesuatu yang berlebihan hanya karena kita memiliki data yang tebal. Jika Anda tidak memperhatikan fakta bahwa dask diimpor, dan bukan ramp, semuanya tampak sama seperti memproses file dengan seratus baris di ramp (ditambah beberapa peluit dekoratif untuk pembuatan profil).def dask_query():
print('reading CSV file with dask')
with ProgressBar(), ResourceProfiler(dt=0.25) as rprof:
raw_data=dd.read_csv('C:\Open_data\RDW_full.CSV')
model_df=raw_data[raw_data['Merk'].isin(['TESLA MOTORS','TESLA'])]
print(model_df['Taxi indicator'].value_counts().compute())
rprof.visualize()
Sekarang bandingkan dampak file sumber pada kinerja ketika bekerja dengan dasko. Pertama kita membaca file csv yang sama seperti ketika bekerja dengan ramp. Hal yang sama sekitar dua menit dan dua gigabytes memori (1:38 2096 Mb). Tampaknya, apakah layak untuk mencium di semak-semak?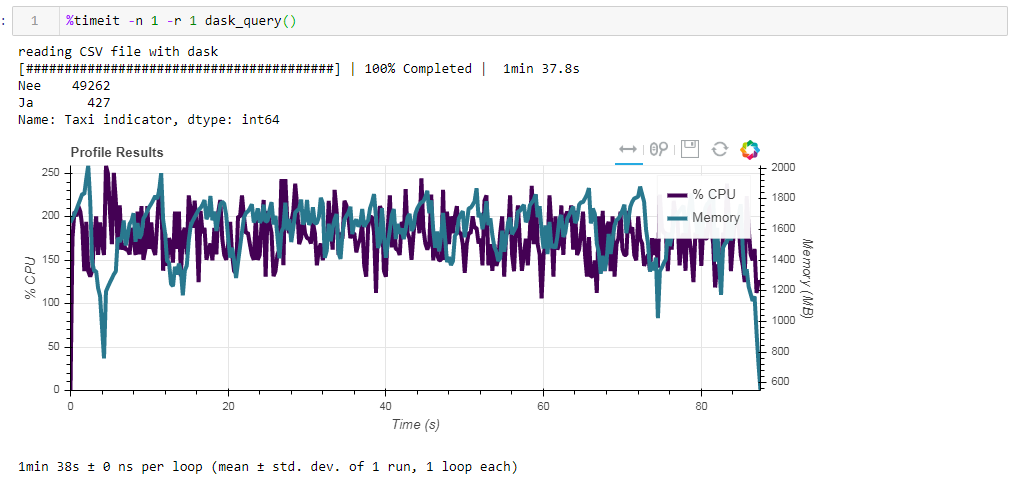 Sekarang beri makan file parket yang tidak dioptimalkan. Permintaan diproses dalam waktu sekitar 54 detik, menghabiskan memori 1388 MB, dan file itu sendiri untuk permintaan sekarang 10 kali lebih kecil (sekitar 700 MB). Di sini bonus sudah terlihat cembung. Pemanfaatan CPU dari ratusan persen adalah paralelisasi di beberapa core.
