Saya secara teratur menemukan situasi di mana banyak pengembang dengan tulus percaya bahwa indeks di PostgreSQL adalah pisau Swiss yang secara universal membantu dengan masalah kinerja permintaan. Cukup menambahkan beberapa indeks baru ke tabel atau untuk memasukkan bidang di suatu tempat di yang sudah ada, dan kemudian (sihir-ajaib!) Semua pertanyaan akan menggunakan indeks ini secara efektif. Pertama, tentu saja, entah itu tidak, atau tidak efisien, atau tidak semuanya. Kedua, indeks tambahan hanya akan menambah masalah kinerja saat menulis.Paling sering, situasi seperti itu terjadi selama pengembangan "lama bermain", ketika tidak ada produk kustom dibuat sesuai dengan model "menulis sekali, memberi, lupa", tetapi, seperti dalam kasus kami, dibuatlayanan dengan siklus hidup yang panjang .Perbaikan terjadi secara iteratif oleh kekuatan banyak tim terdistribusi , yang didistribusikan tidak hanya dalam ruang tetapi juga dalam waktu. Dan kemudian, tanpa mengetahui seluruh sejarah pengembangan proyek atau fitur-fitur dari distribusi data yang diterapkan dalam database-nya, Anda dapat dengan mudah "mengacaukan" dengan indeks. Tetapi pertimbangan dan permintaan pengujian di bawah potongan memungkinkan Anda untuk memprediksi dan mendeteksi bagian dari masalah di muka:
Pertama, tentu saja, entah itu tidak, atau tidak efisien, atau tidak semuanya. Kedua, indeks tambahan hanya akan menambah masalah kinerja saat menulis.Paling sering, situasi seperti itu terjadi selama pengembangan "lama bermain", ketika tidak ada produk kustom dibuat sesuai dengan model "menulis sekali, memberi, lupa", tetapi, seperti dalam kasus kami, dibuatlayanan dengan siklus hidup yang panjang .Perbaikan terjadi secara iteratif oleh kekuatan banyak tim terdistribusi , yang didistribusikan tidak hanya dalam ruang tetapi juga dalam waktu. Dan kemudian, tanpa mengetahui seluruh sejarah pengembangan proyek atau fitur-fitur dari distribusi data yang diterapkan dalam database-nya, Anda dapat dengan mudah "mengacaukan" dengan indeks. Tetapi pertimbangan dan permintaan pengujian di bawah potongan memungkinkan Anda untuk memprediksi dan mendeteksi bagian dari masalah di muka:- indeks yang tidak digunakan
- awalan "klon"
- cap waktu “di tengah”
- boolean diindeks
- array dalam indeks
- Sampah kosong
Yang paling sederhana adalah menemukan indeks yang tidak memiliki lintasan sama sekali . Anda hanya perlu memastikan bahwa reset statistik ( pg_stat_reset()) telah terjadi sejak lama, dan Anda tidak ingin menghapus yang digunakan "jarang, tetapi tepat". Kami menggunakan tampilan sistem pg_stat_user_indexes:SELECT * FROM pg_stat_user_indexes WHERE idx_scan = 0;
Tetapi bahkan jika indeks digunakan dan tidak termasuk dalam pilihan ini, ini tidak berarti bahwa itu cocok untuk permintaan Anda.Indeks apa yang [tidak] cocok
