Kafka Streams adalah perpustakaan Java untuk menganalisis dan memproses data yang disimpan di Apache Kafka. Seperti halnya platform pemrosesan streaming lainnya, platform ini mampu melakukan pemrosesan data dengan dan / atau tanpa pelestarian status secara real time. Dalam posting ini saya akan mencoba menjelaskan mengapa mencapai ketersediaan tinggi (99,99%) bermasalah di Aliran Kafka dan apa yang dapat kita lakukan untuk mencapainya.Apa yang perlu kita ketahui
Sebelum menjelaskan masalah dan solusi yang mungkin, mari kita lihat konsep dasar Kafka Streams. Jika Anda telah bekerja dengan Kafka API untuk Konsumen / Produsen, maka sebagian besar paradigma ini sudah Anda kenal. Pada bagian berikut, saya akan mencoba menjelaskan dalam beberapa kata penyimpanan data dalam partisi, penyeimbangan kembali kelompok konsumen dan bagaimana konsep dasar klien Kafka masuk ke perpustakaan Kafka Streams.Kafka: Mempartisi Data
Di dunia Kafka, aplikasi produsen mengirim data sebagai pasangan kunci-nilai ke topik tertentu. Topiknya sendiri dibagi menjadi satu atau lebih partisi di broker Kafka. Kafka menggunakan kunci pesan untuk menunjukkan di partisi mana data harus ditulis. Akibatnya, pesan dengan kunci yang sama selalu berakhir di partisi yang sama.Aplikasi konsumen diatur ke dalam kelompok konsumen, dan setiap kelompok dapat memiliki satu atau lebih contoh dari konsumen.Setiap instance dari konsumen dalam grup konsumen bertanggung jawab untuk memproses data dari sekumpulan partisi unik dari topik input.
Instans konsumen pada dasarnya adalah cara meningkatkan pengolahan dalam kelompok konsumen Anda.Kafka: Menyeimbangkan Kelompok Konsumen
Seperti yang kami katakan sebelumnya, setiap instance dari grup konsumen menerima sekumpulan partisi unik dari mana ia mengkonsumsi data. Setiap kali konsumen baru bergabung dengan grup, penyeimbangan harus dilakukan sehingga ia mendapat partisi. Hal yang sama terjadi ketika konsumen meninggal, seluruh konsumen harus mengambil partisi untuk memastikan bahwa semua partisi diproses.Kafka Streams: Streams
Pada awal posting ini kami berkenalan dengan fakta bahwa perpustakaan Kafka Streams dibangun berdasarkan API dari produsen dan konsumen dan pemrosesan data diatur dengan cara yang sama dengan solusi standar pada Kafka. Dalam konfigurasi Streaming Kafka, bidang application.id setara dengan group.iddi API konsumen. Kafka Streams pra-membuat sejumlah utas dan masing-masing melakukan pemrosesan data dari satu atau lebih partisi dari topik masukan. Berbicara dalam terminologi API Konsumen, aliran dasarnya bertepatan dengan instance dari Konsumen dari grup yang sama. Thread adalah cara utama untuk menskala pemrosesan data di Kafka Streaming, ini dapat dilakukan secara vertikal dengan menambah jumlah utas untuk setiap aplikasi Streaming Kafka pada satu mesin, atau secara horizontal dengan menambahkan mesin tambahan dengan application.id yang sama.