Pada artikel ini saya akan memberi tahu Anda cara mengatur lingkungan pembelajaran mesin dalam 30 menit, membuat jaringan saraf untuk pengenalan gambar dan kemudian menjalankan jaringan yang sama pada unit pemrosesan grafis (GPU).Pertama, mari kita tentukan apa itu jaringan saraf.Dalam kasus kami, ini adalah model matematika, serta implementasi perangkat lunak atau perangkat kerasnya, yang dibangun berdasarkan prinsip organisasi dan berfungsinya jaringan saraf biologis - jaringan sel saraf organisme hidup. Konsep ini muncul dalam studi proses yang terjadi di otak, dan dalam upaya untuk mensimulasikan proses ini.Jaringan saraf tidak diprogram dalam arti kata yang biasa, mereka dilatih. Kemampuan belajar adalah salah satu keuntungan utama dari jaringan saraf dibandingkan algoritma tradisional. Secara teknis, pelatihan terdiri dalam menemukan koefisien koneksi antara neuron. Dalam proses pembelajaran, jaringan saraf mampu mengidentifikasi hubungan yang kompleks antara input dan output, serta melakukan generalisasi.Dari sudut pandang pembelajaran mesin, jaringan saraf adalah kasus khusus metode pengenalan pola, analisis diskriminan, metode clustering dan metode lainnya.Peralatan
Pertama, mari kita berurusan dengan peralatan. Kami membutuhkan server dengan sistem operasi Linux yang diinstal di dalamnya. Peralatan untuk pengoperasian sistem pembelajaran mesin membutuhkan peralatan yang cukup kuat dan, sebagai konsekuensinya, mahal. Bagi mereka yang tidak memiliki mobil bagus, saya sarankan memperhatikan tawaran penyedia cloud. Server yang diperlukan dapat disewa dengan cepat dan hanya membayar untuk saat penggunaan.Dalam proyek-proyek di mana perlu untuk membuat jaringan saraf, saya menggunakan server salah satu penyedia cloud Rusia. Perusahaan ini menawarkan penyewaan cloud server khusus untuk pembelajaran mesin dengan unit pemrosesan grafis (GPU) Tesla V100 yang kuat dari NVIDIA. Singkatnya: menggunakan server dengan GPU dapat menjadi puluhan kali lebih efisien (cepat) dibandingkan dengan server yang serupa dalam biaya di mana CPU digunakan untuk perhitungan (prosesor sentral yang terkenal). Ini dicapai karena spesifikasi arsitektur GPU, yang menangani perhitungan lebih cepat.Untuk melakukan contoh yang dijelaskan di bawah ini, kami membeli server berikut selama beberapa hari:- SSD 150 GB
- RAM 32 GB
- Prosesor Tesla V100 16 Gb dengan 4 core
Ubuntu 18.04 diinstal pada mesin.Atur lingkungan
Sekarang instal di server semua yang Anda butuhkan untuk bekerja. Karena artikel kami terutama untuk pemula, saya akan membicarakan beberapa hal yang akan berguna bagi mereka.Banyak pekerjaan ketika mengatur lingkungan dilakukan melalui baris perintah. Sebagian besar pengguna menggunakan Windows sebagai OS yang berfungsi. Konsol standar dalam OS ini menyisakan banyak yang diinginkan. Karena itu, kami akan menggunakan Cmder / alat yang mudah digunakan . Unduh versi mini dan jalankan Cmder.exe. Selanjutnya, Anda harus terhubung ke server melalui SSH:ssh root@server-ip-or-hostname
Alih-alih server-ip-atau-hostname, tentukan alamat IP atau nama DNS server Anda. Selanjutnya, masukkan kata sandi dan setelah koneksi berhasil, kita harus mendapatkan sesuatu seperti ini.Welcome to Ubuntu 18.04.3 LTS (GNU/Linux 4.15.0-74-generic x86_64)
Bahasa utama untuk mengembangkan model ML adalah Python. Dan platform paling populer untuk menggunakannya di Linux adalah Anaconda .Instal di server kami.Kami mulai dengan memperbarui manajer paket lokal:sudo apt-get update
Instal curl (utilitas baris perintah):sudo apt-get install curl
Unduh versi terbaru dari Anaconda Distribution:cd /tmp
curl –O https://repo.anaconda.com/archive/Anaconda3-2019.10-Linux-x86_64.sh
Kami memulai instalasi:bash Anaconda3-2019.10-Linux-x86_64.sh
Selama proses instalasi, Anda harus mengonfirmasi perjanjian lisensi. Saat instalasi berhasil, Anda akan melihat ini:Thank you for installing Anaconda3!