Untuk memahami mengapa beberapa kueri "memburuk pada indeks", kami akan berpikir tentang struktur indeks btree biasa , contoh paling sering di alam. Indeks dari satu bidang biasanya tidak menimbulkan masalah, oleh karena itu, kami mempertimbangkan masalah yang muncul pada gabungan sepasang bidang.Cara yang sangat disederhanakan, seperti yang bisa dibayangkan, adalah "kue berlapis", di mana di setiap lapisan ada pohon yang dipesan sesuai dengan nilai-nilai bidang yang sesuai dalam urutan.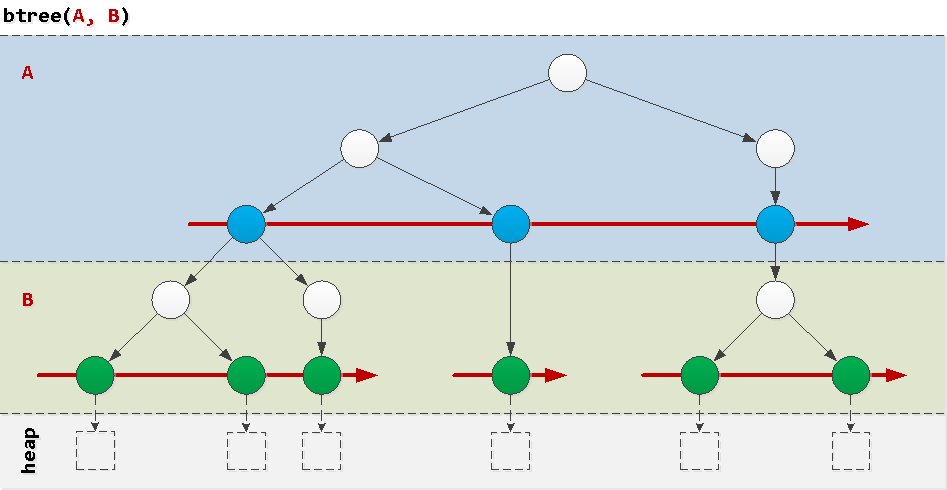 Sekarang jelas bahwa bidang A global memerintahkan, dan B - hanya dalam nilai tertentu A . Mari kita lihat contoh kondisi yang terjadi dalam permintaan nyata, dan bagaimana mereka akan "berjalan" di sekitar indeks.
Sekarang jelas bahwa bidang A global memerintahkan, dan B - hanya dalam nilai tertentu A . Mari kita lihat contoh kondisi yang terjadi dalam permintaan nyata, dan bagaimana mereka akan "berjalan" di sekitar indeks.Bagus: kondisi awalan
Perhatikan bahwa indeks btree(A, B)menyertakan "subindex" btree(A). Ini berarti bahwa semua aturan yang dijelaskan di bawah ini akan berfungsi untuk indeks awalan apa pun.Artinya, jika Anda membuat indeks yang lebih kompleks daripada dalam contoh kami, sesuatu dari jenis btree(A, B, C)- Anda dapat mengasumsikan bahwa database Anda secara otomatis "muncul":btree(A, B, C)btree(A, B)btree(A)
Dan ini berarti bahwa kehadiran "fisik" dari indeks awalan dalam database berlebihan dalam banyak kasus. Lagi pula, semakin banyak indeks yang harus ditulis tabel - semakin buruk bagi PostgreSQL, karena ini disebut Write Amplification - Uber mengeluhkan hal ini (dan di sini Anda dapat menemukan analisis klaim mereka ).Dan jika sesuatu mencegah basis dari hidup dengan baik, ada baiknya mencari dan menghilangkannya. Mari kita lihat sebuah contoh:CREATE TABLE tbl(A integer, B integer, val integer);
CREATE INDEX ON tbl(A, B)
WHERE val IS NULL;
CREATE INDEX ON tbl(A)
WHERE val IS NULL;
CREATE INDEX ON tbl(A, B, val);
CREATE INDEX ON tbl(A);
Permintaan Pencarian Indeks AwalanWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid AND
idx.indexprs IS NULL
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, pre AS (
SELECT
nmt
, wh
, nmf$
, tpf$
, nmi
, def
FROM
fld
ORDER BY
1, 2, 3
)
SELECT DISTINCT
Y.*
FROM
pre X
JOIN
pre Y
ON Y.nmi <> X.nmi AND
(Y.nmt, Y.wh) IS NOT DISTINCT FROM (X.nmt, X.wh) AND
(
Y.nmf$[1:array_length(X.nmf$, 1)] = X.nmf$ OR
X.nmf$[1:array_length(Y.nmf$, 1)] = Y.nmf$
)
ORDER BY
1, 2, 3;
Idealnya, Anda harus mendapatkan pilihan kosong, tetapi lihat - ini adalah grup indeks mencurigakan kami:nmt | wh | nmf$ | tpf$ | nmi | def
---------------------------------------------------------------------------------------
tbl | (val IS NULL) | {a} | {int4} | tbl_a_idx | CREATE INDEX ...
tbl | (val IS NULL) | {a,b} | {int4,int4} | tbl_a_b_idx | CREATE INDEX ...
tbl | | {a} | {int4} | tbl_a_idx1 | CREATE INDEX ...
tbl | | {a,b,val} | {int4,int4,int4} | tbl_a_b_val_idx | CREATE INDEX ...