Sekarang beri makan file parket yang tidak dioptimalkan. Permintaan diproses dalam waktu sekitar 54 detik, menghabiskan memori 1388 MB, dan file itu sendiri untuk permintaan sekarang 10 kali lebih kecil (sekitar 700 MB). Di sini bonus sudah terlihat cembung. Pemanfaatan CPU dari ratusan persen adalah paralelisasi di beberapa core.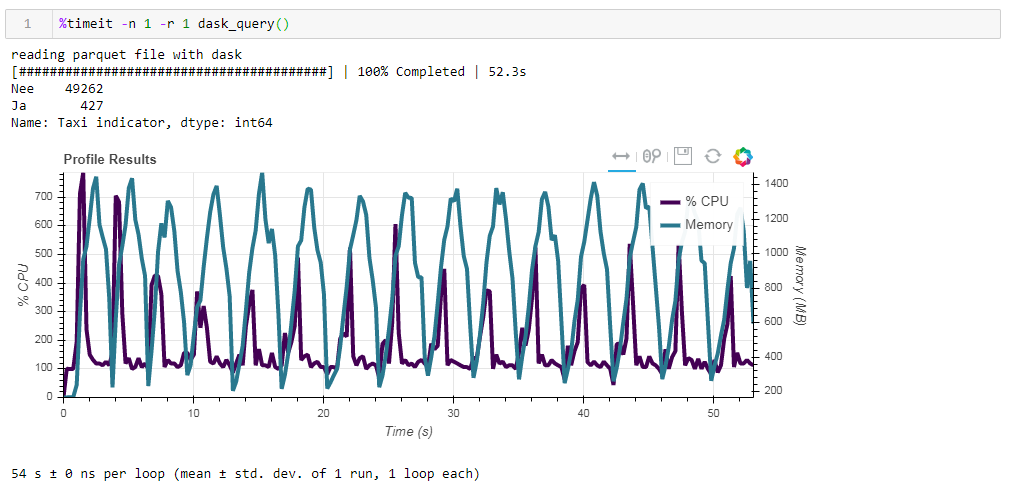 Parket yang sebelumnya dioptimalkan dengan tipe data yang sedikit dimodifikasi dalam bentuk terkompresi hanya 1 MB lebih sedikit, yang berarti bahwa tanpa petunjuk semuanya dikompresi dengan cukup efisien. Peningkatan produktivitas juga tidak terlalu signifikan. Permintaannya membutuhkan 53 detik yang sama dan memakan sedikit memori lebih sedikit - 1332 MB.Berdasarkan hasil latihan kami, kami dapat mengatakan yang berikut:
Parket yang sebelumnya dioptimalkan dengan tipe data yang sedikit dimodifikasi dalam bentuk terkompresi hanya 1 MB lebih sedikit, yang berarti bahwa tanpa petunjuk semuanya dikompresi dengan cukup efisien. Peningkatan produktivitas juga tidak terlalu signifikan. Permintaannya membutuhkan 53 detik yang sama dan memakan sedikit memori lebih sedikit - 1332 MB.Berdasarkan hasil latihan kami, kami dapat mengatakan yang berikut:- Jika data Anda “gemuk” dan Anda terbiasa dengan tanjakan - chunksize akan membantu tanjakan untuk mencerna volume ini, kecepatannya akan tertahankan.
- Jika Anda ingin memeras lebih banyak kecepatan, hemat ruang selama penyimpanan dan Anda tidak menahan hanya menggunakan jalan, maka senja dengan parket adalah kombinasi yang baik.