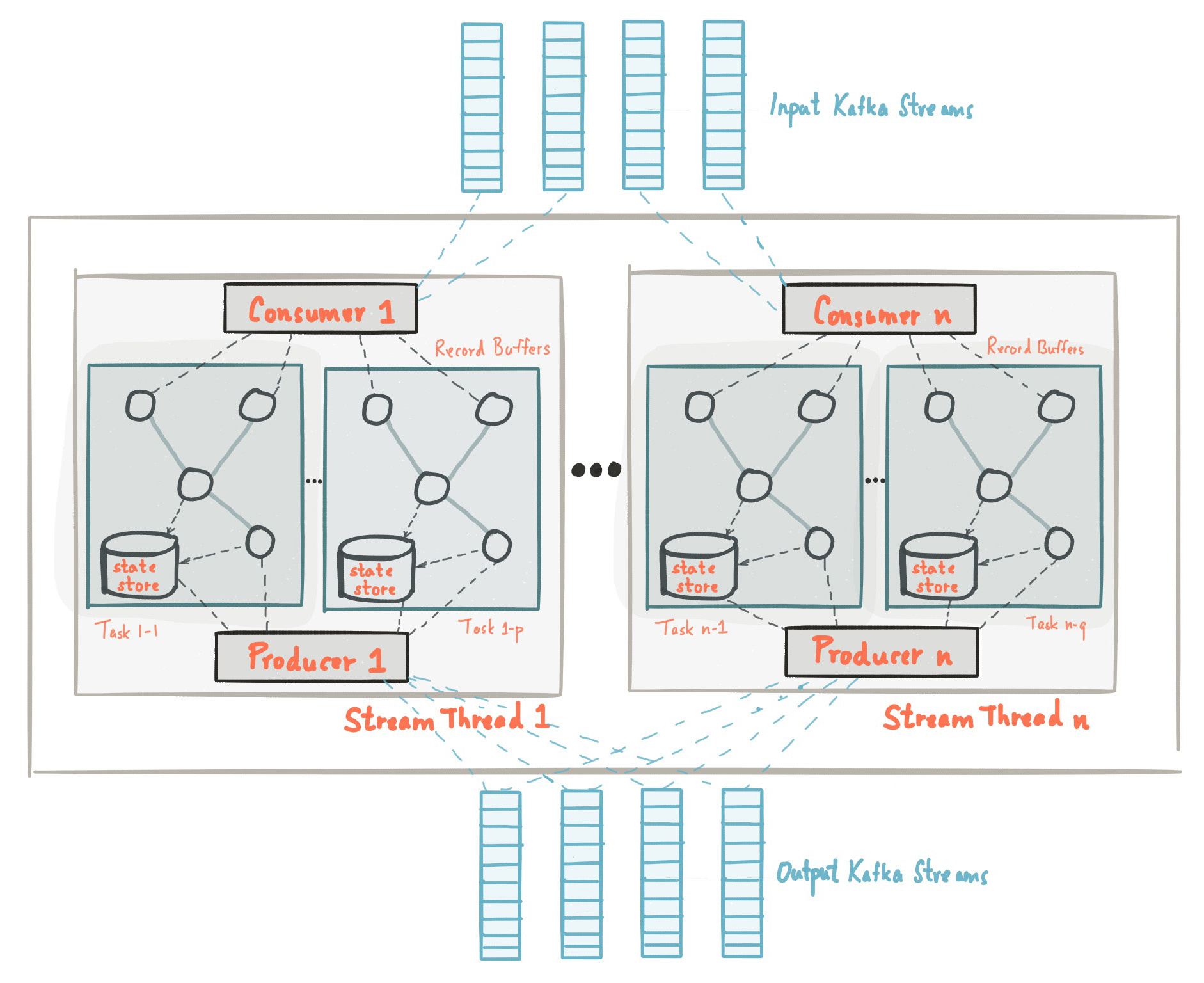 Sumber: kafka.apache.org/21/documentation/streams/architectureAda banyak elemen lagi di Kafka Streaming, seperti tugas, pemrosesan topologi, model threading, dll, yang tidak akan kita bahas dalam posting ini. Informasi lebih lanjut dapat ditemukan di sini.
Sumber: kafka.apache.org/21/documentation/streams/architectureAda banyak elemen lagi di Kafka Streaming, seperti tugas, pemrosesan topologi, model threading, dll, yang tidak akan kita bahas dalam posting ini. Informasi lebih lanjut dapat ditemukan di sini.Kafka Streams: State Storage
Dalam pemrosesan aliran, ada operasi dengan dan tanpa pengawetan negara. Keadaan inilah yang memungkinkan aplikasi untuk mengingat informasi yang diperlukan yang melampaui ruang lingkup catatan yang saat ini sedang diproses.Operasi negara, seperti penghitungan, segala jenis agregasi, penggabungan, dll., Jauh lebih rumit. Ini disebabkan oleh fakta bahwa hanya memiliki satu catatan, Anda tidak dapat menentukan status terakhir (katakanlah, hitung) untuk kunci yang diberikan, jadi Anda perlu menyimpan status aliran Anda di aplikasi Anda. Seperti yang telah kita bahas sebelumnya, setiap utas memproses sekumpulan partisi unik, oleh karena itu, utas hanya memproses sebagian dari seluruh kumpulan data. Ini berarti bahwa setiap utas aplikasi Kafka Streaming dengan application.id yang sama mempertahankan statusnya sendiri yang terisolasi. Kami tidak akan merinci tentang bagaimana negara terbentuk di Kafka Streaming, tetapi penting untuk memahami bahwa negara dipulihkan menggunakan topik log perubahan dan disimpan tidak hanya pada disk lokal, tetapi juga di Kafka Broker.Menyimpan status perubahan log di Kafka Broker sebagai topik terpisah dibuat tidak hanya untuk toleransi kesalahan, tetapi juga agar Anda dapat dengan mudah menggunakan contoh-contoh baru Streaming Kafka dengan application.id yang sama. Karena status disimpan sebagai topik perubahan-log di sisi pialang, instance baru dapat memuat statusnya sendiri dari topik ini.Informasi lebih lanjut tentang penyimpanan negara dapat ditemukan di sini .Mengapa ketersediaan tinggi bermasalah dengan Kafka Streaming?