Kemudian Anda memutuskan sendiri untuk setiap grup apakah layak menghapus indeks yang lebih pendek atau lebih lama tidak diperlukan sama sekali.Bagus: semua konstanta kecuali bidang terakhir
Jika nilai semua bidang indeks, kecuali yang terakhir, ditetapkan oleh konstanta (dalam contoh kami, ini adalah bidang A), indeks dapat digunakan secara normal. Dalam hal ini, nilai dari bidang terakhir dapat ditetapkan secara sewenang-wenang: konstan, ketimpangan, interval, panggilan melalui IN (...)atau = ANY(...). Dan itu juga bisa disortir.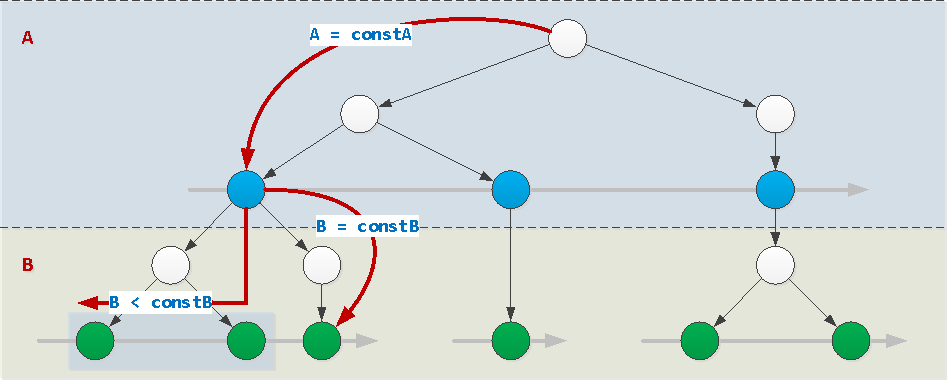
WHERE A = constA AND B [op] constB / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A = constA AND B BETWEEN constB1 AND constB2WHERE A = constA ORDER BY B
Berdasarkan indeks awalan yang dijelaskan di atas, ini akan bekerja dengan baik:WHERE A [op] const / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A BETWEEN const1 AND const2ORDER BY AWHERE (A, B) [op] (constA, constB) / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }ORDER BY A, B
Buruk: enumerasi penuh "lapisan"
Dengan bagian dari kueri, satu-satunya enumerasi gerakan dalam indeks menjadi enumerasi lengkap dari semua nilai di salah satu "lapisan". Beruntung jika ada kesatuan nilai seperti itu - dan jika ada ribuan? ..Biasanya masalah seperti itu muncul jika ketidaksetaraan digunakan dalam kueri , kondisi tidak menentukan bidang yang sebelumnya dalam urutan indeks atau pesanan ini dilanggar selama pengurutan.WHERE A <> constWHERE B [op] const / = ANY(...) / IN (...)ORDER BY BORDER BY B, A
Buruk: interval atau set tidak di bidang terakhir
Sebagai konsekuensi dari yang sebelumnya - jika Anda perlu menemukan beberapa nilai atau kisaran mereka pada beberapa "lapisan" menengah, dan kemudian menyaring atau mengurutkan berdasarkan bidang yang terletak "lebih dalam" di indeks, akan ada masalah jika jumlah nilai unik "di tengah" indeks adalah Bagus.WHERE A BETWEEN constA1 AND constA2 AND B BETWEEN constB1 AND constB2WHERE A = ANY(...) AND B = constWHERE A = ANY(...) ORDER BY BWHERE A = ANY(...) AND B = ANY(...)