Untuk mengembangkan model ML, banyak kerangka kerja sekarang dibuat, kami bekerja dengan yang paling populer: PyTorch dan Tensorflow .Menggunakan kerangka kerja memungkinkan Anda untuk meningkatkan kecepatan pengembangan dan menggunakan alat yang sudah jadi untuk tugas standar.Dalam contoh ini, kita akan bekerja dengan PyTorch. Pasang itu:conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
Sekarang kita perlu meluncurkan Notebook Jupyter - alat pengembangan populer di kalangan spesialis ML. Ini memungkinkan Anda untuk menulis kode dan langsung melihat hasil pelaksanaannya. Jupyter Notebook adalah bagian dari Anaconda dan sudah diinstal di server kami. Anda perlu menghubungkannya dari sistem desktop kami.Untuk melakukan ini, pertama-tama kita jalankan Jupyter di server dengan menentukan port 8080:jupyter notebook --no-browser --port=8080 --allow-root
Selanjutnya, buka tab lain di konsol Cmder kami (menu paling atas adalah dialog konsol Baru), sambungkan pada port 8080 ke server melalui SSH:ssh -L 8080:localhost:8080 root@server-ip-or-hostname
Ketika Anda memasukkan perintah pertama, kami akan ditawari tautan untuk membuka Jupyter di browser kami:To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-18788-open.html
Or copy and paste one of these URLs:
http://localhost:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
or http://127.0.0.1:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
Gunakan tautan untuk localhost: 8080. Salin path lengkap dan rekatkan ke bilah alamat browser lokal PC Anda. Notebook Jupyter terbuka.Mari kita buat laptop baru: Baru - Notebook - Python 3.Periksa operasi yang benar dari semua komponen yang kami instal. Kami memperkenalkan contoh kode PyTorch ke Jupyter dan memulai eksekusi (tombol Jalankan):from __future__ import print_function
import torch
x = torch.rand(5, 3)
print(x)
Hasilnya harus seperti ini: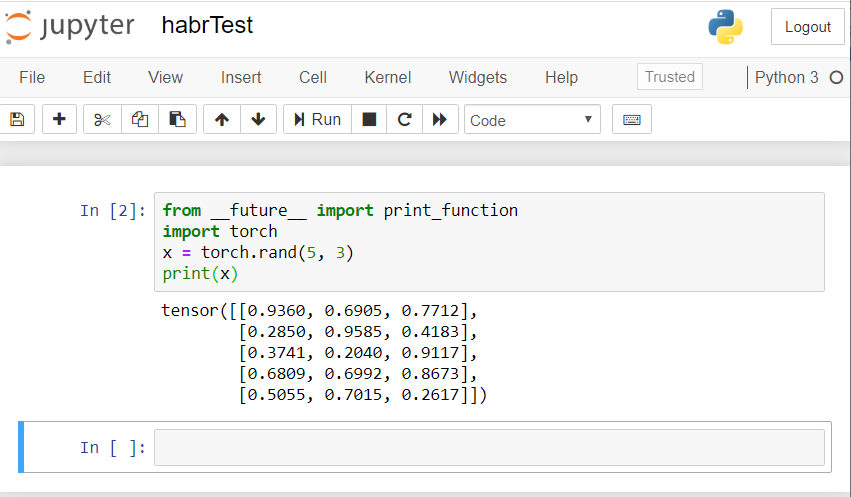 Jika Anda memiliki hasil yang serupa, maka kita semua mengatur dengan benar dan dapat mulai mengembangkan jaringan saraf!