Kami meninjau konsep dasar dan prinsip-prinsip pemrosesan data dengan Kafka Streaming. Sekarang mari kita coba menggabungkan semua bagian bersama-sama dan menganalisis mengapa mencapai ketersediaan tinggi bisa bermasalah. Dari bagian sebelumnya, kita harus ingat:- Data dalam topik Kafka dibagi menjadi beberapa partisi, yang didistribusikan antara aliran Kafka Streaming.
- Aplikasi Kafka Streaming dengan application.id yang sama, pada kenyataannya, satu kelompok konsumen, dan masing-masing utasnya adalah contoh terpisah dari konsumen.
- Untuk operasi negara, utas mempertahankan negaranya sendiri, yang "dicadangkan" oleh topik Kafka dalam bentuk log perubahan.
- , Kafka , .
TransferWise SPaaS (Stream Processing as a Service)
Sebelum menyoroti esensi dari posting ini, izinkan saya terlebih dahulu memberi tahu Anda apa yang kami buat di TransferWise dan mengapa ketersediaan tinggi sangat penting bagi kami.Di TransferWise, kami memiliki beberapa node untuk pemrosesan streaming, dan setiap node berisi beberapa instance Kafka Streams untuk setiap tim produk. Contoh aliran Kafka yang dirancang untuk tim pengembangan spesifik memiliki application.id khusus dan biasanya memiliki lebih dari 5 utas. Secara umum, tim biasanya memiliki 10-20 utas (setara dengan jumlah contoh konsumen) di seluruh kluster. Aplikasi yang digunakan pada node mendengarkan pada topik input dan melakukan beberapa jenis operasi dengan dan tanpa status pada data input dan menyediakan pembaruan data real-time untuk layanan hilir berikutnya.Tim produk perlu memperbarui data yang dikumpulkan secara real time. Ini diperlukan untuk memberi pelanggan kami kemampuan untuk mentransfer uang secara instan. SLA biasa kami:Pada hari tertentu, 99,99% dari data agregat harus tersedia dalam waktu kurang dari 10 detik.
Untuk memberi Anda ide, selama pengujian stres, Kafka Streaming dapat memproses dan mengagregasi 20.085 pesan input per detik. Dengan demikian, 10 detik SLA di bawah beban normal terdengar cukup dapat dicapai. Sayangnya, SLA kami tidak tercapai selama pembaruan bergulir dari node yang digunakan aplikasi, dan di bawah ini saya akan menjelaskan mengapa ini terjadi.Pembaruan node geser
Di TransferWise, kami sangat percaya pada pengiriman perangkat lunak kami yang berkelanjutan dan biasanya merilis versi baru layanan kami beberapa kali sehari. Mari kita lihat contoh pembaruan layanan berkelanjutan sederhana dan lihat apa yang terjadi selama proses rilis. Sekali lagi, kita harus ingat bahwa:- Data dalam topik Kafka dibagi menjadi beberapa partisi, yang didistribusikan antara aliran Kafka Streaming.
- Aplikasi Kafka Streaming dengan application.id yang sama, pada kenyataannya, satu kelompok konsumen, dan masing-masing utasnya adalah contoh terpisah dari konsumen.
- Untuk operasi negara, utas mempertahankan negaranya sendiri, yang "dicadangkan" oleh topik Kafka dalam bentuk log perubahan.
- , Kafka , .