Buruk: ekspresi bukannya bidang
Terkadang pengembang tanpa sadar mengubah kolom dalam kueri menjadi sesuatu yang lain - menjadi ekspresi yang tidak ada indeksnya. Ini dapat diperbaiki dengan membuat indeks dari ekspresi yang diinginkan, atau dengan melakukan transformasi terbalik:WHERE A - const1 [op] const2
memperbaiki: WHERE A [op] const1 + const2WHERE A::typeOfConst = const
memperbaiki: WHERE A = const::typeOfA
Kami memperhitungkan kardinalitas bidang
Misalkan Anda perlu indeks (A, B), dan Anda ingin memilih hanya dengan kesetaraan : (A, B) = (constA, constB). Penggunaan indeks hash akan ideal , tetapi ... Selain non-journaling (wal logging) dari indeks tersebut hingga versi 10, mereka juga tidak bisa ada di beberapa bidang:CREATE INDEX ON tbl USING hash(A, B);
Secara umum, Anda telah memilih btree. Jadi apa cara terbaik untuk mengatur kolom di dalamnya - (A, B)atau (B, A)? Untuk menjawab pertanyaan ini, perlu diperhitungkan parameter seperti kardinalitas data di kolom yang sesuai - yaitu, berapa banyak nilai unik yang dikandungnya.Mari kita bayangkan A = {1,2}, B = {1,2,3,4}, dan menggambar garis besar pohon indeks untuk kedua opsi: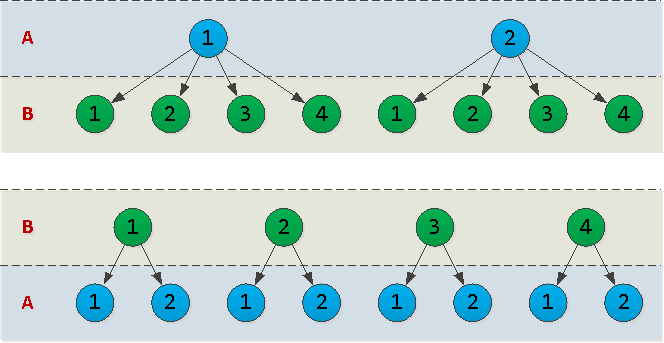 Faktanya, setiap simpul dalam pohon yang kita gambar adalah halaman dalam indeks. Dan semakin banyak, semakin banyak ruang disk yang akan ditempati indeks, semakin lama waktu yang dibutuhkan untuk membacanya.Dalam contoh kami, opsi
Faktanya, setiap simpul dalam pohon yang kita gambar adalah halaman dalam indeks. Dan semakin banyak, semakin banyak ruang disk yang akan ditempati indeks, semakin lama waktu yang dibutuhkan untuk membacanya.Dalam contoh kami, opsi (A, B)memiliki 10 node, dan (B, A)- 12. Artinya, lebih menguntungkan untuk meletakkan "bidang" dengan nilai unik sesedikit mungkin "pertama" .Buruk: banyak dan tidak pada tempatnya (stempel waktu "di tengah")
Karena alasan ini, selalu terlihat mencurigakan jika bidang dengan variabilitas yang jelas besar seperti timestamp [tz] bukan yang terakhir dalam indeks Anda . Sebagai aturan, nilai bidang cap waktu meningkat secara monoton, dan bidang indeks berikut ini hanya memiliki satu nilai pada setiap titik waktu.CREATE TABLE tbl(A integer, B timestamp);
CREATE INDEX ON tbl(A, B);
CREATE INDEX ON tbl(B, A);

Permintaan pencarian untuk indeks cap waktu non-final [tz]WITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
'timestamp' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamptz' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamp' = ANY(opc$[1:array_length(opc$, 1) - 1]) OR
'timestamptz' = ANY(opc$[1:array_length(opc$, 1) - 1])
ORDER BY
1, 2;