Akhirnya, soal komputasi malas. Salah satu fitur dari dask adalah bahwa ia menggunakan perhitungan malas, yaitu, perhitungan tidak dilakukan segera seperti yang ditemukan dalam kode, tetapi ketika mereka benar-benar diperlukan atau ketika Anda secara eksplisit memintanya menggunakan metode komputasi. Misalnya, dalam fungsi kami, dask tidak membaca semua data ke dalam memori ketika kami mengindikasikan untuk membaca file. Dia membacanya nanti, dan hanya kolom-kolom itu yang berhubungan dengan permintaan.Ini mudah dilihat pada contoh berikut. Kami mengambil file pra-filter di mana kami hanya menyisakan 12 kolom dari 64 awal, parket terkompresi membutuhkan 203 MB. Jika Anda menjalankan permintaan reguler kami di atasnya, maka itu akan selesai dalam 8,8 detik, dan penggunaan memori puncak akan sekitar 300 MB, yang sesuai dengan sepersepuluh file terkompresi jika Anda menyalipnya dalam csv sederhana.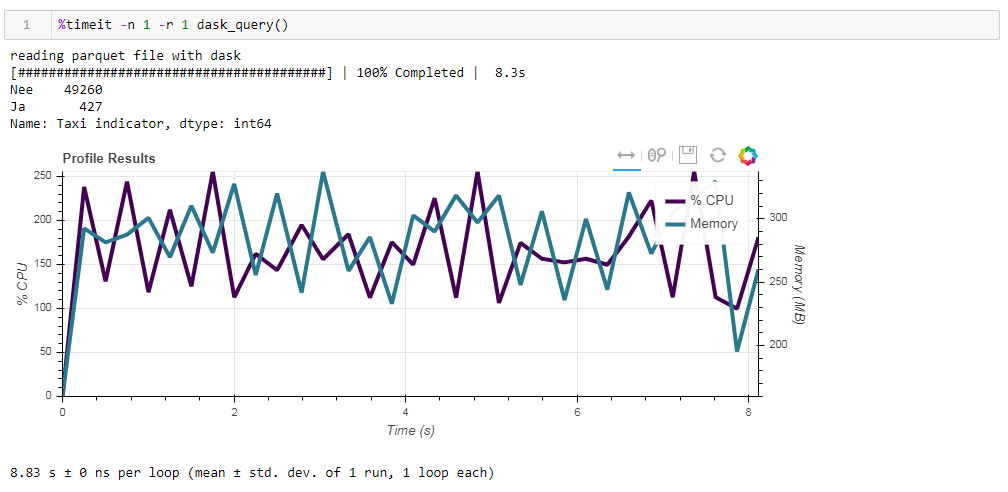 Jika kami secara eksplisit meminta Anda untuk membaca file, dan kemudian mengeksekusi permintaan, maka konsumsi memori akan hampir 10 kali lipat. Kami sedikit memodifikasi fungsi kami dengan membaca file secara eksplisit:
Jika kami secara eksplisit meminta Anda untuk membaca file, dan kemudian mengeksekusi permintaan, maka konsumsi memori akan hampir 10 kali lipat. Kami sedikit memodifikasi fungsi kami dengan membaca file secara eksplisit:def dask_query():
print('reading parquet file with dask')
with ProgressBar(), ResourceProfiler(dt=0.25) as rprof:
raw_data=dd.read_parquet('C:\Open_data\RDW_filtered.parquet' ).compute()
model_df=raw_data[raw_data['Merk'].isin(['TESLA MOTORS','TESLA'])]
print(model_df['Taxi indicator'].value_counts())
rprof.visualize()
Dan inilah yang kami dapatkan, 10,5 detik dan memori 3568 MB (!)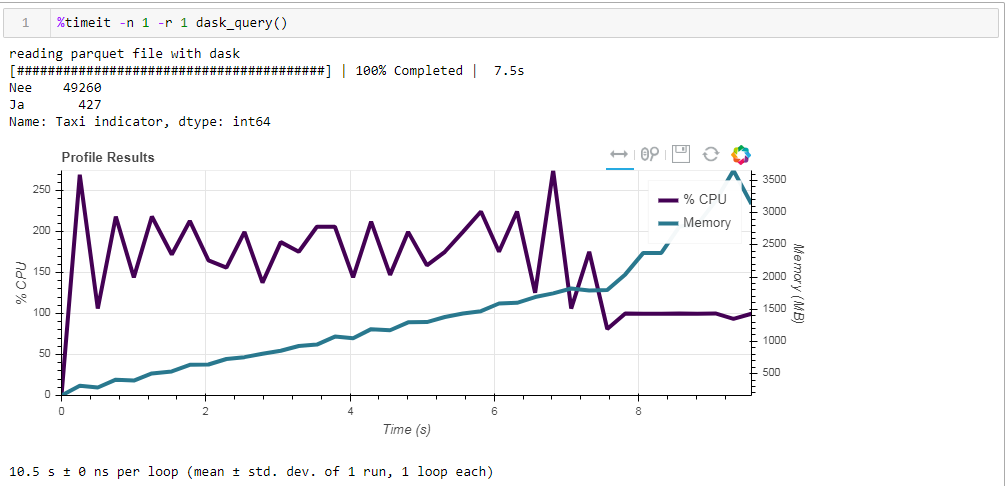 Sekali lagi kami yakin bahwa dask - kompeten dalam tugasnya, dan tidak layak untuk naik ke dalamnya dengan manajemen mikro sekali lagi.
Sekali lagi kami yakin bahwa dask - kompeten dalam tugasnya, dan tidak layak untuk naik ke dalamnya dengan manajemen mikro sekali lagi.