Proses rilis pada satu node biasanya membutuhkan delapan hingga sembilan detik. Selama rilis, instance Kafka Streams pada node "reboot dengan lembut". Jadi, untuk satu simpul, waktu yang diperlukan untuk memulai kembali layanan dengan benar adalah sekitar delapan hingga sembilan detik. Jelas, mematikan instance Kafka Streams pada node menyebabkan penyeimbangan kembali kelompok konsumen. Karena data dipartisi, semua partisi yang termasuk dalam instance bootable harus didistribusikan antara aplikasi Kafka Streaming aktif dengan application.id yang sama. Ini juga berlaku untuk data agregat yang telah disimpan ke disk. Sampai proses ini selesai, data tidak akan diproses.Replika siaga
Untuk mengurangi waktu penyeimbangan ulang untuk aplikasi Kafka Streams, ada konsep replika cadangan, yang didefinisikan dalam konfigurasi sebagai num.standby.replicas. Replika cadangan adalah salinan dari toko negara bagian setempat. Mekanisme ini memungkinkan untuk meniru toko negara dari satu instance Kafka Streams ke yang lain. Ketika utas Kafka Streams mati karena alasan apa pun, durasi proses pemulihan negara dapat diminimalkan. Sayangnya, untuk alasan yang akan saya jelaskan di bawah ini, bahkan replika cadangan tidak akan membantu dengan pembaruan layanan bergulir.Misalkan kita memiliki dua contoh Kafka Streaming pada dua mesin yang berbeda: node-a dan node-b. Untuk setiap instance Kafka Streaming, num.standby.replicas = 1 ditunjukkan pada 2 node ini. Dengan konfigurasi ini, setiap instance Kafka Streaming mempertahankan salinan repositori pada node lain. Selama pembaruan bergulir, kami memiliki situasi berikut:- Versi layanan yang baru telah digunakan untuk node-a.
- Contoh Streaming Kafka pada node-a dinonaktifkan.
- Penyeimbangan telah dimulai.
- Repositori dari node-a telah direplikasi ke node-b, karena kami menetapkan konfigurasi num.standby.replicas = 1.
- node-b sudah memiliki salinan bayangan node-a, sehingga proses penyeimbangan terjadi hampir secara instan.
- simpul-a mulai lagi.
- simpul-a bergabung dengan sekelompok konsumen.
- Pialang Kafka melihat contoh baru Kafka Streaming dan mulai menyeimbangkan kembali.
Seperti yang bisa kita lihat, num.standby.replicas hanya membantu dalam skenario pemadaman total node. Ini berarti bahwa jika simpul-a jatuh, maka simpul-b dapat terus bekerja dengan benar hampir secara instan. Tetapi dalam situasi pembaruan yang bergulir, setelah terputus, node-a akan bergabung dengan grup lagi, dan langkah terakhir ini akan menyebabkan penyeimbangan kembali. Ketika node-a bergabung dengan grup konsumen setelah reboot, itu akan dianggap sebagai instance baru dari konsumen. Sekali lagi, kita harus ingat bahwa pemrosesan data real-time berhenti sampai sebuah instance baru mengembalikan statusnya dari topik perubahan-log.Harap perhatikan bahwa penyeimbangan ulang partisi saat instance baru bergabung ke grup tidak berlaku untuk Kafka Streams API, karena beginilah cara protokol kelompok konsumen Apache Kafka bekerja.Prestasi: Ketersediaan Tinggi dengan Kafka Streams
Terlepas dari kenyataan bahwa pustaka klien Kafka tidak menyediakan fungsionalitas bawaan untuk masalah yang disebutkan di atas, ada beberapa trik yang dapat digunakan untuk mencapai ketersediaan cluster yang tinggi selama pembaruan yang bergulir. Gagasan di balik replika cadangan tetap valid, dan memiliki mesin cadangan saat waktunya tepat adalah solusi yang baik yang kami gunakan untuk memastikan ketersediaan tinggi jika terjadi kegagalan.Masalah dengan pengaturan awal kami adalah bahwa kami memiliki satu kelompok konsumen untuk semua tim di semua node. Sekarang, alih-alih satu kelompok konsumen, kami memiliki dua, dan yang kedua bertindak sebagai kelompok "panas". Dalam prod, node memiliki variabel khusus CLUSTER_ID, yang ditambahkan ke application.id dari contoh Kafka Streams. Berikut ini contoh konfigurasi Spring Boot application.yml:application.ymlspring.profiles: production
streaming-pipelines:
team-a-stream-app-id: "${CLUSTER_ID}-team-a-stream-app"
team-b-stream-app-id: "${CLUSTER_ID}-team-b-stream-app"
Pada satu titik waktu, hanya satu dari cluster dalam mode aktif, masing-masing, cluster cadangan tidak mengirim pesan secara real time ke layanan mikro hilir. Selama rilis rilis, cluster cadangan menjadi aktif, yang memungkinkan untuk pembaruan yang bergulir di cluster pertama. Karena ini adalah kelompok konsumen yang sangat berbeda, pelanggan kami bahkan tidak melihat adanya pelanggaran dalam pemrosesan, dan layanan selanjutnya terus menerima pesan dari gugus yang baru-baru ini aktif. Salah satu kelemahan yang jelas dari menggunakan kelompok cadangan pelanggan adalah biaya overhead tambahan dan konsumsi sumber daya, tetapi, bagaimanapun, arsitektur ini memberikan jaminan tambahan, kontrol dan toleransi kesalahan dari sistem pemrosesan aliran kami.Selain menambahkan cluster tambahan, ada juga trik yang dapat mengurangi masalah dengan penyeimbangan berulang.Tingkatkan group.initial.rebalance.delay.ms
Dimulai dengan Kafka 0.11.0.0, grup konfigurasi.initial.rebalance.delay.ms telah ditambahkan. Menurut dokumentasi, pengaturan ini bertanggung jawab untuk:Jumlah waktu dalam milidetik yang dimiliki GroupCoordinator akan menunda penyeimbangan awal konsumen grup.