Di sini kami segera menganalisis baik jenis bidang input itu sendiri maupun kelas operator yang diterapkan padanya - karena beberapa fungsi timestamptz seperti date_trunc dapat berubah menjadi bidang indeks.nmt | nmi | def | nmf$ | tpf$ | opc$
----------------------------------------------------------------------------------
tbl | tbl_b_a_idx | CREATE INDEX ... | {b,a} | {timestamp,int4} | {timestamp,int4}
Buruk: terlalu sedikit (boolean)
Sisi lain dari koin yang sama, itu menjadi situasi di mana indeks adalah bidang boolean , yang hanya dapat mengambil 3 nilai NULL, FALSE, TRUE. Tentu saja, keberadaannya masuk akal jika Anda ingin menggunakannya untuk pengurutan terapan - misalnya, dengan menetapkannya sebagai jenis simpul dalam hierarki pohon - apakah itu folder atau daun ("folder pertama").CREATE TABLE tbl(
id
serial
PRIMARY KEY
, leaf_pid
integer
, leaf_type
boolean
, public
boolean
);
CREATE INDEX ON tbl(leaf_pid, leaf_type);
CREATE INDEX ON tbl(public, id);
Tetapi, dalam kebanyakan kasus, ini bukan kasusnya, dan permintaan datang dengan beberapa nilai spesifik dari bidang boolean. Dan kemudian menjadi mungkin untuk mengganti indeks dengan bidang ini dengan versi kondisional:CREATE INDEX ON tbl(id) WHERE public;
Permintaan pencarian Boolean dalam indeksWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
(
'bool' = ANY(tpf$) OR
'bool' = ANY(opc$)
) AND
NOT(
ARRAY(
SELECT
nmf$[i:i+1]::text
FROM
generate_series(1, array_length(nmf$, 1) - 1) i
) &&
ARRAY[
'{leaf_pid,leaf_type}'
]
)
ORDER BY
1, 2;
nmt | nmi | def | nmf$ | tpf$ | opc$
------------------------------------------------------------------------------------
tbl | tbl_public_id_idx | CREATE INDEX ... | {public,id} | {bool,int4} | {bool,int4}
Array dalam btree
Titik terpisah adalah upaya untuk "mengindeks array" menggunakan indeks btree. Ini sepenuhnya dimungkinkan karena operator terkait berlaku untuk mereka :(<, >, = . .) , B-, , . ( ). , , .
Tapi masalahnya adalah bahwa penggunaan sesuatu yang dia ingin operator inklusi dan persimpangan : <@, @>, &&. Tentu saja, ini tidak berhasil - karena mereka membutuhkan jenis indeks lain . Bagaimana btree seperti itu tidak berfungsi untuk fungsi mengakses elemen tertentu arr[i].Kami belajar menemukan:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, pid
integer
, list
integer[]
);
CREATE INDEX ON tbl(pid);
CREATE INDEX ON tbl(list);
Array permintaan pencarian di btreeWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid AND
cli.relam = (
SELECT
oid
FROM
pg_am
WHERE
amname = 'btree'
LIMIT 1
)
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, nmf$
, tpf$
, def
FROM
fld
WHERE
tpf$ && ARRAY(
SELECT
typname
FROM
pg_type
WHERE
typname ~ '^_'
)
ORDER BY
1, 2;
nmt | nmi | nmf$ | tpf$ | def
--------------------------------------------------------
tbl | tbl_list_idx | {list} | {_int4} | CREATE INDEX ...