Jika Anda memiliki hasil yang serupa, maka kita semua mengatur dengan benar dan dapat mulai mengembangkan jaringan saraf!Buat jaringan saraf
Kami akan membuat jaringan saraf untuk pengenalan gambar. Kami mengambil panduan ini sebagai dasar .Untuk melatih jaringan, kami akan menggunakan dataset CIFAR10 yang tersedia untuk umum. Dia memiliki kelas: "pesawat terbang", "mobil", "burung", "kucing", "rusa", "anjing", "katak", "kuda", "kapal", "truk". Gambar dalam CIFAR10 memiliki ukuran 3x32x32, yaitu gambar berwarna 3-channel 32x32 piksel.Untuk bekerja, kami akan menggunakan paket PyTorch yang dibuat untuk bekerja dengan gambar - torchvision.Kami akan mengambil langkah-langkah berikut secara berurutan:- Unduh dan normalkan pelatihan dan set data uji
- Definisi jaringan saraf
- Pelatihan jaringan tentang data pelatihan
- Menguji jaringan dengan data uji
- Ulangi pelatihan dan pengujian GPU
Semua kode di bawah ini akan kami jalankan di Jupyter Notebook.Unduh dan normalisasikan CIFAR10
Salin dan jalankan kode berikut di Jupyter:
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Jawabannya harus seperti ini:Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verified
Kami akan mendapatkan beberapa gambar pelatihan untuk memeriksa:
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
img = img / 2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
dataiter = iter(trainloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

Definisi jaringan saraf
Pertama-tama mari kita periksa bagaimana jaringan saraf untuk pengenalan gambar bekerja. Ini adalah jaringan koneksi langsung yang sederhana. Dibutuhkan input, melewati beberapa lapisan satu per satu, dan akhirnya memberikan output.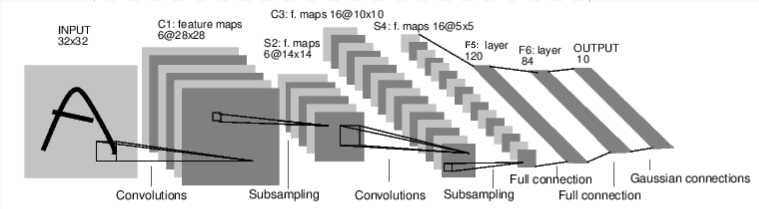 Mari kita buat jaringan serupa di lingkungan kita:
Mari kita buat jaringan serupa di lingkungan kita:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
Kami juga mendefinisikan fungsi kerugian dan pengoptimal
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
Pelatihan jaringan tentang data pelatihan
Kami mulai melatih jaringan saraf kami. Saya menarik perhatian Anda pada fakta bahwa setelah ini, saat Anda menjalankan kode ini, Anda perlu menunggu beberapa saat sampai pekerjaan selesai. Saya butuh 5 menit. Jaringan membutuhkan waktu. for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
Kami mendapatkan hasil berikut: Kami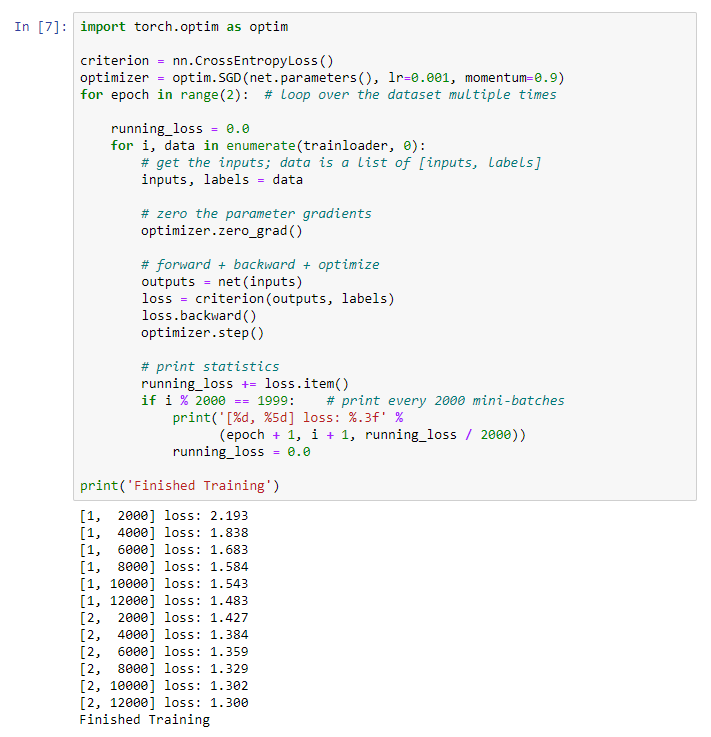 menyimpan model terlatih kami:
menyimpan model terlatih kami:PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
Menguji jaringan dengan data uji
Kami melatih jaringan menggunakan satu set data pelatihan. Tetapi kita perlu memeriksa apakah jaringan telah mempelajari sesuatu.Kami akan memverifikasi ini dengan memprediksi label kelas yang dihasilkan oleh jaringan saraf, dan memeriksa kebenaran. Jika perkiraannya benar, kami menambahkan sampel ke daftar perkiraan yang benar.Mari kita tunjukkan gambar dari test suite:dataiter = iter(testloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
 Sekarang tanyakan jaringan saraf untuk memberi tahu kami apa yang ada di dalam gambar ini:
Sekarang tanyakan jaringan saraf untuk memberi tahu kami apa yang ada di dalam gambar ini:
net = Net()
net.load_state_dict(torch.load(PATH))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))
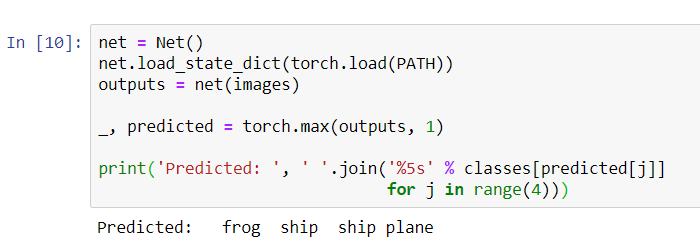 Hasilnya tampak cukup bagus: jaringan mengidentifikasi dengan benar tiga dari empat gambar.Mari kita lihat bagaimana jaringan bekerja di seluruh kumpulan data.
Hasilnya tampak cukup bagus: jaringan mengidentifikasi dengan benar tiga dari empat gambar.Mari kita lihat bagaimana jaringan bekerja di seluruh kumpulan data.