Misalnya, jika kita menetapkan 60.000 milidetik dalam pengaturan ini, maka dengan pembaruan yang bergulir, kita mungkin memiliki jendela kecil untuk rilis rilis. Jika instance Kafka Streaming berhasil me-restart di jendela waktu ini, tidak ada penyeimbangan ulang akan dipanggil. Harap perhatikan bahwa data yang bertanggung jawab atas kejadian aliran Kafka yang dimulai kembali akan terus tidak tersedia hingga node kembali ke mode online. Misalnya, jika sebuah instance reboot membutuhkan waktu sekitar delapan detik, Anda akan memiliki downtime delapan detik untuk data yang menjadi tanggung jawab instance ini.Perlu dicatat bahwa kelemahan utama dari konsep ini adalah bahwa jika terjadi kegagalan simpul, Anda akan menerima penundaan tambahan satu menit selama pemulihan, dengan mempertimbangkan konfigurasi saat ini.Mengecilkan ukuran segmen dalam topik log perubahan
Keterlambatan besar dalam menyeimbangkan aliran Kafka adalah karena pemulihan toko-toko negara dari topik perubahan-log. Topik log perubahan adalah topik terkompresi, yang memungkinkan Anda untuk menyimpan catatan terbaru untuk kunci tertentu dalam topik. Saya akan menjelaskan secara singkat konsep ini di bawah ini.Topik dalam Kafka Broker diorganisasikan dalam segmen. Saat segmen mencapai ukuran ambang yang dikonfigurasi, segmen baru dibuat dan yang sebelumnya dikompresi. Secara default, ambang ini diatur ke 1 GB. Seperti yang Anda ketahui, struktur data utama yang mendasari topik Kafka dan partisi mereka adalah struktur log dengan penulisan maju, yaitu, ketika pesan dikirim ke topik, mereka selalu ditambahkan ke segmen "aktif" terakhir, dan kompresi tidak sedang terjadi.Oleh karena itu, sebagian besar status penyimpanan yang disimpan dalam changelog selalu dalam file "segmen aktif" dan tidak pernah dikompres, menghasilkan jutaan pesan changelog yang tidak terkompresi. Untuk Kafka Streaming, ini berarti bahwa selama penyeimbangan kembali, ketika instance Kafka Streaming memulihkan keadaannya dari topik changelog, ia perlu membaca banyak entri yang berlebihan dari topik changelog. Karena toko-toko negara hanya peduli pada keadaan terakhir, dan bukan tentang sejarah, waktu pemrosesan ini terbuang sia-sia. Mengurangi ukuran segmen akan menyebabkan kompresi data yang lebih agresif, sehingga contoh baru aplikasi Kafka Streaming dapat pulih lebih cepat.Kesimpulan
Meskipun Kafka Streaming tidak menyediakan kemampuan bawaan untuk menyediakan ketersediaan tinggi selama pembaruan layanan bergulir, ini masih dapat dilakukan di tingkat infrastruktur. Kita harus ingat bahwa Kafka Streams bukan "kerangka kerja klaster" tidak seperti Apache Flink atau Apache Spark. Ini adalah perpustakaan Java ringan yang memungkinkan pengembang untuk membuat aplikasi yang dapat diskalakan untuk mengalirkan data. Meskipun demikian, ini menyediakan blok bangunan yang diperlukan untuk mencapai tujuan streaming yang ambisius seperti ketersediaan "99,99%".