Entri indeks NULL
Masalah terakhir yang cukup umum adalah "membuang sampah sembarangan" indeks dengan entri sepenuhnya NULL. Artinya, catatan di mana ekspresi yang diindeks di setiap kolom adalah NULL . Catatan seperti itu tidak memiliki manfaat praktis, tetapi menambah kerusakan pada setiap sisipan.Biasanya mereka muncul ketika Anda membuat bidang FK atau hubungan nilai dengan padding opsional dalam tabel. Kemudian roll indeks sehingga FK bekerja dengan cepat ... dan ini dia. Semakin sedikit koneksi akan diisi, semakin banyak "sampah" akan masuk ke dalam indeks. Kami akan mensimulasikan:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, fk
integer
);
CREATE INDEX ON tbl(fk);
INSERT INTO tbl(fk)
SELECT
CASE WHEN i % 10 = 0 THEN i END
FROM
generate_series(1, 1000000) i;
Dalam kebanyakan kasus, indeks semacam itu dapat dikonversi ke yang bersyarat, yang juga membutuhkan waktu lebih sedikit:CREATE INDEX ON tbl(fk) WHERE (fk) IS NOT NULL;
_tmp=# \di+ tbl*
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+----------------+-------+----------+----------+---------+-------------
public | tbl_fk_idx | index | postgres | tbl | 36 MB |
public | tbl_fk_idx1 | index | postgres | tbl | 2208 kB |
public | tbl_pkey | index | postgres | tbl | 21 MB |
Untuk menemukan indeks seperti itu, kita perlu mengetahui distribusi data yang sebenarnya - yaitu, setelah semua, membaca semua isi tabel dan menempatkannya sesuai dengan WHERE-kondisi terjadinya (kita akan melakukan ini menggunakan dblink ), yang dapat memakan waktu sangat lama .Permintaan pencarian untuk entri NULL dalam indeksWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisprimary AND
idx.indisready AND
idx.indisvalid AND
NOT EXISTS(
SELECT
NULL
FROM
pg_constraint
WHERE
conindid = cli.oid
LIMIT 1
) AND
pg_relation_size(cli.oid) > 1 << 20
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, regexp_replace(
CASE
WHEN def ~ ' USING btree ' THEN
regexp_replace(def, E'.* USING btree (.*?)($| WHERE .*)', E'\\1')
END
, E' ([a-z]*_pattern_ops|(ASC|DESC)|NULLS\\s?(?:FIRST|LAST))'
, ''
, 'ig'
) fld
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, q AS (
SELECT
nmt
, $q$
SET search_path = $q$ || quote_ident((TABLE sch)) || $q$, public;
SELECT
ARRAY[
count(*)
$q$ || string_agg(
', coalesce(sum((' || coalesce(wh, 'TRUE') || ')::integer), 0)' || E'\n' ||
', coalesce(sum(((' || coalesce(wh, 'TRUE') || ') AND (' || fld || ' IS NULL))::integer), 0)' || E'\n'
, '' ORDER BY nmi) || $q$
]
FROM
$q$ || quote_ident((TABLE sch)) || $q$.$q$ || quote_ident(nmt) || $q$
$q$ q
, array_agg(clioid ORDER BY nmi) oid$
, array_agg(nmi ORDER BY nmi) idx$
, array_agg(fld ORDER BY nmi) fld$
, array_agg(wh ORDER BY nmi) wh$
FROM
fld
WHERE
fld IS NOT NULL
GROUP BY
1
ORDER BY
1
)
, res AS (
SELECT
*
, (
SELECT
qty
FROM
dblink(
'dbname=' || current_database() || ' port=' || current_setting('port')
, q
) T(qty bigint[])
) qty
FROM
q
)
, iter AS (
SELECT
*
, generate_subscripts(idx$, 1) i
FROM
res
)
, stat AS (
SELECT
nmt table_name
, idx$[i] index_name
, pg_relation_size(oid$[i]) index_size
, pg_size_pretty(pg_relation_size(oid$[i])) index_size_humanize
, regexp_replace(fld$[i], E'^\\((.*)\\)$', E'\\1') index_fields
, regexp_replace(wh$[i], E'^\\((.*)\\)$', E'\\1') index_cond
, qty[1] table_rec_count
, qty[i * 2] index_rec_count
, qty[i * 2 + 1] index_rec_count_null
FROM
iter
)
SELECT
*
, CASE
WHEN table_rec_count > 0
THEN index_rec_count::double precision / table_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_cover_prc
, CASE
WHEN index_rec_count > 0
THEN index_rec_count_null::double precision / index_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_null_prc
FROM
stat
WHERE
index_rec_count_null * 4 > index_rec_count
ORDER BY
1, 2;
-[ RECORD 1 ]--------+--------------
table_name | tbl
index_name | tbl_fk_idx
index_size | 37838848
index_size_humanize | 36 MB
index_fields | fk
index_cond |
table_rec_count | 1000000
index_rec_count | 1000000
index_rec_count_null | 900000
index_cover_prc | 100.00 -- 100%
index_null_prc | 90.00 -- 90% NULL-""
Saya harap beberapa pertanyaan dalam artikel ini akan membantu Anda.