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
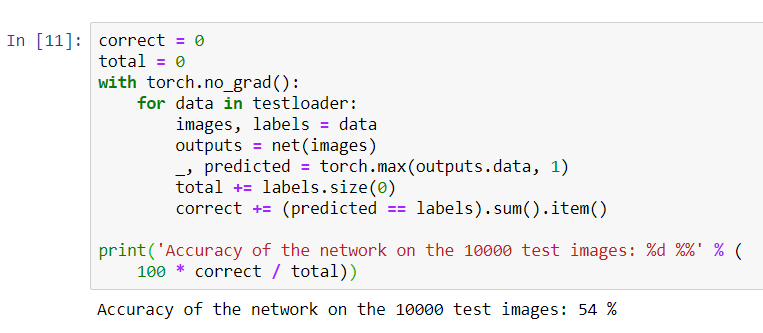 Sepertinya jaringan tahu dan bekerja. Jika dia mendefinisikan kelas secara acak, maka akurasinya adalah 10%.Sekarang mari kita lihat kelas apa yang didefinisikan oleh jaringan dengan lebih baik:
Sepertinya jaringan tahu dan bekerja. Jika dia mendefinisikan kelas secara acak, maka akurasinya adalah 10%.Sekarang mari kita lihat kelas apa yang didefinisikan oleh jaringan dengan lebih baik:class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
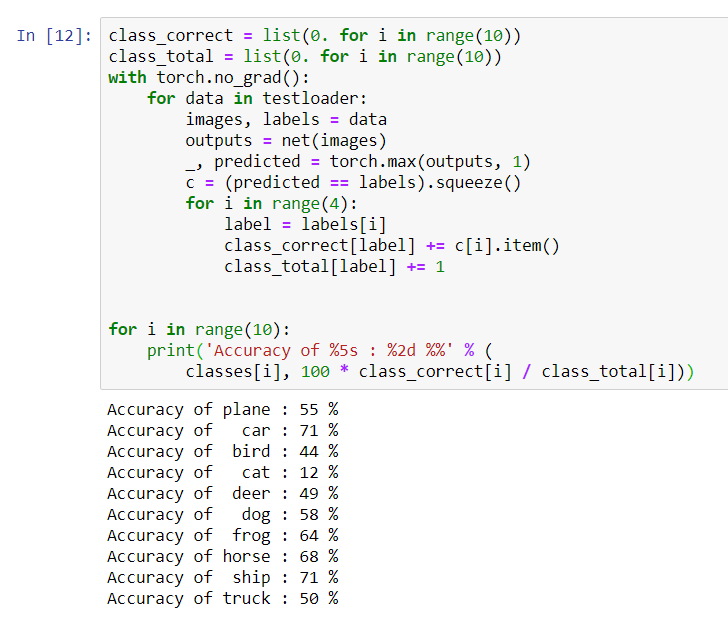 Tampaknya jaringan menentukan mobil dan kapal terbaik: akurasi 71%.Jadi jaringannya berfungsi. Sekarang mari kita coba mentransfer karyanya ke prosesor grafis (GPU) dan lihat perubahannya.
Tampaknya jaringan menentukan mobil dan kapal terbaik: akurasi 71%.Jadi jaringannya berfungsi. Sekarang mari kita coba mentransfer karyanya ke prosesor grafis (GPU) dan lihat perubahannya.Pelatihan jaringan saraf GPU
Pertama, saya akan menjelaskan secara singkat apa itu CUDA. CUDA (Compute Unified Device Architecture) adalah platform komputasi paralel yang dikembangkan oleh NVIDIA untuk komputasi umum pada GPU. Dengan CUDA, pengembang dapat secara signifikan mempercepat aplikasi komputasi menggunakan kemampuan GPU. Di server kami yang kami beli, platform ini sudah diinstal.Pertama-tama mari kita mendefinisikan GPU kita sebagai perangkat cuda pertama yang terlihat.device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
print ( device )
 Kirim jaringan ke GPU:
Kirim jaringan ke GPU:net.to(device)
Kami juga harus mengirim masukan dan sasaran di setiap langkah dan ke GPU:inputs, labels = data[0].to(device), data[1].to(device)
Jalankan pelatihan ulang jaringan di GPU:import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
Kali ini, pelatihan jaringan berlangsung sekitar 3 menit. Ingatlah bahwa tahap yang sama pada prosesor biasa berlangsung 5 menit. Perbedaannya tidak signifikan, ini karena jaringan kami tidak begitu besar. Saat menggunakan array besar untuk pelatihan, perbedaan antara kecepatan GPU dan prosesor tradisional akan meningkat.Sepertinya hanya itu saja. Apa yang berhasil kami lakukan:- Kami memeriksa apakah GPU itu dan memilih server yang memasang GPU itu;
- Kami mengatur lingkungan perangkat lunak untuk membuat jaringan saraf;
- Kami menciptakan jaringan saraf untuk pengenalan gambar dan melatihnya;
- Kami mengulangi pelatihan jaringan menggunakan GPU dan menerima peningkatan kecepatan.
Saya akan dengan senang hati menjawab pertanyaan di komentar.